Материалы по тегу: инференс
|
05.03.2025 [11:51], Сергей Карасёв
Lenovo представила компактный ИИ-сервер ThinkEdge SE100 для инференсаLenovo анонсировала сервер ThinkEdge SE100, предназначенный для решения задач ИИ-инференса на периферии. Новинка ориентирована на предприятия в различных отраслях, включая розничную торговлю, производство, телекоммуникации и здравоохранение. Сервер комплектуется процессором Intel поколения Arrow Lake-H: это может быть чип Core Ultra 7 255H (6P+8E+2LP-E) с частотой до 5,1 ГГц или Core Ultra 5 225H (4P+8E+2LP-E) с частотой до 4,9 ГГц. Поддерживается до 64 Гбайт оперативной памяти DDR5-6400 в виде двух модулей CSO-DIMM (Clocked Small Outline DIMM). Устройство располагает одним слотом PCIe 4.0 x8 HHHL для ускорителя на базе GPU, например, NVIDIA RTX 2000E ADA или NVIDIA RTX A1000. Система может быть оборудована загрузочным накопителем M.2 2280 вместимостью до 960 Гбайт, а также двумя SSD формата M.2 (NVMe) ёмкостью до 3,84 Тбайт. Присутствуют два сетевых порта 1GbE и выделенный сетевой порт управления 1GbE RJ-45. Для модели ThinkEdge SE100 предусмотрен широкий выбор вариантов монтажа, включая крепление VESA и на DIN-рейку, установку в стойку и использование в «настольном» режиме. Базовый модуль имеет размеры 53 × 142 × 278 мм, блок расширения — 53 × 214 × 278 мм. 
Источник изображений: Lenovo Во фронтальной части сервера расположены порты USB 3.2 Gen2 Type-A (×2), USB 3.2 Gen2 Type-C, HDMI 2.0 (×2) и RJ-45. Сзади сосредоточены разъёмы USB Type-C (×2), USB 3.2 Gen2 Type-A (×2) и RJ-45 (×3). Диапазон рабочих температур — от +5 до +45 °C. Заявлена совместимость с программными платформами Windows 11 Enterprise, Ubuntu 24.04, RHEL.  По утверждениям Lenovo, сервер ThinkEdge SE100 на 85 % компактнее традиционных систем, ориентированных на ИИ-инференс. При этом обеспечивается «производительность корпоративного уровня». На устройство предоставляется трёхлетняя гарантия.
27.02.2025 [16:27], Владимир Мироненко
NVIDIA увеличила выручку, но снизила валовую прибыль — продукты стали сложнее и дороже, а спрос на Blackwell потрясающийNVIDIA объявила финансовые результаты за IV квартал и 2025 финансовый год, завершившийся 26 января 2025 года. Выручка компании в IV квартале составила $39,3 млрд, что на 12 % выше результата предыдущего квартала и на 78 % больше год к году при консенсус-прогнозе аналитиков, опрошенных LSEG, в размере $38,05 млрд. Вместе с тем компания сообщила о снижении валовой прибыли в отчётном квартале на 3 п.п. в годовом исчислении 73 %, объяснив это выходом новых продуктов для ЦОД, которые стали сложнее и дороже. Чистая прибыль (GAAP) выросла год к году на 80 % до $22,09 млрд. Чистая прибыль на разводнённую акцию (GAAP) составила $0,89, что на 14 % больше, чем в предыдущем квартале и на 82 % больше год к году. Скорректированная чистая прибыль на разводнённую акцию (Non-GAAP) составила $0,89, что на 10 % больше, чем в предыдущем квартале и на 71% больше, чем годом ранее, а также больше консенсус-прогноза аналитиков Уолл-стрит согласно опросу LSEG в размере $0,84. 
Источник изображений: NVIDIA Выручка компании в 2025 финансовом году выросла на 114 % до $130,5 млрд. Чистая прибыль (GAAP) увеличилась на 145 % с $29,76 млрд или $1,19 на разводнённую акцию в предыдущем финансовом году до $72,88 млрд или $2,94 на акцию в отчётном. Скорректированная чистая прибыль (Non-GAAP) выросла за год на 130 % до $2,99 на разводнённую акцию. В сегменте решений для ЦОД выручка за IV квартал составила $35,6 млрд, увеличившись на 93 % в годовом исчислении и опередив прогноз Уолл-стрит в $33,65 млрд. За год выручка этого сегмента увеличилась на 142 % до $115,2 млрд. Как отметил ресурс SiliconANGLE, на данный сегмент пришлось 91 % от общего дохода компании за IV квартал, по сравнению с 83 % год назад и всего 60 % в аналогичном квартале 2023 финансового года. Доход компании от продуктов для ЦОД вырос за последние два года почти в десять раз. Вместе с тем выручка от продаж сетевого оборудование упала за квартал на 9 % до $3 млрд, но компания наверняка увеличит продажи, т.к. решениями Spectrum-X буду оснащатсья первые ЦОД ИИ-мегапроекта Stargate. 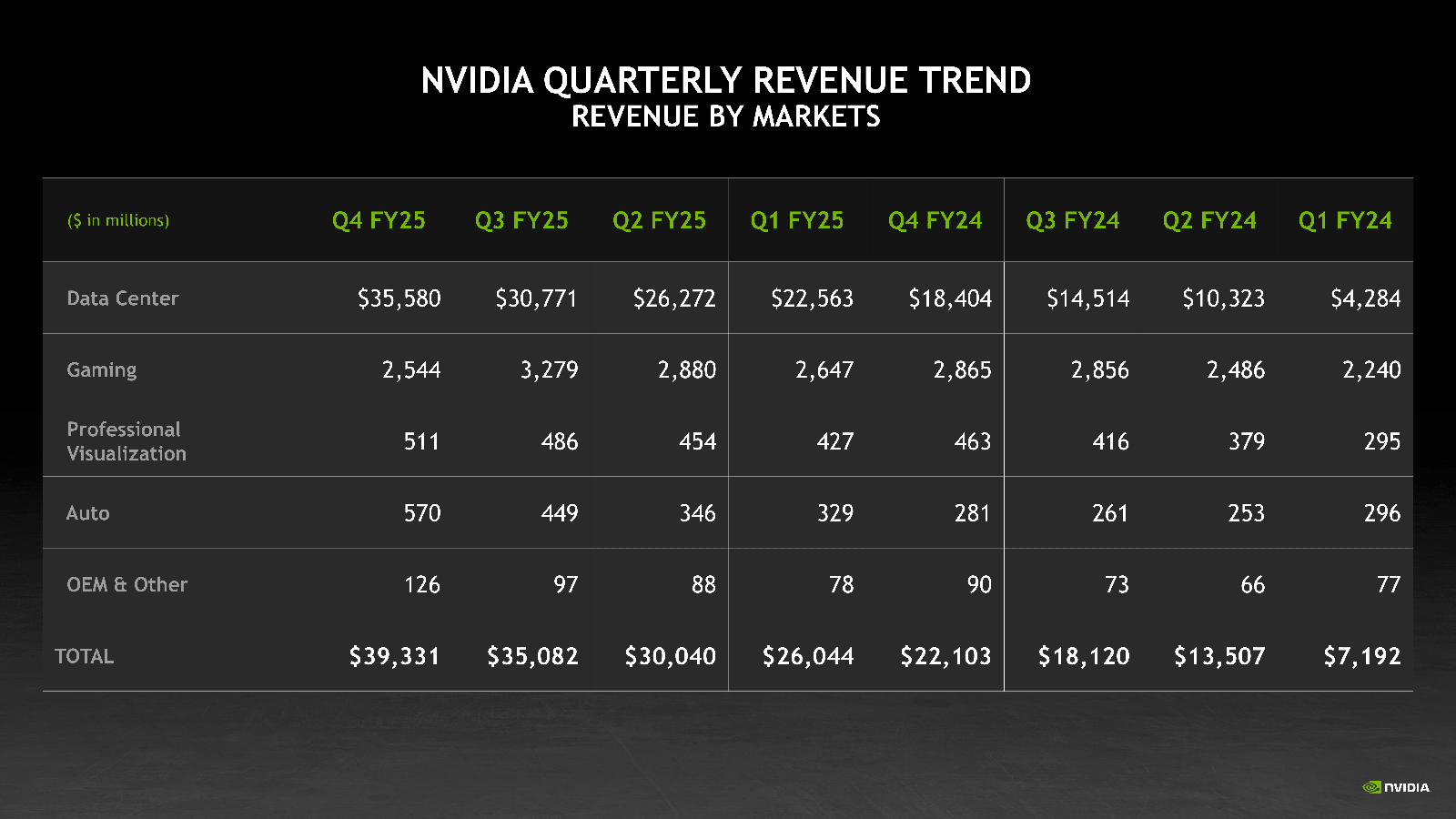 NVIDIA сообщила, что доход от продаж чипов с архитектурой Blackwell составил за квартал $11 млрд, что является «самым быстрым ростом продукта» в её истории. «Спрос на Blackwell потрясающий», — цитирует Bloomberg заявление гендиректора NVIDIA Дженсена Хуанга (Jensen Huang). Финансовый директор NVIDIA Колетт Кресс (Colette Kress) сообщила, что чипы Blackwell были лидерами по продажам для дата-центров и принесли порядка 50 % всего дохода сегмента ЦОД. В ходе телефонной конференции Хуанг сообщил, что предыдущие поколения чипов компании в основном использовались для обучения моделей ИИ, а новые чипы Blackwell в основном применяются для инференса. Некоторые инвесторы высказывали опасения, что спрос на самые мощные чипы NVIDIA может упасть из-за прогресса китайской DeepSeek, чья недорогая модель со способностью к рассуждениям DeepSeek R1 произвела фурор в отрасли, хотя на её разработку якобы ушло всего несколько миллионов долларов.  В ответ на это Кресс сообщила, что новые модели, разработанные для более тщательного «обдумывания» своих ответов, вероятно, потребуют гораздо больше вычислительной мощности по сравнению с более ранними моделями генеративного ИИ. «Для продолжительно думающего, рассуждающего ИИ может потребоваться в 100 раз больше вычислений на задачу по сравнению с однократными инференсами», — сказала она. Хуанг поддержал её, заявив, что «подавляющее большинство вычислений сегодня на самом деле относится к инференсу». Он выразил мнение, что в ближайшие годы ИИ-модели нового поколения могут потребовать «в миллионы раз» больше вычислительных мощностей, чем доступно сейчас. Опасения инвесторов также вызывает то, что AWS, Google и Microsoft, разрабатывающие собственные, кастомизированные ускорители, могут создать сильную конкуренцию NVIDIA. В ответ Хуанг заявил, что этим конкурентам ещё предстоит пройти долгий путь, и то, что чип разработан вовсе не означает, что он будет выпускаться.  Что касается результатов остальных подразделений компании, то игровой бизнес компании, включающий графические процессоры для 3D-игр, принёс ей $2,5 млрд, что меньше год к году на 11 %, а также меньше прогноза StreetAccount в размере $3,04 млрд. В сегменте профессиональной визуализации продажи за квартал составили $511 млн, что на 10 % больше год к году. За весь год выручка подразделения увеличилась на 21 % до $1,9 млрд. В автомобильном секторе выручка компании за отчётный квартал увеличилась в годовом исчислении на 103 % до $570 млн. За год выручка составила $1,7 млрд (рост — 55 %). Прогноз NVIDIA на I квартал 2026 финансового года по выручке равен $43 млрд ± 2 %, против $41,78 млрд, ожидаемых по оценкам LSEG. Это означает рост примерно на 65 % год к году, что является замедлением темпов роста компании по сравнению с ростом на 262 % за тот же период годом ранее. Компания также предупредила, что валовая прибыль будет меньше, чем ожидалось, поскольку она спешит выпустить новый дизайн чипа с архитектурой Blackwell. И также есть риск, что введение пошлин на импорт Соединёнными Штатами повлияет на результаты её работы. Акции NVIDIA выросли чуть более чем на 1 % в ходе расширенных торгов, что добавилось к росту более чем на 3 % в ходе обычной торговой сессии, отметил Bloomberg.
24.02.2025 [12:22], Сергей Карасёв
SambaNova развернула самую быструю инференс-платформу для ИИ-модели DeepSeek-R1 671BКомпания SambaNova объявила о том, что в её облаке SambaNova Cloud стала доступна большая языковая модель DeepSeek-R1 с 671 млрд параметров. При этом благодаря применению фирменных ускорителей SN40L обеспечивается рекордно высокая скорость инференса. Изделия SambaNova SN40L RDU (Reconfigurable Dataflow Unit) состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM и 64 Гбайт памяти HBM3. Восьмипроцессорная система на базе SN40L, по заявлениям SambaNova, способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256k. Платформа SambaNova Cloud при использовании DeepSeek-R1 671B демонстрирует производительность до 198 токенов в секунду, что на сегодняшний день является рекордным показателем. Для сравнения: у ближайшего конкурента — Together AI — результат составляет 98 токенов в секунду, а у Microsoft Azure — 20 токенов в секунду. Ранее Cerebras объявила о собственном рекорде — до 1508 токенов/с, но для гораздо более скромной и, по мнению компании, практичной модели DeepSeek-R1-Distill-Llama-70B. 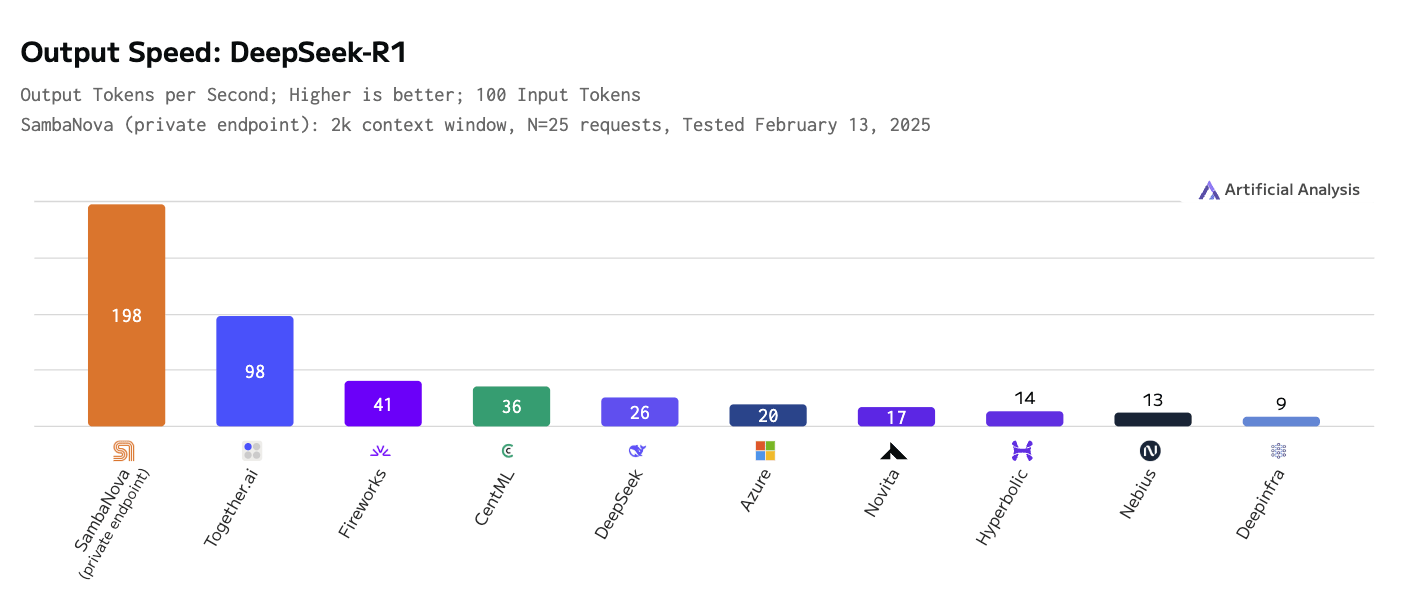
Источник изображения: SambaNova Утверждается, что ускорители SambaNova SN40L RDU по сравнению с новейшими GPU обеспечивают в три раза большую производительность и в пять раз более высокую эффективность. В частности, по заявлениям SambaNova, одна стойка с 16 экземплярами SN40L RDU по быстродействию сопоставима с 40 стойками, насчитывающими в общей сложности 320 передовых GPU. Таким образом, существенно сокращаются затраты на использование DeepSeek-R1 671B. Доступ к DeepSeek-R1 671B в облаке SambaNova Cloud предоставляется посредством API. В перспективе компания планирует наращивать вычислительные мощности, обеспечив производительность на уровне 20 000 токенов в секунду.
16.02.2025 [00:22], Сергей Карасёв
HBF вместо HBM: SanDisk предлагает увеличить объём памяти ИИ-ускорителей в 16 раз, заменив DRAM на сверхбыструю флеш-памятьКомпания SanDisk, которая вскоре станет независимой, отделившись от Western Digital, предложила способ многократного увеличения объёма памяти ИИ-ускорителей. Как сообщает ресурс ComputerBase.de, речь идёт о замене HBM (High Bandwidth Memory) на флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). На первый взгляд, идея может показаться абсурдной, поскольку флеш-память NAND значительно медленнее DRAM, которая служит основой HBM. Но, по заявлениям SanDisk, архитектура HBF позволяет обойти ограничения, присущие традиционным NAND-изделиям, что сделает память нового типа пригодной для применения в ИИ-ускорителях. При этом HBF планируется использовать прежде всего для задач инференса, а не обучения моделей ИИ. С каждым новым поколением HBM растёт объём памяти, которым оснащаются ИИ-карты: у современных ускорителей AMD и NVIDIA он достигает 192 Гбайт. Благодаря внедрению HBF компания SanDisk рассчитывает увеличить показатель в 8 или даже 16 раз при сопоставимой цене. Компания предлагает две схемы использования флеш-памяти с высокой пропускной способностью: одна предусматривает полную замену HBM на HBF, а другая — совмещение этих двух технологий. 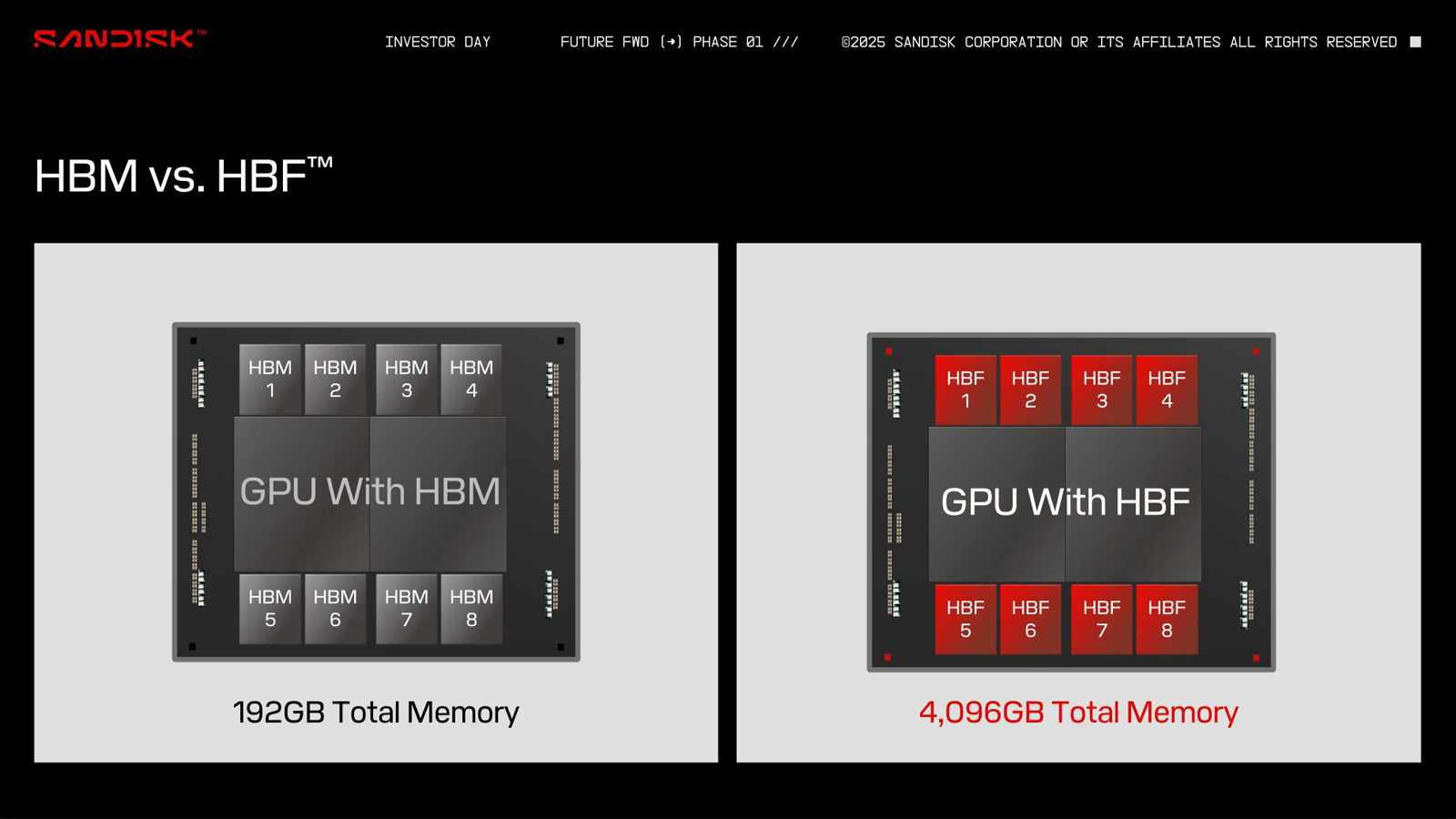
Источник изображений: ComputerBase.de В качестве примера SanDisk приводит GPU со 192 Гбайт памяти HBM, которая разделена на восемь стеков по 24 Гбайт. В случае HBF каждый такой стек сможет иметь ёмкость 512 Гбайт. Таким образом, при полной замене HBM ускоритель сможет нести на борту 4 Тбайт памяти: это позволит полностью загрузить большую языковую модель Frontier с 1,8 трлн параметров размером 3,6 Тбайт. В гибридной конфигурации можно, например, использовать связку стеков 2 × HBM плюс 6 × HBF, что в сумме даст 3120 Гбайт памяти. 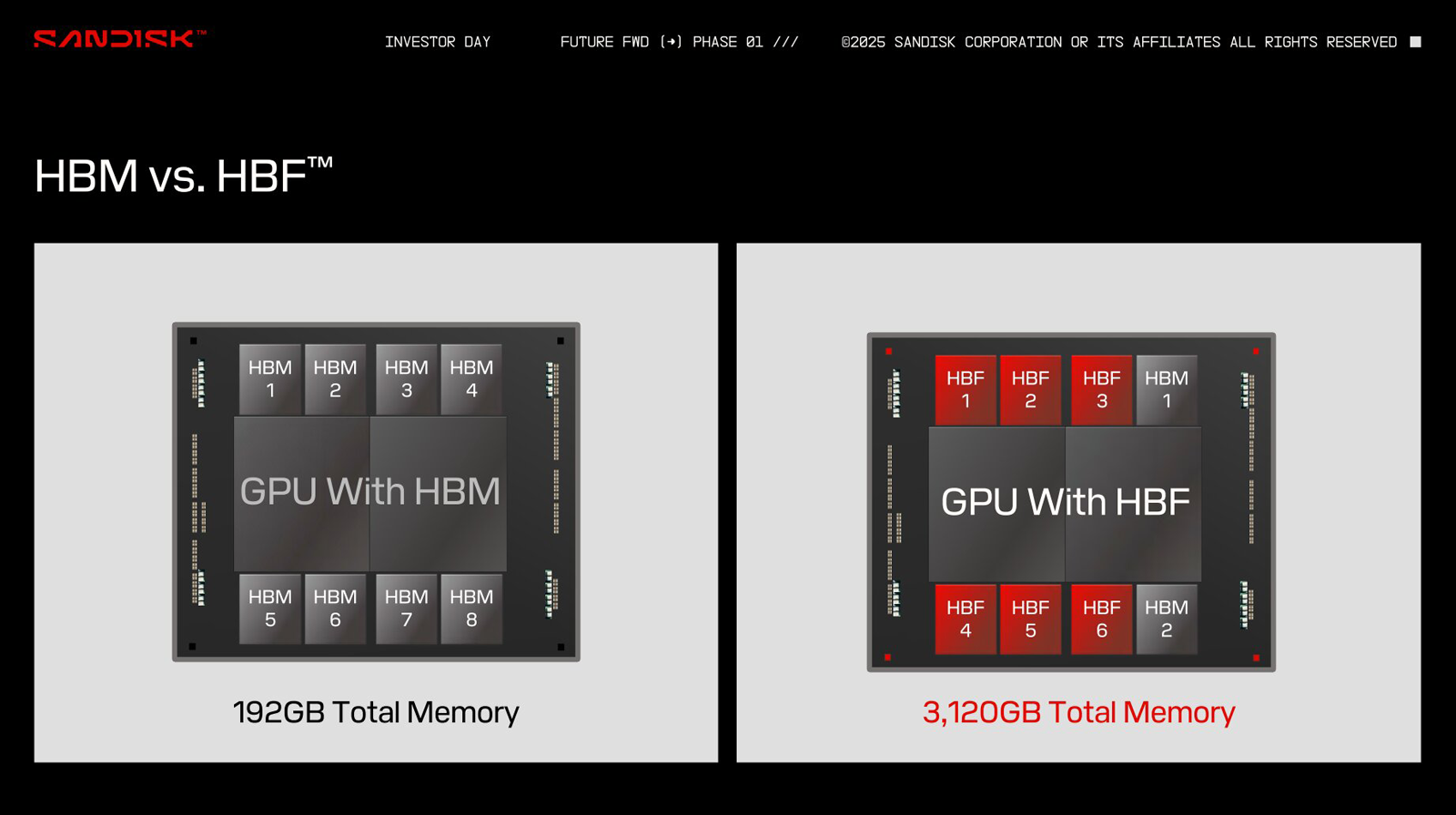 Архитектура HBF предполагает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. Обычная флеш-память NAND приближается к DRAM по пропускной способности, но не может сравниться с ней по времени доступа. SanDisk предлагает решить проблему путём разделения HBF на массив областей с большим количеством линий данных: это позволит многократно увеличить скорость доступа.  SanDisk разработала архитектуру HBF в 2024 году под «влиянием ключевых игроков в области ИИ». В дальнейшие планы входят формирование технического консультативного совета, включающего партнёров и лидеров отрасли, и создание открытого стандарта. Впрочем, есть и другие методы увеличения объёма памяти ускорителей. Один из них — использование CXL-пулов.
14.02.2025 [13:24], Руслан Авдеев
Эксперты прогнозируют охлаждение рынка ИИ-серверов в 2025 годуТехнологические санкции США и подготовка цепочки поставок к поступлению на рынок новейшего оборудования NVIDIA, вероятно, приведут к снижению объёмов продаж ИИ-серверов в 2025 году, сообщает The Register со ссылкой на мнение независимых экспертов. Так, TrendForce сообщает, что поставки ИИ-серверов в прошлом году выросли на 46 %, преимущественно благодаря заказам провайдеров облачных сервисов (CSP). В частности, производитель серверов Foxconn объяснил недавний рекордный рост выручки именно продажами ИИ-серверов. При этом в TrendForce рассматривают несколько вариантов развития событий на рынке серверов в 2025 году из-за неопределённости, царящей в нише ИИ-решений. Наиболее вероятным считается дальнейшее расширение рынка, но с более низким годовым приростом. Впрочем, даже в таких условиях он может превысить 30 % — Microsoft, Meta✴, Amazon и Google намерены увеличить капитальные затраты на ИИ-инфраструктуру. Как ожидается, это будет способствовать поддержке спроса на ИИ-серверы. Наихудшим сценарием, по оценке TrendForce, причём следующим по вероятности, является рост поставок ИИ-серверов до «всего» 20–25 %. Этот прогноз учитывает ужесточение США экспорта ИИ-чипов в Китай, что создаёт большую неопределённость на рынке. Кроме того, не исключены задержки поставок стоечных решений NVIDIA на основе суперчипов Grace Blackwell — их структура довольно сложна, поэтому масштабное развёртывание откладывается на II половину года. 
Источник изображения: Foxconn Более оптимистичный сценарий предполагает, что масштабные проекты в Китае и США (например, Stargate) помогут ускоренному развёртыванию ИИ-серверов. Кроме того, хотя триумф DeepSeek может негативно повлиять на необходимость внедрения большого количества ИИ-ускорителей, он же способен расширить применение искусственного интеллекта, стимулируя рост ИИ на периферии. При удачном стечении обстоятельств поставки ИИ-серверов вырастут в 2025 году почти на 35 %. Недавно глава IBM Арвинд Кришна (Arvind Krishna) уже предсказал, что использование аналогичных решениям DeepSeek экономичных и эффективных технологий не только не приведёт к падению рынка, но, наоборот, значительно увеличит использование оборудования после снижения «порога входа» для применения ИИ-моделей. Схожей позиции придерживаются инвесторы в ИИ-инфраструктуру вроде Blackstone и Brookfield, ожидающие, что спрос на ЦОД и оборудование не уменьшится. В TrendForce ожидают, что влияние DeepSeek будет способствовать переходу облачных операторов на недорогие чипы собственной разработки, поскольку акцент в последнее время смещается с обучения ИИ на инференс. В результате серверы, оптимизированные для запуска моделей, займут большую часть рынка. Вероятно, рынок серверов станет более сегментированным, поскольку крупные облачные игроки продолжат инвестиции в высокопроизводительные решения, а корпоративные заказчики будут отдавать предпочтение более экономичным альтернативам.
13.02.2025 [01:05], Владимир Мироненко
Meta✴ намерена купить разработчика ИИ-ускорителей FuriosaAI, и не одна онаMeta✴ ведет переговоры о приобретении южнокорейского стартапа FuriosaAI, разработчика ИИ-ускорителей, базирующегося в Сеуле (Южная Корея) и Санта-Кларе (США), что позволит ей выпускать собственные кастомные чипы на фоне нехватки ускорителей NVIDIA, сообщил Forbes со ссылкой на информированные источники. По словам одного из источников, сделка может быть заключена уже в этом месяце. Другой источник утверждает, что ещё несколько компаний ведут переговоры о приобретении FuriosaAI. Компанию основал в 2017 году Джун Пайк (June Paik), ранее работавший в Samsung Electronics и AMD и занимающий сейчас пост гендиректора. FuriosaAI привлекла в общей сложности около ₩170 млн (около $115 млн) венчурного финансирования. Среди первых инвесторов были южнокорейский интернет-гигант Naver и базирующаяся в Сеуле DSC Investment. В последнем раунде финансирования, прошедшем на прошлой неделе, FuriosaAI получила ₩2 млрд (около $1,4 млн) от южнокорейской CRIT Ventures. В августе прошлого года FuriosaAI представила энергоэффективный ИИ-ускоритель RNGD, который был разработан в партнёрстве с тайваньским производителем микросхем Global Unichip Corp. По словам компании, RNGD является идеальным выбором для крупномасштабного развёртывания продвинутых моделей генеративного ИИ, таких как Llama 2 и Llama 3, поскольку не уступает передовым ускорителям по производительности, отличаясь при этом низким TDP в пределах 150 Вт. 
Источник изображения: FuriosaAI RNGD предназначен для инференса и оснащён HBM3-памятью SK hynix. FuriosaAI сообщила, что RNGD показывает в три раза большую производительность в расчёте на 1 Вт, чем ускорители NVIDIA H100 при запуске продвинутых больших языковых моделей (LLM). Как ожидается, массовое производство RNGD начнётся во II половине 2025 года. При этом сама Meta✴ разработала уже два поколения собственных ИИ-ускорителей для инференса. И если от MTIA v1 в итоге было решено отказаться в пользу в первую очередь продуктов NVIDIA, то MTIA v2, судя по всему, активно внедряются, но их всё ещё не хватает для удовлетворения потребностей компании. 
Источник изображения: Meta✴ По данным Forbes, заинтересованность в RNGD также продемонстрировали исследовательская ИИ-лаборатория LG и Saudi Aramco. В сентябре последняя подписала меморандум о взаимопонимании с FuriosaAI и Cerebras Systems, ещё одним производителем ИИ-ускорителей, для «изучения сотрудничества в области суперкомпьютеров и ИИ». Переговоры проходят спустя несколько месяцев после того, как ещё один южнокорейский стартап в сфере ИИ Rebellions, завершил слияние с поддерживаемой SK hynix компанией Sapeon. Объединённая компания, которая осуществляет деятельность под брендом Rebellions, является первым в Южной Корее единорогом в области производства чипов ИИ.
12.02.2025 [08:29], Владимир Мироненко
NXP Semiconductors купила Kinara, разработчика NPU для периферийных вычисленийНидерландский производитель микросхем NXP Semiconductors N.V. сообщил о приобретении за $307 млн калифорнийского стартапа Kinara, специализирующегося на разработке программируемых дискретных нейропроцессорных модулей (NPU) для обработки ИИ-нагрузок на периферии. Как ожидается, сделка будет закрыта во II половине 2025 года после получения одобрения регуляторами. NXP и Kinara являются давними партнёрами, так что интеграция решений не займёт много времени. В пресс-релизе указано, что инновационные NPU и комплексное ПО Kinara обеспечивают высокую производительность в сочетании энергоэффективностью при обработке различных нейронных сетей, включая генеративный ИИ, для удовлетворения быстрорастущих потребностей в интеллектуальных функциях на промышленных и автомобильных рынках. Приобретение Kinara позволит расширить возможности NXP по предложению масштабируемых ИИ-платформ, от облегчённых и оптимизированных вариантов (TinyML) до полноценного генеративного ИИ. 
Источник изображения: NXP Сообщается, что дискретные NPU Kinara, включая Ara-1 и Ara-2, предназначенные для периферийных вычислений, входят в число лидеров отрасли по производительности и энергоэффективности, что делает их предпочтительным решением для новых приложений ИИ в области визуализации, обработки голоса, жестов и множества других многомодальных вариантов генеративного ИИ. Оба чипа имеют инновационную архитектуру, которая отличается не только энергоэффективностью в задачах инференса, но и программируемостью, что позволяет со временем задействовать всё новые модели и сценарии, включая, например, агентный ИИ в будущем. 
Источник изображения: Kinara NPU второго поколения Ara-2 обеспечивает производительность до 40 TOPS, оптимизирован для достижения высокой производительности на системном уровне для генеративного ИИ. NPU Ara-1 и Ara-2 можно легко интегрировать со встраиваемыми системами для расширения их возможностей, включая модернизацию уже развёрнутых систем. Также Kiara предоставляет полный комплект инструментов для разработки ПО, позволяющий клиентам оптимизировать производительность моделей и упростить их развёртывание. Инструмены и библиотеки ИИ Kinara будут интегрированы в среду разработки NXP eIQ AI/ML, чтобы клиенты могли быстро и легко создавать сквозные готовые ИИ-решения.
10.02.2025 [19:33], Сергей Карасёв
Groq развернула в Саудовской Аравии почти 20 тыс. ИИ-ускорителей LPUКомпании Groq и Aramco Digital объявили об открытии крупнейшего в Европе, на Ближнем Востоке и в Африке (EMEA) вычислительного ИИ-центра, ориентированного на задачи инференса. Площадка располагается в Даммаме в Саудовской Аравии. Groq занимается разработкой ускорителей LPU (Language Processing Unit) для работы с большими языковыми моделями (LLM). Утверждается, что они могут успешно конкурировать с ИИ-ускорителями NVIDIA, AMD и Intel. Aramco Digital, подразделение нефтегазового и химического гиганта Aramco, и Groq сообщили о намерении создать в Саудовской Аравии крупнейший в мире центр по развитию ИИ в марте 2024 года. Тогда говорилось, что Aramco Digital будет сдавать мощности Groq LPU в аренду клиентам на Ближнем Востоке. Предполагается также, что партнёрство с Groq поможет Aramco Digital вывести на рынок управляемую голосом ИИ-модель Norous. 
Источник изображения: Twitter/@sundeep Как теперь сообщается, на базе нового ИИ-центра заработал облачный регион GrogCloud, включающий 19 725 LPU. Инвестиции в проект составили $1,5 млрд — совместно от Groq и Aramco Digital. Джонатан Росс (Jonathan Ross), генеральный директор Groq, сообщил, что к концу I квартала 2025 года компания развернёт сможет генерировать не менее 25 млн токенов в секунду. В перспективе планируется повышение данного показателя вплоть до 1 млрд токенов в секунду. 
Источник изображения: Twitter/@sundeep С момента запуска GroqCloud в марте 2024 года более 800 тыс. разработчиков по всему миру начали использовать эту платформу на базе LPU Inference Engine через программный интерфейс Groq API. Облако, как утверждается, обеспечивает инференс в реальном времени с меньшей задержкой и большей пропускной способностью, чем у конкурентов. GroqCloud подходит для генеративных и разговорных приложений ИИ. 
Источник изображения: Twitter/@sundeep В целом, Groq создаёт высокопроизводительную инфраструктуру ИИ, предназначенную для обслуживания более 4 млрд человек в Саудовской Аравии, на Ближнем Востоке, в Африке и за пределами этого региона. Сделка с Groq является частью крупномасштабного плана Vision-2030, предполагающего переход Саудовской Аравии к инновационной экономике на базе ИИ, которая призвана снизить зависимость страны от добычи нефти и газа.
03.02.2025 [09:20], Руслан Авдеев
The Register: Успех DeepSeek показал важность обдуманных инвестиций в ИИ, но потребность в развитии инфраструктуры никуда не денетсяШок, вызванный недавним триумфом китайского ИИ-стартапа DeepSeek, представившего дешёвые и эффективные ИИ-модели, заставил многих усомниться в результативности масштабных вложений в инфраструктуру на базе дорогих ИИ-ускорителей, сообщает The Register. Тем не менее эксперты уверены, что отказываться от инвестиций было бы нецелесообразно. На прошлой неделе акции ряда крупнейших американских ИИ-брендов после дебюта весьма эффективной модели DeepSeek R1, использующей, со слов создателей, сравнительно мало ускорителей NVIDIA, буквально обрушились в цене. Из-за этого многие эксперты усомнились в том, что траты миллиардов на аппаратную инфраструктуру для ИИ себя оправдывают, если Китай способен добиться хороших результатов, используя не самое мощное оборудование. Например, NVIDIA «в моменте» потеряла $600 млрд рыночной стоимости. Настоящая истерия наложилась на растущее беспокойство в связи с тем, что всё больше денег тратится на инфраструктуру и её поддержку, а особенной отдачи пока не видно. Впрочем, паника может быть неуместной, поскольку обрушение акций прекратилось, а DeepSeek обвиняется в использовании ИИ-моделей Anthropic и OpenAI. Как отмечает The Register, нет и реальных подтверждений того, что производительность моделей DeepSeek находится на уровне лучших из актуальных моделей, а также того, что на обучение китайского ИИ ушло всего $6 млн. По оценкам SemiAnalysis, доступная DeepSeek инфраструктура гораздо больше, чем утверждает компания, и стоит более чем $1,5 млрд. 
Источник изображения: Etienne Girardet/unsplash.com По словам экспертов Omdia, опасения относительно «сокрушительных» инноваций DeepSeek сильно преувеличены. В компании подтверждают, что китайский стартап использовал некоторые «гениальные инновации», но они приведут лишь к массовому использованию аналогичных решений и строительству новой ИИ-инфраструктуры. В Omdia прогнозируют, что в ближайшие годы рынок ИИ-инфраструктуры, скорее всего, значительно вырастет. В компании полагают, что до 2028 года поставки серверов для инференса будут расти на 17 % ежегодно. В TrendForce придерживаются несколько иного мнения и предполагают, что в будущем организации всё же станут более строго оценивать инвестиции в инфраструктуру ИИ и станут применять более эффективные модели для того, чтобы снизить зависимость от доступности ускорителей. Также не исключается, что чаще будут использоваться кастомные ASIC вместо сторонних ИИ-ускорителей и спрос на «классические» модели может претерпеть с 2025 года заметные изменения. Если раньше индустрия полагалась в первую очередь на масштабирование моделей, увеличение объёмов данных и повышение производительности оборудования, то теперь стратегия меняется. DeepSeek прибегла к «дистилляции» моделей, повышению скорости инференса и снижения зависимости от оборудования. Не так давно генеральный директор IBM Арвинд Кришна (Arvind Krishna) объявил, что деятельность DeepSeek подтвердила правильность подхода к ИИ его собственной компании, считающей, что модели могут быть меньше, как и время их обучения. При использовании подобных подходов затраты на инференс могут снизиться в 30 раз, что очень хорошо для корпоративных клиентов. Ещё в 2023 году компания начала развивать серию «экономичных» базовых моделей Granite. Вероятно, по этому пути пойдут и другие. 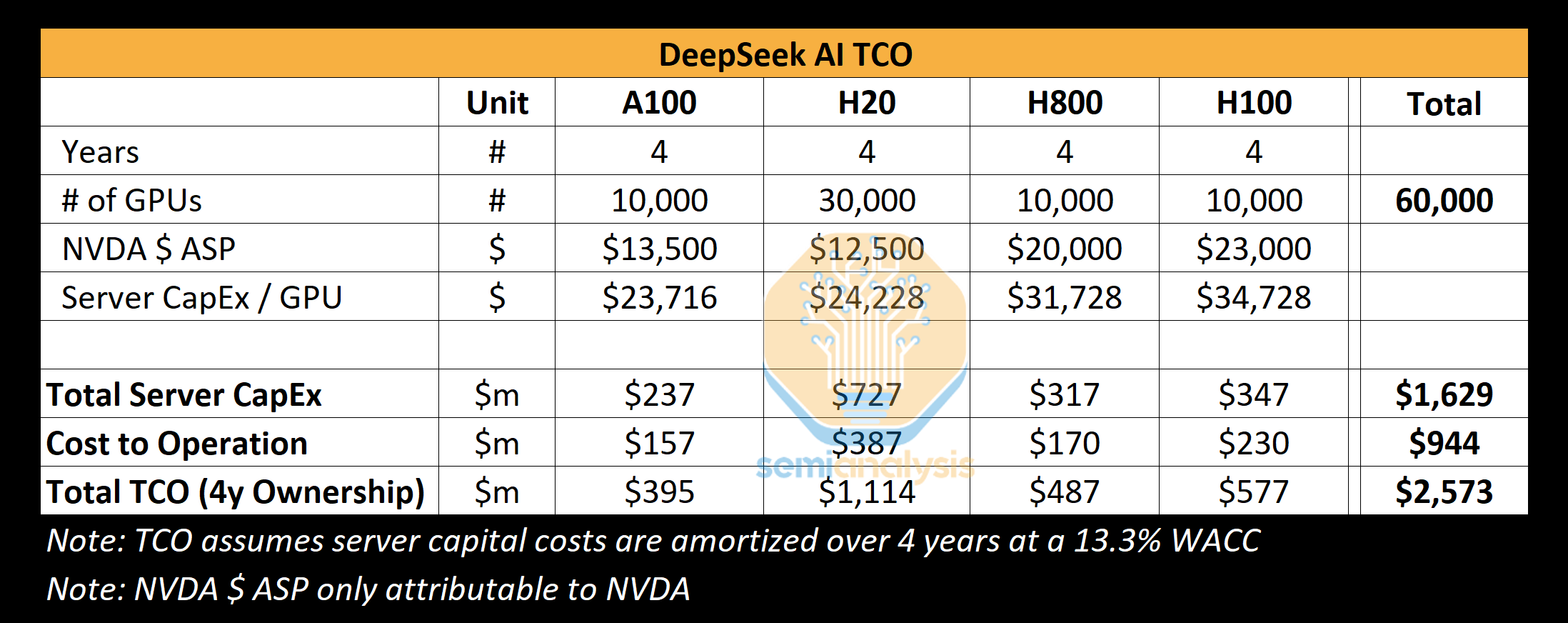
Источник изображения: SemiAnalysis Gartner также сообщает, что именно эффективное масштабирование ИИ будет целесообразнее простого наращивания вычислительных ресурсов. Впрочем, китайский ИИ не устанавливает новый стандарт эффективности моделей, поскольку те соответствуют показателям уже существующих, но не превосходят их. Кроме того, нет доказательств, что добавление дополнительных вычислительных ресурсов и данных не имеет значения. The Register прогнозирует, что продукты и технологии DeepSeek не вызовут резкого падения спроса на ИИ-инфраструктуру, поэтому инвесторам NVIDIA и строителям ЦОД, вероятно, можно не бояться того, что «пузырь» ИИ лопнет, как этого ожидают некоторые эксперты. Во всяком случае одни из крупнейших инвесторов в сектор ЦОД — Blackstone и Brookfield — заявили, что следят за успехами DeepSeek, но отказываться от инвестиций не собираются. Тем не менее, успех китайского стартапа напоминает о том, что «всегда можно сделать ещё лучше» и экстенсивное вливание денег и вычислительных ресурсов не всегда лучший вариант.
01.02.2025 [15:23], Сергей Карасёв
Самый быстрый инференс DeepSeek R1 в мире: ИИ-платформа Cerebras снова поставила рекорд производительностиАмериканский стартап Cerebras Systems объявил о том, что его инференс-платформа позволила установить мировой рекорд производительности при использовании «рассуждающей» ИИ-модели DeepSeek R1 в модификации с 70 млрд параметров (DeepSeek-R1-Distill-Llama-70B). DeepSeek R1 может содержать до 671 млрд параметров. Однако, как отмечает Cerebras, развёртывание модели со способностью к рассуждению столь большого масштаба представляет значительные проблемы. Версия с 70 млрд параметров позволяет совместить возможности рассуждений более крупной модели с MoE с широко поддерживаемой архитектурой Meta✴ Llama. 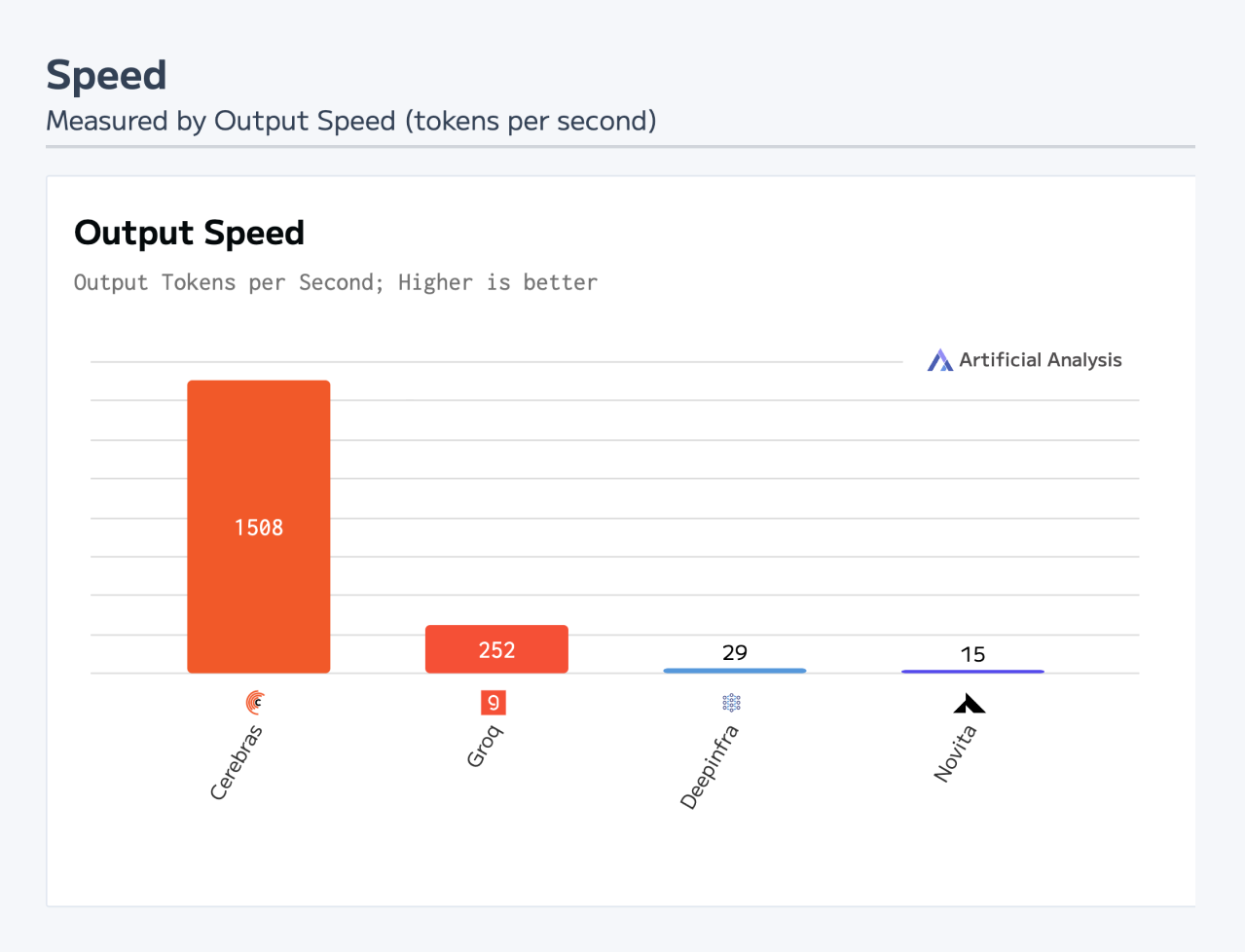
Источник изображений: Cerebras Основой платформы Cerebras являются царь-ускорители собственной разработки WSE (Wafer Scale Engine). Производительность DeepSeek R1 при работе на инфраструктуре Cerebras достигает 1508 токенов в секунду — это значительно быстрее по сравнению с конкурирующими решениями. В частности, в случае Groq показатель составляет 252 токена в секунду. Стандартный запрос на генерацию кода, который, как утверждает компания, занимает 22 секунды на конкурирующих платформах, в случае Cerebras завершается всего за 1,5 секунды, что соответствует 15-кратному повышению производительности. Cerebras подчёркивает, что DeepSeek-R1-Distill-Llama-70B превосходит как GPT-4o, так и o1-mini в сложных математических задачах и генерации кода. 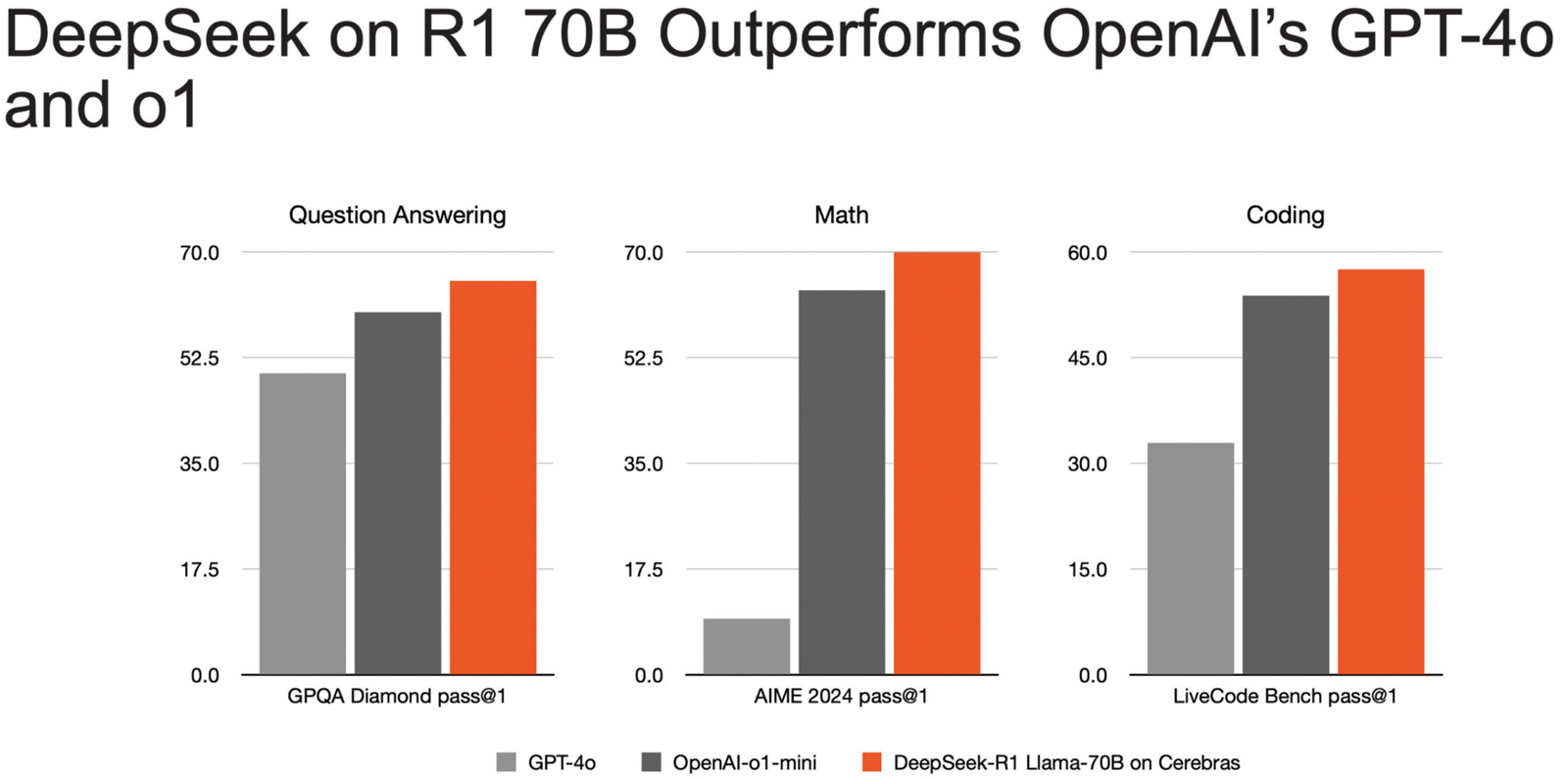 Cerebras также отмечает, что все вычисления осуществляются на базе ИИ-инфраструктуры в США, развёрнутой в собственных дата-центрах компании. При этом никакие данные не сохраняются, что гарантирует полную безопасность для клиентов. Кроме того, модель DeepSeek R1 может быть развёрнута локально в ЦОД заказчика для обеспечения максимального контроля. |
|

