Материалы по тегу: интерконнект
|
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
14.03.2024 [23:45], Алексей Степин
Войны ретаймеров: Astera Labs анонсировала чипы Aries 6 для PCIe 6.0Практически сразу после анонса чипов Broadcom Vantage 5 и 6 Astera представила свой вариант ретаймеров для инфраструктуры PCIe следующего поколения — серию чипов Aries 6, передаёт ServeTheHome. Высокий интерес к ретаймерам вызван теми возможностями, что открывает PCI Express 6.0 как в плане скоростей, так и в плане функциональности (CXL). А переход на новое поколение шины необходим для дальнейшего развития набирающего популярность генеративного ИИ. По мере роста скоростей PCI Express обострялась и проблема длины проводников на печатной плате, при которой сигнал достаточно устойчив и вписывается в окно требуемых характеристик. Если при переходе от PCIe 3.0 к 4.0 удалось обойтись сравнительно малой кровью, то для PCIe 5.0 уже потребовались более сложная схемотехника и более продвинутые ретаймеры. PCIe 6.0 же накладывает ещё более жёсткие требования к целостности сигнала. 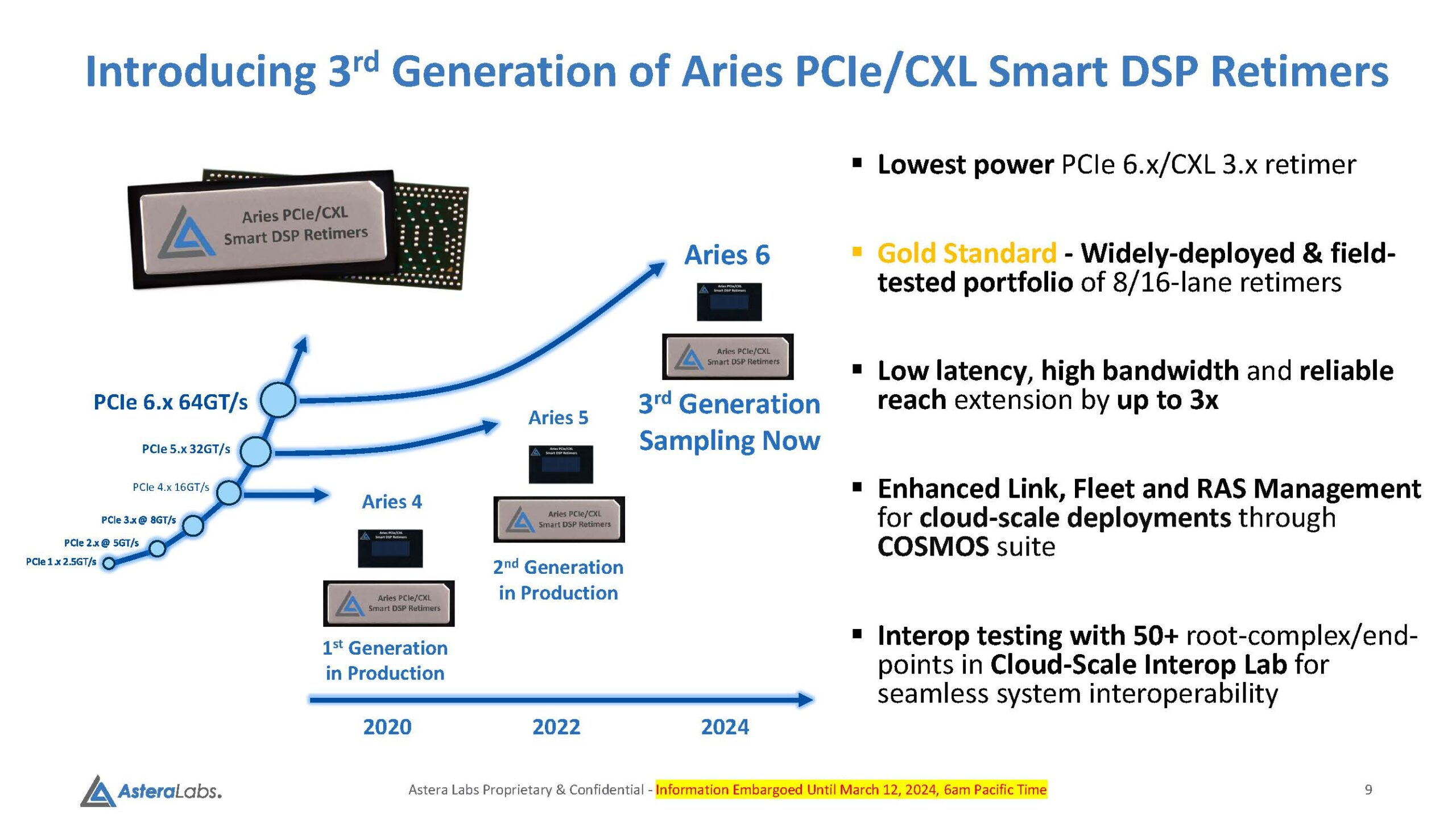
Источник здесь и далее: Astera Labs via Serve The Home Платформы GPU-кластеров и СХД компактнее не становятся, так что требуемая длина проводников на печатных платах растёт, а вместе с ней растёт и важность ретаймеров, поскольку без них согласовать высокоскоростной сигнал PCIe 6.0 становится невозможно. Таким системам требуется сразу несколько подобных чипов, причём стоимость каждого из них достигает $20, так что суммарная стоимость этих компонентов на уровне целого ЦОД весьма внушительна. 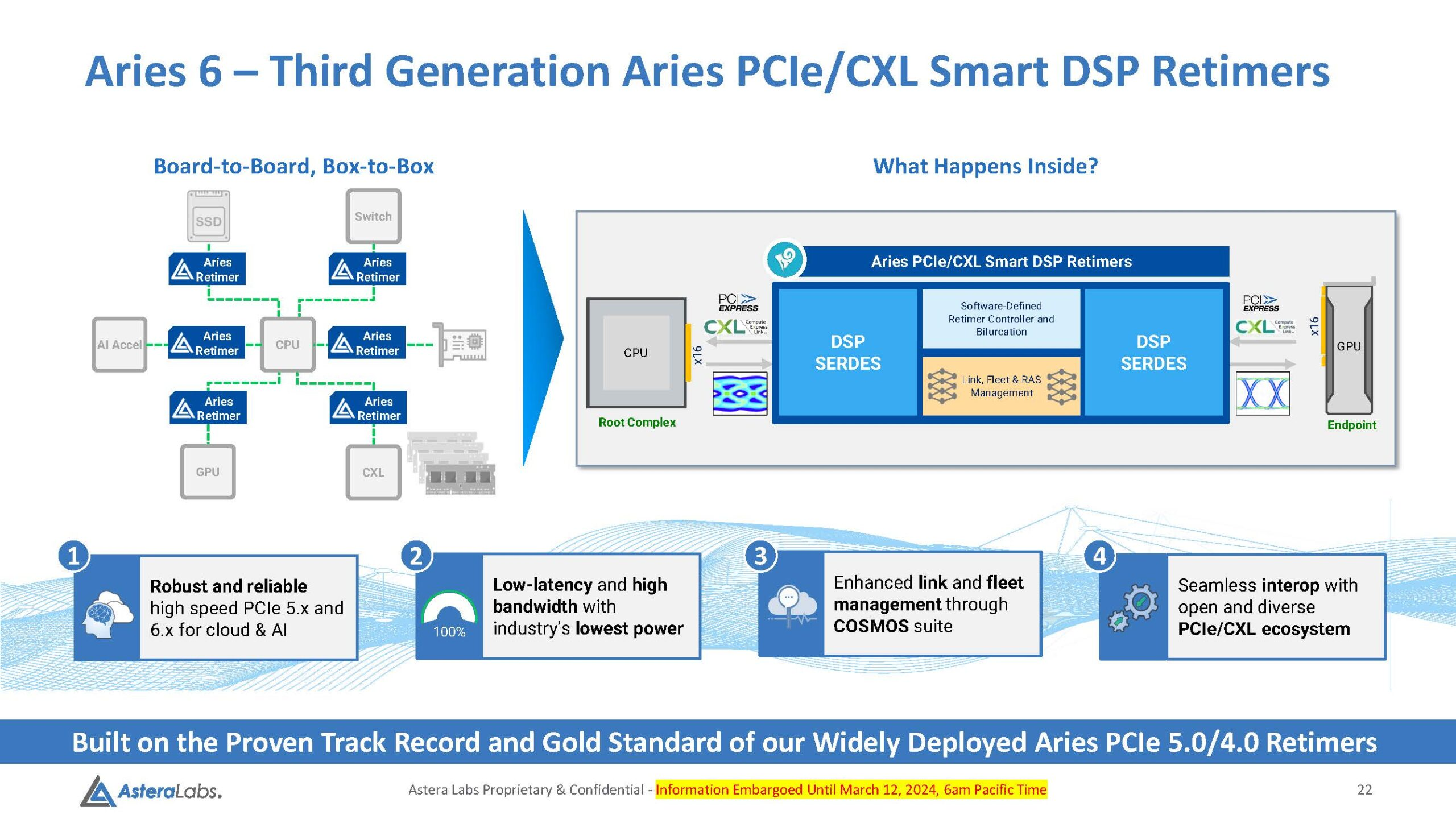 Новые чипы Aries 6 относятся к третьему поколению «умных» DSP-ретаймеров. Они представлены в вариантах с 8 и 16 линиями PCIe 6.0 и позволяют в три раза увеличить длину соответствующего соединения на плате, говорит Astera Labs. При этом новинки поддерживают CXL 3.x и предоставляют расширенные средства диагностики и управления COSMOS. Энергопотребление в режиме PCIe 6.0 при этом заявлено меньше, чем у Broadcom Vantage 6 — 11 Вт против 13 Вт у конкурента. 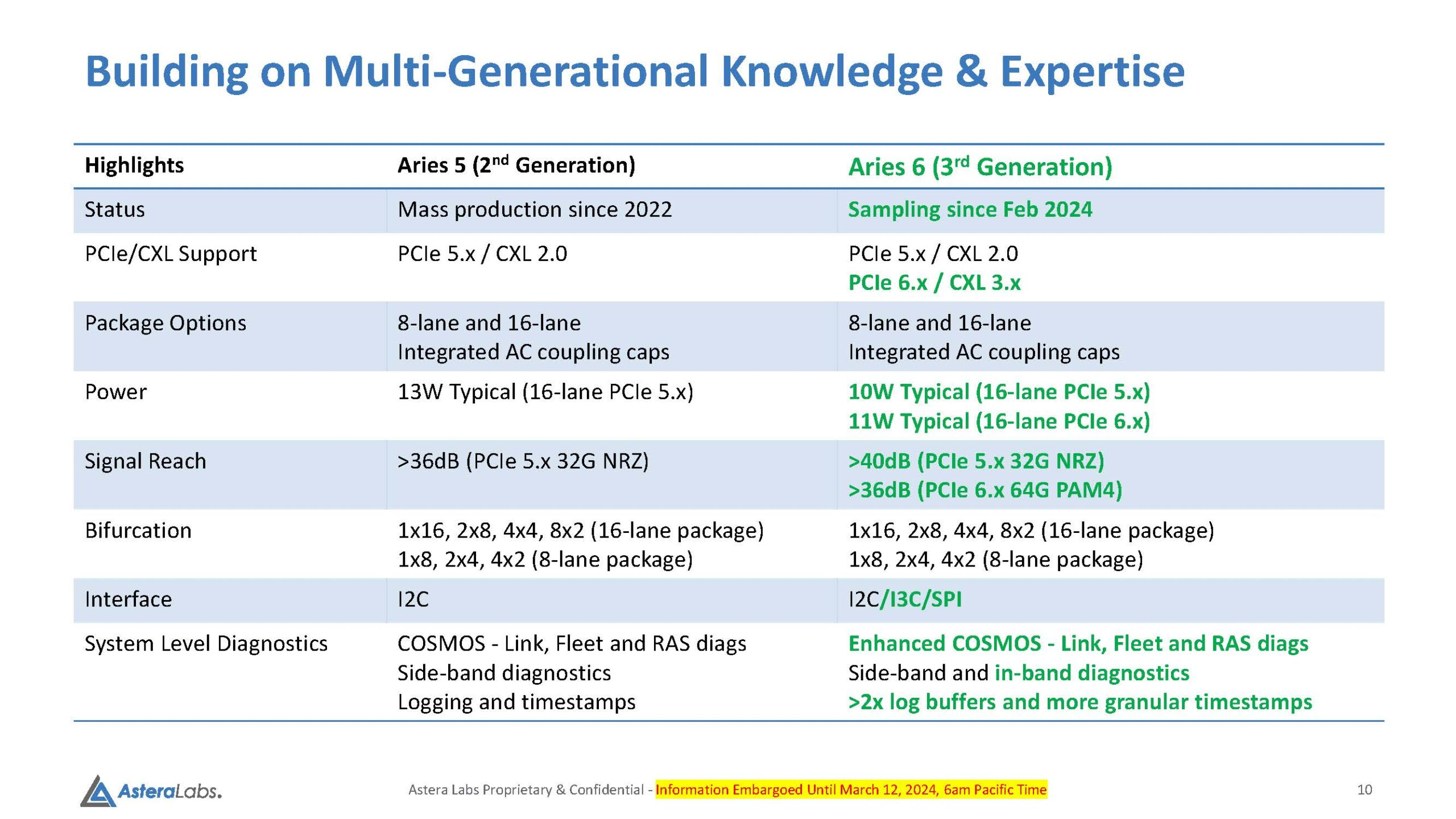 Aries 6 уже протестированы на совместимость с полсотней разнообразных PCIe-соединений, включая root-комплексы и конечные устройства. И если Broadcom пока только говорит о ретаймерах для PCIe 6.0, а появление первого «кремния» Vantage 6 запланировано лишь на следующий год, то Astera Labs начала поставки образцов Aries 6 ещё в феврале. Похоже, Broadcom будет нелегко развернуться на этом рынке.
08.03.2024 [00:03], Алексей Степин
Broadcom готовит чипы для PCIe 6.0/7.0 с поддержкой AMD Infinity FabricОдним из столпов, на которых зиждется господство NVIDIA в мире ускорителей, является NVLink — высокоскоростной интерконнект, позволяющий чипам общаться напрямую не только в составе одного узла, но и за его пределами. AMD пытается ответить на это продвижением XGMI/Infinity Fabric, и в предварительном обзоре Instinct MI300 были затронуты вопросы топологии серверов в исполнении «красных». Ещё тогда, в момент анонса MI300, компания Broadcom объявила о поддержке данного интерконнекта в будущих поколениях своих PCIe-коммутаторов, а сейчас ресурс ServeTheHome поделился новыми подробностями. XGMI действительно станет коммутируемым, что упростит масштабирование систем на базе ускорителей AMD Instinct. Интерконнект получил официально название AFL (Accelerated Fabric Link). В основе AFL по-прежнему будет лежать PCI Express, в данном случае речь идёт уже о PCI Express 7.0. Поддержка данной технологии дебютирует в PCIe-коммутаторах Broadcom Atlas 4. В дополнение к ним будут выпущены и новые ретаймеры Vantage 7, которые также получат поддержку CXL 4.0. 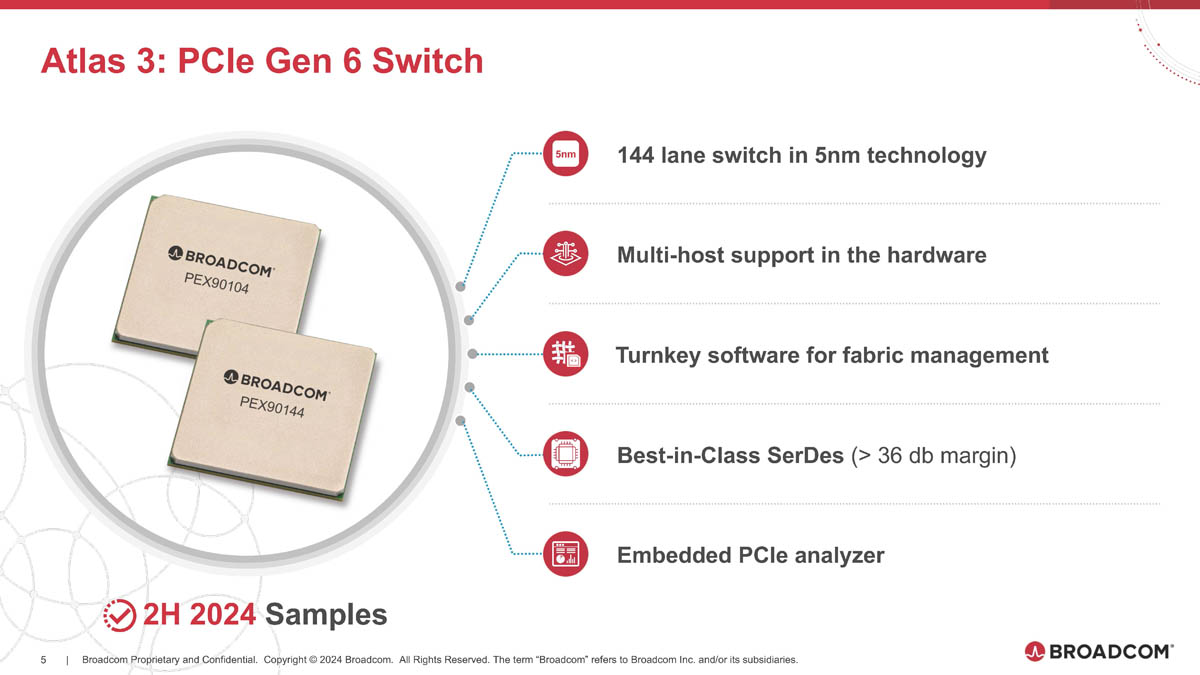
Источник здесь и далее: Broadcom via ServeTheHome Но перед этим Broadcom начнёт поставки образцов чипов-коммутаторов Atlas 3 со 144 линиями PCIe 6.0 во II половине 2024 года, а серверы с такими коммутаторами появятся в 2025 году. Поддержка CXL здесь будет расширена до версии 3.1.  Что касается ретаймеров, то здесь Broadcom уже нанесла ответный удар Astera Labs, анонсировав чипы серий Vantage 5 и Vantage 6 для экосистем PCI Express 5.0 и PCI Express 6.0 соответственно. Они будут выпускаться в вариантах с 8 и 16 линиями с опцией бифуркации и поддержкой CXL 2.0 и 3.1. Broadcom заявляет о более низком энергопотреблении, достигнутом за счёт применения 5-нм техпроцесса, лучших в индустрии блоках SerDes и расширенных средствах диагностики, интегрированных в новые ретаймеры. 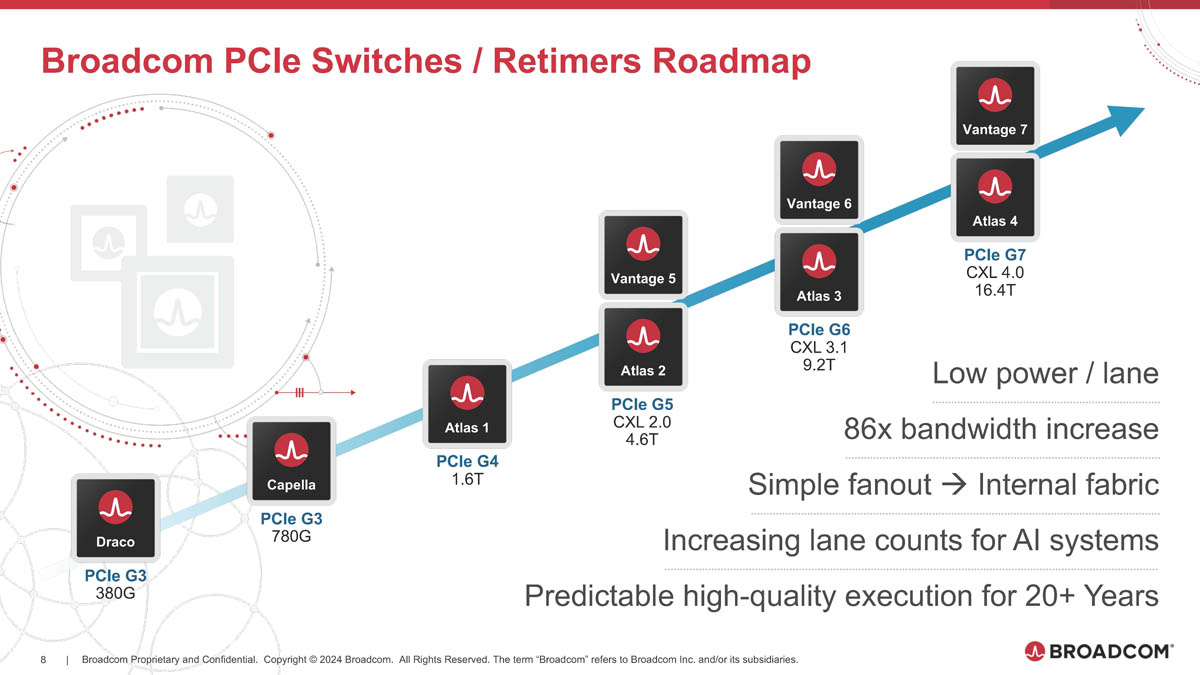 Экономичность здесь играет важную роль: хотя даже 7-нм ретаймер потребляет немного, таких микросхем в составе каждого GPU-сервера несколько, что при дальнейшем масштабировании выливается весьма серьёзные цифры. К тому же меньшая нагрузка ляжет и на систему охлаждения, ведь если CPU и ускорители могут обслуживаться СЖО, то остальные компоненты в таких серверах по-прежнему охлаждаются обычными вентиляторами.  Что касается SerDes-блоков, то они позволят на 40 % удлинить соединения при сохранении стабильной работы. Ну а наличие продвинутого диагностического программного обеспечения с расширенными возможностями упростит разработку, отладку и ремонт систем нового поколения.  Ретаймеры Vantage 5 будут использоваться в комплекте с коммутаторами Atlas 2 в решениях Broadcom уже сегодня, они обеспечат поддержку CXL 2.0, ну а системы с Vantage 6 и поддержкой CXL 3.1, как уже упоминалось, должны увидеть свет в следующем году.  Astera Labs есть о чём беспокоиться: если на данный момент её ретаймерам почти нет альтернативы, то уже в ближайшем будущем ситуация может коренным образом измениться, поскольку Broadcom явно осознала всю важность этого компонента в экосистеме PCI Express и оценила солидный объём потенциальной клиентской базы.
13.02.2024 [22:21], Алексей Степин
Дотянуться до GPU: Astera Labs представила кабельные модули Aries для PCIe 5.0 и CXLРазвитие пула технологий CXL естественным образом вызывает необходимость в разработке соответствующей кабельной инфраструктуры. Активные оптические кабели достаточно дороги для того, чтобы использовать их на соединениях малой длины, а полностью пассивная «медь» неизбежно потребует установки дополнительных ретаймеров. Astera Labs, разработчик решений для CXL, предлагает решить эту проблему путём использования активных медных кабелей, оснащённых встроенными ретаймерами. 
Изображение: Astera Labs Новый тип кабельных модулей получил название Aries PCIe/CXL Smart Cable, он гарантирует устойчивую работу при длине соединения до 7 м, в то время как PCIe 5.0-совместимая пассивная «медь» работоспособна лишь на длинах до 3 м. В основу легли разработанные ещё в 2022 году ретаймеры серии Aries, представленные в рамках анонса целого портфолио решений с поддержкой CXL. 
Изображение: Astera Labs Все решения Astera Labs поддерживают единую программно-аппаратную платформу COSMOS, отвечающую за управление и телеметрию, что должно упростить развёртывание и эксплуатацию крупномасштабных систем на базе PCIe/CXL-интерконнекта любой сложности, от комплексов GPU-кластеризации до пулов CXL-памяти. 
Источник изображений здесь и далее: Astera Labs via Serve The Home Сами ретаймеры Aries несмотря на свою компактность, представляют собой сложные устройства с достаточно производительными для работы на скоростях PCIe 5.0 сигнальными процессорами (DSP). Помимо DSP в состав чипа входит блок телеметрии и удалённого управления и программно-определяемый контроллер, отвечающий за режимы бифуркации. 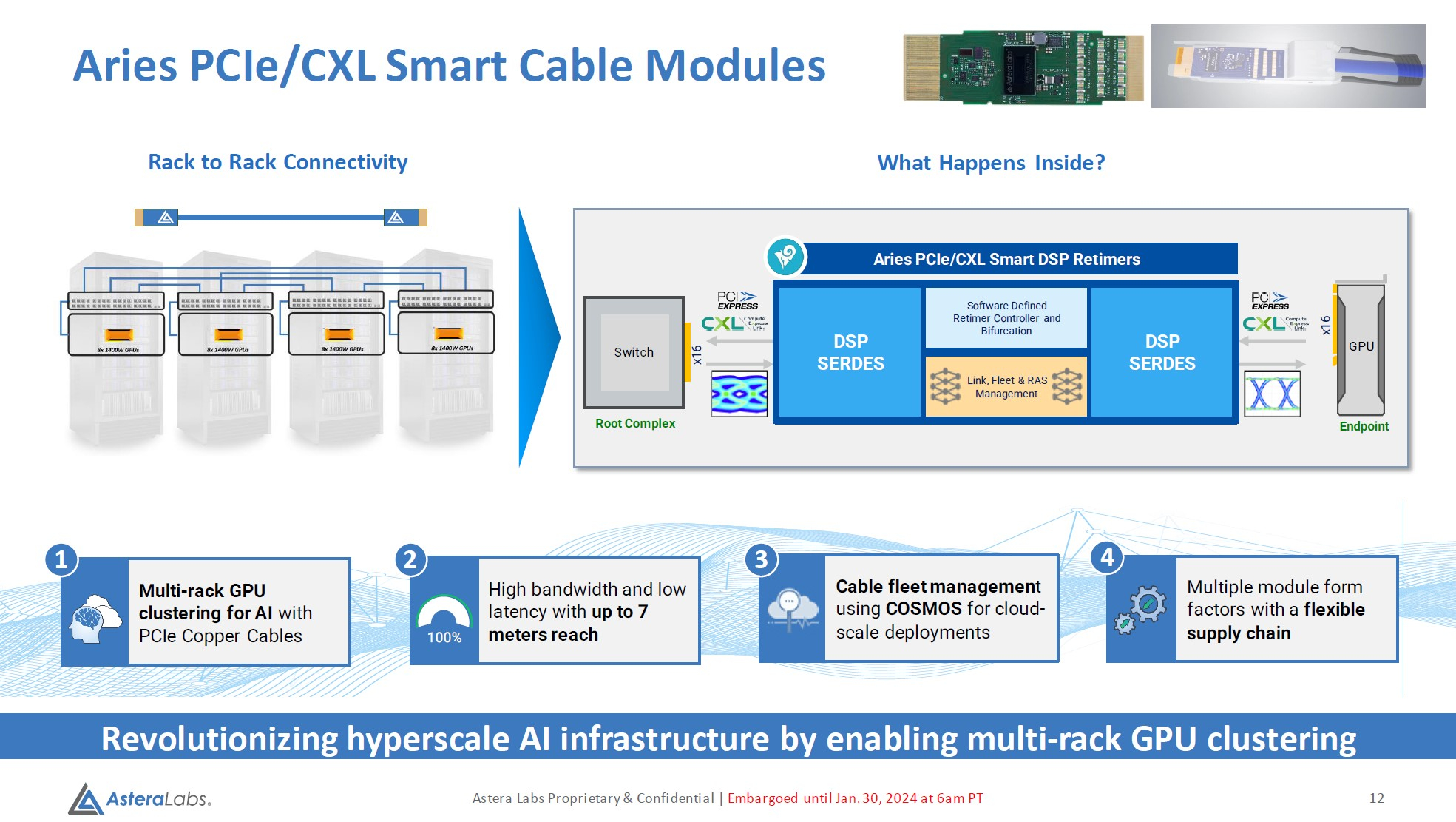 Применение «умных» медных кабелей Astera упростит и удешевит конструкцию систем с более чем одной стойкой, а также позволит использовать более разнообразные варианты топологии. Для подключений длиной более 7 м компания ведёт разработку активных оптических соединителей. 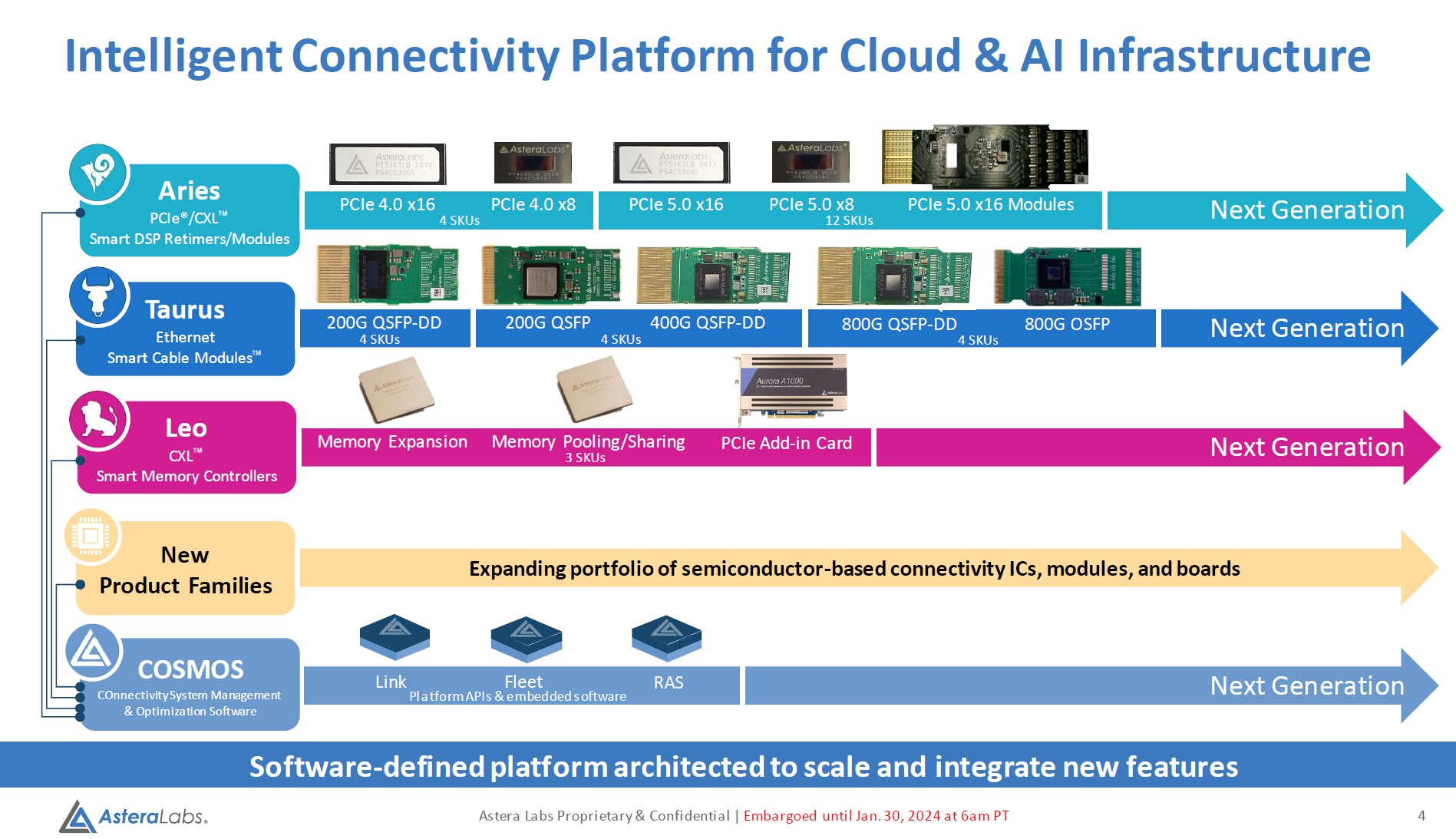 Стоит отметить, что готовые кабели Astera Labs не продаёт. Она поставляет кабельные модули, которые гиперскейлеры и ОЕМ-производители вольны использовать в своих решениях так, как им представляется необходимым.
23.11.2023 [01:01], Владимир Мироненко
Nokia поможет консорциуму Ultra Ethernet в разработке новых спецификаций Ethernet для систем ИИNokia объявила о поддержке консорциума Ultra Ethernet Consortium (UEC), созданного с целью объединения усилий компаний для обновления спецификаций Ethernet и разработки API, позволяющих удовлетворить растущие сетевые требований систем ИИ и HPC. Компания отметила, что почти универсальный протокол для сетей передачи данных Ethernet способен удовлетворить широкие потребности систем ИИ в производительности, а благодаря поддержке Nokia консорциум сможет разрабатывать новые стандарты, лучшие практики и архитектуры для специализированных сетей ЦОД с ИИ. Nokia добилась больших успехов в разработке сверхмасштабируемых сетевых решений с низкой задержкой для ЦОД и интерконнекта. Компания планирует использовать накопленный опыт при участии в нескольких рабочих группах UEC, помогая обеспечить соответствие продуктов консорциума критическим потребностям всех своих клиентов. 
Источник изображения: Nokia «Используя наше широкое присутствие в сфере коммуникаций, корпоративных и веб-сетей, мы стремимся сделать Ultra Ethernet высоко совместимой, недорогой и функционально интероперабельной частью будущих стеков приложений искусственного интеллекта и высокопроизводительных вычислений», — заявил глава IP-подразделения Nokia.
17.11.2023 [21:46], Алексей Степин
PCI-SIG выпустила предварительные спецификации PCIe 7.0 и анонсировала кабели CopprLinkОрганизация PCI Special Interest Group (PCI-SIG) рассказала о последних планах по развитию интерфейса PCI Express. В числе прочего были опубликованы сведения о новом стандарте кабелей и разъёмов CopprLink для подключений PCIe 5.0/6.0. Основанная в 1992 году организация PCI-SIG опубликовала первые спецификации PCI Express в 2003 году, а сегодня без этого интерфейса невозможно представить себе ни одну мало-мальски мощную вычислительную систему. В PCI-SIG на данный момент входит свыше 950 участников. Планы по развитию PCI Express, простирающиеся до 2028 года, показывают, что разработка новых, более производительных версий шины идёт темпами, позволяющими удовлетворить требования к скорости IO-подсистем, удваивающиеся примерно каждые 3 года. В версии PCIe 7.0 планируется довести этот показатель для x16-подключений до 512 Гбайт/с. Предварительная версия стандарта (релиз 0.3) была сформирована совсем недавно. 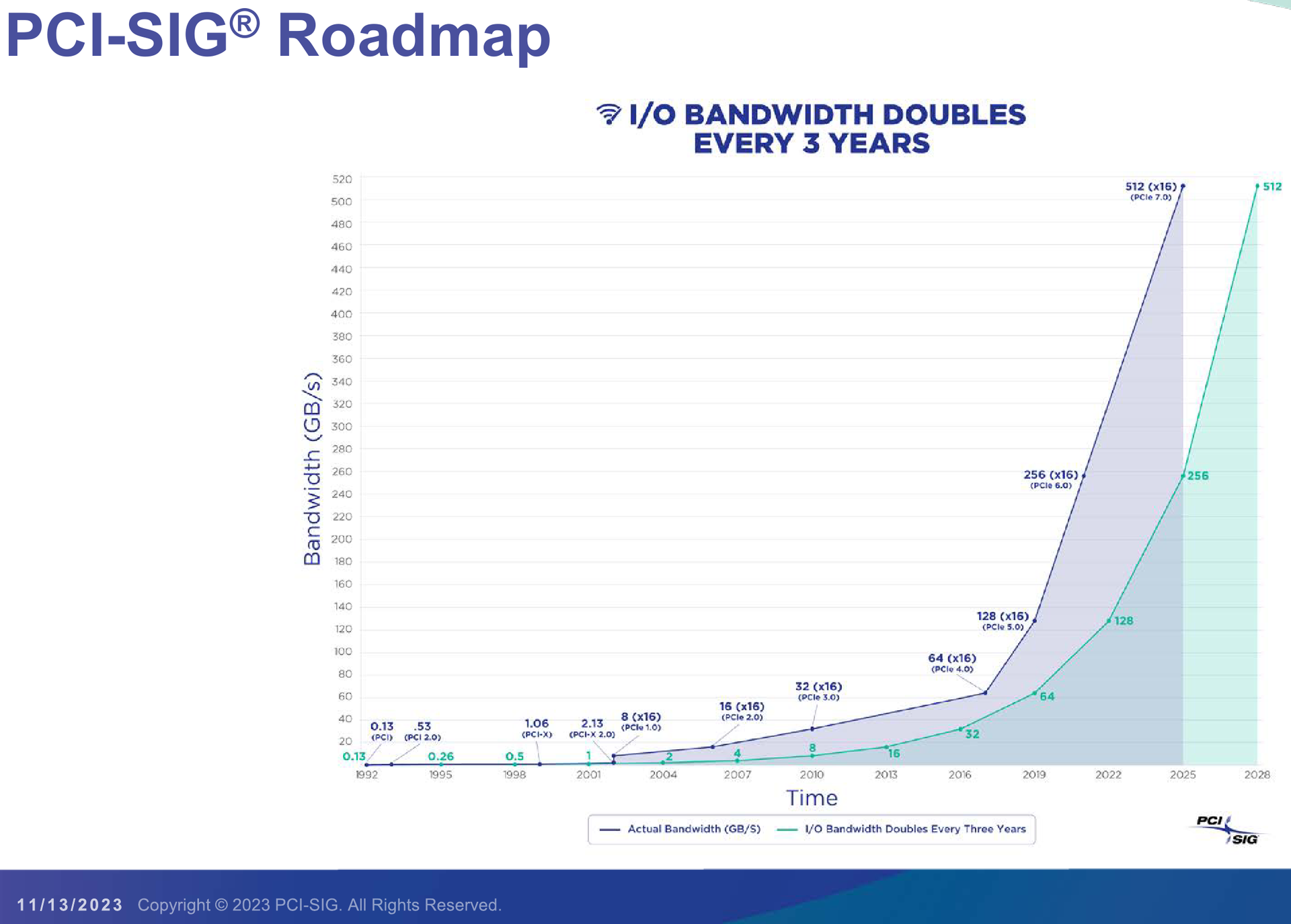
Источник изображений здесь и далее: PCI-SIG На данный момент релиз спецификаций PCI Express 7.0 ожидается в 2025 году, а массовое появление новых продуктов на их основе запланировано на 2028 год. Впрочем, первые продукты наверняка появятся чуть раньше. Во II квартале 2024 года ожидается появление первых решений с PCIe 6.0, а массовый характер программа тестирования таких устройств на соответствие стандарту примет лишь в 2025.  В августе этого года была сформирована новая рабочая группа PCI-SIG Optical Workgroup, ответственная за разработку оптического интерконнекта на базе PCI Express и взаимодействие с производителями в этой области. Задача заключается в адаптации стека технологий PCIe к оптической среде передачи данных с минимальными изменениями. Новые кабели позволят организовать соединения между стойками в пределах ЦОД в случаях, когда требуется минимальная латентность.  Однако полная замена медных кабелей не планируется — оптика дополнит медь там, где нужна большая длина соединения. Поэтому PCI-SIG ведёт разработку нового стандарта электрических кабелей под общим названием CopprLink, который должен будет заменить существующие кабели OCuLink. Возможностей последних для организации внутрисистемного интерконнекта в современных условиях уже не всегда достаточно.  Новые серверы и СХД требуют более высокой пропускной способности и гибкости топологии, что учитывается при разработке CopprLink. Эти кабели позволят как обеспечивать высокоскоростные подключения в пределах самих систем, так и соединять между собой шасси в пределах стойки. Разрабатываются и варианты для межстоечного соединения.  Вопреки непроверенным слухам, CopprLink не поддерживает передачу сколько-нибудь мощного питания и не является заменой стандарту 12VHPWR. В настоящее время спецификации CopprLink, обеспечивающего работу на скоростях PCIe 5.0/6.0, уже достигли версии 0.9. Полноценный анонс технологии должен состояться в начале 2024 года. 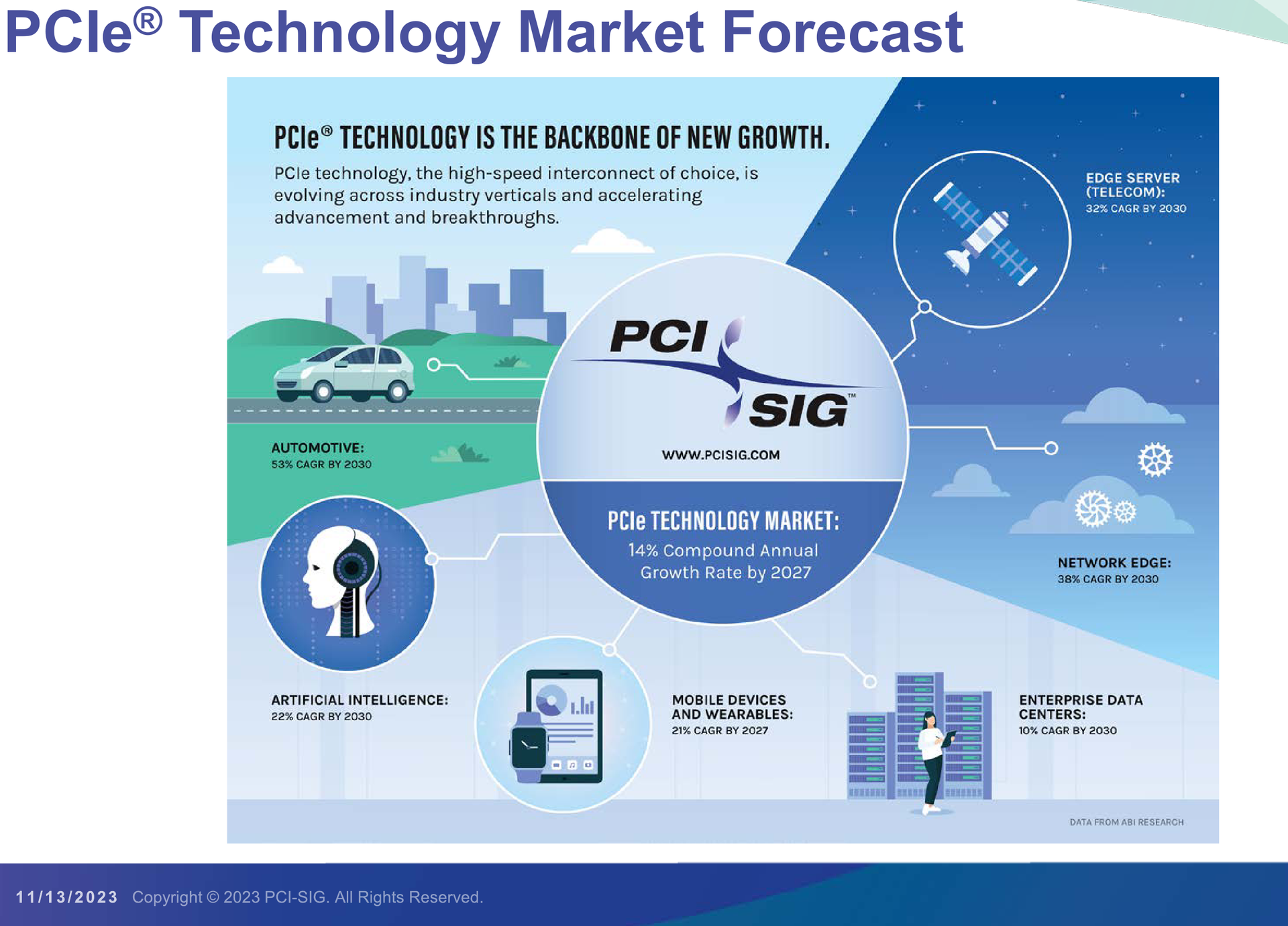 Технология PCI Express востребована во многих сегментах, от традиционных серверов и ПК до крупных ЦОД, телеком-платформ, ИИ-кластеров, умного транспорта и даже в мобильных и носимых устройствах. Ожидается, что в период до 2027 показатель CAGR для рынка PCIe-решений составит 14 %, а к концу периода он достинет объёма $10 млрд. Быстрее всего развитие будет идти в секторе автомобильных решений (CAGR 53 % до 2030 года), периферийных сетевых (38 %) и телекоммуникационных (32 %) платформ.
17.11.2023 [13:35], Сергей Карасёв
Cornelis Networks присоединилась к консорциуму Ultra EthernetКомпания Cornelis Networks, поставщик HPC-интерконнекта на базе технологий Omni-Path, объявила о вступлении в организацию Ultra Ethernet Consortium. Специалисты Cornelis помогут в разработке интерконнекта нового поколения с высокой пропускной способностью. Цель консорциума Ultra Ethernet, сформированного в июле нынешнего года, заключается в создании основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Cornelis Networks отмечает, что требования к производительности и масштабируемости приложений ИИ обнажают ограничения традиционных коммуникационных решений на основе Ethernet. А поэтому необходима разработка альтернативных систем, способных удовлетворить потребность в высокоскоростных соединениях для обмена огромными массивами данных. Cornelis Networks привнесёт в консорциум свой опыт в области высокопроизводительных сетей, а также базу актуальных и уникальных технологий. 
Источник изображения: Cornelis Networks Ожидается, что благодаря сотрудничеству коллективный опыт участников Ultra Ethernet Consortium позволит установить новые стандарты совместимости и производительности, что в конечном итоге приведет к появлению революционных коммуникационных платформ. На сегодняшний день в состав консорциума входят AMD, Arista, Broadcom, Cisco, Eviden, HPE, Intel, Meta✴, Microsoft, Oracle и другие крупные компании.
15.11.2023 [20:25], Алексей Степин
Cornelis Networks анонсировала семейство продуктов CN5000 для экосистемы Omni-Path 400GКак известно, уроненное Intel знамя Omni-Path подхватила компания Cornelis Networks, которая достаточно успешно и уверенно продолжает совершенствовать эту систему интерконнекта. Буквально на днях состоялся официальный анонс CN5000 — серии решений для экосистемы Omni-Path второго поколения, способных работать на скорости 400 Гбит/с. 
Источник изображений здесь и далее: Cornelis Networks О планах Cornelis Networks относительно CN5000 и следующих за ним поколений Omni-Path уже рассказывалось ранее. Во втором поколении разработчики отказались от Performance Scale Messaging и целиком перешли на открытый стек OFI (libfabric). По всей видимости, дела у Cornelis идут хорошо, поскольку анонс состоялся уже сейчас, хотя ранее выход CN5000 был запланирован на 2024 год. Никаких данных о сроках начала массовых поставок и ценах компания-разработчик пока не приводит, но потенциальным заказчикам уже предлагает связаться с отделом продаж.  Компания назвала главные достоинства новой технологии. Среди них высокая инфраструктурная эффективность, отличное соотношение цены и качеству, высокая защищённость соединений, реализация QoS, а также лучшая в своём классе латентность (менее 1 мкс), что особенно важно для рынков ИИ и HPC.  В основе инфраструктуры Omni-Path CN5000 лежат три ключевых продукта: хост-адаптеры PCIe 5.0, непосредственно устанавливаемые в узлы, 48-портовые 1U-коммутаторы и 576-портовые 17U-директоры. Для всех трёх доступно как воздушное, так и жидкостное охлаждение. Фабрика на базе CN5000 может содержать до 330 тыс. узлов, чего достаточно для построения крупномасштабных HPC-систем.
24.10.2023 [12:35], Сергей Карасёв
Консорциум PCI-SIG открыл тестовые лаборатории для технологии PCI ExpressКонсорциум PCI-SIG объявил об открытии авторизованных испытательных лабораторий (ATL) для тестирования технологий PCI Express (PCIe). Участники PCI-SIG смогут получить статус лаборатории, пройдя специальный квалификационный процесс. Прохождение тестирования на базе ATL позволит заинтересованным сторонам претендовать на включение в список интеграторов PCI-SIG Integrators List. Лаборатории обязаны обеспечивать возможность проведения необходимых тестовых измерений в соответствии с требованиями PCI-SIG. 
Источник изображения: PCI-SIG Первой авторизованной площадкой ATL стала Granite River Labs (GRL). Компания начала деятельность в 2010 году: она предоставляет услуги по тестированию, чтобы помочь разработчикам оборудования во внедрении технологий высокоскоростного подключения. GRL сотрудничает с более чем 500 компаниями-производителями полупроводников и различных систем, предоставляя комплексные инженерные услуги и решения для испытаний в своих центрах исследований и разработок по всему миру. Появление авторизованных тестовых лабораторий предоставляет разработчикам дополнительную возможность принять участие в программе соответствия PCI-SIG. При этом компании смогут выводить продукты с поддержкой PCIe на коммерческий рынок в соответствии со своим собственным графиком.
10.10.2023 [22:33], Алексей Степин
Опубликованы первичные спецификациии InfiniBand XDR: 200 Гбит/с на линию, 800 — на портАссоциация IBTA (InfiniBand Trade Association), ответственная за развитие данного стандарта, опубликовала новые спецификации, утверждающие характеристики стандарта InfiniBand XDR. Хотя Ethernet активно вытесняет другие сетевые стандарты благодаря быстрому росту скоростей и активному освоению всё новых технологий вроде RDMA, InfiniBand (IB) зачастую продолжает оставаться предпочтительным выбором для HPC-систем благодаря низкому уровню задержек, особенно критичному в случае крупномасштабной сети. Согласно данным Naddod, задержи у InfiniBand составляют не более 150–200 нс, в то время как для Ethernet этот показатель обычно составляет 500 нс и более. Проблему с отставанием в пропускной способности должны решить новые спецификации, опубликованные IBTA в виде томов Volume 1 Release 1.7 (ядро архитектуры InfiniBand) и Volume 2 release 1.5 (аспекты физической реализации). Наиболее важным в новых спецификациях является первичное введение и описание стандарта XDR, предусматривающего скорость передачи данных 200 Гбит/с на каждую линию. Это автоматически даёт 800 Гбит/с на стандартный IB-порт из четырёх линий, а для связи между коммутаторами может быть использован канал на восемь линий, что даёт 1600 Гбит/с. 
Текущие планы IBTA по развитиию InfiniBand. Источник: InfiniBand Trade Association Также тома содержат финальные спецификации физического уровня для InfiniBand NDR (100 Гбит/с на линию, 400 Гбит/с на порт). В данный момент полные тексты спецификаций доступны только для зарегистрированных пользователей на сайте IBTA. С кратким обзором Volume 1 Release 1.7 можно ознакомиться здесь. Помимо этого, в обновлениях описывается улучшенная поддержка крупных многопортовых коммутаторов (radix switches), а также механизмы, улучшающие обработку сетевых заторов (congestion control). Как отмечает IBTA, InfiniBand XDR должен стать новым золотым стандартом в среде ИИ и HPC благодаря оптимальному сочетанию высокой пропускной способности с низким уровнем задержек и энергоэффективностью. Дальнейшие планы IBTA включают освоение ещё более скоростных стандартов GDR и LDR к 2026 и 2030 гг. соответственно. |
|

