Материалы по тегу: ускоритель
|
11.04.2025 [11:00], Сергей Карасёв
NTT представила ИИ-чип для обработки видео на периферииКомпания NTT объявила о создании ИИ-чипа, предназначенного для задач инференса на периферии. Изделие может применяться для обработки видео высокой чёткости, в том числе в формате 4K, в реальном времени на устройствах со строгими ограничениями по мощности. В качестве сфер применения новинки NTT выделяет беспилотные летательные аппараты и камеры видеонаблюдения. Например, благодаря представленному чипу дроны могут использоваться для обнаружения прохожих и объектов, таких как автомобили, с высоты до 150 м. Для повышения эффективности инференса при одновременном снижении энергопотребления задействованы специальные алгоритмы. Входное изображение высокого разрешения сегментируется на фрагменты, после чего производится независимая обработка каждого из них. Это позволяет обнаруживать объекты небольшого размера. 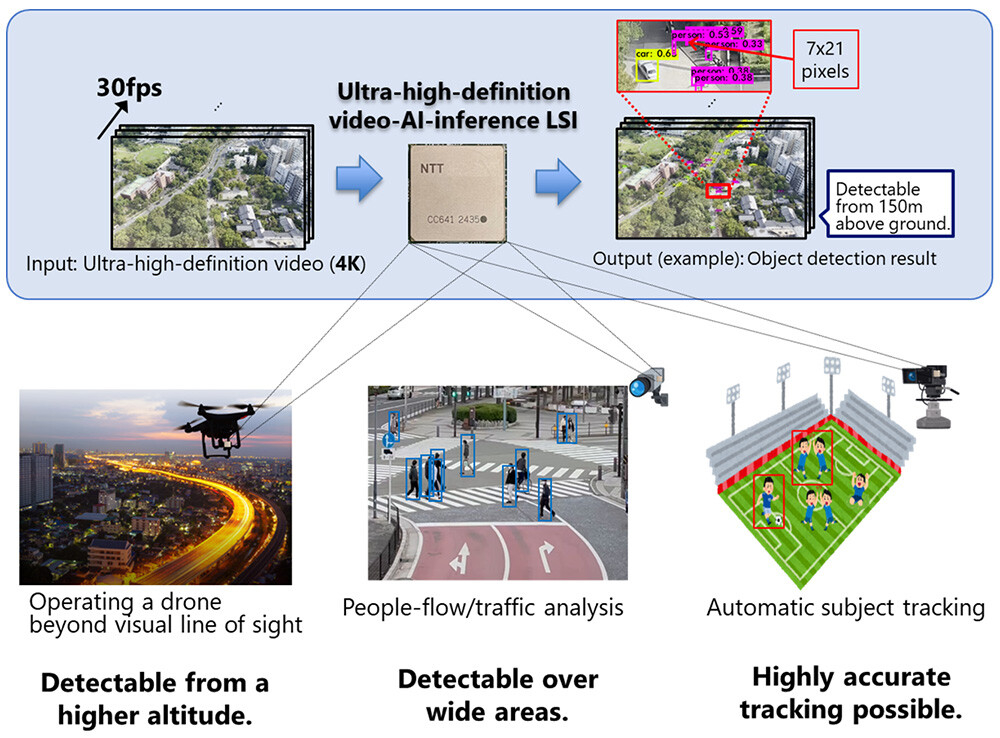
Источник изображений: NTT Параллельно с этим выполняется анализ целого изображения в сжатом виде для обнаружения крупных объектов. После этого полученные результаты объединяются: таким образом, могут быть идентифицированы как небольшие, так и крупные детали. При этом все операции могут выполняться независимо друг от друга, что обеспечивает высокую эффективность. 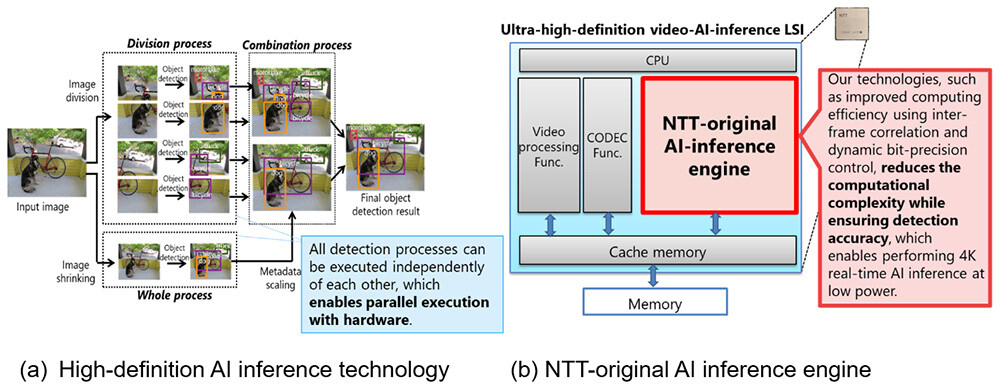 По заявлениям NTT, в случае нового изделия обнаружение объектов в реальном времени при разрешении 4K (30 к/с) возможно с тем же или более низким энергопотреблением (менее 20 Вт), что и при выполнении задачи с пониженным разрешением — 608 × 608 пикселей. Повышение эффективности вычислений достигается с помощью межкадровой корреляции и динамического управления точностью вычислений. Это позволяет добиться ИИ-инференса в реальном времени при низкой затрачиваемой мощности. На коммерческий рынок изделие планируется вывести в течение 2025 года через операционную компанию NTT Innovative Devices Corporation. Отмечается также, что NTT продолжат разработку дополнительных технологий, связанных с новым чипом.
10.04.2025 [09:14], Владимир Мироненко
ZeroPoint Technologies и Rebellions займутся разработкой ИИ-ускорителей со «сжимаемой» памятьюШведская компания ZeroPoint Technologies, специализирующаяся на создании решений для оптимизации памяти, объявила о стратегическом альянсе с южнокорейским разработчиком ИИ-чипов Rebellions с целью разработки ИИ-ускорителей для инференс. Компании планируют представить новые продукты в 2026 году, обещая «беспрецедентную производительность в пересчёте на токены в секунду на Вт (TPS/W)», пишет EE Times. Компании планируют увеличить эффективную пропускную способность и ёмкость памяти для нагрузок инференса, используя технологии сжатия, уплотнения и управления памятью от ZeroPoint Technologies. По словам генерального директора ZeroPoint Technologies Класа Моро (Klas Moreau), аппаратная оптимизация работы с памятью на уровне ЦОД позволит увеличить адресуемую ёмкость с ускорением работы почти в 1000 раз по сравнению с использованием программного сжатия. Компании планируют улучшить показатели токенов в секунду на Вт без ущерба для точности, используя сжатие модели без потерь для уменьшения её размера и сокращения использования энергии, необходимой для перемещения компонентов модели. Гендиректор Rebellions Сонхён Пак (Sunghyun Park) указал, что партнёрство позволит компаниям переопределить возможности инференса, предоставляя более умную, экономичную и устойчивую ИИ-инфраструктуру. 
Источник изображения: ZeroPoint Technologies Моро ранее заявил, что более 70 % данных, хранящихся в памяти, являются избыточными, что позволяет полностью избавиться от них, добившись сжатия без потерь полезной информации. Такая технология сжатия должна выполнять ряд специфических действий в пределах наносекунды, т.е. всего нескольких тактов: «Во-первых, она должна отрабатывать сжатие и распаковку. Во-вторых, она должна уплотнять полученные данные, собирая небольшие фрагменты в единичную линию кеша, чтобы значительно улучшить видимую пропускную способность памяти, и, наконец, она должна бесперебойно управлять данными, отслеживая все фрагменты. Чтобы минимизировать задержку, такой подход должен работать с гранулярностью линий кеша — сжимая, уплотняя и управляя данными в 64-байт фрагментах — в отличие от гораздо больших блоков 4–128 Кбайт, используемых традиционными методами сжатия вроде ZSTD и LZ4». По словам Моро, благодаря этой технологии, для базовых рабочих нагрузок в ЦОД гиперскейлера адресуемая ёмкость памяти и пропускная способность могут быть увеличены в два-четыре раза, производительность на Вт может увеличиться на 50 %, а совокупная стоимость владения (TCO) может быть значительно снижена. А для специализированных нагрузок, таких как большие языковые модели (LLM), интеграция программного сжатия в сочетании с встроенной аппаратной декомпрессией (что минимизирует любую дополнительную задержку) уже продемонстрировала прирост примерно на 50 % в адресуемой ёмкости памяти, пропускной способности и токенах в секунду. Моро утверждает, что грядущая интеграция аппаратной (де-)компрессии обещает ещё более существенные улучшения. Например, для базовых ИИ-нагрузок кластер со 100 Гбайт физической памяти благодаря использованию этой технологии будет функционировать так, как если бы у него было 150 Гбайт памяти. «Это не только представляет собой миллиарды долларов потенциальной экономии, но и может повысить производительность сложных ИИ-моделей», — заявил Моро. «Эти достижения обеспечивают надёжную основу для компаний, производящих чипы ИИ, позволяя бросить вызов доминированию таких гигантов отрасли, как NVIDIA», — добавил он.
09.04.2025 [21:55], Владимир Мироненко
Google представила ИИ-ускоритель TPU v7 Ironwood, созданный специально для инференса «размышляющих» моделейКомпания Google Cloud представила тензорный ускоритель TPU седьмого поколения Ironwood, который охарактеризовала как свой самый производительный и масштабируемый настраиваемый ИИ-ускоритель на сегодняшний день и первый среди её чипов, разработанный специально для инференса. Новый чип представляет собой важный поворот в десятилетней стратегии Google по разработке ИИ-чипов, отметил ресурс VentureBeat. В то время как предыдущие поколения TPU были созданы в первую очередь для рабочих нагрузок обучения и инференса, Ironwood — первый чип, специально созданный для инференса. Как пояснила Google, Ironwood знаменует значительный сдвиг в развитии ИИ и инфраструктуры — переход от простых ИИ-моделей, которые просто предоставляют информацию в режиме реального времени, к моделям, которые обеспечивают проактивную генерацию идей и интерпретацию данных. Компания назвала этот период «эпохой инференса», когда ИИ-агенты будут активно извлекать и генерировать данные, чтобы совместно предоставлять информацию и ответы, а не просто «голые» сведения. 
Источник изображений: Google Ironwood разработан в соответствии со сложными вычислительными и коммуникационными требованиями «моделей мышления», которые охватывают большие языковые модели (LLM), смешанные экспертные модели (MoE) и сложные задачи для рассуждения. Эти модели требуют массивной параллельной обработки и эффективного доступа к памяти. В частности, Ironwood разработан для минимизации перемещения данных и задержек на чипе при выполнении массивных тензорных манипуляций. Требования размышляющих моделей к вычислительным мощностям выходят далеко за рамки возможностей любого отдельного чипа.  Google Cloud Ironwood будет поставляться в двух конфигурациях: с 256 или с 9216 чипами. Один чип может похвастаться пиковой вычислительной мощностью 4614 Тфлопс (FP8), а кластер из 9216 чипов мощностью порядка 10 МВт выдаёт в общей сложности 42,5 Эфлопс. Ironwood оснащён усовершенствованным блоком SparseCore, предназначенным для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. Расширенная реализация SparseCore в Ironwood позволяет ускорить более широкий спектр рабочих нагрузок, выйдя за рамки традиционной области ИИ в финансовые и научные сферы. 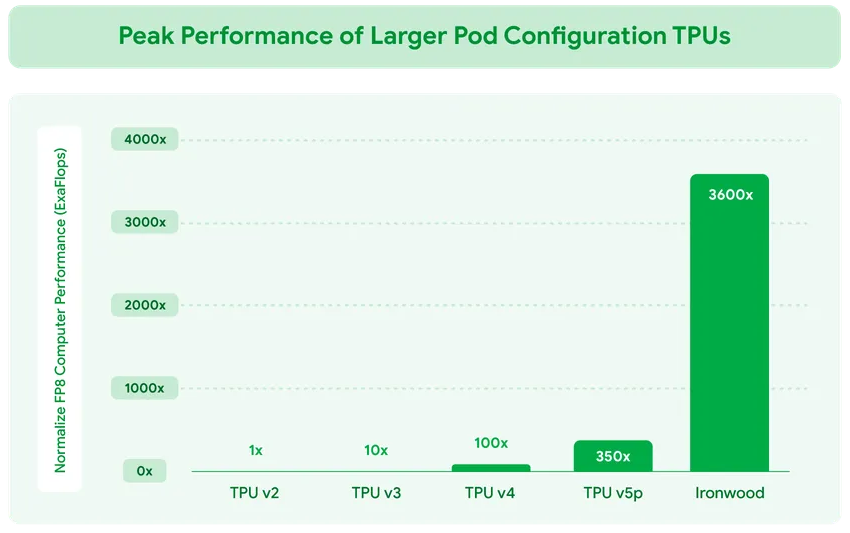 Каждый чип оснащен 192 Гбайт памяти HBM, что в шесть раз больше, чем у TPU v6 Trillium. Пропускная способность памяти достигает 7,2 Тбайт/с на чип, что в 4,5 раза больше, чем у Trillium. Также используется межчиповый интерконнект Inter-Chip Interconnect (ICI) с пропускной способностью 1,2 Тбайт/с в дуплексе, что в 1,5 раза больше, чем у Trillium. Наконец, самое важное в эпоху ограниченных по мощности ЦОД — Ironwood обеспечивает вдвое большую производительность на Вт по сравнению с Trillium, а в сравнении с самым первым TPU от 2018 года он почти в 30 энергоэффективнее. Для Ironwood используется СЖО. 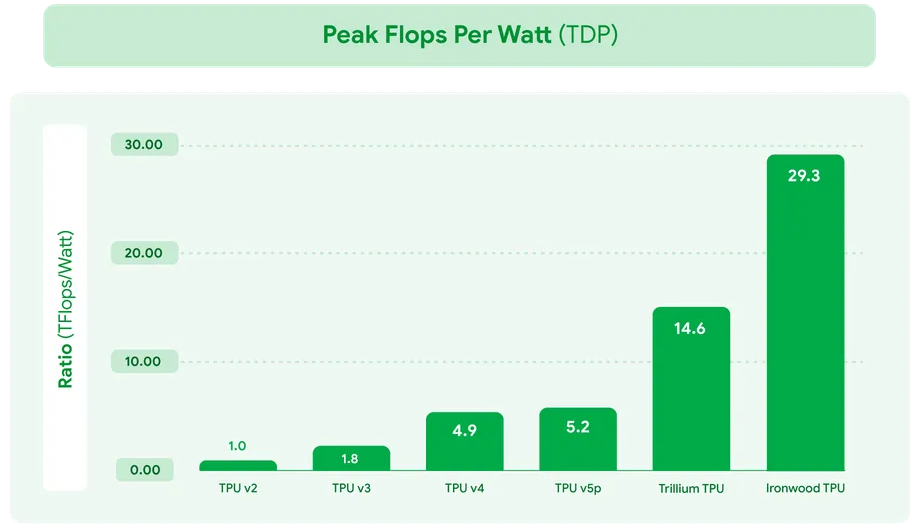 С Ironwood разработчики также могут задействовать программный стек Pathways от Google DeepMind, чтобы использовать объединённую вычислительную мощность десятков тысяч TPU Ironwood. Как сообщается, Ironwood будет доступен клиентам Google и её собственным разработчикам в конце 2025 года.  Google зафиксировала 10-кратный рост спроса на ИИ-вычисления за последние восемь лет. Как отметил ресурс VentureBeat, перенос Google фокуса на оптимизацию инференса имеет смысл. Обучение производится редко, а операции инференса — миллиарды раз в день. Экономика ИИ всё больше связана с затратами на инференс, особенно по мере того, как модели становятся всё более сложными и требующими больших вычислительных ресурсов.
04.04.2025 [11:29], Руслан Авдеев
NVIDIA может переключиться на выполнение заказов только из Китая в преддверии усиления санкций СШАНе исключено, что NVIDIA может заставить подождать с выполнением заказов клиентов… всех, кроме представителей китайского бизнеса. Клиенты из Поднебесной, по слухам, заказали ускорители H20 на огромную сумму $16 млрд — до того, как США, возможно, запретит продавать их в КНР, сообщает The Information. По данным китайских инсайдеров, ByteDance, Alibaba Group, Tencent Holdings и др. заказали огромное количество H20 в первые три месяца текущего года. Имеются данные о том, что таких чипов уже не хватает в Китае, и NVIDIA может сфокусировать усилия на производстве большего количества H20 для удовлетворения спроса огромного рынка до того, как предложенный запрет вступит в действие. Может быть выполнено заказов минимум на $16 млрд — это приведёт к тому, что выпуск прочих чипов компании замедлится и приведёт к ещё большему дефициту передовых ускорителей на рынке. В результате американским и европейским клиентам придётся ждать выполнения своих заказов дольше обычного. 
Источник изображения: Glsun Mall/unsplash.com H20 является самым производительным ИИ-ускорителем, допущенным для поставок в Китай в соответствии с американскими экспортными ограничениями, введёнными в октябре 2023 года. Тем не менее, США могут вскоре и вовсе запретить поставки любых ускорителей. В то же время Пекин, по слухам, ужесточает контроль над продажами чипов иностранного производства — соответствующие правила уже действуют. Это предпринимается для того, чтобы китайские компании приобрели ускорители местного производства. В IDC уже заявляли, что китайские власти поддерживают и субсидируют местных производителей для выпуска чипов на архитектуре Arm. Впервые США ввели связанный с поставками в Китай чипов экспортный контроль в октябре 2022 года для замедления технологического развития Китая. В частности, были запрещены продажи передовых на тот момент ускорителей NVIDIA A100 и H100, специально ослабленные A800 и H800 запретили позже. После триумфального дебюта open source ИИ-моделей китайского стартапа DeepSeek в январе 2025 года спрос на H20 значительно вырос. И, хотя H20, по некоторым данным, в 15 раз «медленнее», чем новейшие модели серии NVIDIA Blackwell, только их ещё разрешено официально продавать в Китай после ограничений, введённых в октябре 2023 года. Ускорители применяются китайскими компаниями для обучения ИИ-моделей, хотя изначально чипы позиционировались как решения для инференса. Впрочем, как считают эксперты Moor Insights & Strategy, наращивание производства H20 не повлияет на поставки в США и Европе, поскольку для выпуска современных ускорителей Blackwell используется другой техпроцесс, т.е. другие производственные линии.
04.04.2025 [10:10], Сергей Карасёв
Tenstorrent представила ИИ-ускорители Blackhole на архитектуре RISC-VКанадский стартап Tenstorrent анонсировал ИИ-ускорители семейства Blackhole, выполненные в виде двухслотовых карт расширения с интерфейсом PCI Express 5.0 x16. Кроме того, дебютировала рабочая станция TT-QuietBox, оборудованная этими изделиями. Напомним, ранее Tenstorrent выпустила ИИ-ускорители Wormhole с 72 и 128 ядрами Tensix, каждое из которых содержит пять ядер RISC-V. Объём памяти GDDR6 составляет соответственно 12 и 24 Гбайт. Производительность достигает 262 и 466 Тфлопс на операциях FP8. В семейство Blackhole вошли модели p100a и p150a/p150b. Первая располагает 120 ядрами Tensix, 16 «большими» ядрами RISC-V, 180 Мбайт памяти SRAM и 28 Гбайт памяти GDDR6 с пропускной способностью 448 Гбайт/с. Изделия p150a/p150b оснащены 140 ядрами Tensix, 16 «большими» ядрами RISC-V, 210 Мбайт памяти SRAM и 32 Гбайт памяти GDDR6 с пропускной способностью 512 Гбайт/с. 
Источник изображений: Tenstorrent Энергопотребление у всех ускорителей достигает 300 Вт. Тактовая частота ИИ-блока — 1,35 ГГц. Габариты карт составляют 42 × 270 × 111 мм. Модели p100a и p150a наделены активным охлаждением, версия p150b — пассивным. При этом ускорители p150a/p150b оборудованы четырьмя разъёмами QSFP-DD 800G.  Рабочая станция TT-QuietBox несёт на борту четыре карты Blackhole p150. Основой служат материнская плата ASRock Rack SIENAD8-2L2T и процессор AMD EPYC 8124P (Siena) с 16 ядрами (32 потока) с тактовой частотой до 3 ГГц. Объём оперативной памяти DDR5-4800 ECC RDIMM равен 256 Гбайт (8 × 32 Гбайт). Установлен SSD вместимостью 4 Тбайт с интерфейсом PCIe 4.0 x4 (NVMe). Присутствуют по два сетевых порта 10GbE RJ45 (контроллер Intel X710-AT2) и 1GbE RJ45 (Intel i210), четыре порта USB 3.1 Gen1 Type-A (по два спереди и сзади), аналоговый разъём D-Sub.  Ускоритель Blackhole p100 предлагается по цене около $1000, тогда как обе модификации Blackhole p150 оценены в $1300. Рабочая станция TT-QuietBox Blackhole обойдётся в $12 тыс.
02.04.2025 [11:50], Руслан Авдеев
Царь-чипы с интегрированной фотоникой: Cerebras Systems и Ranovus выбраны DARPA для создания вычислительной платформы нового поколенияИИ-стартап Cerebras Systems выбран американским военно-техническим управлением DARPA для разработки высокопроизводительной вычислительной системы нового поколения. Cerebras объединит собственные ИИ-ускорители и фотонные CPO-интерконнекты Ranovus для обеспечения высокой производительности при малом энергопотреблении, сообщает пресс-центр Cerebras. Комбинация технологий двух компаний позволит обеспечить в реальном времени моделирование сложных физических процессов и выполнение масштабных ИИ-задач. С учётом успеха программы DARPA Digital RF Battlespace Emulator (DRBE), в рамках которой Cerebras уже разрабатывает передовой суперкомпьютер для радиочастотной эмуляции, именно Cerebras и Ranovus были выбраны для новой инициативы, позволяющей объединить вычислительные продукты Cerebras с первыми в отрасли фотонными интерконнектами Ranovus. Решение крайне актуальное, поскольку двумя ключевыми вопросами для современных вычислительных систем являются проблемы с памятью и обменом данных между ускорителями и иной серверной инфраструктурой — вычислительные потребности растут быстрее, чем возможности памяти или IO-систем ввода-вывода. Как утверждают в Cerebras, её WSE-чипы имеют в 7 тыс. раз большую пропускную способность, чем классические ускорители, что даёт самый быстрый в мире инференс и самое быстрое моделирование молекулярных процессов. 
Источник изображения: Cerebras В рамках нового плана DARPA стартап Cerebras будет использовать интерконнект Ranovus, что позволит получить производительность, недоступную даже для крупнейших суперкомпьютерных кластеров современности. При этом энергопотребление будет значительно ниже, чем у самых современных решений с использованием коммутаторов. Последние являются одними из самых энергоёмких компонентов в современных ИИ-системах или суперкомпьютерах. Утверждается, что комбинация новых технологий двух компаний позволит искать решения самых сложных задач в реальном времени, будь то ИИ или сложное моделирование физических процессов, на недостижимом сегодня уровне. Подчёркивается, что оставаться впереди конкурентов — насущная необходимость для обороны США, а также местного коммерческого сектора. В частности, это открывает огромные возможности для работы ИИ в режиме реального времени — от обработки данных с сенсоров до симуляции боевых действий и управления боевыми или коммерческими роботами. В Ranovus заявили, что платформа Wafer-Scale Co-Packaged Optics в 100 раз производительнее аналогичных современных решений, что позволяет значительно повысить эффективность ИИ-кластеров, и значительно энергоэффективнее продуктов конкурентов. Партнёрство компаний позволит задать новый стандарт для суперкомпьютерной и ИИ-инфраструктуры, решая задачи роста спроса на передачу и обработку данных и давая возможность реализовать военное и коммерческое моделирование нового поколения. Помимо использования в целях американских военных, гигантские ИИ-чипы Cerebras применяются и оборонными ведомствами других стран. Так, весной 2024 года сообщалось, что продукты компании помогут натренировать ИИ для военных Германии.
31.03.2025 [10:49], Руслан Авдеев
Новые нормы энергоэффективности ИИ-ускорителей угрожают бизнесу NVIDIA в КитаеПекин представил новые нормы энергоэффективности для ИИ-ускорителей. Весьма вероятно, что они помешают китайским компаниям приобретать наиболее востребованные в Китае ускорители NVIDIA, если регуляторы всерьёз возьмутся за контроль их исполнения, сообщает The Financial Times. Национальная комиссия по развитию и реформам (NDRC) настоятельно рекомендует местным игрокам рынка ЦОД использовать ускорители, соответствующие требованиям к энергоэффективности, при строительстве новых дата-центров и расширении уже существующих объектов. Популярный в Китае ИИ-ускоритель NVIDIA H20 менее производителен, чем флагманские модели компании, но его можно официально поставлять в страну. Однако, по данным издания, на сегодняшний день H20 не соответствует новым требованиям комиссии. По информации источников, в последние несколько месяцев китайский регулятор без лишнего шума «отговаривает» местные IT-гиганты, такие как Alibaba, ByteDance и Tencent, от использования H20. Впрочем, пока правила применяются не слишком жёстко, и эти ускорители NVIDIA по-прежнему востребованы на китайском рынке. Последствия для бизнеса NVIDIA могут оказаться серьёзнее, если комиссия решит ужесточить запрет — это поставит под угрозу многомиллиардные доходы компании в Китае. Несмотря на активное строительство дата-центров, американский разработчик рискует потерять заказы, а его место займёт Huawei, чьи продукты лучше соответствуют новым «зелёным» требованиям. В настоящее время NVIDIA ищет способы повысить энергоэффективность своих решений и стремится провести переговоры с руководством NDRC для обсуждения сложившейся ситуации. Однако это приведёт к снижению производительности H20 и, соответственно, конкурентоспособности на китайском рынке. 
Источник изображения: Henry Chen/unsplash.com Поскольку ограничения распространяются главным образом на новые, строящиеся ЦОД, некоторые компании обходят правила, заменяя в уже действующих дата-центрах старые ускорители на H20. В других случаях несоблюдение норм может привести к проверкам и штрафам. Хотя ограничения вступили в силу ещё в прошлом году, до недавнего времени о них не сообщалось — Китай всеми силами стремится к технологическому суверенитету в полупроводниковой сфере и активно содействует отказу местных компаний от продукции NVIDIA. Прямым конкурентом H20 считается Huawei Ascend 910B, на подходе и вариант 910C. NRDC недвусмысленно намекает на будущее отношений Пекина и NVIDIA. После ужесточения экспортных ограничений США в отношении Китая в октябре 2023 года компания специально разработала ослабленную экспортную версию H20. Однако на фоне триумфа китайских ИИ-моделей стартапа DeepSeek в стране разразился настоящий бум ИИ-технологий, и компании вроде Alibaba и Tencent активно закупают H20, особенно с учётом вероятного дальнейшего ужесточения американских санкций, включая возможный запрет на поставки даже ослабленных ускорителей. Китай — четвёртый по величине рынок для NVIDIA в мире: в 2025 фискальном году выручка компании здесь составила $17,1 млрд, или 13 % от всех продаж. Помимо Huawei, конкуренцию NVIDIA на китайском рынке может составить и Intel с её ускорителями HL328 и HL388, однако они также не соответствуют новым китайским требованиям по энергоэффективности. Впрочем, их доля в китайском импорте изначально была незначительной.
29.03.2025 [10:11], Алексей Степин
Bolt Graphics анонсировала универсальную видеокарту со слотами SO-DIMM, которая может потягаться с RTX 5080Все современные графические ускорители предлагаются с жёстко заданным при производстве объёмом видеопамяти, а в наиболее производительных моделях память типа HBM вообще интегрирована на одной с основным кристаллом подложке. Однако требования к объёму памяти в последнее время растут быстрее, а за дополнительный объём вендор просят всё больше. Кардинально иной подход предлагает компания Bolt Graphics, недавно анонсировавшая серию ускорителей Zeus. Несмотря на «ИИ-пандемию», Bolt Graphics в своём анонсе не делает упор на искусственный интеллект, а называет Zeus первым GPU, специально созданным для целей HPC, рендеринга, трассировки лучей и даже компьютерных игр. Что интересно, в основе Zeus лежит не некая закрытая архитектура: скалярная часть нового GPU построена на базе спецификации RISC-V RVA23, векторная представлена FP64 ALU на базе несколько модифицированной RVV 1.0. Прочие функции реализованы путём кастомных расширений и отдельных блоков-ускорителей. Все они пользуются общим кешем объёмом 128 Мбайт. Дополняет картину блок телеметрии и внутренний интерконнект для общения с другими вычислительным блоками. 
Zeus 1c26-032 (Источник изображений: Bolt Graphics) Используется чиплетный подход. Базовый «строительный блок» Zeus 1c26-032 включает GPU-чиплет, который соединён с 32 Гбайт набортной памяти LPDDR5x (273 Гбайт/с) и контроллером внешней памяти DDR5 (90 Гбайт/с), т.е. при желании можно установить ещё 128 Гбайт RAM (два модуля SO-DIMM). В GPU-чиплет встроены контроллеры DisplayPort 2.1a и HDMI 2.1b, а с внешним миром он общается посредством IO-чиплета, с которым он соединён 256-Гбайт/с каналом. IO-чиплет предлагает необычный набор портов. Помимо сразу двух интерфейсов PCIe 5.0 x16 (64 Гбайт/с каждый) имеется выделенный порт RJ-45 для BMC и 400GbE-порт QSFP-DD. Наконец, есть аппаратный блок видеокодирования, способный справиться с двумя потоками 8K@60 AV1/H.264/H.265.  Заявленный уровень производительности в векторных FP64/FP32/FP16-вычислениях составляет 5/10/20 Тфлопс, а в матричных INT16/INT8 — 307,2/614,4 Топс. Аппаратный блок ускорения лучей (path tracing) выдаёт до 77 гигалучей. Для сравнения: NVIDIA RTX 5090 способна выдавать 32 гигалуча, а FP64-производительность составляет 1,6 Тфлопс. В то же время в расчётах пониженной точности актуальные решения NVIDIA всё равно быстрее Zeus 1c26-032. Однако у новинки есть важное преимущество — её уровень TDP составляет всего 120 Вт. Второй интерфейс PCIe 5.0 x16 можно использовать для прямого объединения двух карт. 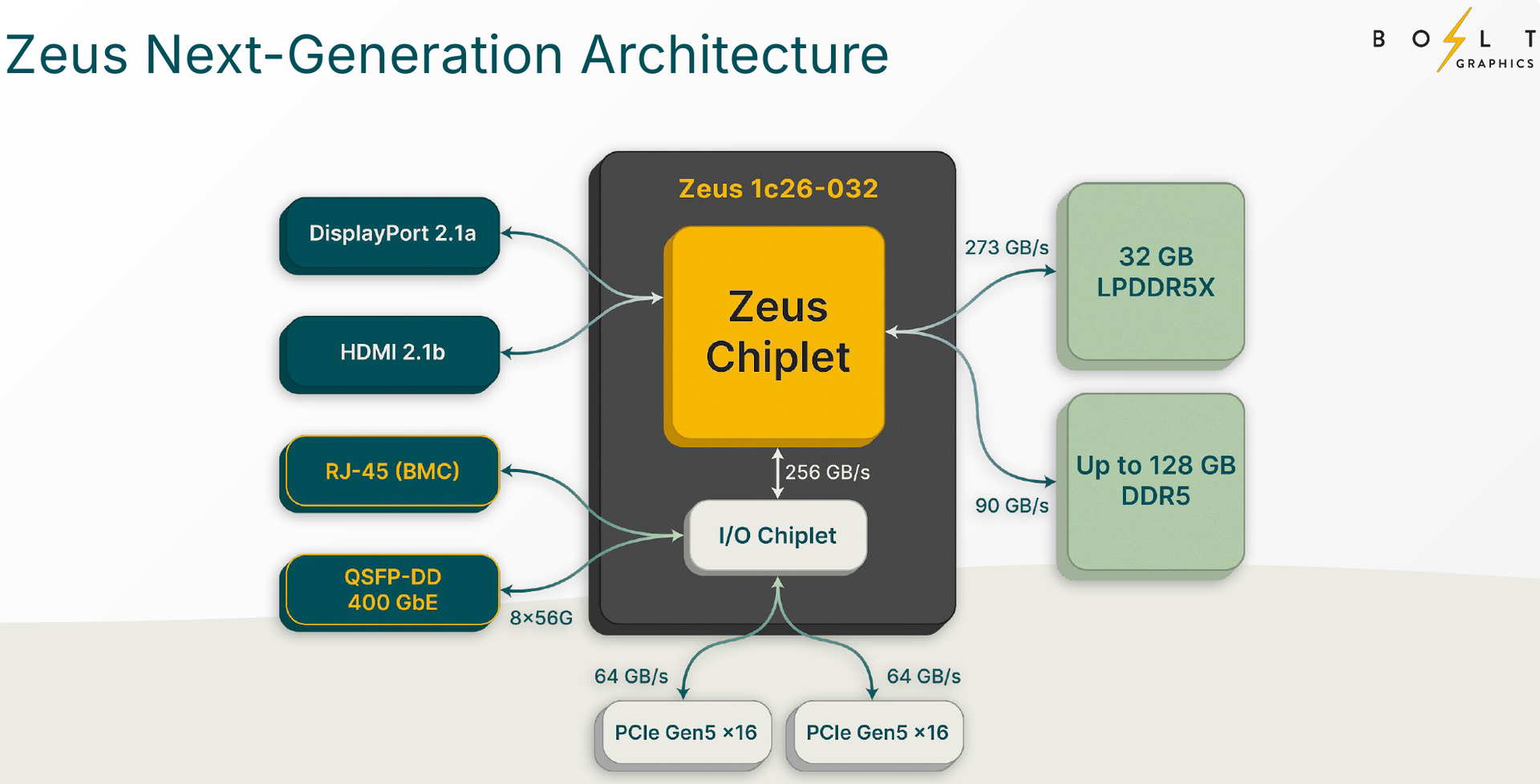 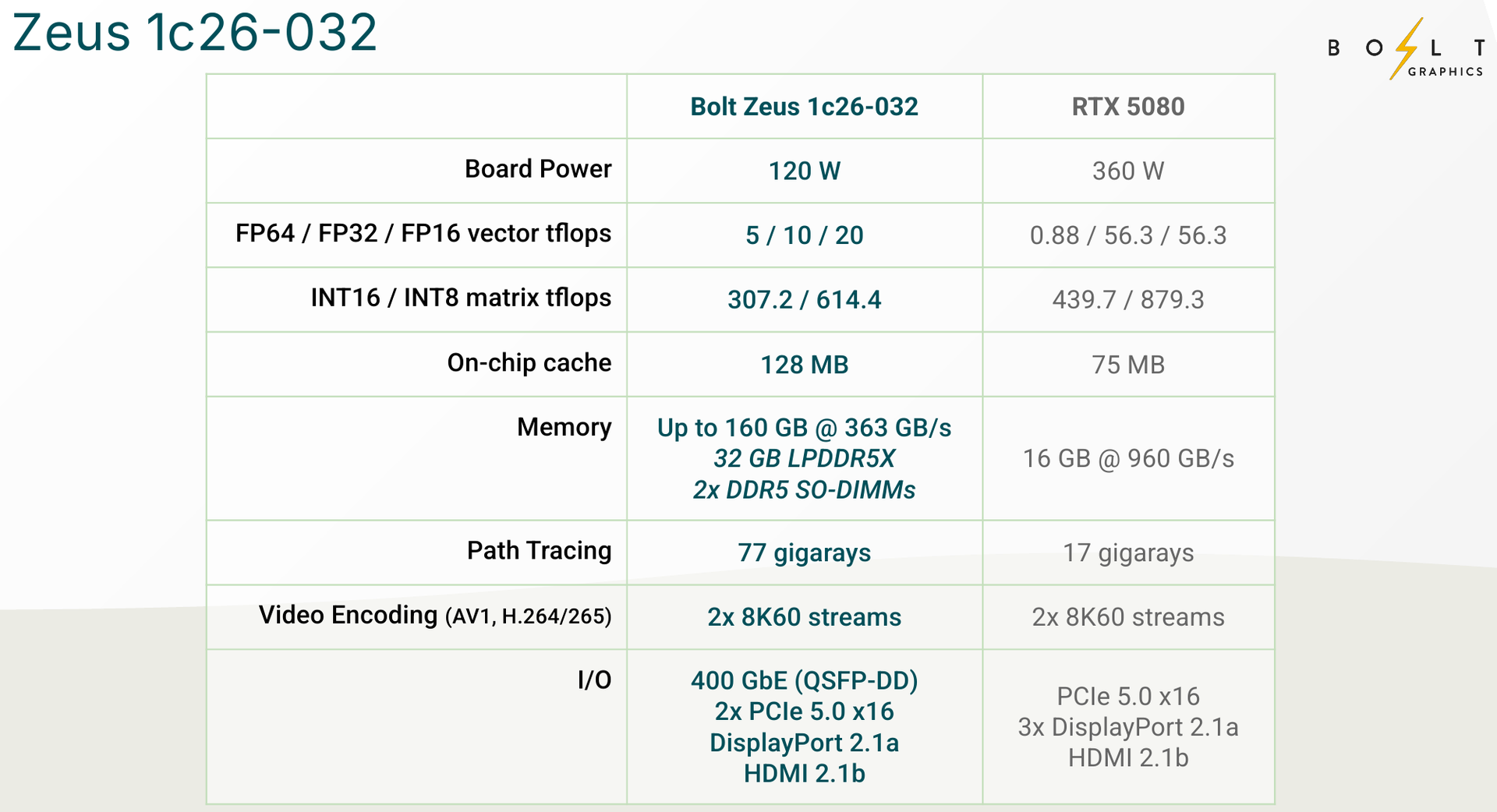 Вариант ускорителя с двумя чиплетами носит название Zeus 2c26-064/128, а с четырьмя — 4c26-256. Последние числа обозначают объём распаянной памяти LPDDR5X. Что касается расширяемой памяти, то количество доступных разъёмов SO-DIMM также зависит от модели и составляет до восьми, так что во флагманской конфигурации базовые 256 Гбайт LPDDR5x можно дополнить аж 2 Тбайт DDR5. Производительность с увеличением количеств GPU-чиплетов растёт практически пропорционально, но есть некоторые другие нюансы. Так, в Zeus 2c26-064 и Zeus 2c26-128 (оба варианта имеют TDP 250 Вт) есть только один IO-чиплет, а GPU-чиплеты объединены шиной со скоростью 768-Гбайт. 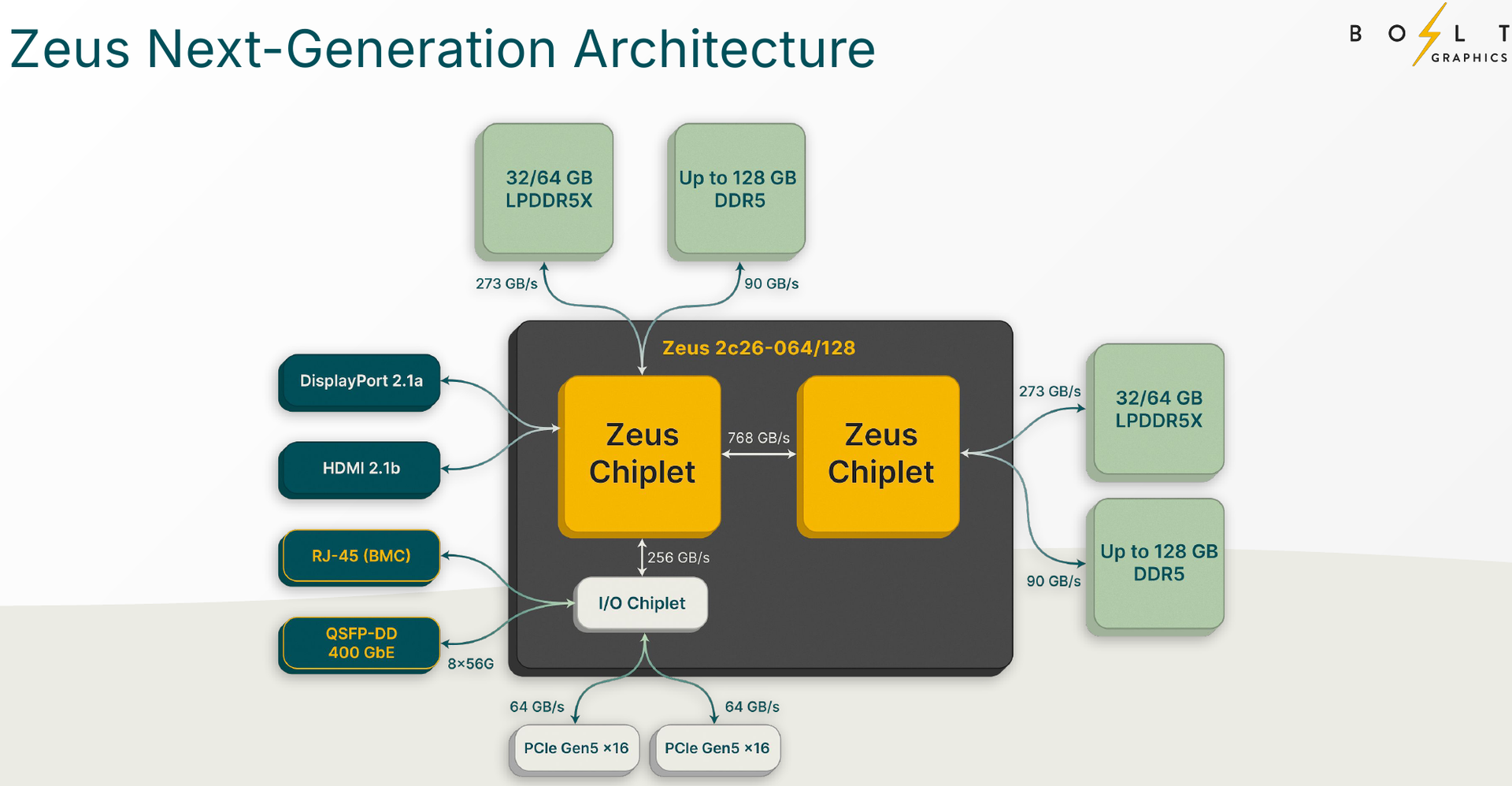  Zeus 4c26-256 имеет сразу четыре I/O чиплета в составе, которые дают восемь контроллеров PCIe 5.0 x4 (один чиплет, совокупно 32 линии) и шесть 800GbE-портов OSFP (три чиплета). Между собой GPU-чиплеты объединены шиной со скоростью 512-Гбайт/с. Каждый из них соединён с собственным IO-чиплетом на скорости 256 Гбайт/с. Теплопакет флагмана составляет 500 Ватт, ускоритель, если верить Bolt Graphnics, развивает 20 Тфлопс в режиме FP64, почти 2500 Топс на вычислениях FP8 и способен обрабатывать до 307 гигалучей. 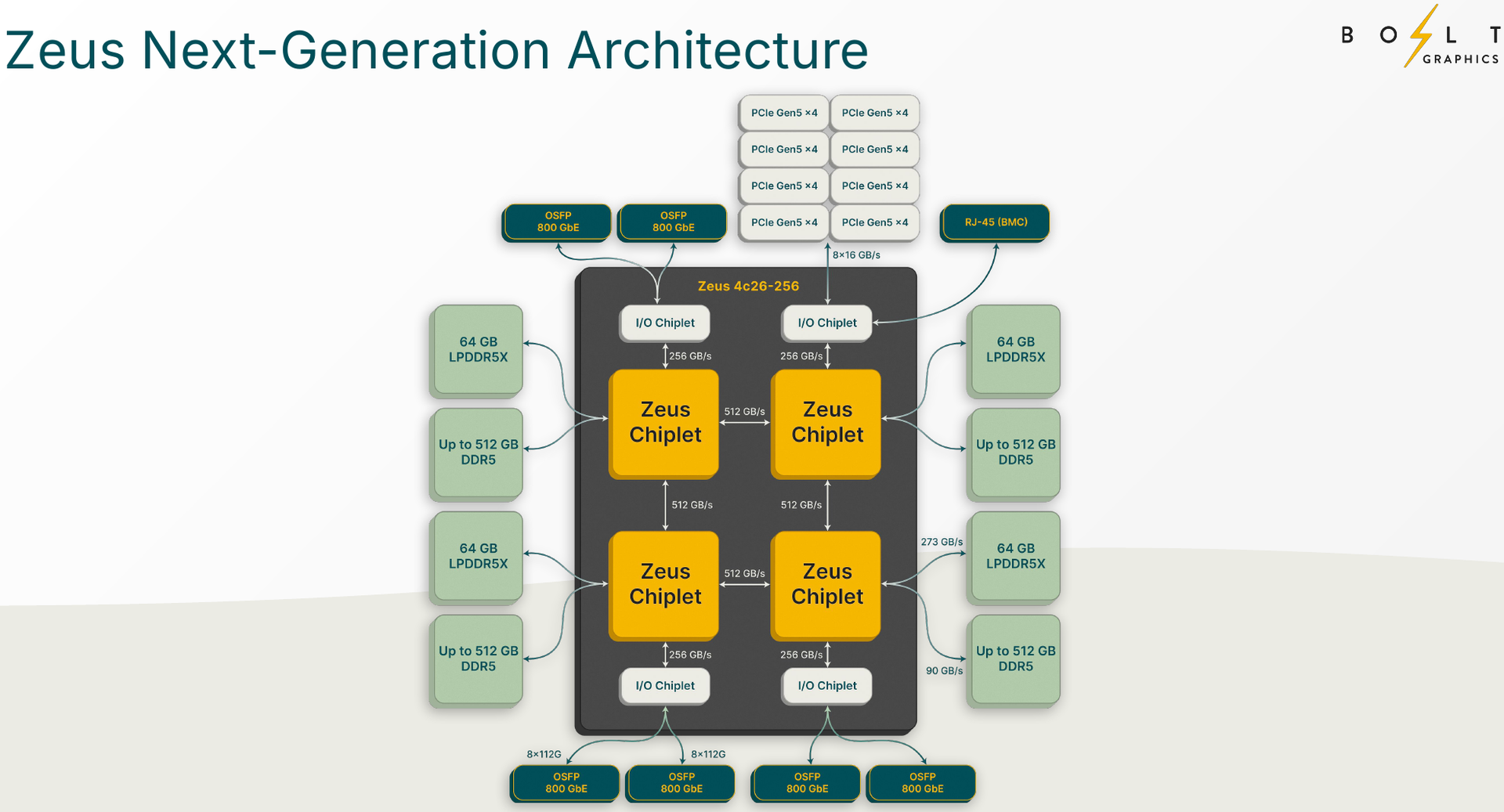 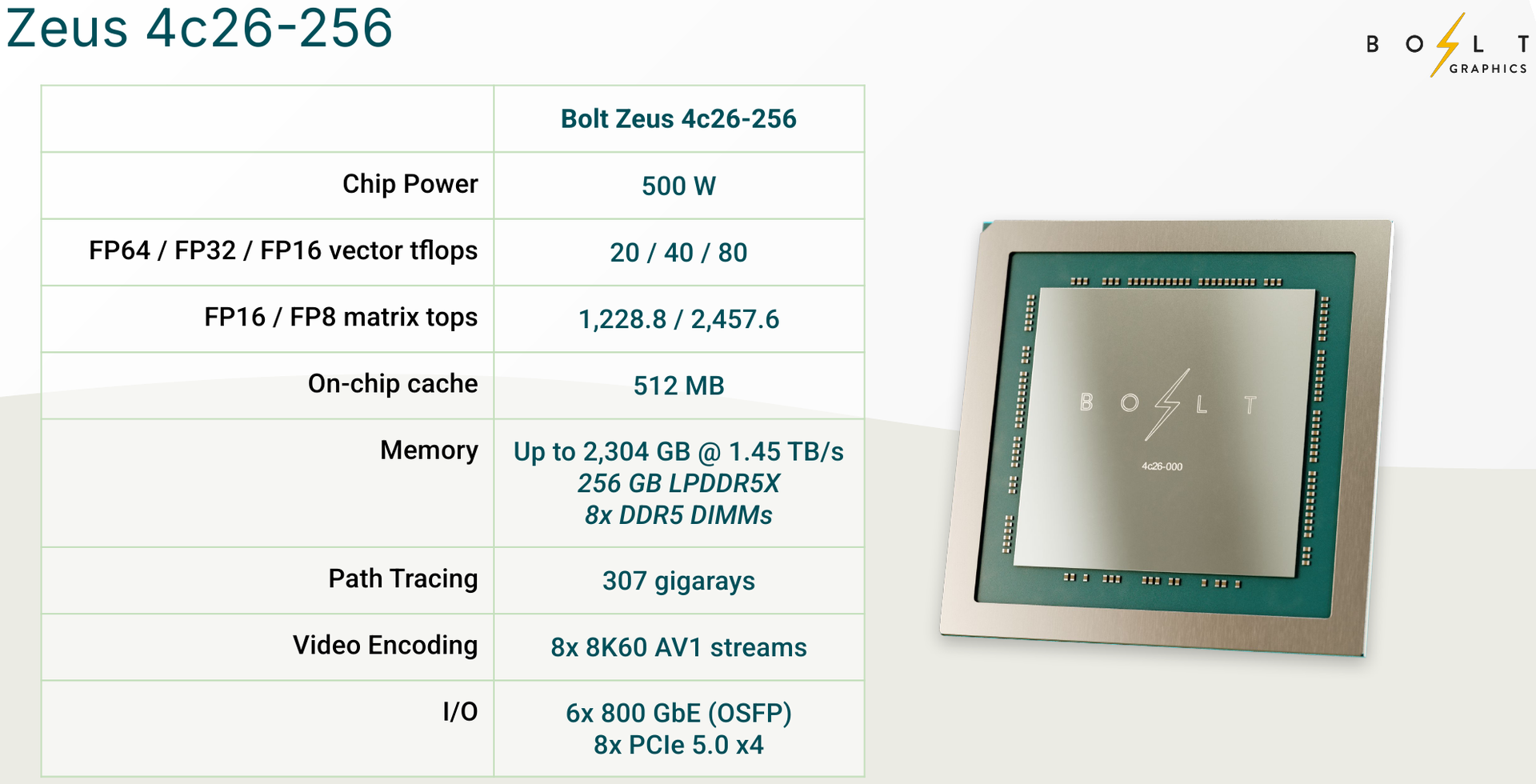 Разработчики явно заложили в своё детище широкие возможности кластеризации, о чём свидетельствует наличие мощной сетевой подсистемы. Поддерживаются как скромные конфигурации из двух GPU, соединённых непосредственно по Ethernet 400GbE, так и масштабные системы уровня стойки, содержащей 80 плат Zeus 4c26-256, соединённых как с коммутатором, так и напрямую друг с другом. Такой кластер потребляет 44 кВт, но зато способен обеспечивать запуск крупных физических симуляций или обучение ИИ моделей за счёт огромного массива общей памяти, составляющего 160 Тбайт. Вычислительная производительность такого кластера достигает 1,6 Пфлопс в режиме FP64 и 196 Попс в режиме FP8. 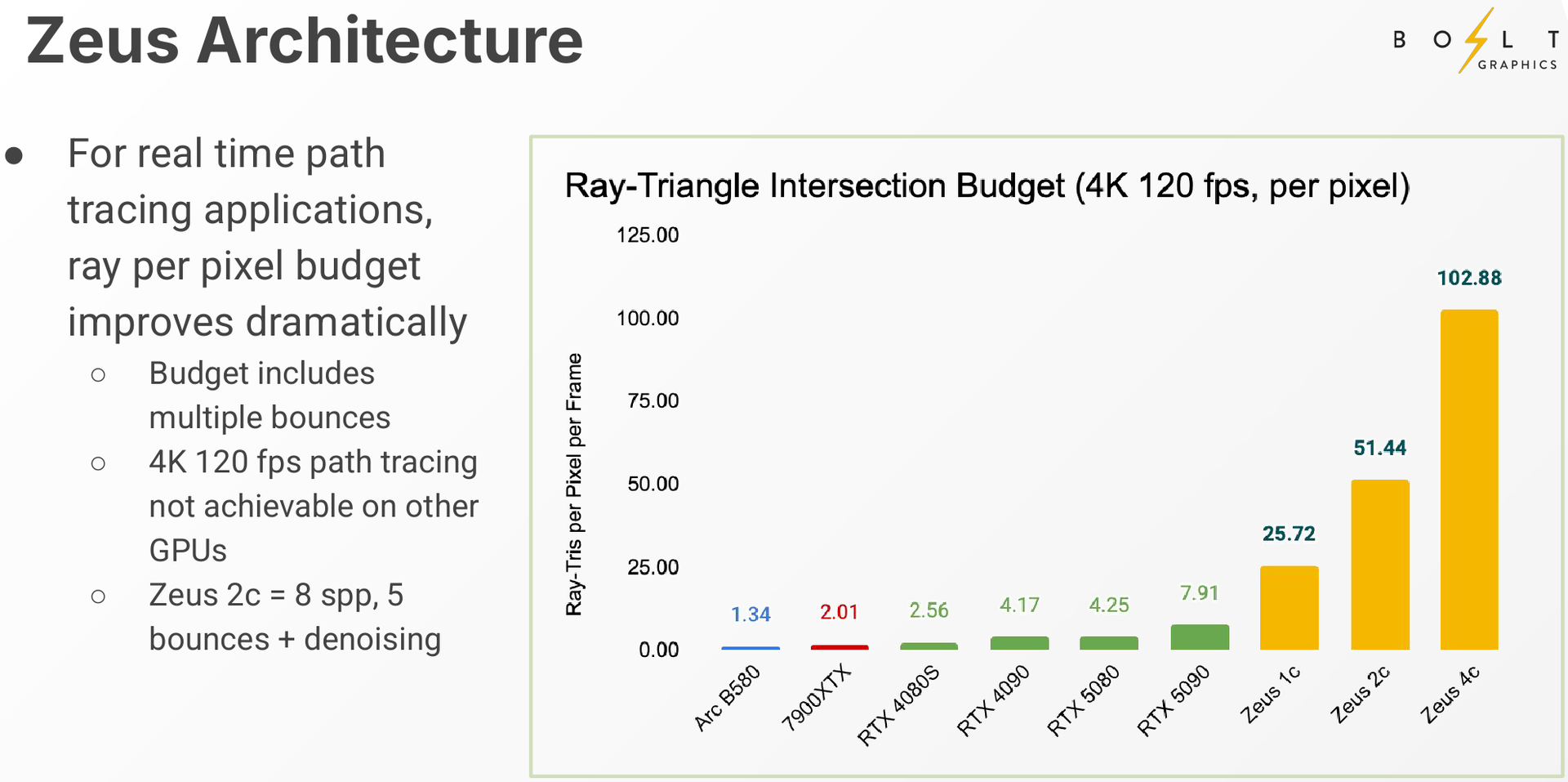  Одной из особенностей новинок является трассировщик лучей Glowstick, способный работать в режиме реального времени практически во всех современных пакетах 3D-моделирования или видеоредактирования, таких как Maya, 3ds Max, Blender, SketchUp, Houdini и Nuke. Он будет дополнен фирменной библиотекой Bolt MaterialX, содержащей более 5000 текстур высокого качества. А благодаря поддержке стандарта OpenUSD он сможет легко интегрироваться в любую цепочку рендеринга и пост-обработки. Также запланирован электромагнитный симулятор Bolt Apollo. Обещаны фирменные драйверы Vulkan/DirectX и SDK с использованием LLVM. 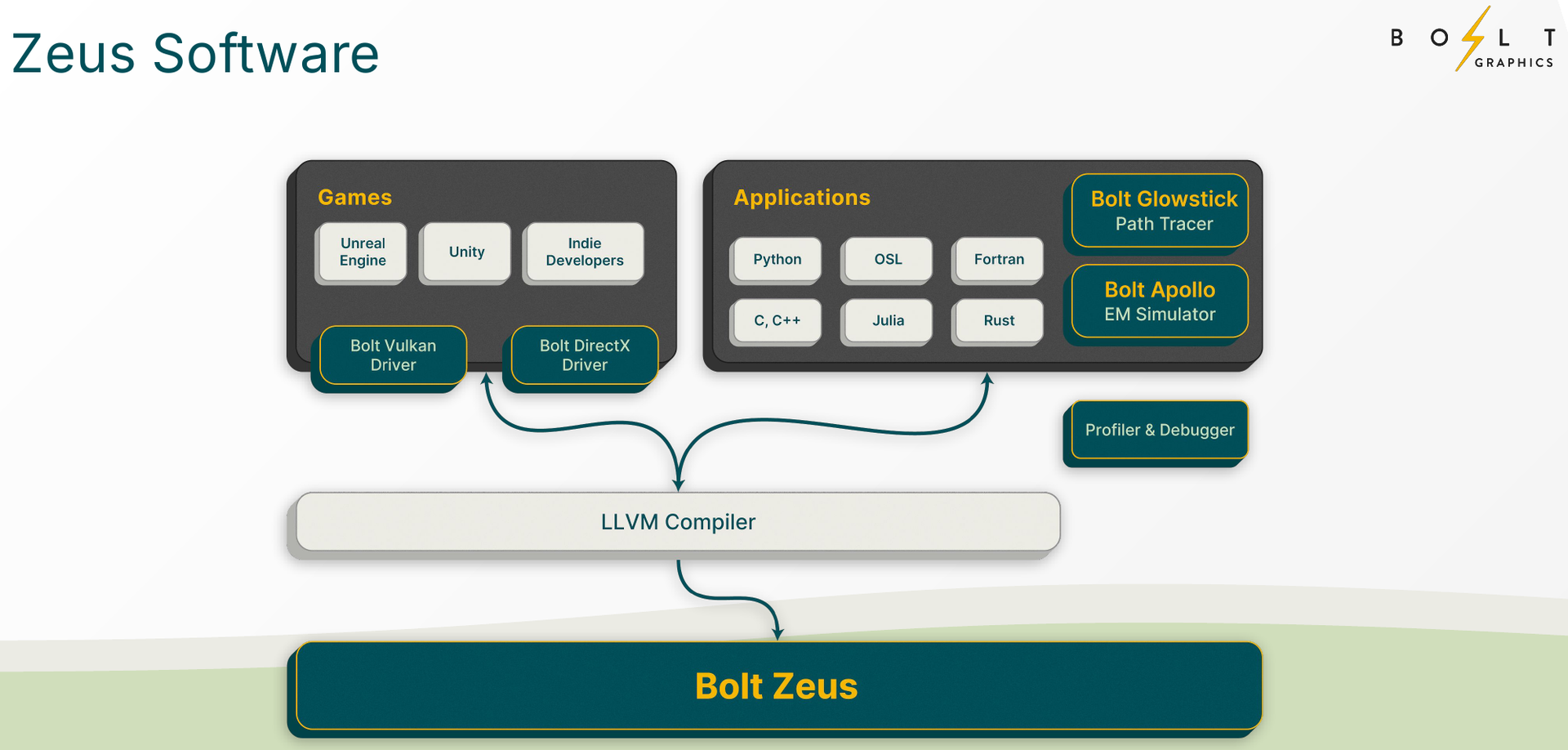 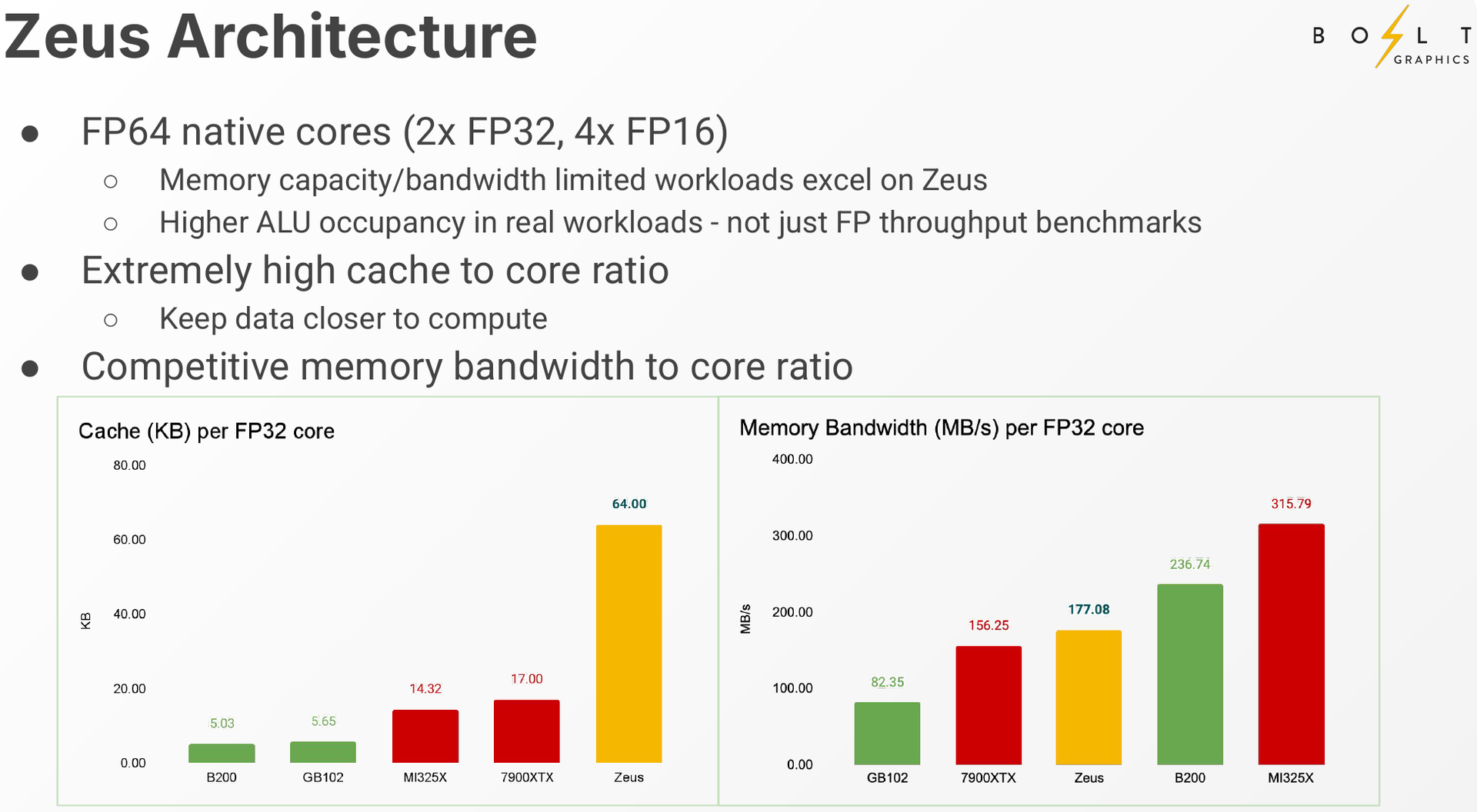 Ранний доступ к комплектам разработчика Bolt Graphics наметила на IV квартал текущего года. В III квартале 2026 года должны появиться 2U-серверы на базе Zeus, а массовые поставки серверов и PCIe-карт начнутся не ранее IV квартала того же года. Пока сложно сказать, насколько хорошо новая архитектура себя проявит, но если верить предварительным тестам Zeus, выигрыш в сравнении с существующими ускорителями существенен, особенно в энергопотреблении.
20.03.2025 [01:10], Владимир Мироненко
Анонсированы суперускорители на Rubin и Rubin Ultra, в которых NVIDIA не будет ошибаться в подсчётахNVIDIA анонсировала ИИ-ускорители следующего поколения Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Выход Rubin Ultra запланирован на II половину 2027 года. Компанию им составят Arm-процессоры Vera. Серия названа в честь астронома Веры Купер Рубин (Vera Florence Cooper Rubin), известной своими исследованиями тёмной материи. NVIDIA отметила, что в названии предыдущих ускорителей была «допущена ошибка». В Blackwell каждый чип состоит из двух GPU, но, например, в названии GB200/GB300 NVL72 упоминается только 72 GPU, хотя речь фактически идёт о 144 GPU. Поэтому, начиная с Rubin компания будет использовать новую схему наименований, которая больше не учитывает количество чипов, а относится исключительно к количеству GPU. Таким образом, следующее поколение суперускорителей, упакованных в ту же стойку Oberon, что используется для Grace Blackwell, получило название Vera Rubin NVL144. Rubin во многом повторяет дизайн Blackwell, поскольку R200 всё так же включает два кристалла GPU (в составе SXM7), способных выдавать до 50 Пфлопс в вычислениях FP4 (без разреженности), и 288 Гбайт памяти в восьми стеках 12-Hi, но на этот раз уже HBM4 с общей пропускную способностью 13 Тбайт/с (2048-бит шина). Кристаллы GPU будут изготовлены по техпроцессу TSMC N3P, а компанию им составят два IO-чиплеты, отвечающие за все внешние коммуникации, пишет SemiAnalysis. Всё вместе будет упаковано посредством CoWoS-L. TDP новинок не указывается. 
Источник изображений: NVIDIA Чипы перейдут на интерконнект NVLink 6 со скоростью 1,8 Тбайт/с в каждую сторону (3,6 Тбайт/с в дуплексе), что вдвое выше, чем у текущего поколения NVLink 5. Аналогичным образом вырастет и коммутационная способность NVSwitch, а также NVLink C2C. Впрочем, при сохранении прежней схемы, когда один CPU обслуживает два модуля GPU, каждому из последних, по-видимому, достанется половина пропускной способности шины. Собственно процессор Vera получит 88 кастомных (а не Neoverse CSS в случае Grace) 3-нм Arm-ядра, причём с SMT, что даст 176 потоков. Каждый CPU получит порядка 1 Тбайт LPDRR-памяти и будет вдвое быстрее Grace при теплопакете в районе 50 Вт.  По словам NVIDIA, VR200 NVL144 будет в 3,3 раза быстрее: 3,6 Эфлопс в FP4-вычислениях для инференса и 1,2 Эфлопс в FP8 для обучения. Суммарный объём HBM-памяти составит более 20,7 Тбайт, системной памяти — 75 Тбайт. Внешняя сеть будет представлена адаптерами ConnectX-9 SuperNIC со скоростью 1,6 Тбит/с на порт, что вдвое больше, чем у ConnectX-8, обслуживающих GB300.  Во II половине 2027 года появится ускоритель Rubin Ultra (R300) с FP4-производительностью более 100 Пфлопс (без разреженности), объединяющий сразу четыре GPU, два IO-чиплета и 16 стеков HBM4e-памяти 16-Hi общим объёмом 1 Тбайт (32 Тбайт/с) в упаковке SXM8. Более того, ускорители, по-видимому, получат ещё и LPDDR-память. Процессор Vera перекочует в новую платформу без изменений, один CPU будет приходиться на четыре GPU. Внутренней шиной станет NVLink 7, которая сохранит скорость NVLink 6, зато получит вчетверо более производительные коммутатор NVSwitch. А вот внешнее подключение по-прежнему будут обслуживать адаптеры ConnectX-9.  Новая стойка Kyber полностью поменяет компоновку. Узлы теперь напоминают вертикальные блейд-серверы, используемые в суперкомпьютерах. Каждый узел (VR300) будет включать один процессор Vera и один ускоритель Rubin Ultra. Всего таких узлов будет 144, что в сумме даёт 144 CPU, 576 GPU и 144 Тбайт HBM4e. Суперускоритель Rubin Ultra NVL576 будет потреблять 600 кВт и обеспечит быстродействие в 15 Эфлопс для инференса (FP4) и 5 Эфлопс для обучения (FP8). При этом упоминается, что объём быстрой (fast) памяти составит 365 Тбайт, но сколько из них достанется CPU, не уточняется. Дальнейшие планы NVIDIA включают выход во II половине 2028 года первого ускорителя на новой архитектуре Feynman, названной в честь физика-теоретика Ричарда Филлипса Фейнмана (Richard Phillips Feynman). Сообщается, что Feynman будет полагаться на память HBM «следующего поколения» и, вероятно, на CPU Vera. Это поколение также получит коммутаторы NVSwitch 8 (NVL-Next), сетевые коммутаторы Spectrum7 и адаптеры ConnectX-10.
19.03.2025 [08:28], Сергей Карасёв
NVIDIA представила ускоритель RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 6000 Blackwell Server Edition для требовательных приложений ИИ и рендеринга высококачественной графики. Ожидается, что новинка будет востребована среди заказчиков из различных отраслей, включая архитектуру, автомобилестроение, облачные платформы, финансовые услуги, здравоохранение, производство, игры и развлечения, розничную торговлю и пр. Как отражено в названии, в основу решения положена архитектура Blackwell. Задействован чип GB202: конфигурация включает 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. Устройство несёт на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Ускоритель RTX Pro 6000 Blackwell Server Edition использует интерфейс PCIe 5.0 x16. Энергопотребление может настраиваться в диапазоне от 400 до 600 Вт. Реализована поддержка DisplayPort 2.1 с возможностью вывода изображения в форматах 8K / 240 Гц и 16K / 60 Гц. Аппаратный движок NVIDIA NVENC девятого поколения значительно повышает скорость кодирования видео (упомянута поддержка 4:2:2 H.264 и HEVC). Всего доступно по четыре движка NVENC/NVDEC. 
Источник изображения: NVIDIA По заявлениям NVIDIA, по сравнению с ускорителем предыдущего поколения L40S Ada Lovelace модель RTX PRO 6000 Blackwell Server Edition обеспечивает многократное увеличение производительности в широком спектре рабочих нагрузок. В частности, скорость инференса больших языковых моделей (LLM) повышается в пять раз для приложений агентного ИИ. Геномное секвенирование ускоряется практически в семь раз, а быстродействие в задачах генерации видео на основе текстового описания увеличивается в 3,3 раза. Достигается также двукратный прирост скорости рендеринга и примерно такое же повышение скорости инференса рекомендательных систем. Ускоритель RTX PRO 6000 Blackwell Server Edition может использоваться в качестве четырёх полностью изолированных экземпляров (MIG) с 24 Гбайт памяти GDDR7 каждый. Это обеспечивает возможность одновременного запуска различных рабочих нагрузок — например, ИИ-задач и обработки графики. Упомянута поддержка TEE. |
|

