Материалы по тегу: интерконнект
|
05.06.2023 [22:19], Владимир Мироненко
Разработчик фотонных ИИ-ускорителей Lightmatter привлёк $154 млн инвестиций и втрое увеличил капитализациюСтартап Lightmatter сообщил о завершении раунда финансирования серии C, в результате которого он привлёк инвестиции на сумму $154 млн. В этом раунде приняли участие венчурные подразделения Alphabet и HPE, а также ряд других институциональных инвесторов. Сообщается, что после этого раунда утроилась нераскрытая оценка Lightmatter, которую стартап получил после проведения раунда финансирования в 2021 году. По словам Lightmatter, разработанный ею оптический интерконнект Passage обеспечивает до 100 раз большую пропускную способность, чем традиционные альтернативы. Ускорение перемещения данных в чипе и между чипами повышает производительность приложений. Lightmatter утверждает, что Passage занимает значительно меньше места, чем традиционные электрические соединения, и потребляет в пять раз меньше энергии. Кроме того, Passage упрощает работу с системой, позволяя автоматические менять конфигурацию интернконнекта менее чем 1 мс. 
Источник изображения: Lightmatter Lightmatter Passage является частью инференс-платформы Envise 4S, оптимизированной для работы с самыми крупными ИИ-моделями. По данным компании, система втрое быстрее, чем NVIDIA DGX A100, занимая при этом 4U-шасси и потребляя порядка 3 кВт. Сервер Envise 4S оснащён 16 фотонными ИИ-ускорителями Envise, каждый из которых содержит 500 Мбайт памяти, 400G-подключение к соседним чипам и 256 RISC-ядер общего назначения. Ускорители объединены оптической фабрикой производительностью 6,4 Тбит/с. Полученные в результате нового раунда средства компания планирует использовать для коммерциализации Passage и Envise, а также внедрения Idiom, программного инструментария, который упрощает написание приложений для Envise.
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 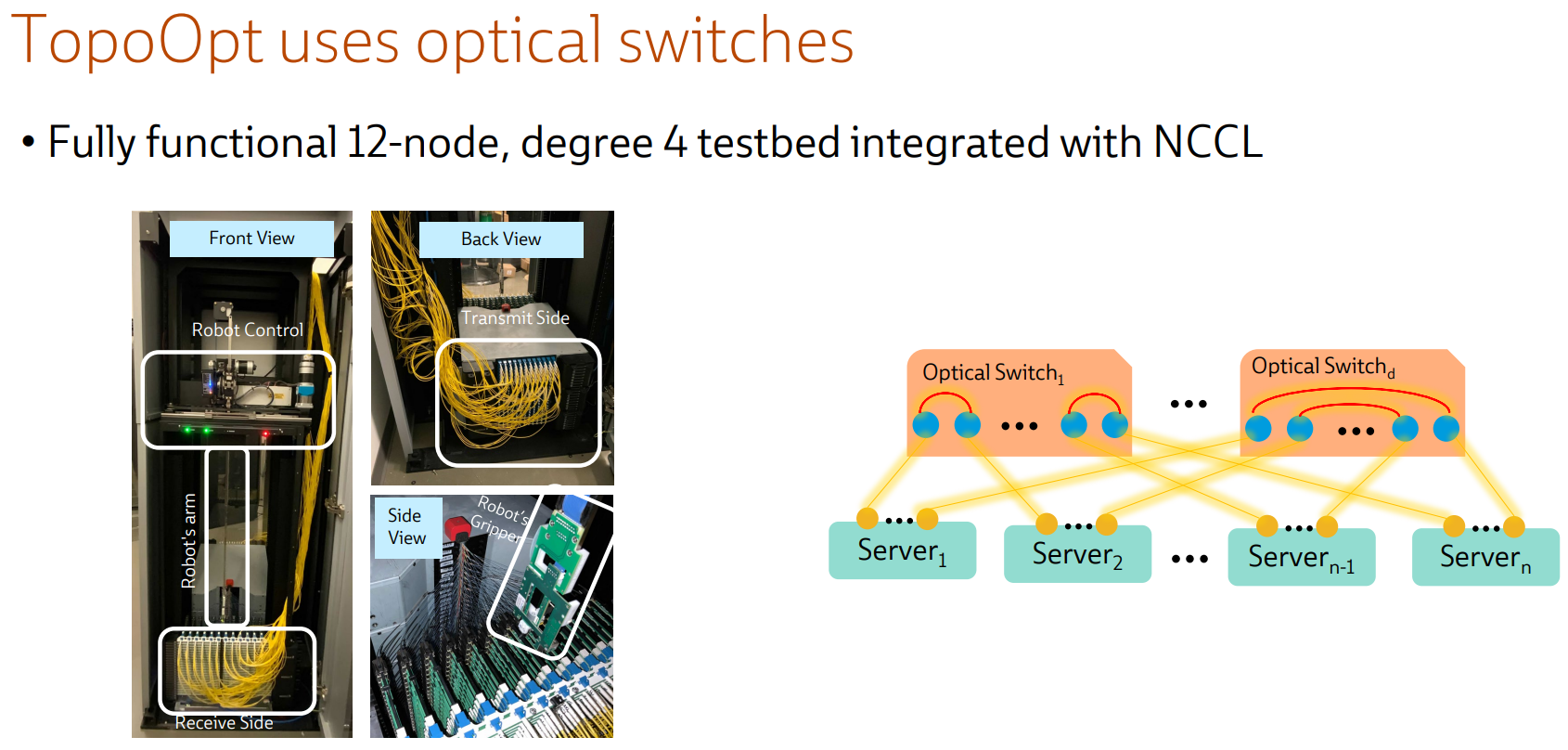
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
06.09.2022 [22:47], Алексей Степин
Кремниевая фотоника Lightmatter Passage объединит чиплеты на скорости 96 Тбайт/сНа конференции Hot Chips 34 компания Lightmatter, занимающаяся созданием фотонного ИИ-процессора, рассказала о своей новой разработке, Lightmatter Passage, открывающей для чиплетов эру фотоники. Как известно, переход на чиплеты позволил разработчикам сложных чипов сравнительно малой кровью обойти ограничения, накладываемые технологиями на создание монолитных кристаллов большой площади. Однако современный высокоскоростной межчиплетный интерконнект всё равно весьма сложен и потребляет сравнительно много энергии. И по мере роста количества чиплетов на общей подложке проблема будет лишь обостряться. 
Изображения: Lightmatter (via ServeTheHome) Но технология Lightmatter Passage, призванная заменить электрический интерконнект оптическим, позволит эту проблему обойти. По сути, Passage — универсальная кремниевая прослойка, содержащая в своём составе лазеры, оптические модуляторы, фотодетекторы, волноводы, а также классические транзисторы для сопутствующей логики. Поверх этой прослойки Lightmatter и предлагает размещать чиплеты любой архитектуры. 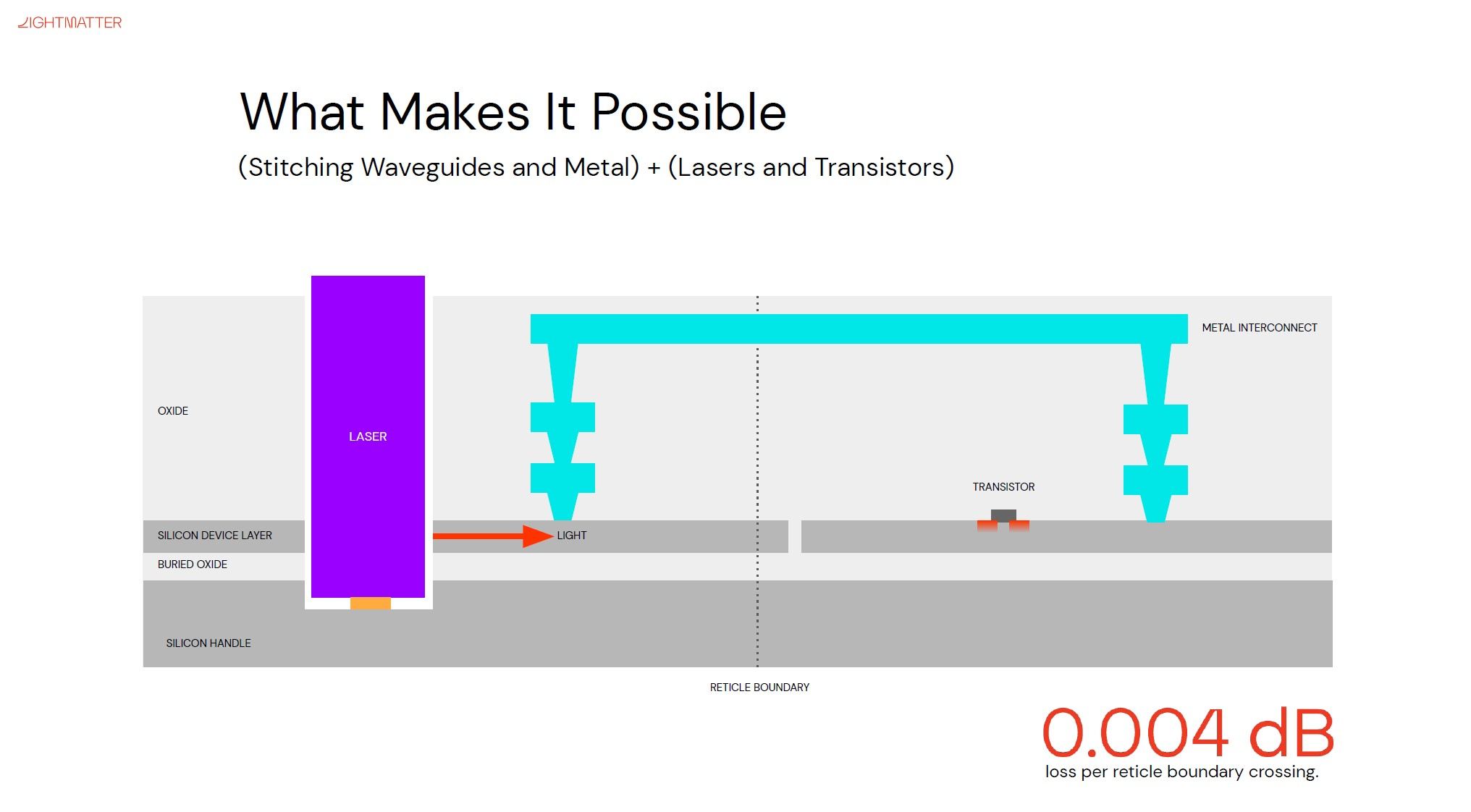 Электрическая часть Passage имеет изменяемую конфигурацию и в текущей реализации поддерживает установку до 48 чиплетов (в виде матрицы 6×8). Производится такая прослойка из 300-мм кремниевой пластины SOI, верхний и нижний слои Passage имеют классические контакты для чиплетов и установки на PCB соответственно. При этом максимальная подводимая электрическая мощность может достигать 700 Вт. Вся же коммуникация чиплетов между собой происходит внутри и является оптической. 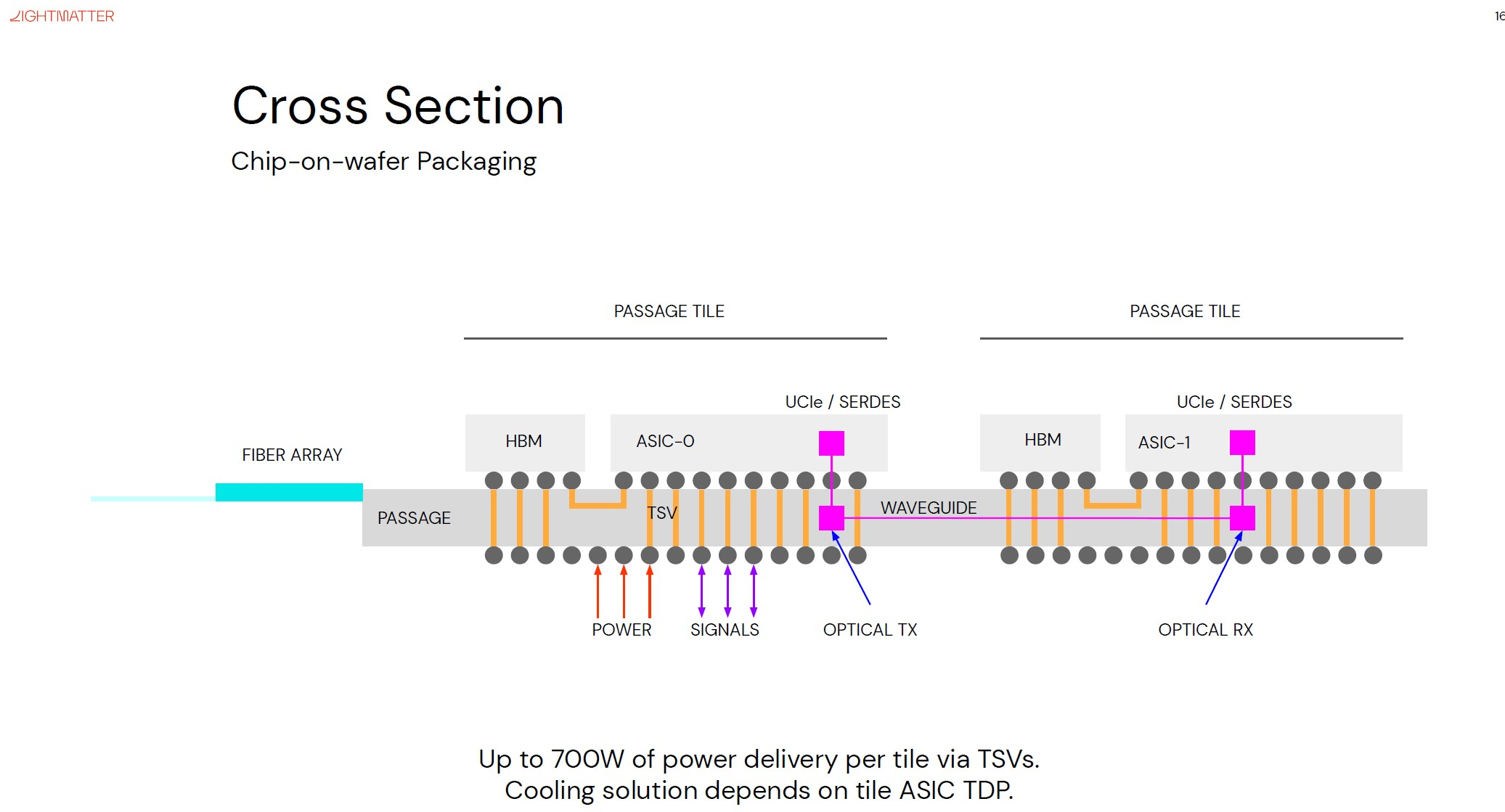 Матрица фотонных волноводов, плотность которой в 40 раз выше, чем у традиционных оптоволоконные технологий, обеспечивает латентность одного перехода на уровне менее 2 нс. Как заявляют разработчики, расстояние между чиплетами при этом роли не играет — для любого сочетания пары точек «входа» и «выхода» сигнала значение задержки одинаково. Высокая плотность волноводов позволяет «накормить» каждый чиплет потоком данных до 96 Тбайт/с, а внешние каналы Passage позволяют связать чипы с другими компонентами системы на скоростях до 16 Тбайт/с. 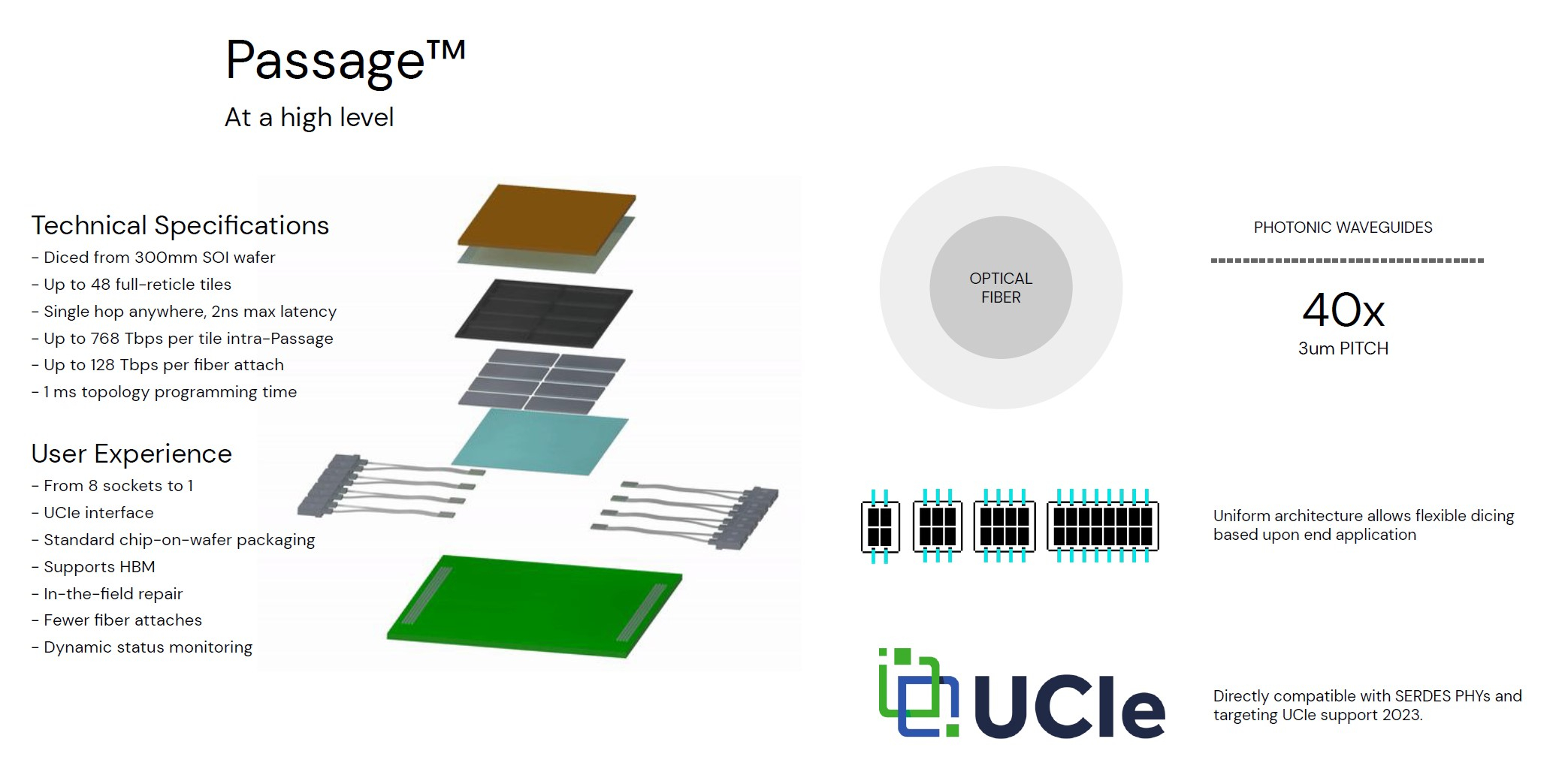 Основой данной технологии является фирменная разработка компании, позволяющая точно «сшивать» в пределах нескольких слоев SOI-кремния электрические соединения с многочисленными волноводами. Уже существующая в кремнии тестовая реализация Passage потребляет 21 Вт, позволяет устанавливать до 48 чиплетов площадью по 800 мм2, обеспечивает каждое посадочное место 32 каналами с пропускной способностью 1024 Тбит/с, причём топологию интерконнекта можно динамически менять.  Тестовая подложка Passage, полученная из 300-мм пластины, содержит 288 лазеров мощностью 50 мВт каждый. Всего в состав системы входит 150 тыс. компонентов, и это заявка на абсолютный рекорд для фотонных чипов. Кроме того, новая технология совместима со стандартом UCIe — говорится о скорости 32 Гбит/с на линию. Впрочем, в случае простого SerDes-соединения, как считают создатели, этот показатель можно поднять до 112 Гбит/с.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла.  Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с).  При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 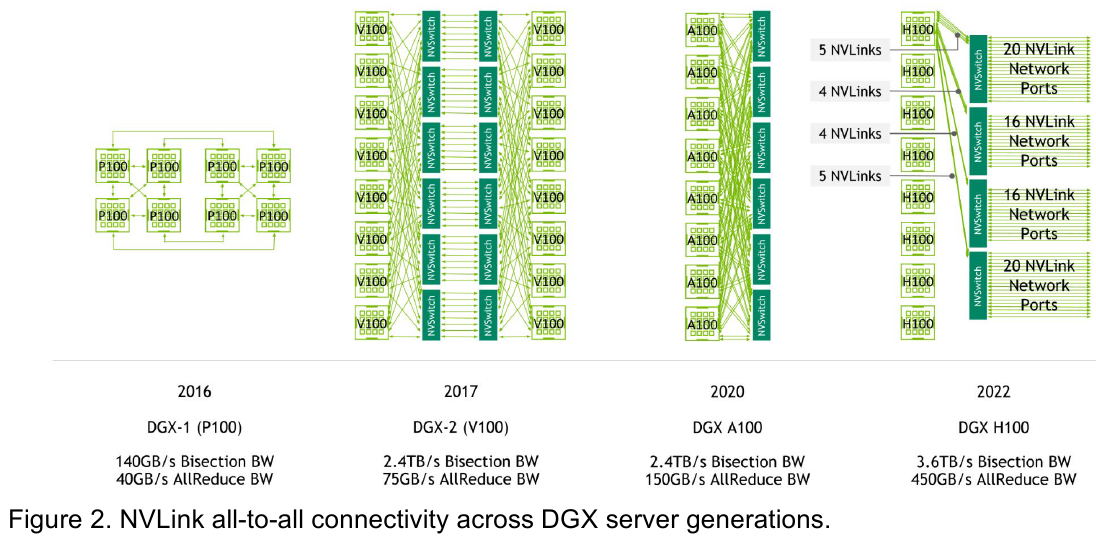 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 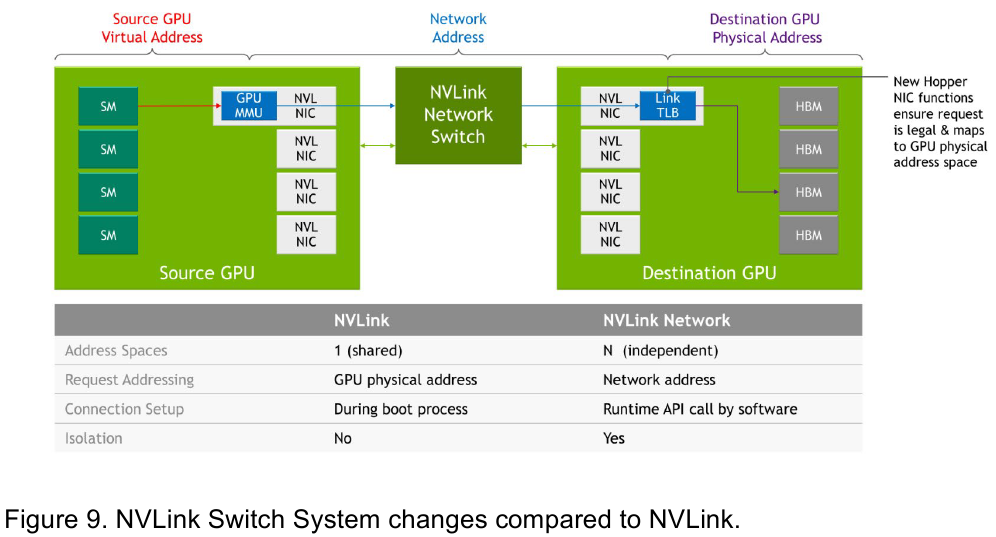 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
04.07.2022 [22:18], Алексей Степин
Intel разработала фотонный техпроцесс с интегрированным мультиволновым массивом лазеровФотоника сулит немалые преимущества, и особенно ярко они проявятся в случае достижения высокой степени интеграции — если внешний источник лазерного излучения может существенно усложнить систему и сделать её более дорогой, то интегрированный на кремниевую пластину, напротив, многое упрощает. Неудивительно, что разработчики, бьющиеся над созданием гибридных фотонных чипов, нацелены именно на такой вариант. Ранее мы рассказывали о варианте Synopsys и Juniper Networks, которые также планируют использовать интегрированные лазеры в рамках возможностей техпроцесса PH18DA компании Tower Semiconductor, а сейчас успеха добилась корпорация Intel. 
Традиционные оптические модуляторы достаточно громоздки. Источник: Intel Labs Научно-исследовательское подразделение компании, Intel Labs, сообщает, что на базе «существующего кремниевого-фотонного техпроцесса для пластин диаметром 300 мм» удалось создать интегрированный лазерный массив, работающий с восемью длинами волн. Это хорошо отработанная технология, на её основе Intel уже производит оптические трансиверы, что открывает дорогу к достаточно быстрому началу производству фотонных чипов со встроенными лазерными массивами. 
Вариант Intel использует компактные кольцевые микромодуляторы. Источник: Intel Labs В технологии используются лазерные диоды с распределённой схемой обратной связи (distributed feedback, DFB), которая позволяет добиться высокой точности как в мощности излучения в пределах 0,25 дБ, так и в спектральных характеристиках, где отклонения в границах используемых спектров не превышают 6,5%. Достигнутые параметры превышают аналогичные показатели классических полупроводниковых лазеров. Компания также отмечает, что применённая ей новая технология кольцевых микромодуляторов, отвечающих за конверсию электрического сигнала в оптический, существенно компактнее более традиционных решений других разработчиков. Такой подход позволяет поднять удельную плотность фотонных линий передачи данных, то есть, при прочих равных условиях, чип, оснащённый интерконнектом Intel, будет иметь более «широкую» оптическую шину с более высокой пропускной способностью. 
В технологии используется массив из 8 лазеров. Источник: Intel Labs Технология гибридной фотоники со встроенными лазерами, использующая мультиплексирование с разделением по длине волны (dense wavelength division multiplexing, DWDM), делает высокоскоростной оптический интерконнект возможным, но до успеха Intel данная технология упиралась именно в точность разделения спектра и в достаточно высокое энергопотребление источников излучения. В настоящее время уже ведутся работы по созданию специального чиплета, который позволит вывести оптический интерконнект за пределы кремниевой пластины, а это в перспективе даст возможность как для фотонного соединения между центральным процессором и памятью или GPU, так и для реализации будущих ещё более скоростных версий стандарта PCI Express или его наследника. 
Дорога к высокоскоростному оптическому интерконнекту открыта! Источник: Intel Labs Ayar Labs, один из пионеров в освоении гибридных электронно-оптических технологий однако считает, что у подхода Intel есть и недостатки. Сам по себе оптический интерконнект, конечно, может быть производительнее классического, и к тому же он не подвержен помехам. Однако лазерные диоды по природе своей достаточно капризны, а глубокая интеграция источника излучения в чип при выходе хотя бы одного лазера из строя делает всю схему бесполезной. В своих решениях Ayar Labs полагается на внешний лазерный модуль SuperNova.
16.05.2022 [23:41], Алексей Степин
Intel: UCIe объединит разнородные чиплеты внутри одной упаковки и за её пределамиШина PCI Express давно стала стандартом де-факто: она не требует много контактов, её производительность в пересчёте на линию уже достигла ≈4 Гбайт/с (32 ГТ/с) в версии PCIe 5.0, а использование стека CXL сделает PCI Express поистине универсальной. Но для соединения чиплетов или межпроцессорной коммуникации эта шина в текущем её виде подходит не лучшим образом. Но использование проприетарных технологий существенно ограничивает потенциал чиплетных решений, и для преодоления этого ограничения в марте этого года 10-ю крупными компаниями-разработчиками, включая AMD, Qualcomm, TSMC, Arm и Samsung, был основан новый стандарт Universal Chiplet Interconnect Express (UCIe). 
Изображение: UCIe Consortium Уже первая реализация UCIe должна превзойти PCI Express во многих аспектах: если линия PCIe 5.0 представляет собой четыре физических контакта с пропускной способностью 32 ГТ/с, то UCIe позволит передавать по единственному контакту до 12 Гбит/с, а затем планка будет повышена до 16 Гбит/с. При этом энергопотребление у UCIe ниже, а эффективность — выше. На равном с PCIe расстоянии новый стандарт может быть вчетверо производительнее при том же количестве проводников. В перспективе эта цифра может быть увеличена до 10–20 раз, то есть, узким местом между чиплетами UCIe явно не станет. Более того, новый интерконнект не только изначально совместим с CXL, но и гораздо лучше приспособлен к задачам дезагрегации. Иными словами, быстрая связь напрямую между чиплетами возможна не только в одной упаковке или внутри узла, но и за его пределами. 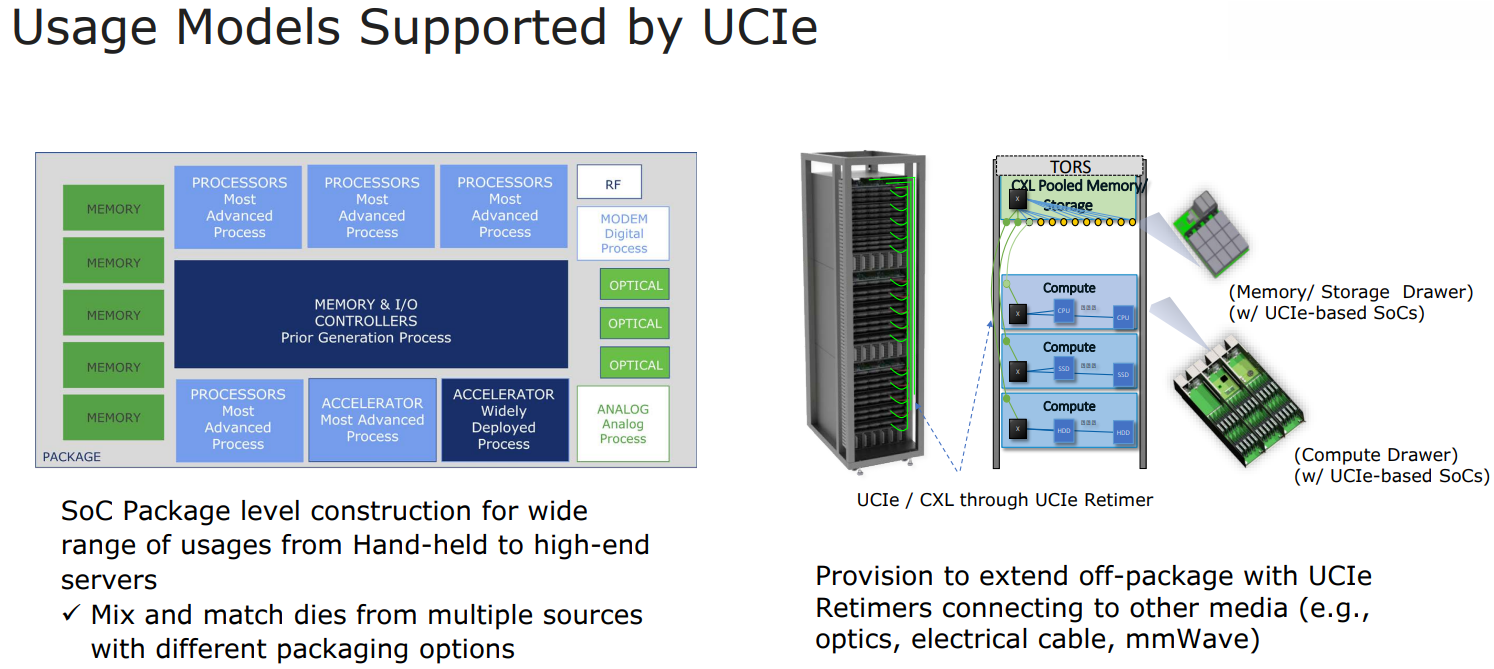
Изображение: UCIe Consortium Весьма заинтересована в новом стандарте Intel, которая планирует использовать UCIe таким образом, что в процессорах нового поколения ядра x86 смогут соседствовать с Arm или RISC-V. При этом планируется обеспечить совместимость UCIe с технологиями упаковки Intel EMIB и TSMC CoWoS, заодно добавив поддержку других шин, в том числе Arm AMBA, а также возможность легкой конвертации в проприетарные протоколы других разработчиков. В настоящее время Intel уже есть несколько примеров использования UCIe. Так, в одном из вариантов с помощью новой шины к процессорным ядрам подключаются ускорители и блок управления, а упаковка EMIB используется для подключения чипа к дезагрегированной памяти DDR5 и линиям PCI Express.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки).  Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0.
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 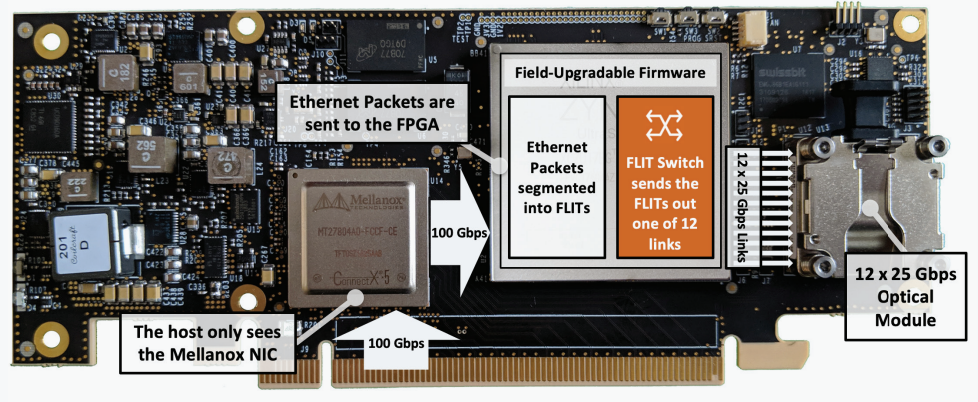 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport. 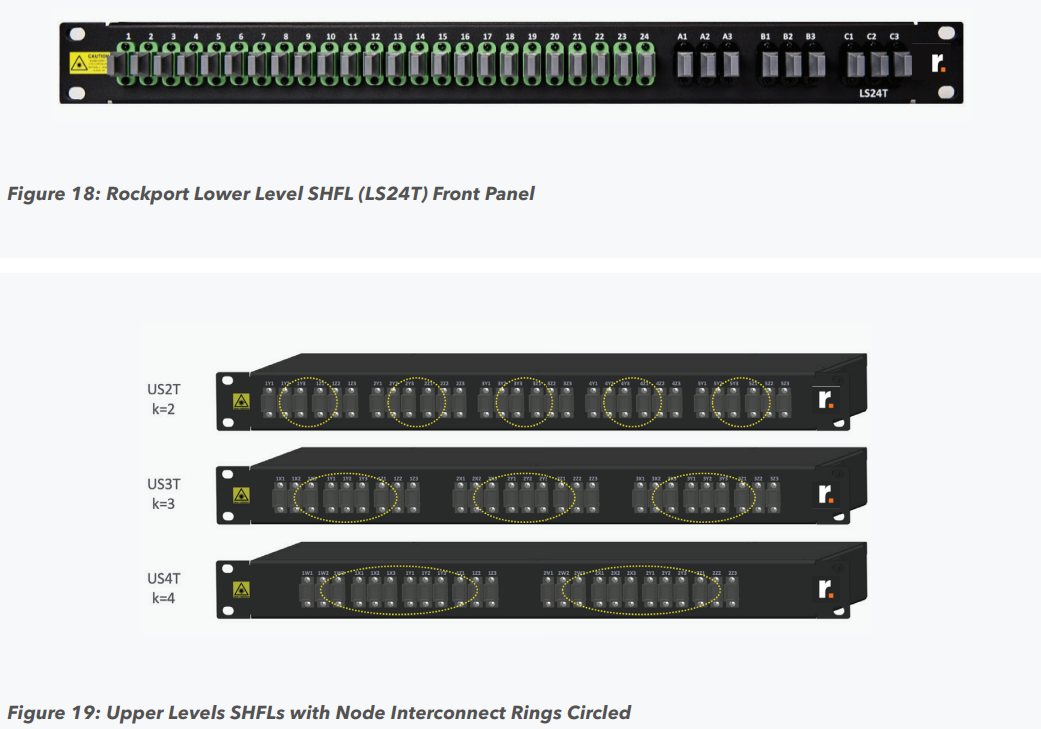 Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 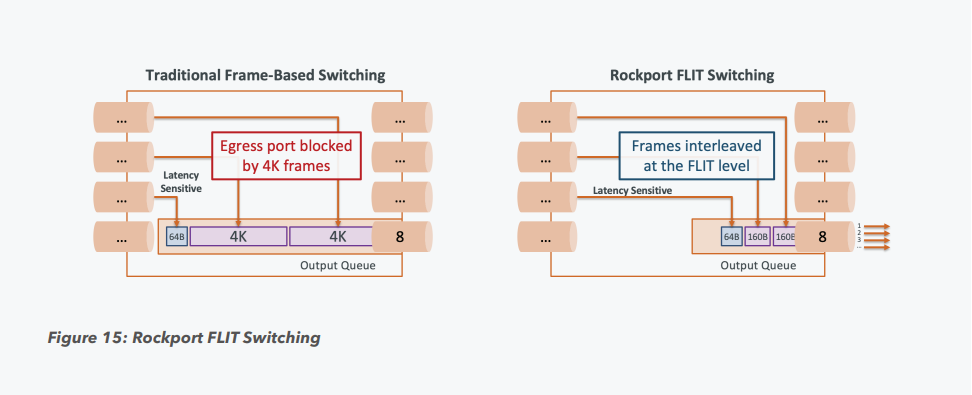 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки.  SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей. |
|

