Материалы по тегу: llm
|
18.10.2023 [14:22], Сергей Карасёв
Китайский ИИ-стартап Baichuan привлек $300 млн от Alibaba, Tencent и XiaomiМолодая китайская фирма Baichuan Intelligent Technology, базирующаяся в Пекине, по сообщению ресурса SiliconAngle, осуществила раунд финансирования Series A1, в ходе которого на развитие привлечено $300 млн. Стартап Baichuan, специализирующийся на технологиях ИИ, начал деятельность в текущем году. Учредителем компании является основатель китайской поисковой службы Sogou (входит в Tencent) Ван Сяочуань (Wang Xiaochuan). 
Источник изображения: pixabay.com Baichuan разрабатывает большие языковые модели (LLM), призванные конкурировать в том числе с платформами OpenAI. С момента своего основания Baichuan представила четыре открытые LLM, которые были загружены приблизительно 6 млн раз. Одна из них — Baichuan-13B на архитектуре Transformer (она же лежит в основе GPT) с 13 млрд параметров. Эта модель обучена на китайском и английском языках. Кроме того, китайский стартап создал две проприетарные LLM — Baichuan-53B и Baichuan2-53B, которые насчитывают 53 млрд параметров. Baichuan стала одной из первых компаний, получивших разрешение китайских регулирующих органов на выпуск ИИ-моделей в стране. После этого компания начала коммерческое внедрение Baichuan2-53B. В ходе начального раунда финансирования Baichuan получила $50 млн. В нынешней программе поддержки Series A1 участвуют Alibaba Group Holding Ltd., Tencent Holdings Ltd. и Xiaomi. Таким образом, общая сумма полученных с момента основания Baichuan средств достигла $350 млн. Рыночная капитализация компании превысила $1 млрд, что делает её «единорогом».
07.10.2023 [23:21], Владимир Мироненко
Docker представил GenAI Stack и Docker AI для быстрого создания приложений генеративного ИИ и интеллектуальной работы с кодом и окружениемПоставщик инструментов для контейнерной разработки Docker Inc. представил на конференции DockerCon, прошедшей на этой неделе в Лос-Анджелесе, решение Stack GenAI, позволяющее разработчикам всего за несколько кликов развернуть полный стек ПО для создания приложений генеративного ИИ. В Docker заявили, что GenAI Stack устраняет необходимость поиска и объединения технологий, необходимых для поддержки LLM. Созданный в партнёрстве с Neo4., LangChain и открытым проектом Ollama новый стек представляет собой предварительно сконфигурированную, готовую к написанию кода высокозащищенную платформу, которая обеспечивает доступ к предварительно настроенным большим языковым моделям (LLM), таким как Llama2, GPT-3.5 и GPT-4, векторной и графовой базе данных Neo4J, а также среде разработки LangChain и инструментам Ollama. Вкупе все эти решения упрощают локальное управление LLM и делают процесс разработки ИИ более плавным. 
Источник изображения: Docker Гендиректор Docker Скотт Джонстон (Scott Johnston) сообщил , что разработчики с энтузиазмом воспринимают генеративный ИИ, но не понимают, с чего начать работу с ним из-за разнообразия доступных стеков технологий.«Сегодняшний анонс устраняет эту дилемму, позволяя разработчикам быстро и безопасно приступить к работе, используя инструменты, контент и сервисы Docker, которые они уже знают и любят, вместе с партнёрскими технологиями на переднем крае разработки приложений генеративного ИИ», — сказал он. В Docker заявили, что GenAI Stack уже доступен на GitHub. Он поставляется с предварительно настроенными LLM Llama 2, Code Llama, Mistral, GPT-3.5 и GPT-4. Ollama предоставит разработчикам поддержку, необходимую для работы с этими моделями и их тюнинга, а Neo4J предоставляет специализированную СУБД. Среда разработки ИИ LangChain помогает организовать базовую LLM, базу данных и создаваемое приложение. Docker же предоставляет вспомогательные инструменты, шаблоны кода, а также всё необходимое для разработки приложений. Компания также представила решение DockerAI, которое предоставляет разработчикам автоматизированные и контекстно-зависимые рекомендации при создании кода, редактировании конфигураций Dockerfile или Docker Compose, отладке и тестировании приложений. Джонстон отметил, что такие инструменты вроде GitHub Copilot в основном ориентированы на генерацию кода приложений. «Помимо исходного кода приложения состоят из веб-серверов, языковых сред выполнения, баз данных, очередей сообщений и многих других технологий, — пояснил он. — Docker AI помогает разработчикам быстро и безопасно определять и устранять неполадки во всех аспектах приложения».
06.10.2023 [01:01], Владимир Мироненко
Dell расширила набор комплексных решений и сервисов для «локализации» генеративного ИИDell объявила о расширении портфеля решений Dell Generative AI Solutions с целью поддержки компаний в трансформации методов работы с генеративным искусственным интеллектом (ИИ). Первоначально в разработанном совместно с NVIDIA решении Dell Validated Design for Generative AI основное внимание уделялось обучению ИИ, но теперь продукт также поддерживает тюнинг моделей и инференс. Это, в частности, означает, что у клиентов есть возможность развёртывать модели в собственных ЦОД, передаёт StorageReview. Dell Validated Design for Generative AI with NVIDIA for Model Customization предлагает предварительно обученные модели, которые извлекают знания из данных компания без необходимости создания моделей с нуля и обеспечивают безопасность информации. Благодаря масштабируемой схеме тюнинга у организаций теперь есть множество способов адаптировать модели генеративного ИИ для выполнения конкретных задач с использованием своих собственных данных. 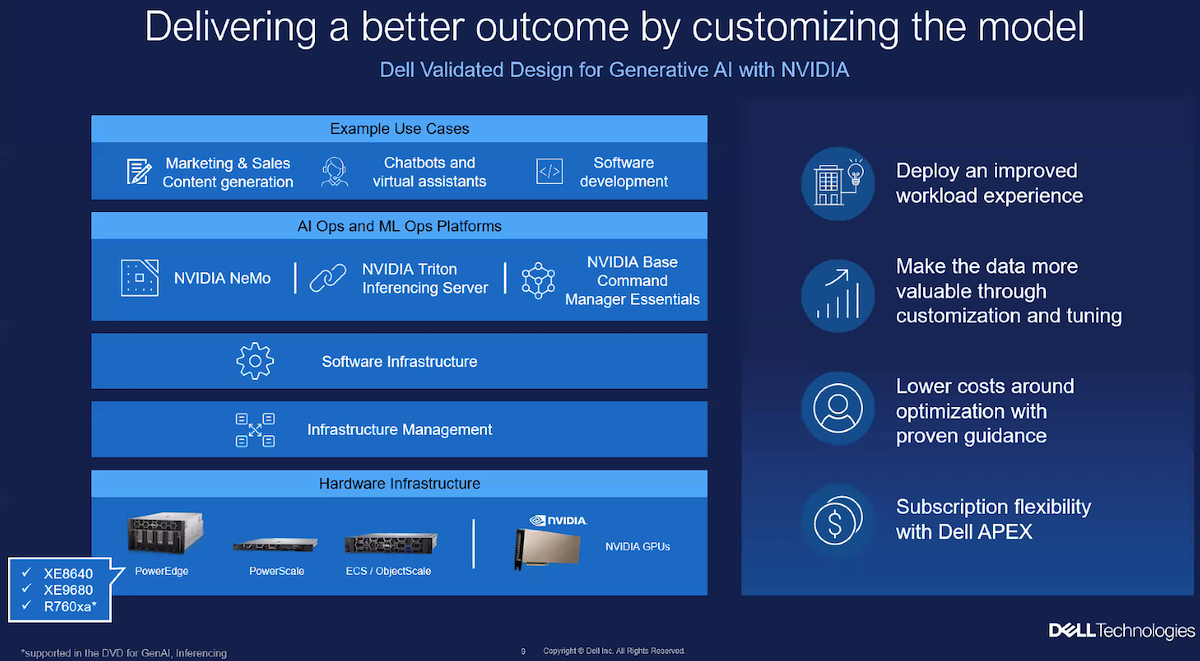
Изображения: Dell (via StorageReview) Инфраструктура базируется на GPU-серверах Dell PowerEdge XE9680 и PowerEdge XE8640 с ускорителями NVIDIA, стеком NVIDIA AI Enterprise и фирменным ПО Dell. Компания позиционирует это как идеальное решение для компаний, которые хотят создавать генеративные ИИ-модели, сохраняя при этом безопасность своих данных на собственных серверах. Для хранения данных предлагаются различные конфигурации Dell PowerScale и Dell ObjectScale. Доступ к этой инфраструктуре также возможен по подписке в рамках Dell APEX. 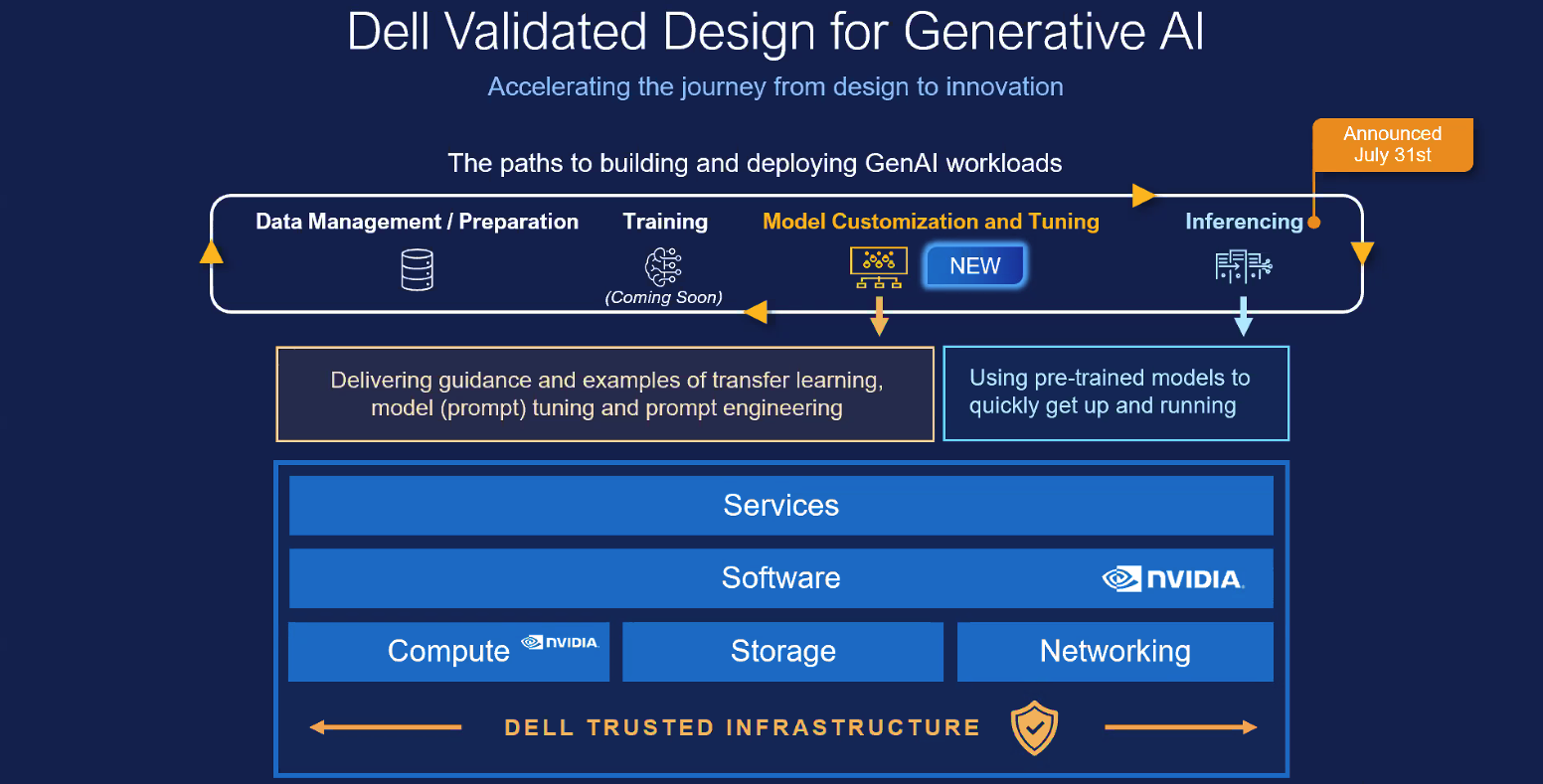 Dell также расширила портфолио профессиональных сервисов. Так, появились сервисы по подготовке данных (Data preparation Services), разработанные специально для предоставления клиентам тщательно подготовленных, очищенных и корректно отформатированных наборов данных. А с помощью сервисов по внедрению (Dell Implementation Services) для компании в короткие сроки создадут полностью готовую платформу генеративного ИИ, оптимизированную для инференса и подстройки моделей. 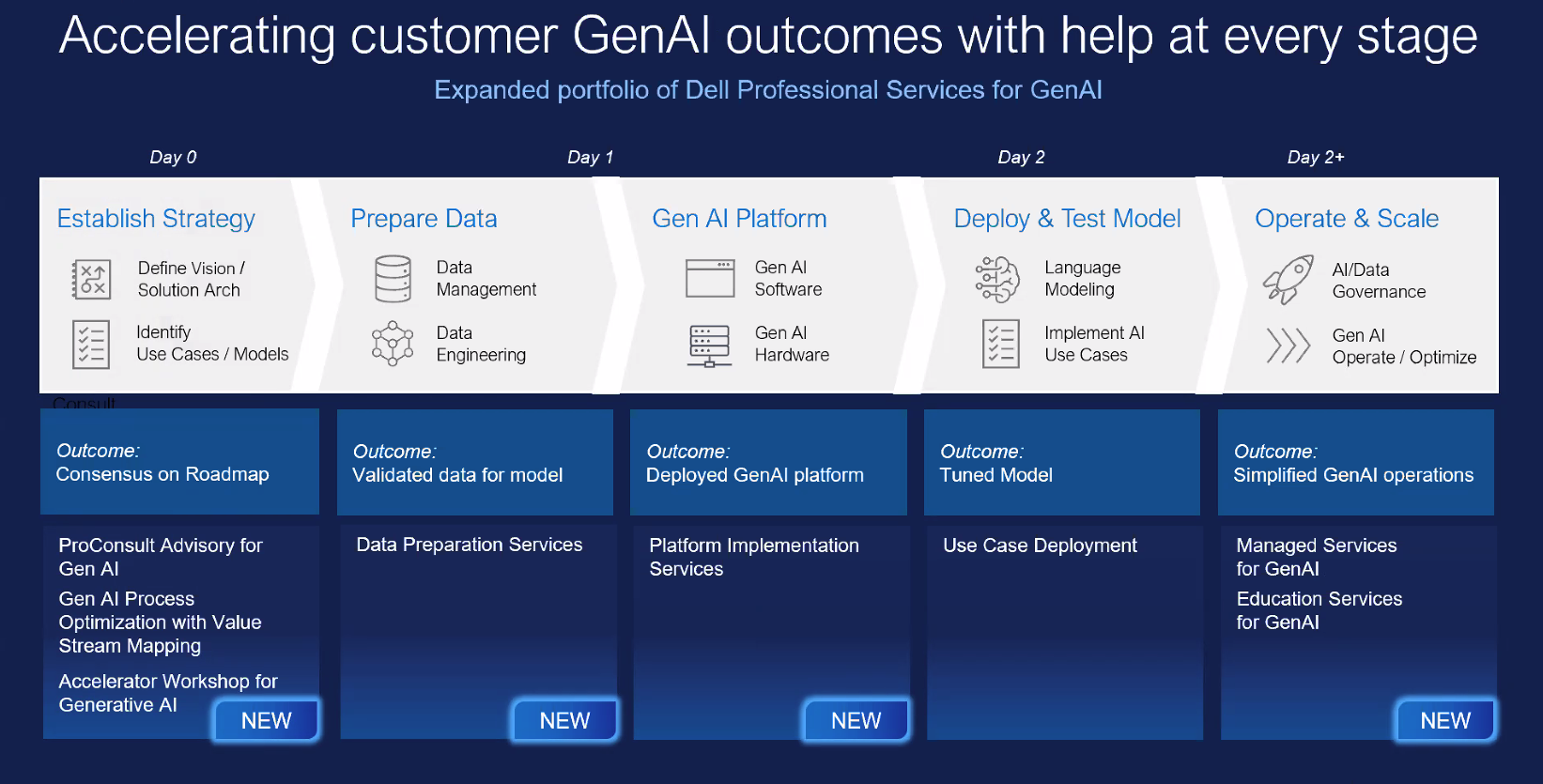 Dell также предлагает новые образовательные сервисы (Education Services) для клиентов, которые хотят обучить своих сотрудников современным ИИ-технологиям. Наконец, было объявлено о партнёрстве Dell и Starburst, в рамках которого Dell интегрирует платформы PowerEdge и СХД с аналитическим ПО Starburst, чтобы помочь клиентам создать централизованное хранилище данных и легче извлекать необходимую информацию из своих данных. 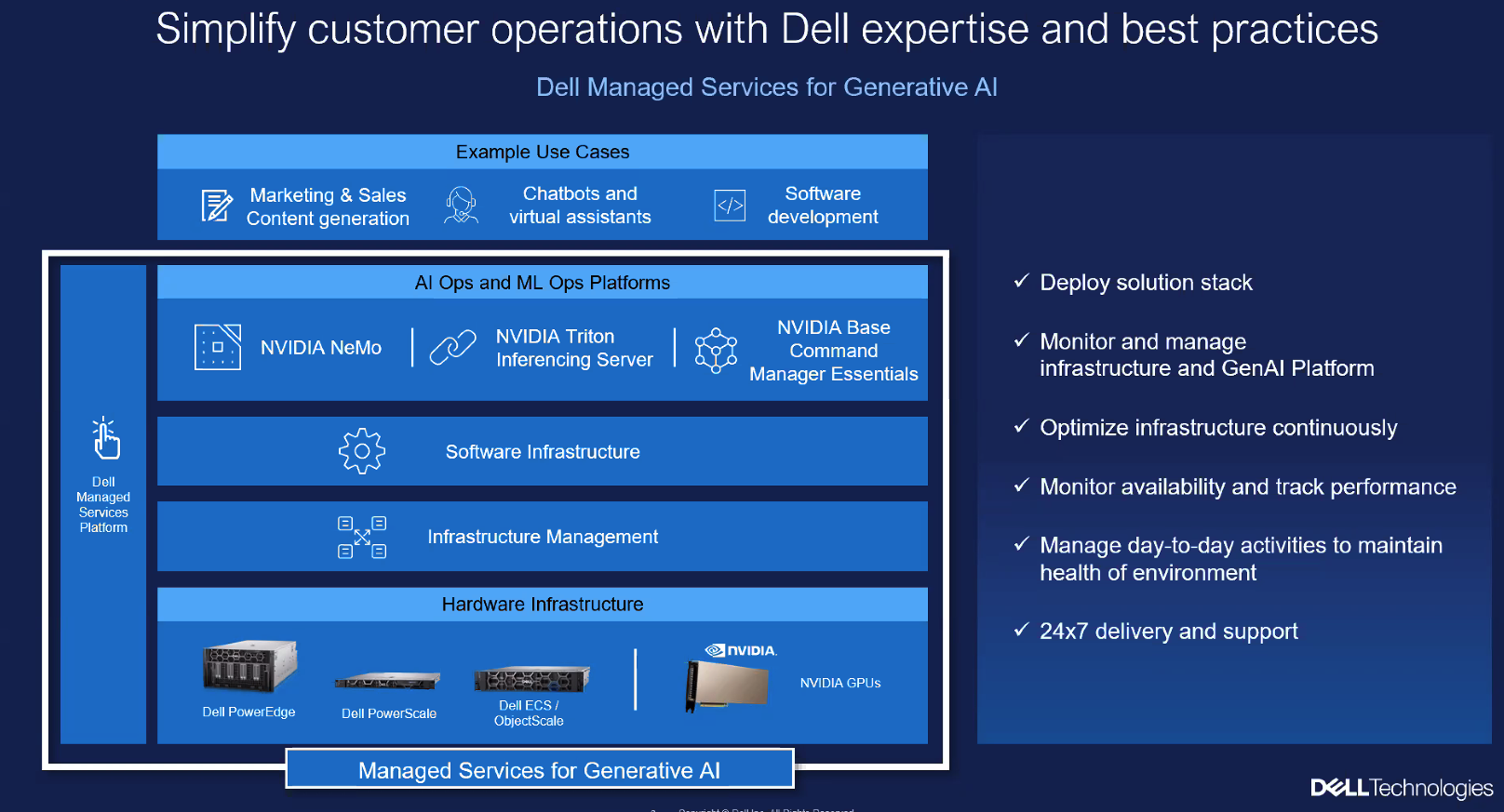 Энди Турай (Andy Thurai), вице-президент и главный аналитик Constellation Research, сообщил в интервью SiliconANGLE, что наиболее мощные LLM, такие как GPT-4, обучаются в специально созданных облачных окружениях из-за их огромных размеров и требований к ресурсам. Вместе с тем некоторые компания ищут способы обучения своих собственных, гораздо меньших по размеру LLM в локальных средах. Турай отметил, что Dell потребуется время, чтобы добиться каких-либо успехов в «локализации» генеративного ИИ, поскольку настройка инфраструктуры, перемещение подгтовка данных — занятие не для слабонервных. Как сообщается, решение Dell Validated Design for Generative AI with NVIDIA for Model Customization будет доступно глобально позже в октябре. Профессиональные сервисы появятся тогда же, но только в некоторых странах. А решение Dell для озера данных на базе Starburst станет глобально доступно в I половине 2024 года. Фактически новые решения Dell являются развитием совместной с NVIDIA инициативы Project Helix.
05.10.2023 [13:06], Сергей Карасёв
ИИ-провайдер 6Estates развернул свою первую систему NVIDIA DGX BasePOD на базе DGX H100Компания 6Estates, сингапурский провайдер ИИ-решений для корпоративных заказчиков, объявила о развёртывании первой системы NVIDIA DGX BasePOD на основе DGX H100. Кластер будет применяться для решения ресурсоёмких задач в области ИИ. Фирма 6Estates, созданная на базе Национального университета Сингапура и Университета Цинхуа, специализируется на предоставлении предприятиям решений, использующих LLM. Кроме того, 6Estates является участником программы NVIDIA Inception по поддержке стартапов в области ИИ. DGX BasePOD — это референсная архитектура, которая объединяет вычислительные мощности, сетевые инструменты, СХД, необходимое ПО и другие компоненты в интегрированную ИИ-инфраструктуру на основе NVIDIA DGX. 6Estates планирует использовать BasePOD на базе DGX H100 для своего нового предложения Model Solutions, которое даёт предприятиям возможность создавать персонализированные LLM и приложения для конкретных задач. Кроме того, 6Estates получит доступ к комплексному пакету фреймворков и ИИ-инструментов NVIDIA AI Enterprise. 
Источник изображения: 6Estates Используя DGX H100, 6Estates существенно сократит время обучения моделей и обеспечит более быстрое предоставление услуг Model Solutions корпоративным клиентам. Кластер также будет поддерживать существующие решения 6Estates в области ИИ, в частности, специализированную платформу, которая автоматизирует обработку и анализ неструктурированных документов без шаблонов, а также автоматизирует рабочие процессы для кредиторов и торговых компаний.
01.10.2023 [20:55], Руслан Авдеев
Microsoft ищет более дешёвые в эксплуатации и простые альтернативы языковым моделям OpenAIХотя Microsoft принадлежит 49 % OpenAI, занимающейся разработкой популярных и производительных языковых моделей вроде GPT-4, интересы компаний не всегда совпадают. Как сообщает Silicon Angle, Bing Chat Enterprise первой и ChatGPT Enterprise второй, по сути, конкурируют за одну и ту же целевую аудиторию. Кроме того, Microsoft, стремящаяся внедрить ИИ почти во все свои программные продукты, готовит новые, более простые и менее ресурсоёмкие модели, чем GPT-4. По данным источников в OpenAI, в Microsoft обеспокоены высокой стоимостью эксплуатации передовых ИИ-моделей. Microsoft пытается встроить ИИ во многие продукты, включая Copilot для Windows на базе GPT-4. С учётом того, что пользователей Windows в мире больше 1 млрд, в компании опасаются, что повсеместное распространение ИИ-инструментов приведёт к неконтролируемому росту расходов. По некоторым данным, компания уже поручила части из своих 1,5 тыс. сотрудников ИИ-департамента заняться более экономичными альтернативами — пусть даже они будут не столь «сообразительными». 
Источник изображения: Microsoft Хотя реализация соответствующих проектов всё ещё находится на ранних стадиях, уже появилась информация, что компания начала внутренние тесты моделей собственной разработки. В частности, «творческий» и «точный» режимы Bing Chat опираются на GPT-4, тогда как «сбалансированный» использует новые модели Prometheus и Turing. Последняя может отвечать только на простые вопросы, а более каверзные она всё равно вынуждена передавать на обработку творению OpenAI. Для программистов у Microsoft есть модель Phi-1 с 1,3 млрд параметров, которая может эффективно генерировать код, но в остальном отстаёт от GPT-4. Ещё одной альтернативой стала разработанная Microsoft модель Orca на основе Meta✴ Llama-2, принадлежащей Meta✴. По некоторым данным, Orca близка по возможностям к моделям OpenAI, но компактнее и требует значительно меньше ресурсов. Считается, что подразделение Microsoft использует около 2 тыс. ускорителей NVIDIA, большинство из которых сегодня и применяется для тренировки более эффективных моделей, имеющих узкую специализацию в отличие от многопрофильной GPT-4. Если раньше состязание на рынке шло за создание ИИ с наибольшими возможностями, то теперь одним из важнейших факторов становится стоимость разработки и обслуживания таких инструментов.
30.09.2023 [16:02], Сергей Карасёв
ИИ за углом: Cloudflare внедрит ускорители NVIDIA в своей глобальной edge-сетиАмериканская компания Cloudflare, предоставляющая услуги CDN, по сообщению Datacenter Dynamics, будет использовать ускорители NVIDIA в своей глобальной edge-сети для обработки ресурсоёмких нагрузок ИИ, в частности, больших языковых моделей (LLM). Как отмечает ресурс NetworkWorld, инициатива носит название Workers AI. Заказчики смогут получать доступ к мощностям устройств NVIDIA для реализации своих ИИ-проектов. Cloudflare также задействует коммутаторы NVIDIA Ethernet и полный набор софта NVIDIA для инференса, включая TensorRT-LLM и Triton Inference. Поначалу не планируется поддержка пользовательских ИИ-моделей: клиентам будет предоставляться доступ только к Meta✴ Llama 2 7B и M2m100-1.2, OpenAI Whisper, Hugging Face Distilbert-sst-2-int8, Microsoft Resnet-50 и Baai bge-base-en-v1.5. В будущем этот перечень планируется расширять. О моделях ускорителей, которые возьмёт на вооружение Cloudflare, ничего не говорится. Но отмечается, что к концу 2023 года решения NVIDIA будут внедрены более чем в 100 городах, а в течение 2024-го они появятся почти во всех зонах присутствия Cloudflare. Глобальная edge-сеть компании использует ЦОД более чем в 300 городах по всему миру. 
Источник изображения: NVIDIA Ещё одной новой инициативой Cloudflare в области ИИ является Vectorize — векторная база данных. Она поможет разработчикам создавать приложения на основе ИИ полностью на платформе Cloudflare. Говорится, что Vectorize получит интеграцию с Workers AI. Наконец, готовится AI Gateway — система оптимизации и управления производительностью, предназначенная для работы с ИИ-приложениями, развёрнутыми в сети Cloudflare.
29.09.2023 [23:55], Алексей Степин
Без CUDA никуда? ИИ-стартап Lamini полагается исключительно на ускорители AMD InstinctКогда речь заходит о больших языковых моделях (LLM), то чаще всего подразумевается их обучение, дообучение и запуск на аппаратном обеспечении NVIDIA, как наиболее широко распространённом и лучше всего освоенном разработчиками. Но эта тенденция понемногу меняется — появляются либо специфические решения, могущие поспорить в эффективности с ускорителями NVIDIA, либо разработчики осваивают другое «железо». К числу последних принадлежит ИИ-стартап Lamini, сделавший ставку на решения AMD: ускорители Instinct и стек ROCm. Главным продуктом Lamini должна стать программно-аппаратная платформа Superstation, позволяющая создавать и развёртывать проекты на базе генеративного ИИ, дообучая базовые модели на данных клиента. 
Изображения: Lamini Напомним, ROCm представляет собой своего рода аналог NVIDIA CUDA, но упор в решении AMD сделан на более широкую поддержку аппаратного обеспечения, куда входят не только ускорители и GPU, но также CPU и FPGA — всё в рамках инициативы Unified AI Stack. К тому же в этом году у ROCm появилась интеграция с популярнейшим фреймворком PyTorch, который в версии 2.0 получил поддержку ускорителей AMD Instinct.  Что же касается Lamini и её проекта, то, по словам основателей, он привлёк внимание уже более 5 тыс. потенциальных клиентов. Интерес к платформе проявили, например, Amazon, Walmart, eBay, GitLab и Adobe. В настоящее время платформа Lamini уже более года работает на кластере, включающем в себя более 100 ускорителей AMD Instinct MI250, и обслуживает клиентов. При этом заявляется возможность масштабирования до «тысяч таких ускорителей». Более того, AMD сама активно пользуется услугами Lamini.  На данный момент это единственная LLM-платформа, целиком работающая на аппаратном обеспечении AMD, при этом стоимость запуска на ней ИИ-модели Meta✴ Llama 2 с 70 млрд параметров, как сообщается, на порядок дешевле, нежели в облаке AWS. Солидный объём набортной памяти (128 Гбайт) у MI250 позволяет разработчикам запускать более сложные модели, чем на A100. Согласно тестам, проведённым Lamini для менее мощного ускорителя AMD Instinct MI210, аппаратное обеспечение «красных» способно демонстрировать в реальных условиях до 89% от теоретически возможного в тесте GEMM и до 70% от теоретической пропускной способности функции ROCm hipMemcpy. Выбор Lamini несомненно принесёт AMD пользу в продвижении своих решений на рынке ИИ. К тому же в настоящее время они более доступны, чем от NVIDIA H10. Сама AMD объявила на мероприятии AI Hardware Summit, что развитие платформы ROCm в настоящее время является приоритетным для компании.
29.09.2023 [21:29], Владимир Мироненко
AWS объявила о доступности Bedrock: широкий выбор базовых ИИ-моделей и тонкая настройка под нужды клиентаAmazon Web Services объявила об доступности сервиса Bedrock, анонсированного в апреле этого года. Amazon Bedrock представляет собой управляемый сервис, предлагающий высокопроизводительные базовые модели (FM) как от Amazon, так и от ведущих провайдеров, включая AI21 Labs, Anthropic, Cohere, Meta✴, Stability AI, а также широкий набор возможностей для создания клиентами собственных приложений на основе генеративного ИИ и их настройки с использованием собственных данных. По словам Amazon, в ближайшие недели в Bedrock появится большая языковая модель (LLM) Llama 2 от Meta✴ с 13 и 70 млрд параметров. Кроме того, в рамках недавно объявленного стратегического сотрудничества все будущие FM от Anthropic будут доступны в Amazon Bedrock с ранним доступом к уникальным функциям для кастомизации моделей и их тонкой настройки. Широкий выбор моделей, включая собственные модели Amazon Titan Embeddings, даст клиентам возможность найти нужное решение для каждого варианта применения и дообучить модель для достижения лучших результатов. 
Источник изображения: Amazon Поскольку Amazon Bedrock является бессерверным сервисом, клиентам не нужно управлять какой-либо инфраструктурой. CloudWatch поможет в отслеживании использования Bedrock и создании дашбордов, а CloudTrail — в мониторинге API и устранении проблем при интеграции с другими системами. Bedrock позволяет создавать приложения, соответствующие общему регламенту ЕС по защите данных (GDPR) или выполнять конфиденциальные рабочие нагрузки, регулируемых Законом США о переносимости и подотчетности медицинского страхования (HIPAA).
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 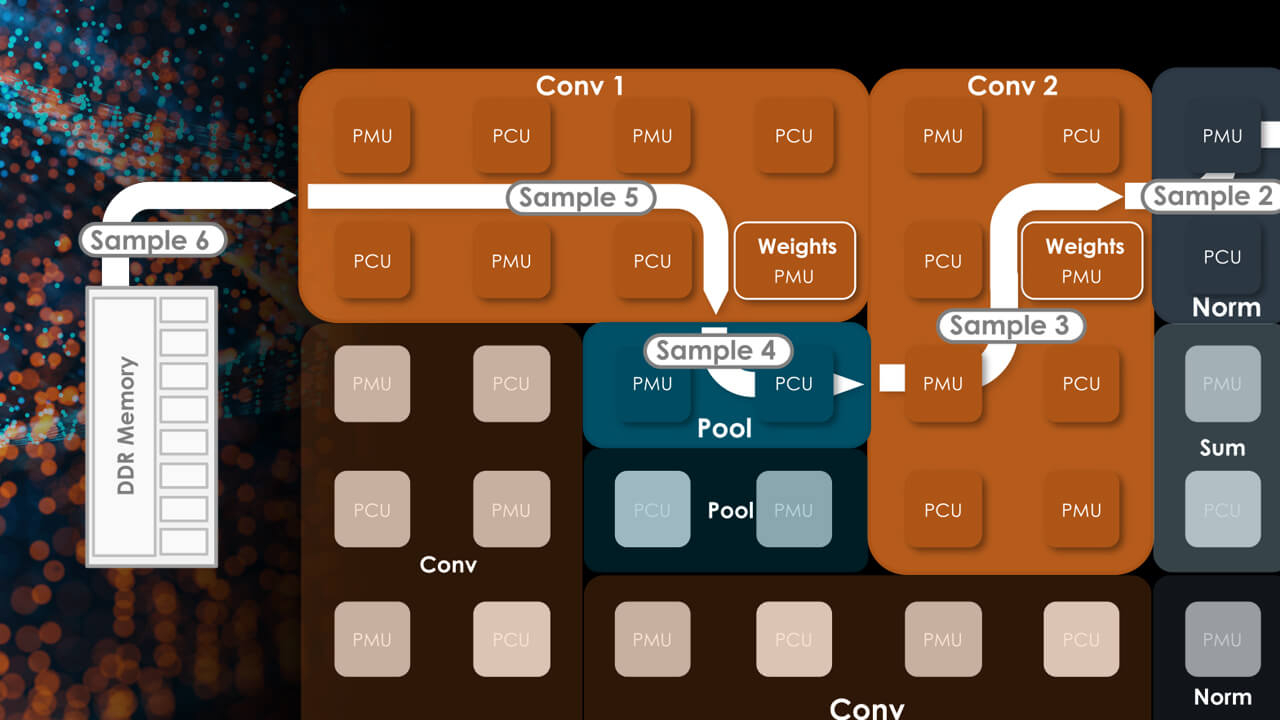
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 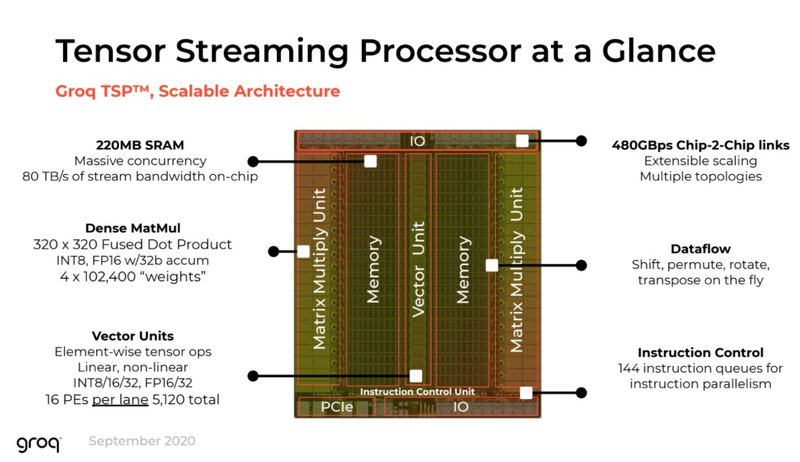 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 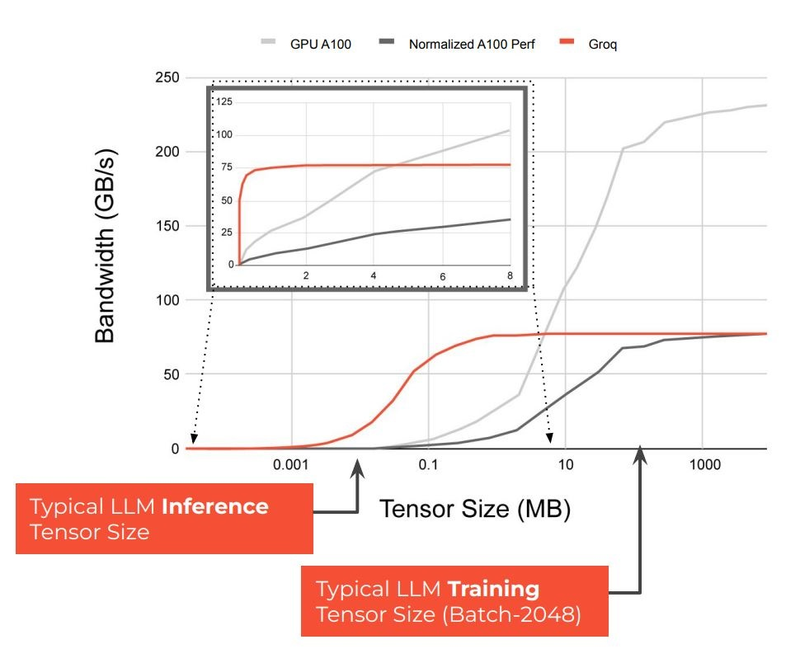 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения. 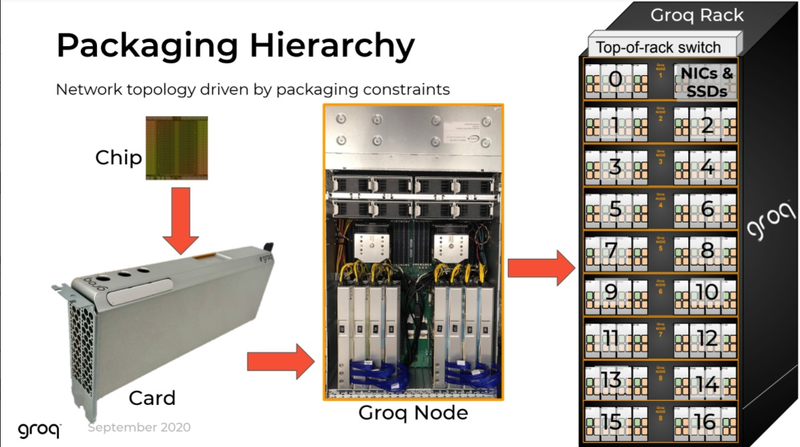 Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 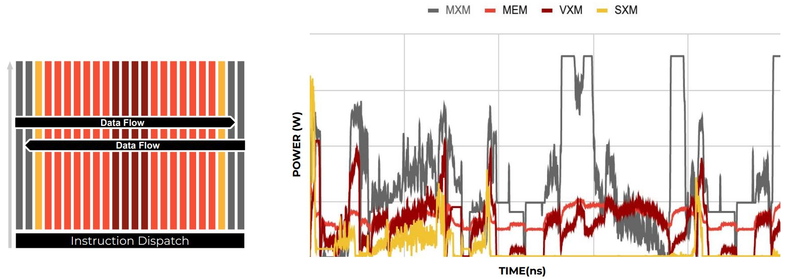
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 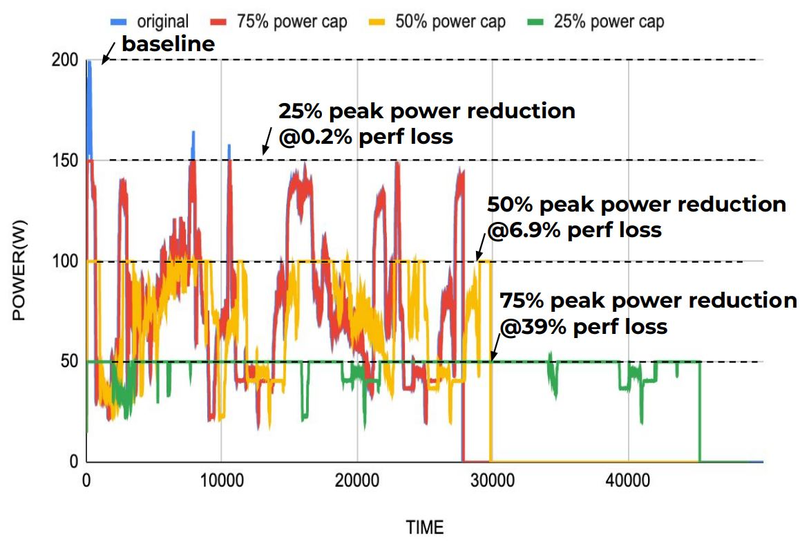
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту. |
|

