Материалы по тегу: llm
|
25.04.2023 [22:53], Владимир Мироненко
NVIDIA NeMo Guardrails избавит ИИ-боты от галлюцинаций и отклонений от заданной темыNVIDIA представила решение NeMo Guardrails с открытым кодом, призванное обеспечить безопасность приложений на основе ИИ — избавить ИИ-боты от так называемых галлюцинаций (ложных утверждений), оградить от обсуждения запретных тем и высказывания токсичных выражений, а также запретить выполнение нежелательных действий. NVIDIA NeMo Guardrails предназначен для работы со всеми большими языковыми моделями (LLM), такими как ChatGPT от OpenAI. Решение позволяет разработчикам настраивать приложения на базе LLM, чтобы те были безопасными и оставались в сфере компетенции компании. NeMo Guardrails работает как промежуточный слой пользователем и LLM или другим ИИ-инструментом и предотвращает выдачу неверных результатов или подсказок. 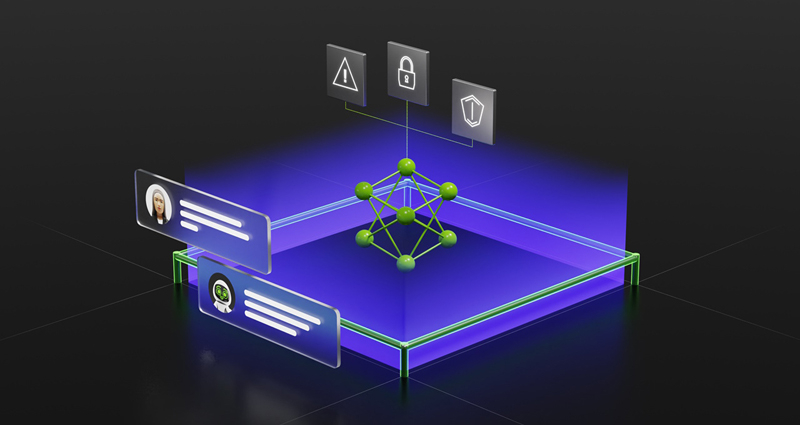
Источник изображений: NVIDIA NeMo Guardrails позволяет разработчикам устанавливать три типа границ:
 NVIDIA включила NeMo Guardrails в платформу NVIDIA NeMo, предоставляющую необходимые инструменты для обучения и настройки языковых моделей с использованием собственных данных компании. Значительная часть инструментария NeMo уже доступна на GitHub. Предприятия также могут получить его в виде полного и поддерживаемого пакета, входящего в состав платформы NVIDIA AI Enterprise.
19.04.2023 [14:33], Владимир Мироненко
The Information: Microsoft с 2019 года работает над собственными ИИ-чипами, но заменой ускорителей NVIDIA они пока не станутMicrosoft уже длительное время работает над созданием собственных ИИ-чипов, которые позволят снизить затраты на обучение генеративных моделей ИИ, подобных той, что используется в чат-боте ChatGPT компании OpenAI LP, сообщил ресурс The Information. По данным источников ресурса, по меньшей мере с 2019 года Microsoft работает над новым 5-нм чипом под кодовым названием Athena. Более того, небольшая группа сотрудников Microsoft и OpenAI уже тестирует производительность новых чипов на больших языковых моделях, таких как GPT-4. Таким образом, Microsoft собирается присоединиться к гиперскейлерам, уже создавшим свои ИИ-ускорители. Так, Google создала уже не одно поколение TPU, а у AWS есть сразу и Trainium, и Inferentia. Meta✴, как сообщается, тоже разрабатывает собственные чипы, но пока активно сотрудничает NVIDIA, лидером рынка ИИ-ускорителей. Последняя построила для Meta✴ ИИ-суперкомпьютер RSC, но самой Meta✴ этого мало, поэтому она будет использовать облачные ИИ-кластеры Microsoft Azure. А Azure, как считается, является одним из крупнейших потребителей чипов NVIDIA — сейчас компании вместе создают ещё один облачный ИИ-суперкомпьютер. 
Источник: NVIDIA Предполагается, что наличие собственных ИИ-чипов позволяет заключить с NVIDIA более выгодные сделки на поставку её ИИ-ускорителей. «Microsoft хочет использовать большие языковые модели во всех своих приложениях, включая Bing, [Microsoft] 365 и GitHub, — сказал ресурсу The Information главный аналитик SemiAnalysis Дилан Патель. — Их развёртывание в таком масштабе с использованием готового оборудования будет стоить десятки миллиардов долларов в год». При этом пока компания старается экономить на оборудовании. В начале 2023 года Microsoft инвестировала в OpenAI $10 млрд и сейчас ускоренно интегрирует технологию ИИ в свои сервисы. Однако внедрение больших языковых моделей (LLM) сдерживается из-за нехватки ускорителей NVIDIA. К тому же NVIDIA продаёт свою продукцию с большой наценкой, поэтому создание собственного ИИ-чипа позволит Microsoft сэкономить значительные суммы. По данным The Information, компания планирует выпуск нескольких поколений чипов, первое из которых должно появиться в 2024 году. Сообщается, что эти чипы пока не предназначены для замены продуктов NVIDIA, поскольку их предполагается использовать для расширения существующей инфраструктуры Microsoft.
14.04.2023 [01:42], Руслан Авдеев
Terve: самый мощный суперкомпьютер Европы позволил создать большую языковую модель для финского языка, притом культурнуюХотя генеративный ИИ активно осваивается миром, и новости о нём поступают со всех концов света, почти ничего не рассказывается об аппаратных мощностях, стоящих за обучением больших языковых моделей (LLM). Как сообщает HPC Wire, ситуацию попытался изменить IT-центр CSC, рассказав о роли европейского суперкомпьютера LUMI в создании LLM для финского языка. Без LUMI обучение модели удалось бы завершить только в 2025 году. Суперкомпьютер LUMI является самым быстрым в Европе и занимает третье место в рейтинге TOP500. LUMI помог в обучении модели TurkuNLP, создававшейся под патронажем учёных из Университета Турку, сумевших сформировать «крупнейшую языковую модель для финского языка за всю историю». Новая ИИ-модель на базе GPT-3 включает 13 млрд параметров — известно, что до TurkuNLP в рамках пилотного проекта создавались и более скромные варианты. Финскому научили и многоязыковую модель BLOOM со 176 млрд параметров. 
Дата-центр LUMI (Фото: Fade Creative) Делить машинное время пришлось со многими другими проектами, по некоторым данным, исследователи временами регистрировали производительность на уровне 75–80 % от расчётной, хотя даже такие показатели признаны неплохими. Поскольку LUMI использует ускорители AMD Instinct MI250X, на их оптимизацию кода под новое «железо» ушло немало времени. Впрочем, группа учёных получила поддержку от команды LUMI User Support Team, AMD и Hugging Face. 
Источник изображения: LUMI Ещё одной нетривиальной задачей стал поиск материалов на финском языке для тренировки модели. Финны — довольно немногочисленный народ, поэтому исходного «сырья» для обучения в мире оцифровано относительно немного. Тексты в электронном виде добывались из всех возможных источников, при этом перед учёными стояла задача отфильтровать контент с ругательствами или материалами, разжигающими ненависть. По данным учёных, им удалось вдвое сократить число спонтанной ругани в сравнении с предыдущими моделями благодаря качественным материалам, использовавшимся для обучения. Перед обучением также пришлось вычистить все персональные данные. Модель опубликована в Сети, но команда уже получила грант на 2 млн GPU-часов в рамках проекта LUMI Extreme Scale, поэтому исследования продолжатся.
13.04.2023 [21:03], Владимир Мироненко
Databricks выпустила полностью бесплатную и открытую ИИ-модель Dolly для создания аналогов чат-бота ChatGPTПоставщик решений для аналитики больших данных и машинного обучения Databricks (США) объявил о выходе Dolly 2.0, модели генеративного искусственного интеллекта (ИИ) следующего поколения с открытым исходным кодом, которая имеет сходные с ChatGPT (OpenAI) возможности. Dolly 2.0, как и предшественница Dolly, вышедшая пару недель назад, использует меньший набор данных, чем имеется у большинства больших языковых моделей (LLM). Dolly имела 6 млрд параметров, а у Dolly 2.0 их вдвое больше — 12 млрд. Для сравнения, у GPT-3 — 175 млрд параметров. Сообщается, что Dolly 2.0 была построена на высококачественном наборе данных. Отличительной особенностью новых моделей генеративного ИИ является возможность использовать собственный набор данных обучения для создания связных предложений и ответов на вопросы пользователей. И Dolly 2.0 может делать это, даже несмотря на намного меньший объём исходных данных, чем у моделей OpenAI. Это, в свою очередь, позволяет использовать модель на собственных серверах без необходимости делиться данными со сторонними организациями. Источник: Databricks «Мы считаем, что такие модели, как Dolly, помогут демократизировать LLM, превратив их из того, что могут себе позволить очень немногие компании, в товар, которым может владеть каждая компания и который можно настраивать для улучшения своих продуктов», — заявила Databricks. Руководитель Databricks в комментарии изданию SiliconANGLE подчеркнул, что предприятия «могут монетизировать Dolly 2.0». 
Источник: Databricks Databricks предлагает Dolly 2.0 под лицензией Creative Commons, с полностью открытыми исходным кодом и набором данных для обучения databricks-dolly-15k, который содержит 15 тыс. высококачественных пар запросов и ответов, созданных человеком. Всё это можно свободно использовать, изменять и дополнять, а также задействовать в коммерческих проектах, ничего никому не платя. Исследователи и разработчики могут получить доступ к Dolly 2.0 на Hugging Face и GitHub. Как утверждает Databricks, в настоящее время Dolly 2.0 является единственной моделью, которая не имеет лицензионных ограничений. Другие модели, включая Alpaca, Koala, GPT4All и Vicuna, нельзя использовать в коммерческих целях из-за использования обучающих данных, предоставленных им с определёнными условиями. Исходный вариант Dolly был обучен на данных Stanford Alpaca с использованием API OpenAI, так что её нельзя было использовать в коммерческих целях, так как в этом случае лицензии запрещают создавать конкурирующие модели. Поэтому Databricks решила создать собственную модель, используя только ответы её сотрудников. Задания для них включали, например, просьбы высказаться на тему «Почему людям нравятся комедии?», обобщить информации из Википедии, написать любовные письма, стихов и даже песни.
07.04.2023 [19:49], Владимир Мироненко
Bloomberg создала собственную ИИ-модель BloombergGPT, которая меньше ChatGPT, но эффективнее при использовании в финансовых операцияхФинансовая фирма Bloomberg решила доказать, что существуют более разумные способы тонкой настройки ИИ-приложений, не имеющих проблем с соблюдением принципов этики или с безопасностью, с которыми сталкиваются при использовании, например, ChatGPT. Bloomberg выпустила собственную большую языковую модель BloombergGPT с 50 млрд параметров, предназначенную для финансовых приложений. Она меньше ChatGPT, основанной на усовершенствованной версии GPT-3 со 175 млрд параметров. Но, как утверждают исследователи из Bloomberg и Johns Hopkins, малые модели — то что нужно для предметно-ориентированных приложений. Bloomberg заявила, что не будет открывать BloombergGPT из-за риска утечки конфиденциальных данных, например, из базы FINPILE, использовавшейся для обучения. 
Источник изображения: Pixabay По словам исследователей, BloombergGPT функционально схожа с ChatGPT, но предлагает большую точность, чем сопоставимые модели с бо́льшим количеством параметров. Они также утверждают, что общие модели не могут заменить предметно-ориентированные. Малые модели отличаются большей точностью результатов и могут обучаться значительно быстрее, чем универсальные модели, такие как GPT-3. К тому же для них требуется меньше вычислительных ресурсов. Bloomberg потратила около 1,3 млн GPU-часов на обучение BloombergGPT на ускорителях NVIDIA A100 в облаке AWS. Обучение проводилось на 64 кластерах ускорителей, в каждом из которых было по восемь A100 (40 Гбайт), объединённых NVswitch. Для связи использовались 400G-подключения посредством AWS Elastic Fabric и NVIDIA GPUDirect Storage, а для хранения данных была задействована распределённая параллельная файловая система Lustre с поддержкой скорости чтения и записи до 1000 Мбайт/с. 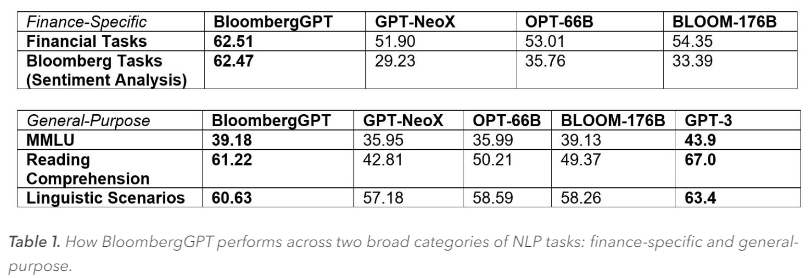
Источник: Bloomberg Общего объёма памяти всех ускорителей оказалось недостаточно, поэтому Bloomberg произвела оптимизацию для обучения модели: разбиение на отдельные этапы, использование вычислений смешанной точности (BF16/FP32) и т.д. «После экспериментов с различными технологиями мы достигли [производительности] в среднем 102 Тфлопс, а каждый этап тренировки занимал 32,5 с», — сообщили исследователи. Bloomberg задействовала чуть больше половины (54 %) имеющегося у неё набора данных — 363 млрд документов (с 2007 года) из внутренней базы данных Bloomberg. Остальные 345 млрд документов были получены из общедоступных пресс-релизов, новостей Bloomberg, публичных документов и даже Википедии. Документы получили название «токен». Исследователи стремились, чтобы обучающие последовательности имели длину 2048 токенов, чтобы поддерживать максимально высокий уровень использования ускорителей.
29.03.2023 [22:27], Владимир Мироненко
Cerebras выпустила семь GPT-моделей для генеративного ИИ под открытой лицензией, обучив их на собственных чипахАмериканский производитель ИИ-комплексов Cerebras Systems объявил о выходе 7 больших языковых моделей (LLM) на базе технологии Generative Pre-trained Transformer (GPT) для генеративного ИИ. Это первые публичные LLM, которые прошли обучение с помощью систем CS-2 в суперкластере Cerebras Andromeda на базе фирменных ИИ-чипов Cerebras WSE-2. Другими словами, это одни из первых больших языковых моделей, которые были обучены без использования систем на основе ускорителей, в частности, NVIDIA. Серия из семи открытых моделей GPT со 111, 256, 590 млн, а также 1,3, 2,7, 6,7 и 13 млрпд параметров соответственно доступны на GitHub и Hugging Face. Обучение таких моделей обычно занимает много месяцев, но Cerebras утверждает, что ей удалось справиться всего за несколько недель благодаря Andromeda. Более того, Cerebas удалось снизить стоимость обучения, а также упростить масштабирование без модификации кода и самой модели, что часто требуется при обучении с использованием кластеров традиционных ускорителей. При этом энергоэффективность всего процесса Cerebras смогла повысить. 
Источник изображения: Cerebras Systems Cerebras отметила, что не только предлагает модели, но и инструкции по их обучению под лицензией Apache 2.0. «Мы считаем, что для того, чтобы LLM были открытой и доступной технологией, важно иметь доступ к современным моделям, которые являются открытыми, воспроизводимыми и бесплатными как для исследовательских, так и для коммерческих приложений», — заявила Cerebras. 
Источник изображения: Cerebras Systems Компания заявила, что это первый случай, когда весь набор моделей GPT, обученных с использованием самых современных методов повышения эффективности, стал общедоступным. Поскольку большие языковые модели Cerebras имеют открытый исходный код, их можно использовать как в исследовательских, так и в коммерческих целях. А предварительно обученную модель можно с минимум затрат дообучить под конкретную задачу на пользовательских данных. 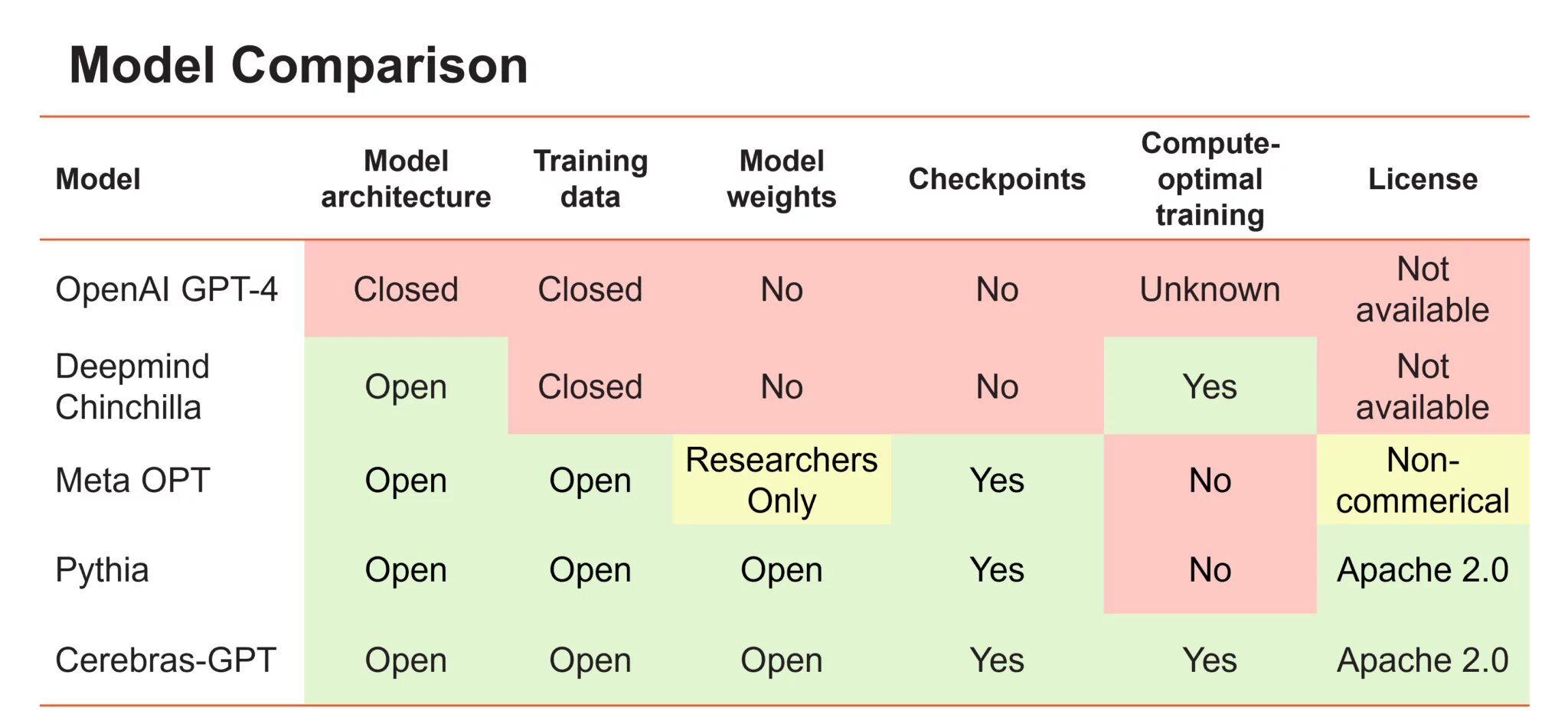
Источник изображения: Cerebras Systems Cerebras отметила, что быстрый рост генеративного ИИ при лидерстве ChatGPT от OpenAI спровоцировал обострение состязания среди производителей ИИ-оборудования для ИИ, взявшихся за создание более мощных и специализированных чипов. Хотя многие из них обещали создать альтернативу ускорителям NVIDIA, пока никому из них не удалось продемонстрировать способность обучать крупномасштабные модели и желание раскрывать наработки под открытыми лицензиями. По словам Cerebras, в связи с конкуренцией доступ к ИИ становится все более закрытым. Так, GPT4 была выпущена без детальной информации об архитектуре модели, параметрах, данных, оборудовании и т.д. Компании создают большие модели с использованием закрытых наборов данных и предлагают выходные данные моделей только через доступ к API.
27.03.2023 [12:19], Сергей Карасёв
Российская ИИ-модель SistemmaGPT поможет в решении бизнес-задачIT-компания Sistemma из России сообщила о создании ИИ-модели SistemmaGPT — отечественного аналога нашумевшего чат-бота ChatGPT. В основу решения, как сообщается, положены собственные разработки Sistemma, а также результаты исследований Стэнфордского университета (США). Модель SistemmaGPT ориентирована прежде всего на бизнес-сектор. ИИ адаптируется к предпочтениям пользователя и учитывает контекст общения. Система способна решать различные задачи: это работа с текстами и программным кодом, поиск необходимой информации, глубокий анализ данных, генерация пошаговых инструкций, творческие задания и пр. 
Источник изображения: pixabay.com / geralt При помощи SistemmaGPT корпоративные заказчики смогут интегрировать функции ИИ в свои рабочие процессы. Модель, как утверждается, может анализировать большие объёмы данных, общаться с клиентами в формате виртуального помощника, создавать персонализированную систему рекомендаций, автоматически обрабатывать заказы и входящие звонки, отвечать на электронные письма, работать с пользователями в социальных сетях, управлять складом и др. Ожидается, что появление SistemmaGPT поможет российскому бизнесу повысить операционную эффективность, сократить издержки и, в конечном итоге, улучшить свою конкурентоспособность. «Наша команда разработчиков активно работает над интеграцией модели с изображениями и видео, что позволит решать сложные визуальные задачи, включая распознавание, анализ и подсчёт объектов», — отмечает Sistemma. |
|

