Материалы по тегу: llm
|
10.08.2023 [17:04], Владимир Мироненко
NVIDIA AI Workbench ускорит внедрение генеративного ИИ предприятиямиNVIDIA анонсировала набор инструментов NVIDIA AI Workbench, который позволяет разработчикам быстро создавать, тестировать и настраивать предварительно обученные модели генеративного ИИ на платформах NVIDIA — от ПК и рабочих станций до ЦОД, публичного облака и сервиса NVIDIA DGX Cloud. Сервис AI Workbench доступен через упрощённый интерфейс, работающий в локальной системе. С его помощью разработчики могут настраивать и тестировать модели из популярных репозиториев, таких как Hugging Face, GitHub и NVIDIA NGC, используя проприетарные данные, а также получать доступ к облачным ресурсам, когда возникает необходимость в масштабировании. Затем готовые модели можно развернуть на нескольких платформах. 
Источник изображения: NVIDIA Вице-президент NVIDIA по корпоративным вычислениям, говорит, что причиной создания AI Workbench является сложность и трудоёмкость настройки больших моделей ИИ. Проекты ИИ корпоративного масштаба могут потребовать поиска нужной платформы и инструментов в нескольких репозиториях, а также наличие навыков настройки модели для конкретного варианта использования. Задача ещё больше усложняется, когда проекты необходимо перемещать из одной инфраструктуры в другую. NVIDIA AI Workbench позволит разработчики настраивать и запускать генеративный ИИ всего за несколько кликов. Он позволяет объединить все необходимые модели, фреймворки, наборы для разработки ПО, открытые библиотеки и ИИ-платформы NVIDIA в единый набор инструментов для разработчиков. По словам NVIDIA, решение AI Workbench уже используют Dell Technologies, HPE, HP, Lambda, Lenovo, Supermicro и многие другие вендоры. NVIDIA также анонсировала четвертую версию своей программной ИИ-платформы NVIDIA AI Enterprise, которая предлагает инструменты, необходимые для внедрения и настройки генеративного ИИ. Платформа включает фреймворк NVIDIA NeMo, службу NVIDIA Triton и ПО NVIDIA Base Command Manager Essentials. NVIDIA AI Enterprise 4.0 будет интегрирована в маркетплейсы партнёров компании, включая AWS, Google Cloud Platform и Microsoft Azure, а также Oracle Cloud Infrastructure.
04.07.2023 [17:20], Владимир Мироненко
Обойдёмся без NVIDIA: MosaicML перенесла обучение ИИ на ускорители AMD Instinct MI250 без модификации кодаРазработчик решений в области генеративного ИИ MosaicML, недавно перешедший в собственность Databricks, сообщил о хороших результатах в обучении больших языковых моделей (LLM) с использованием ускорителей AMD Instinct MI250 и собственной платформы. Компания рассказала, что подыскивает от имени своих клиентов новое «железо» для машинного обучения, поскольку NVIDIA в настоящее время не в состоянии обеспечить своими ускорителями всех желающих. MosaicML пояснила, что требования к таким чипам просты:

Источник изображений: MosaicML Как отметила компания, ни один из чипов до настоящего времени смог полностью удовлетворить все требования MosaicML. Однако с выходом обновлённых версий фреймворка PyTorch 2.0 и платформы ROCm 5.4+ ситуация изменилась — обучение LLM стало возможным на ускорителях AMD Instinct MI250 без изменений кода при использовании её стека LLM Foundry. 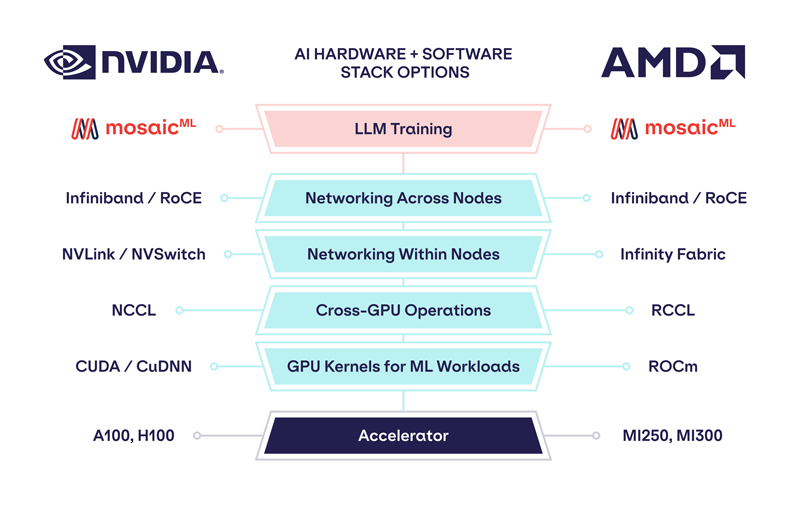 Некоторые основные моменты:
При этом никаких изменений в коде не потребовалось. 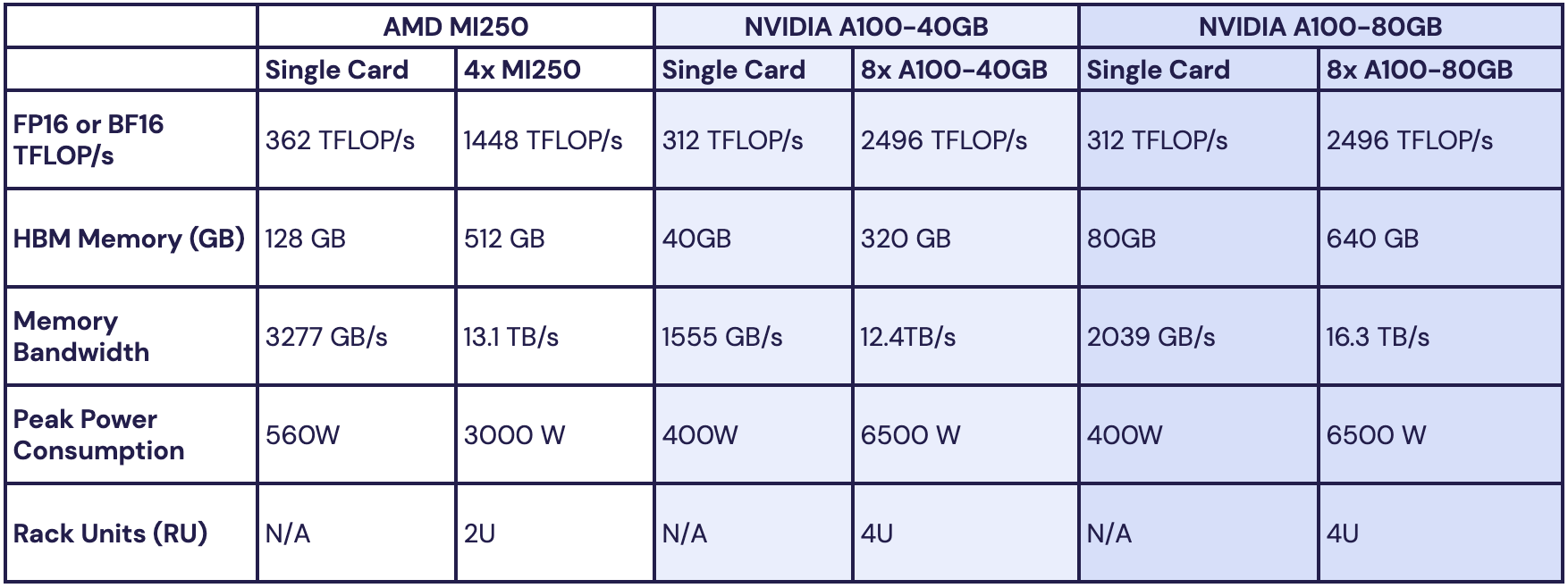 Все результаты получены на одном узле из четырёх MI250, но компания работает с гиперскейлерами для проверки возможностей обучения на более крупных кластерах AMD Instinct. «В целом наши первоначальные тесты показали, что AMD создала эффективный и простой в использовании программно-аппаратный стек, который может конкурировать с NVIDIA», — сообщила MosaicML. Это важный шаг в борьбе с доминирующим положением NVIDIA на рынке ИИ.
02.07.2023 [16:01], Руслан Авдеев
Безопасность открытых проектов на базе LLM оказалась невысокойНовые ИИ-проекты с открытым исходным кодом на базе больших языковых моделей набирают огромную популярность за считаные месяцы. Но, как сообщает Dark Reading, уровень их безопасности оставляет желать лучшего. Тем более что из тысяч действующих версий наиболее популярны одни из самых молодых вариантов. Как выяснила компания Rezilion, занимающаяся проектами в сфере кибербезопасности, использующие решения на основе LLM компании неизбежно ставят свой бизнес под угрозу. Так, проанализировав 50 самых популярных проектов на базе LLM на GitHub, компания пришла к интересным выводам. Для оценки использовался инструмент Scorecard от Open Source Security Foundation, который учитывает различные характеристики проектов, от числа уязвимостей до того, как осуществляется поддержка, а также другие факторы. 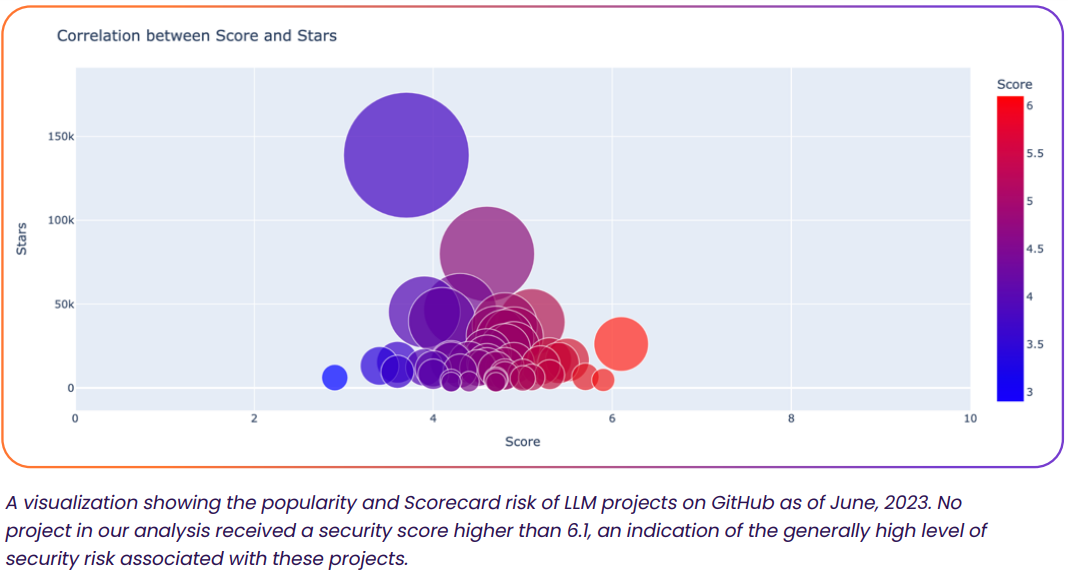
Источник: Rezilion Известно, что с момента публичного дебюта ChatGPT, на GitHub появились более 30 тыс. проектов, использующих GPT-3.5, причём они активно интегрируются в самые разные программные решения. Исследователи составили «карту» популярных проектов, где по оси y отмечался уровень их популярности, а по оси x — уровень безопасности на основе рейтинга OpenSSF Scorecard. В итоге ни один из оценивавшихся проектов не набрал больше 6,1 балла из 10 возможных. Другими словами, все самые популярные решения на основе LLM связаны с высоким уровнем риска, а средний балл и вовсе составил 4,6. 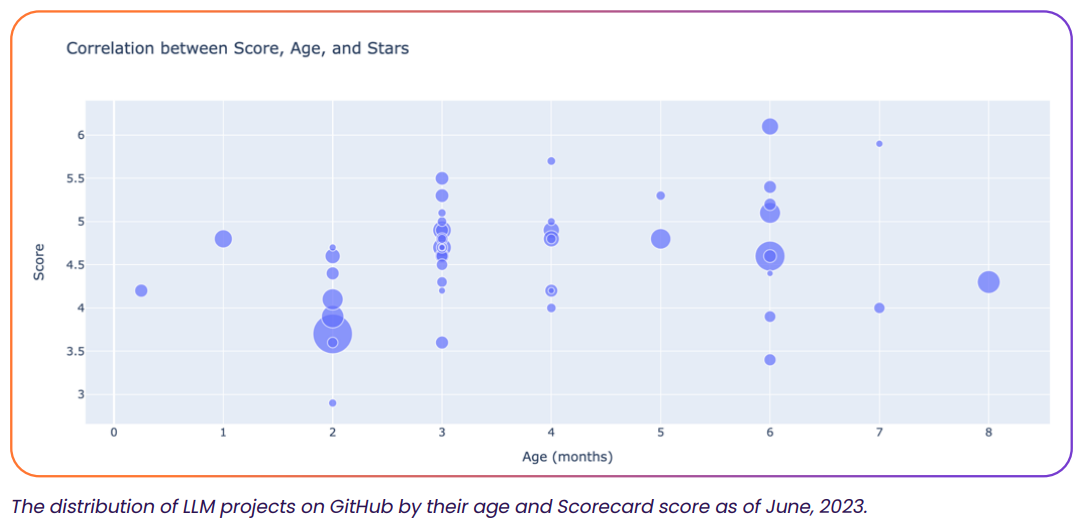
Источник: Rezilion Примечательно, что самый популярный проект Auto-GPT, набравший на GitHub почти 140 тыс. звёзд в местном рейтинге, появился в репозитории меньше трёх месяцев назад и получил рейтинг Scorecard 3,7 — решение является чрезвычайно рискованным. Как заявляют в Rezilion, для новых проектов характерен экспоненциальный рост популярности, но разработчикам и службам информационной безопасности стоит осознавать риски, связанные с применением подобных решений. По данным экспертов организации, когда речь идёт о новом проекте, невозможно достоверно прогнозировать, будет ли он эволюционировать и поддерживаться. Быстро достигнув пика популярности, многие проекты сохраняют невысокий уровень безопасности — когда исследователи оценили соотношение возраста проектов и их уровня в Scorecard, выяснилось, что чаще всего встречались популярные разработки возрастом два месяца и рейтингом 4,5–5 баллов из 10.
28.06.2023 [16:43], Владимир Мироненко
Snowflake и NVIDIA помогут клиентам использовать собственные данные для создания ИИ-приложенийSnowflake, предоставляющая услуги по облачному хранению и обработке данных, и NVIDIA объявили о заключении соглашения о сотрудничестве, благодаря которому компаниям станет проще создавать генеративные приложения искусственного интеллекта (ИИ), используя свои данные в безопасной облачной среде Snowflake Data Cloud. Используя Snowflake Data Cloud, корпоративным клиентам не придётся отправлять на стороны проприетарные данные для обучения и настройки генеративных ИИ и чат-ботов. Возможность тюнинга LLM без перемещения данных позволяет полностью защитить конфиденциальную информацию и управлять ею в пределах платформы Snowflake. Клиентам Snowflake будет обеспечен доступ к базовым моделям LLM и возможностям обучения с помощью NVIDIA NeMo. Они также получат доступ к механизму NeMo Guardrails, который защищает модели от появления «галлюцинаций» и обеспечивает соответствие заданным бизнес-темам и требованиям безопасности. 
Источник изображений: NVIDIA Симбиоз Snowflake Data Cloud и NeMo позволит корпоративным клиентам обучать специализированные большие языковые модели (LLM) с навыками в конкретной области знаний, способные извлекать информацию из источников данных, которые надёжно хранятся в границах облака. Это позволит также сократить как затраты компаний, так и задержки в передаче данных. Фокус на предметно-ориентированные данные характерен для индивидуализированных моделей генеративного ИИ. Кроме того, в ходе саммита Snowflake объявила о расширении партнёрства с Microsoft с целью внедрения генеративных моделей искусственного интеллекта и расширенных возможностей машинного обучения в Data Cloud, что позволит интегрировать новые продукты в сфере ИИ, в разработке приложений, управлении данными и т.д. Сообщается, что компании будут реализовывать новые программы, предоставляя совместные решения своим клиентам. Snowflake также увеличит расходы на Azure, и обе компании будут вместе работать над выводом продуктов на рынок.
27.06.2023 [19:00], Владимир Мироненко
NVIDIA похвасталась рекордами H100 в новом бенчмарке MLPerf для генеративного ИИNVIDIA сообщила, что во всех восьми ИИ-бенчмарках MLPerf Training v3.0 её ускорители H100 установили новые рекорды, причём как по отдельности, так и в составе кластеров. В частности, коммерчески доступный кластер из 3584 ускорителей H100, созданным стартапом Inflection AI и облаком CoreWeave, смог завершить обучение ИИ-модели GPT-3 менее чем за 11 минут. Компания Inflection AI, основанная в 2022 году, использовала возможности решений NVIDIA для создания продвинутой большой языкой модели (LLM) для своего первого проекта под названием Pi. Компания планирует выступать в качестве ИИ-студии, создавая персонализированные ИИ, с которыми пользователи могли бы взаимодействовать простыми и естественными способомами. Inflection AI намерена в сотрудничестве с CoreWeave создать один из крупнейших в мире ИИ-кластеров на базе ускорителей NVIDIA. «Сегодня наши клиенты массово создают современные генеративные ИИ и LLM благодаря тысячам ускорителей H100, объединённых быстрыми сетями InfiniBand с малой задержкой, — сообщил Брайан Вентуро (Brian Venturo), соучредитель и технический директор CoreWeave. — Наша совместная с NVIDIA заявка MLPerf наглядно демонстрирует их высокую производительность». Отдельно подчёркивается, что благодаря NVIDIA Quantum-2 InfiniBand облачный кластер CoreWeave обеспечил такую же производительность, что и локальный ИИ-суперкомпьютер NVIDIA. 
Источник изображений: NVIDIA NVIDIA отметила, что H100 показали высочайшую производительность во всех тестах MLPerf, включая LLM, рекомендательные системы, компьютерное зрение, обработка медицинских изображений и распознавание речи. «Это были единственные чипы, которые прошли все восемь тестов, продемонстрировав универсальность ИИ-платформы NVIDIA» — сообщила компания. А благодаря оптимизации всего стека NVIDIA удалось добиться в тесте LLM практически линейного роста производительности при увеличении количества ускорителей с сотен до тысяч. Отдельно компания напомнила об энергоэффективности H100. 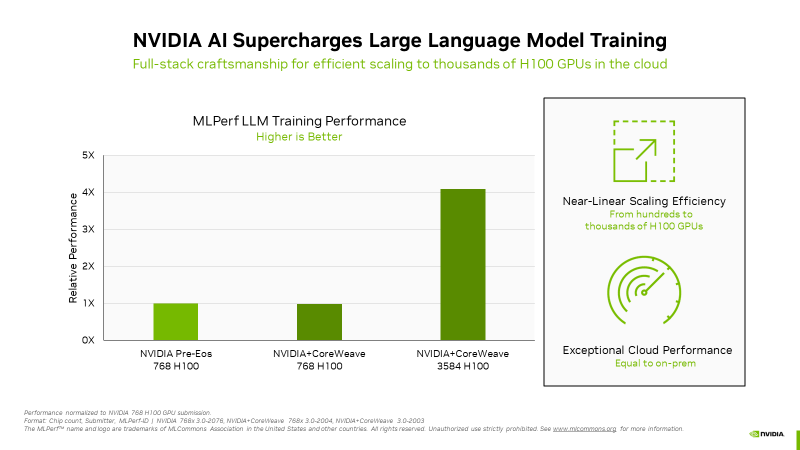 Также сообщается, что обновлённый бенчмарк MLPerf для рекомендательных систем использует больший набор данных и более современную модель, что позволяет лучше отразить проблемы, с которыми сталкиваются провайдеры облачных услуг. NVIDIA была единственной компанией, представившей результаты расширенного теста. Также компания представила результаты MLPerf для платформ L4 и Jetson. Ну а в следующем раунде MLPerf стоит ждать появления NVIDIA Grace Hopper. 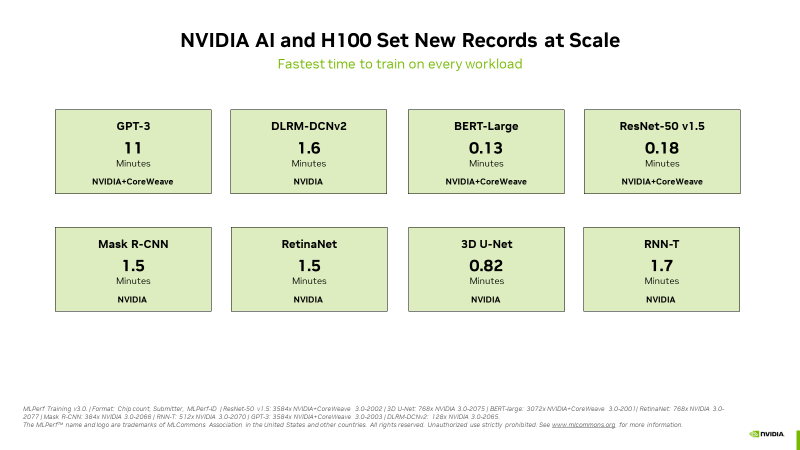 В текущем раунде результаты тестов с использованием платформы NVIDIA представили десяток компаний. Заявки поступили от крупных производителей систем, включая ASUS, Dell Technologies, GIGABYTE, Lenovo и QCT. Более 30 замеров было сделано на ускорителях H100. NVIDIA отметила прозрачность и объективность тестов, поэтому пользователи могут полностью полагаться на результаты MLPerf для принятия решения о покупке систем.
27.06.2023 [16:56], Владимир Мироненко
Databricks купила разработчика генеративного ИИ MosaicML за $1,3 млрдСтартап Databricks, разработчик платформы машинного обучения, анализа и обработки данных, объявил о приобретении компании-разработчика решений в области генеративного ИИ MosaicML Inc. С помощью разработанных MosaicML языковых моделей компании смогут обучать и выполнять точную настройку генеративных ИИ-моделей на основе собственных данных с высоким качеством и низкой стоимостью, а технологии оптимизации обучения моделей MosaicML помогут снизить затраты. MosaicML наиболее известна своим собственным семейством больших языковых моделей (LLM) MPT, с более чем 3,3 млрд загрузок модели MPT-7B. Семейство LLM компании с открытым исходным кодом основано на архитектуре MPT-7B, построенной с 7 млрд параметров и контекстным окном на 64 тыс. токенов. На днях MosaicML выпустила модель MPT-30B с 30 млрд параметров, которая гораздо мощнее MPT-7B и превосходит по качеству модель OpenAI GPT-3 (175 млрд параметров). 
Источник изображения: MosaicML MosaicML сообщила, что размер MPT-30B был специально подобран для развёртывания всего на одном ускорителе — либо NVIDIA A100 80 Гбайт (16-бит точность), либо A100 40 Гбайт (8-бит точность). По словам MosaicML, другие сопоставимые LLM, такие как Falcon-40B, имеют большее количество параметров и не могут обслуживаться на одном ускорителе, что увеличивает минимальную стоимость системы инференса. Платформа Databricks Lakehouse в сочетании с технологиями MosaicML предложит клиентам простой, быстрый и экономичный способ сохранить контроль над данными, а также обеспечить их безопасность и защитить правf собственности. Размещая модели в Databricks Lakehouse, компании смогут адаптировать их к конкретным корпоративным данным и безопасно развёртывать их. Использование обслуживаемых моделей, таких как от OpenAI, может привести к утечке данных и другим рискам. Это особенно важно для строго регулируемых отраслей — модель и данные должны оставаться вместе в изолированном окружении. 
Источник изображения: Databricks Кроме того, решения MosaicML обеспечивают в 2–7 раз более быстрое обучение моделей по сравнению со стандартными подходами, предлагая при этом линейное масштабирование. Компания утверждает, что модели с несколькими миллиардами параметров теперь можно обучить за часы, а не за дни. Согласно пресс-релизу, при применении интегрированной платформы Databricks и MosaicML обучение и использование LLM будет стоить тысячи долларов, а не миллионы. «Теперь Databricks может расширить свою платформу для создания, обучения и размещения традиционных моделей машинного обучения на большие языковые модели, — заявил Джастин ДеБрабант (Justin DeBrabant), старший вице-президент ActionIQ Inc. — Это означает, что Databricks предлагает продукты и услуги на платформе Lakehouse. которые простираются от ETL до аналитики SQL, пользовательского машинного обучения, а теперь и до размещённых LLM».
21.06.2023 [18:38], Владимир Мироненко
HPE предложит в аренду ИИ-суперкомпьютер для тренировки больших языковых моделейКомпания Hewlett Packard Enterprise (HPE) анонсировала на конференции HPE Discover 2023 — GreenLake for LLM (HPE GreenLake для больших языковых моделей) — облачный сервис на основе подписки, который предоставит предприятиям доступ к суперкомпьютерной платформе HPE Cray XD и необходимому ПО для создания и запуска крупномасштабных моделей ИИ. HPE GreenLake для больших языковых моделей в облаке «позволяет выполнять отдельные крупномасштабные задания ИИ и высокопроизводительных вычислений на сотнях или тысячах CPU или GPU одновременно, что очень сильно отличается от облачных предложений общего назначения», — отметил Джастин Хотард (Justin Hotard), исполнительный вице-президент и гендиректор лаборатории высокопроизводительных вычислений (HPC) и искусственного интеллекта (ИИ). 
Источник изображения: HPE GreenLake for LLM предоставляется HPE в партнёрстве с немецким стартапом в области ИИ Aleph Alpha GmbH, который предлагает готовые к использованию LLM для обработки и анализа текста и изображений. В частности, пользователи получат доступ к предварительно обученной модели Aleph Alpha Luminous, доступной на нескольких языках, которая позволяет клиентам использовать свои собственные данные для дообучения и точной настройки модели. С её помощью клиенты смогут создавать различные виды приложений и интегрировать их в свои собственные бизнес-процессы. Luminous, в отличие от ChatGPT, больше нацелена на промышленность и правительственные организации, чем на конечных потребителей. По словам HPE, это решение уже используется различными организациями в сфере здравоохранения и финансовых услуг, а также в юридической сфере в качестве цифрового помощника. 
Источник изображения: HPE Клиенты также получат доступ к среде ML-разработки HPE и ПО для управления данными машинного обучения, которые обеспечивают возможности быстрого обучения моделей ИИ, а также интеграции, отслеживания и аудита данных, на которых они обучаются. Эта платформа основана на технологии, полученной компанией HPE в результате приобретения компании Defined AI, а также на библиотеке моделей ИИ, которая будет включать как модели с открытым исходным кодом, так и проприетарные сторонние модели. Для сервиса будет использоваться инфраструктура на основе суперкомпьютерной платформы HPE Cray XD с ускорителями NVIDIA H100, которая к концу 2023 года будет развёрнута в ЦОД Q01 QScale в Квебеке (Канада), а в начале 2024 года услуга будет доступна для клиентов в Европе. Сообщается, что HPE GreenLake for LLM — лишь первое из серии специализированных ИИ-решений HPE. Другие предложения будут включать решения в области моделирования климата, здравоохранения и медико-биологических наук, финансовых услуг, производства и транспорта.
20.06.2023 [15:10], Владимир Мироненко
«Яндекс» откроет компаниям доступ к бета-тестированию генеративного ИИ YandexGPT уже в июлеРоссийская компания «Яндекс» в июле откроет для компаний доступ к бета-тестированию генеративного ИИ YandexGPT (нейросеть YaLM 2.0) на своей облачной платформе Yandex Cloud, пишет «Интерфакс» со ссылкой на заявление компании. «Яндекс» запустил YandexGPT в прошлом месяце — возможности нейросети можно попробовать в режиме «давай придумаем» в голосовом помощнике «Алиса». «С июля 2023 первые пользователи смогут протестировать сервис для решения актуальных бизнес-задач и совместно с командой Yandex Cloud определить наиболее значимые бизнес-сценарии для развития YandexGPT на облачной платформе», — сообщил «Яндекс». 
Источник изображения: Pixabay Сообщается, что доступ к закрытому тестированию нейросети получит ограниченное число компаний, которые смогут с её помощью создавать умных помощников и ИИ-чат-ботов, а также генерировать текстовый контент. Для участия в проекте компания должна подать заявку с описанием задачи, которую собирается решить с помощью YandexGPT, чтобы специалисты Yandex Cloud смогли оценить, насколько подходит для этого данная версия нейросети. Тестирование YandexGPT будет проводиться в двух режимах. Режим Playground (UI) позволит компании протестировать возможности сервиса для решения бизнес-задач. А в режиме YandexGPT API компании попробуют интегрировать YandexGPT в свои приложения. В «Яндексе» сообщили «Интерфаксу», что возможности YandexGPT могут быть востребованы в крупных банках, ретейле, промышленности, а также других отраслях, добавив, что на этапе тестирования YandexGPT не будет тарифицироваться. «Модель тарификации пока прорабатывается, один из возможных вариантов — по запросам к API», — пояснили в компании.
13.06.2023 [14:22], Владимир Мироненко
Salesforce добавила в свои продукты безопасный генеративный ИИАмериканская компания Salesforce Inc., разработчик одноимённой CRM-платформы, добавила поддержку больших языковых моделей (LLM) в своё портфолио. Генеративный ИИ теперь можно интегрировать в платформу Einstein (новая версия Salesforce Data Cloud), аналитику Tableau, диспетчер Flow и набор инструментов MuleSoft для связывания SaaS-приложений, данных и устройств в облаке и на локальных серверах для помощи в автоматизации бизнес-процессов, пишет ресурс SiliconANGLE. Важной особенностью Einstein является слой Einstein Trust Layer, который, по словам компании, делает её облачную платформу открытой и расширяемой. Как утверждает Salesforce, Trust Layer предотвращает включение проприетарных данных в общедоступные модели, повышает качество контента, создаваемого ИИ, и интегрирует генеративные ответы ИИ в бизнес-процессы, обеспечивая при этом соблюдение правил конфиденциальности, безопасности, резидентности и норм соответствия. Salesforce подчеркнула надёжность моделей ИИ как основной фактор в разработке Trust Layer. Согласно проведённому компанией исследованию, 73 % сотрудников считает, что генеративный ИИ создаёт новые риски для безопасности. Почти 60 % планирующих использовать эту технологию, отметили, что не знают, как обеспечить безопасность данных. В дополнение к собственным LLM Salesforce поддерживаются модели OpenAI, Anthropic PBC, Cohere. В дальнейшем компаниия планирует обеспечить поддержку других сторонних моделей. 
Источник изображения: Salesforce ИИ-бот Einstein GPT включает шлюз, который можно использовать для интеграции моделей из облаков Amazon и Google, а также специфичных для доменов и локально размещаемых моделей. Salesforce подчеркнула, что подсказки и ответы клиентов никогда не покидают её инфраструктуру, а клиенты, которые обучили собственные модели, могут напрямую подключаться к AI Cloud посредством Trust Layer. Salesforce также разработала оптимизированные подсказки ИИ, которые можно настроить для конкретной компании-заказчика. Компания привела примеры использования предварительно обученного генеративного ИИ. Продавцы смогут автоматически создавать персонализированные электронные письма, основанные на данных CRM. Сервисные группы смогут создавать брифинги по обслуживанию, сводки по обращениям и заказы на работу на основе данных об обращениях и истории клиентов. Использование технологии позволит маркетологам сегментировать аудиторию с помощью запросов на естественном языке, а также поможет специалистам по электронной коммерции адаптировать описания продуктов для покупателей на основе имеющихся о них данных. Интеграция с платформой для совместной работы Salesforce Slack позволит пользователям создавать новые рабочие процессы. Наконец, менеджеры по продажам смогут создавать визуализации в Tableau с подсказками на естественном языке, а разработчики будут получать предложения по коду и дополнения непосредственно в Visual Studio.
03.05.2023 [21:12], Владимир Мироненко
MosaicML представила инференс-платформу Mosaic ML Inference и серию моделей MosaicML Foundation SeriesMosaicML, провайдер инфраструктуры генеративного искусственного интеллекта, основанный бывшими сотрудниками Intel и учёными-исследователями, анонсировал инференс-платформу Mosaic ML Inference и серию моделей MosaicML Foundation Series, которые компании могут задействовать в качестве основы при создании собственных моделей ИИ. Как сообщается в пресс-релизе, это решение позволит разработчикам быстро, легко и по доступной цене развёртывать генеративные модели ИИ. «Благодаря добавлению возможностей инференса MosaicML теперь предлагает комплексное решение для обучения и развёртывания генеративного ИИ по наиболее эффективной цене, доступной на сегодняшний день», — отмечено в документе. Клиенты MosaicML отметили, что малые модели, обученные на собственных предметно-ориентированных данных, работают лучше, чем большие универсальные модели вроде GPT 3.5. 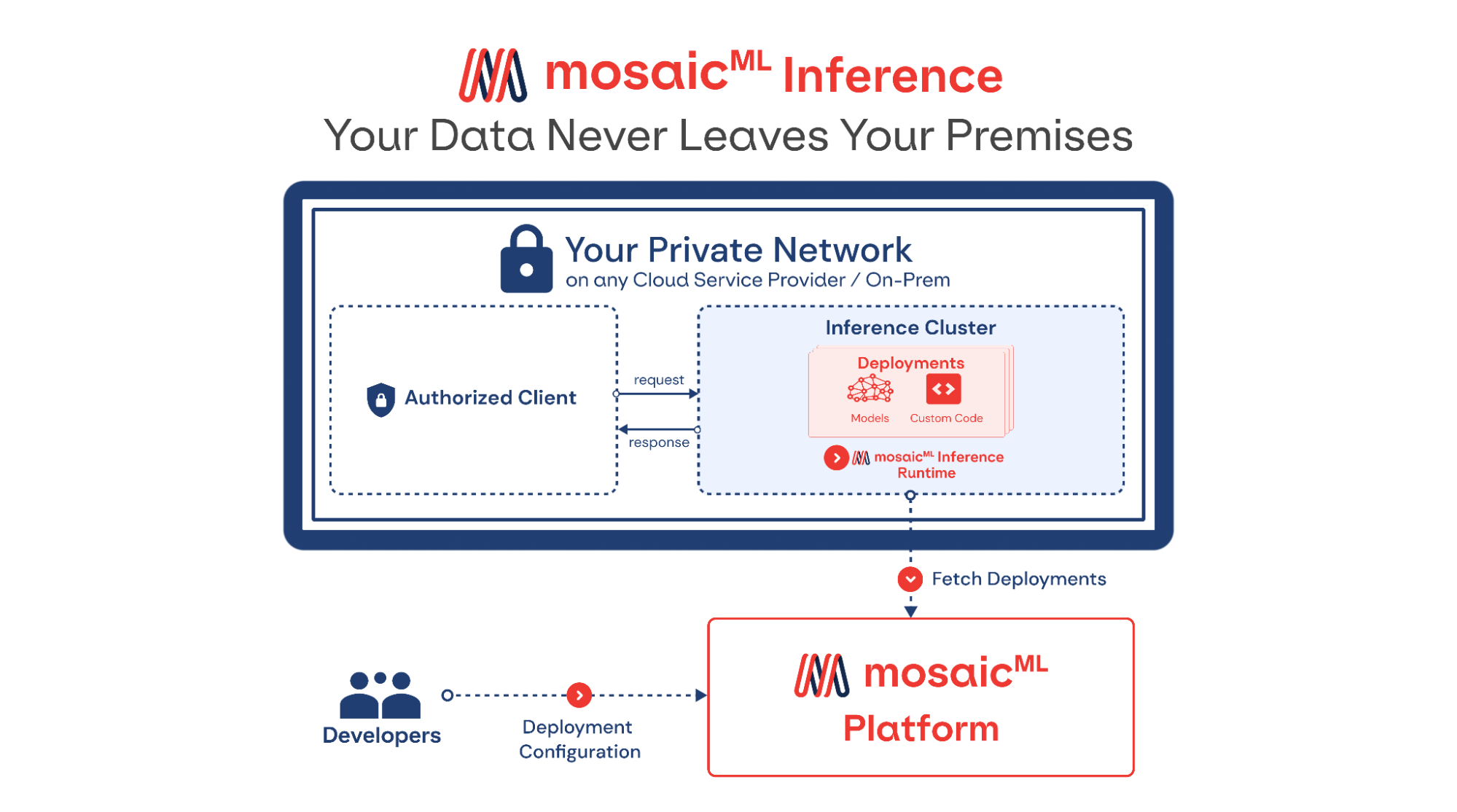
Источник изображений: MosaicML Гендиректор Навин Рао (Naveen Rao) сообщил ресурсу SiliconANGLE, что ценность решения компании для корпоративных клиентов включает два компонента: сохранение конфиденциальности и снижение затрат. Используя решение Inference от MosaicML, клиенты смогут развёртывать ИИ-модели с затратами в четыре раза меньше, чем при использовании большой языковой модели (LLM) от OpenAI, и в 15 раз дешевле при создании изображений, чем при использовании DALL-E 2 этой же компании. «Мы предоставляем инструменты, работающие в любом облаке, которые позволяют клиентам предварительно обучать, настраивать и обслуживать модели, — сказал Рао. — Если клиент обучает модель, он может быть уверен, что эта модель принадлежит ему». С запуском нового сервиса клиенты MosaicML получают доступ к ряду LLM с открытым исходным кодом, включая Instructor-XL, Dolly и GPTNeoX, которые они могут точно настроить в соответствии со своими потребностями. Все модели получат одинаковую оптимизацию и доступность, что позволит им функционировать с меньшими затратами при развёртывании с помощью MosaicML Inference. 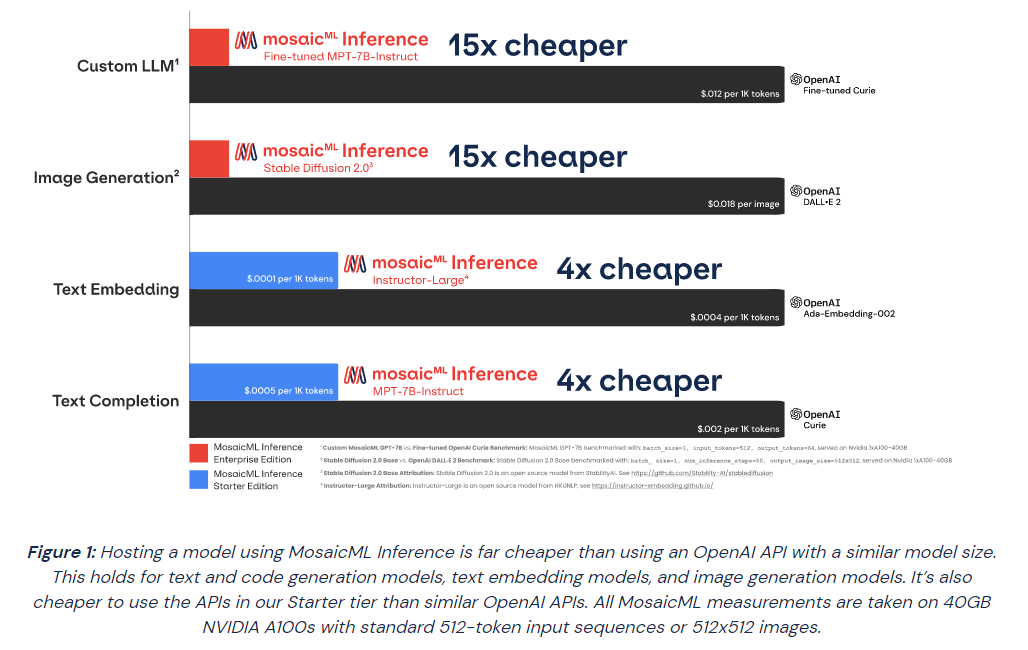 «Это модели с открытым исходным кодом, поэтому клиенты по определению могут настраивать и настраивать и обслуживать их с помощью наших инструментов, — сказал Рао. Компания готова помочь клиентам в работе с их ИИ-моделям. Разработчики смогут выполнять развёртывание в безопасном кластере локально или в облачной инфраструктуре AWS, CoreWeave, Lambda, OCI и GCP. Данные никогда не покидают защищённую среду. Также MosaicML Inference предлагает непрерывный мониторинг метрик кластера. Кроме того, компания предлагает модель MosaicML Foundational Model, одним из преимуществ которой является очень большое «контекстное окно» — более 64 тыс. токенов или около 50 тыс. слов. Для сравнения, максимальное количество токенов GPT-4 составляет 32 768 или около 25 тыс. слов. Чтобы продемонстрировать работу модели, Рао предоставил ей содержание «Великого Гэтсби» Ф. Скотта Фицджеральда и попросил написать эпилог. |
|

