Материалы по тегу: llm
|
04.12.2023 [09:36], Владимир Мироненко
HPE и NVIDIA представили совместное решение для корпоративного ИИ, а HPE анонсировала LLM-платформу Project EthanHewlett Packard Enterprise (HPE) объявила о расширении стратегического сотрудничества с NVIDIA с целью создания инструментов для генеративного ИИ. Совместно разработанное, предварительно настроенное решение позволит предприятиям любого размера использовать собственные данные для быстрой настройки посредством RAG базовых ИИ-моделей, которые были обучены на больших наборах данных и могут быть адаптированы для выполнения различных задач от периферии до облака. HPE и NVIDIA также предоставляют в рамках сотрудничества полнофункциональные готовые решения для обработки приложений ИИ. Эти решения объединяют ПО фирменные среды разработки HPE для машинного обучения, HPE Ezmeral, платформы HPE ProLiant и HPE Cray, а также программный пакет NVIDIA AI Enterprise, включая NVIDIA NeMo. Аппаратная составляющая включает 16 серверов HPE ProLiant DL380a, несущих в общей сложности 64 ускорителя NVIDIA L40S и использующих DPU NVIDIA BlueField-3 и NVIDIA Spectrum-X. 
Источник изображений: HPE Программно-аппаратный комплекс, например, позволяет дообучить на собственных данных модель Llama 2 с 70 млрд параметров. Решение включает ПО HPE Machine Learning Development Environment с новыми возможностями в области генеративного ИИ для быстрого прототипирования и тестирования моделей, а также ПО HPE Ezmeral с поддержкой ускорителей, которое упростит развёртывания и ускорит подготовку данных для ИИ-нагрузок в гибридном облаке. Партнёры HPE смогут заказать решение уже в I квартале 2024 года. Заодно HPE анонсировала платформу Project Ethan, ориентированную на оркестрацию ресурсов в локальных или публичных облаках для работы с большими языковыми моделями (LLM). Кроме того, компания сообщила, как планирует более полно адаптировать платформу Greenlake для работы с ИИ. Например, OpsRamp, ИИ-решение для управления ИТ-операциями (IT Operations Management, ITOM), приобретённое компанией в марте этого года, уже доступно по подписке в Greenlake.  В OpsRamp добавлен HPE Sustainability Insight Center — инструмент для отслеживания и мониторинга энергопотребления ИТ-ресурсов, которыми управляет организация. Это было сделано для удобства клиентов, которые обучают и используют модели ИИ, и хотят контролировать потребление энергии. Обучение и инференс LLM, по словам компании, требует больших затрат электроэнергии — 1200 МВт·ч и 250 МВт·ч в день соответственно. Инструмент позволит управлять энергопотреблением с учётом возможностей компании. Также HPE представила пакет ПО Greenlake Hybrid Operations, объединяющий Ezmeral, OpsRamp с Sustainability Insight Center и набор решений для резервного копирования и восстановления HPE Data Protection Suite. Он позволит клиентам управлять, контролировать и защищать свои данные и рабочие нагрузки от периферии до облака.  В ближайшее время будет представлено и решение HPE Private Cloud Solutions для ИИ, основанное на аппаратных решениях HPE, обновлённой платформе HPE Greenlake for File Storage (эффективная ёмкость до 250 Пбайт, до 700 Гбайт/с на чтение и до 200 Гбайт/с на запись), OpsRamp и Zerto Cyber Resilience Vault. Последнее решение представляет собой автономную платформу для данных, которая помогает восстановить работу после атаки программы-вымогателя, если данные зашифрованы или удалены. Полная информация и даты доступности новых продуктов не разглашаются. Как сообщает ресурс The Register, решение объявить о них на мероприятии HPE Discover EMEA было принято в последнюю минуту.
30.11.2023 [03:10], Игорь Осколков
ИИ в один клик: llamafile позволяет запустить большую языковую модель сразу в шести ОС и на двух архитектурахMozilla представила первый релиз инструмента llamafile, позволяющего упаковать веса большой языковой модели (LLM) в исполняемый файл, который без установки можно запустить практически на любой современной платформе, причём ещё и с поддержкой GPU-ускорения в большинстве случаев. Это упрощает дистрибуцию и запуск моделей на ПК и серверах. llamafile распространяется под лицензией Apache 2.0 и использует открытые инструменты llama.cpp и Cosmopolitan Libc. Утилита принимает GGUF-файл с весами модели, упаковывает его и отдаёт унифицированный бинарный файл, который запускается в macOS, Windows, Linux, FreeBSD, OpenBSD и NetBSD. Готовый файл предоставляет либо интерфейс командной строки, либо запускает веб-сервер с интерфейсом чат-бота. 
Источник: GitHub / Mozilla Ocho Поддерживаются платформы x86-64 и ARM64, причём в первом случае автоматически определяется тип CPU и по возможности используются наиболее современные векторные инструкции. llamafile может использовать ускорители NVIDIA, а в случае платформы Apple задействовать Metal. Разработчики успешно протестировали инструмент в Linux (в облаке Google Cloud) и Windows с картой NVIDIA, в macOS и на NVIDIA Jetson. Впрочем, некоторые нюансы всё же есть. Так, в Windows размер исполняемого файла не может превышать 4 Гбайт, поэтому большие модели вынужденно хранятся в отдельном файле. В macOS на платформе Apple Silicon перед первым запуском всё же придётся установить Xcode, а в Linux, возможно, понадобится обновить некоторые компоненты. Подробности и примеры готовых моделей можно найти в репозитории проекта.
29.11.2023 [23:40], Руслан Авдеев
NVIDIA NeMo Retriever позволит компаниям дополнять ИИ-модели собственными даннымиNVIDIA представила сервис NeMo Retriever, позволяет компаниям дополнять данные для чат-ботов, ИИ-помощников и похожих инструментов специализированными сведениями — для получения более точных ответов на запросы. Сервис стал частью облачного семейства инструментов NVIDIA NeMo, позволяющих создавать, настраивать и внедрять модели генеративного ИИ. RAG (Retrieval Augmented Generation), метод улучшения производительности больших языковых моделей (LLM), позволяет повысить точность и безопасность ИИ-инструментов благодаря заполнению пробелов в «знаниях» языковых моделей с помощью сведений из внешних источников. Обучение каждой модели — чрезвычайно ресурсоёмкий процесс — обычно осуществляется довольно редко, а то и вовсе единожды. При этом до следующего обновления модель не имеет доступа к полной и актуальной информации, что может привести к неточностям, ошибкам и т.н. галлюцинациям. 
Источник изображения: Faisal Mehmood / Pixabay NeMo Retriever позволяет быстро дополнить LLM свежими сведениями в виде баз данных, HTML-страниц, PDF-файлов, изображений, видео и т.п. Другими словами, базовая модель с добавлением специализированных материалов станет заметно эрудированнее и «сообразительнее». При этом данные могут храниться где угодно — как в облаках, так и на собственных серверах компаний. Технология чрезвычайно полезна, поскольку обеспечивает сотрудникам компании работу с полезными данными, закрытыми для широкой публики, при этом пользуясь всеми преимуществами ИИ. 
Источник изображения: NVIDIA В отличие от открытых RAG-инструментов, NVIDIA, по данным самой компании, предлагает готовое к коммерческому использованию решение для доступных на рынке ИИ-моделей, уже оптимизированных для RAG и имеющих поддержку, а также регулярно получающих обновления безопасности. Другими словами, корпоративные клиенты могут брать готовые ИИ-модели и дополнять их собственными данными без отдельной ресурсоёмкой тренировки. NeMo Retriever позволит добавить соответствующие возможности универсальной облачной платформе NVIDIA AI Enterprise, предназначенной для оптимизации разработки ИИ-приложений. Регистрация разработчиков для раннего доступа к NeMo Retriever уже началась. Cadence Design Systems, Dropbox, SAP SE и ServiceNow уже работают с NVIDIA над внедрением RAG в свои внутренние ИИ-инструменты.
19.11.2023 [22:52], Сергей Карасёв
Dell и Hugging Face упростят развёртывание генеративного ИИ на базе локальной инфраструктурыКомпании Dell Technologies и Hugging Face объявили о заключении соглашения о сотрудничестве, цель которого заключается в том, чтобы помочь корпоративным клиентам в создании, настройке и использовании собственных систем на базе генеративного ИИ. Партнёры сформируют новый портал на платформе Hugging Face. Через него будут доступны специальные контейнеры и сценарии, которые помогут заказчикам быстро и безопасно разворачивать открытые ИИ-модели, доступные в репозитории Hugging Face. Ранее похожее решение было представлено для моделей Llama 2. 
Источник изображения: pixabay.com Для локального развёртывания ИИ-приложений будет использоваться оборудование Dell — серверы PowerEdge и СХД. Со временем на портале появятся дополнительные контейнеры с оптимизированными моделями для инфраструктуры Dell, предназначенные для внедрения ИИ-систем нового поколения. Ранее компания представила расширеннное портфолио комплексных решений и сервисов для «локализации» генеративного ИИ.
18.11.2023 [00:38], Владимир Мироненко
NVIDIA и Microsoft развернули в облаке Azure платформу для создания приложений генеративного ИИКомпания NVIDIA представила на конференции Microsoft Ignite 2023 сервис NVIDIA AI Foundry, который позволит предприятиям ускорить разработку и настройку пользовательских приложений генеративного ИИ с использованием собственных данных, развёртываемых в облаке Microsoft Azure. NVIDIA AI Foundry объединяет три элемента: набор базовых моделей NVIDIA AI Foundation, платформу и инструменты NVIDIA NeMo, а также суперкомпьютерные сервисы NVIDIA DGX Cloud AI. Вместе они предоставляют предприятиям комплексное решение для создания пользовательских моделей генеративного ИИ. Компании смогут затем развёртывать свои индивидуальные модели с помощью платформы NVIDIA AI Enterprise для создания приложений ИИ, включая интеллектуальный поиск, обобщение и генерацию контента. «Предприятиям нужны кастомные модели для реализации специализированных навыков, основанных на собственной ДНК их компании — их данных, — сообщил глава NVIDIA Дженсен Хуанг (Jensen Huang), — Сервис NVIDIA AI Foundry сочетает в себе наши технологии моделей генеративного ИИ, опыт обучения LLM и гигантскую фабрику ИИ. Мы создали это в Microsoft Azure, чтобы предприятия по всему миру могли подключить свою собственную модель к ведущим в мире облачным сервисам Microsoft». 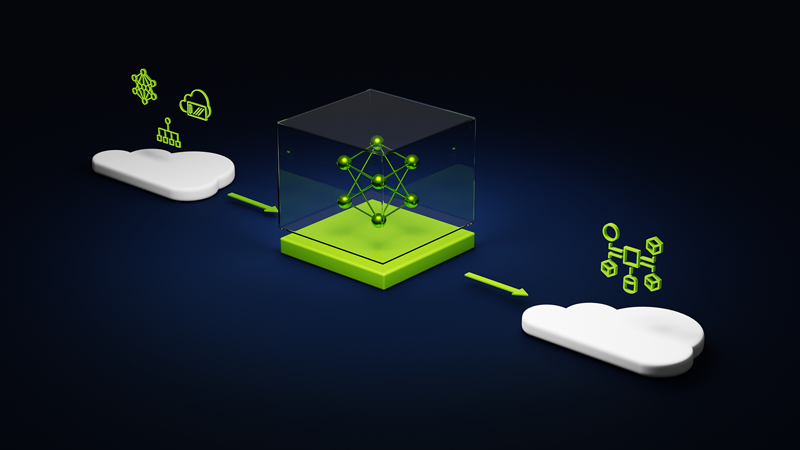
Источник изображения: NVIDIA Сервис NVIDIA AI Foundry можно использовать для настройки моделей для приложений на базе генеративного ИИ в различных отраслях, включая корпоративное ПО, телекоммуникации и медиа. При их развёртывании компании смогут использовать метод генерации с расширенным поиском (RAG), чтобы привязать свои модели к базе корпоративных данных для получения актуальных ответов. В сервисе NVIDIA Foundry клиенты смогут выбирать из нескольких моделей NVIDIA AI Foundation, включая новое семейство Nemotron-3 8B в составе каталога моделей Azure AI. Разработчики также могут получить доступ к моделям Nemotron-3 8B в каталоге NVIDIA NGC и к популярным моделям Llama 2, Mistral и Stable Diffusion XL. NVIDIA сообщила, что одними из первых новым сервисом для создания моделей воспользовались SAP, Amdocs и Getty Images. Наконец, в Azure стала доступна и платформа NVIDIA DGX Cloud AI, в рамках которой клиенты смогут арендовать кластеры, состоящие из тысяч ускорителей NVIDIA и воспользоваться ПО NVIDIA AI Enterprise, включая NeMo, для ускорения настройки LLM. Клиенты Azure смогут использовать существующие кредиты Microsoft Azure Consumption Commitment для ускорения разработки ИИ-моделей. Отметим, что первым сервис DGX Cloud получило облако Oracle, где Microsoft арендует ускорители той же NVIDIA для собственных нужд. По слухам, компания также использует ускорители CoreWeave и Lambda Labs, а также разрабатывает более экономичные ИИ-модели. По-видимому, продавать доступ к аппаратным и иным решениям NVIDIA для Microsoft выгоднее, чем использовать для своих нужд. Впрочем, если всё сложится удачно, то компания перейдёт на ИИ-ускорители Maia 100 собственной разработки.
13.11.2023 [13:56], Сергей Карасёв
ИИ-стартап Aleph Alpha привлёк более $500 млн, в том числе от HPE и SAPНемецкий стартап Aleph Alpha, специализирующийся на технологиях ИИ, сообщил о проведении крупного раунда финансирования Series B, в ходе которого на развитие получено более $500 млн. Средства предоставили, в частности, HPE и SAP. Фирма Aleph Alpha, сформированная в 2019 году, занимается разработкой больших языковых моделей (LLM). При этом стартап делает упор на концепцию «суверенитета данных». Свои LLM компания предлагает корпоративным заказчикам и государственным учреждениям. 
Источник изображения: pixabay.com Aleph Alpha создала семейство LLM под названием Luminous, которое включает три модификации: 13 млрд, 30 млрд и 70 млрд параметров. На веб-сайте компании указано, что также планируется разработка более совершенных языковых моделей с числом параметров до 300 млрд. Модели Aleph Alpha могут обрабатывать текст на английском, немецком, французском, итальянском и испанском языках, а также принимать изображения в качестве входных данных. Эти LLM, как утверждается, подходят для решения самых разных задач — от генерации текста до сортировки документов по темам. Доступ к моделям предоставляется через API, так что разработчики могут интегрировать их в свои продукты. Программу финансирования Series B возглавили Инновационный парк искусственного интеллекта (Ipai), фонд Bosch Ventures и компании Schwarz Group. Деньги выделили упомянутые НРЕ и SAP, а также Christ&Company Consulting и Burda Principal Investments. Стартап вложит полученные средства в дальнейшую разработку LLM и в коммерциализацию своих решений.
09.11.2023 [01:35], Руслан Авдеев
Microsoft из-за прожорливости Bing Chat пришлось договориться об аренде ИИ-ускорителей NVIDIA у OracleТочно неизвестно, велик ли спрос на ИИ-сервисы Microsoft или у компании просто недостаточно вычислительных ресурсов, но IT-гиганту пришлось договариваться с Oracle об использовании ИИ-ускорителей в ЦОД последней. Как сообщает The Register, речь идёт о применении оборудования Oracle для «разгрузки» некоторых языковых моделей Microsoft, применяемых в Bing. Во вторник компании анонсировали многолетнее соглашение. Как сообщают в Microsoft, одновременное использование компанией как Oracle Cloud, так и Microsoft Azure расширит возможности клиентов и ускорит работу с поисковыми сервисами. Сотрудничество связано с тем, что Microsoft надо всё больше вычислительных ресурсов для заявляемого «взрывного роста» её ИИ-сервисов, а у Oracle как раз имеются десятки тысяч ускорителей NVIDIA A100 и H100 для аренды. 
Источник изображения: cliff1126/pixabay.com Служба Oracle Interconnect обеспечивает взаимодействие с облаком Microsoft Azure, что позволяет работающим в Azure сервисам взаимодействовать с ресурсами Oracle Cloud Infrastructure (OCI). Раньше такое решение уже применялось, но для сторонних клиентов двух компаний. Теперь Microsoft применяет Interconnect наряду с Azure Kubernetes Service для организации работы ИИ-узлов в облаке Oracle на благо Bing Chat. Microsoft ещё в феврале интегрировала чат-бота Bing Chat в свой поисковый сервис и свой браузер. Не так давно добавилась и возможность, например, генерировать изображения прямо в процессе диалога. При этом использование больших языковых моделей требует огромного числа ускорителей для их тренировки, но для инференса необходимы ещё большие вычислительные мощности. 
Фото: Microsoft В Oracle утверждают, что облачные суперкластеры компании, которые, вероятно, будет использовать Microsoft, могут масштабироваться до 32 768 ИИ-ускорителей A100 или 16 384 ускорителей H100 с использованием RDMA-сети с ультранизкой задержкой. Дополнением является хранилище петабайтного класса. В самой Microsoft избегают говорить, сколько именно узлов Oracle нужно компании, причём, похоже, не намерены делать этого и в будущем. Конкуренты сотрудничают уже не в первый раз. В сентябре Oracle сообщала о намерении размещать системы с базами данных в ЦОД Azure. Более того, ещё в мае 2023 года Microsoft и Oracle изучали возможность аренды ИИ-серверов друг у друга на случай, если у них вдруг не будет хватать вычислительных мощностей для крупных облачных клиентов. Ранее ходили слухи, что похожие соглашения Microsoft подписала с CoreWeave и Lambda Labs, к которым NVIDIA более благосклонна в вопросах поставки ускорителей. Попутно Microsoft ищет более экономичные альтернативы языковым моделям OpenAI.
03.11.2023 [22:48], Владимир Мироненко
Llama 2 в хорошие руки: Dell и Meta✴ предложили готовый программно-аппаратный комплекс для локального развёртывания ИИDell и Meta✴ предложили совместную разработку для повышения эффективности работы компаний в области генеративного ИИ, основанную на использовании большой языковой модели Meta✴ Llama 2 и инфраструктуры Dell. Запуск таких приложений генеративного ИИ, как чат-боты, виртуальные помощники, в том числе для написания кода, предполагает обучение моделей на собственных данных компаний. Однако решения в публичных облаках хотя и удобны, часто имеют определённые ограничения, включая риски безопасности, связанные с суверенитетом данных, а также непредсказуемые затраты и проблемы с соблюдением регуляторных требований. 
Источник изображения: Dell Локальное развёртывания открытых больших языковых моделей (LLM) вроде Llama 2 обеспечивает клиентам предсказуемые затраты и полный контроль над своими данными, снижая риск для безопасности и утечки интеллектуальной собственности, а также обеспечивая соответствие нормативным требованиям, говорит Dell. Решения Dell Generative AI Solutions вместе с Dell Validated Design for Generative AI предлагают клиентам готовый, предварительно протестированный программно-аппаратный, специально созданный для работы с генеративным ИИ. 
Источник изображения: Dell Теперь же Dell в сотрудничестве с Meta✴ расширила свой портфель предложений для работы с генеративным ИИ — клиентам доступно упрощённое развёртывание и тюнинг ИИ-моделей Meta✴ Llama 2 от Meta✴ в локальной среде. Решение Dell Validated Design for Generative AI вместе с Llama 2 предоставляет компаниям готовую инфраструктуру, ПО и сервисы Dell для оптимизации развёртывания и управления локальными ИИ-проектами. Llama 2 протестирована и проверена Dell, в том числе при работе с (SFT), LoRA и p-tuning на моделях с 7, 13 и 70 млрд параметров Благодаря руководству по развёртыванию и настройке компании смогут быстро запустить свою ИИ-инфраструктуру и использовать Llama 2 с большей предсказуемостью. В частности, доступны анализ использования памяти, задержек и эффективности LLM. «Наша цель — стать предпочтительным поставщиком локальной инфраструктуры для клиентов, развёртывающих Llama 2, и предоставить нашим клиентам лучшие в своём классе генеративные решения ИИ», — сообщила компания. Аппаратная основа включает серверы PowerEdge XE9680, а также PowerEdge R760xa (с NVIDIA L40S).
23.10.2023 [16:14], Руслан Авдеев
SK Telecom и Deutsche Telekom разработают большие языковые модели специально для телеком-отраслиКомпании SK Telecom (SKT) и Deutsche Telekom объявили о подписании соглашения о намерениях совместной разработки больших языковых моделей (LLM), специально предназначенных для телекоммуникационного бизнеса. Как сообщает блог IEEE Communication Society, готовые решения позволят легко и быстро создавать LLM под свои нужды и другим телеком-компаниям. Первую версию LLM планируют представить в I квартале 2024 года. Это первый плод дискуссий, проходивших в июле 2023 года в рамках группы Global Telco AI Alliance, организованной SKT, Deutsche Telekom, E& и Singtel. SKT и Deutsche Telekom намерены взаимодействовать с компаниями, лидирующими в разработках ИИ-систем, включая Anthropic с её Claude 2 и Meta✴ с её Llama2 — новая базовая LLM будет поддерживать разные языки, включая английский, немецкий, корейский и др. 
Источник изображения: Peggy_Marco/pixabay.com Новая языковая модель будет лучше ориентироваться в телеком-специфике, чем LLM общего назначения, поэтому её можно будет использовать, например, в контакт-центрах для помощи живым операторам. В первую очередь это коснётся операторов в Европе, Азии и на Ближнем Востоке — они смогут создавать ИИ-ассистентов с учётом местной специфики. Кроме того, ИИ можно будет применять для мониторинга сетей и выполнения других задач с сопутствующим снижением издержек и ростом эффективности бизнеса в средне- и долгосрочной перспективе. В результате занятые в телеком-бизнесе компании смогут сберечь время и деньги, избежав разработки подобных платформ исключительно собственными силами. Сотрудничество южнокорейской и немецкой компаний будет способствовать расширению глобальной ИИ-экосистемы. Как подчеркнули в Deutsche Telecom, для того, чтобы по максимуму использовать ИИ в сфере поддержки клиентов, LLM будет тренироваться с использованием уникальных данных. В SKT рассчитывают, что сотрудничество двух компаний позволит им завоевать лидирующие позиции в сфере специализированных ИИ-решений, а объединение усилий, ИИ-технологий и инфраструктуры обеспечит новые возможности многочисленным компаниям в разных отраслях. Ранее SK Telecom вложила $100 млн в стартап Anthropic, чтобы получить кастомную LLM для своих нужд.
21.10.2023 [15:52], Сергей Карасёв
Китайский разработчик больших языковых моделей Zhipu получил на развитие более $340 млнИИ-стартап Zhipu из Китая, по сообщению ресурса SiliconAngle, осуществил крупную программу финансирования, в ходе которой на развитие привлечено ¥2,5 млрд, или приблизительно $342 млн. Эти средства будут направлены на ускорение разработки решений в области ИИ и машинного обучения. Финансовую поддержку Zhipu оказали две крупнейшие технологические компании Китая — Alibaba Group Holding Ltd. и Tencent Holdings Ltd. К ним присоединились Xiaomi, оператор платформы доставки еды Meituan и некоторые другие инвесторы. Zhipu была основана в 2019 году специалистами Университета Цинхуа. Компанию возглавляет Тан Цзе (Tang Jie), профессор кафедры компьютерных наук названного вуза. Стартап специализируется на разработке больших языковых моделей (LLM), аналогичных GPT-4. В частности, Zhipu создала две LLM с открытым исходным кодом, GLM-130B и ChatGLM-6B, которые содержат 130 млрд и 6 млрд параметров соответственно. Причём вторая, как утверждается, может работать на GPU потребительского уровня. Компания также предлагает собственного чат-бота под названием Qingyan на базе ИИ. 
Источник изображения: pixabay.com Буквально на днях сообщалось, что Alibaba, Tencent и Xiaomi приняли участие в раунде финансирования другого китайского ИИ-стартапа — фирмы Baichuan, которая также фокусируется на разработке LLM. Эта компания получила на развитие $300 млн в дополнение к $50 млн, привлечённым ранее. Стартап уже занимается коммерческим внедрением модели Baichuan2-53B, которая содержит 53 млрд параметров. |
|

