Материалы по тегу: инференс
|
11.04.2025 [11:00], Сергей Карасёв
NTT представила ИИ-чип для обработки видео на периферииКомпания NTT объявила о создании ИИ-чипа, предназначенного для задач инференса на периферии. Изделие может применяться для обработки видео высокой чёткости, в том числе в формате 4K, в реальном времени на устройствах со строгими ограничениями по мощности. В качестве сфер применения новинки NTT выделяет беспилотные летательные аппараты и камеры видеонаблюдения. Например, благодаря представленному чипу дроны могут использоваться для обнаружения прохожих и объектов, таких как автомобили, с высоты до 150 м. Для повышения эффективности инференса при одновременном снижении энергопотребления задействованы специальные алгоритмы. Входное изображение высокого разрешения сегментируется на фрагменты, после чего производится независимая обработка каждого из них. Это позволяет обнаруживать объекты небольшого размера. 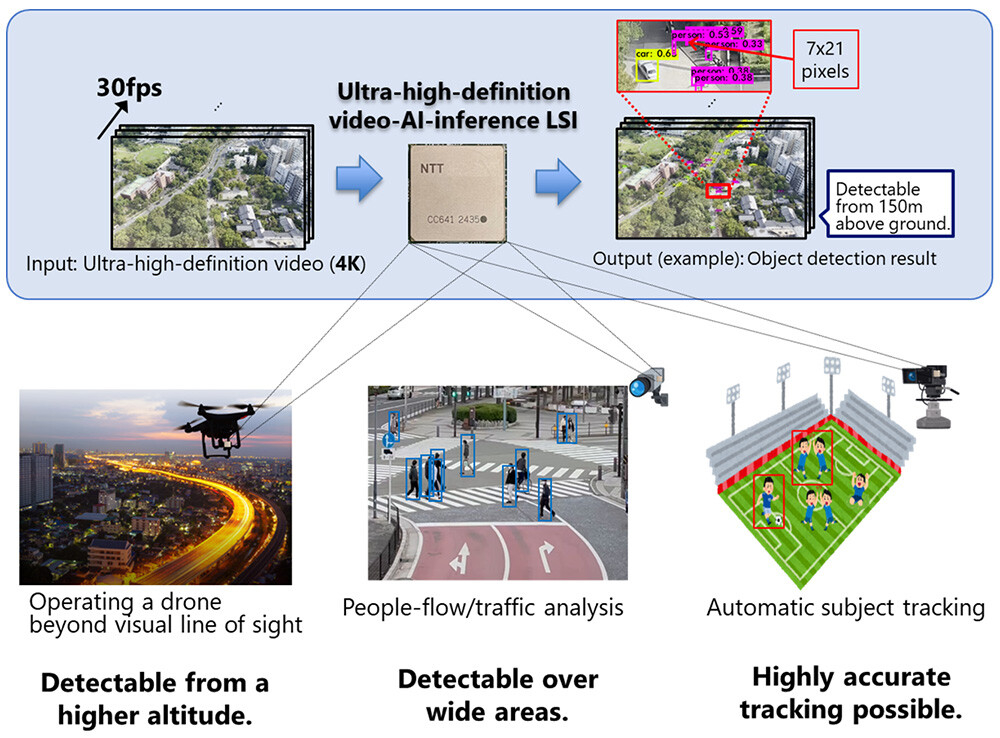
Источник изображений: NTT Параллельно с этим выполняется анализ целого изображения в сжатом виде для обнаружения крупных объектов. После этого полученные результаты объединяются: таким образом, могут быть идентифицированы как небольшие, так и крупные детали. При этом все операции могут выполняться независимо друг от друга, что обеспечивает высокую эффективность. 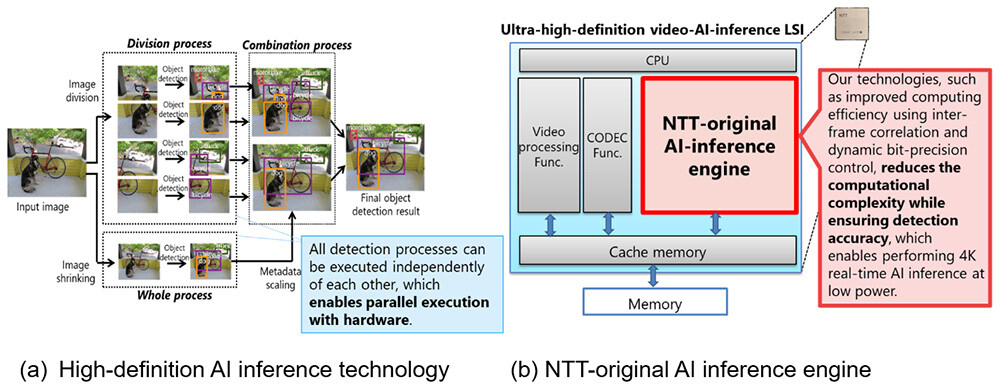 По заявлениям NTT, в случае нового изделия обнаружение объектов в реальном времени при разрешении 4K (30 к/с) возможно с тем же или более низким энергопотреблением (менее 20 Вт), что и при выполнении задачи с пониженным разрешением — 608 × 608 пикселей. Повышение эффективности вычислений достигается с помощью межкадровой корреляции и динамического управления точностью вычислений. Это позволяет добиться ИИ-инференса в реальном времени при низкой затрачиваемой мощности. На коммерческий рынок изделие планируется вывести в течение 2025 года через операционную компанию NTT Innovative Devices Corporation. Отмечается также, что NTT продолжат разработку дополнительных технологий, связанных с новым чипом.
10.04.2025 [09:14], Владимир Мироненко
ZeroPoint Technologies и Rebellions займутся разработкой ИИ-ускорителей со «сжимаемой» памятьюШведская компания ZeroPoint Technologies, специализирующаяся на создании решений для оптимизации памяти, объявила о стратегическом альянсе с южнокорейским разработчиком ИИ-чипов Rebellions с целью разработки ИИ-ускорителей для инференс. Компании планируют представить новые продукты в 2026 году, обещая «беспрецедентную производительность в пересчёте на токены в секунду на Вт (TPS/W)», пишет EE Times. Компании планируют увеличить эффективную пропускную способность и ёмкость памяти для нагрузок инференса, используя технологии сжатия, уплотнения и управления памятью от ZeroPoint Technologies. По словам генерального директора ZeroPoint Technologies Класа Моро (Klas Moreau), аппаратная оптимизация работы с памятью на уровне ЦОД позволит увеличить адресуемую ёмкость с ускорением работы почти в 1000 раз по сравнению с использованием программного сжатия. Компании планируют улучшить показатели токенов в секунду на Вт без ущерба для точности, используя сжатие модели без потерь для уменьшения её размера и сокращения использования энергии, необходимой для перемещения компонентов модели. Гендиректор Rebellions Сонхён Пак (Sunghyun Park) указал, что партнёрство позволит компаниям переопределить возможности инференса, предоставляя более умную, экономичную и устойчивую ИИ-инфраструктуру. 
Источник изображения: ZeroPoint Technologies Моро ранее заявил, что более 70 % данных, хранящихся в памяти, являются избыточными, что позволяет полностью избавиться от них, добившись сжатия без потерь полезной информации. Такая технология сжатия должна выполнять ряд специфических действий в пределах наносекунды, т.е. всего нескольких тактов: «Во-первых, она должна отрабатывать сжатие и распаковку. Во-вторых, она должна уплотнять полученные данные, собирая небольшие фрагменты в единичную линию кеша, чтобы значительно улучшить видимую пропускную способность памяти, и, наконец, она должна бесперебойно управлять данными, отслеживая все фрагменты. Чтобы минимизировать задержку, такой подход должен работать с гранулярностью линий кеша — сжимая, уплотняя и управляя данными в 64-байт фрагментах — в отличие от гораздо больших блоков 4–128 Кбайт, используемых традиционными методами сжатия вроде ZSTD и LZ4». По словам Моро, благодаря этой технологии, для базовых рабочих нагрузок в ЦОД гиперскейлера адресуемая ёмкость памяти и пропускная способность могут быть увеличены в два-четыре раза, производительность на Вт может увеличиться на 50 %, а совокупная стоимость владения (TCO) может быть значительно снижена. А для специализированных нагрузок, таких как большие языковые модели (LLM), интеграция программного сжатия в сочетании с встроенной аппаратной декомпрессией (что минимизирует любую дополнительную задержку) уже продемонстрировала прирост примерно на 50 % в адресуемой ёмкости памяти, пропускной способности и токенах в секунду. Моро утверждает, что грядущая интеграция аппаратной (де-)компрессии обещает ещё более существенные улучшения. Например, для базовых ИИ-нагрузок кластер со 100 Гбайт физической памяти благодаря использованию этой технологии будет функционировать так, как если бы у него было 150 Гбайт памяти. «Это не только представляет собой миллиарды долларов потенциальной экономии, но и может повысить производительность сложных ИИ-моделей», — заявил Моро. «Эти достижения обеспечивают надёжную основу для компаний, производящих чипы ИИ, позволяя бросить вызов доминированию таких гигантов отрасли, как NVIDIA», — добавил он.
09.04.2025 [21:55], Владимир Мироненко
Google представила ИИ-ускоритель TPU v7 Ironwood, созданный специально для инференса «размышляющих» моделейКомпания Google Cloud представила тензорный ускоритель TPU седьмого поколения Ironwood, который охарактеризовала как свой самый производительный и масштабируемый настраиваемый ИИ-ускоритель на сегодняшний день и первый среди её чипов, разработанный специально для инференса. Новый чип представляет собой важный поворот в десятилетней стратегии Google по разработке ИИ-чипов, отметил ресурс VentureBeat. В то время как предыдущие поколения TPU были созданы в первую очередь для рабочих нагрузок обучения и инференса, Ironwood — первый чип, специально созданный для инференса. Как пояснила Google, Ironwood знаменует значительный сдвиг в развитии ИИ и инфраструктуры — переход от простых ИИ-моделей, которые просто предоставляют информацию в режиме реального времени, к моделям, которые обеспечивают проактивную генерацию идей и интерпретацию данных. Компания назвала этот период «эпохой инференса», когда ИИ-агенты будут активно извлекать и генерировать данные, чтобы совместно предоставлять информацию и ответы, а не просто «голые» сведения. 
Источник изображений: Google Ironwood разработан в соответствии со сложными вычислительными и коммуникационными требованиями «моделей мышления», которые охватывают большие языковые модели (LLM), смешанные экспертные модели (MoE) и сложные задачи для рассуждения. Эти модели требуют массивной параллельной обработки и эффективного доступа к памяти. В частности, Ironwood разработан для минимизации перемещения данных и задержек на чипе при выполнении массивных тензорных манипуляций. Требования размышляющих моделей к вычислительным мощностям выходят далеко за рамки возможностей любого отдельного чипа.  Google Cloud Ironwood будет поставляться в двух конфигурациях: с 256 или с 9216 чипами. Один чип может похвастаться пиковой вычислительной мощностью 4614 Тфлопс (FP8), а кластер из 9216 чипов мощностью порядка 10 МВт выдаёт в общей сложности 42,5 Эфлопс. Ironwood оснащён усовершенствованным блоком SparseCore, предназначенным для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. Расширенная реализация SparseCore в Ironwood позволяет ускорить более широкий спектр рабочих нагрузок, выйдя за рамки традиционной области ИИ в финансовые и научные сферы. 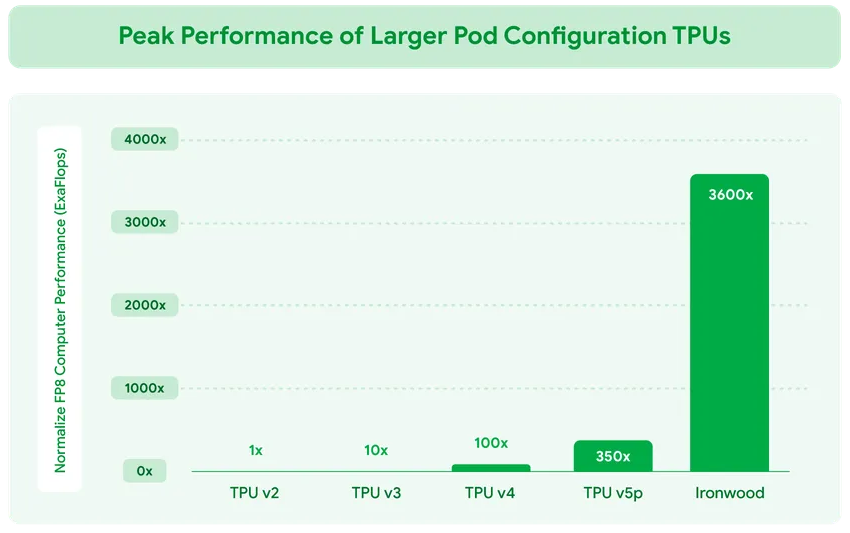 Каждый чип оснащен 192 Гбайт памяти HBM, что в шесть раз больше, чем у TPU v6 Trillium. Пропускная способность памяти достигает 7,2 Тбайт/с на чип, что в 4,5 раза больше, чем у Trillium. Также используется межчиповый интерконнект Inter-Chip Interconnect (ICI) с пропускной способностью 1,2 Тбайт/с в дуплексе, что в 1,5 раза больше, чем у Trillium. Наконец, самое важное в эпоху ограниченных по мощности ЦОД — Ironwood обеспечивает вдвое большую производительность на Вт по сравнению с Trillium, а в сравнении с самым первым TPU от 2018 года он почти в 30 энергоэффективнее. Для Ironwood используется СЖО. 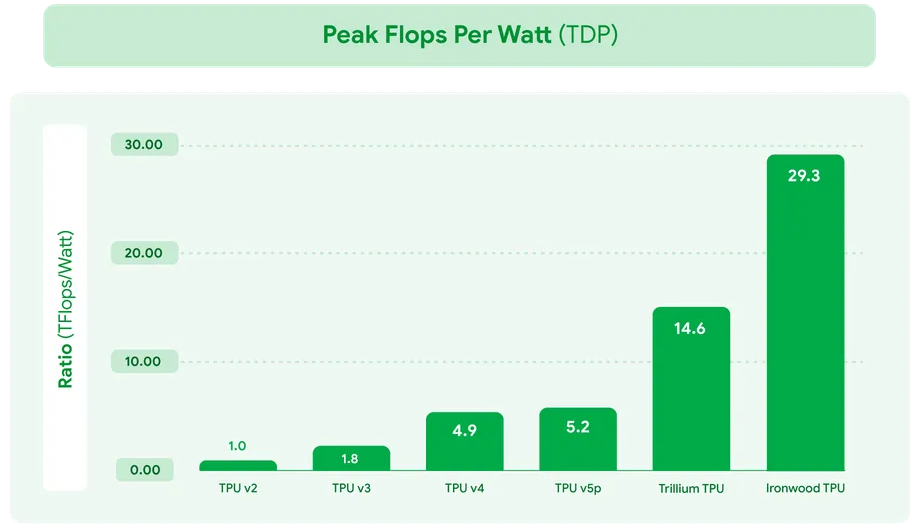 С Ironwood разработчики также могут задействовать программный стек Pathways от Google DeepMind, чтобы использовать объединённую вычислительную мощность десятков тысяч TPU Ironwood. Как сообщается, Ironwood будет доступен клиентам Google и её собственным разработчикам в конце 2025 года.  Google зафиксировала 10-кратный рост спроса на ИИ-вычисления за последние восемь лет. Как отметил ресурс VentureBeat, перенос Google фокуса на оптимизацию инференса имеет смысл. Обучение производится редко, а операции инференса — миллиарды раз в день. Экономика ИИ всё больше связана с затратами на инференс, особенно по мере того, как модели становятся всё более сложными и требующими больших вычислительных ресурсов.
04.04.2025 [10:26], Владимир Мироненко
Бенчмарк MLPerf Inference 5.0 показал, что ускорители AMD Instinct MI325X не уступают NVIDIA H200Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Inference 5.0, о чём сообщил ресурс IEEE Spectrum. Он отметил, что ускорители NVIDIA с архитектурой Blackwell превзошли все остальные чипы, но последняя версия ускорителей Instinct от AMD — Instinct MI325X — оказалась на уровне конкурирующего решения NVIDIA H200. Сопоставимые результаты были получены в основном в тестах одной из маломасштабных больших языковых моделей (LLM) — Llama2 70B. Чтобы лучше отражать особенности развития ИИ, консорциум добавил три новых теста MLPerf — всего доступно 11 бенчмарков. Добавлены два теста для LLM. Популярная и относительно компактная Llama2 70B уже является устоявшимся эталоном MLPerf, но консорциум решил включить тест, имитирующий скорость реагирования, ожидаемую пользователями от чат-ботов. Поэтому был добавлен новый эталон Llama2-70B Interactive, который ужесточает требования к оборудованию: системы должны выдавать не менее 25 токенов в секунду при задержке на ответ не более 450 мс. С учётом роста популярности «агентного ИИ» в MLPerf решили добавить тестирование LLM с характеристиками, необходимыми для таких задач. В итоге была выбрана Llama3.1 405B. Эта модель имеет широкое контекстное окно — 128 тыс. токенов, что в 30 раз больше, чем у Llama2 70B. Третий новый бенчмарк — RGAT — представляет собой графовую сеть. Он классифицирует информацию в сети. Например, набор данных для тестирования RGAT состоит из научных статей, связанных между собой авторами, учреждениями и областями исследований, что составляет 2 Тбайт данных. RGAT должен классифицировать статьи по почти 3000 темам. 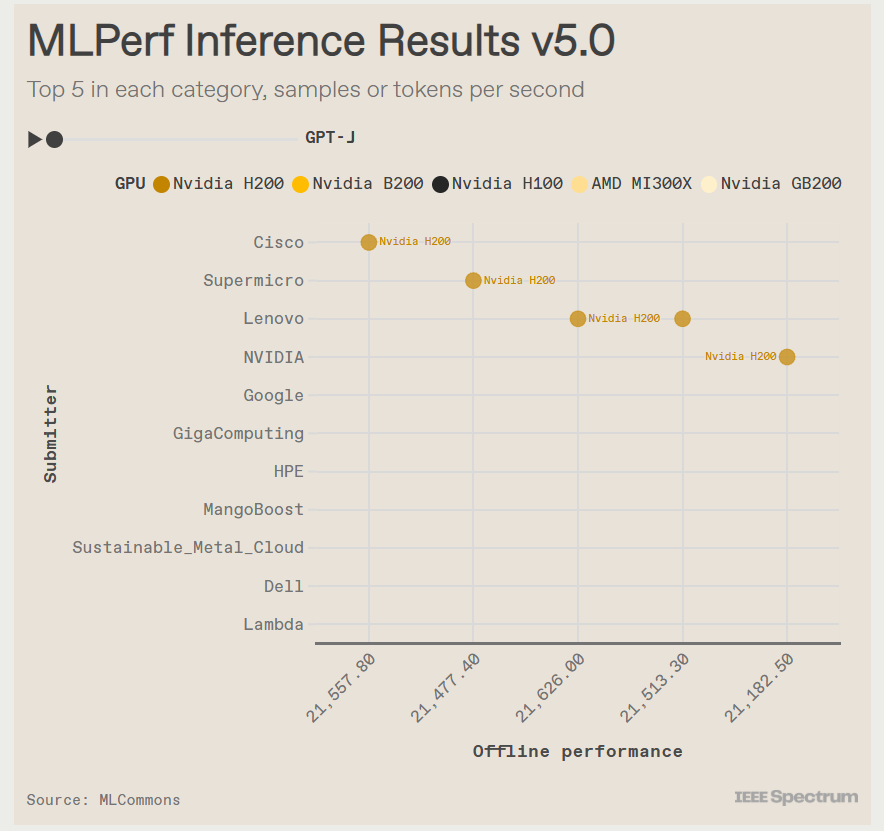
Источник изображения: IEEE Spectrum В этом раунде тестов поступили заявки от NVIDIA и 15 компаний-партнёров, включая Dell, Google и Supermicro. Оба ускорителя NVIDIA с архитектурой Hopper первого и второго поколения — H100 и H200 — показали хорошие результаты. «Мы смогли добавить ещё 60 % производительности за последний год, — у Hopper, которая была запущена в производство в 2022 году, сообщил Дэйв Сальватор (Dave Salvator), один из директоров NVIDIA. — У неё всё ещё есть некоторый запас производительности». Лидером же оказался B200 с архитектурой Blackwell. B200 содержит на 36 % больше памяти HBM, чем у H200, но, что ещё важнее, он может выполнять ключевые математические операции, используя FP4 вместо FP8 у Hopper. В тесте Llama3.1 405B система от Supermicro с восемью B200 выдала почти в четыре раза больше токенов в секунду, чем система с восемью H200 от Cisco. И та же система Supermicro была в три раза быстрее самого быстрого сервера на H200 в интерактивной версии Llama2 70B. NVIDIA использовала суперчип GB200 — сочетание ускорителей Blackwell и процессоров Grace — чтобы продемонстрировать эффективность интерконнекта NVLink, который позволяет работать множеству узлов как один ускоритель. В непроверенном результате, которым компания поделилась с журналистами, стойка GB200 NVL72 выдавала 869 200 токенов в секунду в Llama2 70B. Самая быстрая система текущего раунда MLPerf Inference — сервер NVIDIA B200 — показала 98 443 токена в секунду. Ускоритель Instinct MI325X позиционируется AMD как конкурент H200. Он имеет ту же архитектуру, что и предшественник MI300, но оснащён увеличенным объёмом памяти HBM с более высокой пропускной способностью — 256 Гбайт и 6 Тбайт/с (рост на 33 % и 13 % соответственно). AMD оптимизировала ПО, что позволило увеличить скорость инференса DeepSeek-R1 в 8 раз. В тесте Llama2 70B компьютеры с восемью MI325X отставали от аналогичных систем на базе H200 всего на 3–7 %. В задачах генерации изображений система MI325X показала отличия в пределах 10 % от системы на H200. Также сообщается, что партнёр AMD, компания Mangoboost, продемонстрировала почти четырёхкратное увеличение производительности в тесте Llama2 70B, запустив вычисления на четырёх узлах. 
Источник изображения: ML Commons Intel традиционно использует в тестах только процессорные системы, чтобы показать, что для некоторых рабочих нагрузок GPU не требуются. В этот раз были представлены первые данные по чипам Intel Xeon 6900P и 6700P (Granite Rapids), выпускаемым по техпроцессу Intel 3. Компьютер с двумя Xeon 6 показал результат в 40 285 семплов в секунду в тесте распознавания изображений, что составляет около одной трети производительности системы Cisco с двумя NVIDIA H100. По сравнению с результатами Xeon 5 в октябре 2024 года новый процессор демонстрирует прирост в 80 % в данном тесте и ещё большее ускорение в задачах обнаружения объектов и медицинской визуализации. С 2021 года, когда Intel начала представлять результаты Xeon, её процессоры достигли 11-кратного прироста производительности в тесте ResNet. Intel отказалась от участия в категории ускорителей: её конкурент для H100 — Gaudi 3 — не появился ни в текущих результатах MLPerf, ни в версии 4.1, выпущенной в октябре 2024 года. Чип Google TPU v6e также продемонстрировал свои возможности, хотя результаты были ограничены задачей генерации изображений. При 5,48 запроса в секунду система с четырьмя TPU показала прирост в 2,5 раза по сравнению с аналогичным компьютером, использующим TPU v5e, в результатах за октябрь 2024 года. Тем не менее 5,48 запроса в секунду — это примерно те же показатели, что и у аналогичного по размеру компьютера Lenovo с NVIDIA H100.
24.03.2025 [09:03], Владимир Мироненко
От СХД напрямую к ИИ: NVIDIA анонсировала эталонную платформу AI Data Platform для быстрого извлечения данных во время инференсаNVIDIA анонсировала NVIDIA AI Data Platform — настраиваемую эталонную архитектуру, которую ведущие поставщики смогут использовать для создания нового класса ИИ-инфраструктуры для требовательных рабочих нагрузок ИИ-инференса: корпоративных платформ хранения со специализированными ИИ-агентами, использующих ускорители, сетевые решения и ПО NVIDIA. Эти агенты помогут генерировать ответы из имеющихся данных практически в реальном времени, используя ПО NVIDIA AI Enterprise — включая микросервисы NVIDIA NIM для новых моделей NVIDIA Llama Nemotron, а также NVIDIA AI-Q Blueprint. Провайдеры хранилищ смогут оптимизировать свою инфраструктуру для обеспечения работы этих агентов с помощью ускорителей NVIDIA Blackwell, DPU BlueField, сетей Spectrum-X и библиотеки инференса с открытым исходным кодом NVIDIA Dynamo. Ведущие провайдеры платформ данных и хранилищ, включая DDN, Dell, HPE, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, VAST Data и WEKA, сотрудничают с NVIDIA для создания настраиваемых ИИ-платформ данных, которые могут использовать корпоративные данные для рассуждений и ответов на сложные запросы. 
Источник изображения: NVIDIA NVIDIA Blackwell, DPU BlueField и сетевое оборудование Spectrum-X предоставляют механизм для ускорения доступа ИИ-агентов запроса к данным, хранящимся в корпоративных системах. DPU BlueField обеспечивают производительность до 1,6 раз выше, чем хранилища на базе ЦП, при этом снижая энергопотребление до 50 %, а Spectrum-X ускоряет доступ к хранилищам до 48 % по сравнению с традиционным Ethernet, применяя адаптивную маршрутизацию и контроль перегрузки, говорит NVIDIA. ИИ-агенты, созданные с помощью AI-Q Blueprint, подключаются к данным во время инференса, чтобы предоставлять более точные, контекстно-зависимые ответы. Они могут быстро получать доступ к большим объёмам информации и обрабатывать различные типы данных, включая структурированные, полуструктурированные и неструктурированные данные из нескольких источников, в том числе текст, PDF, изображения и видео. Сертифицированные партнёры NVIDIA в области СХД уже сотрудничают с NVIDIA в деле создания новых ИИ-платформ:
21.03.2025 [10:09], Владимир Мироненко
«ОС» для ИИ-фабрик: NVIDIA Dynamo ускорит инференс и упростит масштабирование рассуждающих ИИ-моделейNVIDIA представила NVIDIA Dynamo, преемника NVIDIA Triton Inference Server — программную среду с открытым исходным кодом для разработчиков, обеспечивающую ускорение инференса, а также упрощающую масштабирование рассуждающих ИИ-моделей в ИИ-фабриках с минимальными затратами и максимальной эффективностью. Глава NVIDIA Дженсен Хуанг (Jensen Huang) назвал Dynamo «операционной системой для ИИ-фабрик». NVIDIA Dynamo повышает производительность инференса, одновременно снижая затраты на масштабирование вычислений во время тестирования. Сообщается, что благодаря оптимизации инференса на NVIDIA Blackwell эта платформа многократно увеличивает производительность рассуждающей ИИ-модели DeepSeek-R1. 
Источник изображений: NVIDIA Платформа NVIDIA Dynamo, разработанная для максимизации дохода от токенов для ИИ-фабрик (ИИ ЦОД), организует и ускоряет коммуникацию инференса на тысячах ускорителей, и использует дезагрегированную обработку данных для разделения фаз обработки и генерации больших языковых моделей (LLM) на разных ускорителях. Это позволяет оптимизировать каждую фазу независимо от её конкретных потребностей и обеспечивает максимальное использование вычислительных ресурсов. 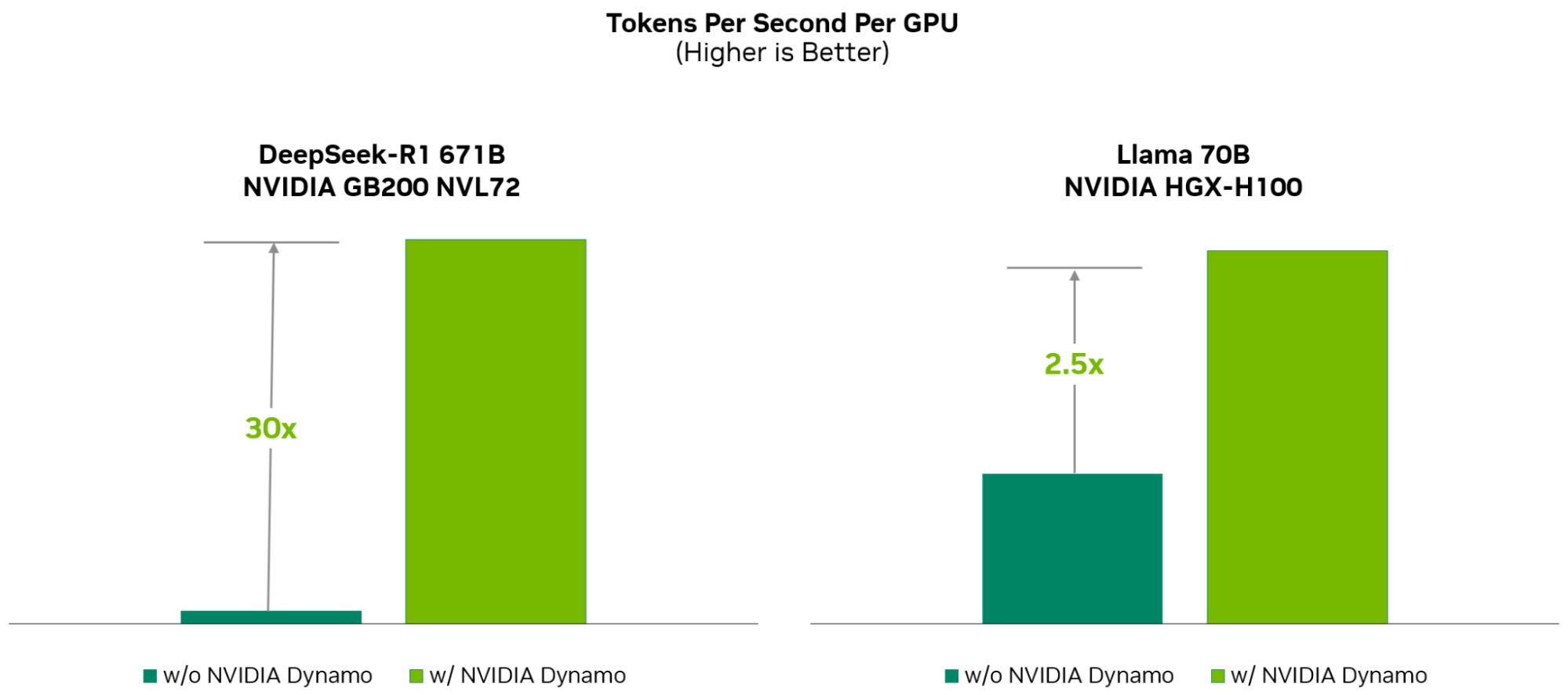 При том же количестве ускорителей Dynamo удваивает производительность (т.е. фактически доход ИИ-фабрик) моделей Llama на платформе NVIDIA Hopper. При запуске модели DeepSeek-R1 на большом кластере GB200 NVL72 благодаря интеллектуальной оптимизации инференса с помощью NVIDIA Dynamo количество генерируемых токенов на каждый ускоритель токенов увеличивается более чем в 30 раз, сообщила NVIDIA. 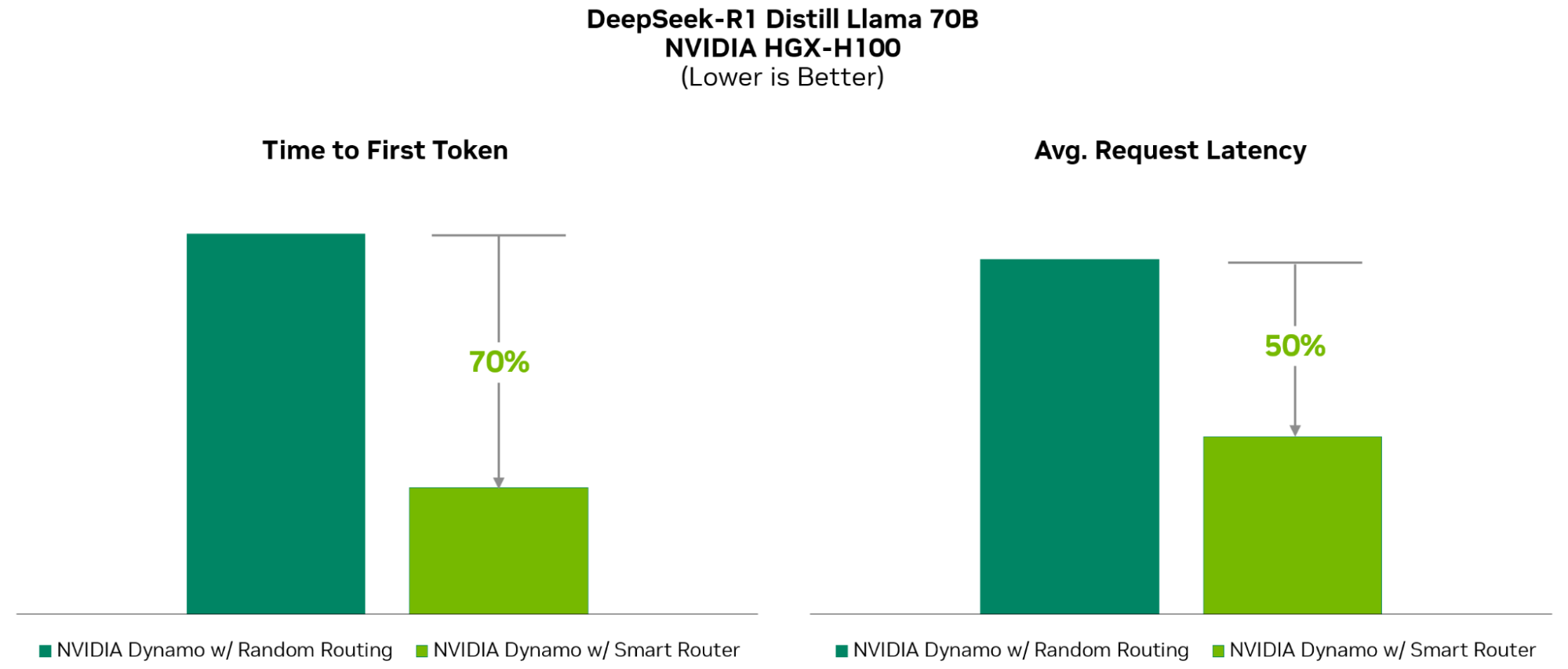 NVIDIA Dynamo может динамически перераспределять нагрузку на ускорители в ответ на меняющиеся объёмы и типы запросов, а также закреплять задачи за конкретными ускорителями в больших кластерах, что помогает минимизировать вычисления для ответов и маршрутизировать запросы. Платформа также может выгружать данные инференса в более доступную память и устройства хранения данных и быстро извлекать их при необходимости. 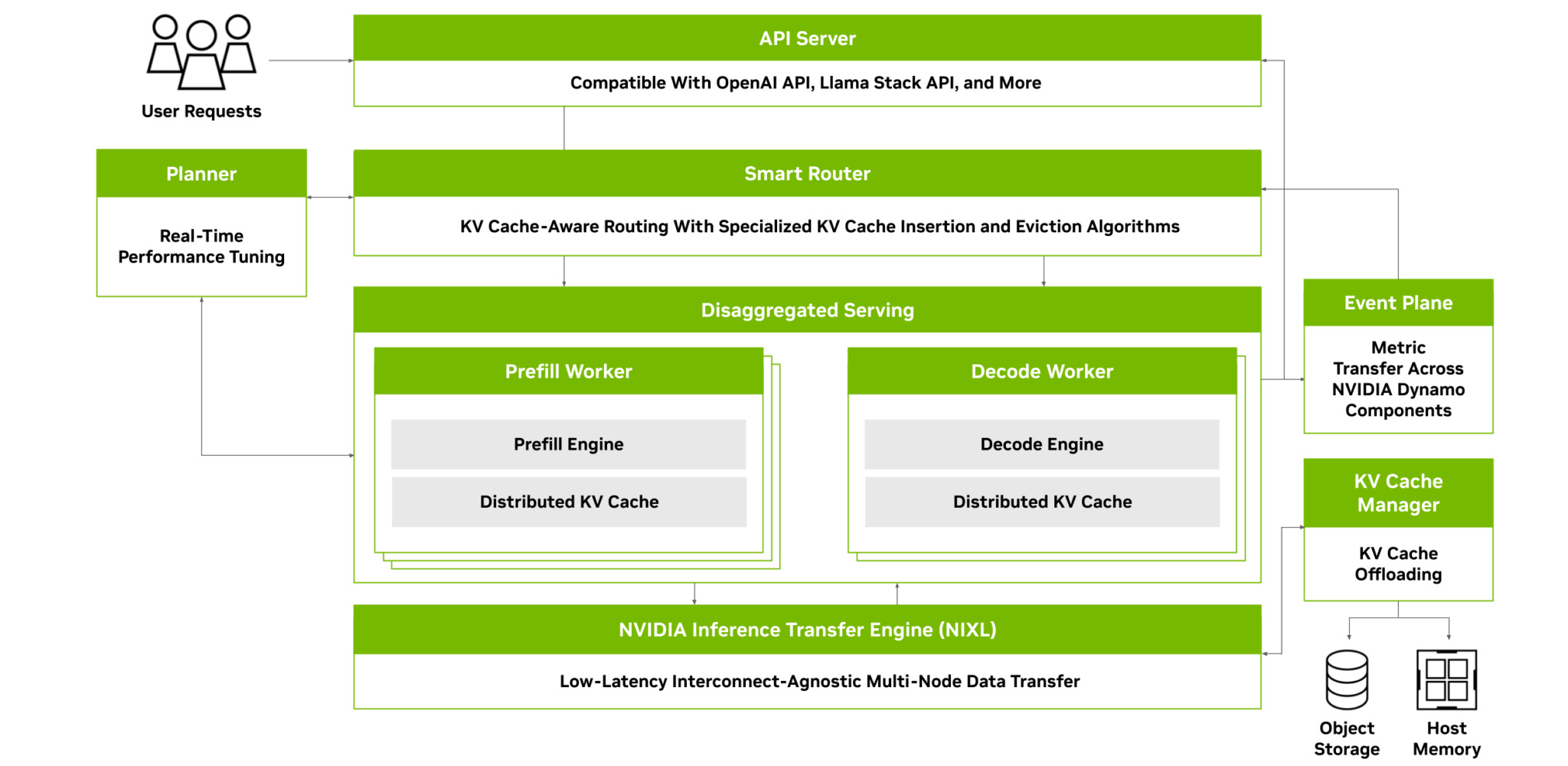 NVIDIA Dynamo имеет полностью открытый исходный код и поддерживает PyTorch, SGLang, NVIDIA TensorRT-LLM и vLLM, что позволяет клиентам разрабатывать и оптимизировать способы запуска ИИ-моделей в рамках дезагрегированного инференса. По словам NVIDIA, это позволит ускорить внедрение решения на различных платформах, включая AWS, Cohere, CoreWeave, Dell, Fireworks, Google Cloud, Lambda, Meta✴, Microsoft Azure, Nebius, NetApp, OCI, Perplexity, Together AI и VAST. 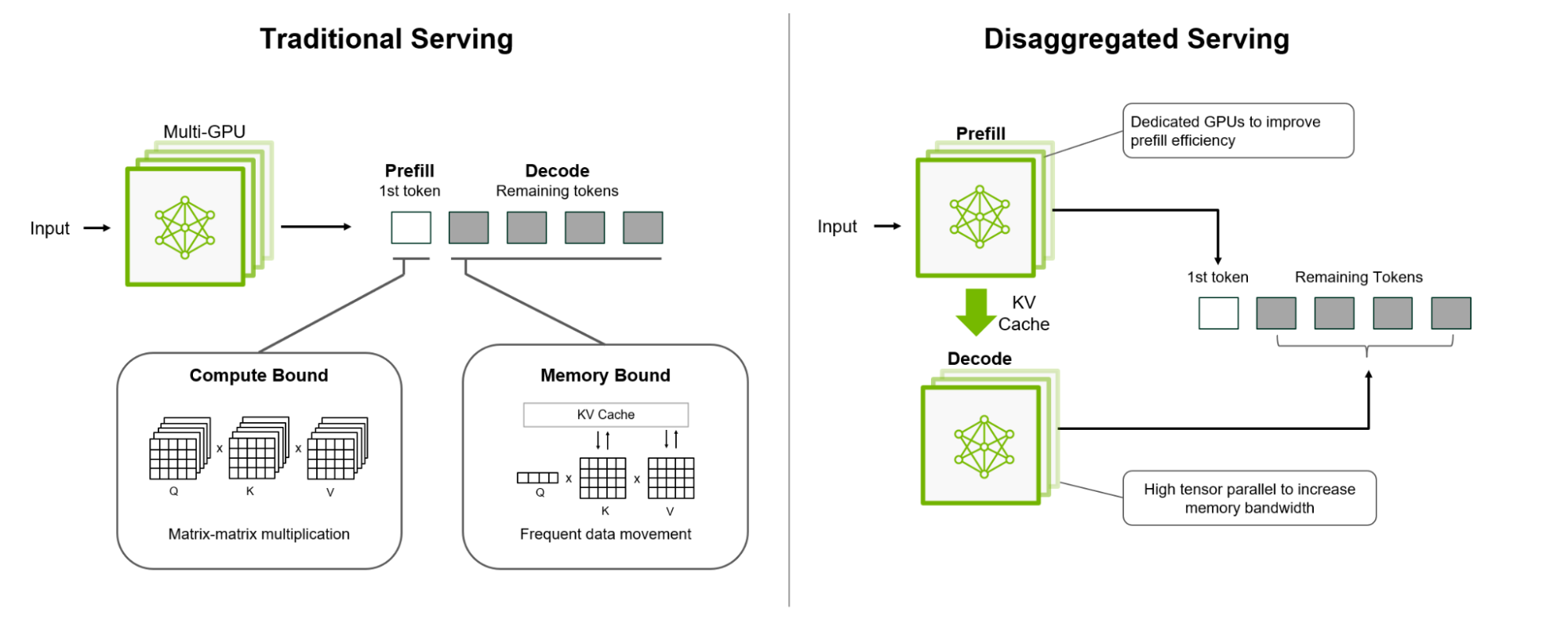 NVIDIA Dynamo распределяет информацию, которую системы инференса хранят в памяти после обработки предыдущих запросов (KV-кеш), на множество ускорителей (до тысяч). Затем платформа направляет новые запросы на те ускорители, содержимое KV-кеша которых наиболее близко к новому запросу, тем самым избегая дорогостоящих повторных вычислений. 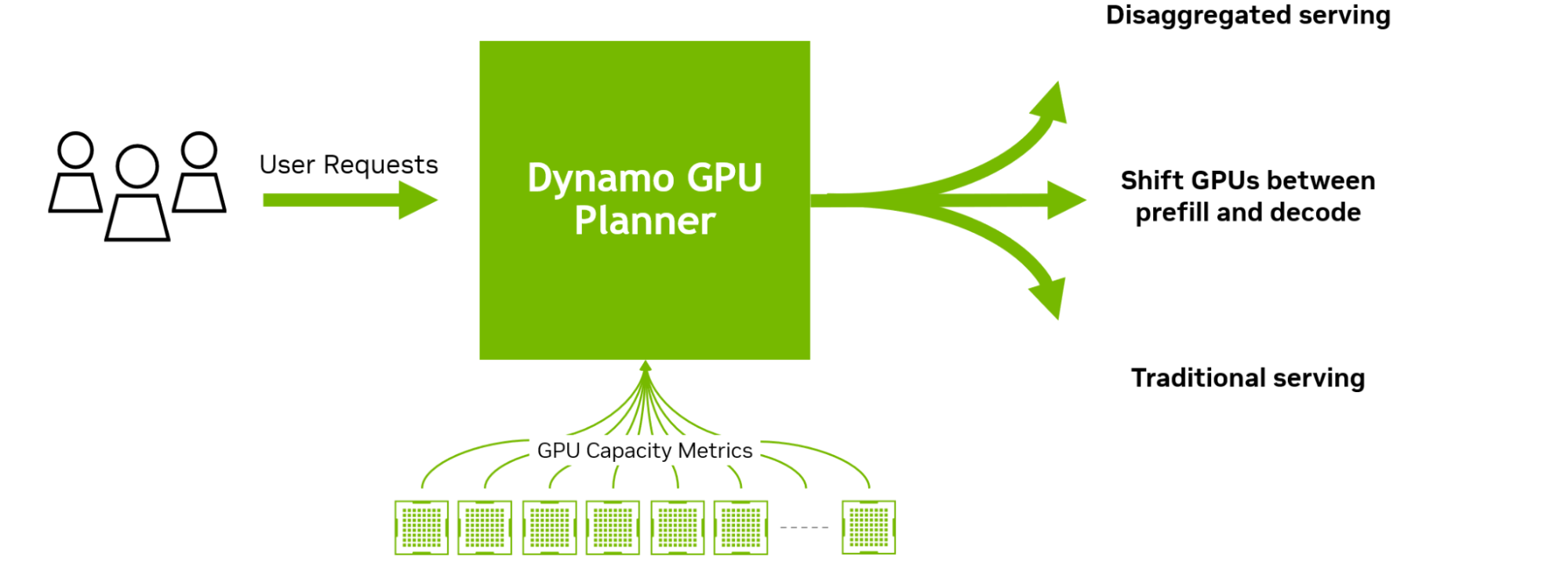 NVIDIA Dynamo также обеспечивает дезагрегацию обработки входящих запросов, которое отправляет различные этапы исполнения LLM — от «понимания» запроса до генерации — разным ускорителям. Этот подход идеально подходит для рассуждающих моделей. Дезагрегированное обслуживание позволяет настраивать и выделять ресурсы для каждой фазы независимо, обеспечивая более высокую пропускную способность и более быстрые ответы на запросы.  NVIDIA Dynamo включает четыре ключевых механизма:
Платформа NVIDIA Dynamo будет доступна в микросервисах NVIDIA NIM и будет поддерживаться в будущем выпуске платформы NVIDIA AI Enterprise.
17.03.2025 [17:23], Руслан Авдеев
Ежегодные расходы техногигантов на ИИ превысят $500 млрд, но большая часть денег пойдёт на инференс, а не на обучение моделейКрупнейшие IT-компании нарастят ежегодные расходы на ИИ-технологии — в совокупности они превысят $500 млрд уже в следующем десятилетии. Одной из причин роста инвестиций в ИИ станет новый подход к разработкам со стороны китайской DeepSeek и OpenAI, сообщает Bloomberg Intelligence. Группа гиперскейлеров, включая Microsoft, Amazon и Meta✴ намерена потратить $371 млрд на ЦОД и вычислительные ресурсы для ИИ в 2025 году, на 44 % больше, чем годом ранее. К 2032 году затраты вырастут до $525 млрд — быстрее, чем ожидали в Bloomberg Intelligence до того, как недавно «выстрелили» продукты DeepSeek. До недавних пор большая часть инвестиций в ИИ уходила на дата-центры и чипы, которые использовались для обучения или разработки новых, всё более крупных ИИ-моделей. Теперь компании намерены больше тратить на инференс. Изменение стратегии ускорилось после выпуска «рассуждающих» моделей компаний OpenAI и DeepSeek. У этих систем уходит больше времени на ответы на запросы пользователей, при этом они требуют больше ресурсов на инференс. Неожиданный для многих успех DeepSeek, которая, как утверждается, создала чрезвычайно недорогую и конкурентоспособную модель на уровне современных продуктов западных конкурентов (с оговорками), вызвал вопросы об эффективности инвестиций в США. Эксперты оценивают, стоило ли вкладывать огромные средства в укрупнение моделей. Некоторые компании уже стали внедрять эффективные LLM, работающие на относительно небольшом числе ускорителей. 
Источник изображения: The Drink/unspalsh.com По данным Bloomberg, «рассуждающие» модели обеспечивают новые возможности для заработка на ПО и потенциально обходятся дороже на этапе инференса, чем на этапе обучения. Это, похоже, приведёт к наращиванию инвестиций в соответствии с новой концепцией и приведёт к росту вложений в ИИ в целом. Рост капитальных затрат на обучение ИИ, как считают в Bloomberg, может быть заметно медленнее, чем предсказывалось ранее. Огромное внимание, которое привлекла DeepSeek, вероятно, заставит технологические фирмы нарастить инвестиции в инференс — именно он станет самым быстрорастущим сегментом на рынке систем генеративного ИИ. Похожие прогнозы давала и Omdia. Хотя в текущем году затраты на связанные с обучением задачи, вероятно, составят более 40 % расходов гиперскейлеров на ИИ, сегмент, как ожидается, уменьшится к 2032 году до всего 14 %. В том же году связанные с инференсом инвестиции могут составить около половины всех расходов на ИИ. Как считают в Bloomberg, наилучшие позиции среди гиперскейлеров у Google. У неё TPU собственной разработки, которые можно использовать как для обучения, так и для инференса. Другие компании, вроде Microsoft и Meta✴, сильно зависят от NVIDIA и могут оказаться не столь гибкими в гонке по новым правилам.
13.03.2025 [08:50], Руслан Авдеев
Cerebras развернёт царь-ускорители WSE-3 ещё в шести ЦОД во Франции, США и КанадеКомпания Cerebras начала установку более тысячи ИИ-систем CS-3 на базе гигантских ускорителей WSE-3 по всей Северной Америке и во Франции. Компания стремится зарекомендовать себя как поставщика одной из крупнейших и быстрейших облачных инференс-платформ, сообщает The Register. Кроме того, компания объявила о расширении сотрудничества с Hugging Face. К концу 2025 года развернёт свои ускорители в дата-центрах в Техасе, Миннесоте, Оклахоме и Джорджии, а также в Канаде и во Франции. Cerebras будет целиком владеть площадками в Оклахома-Сити (Оклахома) и Монреале (Канада), а оставшиеся объекты будут эксплуатироваться в рамках соглашения с G42 из ОАЭ. Крупнейший в США новый кластер CS-3 разместится в Миннеаполисе (Миннесота), его оснастят 512 CS-3 с общим быстродействием 64 Эфлопс (FP16). Он заработает уже во II квартале 2025 года. Cerebras давно сотрудничает с фондом G42, который активно спонсирует ИИ-стартап и является его якорным заказчиком — на G42 пришлось 83 % от всей выручки Cerebras за 2023 календарный год. Однако именно это сотрудничество привело к тому, что Cerebras вынужденно отложила IPO — власти США опасаются, что Китай получит доступ к ИИ-суперчипам Cerebras при посредничестве ОАЭ. По слухам, G42 заключила сделку с США, отказавшись от работы с Китаем в обмен на инвестиции. 
Источник изображения: SNL В ближайшее время Cerebras также намерена расширить API-доступ к своим ускорителям для разработчиков, договорившись с репозиторием моделей Hugging Face. Также Cerebras выиграла контракты с Mistral AI и Perplexity. Недавно объявлено о намерении аналитической платформы AlphaSense заменить трёх поставщиков моделей с закрытым кодом на модель open source, работающую на CS-3. Летом прошлого года было объявлено о партнёрстве с Dell.
07.03.2025 [15:36], Сергей Карасёв
Стартап Axelera AI анонсировал ИИ-ускоритель TitaniaНидерландский стартап Axelera AI B.V., специализирующийся на разработке ИИ-ускорителей, анонсировал решение Titania — высокопроизводительный, энергоэффективный и масштабируемый чиплет для задач инференса. Полностью технические характеристики изделия пока не раскрываются. Известно, что Titania использует проприетарную модель вычислений в памяти Digital In-Memory Computing (D-IMC). Этот подход, как заявляет Axelera AI, обеспечивает ИИ-производительность свыше 50 TOPS на ядро (эквивалентная точность FP32) и энергоэффективность на уровне 15 TOPS на 1 Вт затрачиваемой энергии. Решение Titania базируется на открытой архитектуре RISC-V. Несколько чиплетов могут быть объединены в виде модуля SiP (System-in-Package). Использование D-IMC обеспечивает практически линейную масштабируемость производительности без значительного увеличения затрат на питание и охлаждение. В качестве потенциальных областей применения Titania названы НРС-платформы, корпоративные дата-центры, робототехника, автомобилестроение и пр. 
Источник изображения: Axelera AI Одновременно с анонсом Titania стартап Axelera AI объявил о привлечении до €61,6 млн от EuroHPC JU в рамках проекта Digital Autonomy with RISC-V for Europe (DARE). Компания Axelera AI будет поддерживать EuroHPC в области разработки суперкомпьютерной экосистемы мирового класса в Европе. В частности, стартап планирует расширять свои научно-исследовательские и опытно-конструкторские подразделения в Нидерландах, Италии и Бельгии. Отмечается также, что основанная в 2021 году компания Axelera AI за три года существования получила инвестиции на общую сумму более $200 млн.
05.03.2025 [11:51], Сергей Карасёв
Lenovo представила компактный ИИ-сервер ThinkEdge SE100 для инференсаLenovo анонсировала сервер ThinkEdge SE100, предназначенный для решения задач ИИ-инференса на периферии. Новинка ориентирована на предприятия в различных отраслях, включая розничную торговлю, производство, телекоммуникации и здравоохранение. Сервер комплектуется процессором Intel поколения Arrow Lake-H: это может быть чип Core Ultra 7 255H (6P+8E+2LP-E) с частотой до 5,1 ГГц или Core Ultra 5 225H (4P+8E+2LP-E) с частотой до 4,9 ГГц. Поддерживается до 64 Гбайт оперативной памяти DDR5-6400 в виде двух модулей CSO-DIMM (Clocked Small Outline DIMM). Устройство располагает одним слотом PCIe 4.0 x8 HHHL для ускорителя на базе GPU, например, NVIDIA RTX 2000E ADA или NVIDIA RTX A1000. Система может быть оборудована загрузочным накопителем M.2 2280 вместимостью до 960 Гбайт, а также двумя SSD формата M.2 (NVMe) ёмкостью до 3,84 Тбайт. Присутствуют два сетевых порта 1GbE и выделенный сетевой порт управления 1GbE RJ-45. Для модели ThinkEdge SE100 предусмотрен широкий выбор вариантов монтажа, включая крепление VESA и на DIN-рейку, установку в стойку и использование в «настольном» режиме. Базовый модуль имеет размеры 53 × 142 × 278 мм, блок расширения — 53 × 214 × 278 мм. 
Источник изображений: Lenovo Во фронтальной части сервера расположены порты USB 3.2 Gen2 Type-A (×2), USB 3.2 Gen2 Type-C, HDMI 2.0 (×2) и RJ-45. Сзади сосредоточены разъёмы USB Type-C (×2), USB 3.2 Gen2 Type-A (×2) и RJ-45 (×3). Диапазон рабочих температур — от +5 до +45 °C. Заявлена совместимость с программными платформами Windows 11 Enterprise, Ubuntu 24.04, RHEL.  По утверждениям Lenovo, сервер ThinkEdge SE100 на 85 % компактнее традиционных систем, ориентированных на ИИ-инференс. При этом обеспечивается «производительность корпоративного уровня». На устройство предоставляется трёхлетняя гарантия. |
|

