Материалы по тегу: deepseek
|
17.03.2025 [17:23], Руслан Авдеев
Ежегодные расходы техногигантов на ИИ превысят $500 млрд, но большая часть денег пойдёт на инференс, а не на обучение моделейКрупнейшие IT-компании нарастят ежегодные расходы на ИИ-технологии — в совокупности они превысят $500 млрд уже в следующем десятилетии. Одной из причин роста инвестиций в ИИ станет новый подход к разработкам со стороны китайской DeepSeek и OpenAI, сообщает Bloomberg Intelligence. Группа гиперскейлеров, включая Microsoft, Amazon и Meta✴ намерена потратить $371 млрд на ЦОД и вычислительные ресурсы для ИИ в 2025 году, на 44 % больше, чем годом ранее. К 2032 году затраты вырастут до $525 млрд — быстрее, чем ожидали в Bloomberg Intelligence до того, как недавно «выстрелили» продукты DeepSeek. До недавних пор большая часть инвестиций в ИИ уходила на дата-центры и чипы, которые использовались для обучения или разработки новых, всё более крупных ИИ-моделей. Теперь компании намерены больше тратить на инференс. Изменение стратегии ускорилось после выпуска «рассуждающих» моделей компаний OpenAI и DeepSeek. У этих систем уходит больше времени на ответы на запросы пользователей, при этом они требуют больше ресурсов на инференс. Неожиданный для многих успех DeepSeek, которая, как утверждается, создала чрезвычайно недорогую и конкурентоспособную модель на уровне современных продуктов западных конкурентов (с оговорками), вызвал вопросы об эффективности инвестиций в США. Эксперты оценивают, стоило ли вкладывать огромные средства в укрупнение моделей. Некоторые компании уже стали внедрять эффективные LLM, работающие на относительно небольшом числе ускорителей. 
Источник изображения: The Drink/unspalsh.com По данным Bloomberg, «рассуждающие» модели обеспечивают новые возможности для заработка на ПО и потенциально обходятся дороже на этапе инференса, чем на этапе обучения. Это, похоже, приведёт к наращиванию инвестиций в соответствии с новой концепцией и приведёт к росту вложений в ИИ в целом. Рост капитальных затрат на обучение ИИ, как считают в Bloomberg, может быть заметно медленнее, чем предсказывалось ранее. Огромное внимание, которое привлекла DeepSeek, вероятно, заставит технологические фирмы нарастить инвестиции в инференс — именно он станет самым быстрорастущим сегментом на рынке систем генеративного ИИ. Похожие прогнозы давала и Omdia. Хотя в текущем году затраты на связанные с обучением задачи, вероятно, составят более 40 % расходов гиперскейлеров на ИИ, сегмент, как ожидается, уменьшится к 2032 году до всего 14 %. В том же году связанные с инференсом инвестиции могут составить около половины всех расходов на ИИ. Как считают в Bloomberg, наилучшие позиции среди гиперскейлеров у Google. У неё TPU собственной разработки, которые можно использовать как для обучения, так и для инференса. Другие компании, вроде Microsoft и Meta✴, сильно зависят от NVIDIA и могут оказаться не столь гибкими в гонке по новым правилам.
10.03.2025 [17:43], Руслан Авдеев
Goldman Sachs: китайские телеком-операторы станут крупнейшими бенефициарами ИИ-бума, раньше всех взяв на вооружение продукты DeepSeekТри крупнейших китайских телеком-оператора получат максимальную выгоду от бума ИИ-технологий в Китае. Согласно исследованию Goldman Sachs-China, компании China Mobile, China Telecom и China Unicom становятся ключевыми бенефициарами благодаря наличию собственной облачной инфраструктуры и принятию на вооружение продуктов DeepSeek, сообщает блог IEEE Comsoc. Наличие у тройки лидеров крупнейшей в КНР облачной инфраструктуры позволяет обслуживать и другие облачные компании, а также предлагать собственные облачные сервисы конечным пользователям. В частности, их дата-центрами пользуется Alibaba. А собственная развитая сетевая инфраструктура позволяет снизить себестоимость услуг связи. Более того, другим операторам за передачу данных приходится платить именно «большой тройке» по рыночным ценам. Как считают в Goldman Sachs, в некоторых компаниях, предоставляющих в КНР услуги IaaS, например, QingCloud Technology на ЦОД и услуги связи уходит 50–60 % от общих расходов. «Большая тройка» сделала ставку на решения DeepSeek, поэтому имеют все шансы воспользоваться преимуществами раннего внедрения этих ИИ-технологий. При этом государство активно поддерживает использование ИИ на государственных предприятиях, на которые приходится до 30 % выручки телеком-операторов. В последние три недели операторы начали помогать ключевым клиентам в развёртывании LLM DeepSeek. China Mobile поддерживает PetroChina в развертывании полнофункциональной модели, China Telecom предоставляет ту же услугу Sinopec, а China Unicom сотрудничает с Фошаньским муниципальным бюро промышленности и информационных технологий. 
Источник изображения: Eric Prouzet/unsplash.com Более того, 21 февраля Комитет по контролю и управлению государственным имуществом Китая (SASAC) инициировала реализацию плана AI+, призванного стимулировать разработку и коммерческое применение ИИ китайскими государственными предприятиями. China Mobile также объявила, что использует ИИ для преобразования своих телекоммуникационных сетей в рамках стратегии AI+NETWORK, ориентированной на интеграцию ИИ в сетевую инфраструктуру.
26.02.2025 [17:15], Руслан Авдеев
Триумф ИИ-моделей DeepSeek подстегнул спрос на ускорители NVIDIA H20 в КитаеКитайские техногиганты Alibaba, ByteDance и Tencent наращивают закупки урезанных ускорителей NVIDIA H20. Даже ослабленные чипы весьма востребованы китайским бизнесом для обеспечения работы ИИ-моделей, сообщает Reuters. Это опровергает опасения относительно падения спроса на фоне того, что модели DeepSeek для обучения и инференса требуют гораздо менее производительного оборудования. Несмотря на введённые США экспортные ограничения в отношении Китая, запрещающие поставки наиболее передовых ускорителей, NVIDIA продала в 2024 году около 1 млн чипов H20, выручив порядка $12 млрд. Это свидетельствует о том, что спрос на строительство ИИ-инфраструктуры в Китае по-прежнему высок. Стоимость H20 составляет $12-15 тыс., но модель стала критически важным компонентом в гонке китайских ИИ-платформ после новых ограничений, введённых в отношении КНР в 2023 году. Кроме того, есть риск, что новая администрация США запретит продажи Китаю ускорителей H20. Источник изображения: NVIDIA Спрос на вычислительные ИИ-мощности в Китае подстегнул триумф местного стартапа DeepSeek, представившего удивительно экономичные и эффективные ИИ-модели. Закупки наращивают Alibaba, ByteDance и Tencent, в частности, для облачных сервисов на базе DeepSeek-R1. ИИ-серверы на базе H20 с DeepSeek также востребованы медицинскими организациями и образовательными ведомствами. Ускорители Huawei Ascend тоже активно закупаются для снижения зависимости от американских технологий. И хотя они не слишком хороши в обучении моделей в сравнении с продуктами NVIDIA, для инференса их возможностей хватает, а это одна из ключевых ИИ-нагрузок. Инференс-платформы для DeepSeek предлагают и американские компании Cerebras и SambaNova.
24.02.2025 [12:22], Сергей Карасёв
SambaNova развернула самую быструю инференс-платформу для ИИ-модели DeepSeek-R1 671BКомпания SambaNova объявила о том, что в её облаке SambaNova Cloud стала доступна большая языковая модель DeepSeek-R1 с 671 млрд параметров. При этом благодаря применению фирменных ускорителей SN40L обеспечивается рекордно высокая скорость инференса. Изделия SambaNova SN40L RDU (Reconfigurable Dataflow Unit) состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM и 64 Гбайт памяти HBM3. Восьмипроцессорная система на базе SN40L, по заявлениям SambaNova, способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256k. Платформа SambaNova Cloud при использовании DeepSeek-R1 671B демонстрирует производительность до 198 токенов в секунду, что на сегодняшний день является рекордным показателем. Для сравнения: у ближайшего конкурента — Together AI — результат составляет 98 токенов в секунду, а у Microsoft Azure — 20 токенов в секунду. Ранее Cerebras объявила о собственном рекорде — до 1508 токенов/с, но для гораздо более скромной и, по мнению компании, практичной модели DeepSeek-R1-Distill-Llama-70B. 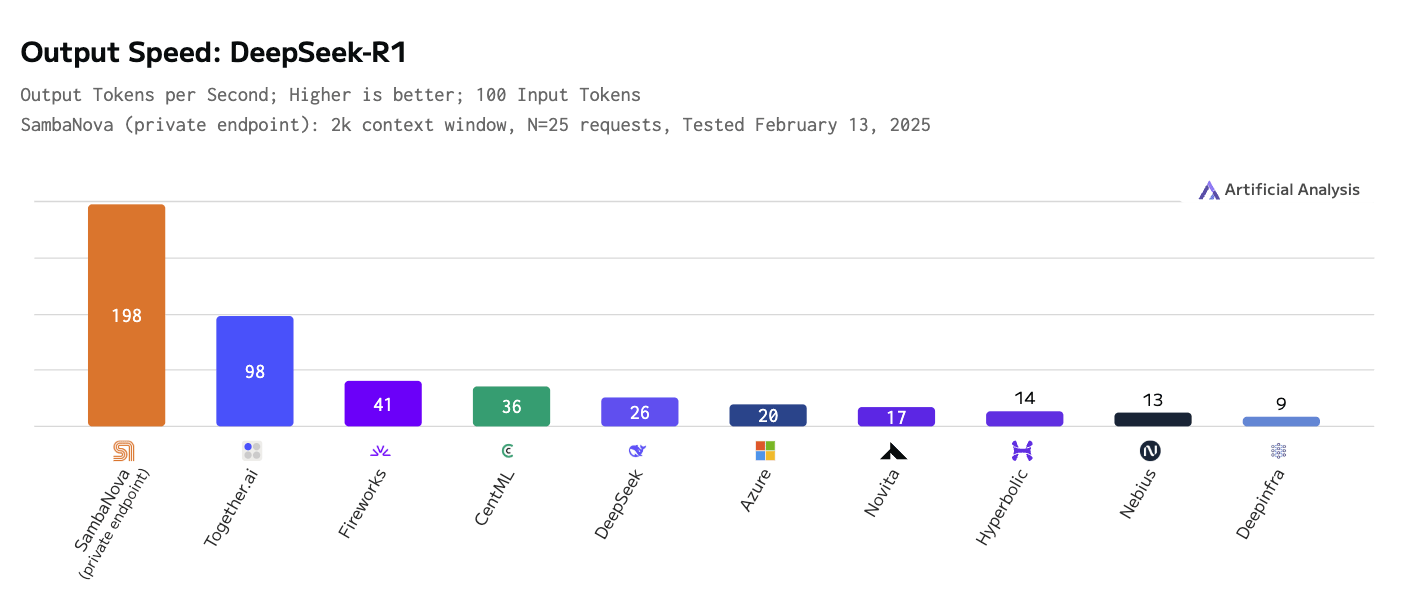
Источник изображения: SambaNova Утверждается, что ускорители SambaNova SN40L RDU по сравнению с новейшими GPU обеспечивают в три раза большую производительность и в пять раз более высокую эффективность. В частности, по заявлениям SambaNova, одна стойка с 16 экземплярами SN40L RDU по быстродействию сопоставима с 40 стойками, насчитывающими в общей сложности 320 передовых GPU. Таким образом, существенно сокращаются затраты на использование DeepSeek-R1 671B. Доступ к DeepSeek-R1 671B в облаке SambaNova Cloud предоставляется посредством API. В перспективе компания планирует наращивать вычислительные мощности, обеспечив производительность на уровне 20 000 токенов в секунду.
17.02.2025 [17:42], Руслан Авдеев
Исследователи DeepMind предложили распределённое обучение больших ИИ-моделей, которое может изменить всю индустриюПосле того, как ИИ-индустрия немного отошла от шока, вызванного неожиданным триумфом китайской DeepSeek, эксперты пришли к выводу, что отрасли, возможно, придётся пересмотреть методики обучения моделей. Так, исследователи DeepMind заявили о модернизации распределённого обучения, сообщает The Register. Недавно представившая передовые ИИ-модели DeepSeek вызвала некоторую панику в США — компания утверждает, что способна обучать модели с гораздо меньшими затратами, чем, например, OpenAI (что оспаривается), и использованием относительно небольшого числа ускорителей NVIDIA. Хотя заявления компании оспариваются многими экспертами, индустрии пришлось задуматься — насколько эффективно тратить десятки миллиардов долларов на всё более масштабные модели, если сопоставимых результатов можно добиться в разы дешевле, с использованием меньшего числа энергоёмких ЦОД. Дочерняя структура Google — компания DeepMind опубликовала результаты исследования, в котором описывается методика распределённого обучения ИИ-моделей с миллиардами параметров с помощью удалённых друг от друга кластеров при сохранении необходимого уровня качества обучения. В статье «Потоковое обучение DiLoCo с перекрывающейся коммуникацией» (Streaming DiLoCo with overlapping communication) исследователи развивают идеи DiLoCo (Distributed Low-Communication Training или «распределённое обучение с низким уровнем коммуникации»). Благодаря этому модели можно будет обучать на «островках» относительно плохо связанных устройств. 
Источник изображения: Igor Omilaev/unsplash.com Сегодня для обучения больших языковых моделей могут потребоваться десятки тысяч ускорителей и эффективный интерконнект с большой пропускной способностью и низкой задержкой. При этом расходы на сетевую часть стремительно растут с увеличением числа ускорителей. Поэтому гиперскейлеры вместо одного большого кластера создают «острова», скорость сетевой коммуникации и связность внутри которых значительно выше, чем между ними. DeepMind же предлагает использовать распределённые кластеры с относительно редкой синхронизацией — потребуется намного меньшая пропускная способность каналов связи, но при этом без ущерба качеству обучения. Технология Streaming DiLoCo представляет собой усовершенствованную версию методики с синхронизацией подмножеств параметров по расписанию и сокращением объёма подлежащих обмену данных без потери производительности. Новый подход, по словам исследователей, требует в 400 раз меньшей пропускной способности сети. 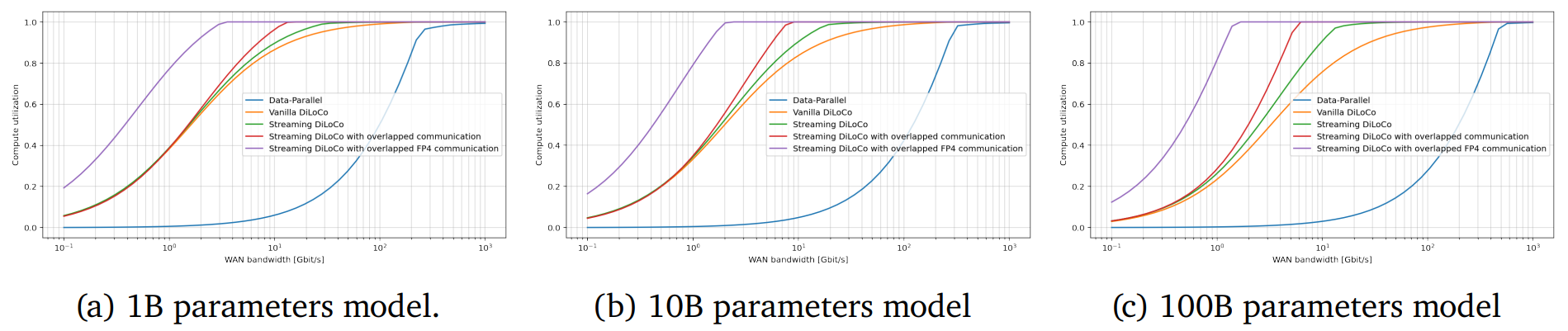
Источник изображения: DeepMind Важность и потенциальную перспективность DiLoCo отмечают, например, и в Anthropic. В компании сообщают, что Streaming DiLoCo намного эффективнее обычного варианта DiLoCo, причём преимущества растут по мере масштабирования модели. В результате допускается, что обучение моделей в перспективе сможет непрерывно осуществляться с использованием тысяч разнесённых достаточно далеко друг от друга систем, что существенно снизит порог входа для мелких ИИ-компаний, не имеющих ресурсов на крупные ЦОД. В Gartner утверждают, что методы, уже применяемые DeepSeek и DeepMind, уже становятся нормой. В конечном счёте ресурсы ЦОД будут использоваться всё более эффективно. Впрочем, в самой DeepMind рассматривают Streaming DiLoCo лишь как первый шаг на пути совершенствования технологий, требуется дополнительная разработка и тестирование. Сообщается, что возможность объединения многих ЦОД в единый виртуальный мегакластер сейчас рассматривает NVIDIA, часть HPC-систем которой уже работает по схожей схеме.
03.02.2025 [15:21], Сергей Карасёв
Реальные затраты DeepSeek на создание ИИ-моделей на порядки выше заявленных, но достижений компании это не умаляетКитайский стартап DeepSeek наделал много шума в Кремниевой долине, анонсировав «рассуждающую» ИИ-модель DeepSeek R1 c 671 млрд параметров. Утверждается, что при её обучении были задействованы только 2048 ИИ-ускорителей NVIDIA H800, а затраты на данные работы составили около $6 млн. Это бросило вызов многим западным конкурентам, таким как OpenAI, а акции ряда крупных ИИ-компаний начали падать в цене. Однако, как сообщает ресурс SemiAnalysis, фактические расходы DeepSeek на создание ИИ-инфраструктуры и обучение нейросетей могут быть гораздо выше. Стартап DeepSeek берёт начало от китайского хедж-фонда High-Flyer. В 2021 году, ещё до введения каких-либо экспортных ограничений, эта структура приобрела 10 тыс. ускорителей NVIDIA A100. В мае 2023 года с целью дальнейшего развития направления ИИ из High-Flyer была выделена компания DeepSeek. После этого стартап начал более активное расширение вычислительной ИИ-инфраструктуры. По данным SemiAnalysis, на сегодняшний день DeepSeek имеет доступ примерно к 10 тыс. изделий NVIDIA H800 и 10 тыс. NVIDIA H100. Кроме того, говорится о наличии около 30 тыс. ускорителей NVIDIA H20, которые совместно используются High-Flyer и DeepSeek для обучения ИИ, научных исследований и финансового моделирования. Таким образом, в общей сложности DeepSeek может использовать до 50 тыс. ускорителей NVIDIA при работе с ИИ, что в разы больше заявленной цифры в 2048 ускорителей. 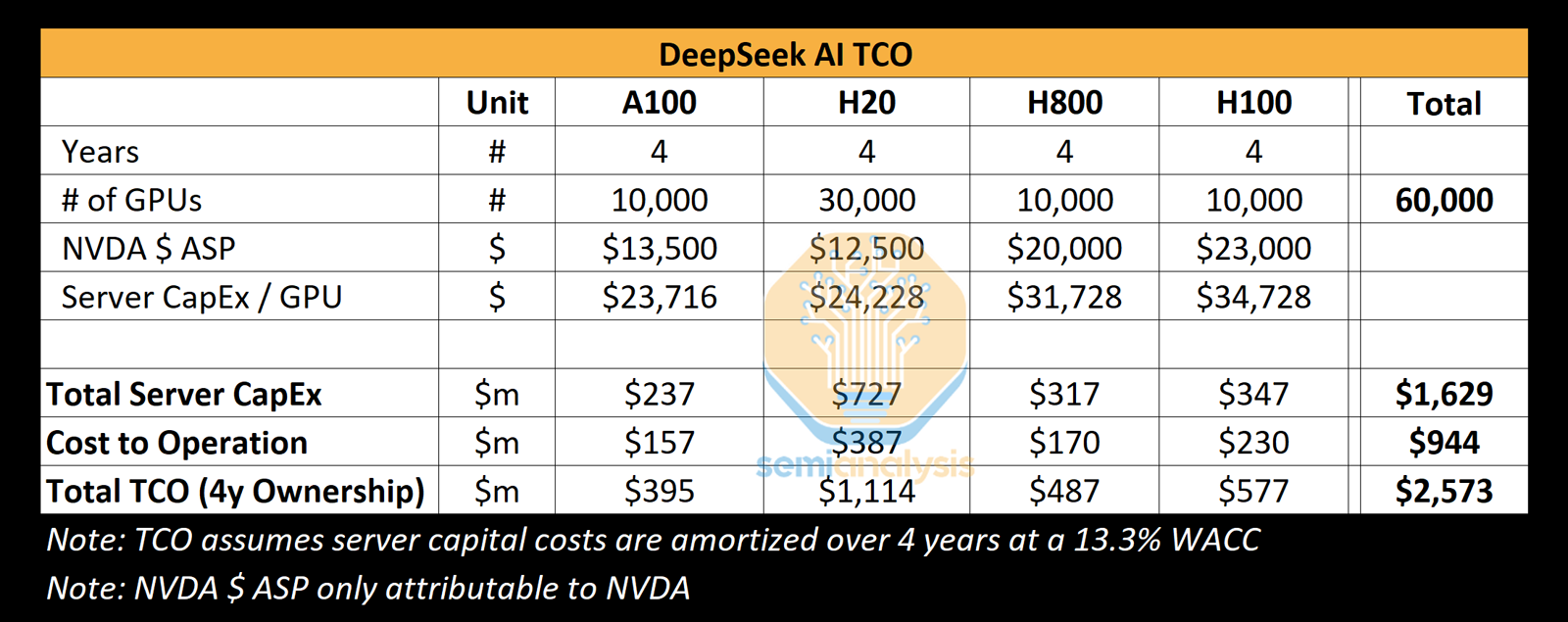
Источник изображения: SemiAnalysis Кроме того, SemiAnalysis сообщает, что общие капитальные затраты на ИИ-серверы для DeepSeek составили около $1,6 млрд, тогда как операционные расходы могут достигать $944 млн. Это подрывает заявления о том, что DeepSeek заново изобрела процесс обучения ИИ и инференса с существенно меньшими инвестициями, чем лидеры отрасли. Цифра в $6 млн не учитывает затраты на исследования, тюнинг модели, обработку данных и пр. На самом деле, как подчёркивается, DeepSeek потратила более $500 млн на разработки с момента своего создания. И всё же DeepSeek имеет ряд преимуществ перед другими участниками глобального ИИ-рынка. В то время как многие ИИ-стартапы полагаются на внешних поставщиков облачных услуг, DeepSeek эксплуатирует собственные дата-центры, что позволяет быстрее внедрять инновации и полностью контролировать разработку, оптимизируя расходы. Кроме того, DeepSeek остаётся самофинансируемой компанией, что обеспечивает гибкость и позволяет более оперативно принимать решения. Плюс к этому DeepSeek нанимает специалистов исключительно из Китая, уделяя особое внимание не формальным записям в аттестатах, а практическим навыкам работы и способностям эффективно выполнять поставленные задачи. Некоторые ИИ-исследователи в DeepSeek зарабатывают более $1,3 млн в год, что говорит об их высочайшей квалификации.
03.02.2025 [09:20], Руслан Авдеев
The Register: Успех DeepSeek показал важность обдуманных инвестиций в ИИ, но потребность в развитии инфраструктуры никуда не денетсяШок, вызванный недавним триумфом китайского ИИ-стартапа DeepSeek, представившего дешёвые и эффективные ИИ-модели, заставил многих усомниться в результативности масштабных вложений в инфраструктуру на базе дорогих ИИ-ускорителей, сообщает The Register. Тем не менее эксперты уверены, что отказываться от инвестиций было бы нецелесообразно. На прошлой неделе акции ряда крупнейших американских ИИ-брендов после дебюта весьма эффективной модели DeepSeek R1, использующей, со слов создателей, сравнительно мало ускорителей NVIDIA, буквально обрушились в цене. Из-за этого многие эксперты усомнились в том, что траты миллиардов на аппаратную инфраструктуру для ИИ себя оправдывают, если Китай способен добиться хороших результатов, используя не самое мощное оборудование. Например, NVIDIA «в моменте» потеряла $600 млрд рыночной стоимости. Настоящая истерия наложилась на растущее беспокойство в связи с тем, что всё больше денег тратится на инфраструктуру и её поддержку, а особенной отдачи пока не видно. Впрочем, паника может быть неуместной, поскольку обрушение акций прекратилось, а DeepSeek обвиняется в использовании ИИ-моделей Anthropic и OpenAI. Как отмечает The Register, нет и реальных подтверждений того, что производительность моделей DeepSeek находится на уровне лучших из актуальных моделей, а также того, что на обучение китайского ИИ ушло всего $6 млн. По оценкам SemiAnalysis, доступная DeepSeek инфраструктура гораздо больше, чем утверждает компания, и стоит более чем $1,5 млрд. 
Источник изображения: Etienne Girardet/unsplash.com По словам экспертов Omdia, опасения относительно «сокрушительных» инноваций DeepSeek сильно преувеличены. В компании подтверждают, что китайский стартап использовал некоторые «гениальные инновации», но они приведут лишь к массовому использованию аналогичных решений и строительству новой ИИ-инфраструктуры. В Omdia прогнозируют, что в ближайшие годы рынок ИИ-инфраструктуры, скорее всего, значительно вырастет. В компании полагают, что до 2028 года поставки серверов для инференса будут расти на 17 % ежегодно. В TrendForce придерживаются несколько иного мнения и предполагают, что в будущем организации всё же станут более строго оценивать инвестиции в инфраструктуру ИИ и станут применять более эффективные модели для того, чтобы снизить зависимость от доступности ускорителей. Также не исключается, что чаще будут использоваться кастомные ASIC вместо сторонних ИИ-ускорителей и спрос на «классические» модели может претерпеть с 2025 года заметные изменения. Если раньше индустрия полагалась в первую очередь на масштабирование моделей, увеличение объёмов данных и повышение производительности оборудования, то теперь стратегия меняется. DeepSeek прибегла к «дистилляции» моделей, повышению скорости инференса и снижения зависимости от оборудования. Не так давно генеральный директор IBM Арвинд Кришна (Arvind Krishna) объявил, что деятельность DeepSeek подтвердила правильность подхода к ИИ его собственной компании, считающей, что модели могут быть меньше, как и время их обучения. При использовании подобных подходов затраты на инференс могут снизиться в 30 раз, что очень хорошо для корпоративных клиентов. Ещё в 2023 году компания начала развивать серию «экономичных» базовых моделей Granite. Вероятно, по этому пути пойдут и другие. 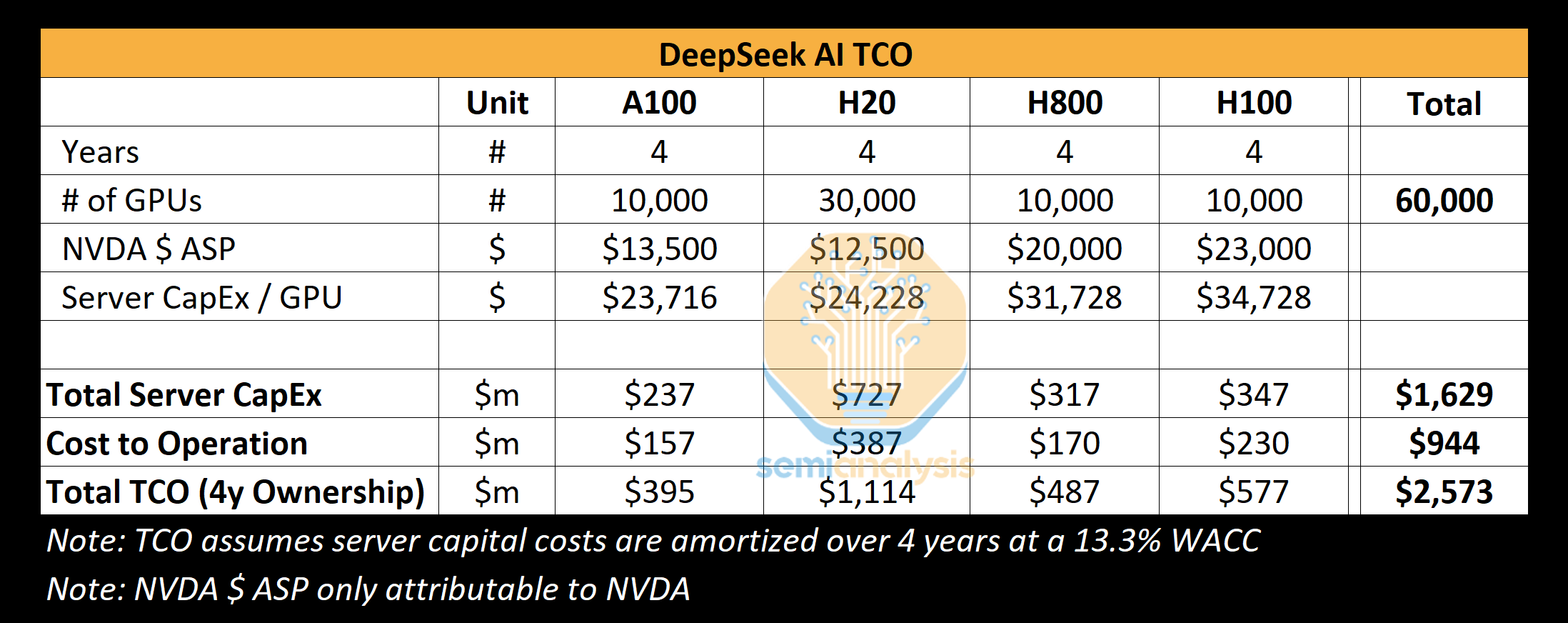
Источник изображения: SemiAnalysis Gartner также сообщает, что именно эффективное масштабирование ИИ будет целесообразнее простого наращивания вычислительных ресурсов. Впрочем, китайский ИИ не устанавливает новый стандарт эффективности моделей, поскольку те соответствуют показателям уже существующих, но не превосходят их. Кроме того, нет доказательств, что добавление дополнительных вычислительных ресурсов и данных не имеет значения. The Register прогнозирует, что продукты и технологии DeepSeek не вызовут резкого падения спроса на ИИ-инфраструктуру, поэтому инвесторам NVIDIA и строителям ЦОД, вероятно, можно не бояться того, что «пузырь» ИИ лопнет, как этого ожидают некоторые эксперты. Во всяком случае одни из крупнейших инвесторов в сектор ЦОД — Blackstone и Brookfield — заявили, что следят за успехами DeepSeek, но отказываться от инвестиций не собираются. Тем не менее, успех китайского стартапа напоминает о том, что «всегда можно сделать ещё лучше» и экстенсивное вливание денег и вычислительных ресурсов не всегда лучший вариант.
01.02.2025 [15:23], Сергей Карасёв
Самый быстрый инференс DeepSeek R1 в мире: ИИ-платформа Cerebras снова поставила рекорд производительностиАмериканский стартап Cerebras Systems объявил о том, что его инференс-платформа позволила установить мировой рекорд производительности при использовании «рассуждающей» ИИ-модели DeepSeek R1 в модификации с 70 млрд параметров (DeepSeek-R1-Distill-Llama-70B). DeepSeek R1 может содержать до 671 млрд параметров. Однако, как отмечает Cerebras, развёртывание модели со способностью к рассуждению столь большого масштаба представляет значительные проблемы. Версия с 70 млрд параметров позволяет совместить возможности рассуждений более крупной модели с MoE с широко поддерживаемой архитектурой Meta✴ Llama. 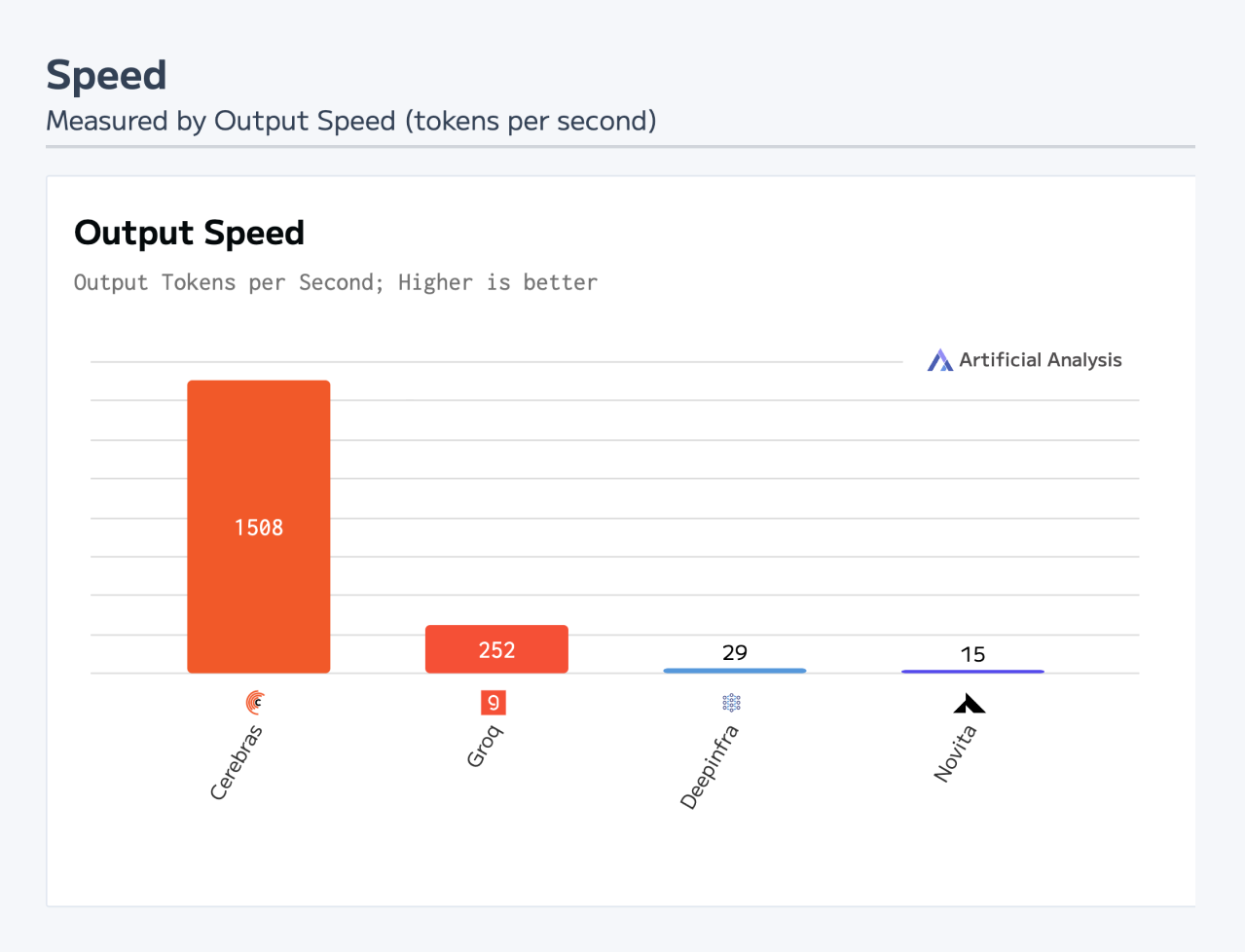
Источник изображений: Cerebras Основой платформы Cerebras являются царь-ускорители собственной разработки WSE (Wafer Scale Engine). Производительность DeepSeek R1 при работе на инфраструктуре Cerebras достигает 1508 токенов в секунду — это значительно быстрее по сравнению с конкурирующими решениями. В частности, в случае Groq показатель составляет 252 токена в секунду. Стандартный запрос на генерацию кода, который, как утверждает компания, занимает 22 секунды на конкурирующих платформах, в случае Cerebras завершается всего за 1,5 секунды, что соответствует 15-кратному повышению производительности. Cerebras подчёркивает, что DeepSeek-R1-Distill-Llama-70B превосходит как GPT-4o, так и o1-mini в сложных математических задачах и генерации кода. 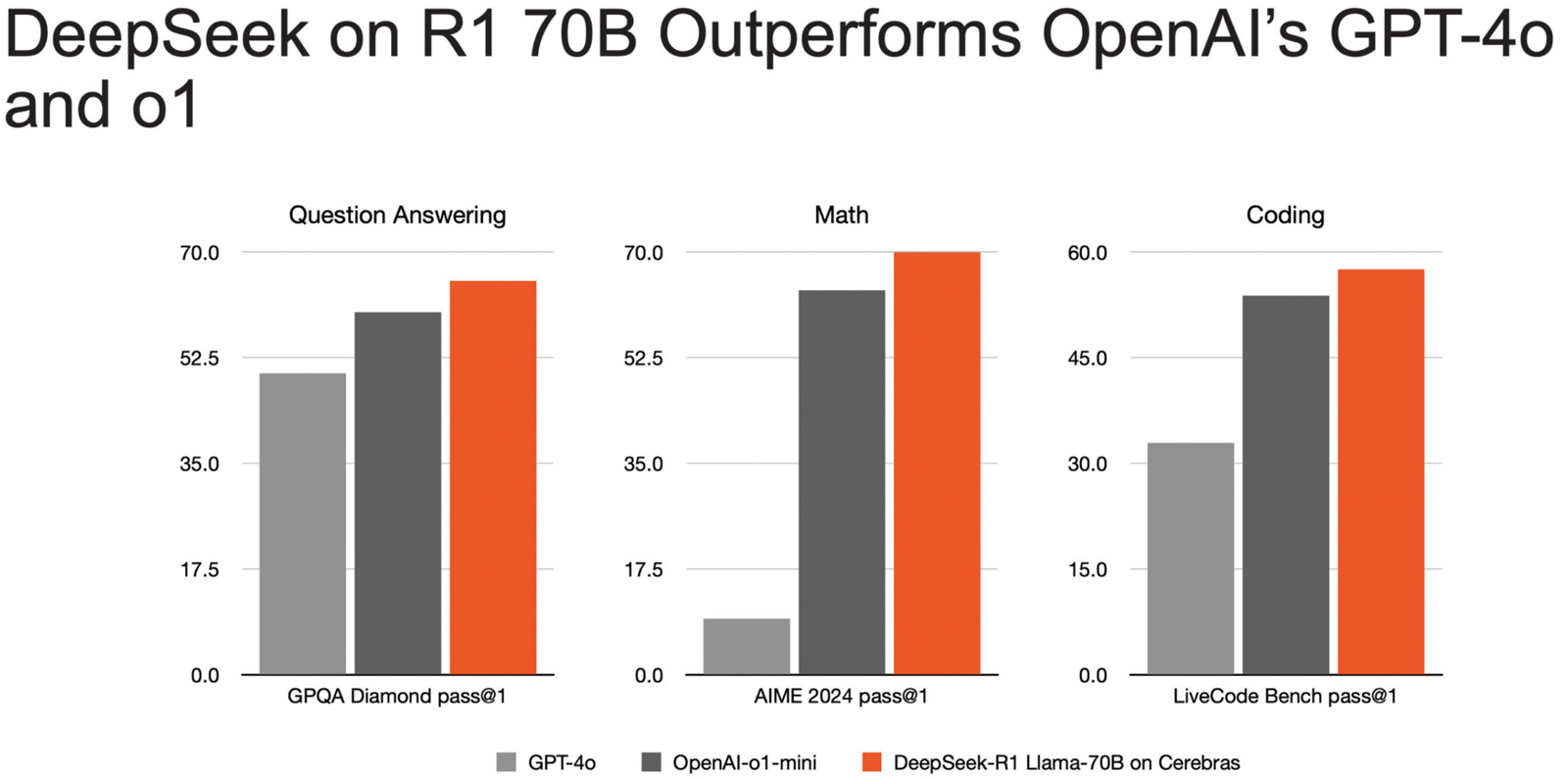 Cerebras также отмечает, что все вычисления осуществляются на базе ИИ-инфраструктуры в США, развёрнутой в собственных дата-центрах компании. При этом никакие данные не сохраняются, что гарантирует полную безопасность для клиентов. Кроме того, модель DeepSeek R1 может быть развёрнута локально в ЦОД заказчика для обеспечения максимального контроля.
31.01.2025 [16:44], Руслан Авдеев
США подозревают DeepSeek в получении подсанкционных ИИ-ускорителей NVIDIA через посредников в СингапуреАмериканские власти намерены выяснить, не покупал ли китайский ИИ-стартап DeepSeek передовые ускорители NVIDIA у сингапурских компаний в обход введённых США санкций. Недавно китайская компания представила модели R1 и V3, в некоторых отношениях сопоставимые по возможностям с американскими решениями или даже превосходящие их, при этом гораздо более дешёвых. Это косвенно свидетельствует о том, что ИИ в Китае развивается гораздо успешнее, чем считалось, сообщает Bloomberg. Эксперты уже отметили экономическую эффективность и производительность бота, а соперники задумались, не имели ли стартап доступ к подсанкционным западным технологиям. Представители Белого дома и ФБР пытаются выяснить, мог ли DeepSeek воспользоваться услугами посредников из Сингапура для покупки чипов NVIDIA, запрещённых к официальным поставкам в КНР. В самой китайской компании не ответили на запрос журналистов, а в NVIDIA заявили, что её партнёры соблюдают все соответствующие законы. Если появится информация об обратном, NVIDIA будет «действовать соответствующим образом». Ранее компания предположила, что DeepSeek не нарушает американских санкций. В Министерстве торговли США полагают, что DeepSeek обошла экспортные ограничения на чипы NVIDIA, закупая их «тоннами». Чиновники заявили: если китайская компания хочет конкурировать, пусть делает это без использования американских инструментов, и пообещали проводить жёсткую политику в отношении экспортного контроля. Однако самая ситуация привела к дебатам об эффективности американских попыток отрезать КНР от передовых технологий. Ограничения, касающиеся самых передовых ускорителей и инструментов для их производства, должны были замедлить развитие ИИ в Китае. 
Источник изображения: Joshua Wordel / Unsplash DeepSeek утверждает, что для обучения моделей она использовала 10 тыс. ускорителей NVIDIA A100 и 2048 ускорителей NVIDIA H800 с «урезанной» функциональностью, выпускавшихся специально для Китая. В октябре 2023 года власти США запретили продавать в Китай и H800, поэтому NVIDIA выпустила ещё более слабые ускорители H20 для этого рынка. Теперь ведутся дискуссии, стоит ли запретить продавать в КНР и их. В 2023 году США ввели ограничения в отношении более 40 стран, которые могли служить посредниками для переправки ускорителей в Китай. Запрет коснулася большинства стран Ближнего Востока и ряда государств Юго-Восточной Азии, но Сингапур в их число не вошёл. В 2025 году действие ограничений расширили на большую часть планеты — за исключением горстки союзников. Теперь крупные поставки в Сингапур требуют специальной разрешения. Важно, что на Сингапур приходится около 20 % выручки NVIDIA, но, по некоторым данным, большинство заказов фактически уходит в другие регионы, а в сам город-государство поступало довольно мало ускорителей. В NVIDIA настаивают, что огромная выручка от торговли с Сингапуром не связана с утечкой в Китай. В компании заявляют, что многие компании имеют структуры в Сингапуре, которые выпускают продукты, предназначенные для США и Запада в целом. Впрочем, члены Палаты представителей США от обеих правящих партий уже обратились к советнику президента по национальной безопасности. Они заявили, что необходимо ввести строгое лицензирование экспорта для стран вроде Сингапура, «не желающих пресечь» поставки в Китай.
28.01.2025 [18:40], Владимир Мироненко
«Рынки ошибаются»: DeepSeek не угрожает NVIDIA и другим американским IT-гигантам
deepseek
fortune
hardware
nvidia
анализ рынка
ии
инференс
китай
прогноз
санкции
сша
ускоритель
финансы
Рост популярности ИИ-технологий способствовал росту рыночной стоимости NVIDIA выше $3 трлн. Однако её акции обрушились в понедельник на 17 %, вызвав падение рыночной стоимости компании почти на $600 млрд, после анонса китайским стартапом DeepSeek ИИ-моделей V3 и R1, способных соперничать с лучшими моделями любой американской компании, хотя и были обучены за малую часть стоимости на менее продвинутых чипах NVIDIA H800 и A100, пишет Fortune. Также в начале недели приложение AI Assistant стартапа DeepSeek вышло на первое место в рейтинге самых популярных бесплатных приложений в интернет-магазине в Apple App Store в США, опередив ИИ-чат-бот ChatGPT от OpenAI. Более того, модель DeepSeek R1, призванная бросить вызов модели «рассуждений» OpenAI o1, можно запустить на рабочей станции, а не в ЦОД. Поскольку мощные ускорители NVIDIA являются одной из самых больших статей расходов на разработку самых передовых моделей ИИ, инвесторы начали пересматривать свои представления относительно вложений в ИИ-бизнес. Да, DeepSeek явно потряс рынок ИИ, однако разговоры о крахе NVIDIA могут быть преждевременными, равно как и заявления о том, что успех DeepSeek означает, что США следует отказаться от политики, направленной на ограничение доступа Китая к самым передовым ИИ-чипам, предупреждают аналитики Fortune. DeepSeek утверждает, что использует 10 тыс. ускорителей NVIDIA A100, а также чипы H800, что на порядок меньше, чем используют американские компании для обучения своих самых передовых ИИ-моделей. Например, Xai Илона Маска (Elon Musk) построила вычислительный кластер Colossus в Теннесси на базе 100 тыс. ускорителей NVIDIA H100, его планирует расширить до 1 млн чипов. 
Источник изображения: Heather Wilde / Unsplash Это дало повод некоторым экспертам утверждать, что введение ограничений США подстегнуло инновации в Китае. В Fortune считают такие умозаключения недальновидными и утверждают, что влияние DeepSeek может, как это ни парадоксально звучит на первый взгляд, увеличить спрос на передовые чипы ИИ — как NVIDIA, так и её конкурентов. Причина отчасти заключена в феномене, известном как парадокс Джевонса (Jevons Paradox). Парадокс Джевонса, также известный как эффект отскока, назван в честь британского экономиста XIX века Уильяма Стэнли Джевонса (William Stanley Jevons), который заметил: когда технический прогресс делает использование ресурса более эффективным, общее потребление этого ресурса имеет тенденцию к увеличению. Это имеет смысл, если спрос на что-либо относительно эластичен — снижающаяся из-за повышения эффективности цена создаёт ещё больший спрос на продукт. Одной из причин слабого внедрения ИИ-моделей в крупных организациях была их дороговизна. Это особенно касалось новых «рассуждающих» моделей, таких как o1 от OpenAI. Модели DeepSeek гораздо дешевле конкурентов в эксплуатации, так что теперь компании могут позволить себе развёртывать их для многих сценариев использования. В масштабах отрасли это может привести к резкому росту спроса на вычислительную мощность. В понедельник гендиректор Microsoft Сатья Наделла (Satya Nadella) и бывший гендиректор Intel Пэт Гелсингер (Pat Gelsinger) указали на это в сообщениях в социальных сетях. Наделла напрямую сослался на парадокс Джевонса, в то время как Гелсингер сказал, что «вычисления подчиняются» тому, что он назвал «законом газа». «Если сделать его значительно дешевле, рынок для него расширится… это сделает ИИ гораздо более широко распространенным, — написал он. — Рынки ошибаются». 
Источник изображения: Mark Daynes / Unsplash В Fortune задались вопросом: «Какая именно вычислительная мощность потребуется?». Топовые ускорители NVIDIA оптимизированы для обучения крупнейших больших языковых моделей (LLM), таких как GPT-4 от OpenAI или Claude 3-Opus от Anthropic. Для инференса чипы NVIDIA меньше подходят, чем изделия конкурентов, включая AMD и, например, Groq, чипы которых позволяют исполнять ИИ-нагрузки быстрее и намного эффективнее. Google и Amazon также создают свои собственные чипы ИИ, некоторые из которых оптимизированы для инференса. NVIDIA сейчас занимает более 80 % рынка ИИ-вычислений на базе ЦОД (если исключить кастомные ASIC облачных провайдеров, её доля может составить до 98 %) и вряд ли утратит доминирование быстро или полностью, отметили в Fortune. Ёе ускорители также могут использоваться для инференса, а программная платформа CUDA имеет большое и лояльное сообщество разработчиков, которое вряд ли откажется от него в одночасье. Если общий спрос на ИИ-чипы увеличится из-за парадокса Джевонса, общие доходы NVIDIA всё равно смогут вырасти даже при падении доли на рынке из-за увеличившегося рынка. Ещё одна причина, по которой спрос на передовые ИИ-чипы, вероятно, продолжит рост, связана с особенностями работы моделей рассуждений, таких как R1. В то время как способности предыдущих типов LLM росли по мере увеличения доступной вычислительной мощности во время обучения, то модели рассуждений зависят от вычислительных ресурсов во время инференса — чем их больше, тем лучше ответы. 
Источник изображения: Kayla Kozlowski / Unsplash Запустив R1 на ноутбуке, можно получить хороший ответ на сложный математический вопрос, скажем, через час, в то время как при использовании ускорителей в облаке на тот же ответ уйдут считанные секунды. Для многих бизнес-приложений задержка или время, необходимое модели для ответа, имеет большое значение. И чтобы сократить время выполнения задачи, по-прежнему будут нужны передовые ИИ-ускорители. Кроме того, многие эксперты сомневаются в правдивости заявления DeepSeek о том, что её модель V3 была обучена примерно на 2048 урезанных ускорителях NVIDIA H800 или что её модель R1 была обучена на столь малом количестве чипов. Александр Ван (Alexandr Wang), генеральный директор Scale AI, сообщил в интервью CNBC, что, по его данным, DeepSeek тайно получила доступ к кластеру из 50 тыс. ускорителей H100. Также известно, что хедж-фонд HighFlyer, которому принадлежит DeepSeek, успел закупить до введения санкций значительное количество менее производительных ускорителей NVIDIA. Так что вполне возможно, что NVIDIA находится в лучшем положении, чем предполагают паникующие инвесторы, и что проблема с экспортным контролем США заключается не в политике, а в её реализации, подытожили аналитики Fortune. |
|

