Материалы по тегу: ии
|
31.12.2024 [14:05], Владимир Мироненко
Национальный координационный центр по компьютерным инцидентам ФСБ и Positive Technologies перезаключили соглашение о сотрудничествеНациональный координационный центр по компьютерным инцидентам (НКЦКИ) ФСБ и Positive Technologies заключили новое бессрочное соглашение о сотрудничестве в области обнаружения, предупреждения и ликвидации последствий компьютерных атак, расторгнутое в ноябре по инициативе НКЦКИ, объяснившего свое решение отсутствием взаимодействия по предусмотренным соглашением направлениям. В Positive Technologies назвали расторжение договора «плановой активностью», о которой она была уведомлена заранее, связанной с тем, что НКЦКИ «меняет требования к обязанностям корпоративных центров ГосСОПКА». О заключении нового договора сообщается на сайте Государственной системы обнаружения, предупреждения и ликвидации последствий компьютерных атак (ГосСОПКА). В своём объявлении НКЦКИ также уведомляет госструктуры и иные организации, являющиеся субъектами критической информационной инфраструктуры РФ о возможности привлечения по вопросам обнаружения, предупреждения и ликвидации последствий компьютерных атак АО «Позитивные технологии» в качестве центра ГосСОПКА класса А. 
Источник изображения: Markus Spiske/unsplash.com «НКЦКИ подтверждает, что все субъекты КИИ Российской Федерации могут продолжать передавать работы по обнаружению, предупреждению и ликвидации последствий компьютерных атак в Positive Technologies, являющуюся старейшим центром ГосСОПКА класса А», — сообщили в Positive Technologies. Управляющий директор Positive Technologies назвал в интервью Forbes подписанное соглашение первым в этом плане у НКЦКИ, который перезаключит договоры со всеми центрами ГосСОПКА: «Регулятор изменил требования к обязанностям корпоративных центров ГосСОПКА, которые зафиксированы в таких соглашениях, и запустил процесс их переподписания со всеми центрами ГосСОПКА в соответствии с историческим таймингом их появления». Согласно исследованию Центра стратегических решений, общий объём рынка услуг кибербезопасности в 2023 году вырос на 31,1 %, до 65,9 млрд руб. Как сообщили в Positive Technologies, на услуги, которые может оказывать субъектам КИИ центр ГосСОПКА класса А, приходится треть этого объёма.
31.12.2024 [14:02], Сергей Карасёв
NVIDIA закрыла сделку по покупке Run:ai: исходный код ПО стартапа будет открытNVIDIA завершила сделку по приобретению стартапа Run:ai, разрабатывающего ПО для управления рабочими нагрузками ИИ и оркестрации на базе Kubernetes. Стоимость купленной компании, по оценкам, составила около $700 млн. О поглощении Run:ai корпорация NVIDIA объявила в апреле 2024 года. Но сделка вызвала вопросы у американских и европейских регуляторов. Дело в том, что NVIDIA доминирует на мировом ИИ-ускорителей с долей примерно 80 %. Высказывались предположения, что NVIDIA приобретает Run:ai с тем, чтобы в дальнейшем поставить крест на технологиях стартапа, которые сокращают потребность в ИИ-ускорителях и тем самым могут негативно повлиять на продажи продуктов NVIDIA. Антимонопольный орган Евросоюза изучал вопросы, связанные с тем, ставит ли сделка под угрозу конкуренцию на рынках, где работают компании. В результате, регулятор пришёл к выводу, что деятельность NVIDIA и Run:ai не пересекается, а поэтому слияние не создаст проблем с конкуренцией в Европейской экономической зоне. Еврокомиссия одобрила сделку, и теперь все необходимые процедуры завершены. 
Источник изображения: Run:ai В заявлении Run:ai говорится, что стартап намерен открыть исходный код своего ПО, чтобы «помочь сообществу в создании лучшего ИИ». Наблюдатели отмечают, что данный шаг призван развеять опасения, касающиеся монополизации рынка. «Хотя в настоящее время Run:ai поддерживает только GPU NVIDIA, открытие исходного кода позволит расширить доступность решений для всей экосистемы ИИ», — заявляет стартап. Отмечается, что в составе NVIDIA компания Run:ai продолжит развивать своё семейство продуктов, расширять штат и укреплять положение на рынке. Цель Run:ai остаётся прежней — оказывать помощь клиентам в извлечении максимальной пользы из своей инфраструктуры ИИ. Стартап намерен укреплять партнёрские отношения и взаимодействовать с участниками экосистемы, чтобы предоставлять широкий спектр решений ИИ и вариантов платформ.
30.12.2024 [15:59], Руслан Авдеев
Облачные ИИ-стартапы вряд ли потеснят гиперскейлеров, но всё равно повлияют на нихОблачные ИИ-стартапы вроде xAI, OpenAI, Vultr и др. интенсивно развиваются и уже планируют строить собственную инфраструктуру ИИ-серверов и дата-центров. И они уже влияют на традиционных облачных провайдеров, но заменить их вряд ли смогут, передаёт IEEE ComSoc. xAI построила построила ИИ-кластер Colossus из 100 тыс. ускорителей NVIDIA и готова расширить его до 1 млн ускорителей. Colossus используется для обучения LLM, но также пригодится для создания систем автономного вождения, решений для робототехники и научных исследований. Облако Vultr привлекло $333 млн в недавнем раунде финансирования, источником средств стали AMD и хеджевый фонд LuminArx Capital Management, теперь компания оценивается в $3,5 млрд. Облако CoreWeave уже можно считать «тяжеловесом» — оценка компании достигла $23 млрд, а сама она развивает ЦОД по всему миру. В OpenAI сообщают, что компания построит цифровую инфраструктуру для обучения своих систем, а «чипы, данные и энергия» станут ключевыми факторами для решения задач вроде создания «общего искусственного интеллекта» (AGI), способного превзойти человеческий мозг по сообразительности. Не так давно глава компании Сэм Альтман (Sam Altman) призывал американские власти строить в стране сеть 5-ГВт ЦОД. Имеются данные, что компания намерена строить кластеры ЦОД на Среднем Западе США и юго-западе страны. 
Источник изображения: Maximalfocus/unsplash.com Облачные ИИ-стартапы могут представлять некоторую угрозу гиперскейлерам, поскольку они специализируются исключительно на ИИ и часто работают над специфическими и передовыми решениями именно для этой области, тогда сервисы гиперскейлеров носят более общий характер. Стартапы способны на быстрые инновации в сравнении с неповоротливыми техногигантами и быстро отвечают на запросы нишевых рынков, предлагая уникальные ИИ-инструменты. Также стартапы более экономично расходуют средства, что позволяет им предлагать более гибкие и привлекательные системы ценообразования в сравнении с предложениями гиперскейлеров. Наконец, некоторые просто дополняют своими решениями сервисы гиперскейлеров. При этом такие услуги от новичков со временем могут развиться в более масштабные предложения, способные посягнуть на часть бизнеса партнёров-техногигантов. В то же время гиперскейлеры обладают несопоставимо большей и развитой инфраструктурой. Они обеспечивают высокую производительность, надёжность и глобальный охват, не говоря уж об известности их брендов. Именно на них обычно полагаются крупные корпоративные клиенты. Поэтому стартапы должны предлагать решения, совместимые с уже работающими инструментами, или найти аргументы, чтобы мотивировать компании выбрать новые сервисы с неясным будущим. Таким образом, хотя стартапы, вероятно, получат свои ниши на быстрорастущем рынке ИИ-решений, они смогут состязаться с гиперскейлерами только в отдельных сегментах. Крупные провайдеры располагают инфраструктурой, ресурсами и базами лояльных клиентов для сохранения своих рыночных позиций. Впрочем, со временем ИИ-стартапы, возможно, повлияют на эволюцию традиционных облачных сервисов, заставляя гиперскейлеров поддерживать высокий уровень конкурентоспособности. Небольшая угроза гиперскейлерам вроде AWS, Microsoft Azure и Google Cloud, конечно, есть, но эффект появится только спустя значительное время и вряд ли будет иметь критическое значение.
30.12.2024 [12:56], Сергей Карасёв
Firefly представила серверы CSB1-N10 для создания ИИ-кластеров из одноплатных компьютеровКомпания Firefly Technology, по сообщению ресурса CNX-Software, выпустила серверы серии CSB1-N10 для построения ИИ-кластеров. Устройства, выполненные в форм-факторе 1U, подходят для дата-центров, периферийных развёртываний и локальных площадок. В семейство вошли пять моделей: CSB1-N10S1688, CSB1-N10R3588, CSB1-N10R3576, CSB1-N10NOrinNano и CSB1-N10NOrinNX. Узлы систем оснащены соответственно процессором Sophgo Sophon BM1688 (8 ядер, до 1,6 ГГц), Rockchip RK3588 (8 ядер, до 2,4 ГГц), Rockchip RK3576 (8 ядер, до 2,2 ГГц), NVIDIA Jetson Orin Nano (6 ядер, до 1,5 ГГц) и Jetson Orin NX (8 ядер, до 2,0 ГГц). Первые три из перечисленных узлов комплектуются оперативной памятью LPDDR4 объёмом 8, 16 и 8 Гбайт соответственно, а также флеш-модулем eMMC вместимостью 32, 256 и 64 Гбайт. Варианты Orin оборудованы 8 и 16 Гбайт памяти LPDDR5 и накопителем NVMe SSD на 256 Гбайт. Все серверы содержат десять вычислительных узлов и дополнительный управляющий узел на чипе RK3588. Присутствует слот для SSD с интерфейсом SATA-3. В оснащение входят по два сетевых порта 10GbE (SFP+) и 1GbE (RJ45), выделенный сетевой порт управления 1GbE, аналоговый разъём D-Sub (1080p60), два порта USB 3.0, а также последовательный порт. Применяется воздушное охлаждение. За питание отвечает блок мощностью 550 Вт. Диапазон рабочих температур — от 0 до +45 °C. 
Источник изображения: Firefly Кластер на базе CSB1-N10S1688 обеспечивает ИИ-производительность до 160 TOPS на операциях INT8. В случае CSB1-N10R3588 и CSB1-N10R3576 это показатель составляет 60 TOPS. Эти три системы поддерживают работу с большими языковыми моделями (LLM), а также фреймворками TensorFlow, PyTorch, PaddlePaddle, ONNX, Caffe. В случае CSB1-N10NOrinNano и CSB1-N10NOrinNX быстродействие достигает 400 и 1000 TOPS. Говорится о поддержке LLaMa3 и Phi-3 Mini, фреймворков TensorFlow, PyTorch, Matlab и др. Цена варьируется от $2059 до $14 709.
29.12.2024 [17:40], Владимир Мироненко
Конструктор вместо монолита: NVIDIA дала больше свободы в кастомизации GB300 NVL72Для новых суперускорителей (G)B300 компания NVIDIA существенно поменяла цепочку поставок, сделав её более дружелюбной к гиперскейлерам, то есть основным заказчиком новинок, передаёт SemiAnalysis. В случае GB200 компания поставляла готовые, полностью интегрированные платы Bianca, включающие ускорители Blackwell, CPU Grace, 512 Гбайт напаянной LPDDR5X, VRM и т.д. GB300 будут поставляться в виде модулей: SXM Puck B300, CPU Grace в корпусе BGA, HMC от Axiado (вместо Aspeed). А в качестве системной RAM будут применяться модули LPCAMM, преимущественно от Micron. Переход на SXM Puck даст возможность создавать новые системы большему количеству OEM- и ODM-поставщиков, а также самим гиперскейлерам. Если раньше только Wistron и Foxconn могли производить платы Bianca, то теперь к процессу сборки ускорителей могут подключиться другие. Wistron больше всех потеряет от этого решения, поскольку потеряет долю рынка производителей Bianca. Для Foxconn же, которая благодаря NVIDIA вот-вот станет крупнейшим в мире поставщиком серверов, потеря компенсируется эксклюзивным производством SXM Puck. 
Источник изображений: NVIDIA Еще одно важное изменение касается VRM. Хотя на SXM Puck есть некоторые компоненты VRM, большая часть остальных комплектующих будет закупаться гиперскейлерами и вендорами напрямую у поставщиков VRM. Стоечные NVSwitch-коммутаторы и медный backplane по-прежнему будут поставляться самой NVIDIA. Для GB300 компания предлагает 800G-платформу InfiniBand/Ethernet Quantum-X800/Spectrum-X800 с адаптерами ConnectX-8, которые не попали GB200 из-за нестыковок в сроках запуска продуктов. Кроме того, у ConnectX-8 сразу 48 линий PCIe 6.0, что позволяет создавать уникальные архитектуры, такие как MGX B300A с воздушным охлаждением.  Сообщается, что все ключевые гиперскейлеры уже приняли решение перейти на GB300. Частично это связано с более высокой производительностью и экономичностью GB300, но также вызвано и тем, что теперь они сами могут кастомизировать платформу, систему охлаждения и т.д. Например, Amazon сможет, наконец, использовать собственную материнскую плату с водяным охлаждением и вернуться к архитектуре NVL72, улучшив TCO. Ранее компания единственная из крупных игроков выбрала менее эффективный вариант NVL36 из-за использования собственных 200G-адаптеров и PCIe-коммутаторов с воздушным охлаждением. Впрочем, есть и недостаток — гиперскейлерам придётся потратить больше времени и ресурсов на проектирование и тестирование продукта. Это, пожалуй, самая сложная платформа, которую когда-либо приходилось проектировать гиперскейлерам (за исключением платформ Google TPU), отметил ресурс SemiAnalysis.
28.12.2024 [12:42], Сергей Карасёв
Итальянская нефтегазовая компания Eni запустила суперкомпьютер HPC6 с производительностью 478 ПфлопсИтальянский нефтегазовый гигант Eni запустил вычислительный комплекс HPC6. На сегодняшний день это самый мощный суперкомпьютер в Европе и один из самых производительных в мире: в свежем рейтинге TOP500 он занимает пятую позицию. О подготовке HPC6 сообщалось в начале 2024 года. В основу системы положены процессоры AMD EPYC Milan и ускорители AMD Instinct MI250X. Комплекс выполнен на платформе HPE Cray EX4000 с хранилищем HPE Cray ClusterStor E1000 и интерконнектом HPE Slingshot 11. В общей сложности в состав HPC6 входят 3472 узла, каждый из которых несёт на борту 64-ядерный CPU и четыре ускорителя. Таким образом, суммарное количество ускорителей Instinct MI250X составляет 13 888. Суперкомпьютер обладает FP64-быстродействием 477,9 Пфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 606,97 Пфлопс. Максимальная потребляемая мощность системы составляет 10,17 МВА. Комплекс HPC6 смонтирован на площадке Eni Green Data Center в Феррера-Эрбоньоне: это, как утверждается, один из самых энергоэффективных и экологически чистых дата-центров в Европе. Новый суперкомпьютер оснащён системой прямого жидкостного охлаждения, которая способна рассеивать 96 % вырабатываемого тепла. ЦОД, где располагается HPC6, оборудован массивом солнечных батарей мощностью 1 МВт. 
Источник изображения: Eni Как отмечает ресурс Siliconangle, на создание суперкомпьютера потрачено более €100 млн. Применять комплекс планируется, в частности, для оптимизации работы промышленных предприятий, повышения точности геологических и гидродинамических исследований, разработки источников питания нового поколения, оптимизации цепочки поставок биотоплива, создания инновационных материалов и моделирования поведения плазмы при термоядерном синтезе с магнитным удержанием.
28.12.2024 [12:16], Сергей Карасёв
Xiaomi создаст ИИ-кластер с 10 тыс. GPUКитайская компания Xiaomi, по сообщению Jiemian News, намерена создать собственный вычислительный кластер для решения ресурсоёмких задач в области ИИ. Предполагается, что в основу системы лягут около 10 тыс. ускорителей на базе GPU. Отмечается, что Xiaomi активно развивает направление ИИ. Соответствующее подразделение было сформировано ещё в 2016 году, и с тех пор его штат увеличился примерно в шесть раз — до более чем 3000 сотрудников (включая специалистов, задействованных в смежных областях). С начала 2024 года Xiaomi использует для проектов ИИ вычислительную платформу, насчитывающую около 6500 ускорителей на основе GPU. В дальнейшем количество GPU планируется наращивать. Инициативы Xiaomi в области ИИ курирует генеральный директор компании Лэй Цзюнь (Lei Jun). 
Источник изображения: Xiaomi Проекты Xiaomi в сфере ИИ охватывают самые разные направления, включая компьютерное зрение, обработку естественного языка, графы знаний, машинное обучение, большие языковые модели (LLM) и мультимодальные технологии. Эти технологии по мере развития интегрируются в смартфоны, автомобильные бортовые системы, робототехнику, а также в интеллектуальные устройства Интернета вещей (AIoT). Ранее Цзюнь сообщил, что Xiaomi успешно адаптировала LLM для локального использования на мобильных устройствах: утверждается, что модель с 1,3 млрд параметров достигла сопоставимой с облаком производительности в некоторых сценариях. Кроме того, компания создала более мощную LLM с 6 млрд параметров. Говорится также, что Xiaomi сотрудничает с другими участниками рынка в рамках развития проектов ИИ: в число партнёров входят Qualcomm и MediaTek.
28.12.2024 [11:41], Сергей Карасёв
Объём телеком-рынка в России в 2024 году превысил 2 трлн руб.Аналитическое агентство «ТМТ Консалтинг» подвело итоги исследования российского телекоммуникационного рынка: учитываются затраты в области мобильной связи, интернет-доступа, платного телевидения и пр. В 2024 году объём отрасли достиг 2,04 трлн руб., что на 6,2 % больше по сравнению с 2023-м, когда расходы составляли 1,92 трлн руб. Драйвером телеком-рынка в РФ аналитики называют сегмент сотовой связи, на который по итогам года пришлось 61 % выручки, или приблизительно 1,24 трлн руб. Рост в годовом исчислении зафиксирован на уровне 7,1 %. Количество мобильных абонентов (активных SIM-карт) увеличилось по отношению к 2023 году на 1,9 % — до 263 млн: в абсолютном выражении прирост превысил 4 млн абонентов. Проникновение услуг сотовой связи достигло 180 %. Объём мобильного интернет-трафика за год прибавил почти 15 %. Росту в секторе сотовой связи способствуют несколько факторов: это высокая динамика банковских виртуальных операторов (MVNO), продолжающееся развитие межмашинных коммуникаций (М2М), тарифная политика участников рынка, продвижение дополнительных услуг и опций, медийных сервисов и конвергентных пакетов. 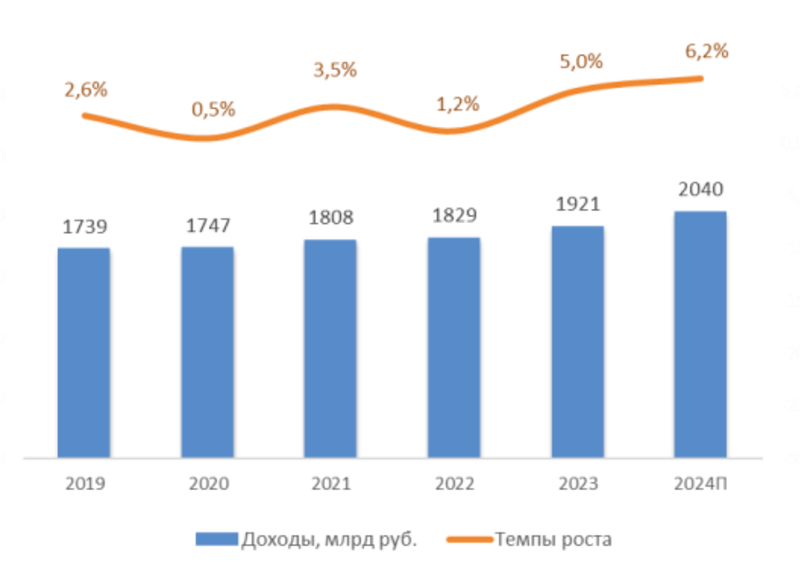
Источник изображений: «ТМТ Консалтинг» Количество абонентов широкополосного доступа в интернет по итогам 2024 года увеличилось на 1,9 %, а проникновение услуги приблизилось к 56 %. Развитие происходит благодаря экспансии в пригороды и частный сектор. Выручка в годовом исчислении поднялась на 6,1%, чему способствовало повышение тарифов для домашних пользователей и юридических лиц. В сегменте платного ТВ количество абонентов сократилось по сравнению с 2023 годом более чем на 100 тыс. (на 0,2 %), но выручка увеличилась на 1,9 %. Такая ситуация связана с ростом конкуренции со стороны OTT-видеосервисов при одновременном повышении тарифов. 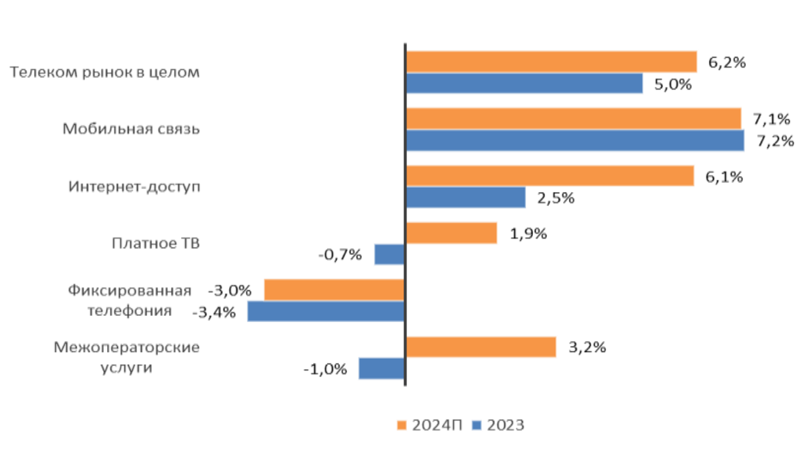 Денежные поступления от фиксированной телефонной связи в 2024 году сократились на 3,0 %. Количество абонентов уменьшилось на 7,9 %, или на 1,3 млн. Проникновение услуги снизилось на 2 %, оказавшись на уровне примерно 15 %. Отрицательная динамика обусловлена продолжающимся отказом от квартирных телефонов. «ТМТ Консалтинг» прогнозирует, что среднегодовой рост российского рынка телекоммуникаций в 2024–2029 гг. (CAGR) составит около 4 %. Ожидаются увеличение потребления услуг передачи данных, а также индексация тарифов на мобильную связь, широкополосный интернет-доступ и платное ТВ.
28.12.2024 [10:10], Алексей Степин
Решения YADRO станут основой IT-инфраструктуры Евразийской экономической комиссииYADRO играет немалую роль в прогрессе отечественной ИТ-индустрии, поскольку постоянно пополняет и развивает арсенал своих программных и аппаратных решений. На этот раз речь идёт о внедрении оборудования для обеспечения работы информационных ресурсов российского сегмента такой масштабной межгосударственной организации, как Европейская экономическая комиссия (ЕЭК). Информационные системы ЕЭК весьма обширны: это и системы электронного документооборота, и средства автоматизации финансово-хозяйственной деятельности, различного рода порталы, базы данных, справочные системы, подсистемы администрирования, обеспечения ИТ-безопасности и многое другое. Комплекс этих систем, носящий название Интегрированная информационная система Евразийского экономического союза (ИИС EAЭС) предоставляет оптимальные средства для взаимодействия стран-участниц союза и активно работающих с ЕАЭС частных компаний. В рамках проведённого тендера выбор был сделан в пользу серверов YADRO серии VEGMAN R120 G2 и систем хранения данных TATLIN.FLEX.PRO как наиболее полно отвечающих всем требованиям к функциональности и производительности. О последних мы не столь давно уже рассказывали: компания-производитель выпустила систему TATLIN.FLEX.PRO v2 c обновленной аппаратной платформой. Это одна из моделей семейства систем хранения данных TATLIN.FLEX, предназначенная для проектов малой и средней сложности. Система обладает высокой гибкостью за счёт вариативности в выборе типа и количества модулей расширения: до 12, 24 и 78 накопителей, наличием блочного и файлового доступов к данным, необходимым в сегменте пакетом функциональности и высокой производительностью благодаря двухконтроллерной конфигурации с 256 ГБ RAM на каждый контроллер. 
Система хранения данных TATLIN.FLEX.PRO v2. Здесь и далее источник изображений: YADRO Серверы VEGMAN R120 G2 являются одной из двух моделей второго поколения флагманской линейки серверов YADRO широкого назначения. Это компактные и эргономичные 1U-решения с высокими возможностями конфигурирования под различные типы рабочих нагрузок. Основой этих серверов является платформа Intel Xeon Ice Lake-SP. VEGMAN R120 G2 допускают установку двух процессоров с TDP до 205 Вт. Совокупный объём оперативной памяти может при этом достигать 8 Тбайт благодаря 32 разъёмам памяти DDR4-3200 в системе. Локальное администрирование сервера сделано удобным благодаря выносу на переднюю панель разъёма VGA и пары портов USB 2.0. 
Сервер VEGMAN R120 G2 В стандартную конфигурацию платформы VEGMAN R120 G2 входят четыре сетевых порта 1GbE RJ45, не считая переключаемого Host/BMC. Для установки карт расширения можно использовать до трёх отсеков PCIe 4.0 (до 2x16 + 1x8), дополненных отсеком OCP 3.0 PCIe 4.0 x8. В силу форм-фактора поддерживается установка до двух GPU. Загружаются эти системы с пары внутренних M.2 SSD, которые также можно объединить в RAID-массив. Фронтальная дисковая корзина имеет два варианта исполнения: четыре отсека LFF SAS/SATA или десять отсеков SFF SAS/SATA/NVMe. Ещё пара SFF-накопителей может быть установлена в задней дисковой корзине. Питается VEGMAN R120 G2 от двух (1+1) блоков мощностью до 1600 Вт каждый. Дополнительное удобство управления, мониторинга и обновления парка оборудования YADRO обеспечивает система СУПРИМ, которую производитель предлагает в виде бесплатного образа виртуальной машины. Она собирает метрики со всего оборудования, умеет обновлять микрокоды и помогает быстрее вводить системы в эксплуатацию и легче их обслуживать. Применительно к задачам проекта серверы VEGMAN R120 G2 обеспечат постоянную доступность ресурсов и данных вкупе с высокой скоростью обработки и защиты ценной информации. Дуэт VEGMAN R120 G2 и TATLIN.FLEX.PRO должен покрыть растущие потребности ЕЭК в вычислительных ресурсах и объёмах хранимых данных и, таким образом, создать прочный фундамент для бесперебойного функционирования и дальнейшего развития ИТ-инфраструктуры ЕАЭС. Обе системы YADRO — СХД TATLIN.FLEX.PRO v2 и серверы VEGMAN R120 G2 — внесены в реестр электронной продукции Минпромторга РФ и производятся на крупнейшем в России предприятии полного цикла «Ядро Фаб Дубна».
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 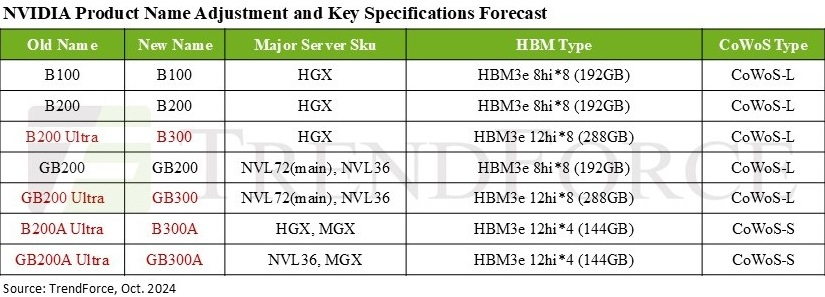
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбай соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорители могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн. |
|

