Материалы по тегу: llm
|
11.09.2023 [19:00], Сергей Карасёв
Много памяти, быстрая шина и правильное питание: гибридный суперчип GH200 Grace Hopper обогнал H100 в ИИ-бенчмарке MLPerf InferenceКомпания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM). Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров. Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт). 
Источник изображений: NVIDIA Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат. 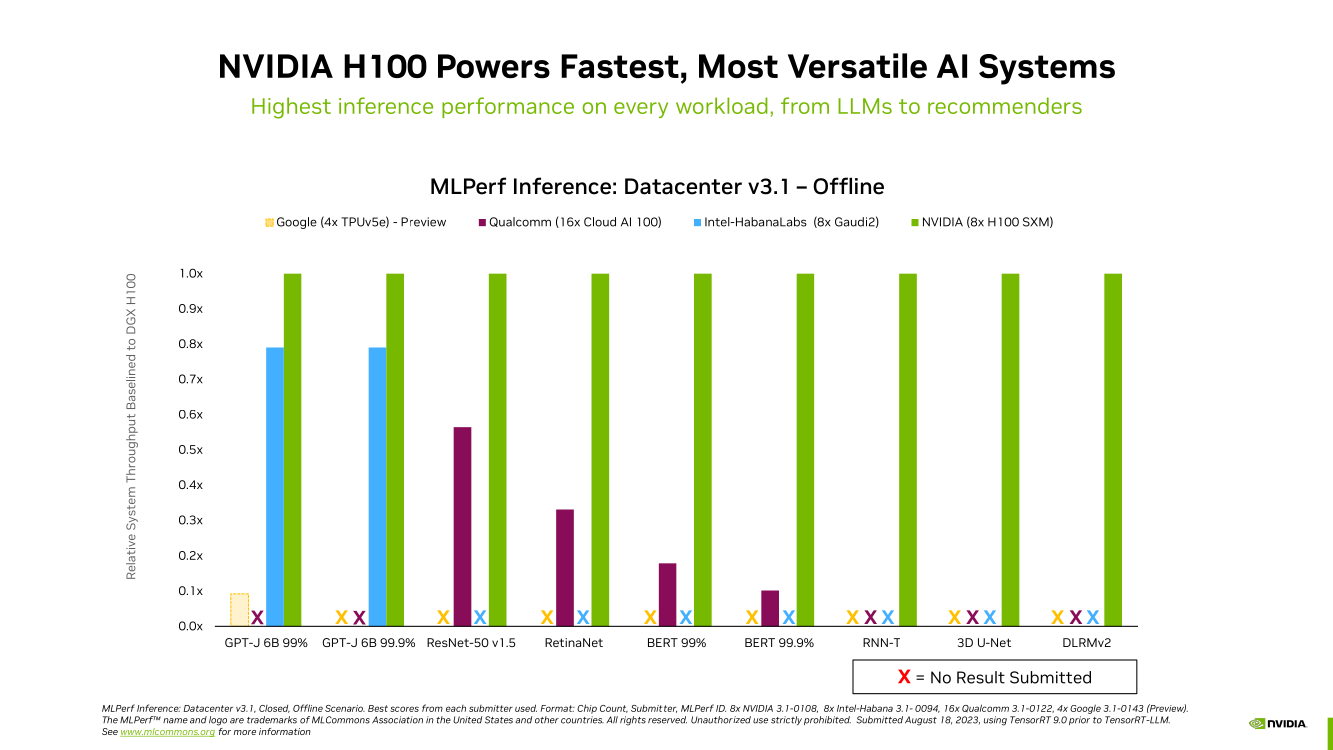 Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU. 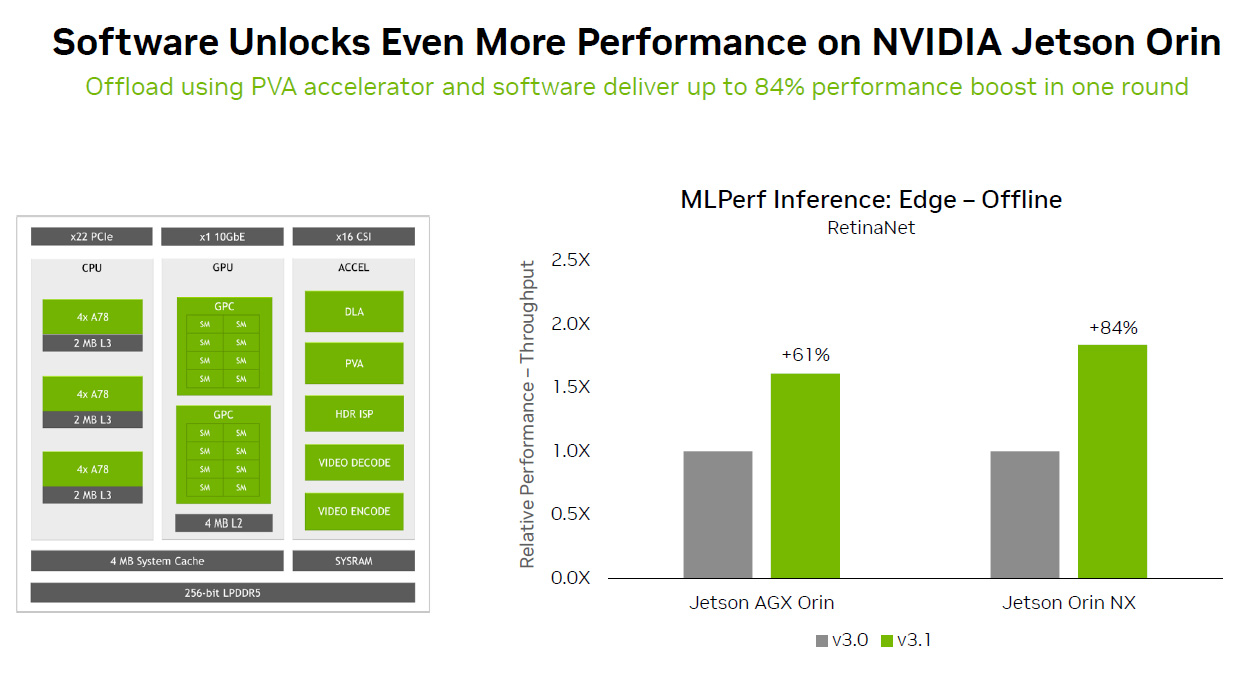 Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ. В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
09.09.2023 [14:38], Сергей Карасёв
Сила оптимизации ПО: NVIDIA вдвое ускорила исполнение языковых моделей на H100 с помощью TensorRT-LLMКомпания NVIDIA анонсировала программное обеспечение TensorRT-LLM с открытым исходным кодом, специально разработанное для ускорения исполнения больших языковых моделей (LLM). Платформа станет доступна в ближайшие недели. Отмечается, что NVIDIA тесно сотрудничает с такими компаниями, как Meta✴, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (входит в состав Databricks), OctoML, Tabnine и Together AI, для ускорения и оптимизации LLM. Однако большой размер и уникальные характеристики LLM могут затруднить их эффективное внедрение. Библиотека TensorRT-LLM как раз и призвана решить проблему. 
Источник изображений: NVIDIA ПО включает в себя компилятор глубокого обучения TensorRT, оптимизированные ядра (kernel), инструменты предварительной и постобработки, а также компоненты для повышения производительности на ускорителях NVIDIA. Платформа позволяет разработчикам экспериментировать с новыми LLM, не требуя глубоких знаний C++ или CUDA. Применяется открытый модульный API Python для определения, оптимизации и выполнения новых архитектур и внедрения усовершенствований по мере развития LLM. По оценкам NVIDIA, применение TensorRT-LLM позволяет вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). При использовании модели Llama2 прирост быстродействия по сравнению с А100 достигает 4,6x. TensorRT-LLM уже включает полностью оптимизированные версии многих популярных LLM, включая Meta✴ Llama 2, OpenAI GPT-2 и GPT-3, Falcon, Mosaic MPT, BLOOM и др. 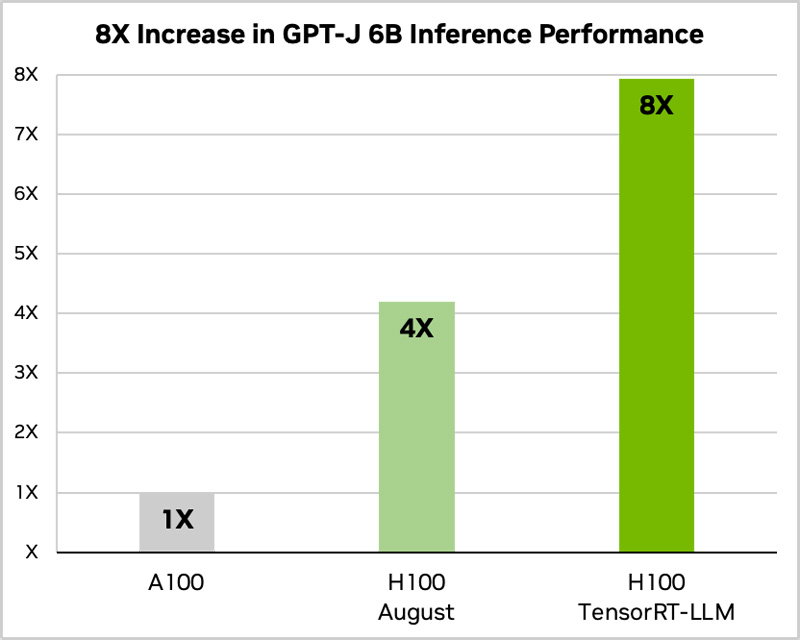 Софт TensorRT-LLM использует тензорный параллелизм — тип параллелизма моделей, при котором отдельные весовые матрицы разделяются между устройствами. При этом TensorRT-LLM автоматически распределяет нагрузка между несколькими ускорителями, связаннными посредством NVLink, или множественными узлами, объединёнными NVIDIA Quantum 2 InfiniBand. Это позволяет легко масштабировать задачи инференса с одного ускорителя до целой стойки. Для управления нагрузками TensorRT-LLM использует специальный метод планирования — пакетную обработку в реальном времени, которая позволяет асинхронно обслуживать множество мелких запросов совместно с единичными большими на одном и том же ускорителе. Эта функция доступна для всех актуальных ускорителей NVIDIA, причём именно она даёт двукратный прирост производительности инференса в случае H100. 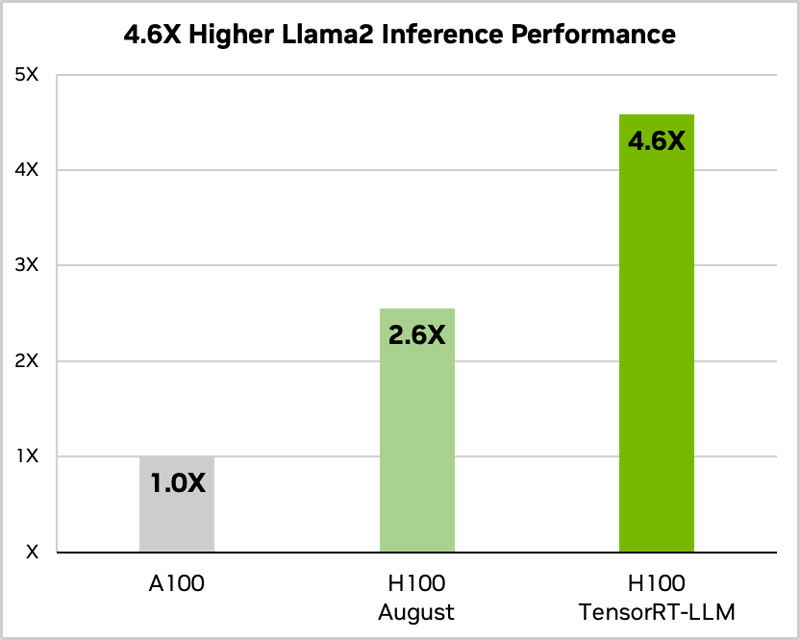 Наконец, конкретно в случае H100 библиотека активно использует возможностиTransformer Engine, позволяющего динамически привести вычисления к FP8-формату, что ускоряет и обработку и снижает потребление памяти без ухудшения точности итогового результата. Одна эта функция позволяет добиться четырёхкратного прироста быстродействия H100 в сравнении с A100.
09.09.2023 [12:10], Сергей Карасёв
Разработчик размышляющего ИИ Imbue привлёк $200 млн, в том числе от NVIDIAИсследовательская ИИ-лаборатория Imbue, по сообщению ресурса SiliconAngle, осуществила крупный раунд финансирования Series B, в ходе которого на развитие привлечено $200 млн. В результате этот стартап получил рыночную оценку в $1 млрд. Деньги предоставили NVIDIA, некоммерческая организация Astera Institute, генеральный директор Cruise LLC Кайл Фогт (Kyle Vogt), соучредитель Notion Labs Саймон Ласт (Simon Last) и ряд других инвесторов. Imbue специализируется на разработке больших языковых моделей (LLM), оптимизированных специально для рассуждений (а также формирования выводов и предсказаний). Они имеют более 100 млрд параметров. Для сравнения: Llama-2 допускает использование до 70 млрд параметров. Imbue обучает модели, применяя особые наборы данных, сформированные с прицелом именно на развитие навыков рассуждения. Тренировка осуществляется на базе кластера, включающего около 10 тыс. ускорителей NVIDIA H100. 
Изображение: Drew Dizzy Graham / Unsplash Imbue использует свои LLM в составе ряда приложений автоматизации, которые компания называет агентами. Большинство из них предназначены для автоматизации задач кодирования. Некоторые агенты используются инженерами Imbue в рамках повседневной работы. Стартап также выполняет исследования в области теоретических основ глубокого обучения. Одним из направлений работ является обучение с самоконтролем — с использованием немаркированных данных, которые не содержат вспомогательной контекстной информации.
09.09.2023 [11:27], Сергей Карасёв
NVIDIA и Reliance создадут большую языковую модель для Индии и развернут ИИ-инфраструктуру мощностью до 2 ГВтКомпании NVIDIA и Reliance Industries сообщили о заключении соглашения о сотрудничестве, которое предусматривает разработку большой языковой модели для Индии. Она будет обучена на различных языках страны и адаптирована для приложений генеративного ИИ. Кроме того, будет построена отдельная ИИ-инфраструктура мощностью до 2000 МВт. Внедрением системы займутся специалисты компании Jio. Партнёры намерены развернуть аппаратную ИИ-инфраструктуру, которая по производительности более чем на порядок превзойдёт самый мощный суперкомпьютер Индии. Для этого планируется задействовать суперчипы NVIDIA GH200 Grace Hopper, а также облачный сервис DGX Cloud. Говорится, что платформа NVIDIA станет основой ИИ-вычислений для Reliance Jio Infocomm, телекоммуникационного подразделения Reliance Industries. В рамках партнёрства Reliance будет создавать приложения и услуги на основе ИИ для примерно 450 млн клиентов Jio, а также предоставит энергоэффективную ИИ-инфраструктуру учёным, разработчикам и стартапам по всей Индии. 
Источник изображения: Reliance Industries Применять ИИ планируется в самых разных отраслях — в сельском хозяйстве, медицине, климатологии и пр. В частности, приложения нового типа помогут предсказывать циклонические штормы, а также улучшат экспертную диагностику симптомов тех или иных заболеваний. Похожий проект реализуется и с Tata Group.
08.09.2023 [17:48], Владимир Мироненко
C3 AI выпустила пакет C3 Generative AI Suite с предметно-ориентированными ИИ-инструментами, которые не галлюцинируют и дают корректные ответыC3 AI, разработчик решений для корпоративного ИИ, объявил о выходе пакета C3 Generative AI Suite, включающего 28 новых предложений в области генеративного ИИ, ориентированных на конкретные потребности различных отраслей, бизнес-процессов и корпоративных систем. Согласно заявлению C3 AI, вышедшие в марте 2023 года первоначальные модели C3 Generative AI уже используются целым рядом крупных компаний и организаций, включая Агентство по противоракетной обороне США. C3 Generative AI Suite построен на платформе C3 AI, обеспечивающей единое рабочее пространство для разработки, тестирования и развёртывания моделей ИИ. Компания отметила, что в C3 Generative AI решены проблемы безопасности и достоверности, характерные для больших языковых моделей (LLM), из-за которых не допускается их широкое коммерческое использование на предприятиях. Предложения C3 Generative AI Suite могут быть развернуты на любой облачной платформе и поддерживают широкий спектр ИИ-моделей, включая Falcon 40B, Llama 2, Flan-T5, Azure GPT-3.5, AWS Bedrock Claude 2, Google PaLM 2, OpenAI GPT-3.5 и MPT-7B. Платформа работает со структурированными и неструктурированными данными, а также может проводить оркестрацию инференса и глубокого обучения. 
Источник изображения: C3 AI По словам технического директора по продуктам компании, в дополнение к более широким отраслевым и предназначенным для отдельных случаев моделям, C3 AI также предлагает тонко настроенные LLM для конкретных задач, таких как ответы на вопросы, чат, обобщение, поиск и оркестрация. C3 AI рекомендует использовать генеративный ИИ с расширенным поиском (retrieval-augmented generative AI). Фреймворк подходит для извлечения фактов из внешней базы знаний, гарантирующий доступ модели к самой свежей информации. «Такой подход помогает нам отделить LLM от личных данных клиента и избежать многих недостатков использования ориентированного на потребителя генеративного ИИ в корпоративном контексте, таких как отсутствие прослеживаемости и галлюцинации», — сказал Кришнан. «Это позволяет генеративному ИИ C3 минимизировать галлюцинации и предоставлять полные ссылки на источники, чтобы пользователи могли проверять ответы и проводить дальнейшие исследования», — отметил он. C3 AI заявила, что её решения дают детерминированные ответы, а не случайные, и что результаты можно сразу проследить до источника. LLM закрыта брандмауэром от исходных данных, чтобы минимизировать риск утечки данных и кибератак. Компании также могут применять средства обеспечения кибербезопасности, такие как шифрование и многофакторная аутентификация, указывать в настройках, что модели работают только с принадлежащими предприятию и лицензированными данными, и обмениваться LLM с другими компаниями. Все продукты из набора C3 Generative AI Suite уже доступны для установки заказчиком. C3 AI поможет заказчику внедрить своё приложение в производство в течение 12 недель, стоимость услуги — $250 тыс. После этого клиент производит почасовую оплату за использование vCPU/vGPU со скидками за объём.
08.09.2023 [14:18], Руслан Авдеев
IBM представила серию «экономичных» языковых моделей Granite, для запуска которых достаточно одного NVIDIA V100Компания IBM представила серию больших языковых моделей (LLM) Granite в рамках ИИ-платформы watsonx. Как сообщает IBM, это не единственное пополнение watsonx — добавятся инструменты, упрощающие создание датасетов для обучения LLM, а также ПО, упрощающее адаптацию нейросетей к новым типам задач. Представленный в мае watsonx представляет собой набор инструментов, помогающий корпоративным клиентам строить генеративные ИИ-модели, а также выполнять смежные задачи вроде адаптации нейросетей под требования безопасности. Новые модели будут доступны при посредничестве компонента watsonx.ai, который уже имеет готовые шаблоны. 
Источник изображения: IBM Серия Granite включает LLM Granite.13b.instruct и Granite.13b.chat, построенные с помощью 2,4-терабайтного набора данных, подобранного специалистами компании. Модели способны составлять краткие резюме документов, «извлекать информацию» и генерировать тексты. Обе модели имеют по 13 млрд параметров. Благодаря относительной компактности, для запуска любой из них достаточно единственного ускорителя NVIDIA V100, который значительно дешевле A100 и H100. Другими словами, получить собственную нейросеть смогут даже очень небольшие компании. В IBM сообщают, что готовятся и другие модели, а watsonx.ai, помимо наработок IBM, получит Llama-2 (разработана Meta✴) и нейросеть StarCoder, предназначенную для программистов — её представили в мае ServiceNow и Hugging Face. Также watsonx.ai получил механизм генерации синтетических данных, применяемых для обучения кастомных LLM, и инструмент для адаптации параметров нейросети для того, чтобы учить её выполнять новые задачи без «перетренировки». Дополнительно стало известно, что IBM расширила возможности компонента watsonx.data для управления датасетами, предназначенными для тренировки ИИ. Сообщается, что инструмент получит новые возможности благодаря добавлению «разговорного» интерфейса. Добавятся и другие функции, например, работа с векторными базами данных.
01.09.2023 [17:35], Владимир Мироненко
Google добавит в своё облако ИИ-модели от Meta✴ и AnthropicGoogle, входящая в Alphabet, объявила о планах добавить в свою облачную платформу инструменты искусственного интеллекта (ИИ) таких компаний, как Meta✴ Platforms и Anthropic, позиционируя себя как универсальная площадка для облачных клиентов, желающих воспользоваться ИИ. При этом более половины стартапов в области генеративного ИИ, поддерживаемых венчурными фондами, включая Anthropic, Character.ai и Cohere, используют именно Google Cloud. Вскоре клиенты Google получат доступ к большой языковой модели (LLM) Llama 2 от Meta✴, а также к ИИ-чат-боту Claude 2 ИИ-стартапа Anthropic для создания с помощью корпоративных данных собственных приложений и сервисов. По словам компании, теперь клиентам Google Cloud доступно более 100 мощных моделей и инструментов ИИ. Сама Google продолжает совершенствовать свои собственные модели и инструменты ИИ. В частности LLM PaLM 2 теперь доступна на 38 языках и может лучше анализировать объёмные документы, такие как исследовательские работы, книги и юридические записки. 
Изображение: Google Заодно компания отметила, что ИИ-помощник для разработчиков Codey стал производительнее, а Imagen, приложение для преобразования текста в изображение, теперь будет выдывать более качественные результаты с возможностью настройки стиля. Кроме того, Google Cloud анонсировала функцию, которая позволит добавлять в изображение водяной знак, указывающий на то, что оно создано ИИ. По словам компании, эта функция, основанная на технологиях Google DeepMind, будет включать водяной знак на уровне пикселей, чтобы его было трудно изменить. Также компанией было объявлено о развитии продукта Duet AI для Google Workspace, доступ к которому для широкой публики появится позже в этом году. Пользователи смогут задействовать помощник с генеративным ИИ, который отвечает на запросы и помогает создавать контент в Google Docs, Sheets и Slides. По словам Google, Duet AI может делать заметки во время видеозвонков, отправлять сводки встреч, переводить субтитры на 18 языков и даже подменять пользователя на видеособраниях. Наконец, Google похвасталась, что её отраслевые модели тоже набирают популярность. Например, LLM Med-PaLM 2, адаптированная для медицинской сферы, используется Bayer Pharmaceuticals, HCA Healthcare и Meditech, а модель Sec-PaLM 2, разработанная для обеспечения кибербезопасности, используется Broadcom и Tenable.
23.08.2023 [15:06], Сергей Карасёв
Платформа VMware Private AI Foundation от NVIDIA и VMware поможет компаниям упростить и ускорить внедрение генеративного ИИNVIDIA и VMware объявили о расширении стратегического партнёрства, нацеленного на развитие систем ИИ. Компании анонсировали платформу VMware Private AI Foundation — полнофункциональное решение, которое позволит заказчикам быстро развёртывать различные приложения на базе генеративного ИИ. Новая платформа представляет собой полностью интегрированный продукт на базе VMware Cloud Foundation, включающий стек ПО для генеративного ИИ и вычислительные ресурсы на базе ускорителей NVIDIA. VMware Private AI Foundation будет поддерживаться Dell Technologies, Hewlett Packard Enterprise (НРЕ) и Lenovo, которые одними из первых предложат готовые ИИ-комплексы. Такие системы будут включать ускорители NVIDIA L40S, DPU BlueField-3 и адаптеры ConnectX-7 SmartNIC . 
Изображение: NVIDIA Предполагается, что благодаря новому совместному решению NVIDIA и VMware сотни тысяч клиентов в сферах финансовых услуг, здравоохранения, производства и других отраслях получат комплексную платформу, позволяющую раскрыть потенциал генеративного ИИ с использованием их собственных данных. В числе ожидаемых преимуществ для заказчиков называются:
22.08.2023 [20:39], Алексей Степин
ИИ-из-коробки: Nutanix представила GPT-in-a-Box для быстрого развёртывания LLM-инфраструктурВ эпоху быстрого развития ИИ-систем многие компании интересуются данной темой, в частности, большими языковыми моделями, но они обеспокоены сохранностью и целостностью собственных данных, чего не могут полностью гарантировать облачные сервисы. Специально для таких случаев компания Nutanix, разработчик решений для мультиоблачных и гиперконвергентных инфраструктур, предложила своё решение — платформу GPT-in-a-Box. За этим названием скрывается программно-определяемая ИИ-платформа, базирующаяся на разработках Nutanix, открытых фреймворках, включая PyTorch и KubeFlow, и вычислительных узлах, оснащённых ускорителями NVIDIA. Она позволяет в кратчайшие сроки развернуть защищённую ИИ-среду в ЦОД или на периферии заказчика. Комплекс задействует файловое и объектное хранилище Nutanix Unified Storage, а также Kubernetes-платформу Karbon 2 с пробросом ускорителей. 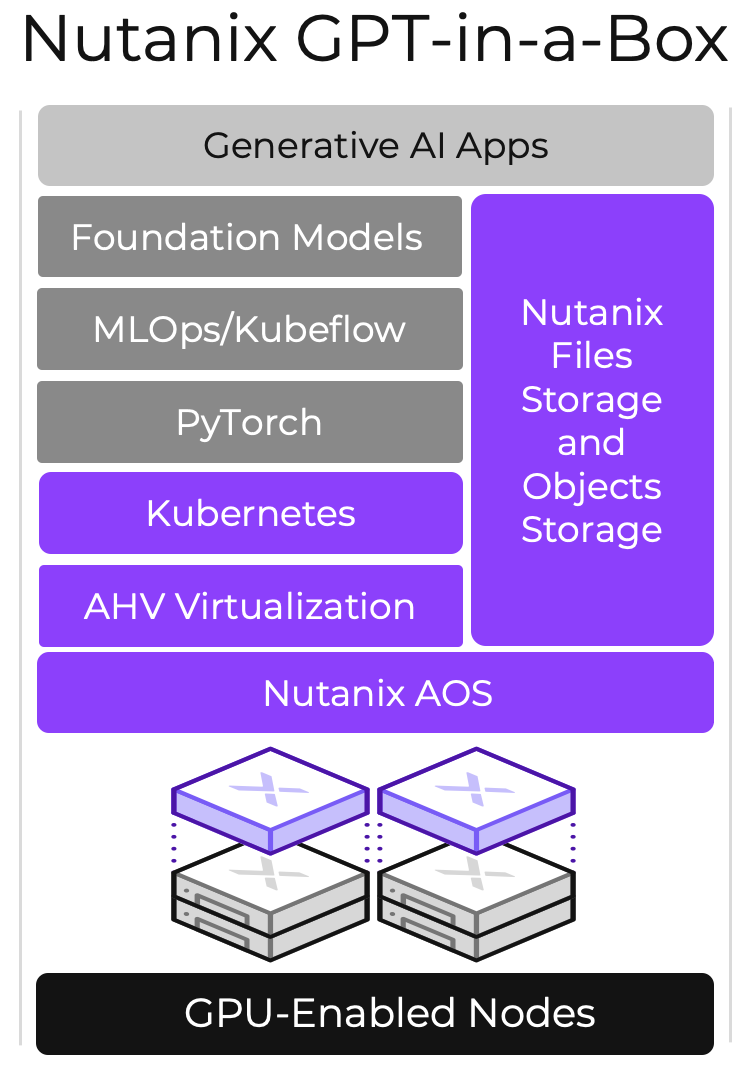
Источник: Nutanix В число поддерживаемых базовых языковых моделей входят Llama2, Falcon LLM и MosaicML, но возможен запуск и других GPT-моделей, а также тонкая подстройка с использованием данных из интегрированного хранилища. При этом GPT-in-a-Box вовсе не требует повышенных затрат, связанных с поддержкой, масштабированием и администрированием. Система функционирует в рамках Nutanix Cloud Platform, которая сертифицирована для NVIDIA AI Enterprise.
14.08.2023 [22:25], Руслан Авдеев
ИИ для телекома: SK Telecom вложила $100 млн в стартап Anthropic, чтобы получить кастомную большую языковую модель для своего бизнесаЮжнокорейский телеком-оператор SK Telecom инвестировал $100 млн в стартап Anthropic, основанный бывшими топ-менеджерами OpenAI и занимающийся генеративным ИИ. Как сообщает DataCenter Dynamics, сделка предусматривает не только инвестиции, но и совместную работу над большими языковыми моделями (LLM), специально оптимизированными для телекоммуникационных компаний. На первом этапе будет создан специальный вариант более общей модели Claude. Новый вариант научится понимать корейский, японский, английский, немецкий, испанский и арабский языки. Курировать работу будет один из основателей стартапа и его главный научный сотрудник Джаред Каплан (Jared Kaplan). Готовая модель поступит в распоряжение группы Global Telco AI Alliance, основанной в прошлом месяце SK Telecom, Deutsche Telekom, e& и Singtel. LLM будет применяться для обслуживания клиентов телеком-сервисов, а также для маркетинга, продаж и других целей. По словам Anthropic, SK Telecom намерена использовать ИИ для «преображения» телекоммуникационной отрасли. Стартап намерен объединить свои навыки в сфере ИИ с опытом SK Telecom в телекоммуникационном бизнесе. При этом последняя уже работает над LLM — в феврале появилась информация о том, что южнокорейская компания удвоила мощность ИИ-суперкомпьютера Titan, ответственного за работу корейского варианта GPT-3 — модели Aidat (A dot). 
Источник изображения: Anthropic С самого начала своего существования Anthropic была хорошо воспринята техногигантами. Среди её инвесторов уже числится Google, вложившая в стартап $300 млн, а всего компания привлекла более $1,5 млрд, причём в числе инвесторов, получивших долю в компании, оказалось и другое подразделение SK Group — SK Telecom Ventures. |
|

