Материалы по тегу: рекорд
|
15.01.2025 [15:35], Руслан Авдеев
Рынок ЦОД поставил рекорд по сделкам в 2024 году — $73 млрдКак свидетельствуют новые данные консалтинговой компании Synergy Research Group, после относительного затишья в 2024 году стоимость закрытых сделок, связанных со слияниями и поглощениями (M&A) ЦОД, стала рекордной, достигнув $73 млрд, сообщает пресс-служба компании. До этого рекордным был 2022 год. Совокупная стоимость официально закрытых сделок превысила $52 млрд, в 2023 году был двухкратный спад до $26 млрд. Впрочем, даже в 2022 году такого уровня не удалось бы добиться без двух крупнейших сделок в данной сфере, объёмом от $11 млрд каждая. Другими словами, «обычные» сделки объёмом до $2 млрд обеспечили довольно скромную статистику и в 2022 году. В этой отношении пиковым был 2021 год. Примечательно, что помимо уже закрытых сделок в 2024 году также имеются оформленные, но ещё не закрытые соглашения на сумму $29 млрд. Также возможны сделки ещё на $15 млрд — компании ищут финансирование или рассматривают доступные варианты. 2025 год тоже имеет все шансы стать рекордным для индустрии ЦОД. 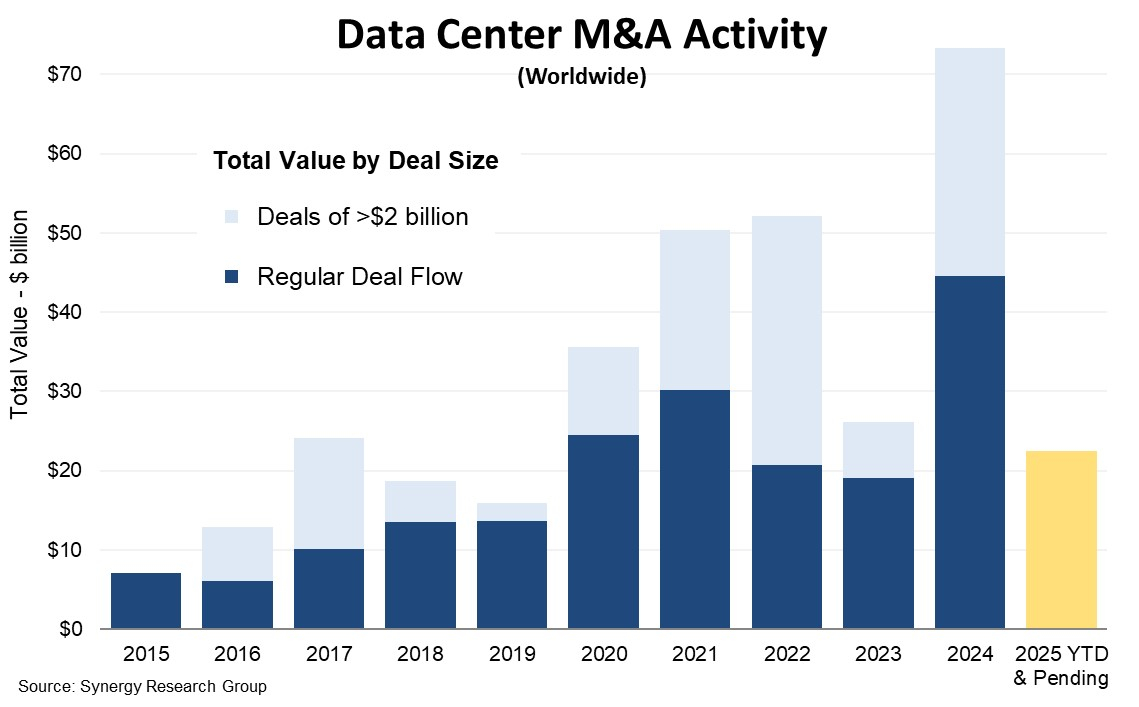
Истчоник: Synergy Research Всего с 2015 года Synergy Research зарегистрировала 1498 сделок слияния и поглощения на рынке ЦОД, общая стоимость составила $300 млрд. В основном речь идёт о покупке компаний целиком, но также были учтены миноритарные инвестиции в акционерный капитал и другие финансовые вложения вплоть до покупки отдельных дата-центров, земли для них и др. В 2021–2022 гг. были закрыты четыре сделки стоимостью от $10 млрд: покупка CyrusOne, Switch, CoreSite и QTS, входящих в Топ-15 колокейшн-провайдеров. В 2024 году в Vantage Data Centers инвестировали в ходе двух сделок $9,2 млрд. Кроме того, компания дважды получила вливания в акционерный капитал в регионе EMEA на общую сумму $3,1 млрд. Также крупные вливания в 2024 году получили EdgeConneX и DataBank. При этом в последние годы на рынок буквально заполонили частные капиталовложения. Если в 2020 году на такие инвестиции пришлось лишь 54 % стоимости закрытых сделок, то в 2021 году их доля увеличилась до 65 %. С тех пор доля выросла до 80–90 % и держится на этом уровне. В Synergy Research подчёркивают, что стремительный рост спроса на мощности ЦОД обусловлен развитием облачных сервисов, социальных сетей и всевозможных цифровых сервисов потребительского и корпоративного уровня. ИИ только усиливает и без того высокий спрос. Уточняется, что сами операторы ЦОД не могли или не хотели инвестировать собственные средства, тогда как частные инвесторы оказались готовыми вложиться в рост рынка. UPD 29.01.2024: Synergy обновила доклад, посвящённый сделкам на рынке ЦОД в 2024 году. Если ранее сообщалось, что их общая сумма составляла $57 млрд, то уточнённые показатели свидетельствуют, что она оказалась выше на целых $16 млрд и составила $73 млрд. В докладе указывается, что добавилась сделка, которая должна была быть закрыта лишь в начале 2025 года, но закрылась в конце декабря. Речь идёт о покупке Blackstone компании AirTrunk, состоявшейся ещё в сентябре, но завершившейся лишь перед самым Новым годом.
12.12.2024 [23:59], Руслан Авдеев
Царь-ускоритель Cerebras WSE-3 в одиночку обучил ИИ-модель с 1 трлн параметровCerebras Systems совместно с Сандийскими национальными лабораториями (SNL) Министерства энергетики США (DOE) провели успешный эксперимент по обучению ИИ-модели с 1 трлн параметров с использованием единственной системы CS-3 с царь-ускорителем WSE-3 и 55 Тбайт внешней памяти MemoryX. Обучение моделей такого масштаба обычно требует тысяч ускорителей на базе GPU, потребляющих мегаватты энергии, участия десятков экспертов и недель на наладку аппаратного и программного обеспечения, говорит Cerebras. Однако учёным SNL удалось добиться обучения модели на единственной системе без внесения изменений как в модель, так и в инфраструктурное ПО. Более того, они смогли добиться и практически линейного масштабирования — 16 систем CS-3 показали 15,3-кратный прирост скорости обучения. 
Источник изображения: Cerebras Модель такого масштаба требует терабайты памяти, что в тысячи раз больше, чем доступно отдельному GPU. Другими словами, классические кластеры из тысяч ускорителей необходимо корректно подключить друг к другу ещё до начала обучения. Системы Cerebras для хранения весов используют внешнюю память MemoryX на базе 1U-узлов с самой обычной DDR5, благодаря чему модель на триллион параметров обучать так же легко, как и малую модель на единственном ускорителе, говорит компания. Ранее SNL и Cerebras развернули кластер Kingfisher на базе систем CS-3, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности.
29.11.2024 [10:15], Сергей Карасёв
Система Cerebras с ускорителями WSE установила рекорд в молекулярной динамике, превзойдя суперкомпьютер FrontierАмериканский стартап Cerebras Systems, специализирующийся на создании чипов для систем машинного обучения и других ресурсоёмких задач, объявил об установлении нового мирового рекорда производительности в области молекулярной динамики. В эксперименте приняли участие Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе Министерства энергетики США (DOE). Вычисления выполнялись на системе, оснащённой фирменными ускорителями Cerebras Wafer Scale Engine (WSE). Говорится, что впервые в истории молекулярной динамики исследователи достигли результата более 1 млн шагов моделирования в секунду (timesteps per second, TPS). В частности, показано значение на уровне 1,1 млн TPS на платформе Cerebras CS-2, оборудованной чипами WSE-2, которые насчитывают 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Для сравнения: в случае суперкомпьютера экзафлопсного класса Frontier, который в нынешнем рейтинге TOP500 занимает второе место, результат составляет 1470 TPS. Таким образом, система Cerebras обеспечивает 748-кратный выигрыш в быстродействии на задачах молекулярной динамики. При этом энергопотребление комплекса Cerebras составляет 27 кВт против 21 МВт у Frontier. 
Источник изображения: Cerebras Кроме того, комплекс Cerebras превзошел Anton 3 — самый мощный в мире специализированный суперкомпьютер для молекулярной динамики. Anton 3 использует 512 кастомных ASIC, а его энергопотребление находится на уровне 400 кВт. Показатель быстродействия Anton 3 достигает 980 тыс. TPS. То есть, система Cerebras показывает выигрыш примерно в 20 %. Предполагается, что ускорители Cerebras предоставят качественно новые возможности для исследований в различных областях, включая разработку материалов следующего поколения, перспективных лекарственных препаратов и решений в сфере возобновляемой энергетики. Нужно отметить, что ранее Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на чипах Cerebras WSE-3. А сама компания Cerebras развернула «самую мощную в мире» ИИ-платформу для инференса.
15.11.2023 [02:15], Владимир Мироненко
Xinnor xiRAID установил новый рекорд производительности среди NVMe-массивов с PCIe 5.0 SSD от KioxiaВ августе этого года израильская компания Xinnor, специализирующаяся на решениях для хранения данных, в том числе программного RAID для современных NVMe SSD, сообщила в ходе саммита Flash Memory Summit о мировом рекорде производительности, установленном с использованием ПО Xinnor xiRAID и 12-ти NVMe SSD Kioxia CM7-R (PCIe 5.0). На SC23 компания обновила рекорд. На этот раз в тесте были задействованы сразу 24 накопителя Kioxia CM7-V (PCIe 5.0, NVMe). Каждый диск имеет скорость последовательного чтения 14 Гбайт/с и последовательной записи 6,75 Гбайт/с, а на случайных операциях производительность составляет 2,7 млн IOPS и более 600 тыс. IOPS соответственно. При развёртывании множества таких SSD в системе первостепенное значение приобретает обеспечение надлежащей масштабируемости производительности и целостности данных. Xinnor выполнила тест на сервере Supermicro с двумя 64-ядерными процессорами AMD EPYC Genoa 9534 и 768 Гбайт RAM. Чтобы избежать узких мест, Xinnor создала две группы RAID 5 по 12 дисков так, что каждый массив находился в рамках одного NUMA-домена. Такая конфигурация обеспечивает наивысшую производительность и одновременно защиту данных в случае сбоя диска для каждого RAID, говорит Xinnor. 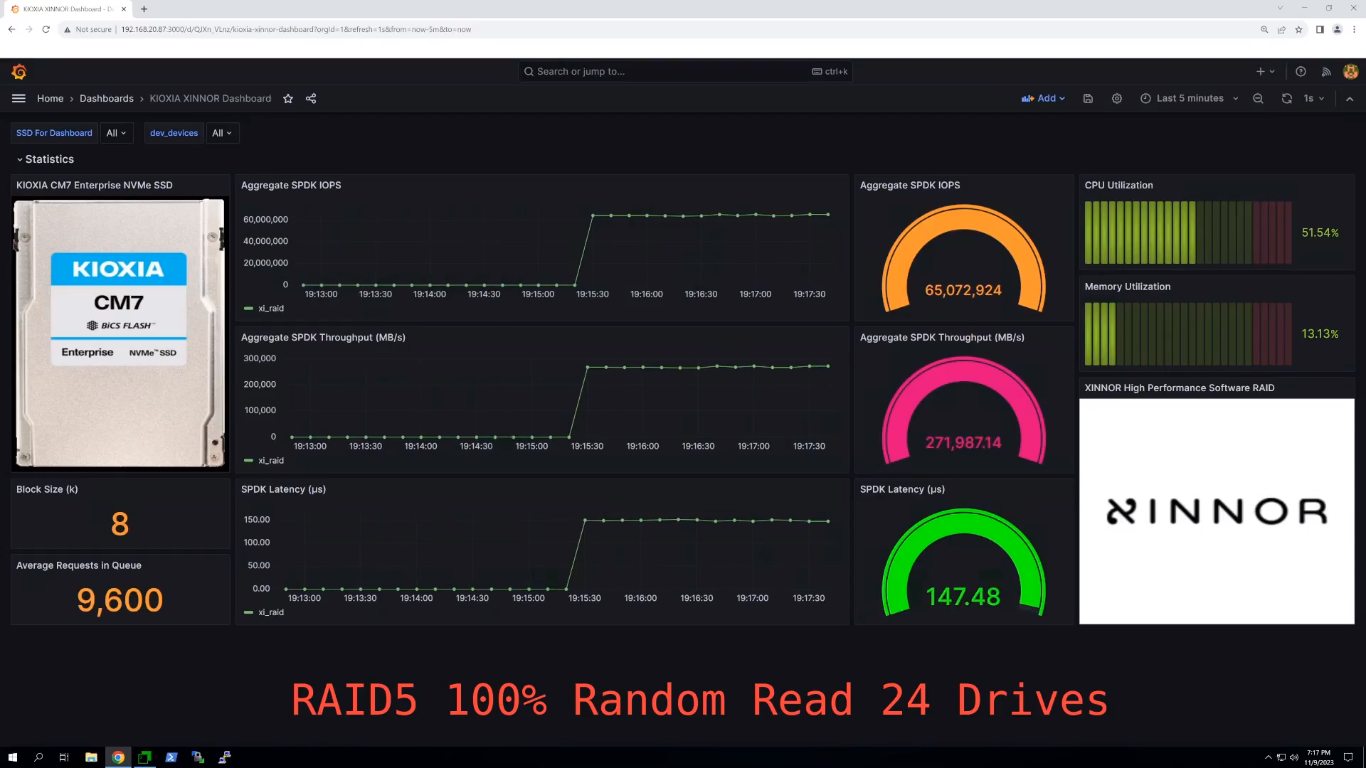
Изображение: Xinnor Сообщается, что в последовательных рабочих нагрузках рекордные показатели (см. таблицу ниже) были достигнуты при использовании лишь 16 из 128 доступных ядер, а на случайных операциях xiRAID нагружал на 3–9 % лишь половину ядер. Низкая нагрузка на CPU и универсальность xiRAID, по словам компании, значительно упрощает развёртывание массивов и позволяет эффективно использовать имеющееся оборудование. 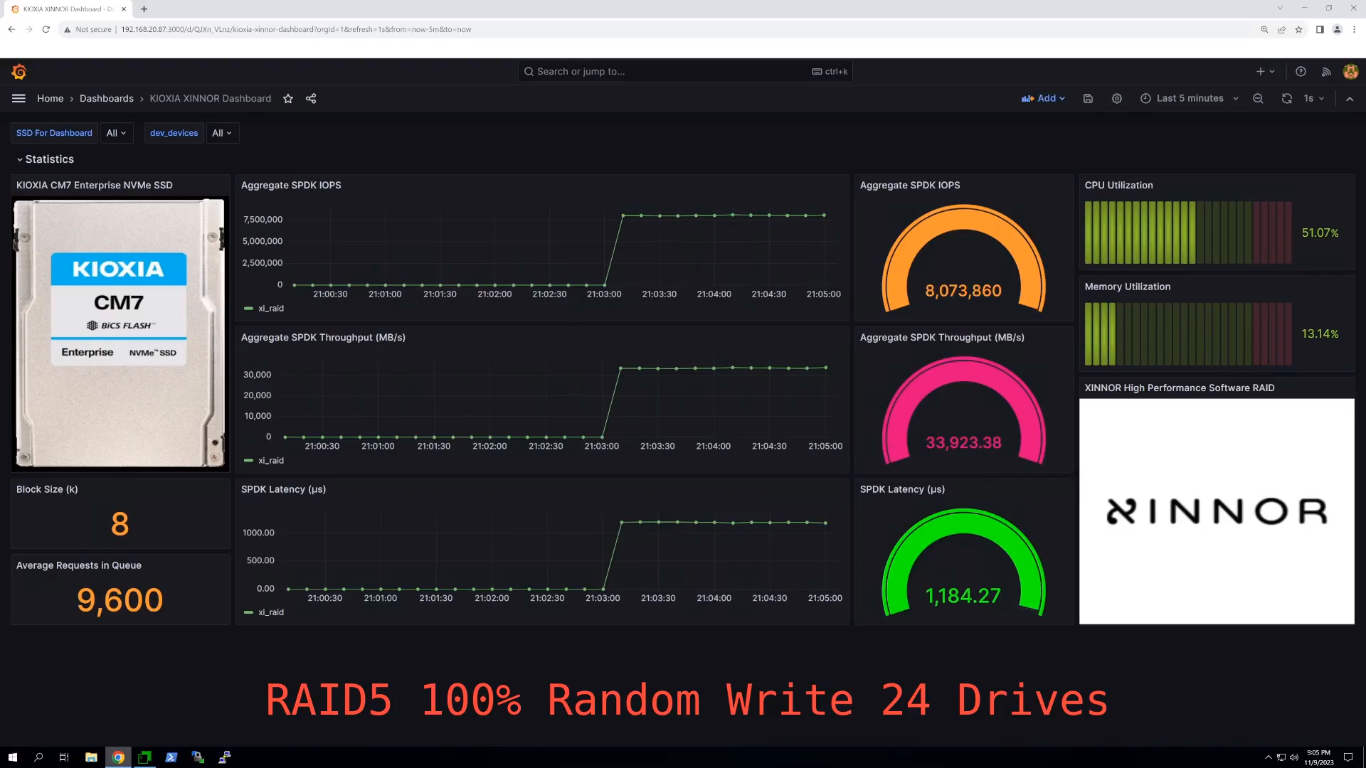 Xinnor также проверила работу в деградированном режиме, когда из массива RAID 5 «выпадает» один накопитель. Даже в этом случае производительность остаётся достаточно высокой: более 34 млн и 6 млн IOPS при произвольных чтении и записи соответственно, что эквивалентно 52 % и 75 % от нормальной производительности. При последовательных операциях доступа Xinnor зафиксировала производительность выше 70 % от нормальной. 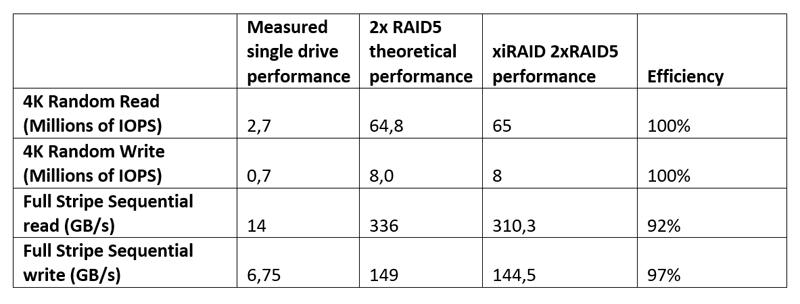 Заодно Xinnor также протестировала ту же систему, создав 2 группы RAID 6 (2 × 10 + 2). При чтении производительность была сравнима с RAID 5: 64 млн IOPS и 310 Гбайт/с. При записи производительность была ниже: 5,2 млн IOPS и 128 Гбайт/с. Впрочем, по словам Xinnor, xiRAID быстрее, чем любое другое альтернативное решение RAID.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 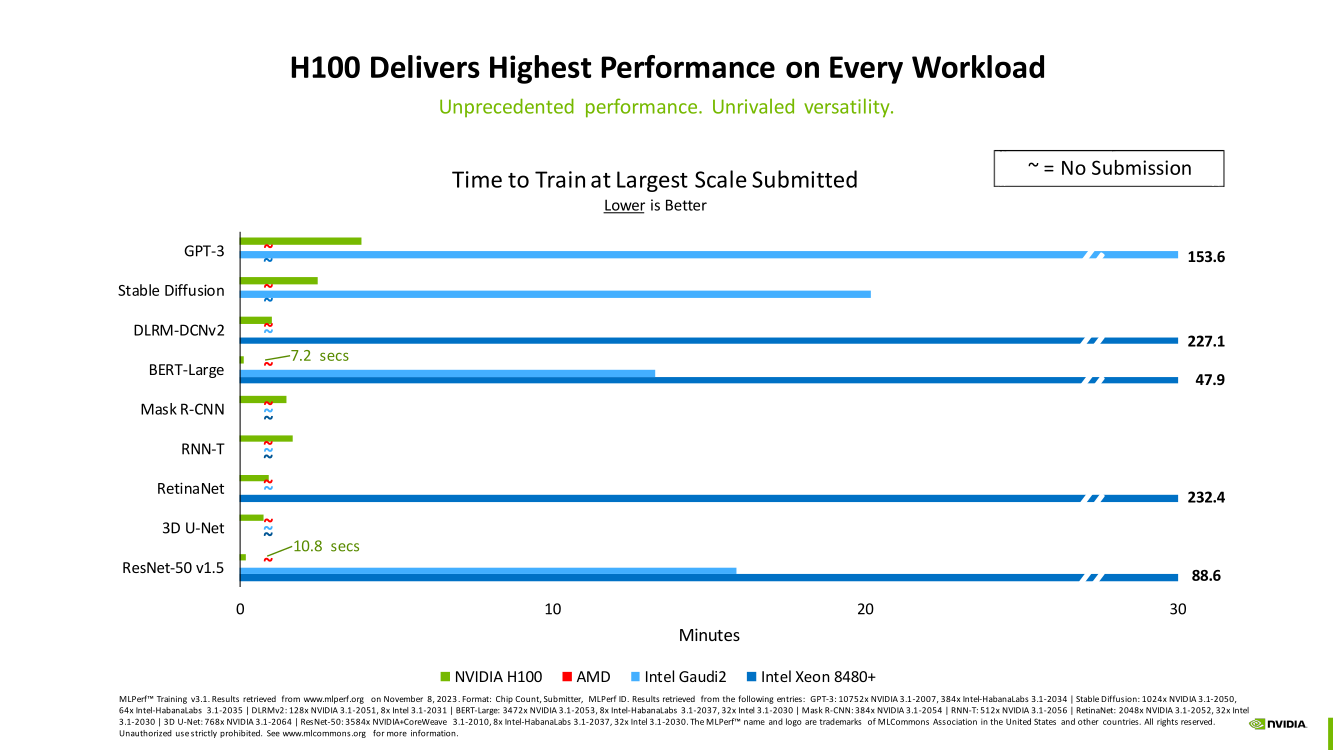 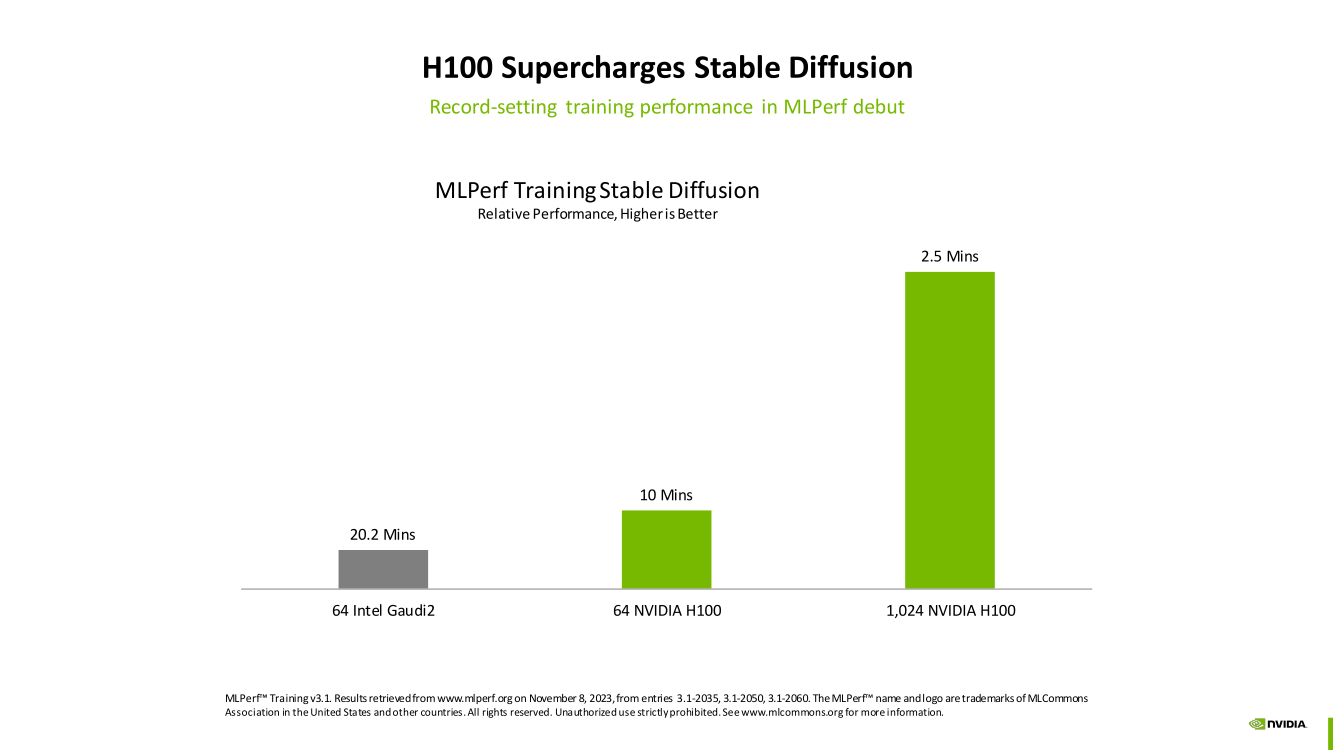 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 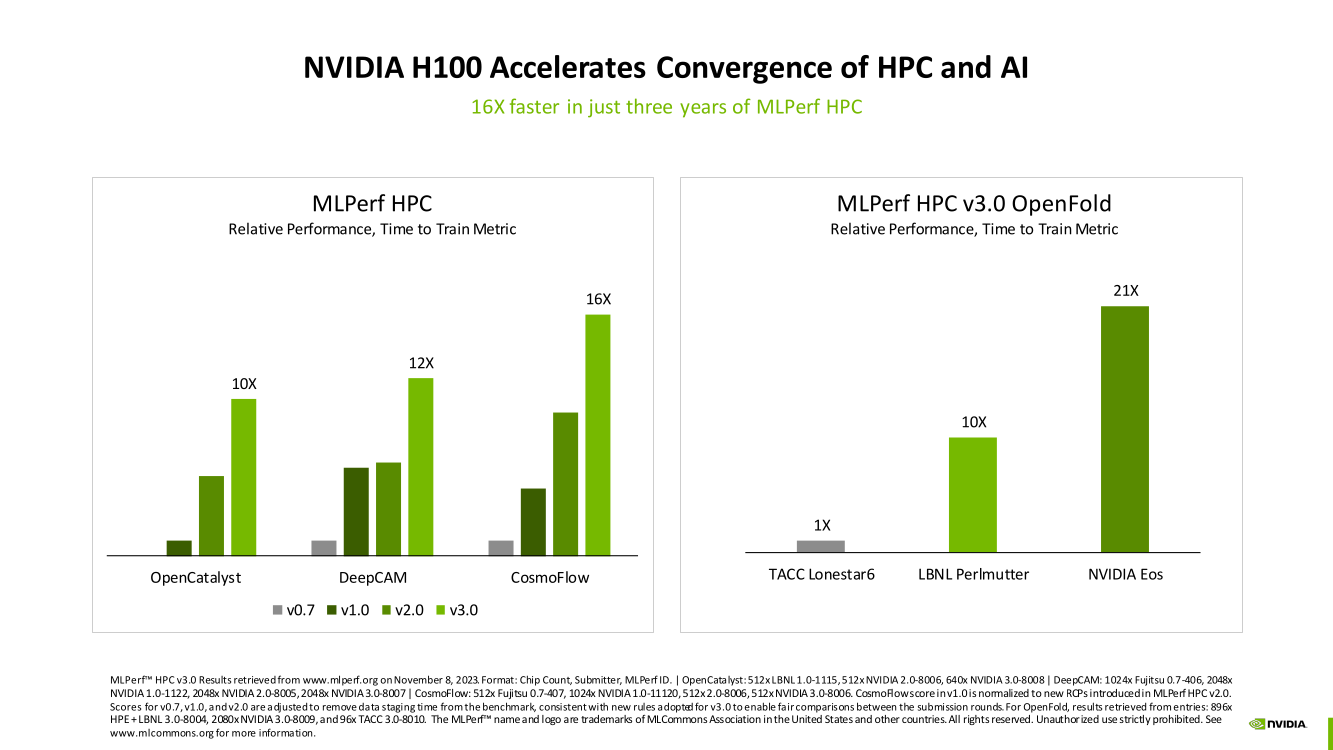
25.10.2023 [11:49], Сергей Карасёв
Экзафлопсный суперкомпьютер Frontier назван лучшим изобретением 2023 года по версии TimeЕжегодно американский журнал Time публикует список из лучших изобретений человечества в самых разных сферах. В нынешнем году в рейтинг вошли 200 продуктов и технологий, которые сгруппированы более чем в 35 категорий. Это, в частности, ПО, связь, виртуальная и дополненная реальность, ИИ, потребительская электроника, чистая энергии, здравоохранение, безопасность, робототехника и многое другое. Одним из направлений являются экспериментальные системы и устройства. В данной категории победителем назван вычислительный комплекс Frontier — самый мощный суперкомпьютер 2023 года. Исследователи уже используют его для самых разных целей: от изучения чёрных дыр до моделирования климата. «Специалисты сравнивают это с эквивалентом высадки на Луну с точки зрения инженерных достижений. Это больше, чем чудо. Это статистическая невозможность», — сказал Ник Дюбе (Nic Dubé), руководитель проекта в HPE. 
Источник изображения: ORNL Система Frontier, созданная специалистами HPE, установлена в Национальной лаборатории Окриджа (ORNL) Министерства энергетики США. Она занимает первое место в рейтинге TOP500 с производительностью 1,194 Эфлопс. В составе системы применяются процессоры AMD EPYC Milan, ускорители Instinct MI250X и интерконнект Cray Slingshot. В общей сложности задействованы 8 699 904 вычислительных ядра. Теоретическое пиковое быстродействие достигает 1,680 Эфлопс.
11.10.2023 [15:43], Сергей Карасёв
Nokia установила новый рекорд скорости при трансокеанской передаче данных — 800 Гбит/с на одной длине волныИсследователи Nokia Bell Labs установили новый мировой рекорд скорости передачи данных через трансокеанскую оптическую линию связи. Инженеры смогли достичь 800 Гбит/с на расстоянии 7865 км при использовании одной длины волны. Названная дистанция, как отмечается, в два раза больше расстояния, которое обеспечивает современное оборудование при работе с указанной пропускной способностью. Значение примерно равно географическому расстоянию между Сиэтлом и Токио, т.е. новая технология позволит эффективно связать континенты 800G-каналами. Исследователи Nokia Bell Labs установили рекорд при использовании испытательного стенда оптических коммуникаций в Париже-Сакле (Франция). Кроме того, специалисты Nokia Bell Labs совместно с сотрудниками дочерней компании Nokia Alcatel Submarine Networks (ASN) показали ещё один рекорд. Они продемонстрировали пропускную способность в 41 Тбит/с на расстоянии 291 км через систему передачи данных в C-диапазоне без повторителей. Такие каналы обычно используются для соединения островов и морских платформ друг с другом и с материком. Предыдущий рекорд для подобных систем — 35 Тбит/с на том же расстоянии. 
Источник изображения: pixabay.com Оба достижения стали возможными благодаря повышению бодрейта. В случае трансокеанских систем связи такое увеличение скорости передачи данных позволит, к примеру, удвоить протяжённость трансокеанских каналов при сохранении прежней пропускной способности, а на коротких расстояних снизить количество трансиверов при увеличении ёмкости без задействования дополнительных частотных диапазанов.
27.06.2023 [19:00], Владимир Мироненко
NVIDIA похвасталась рекордами H100 в новом бенчмарке MLPerf для генеративного ИИNVIDIA сообщила, что во всех восьми ИИ-бенчмарках MLPerf Training v3.0 её ускорители H100 установили новые рекорды, причём как по отдельности, так и в составе кластеров. В частности, коммерчески доступный кластер из 3584 ускорителей H100, созданным стартапом Inflection AI и облаком CoreWeave, смог завершить обучение ИИ-модели GPT-3 менее чем за 11 минут. Компания Inflection AI, основанная в 2022 году, использовала возможности решений NVIDIA для создания продвинутой большой языкой модели (LLM) для своего первого проекта под названием Pi. Компания планирует выступать в качестве ИИ-студии, создавая персонализированные ИИ, с которыми пользователи могли бы взаимодействовать простыми и естественными способомами. Inflection AI намерена в сотрудничестве с CoreWeave создать один из крупнейших в мире ИИ-кластеров на базе ускорителей NVIDIA. «Сегодня наши клиенты массово создают современные генеративные ИИ и LLM благодаря тысячам ускорителей H100, объединённых быстрыми сетями InfiniBand с малой задержкой, — сообщил Брайан Вентуро (Brian Venturo), соучредитель и технический директор CoreWeave. — Наша совместная с NVIDIA заявка MLPerf наглядно демонстрирует их высокую производительность». Отдельно подчёркивается, что благодаря NVIDIA Quantum-2 InfiniBand облачный кластер CoreWeave обеспечил такую же производительность, что и локальный ИИ-суперкомпьютер NVIDIA. 
Источник изображений: NVIDIA NVIDIA отметила, что H100 показали высочайшую производительность во всех тестах MLPerf, включая LLM, рекомендательные системы, компьютерное зрение, обработка медицинских изображений и распознавание речи. «Это были единственные чипы, которые прошли все восемь тестов, продемонстрировав универсальность ИИ-платформы NVIDIA» — сообщила компания. А благодаря оптимизации всего стека NVIDIA удалось добиться в тесте LLM практически линейного роста производительности при увеличении количества ускорителей с сотен до тысяч. Отдельно компания напомнила об энергоэффективности H100. 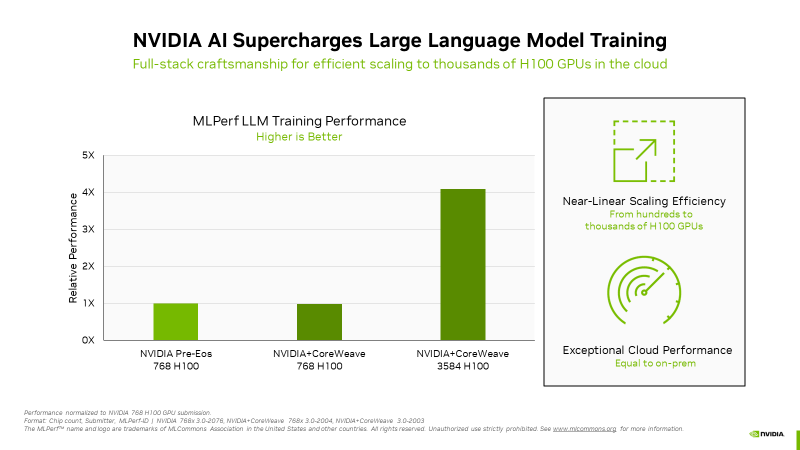 Также сообщается, что обновлённый бенчмарк MLPerf для рекомендательных систем использует больший набор данных и более современную модель, что позволяет лучше отразить проблемы, с которыми сталкиваются провайдеры облачных услуг. NVIDIA была единственной компанией, представившей результаты расширенного теста. Также компания представила результаты MLPerf для платформ L4 и Jetson. Ну а в следующем раунде MLPerf стоит ждать появления NVIDIA Grace Hopper. 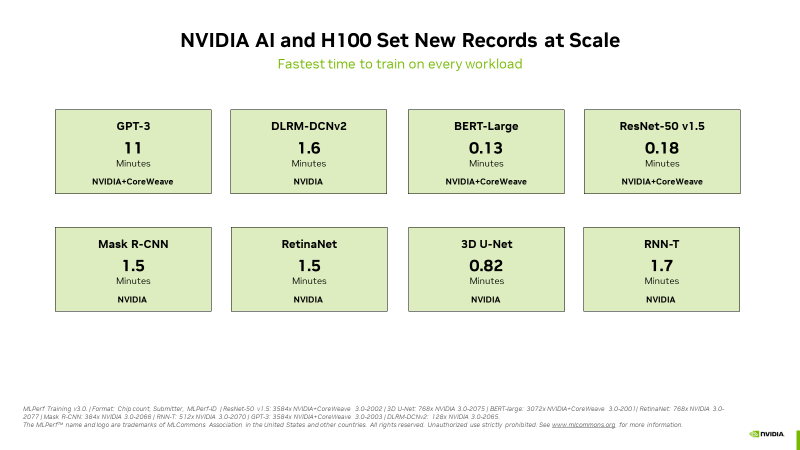 В текущем раунде результаты тестов с использованием платформы NVIDIA представили десяток компаний. Заявки поступили от крупных производителей систем, включая ASUS, Dell Technologies, GIGABYTE, Lenovo и QCT. Более 30 замеров было сделано на ускорителях H100. NVIDIA отметила прозрачность и объективность тестов, поэтому пользователи могут полностью полагаться на результаты MLPerf для принятия решения о покупке систем.
01.05.2023 [17:33], Сергей Карасёв
Запоздалый рекорд: СХД CECT с Optane PMem возглавило рейтинг SPC-1 по соотношению цена/производительностьСистема хранения данных китайской CECT (China Electronics Cloud Technology Company), по сообщению ресурса Blocks & Files, возглавила рейтинг теста производительности SPC-1 (Storage Performance Council) по соотношению цена/производительность. Бенчмарк SPC-1 оценивает производительность СХД в рабочих нагрузках корпоративного класса со случайным доступом к данным, которые могут быть сжаты и/или дедуплицированы. При этом выполняемые операции максимально приближены к рабочим нагрузкам на предприятии — это не просто синтетические тесты, которые часто отдалены от реального положения дел. В последние годы западные компании отказались от SPC-1, поскольку создание таких СХД ради установки одних только рекордов слишком дорого, так что в тесте в основном доминировали китайские поставщики хранилищ, такие как Huawei и Inspur. И вот теперь в рейтинг ворвалась ещё одна китайская фирма — CECT, система которой показал результат в 10 000 690 SPC IOPS при стоимости всего в $1 658 233. 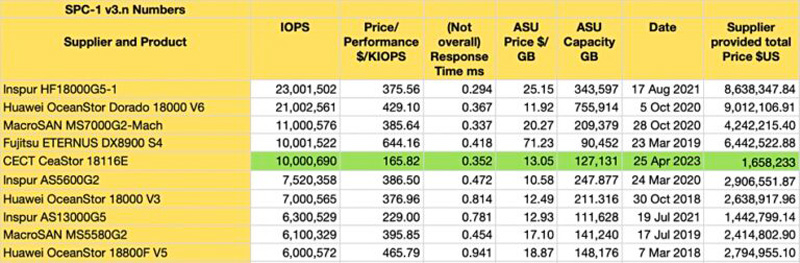
Источник изображения: Blocks & Files Для сравнения: в 2020 году СХД Inspur AS5600G класса all-flash продемонстрировала показатель в 7 520 358 IOPS при цене в $2,9 млн. А гибридный массив Fujitsu ETERNUS DX8900 S4 на базе HDD и SSD смог обеспечить 10 001 522 IOPS в 2019 году при цене в $6,4 млн. 
Источник: www.dostor.com Хранилище CECT объединяет 240 модулей Optane PMem 200 на 256 Гбайт и 180 твердотельных накопителей Intel DC P4610 NVMe ёмкостью 1,6 Тбайт в составе 30 узлов CeaStor 18116E. Суммарная вместимость системы составляет 349 440 Гбайт. При этом устройства Optane применяются для хранения метаданных, а NVMe SSD — для записи обычной информации. Результат впечатляющий и показывающий, на что в реальности способна память Optane. Однако рекорд оказался запоздалым — Intel отказалась от развития 3D XPoint, а последнее поколение модулей Optane PMem 300 (Crow Pass) хоть и совместимо с процессорами Xeon Sapphire Rapids и Emerald Rapids, массово использоваться уже точно не будет.
30.05.2022 [10:00], Игорь Осколков
Июньский TOP500: есть экзафлопс!59-я редакция TOP500, публичного рейтинга самых производительных суперкомпьютеров мира, стала наиболее знаменательной за последние 14 лет, поскольку официально был преодолён экзафлопсный барьер. Путь от петафлопса оказался долгим — первой петафлопсной системой стал суперкомпьютер IBM Roadrunner, и произошло это аж в 2008 году. Но минимальным порогом для попадания в TOP500 эта отметка стала только в 2019 году. Как и было обещано, официально и публично отметку в 1 Эфлопс в бенчмарке HPL на FP64-вычислениях первым преодолел суперкомпьютер Frontier — его устоявшаяся производительность составила 1,102 Эфлопс при теоретическом пике в 1,686 Эфлопс. Система на платформе HPE Cray EX235a использует оптимизированные 64-ядерные процессоры AMD EPYC Milan (2 ГГц), ускорители AMD Instinct MI250X и фирменный интерконнект Slingshot 11-го поколения. Система имеет суммарно 8 730 112 ядер, потребляет 21,1 МВт и выдаёт 52,23 Гфлопс/Вт, что делает её второй по энергоэффективности в мире. 
Суперкомпьютер Frontier (Фото: AMD) Впрочем, первое место в Green500 по данному показателю всё равно занимает тестовый кластер в составе всё того же Frontier: 120 832 ядра, 19,2 Пфлопс, 309 кВт, 62,68 Гфлопс/Вт. Третье и четвёртое места достались европейским машинам LUMI и Adastra, новичкам TOP500, которые по «железу» идентичны Frontier, но значительно меньше. Да и разница в Гфлопс/Вт между ними минимальна. Скопом они сместили предыдущего лидера — экзотичную японскую систему MN-3 от Preferred Networks. Японская система Fugaku, лидер по производительности в течение двух последних лет, сместилась на второе место TOP500. Третье место у финской системы LUMI с показателем производительности 151,9 Пфлопс — обратите внимание, насколько велик разрыв в первой тройке машин. Наконец, в Топ-10 последнее место занял новичок Adastra (46,1 Пфлопс), который расположен во Франции. 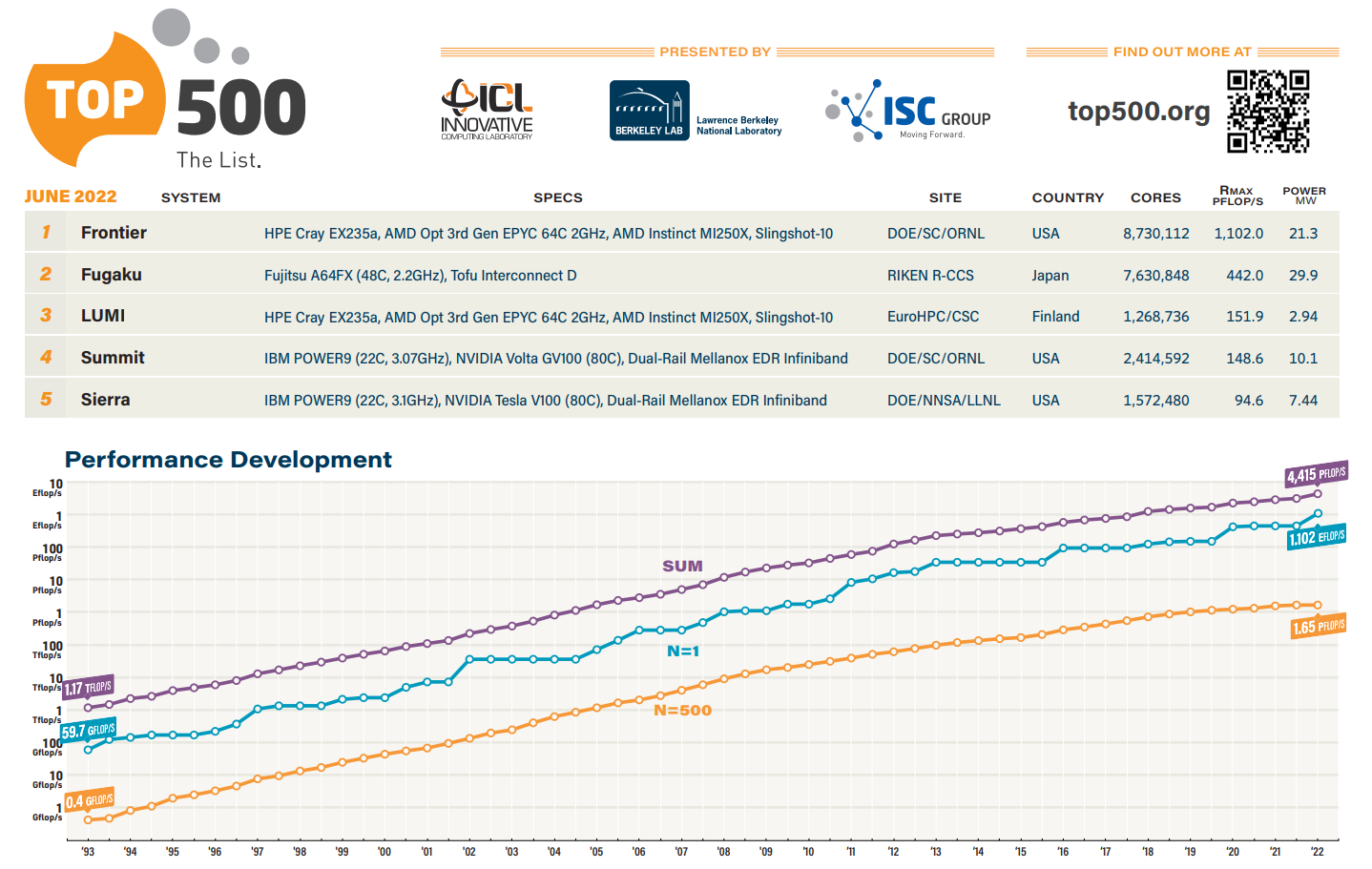
Источник: TOP500 В бенчмарке HPCG всё ещё лидирует Fugaku (16 Пфлопс), но, судя по всему, только потому, что для Frontier данных пока нет. Ну и потому, что результат суперкомпьютера LUMI, который почти на порядок медленнее Frontier, в HPCG составляет 1,94 Пфлопс. Наконец, в HPL-AI Frontier также отобрал первенство у Fugaku — 6,86 Эфлопс в вычислениях смешанной точности против 2 Эфлопс. В общем, у Frontier полная победа по всем фронтам, и эту машину можно назвать не только самой быстрой в мире, но первой по-настоящему экзафлопсной системой. Если, конечно, не учитывать неофициальные результаты OceanLight и Tianhe-3 из Поднебесной, которые в TOP500 никто не заявил. Число китайских систем в нынешнем рейтинге осталось прежним (173 шт.), тогда как США «ужались» со 150 до 127 шт. Российских систем в списке всё так же семь. Лидерами по числу поставленных систем остаются Lenovo, HPE и Inspur, а по их суммарной производительности — HPE, Fujitsu и Lenovo. С другой стороны, массовых изменений и не было — в нынешнем списке всего около сорока новых систем. 
Источник: TOP500 Однако нельзя не отметить явный прогресс AMD — да, чуть больше трёх четвертей машин из списка используют процессоры Intel, но AMD удалось за полгода отъесть около 4 %. При этом AMD EPYC Milan присутствует в более чем трёх десятках систем, а доля Intel Xeon Ice Lake-SP вдвое меньше, хотя эти процессоры появились практически одновременно. Ускорители ожидаемо стали использовать больше — они применяются в 170 системах (было 150). Подавляющее большинство приходится на решения NVIDIA разных поколений, но и для новых Instinct MI250X нашлось место в восьми машинах. Ну а в области интерконнекта Infiniband потихоньку догоняет Ethernet: 226 машин против 196 + ещё 40 с Omni-Path + редкие проприетарные решения. |
|

