Материалы по тегу: gb200
|
11.09.2024 [18:55], Игорь Осколков
Oracle анонсировала зеттафлопсный облачный ИИ-суперкомпьютер из 131 тыс. NVIDIA B200Oracle и NVIDIA анонсировали самый крупный на сегодняшний день облачный ИИ-кластер, состоящий из 131 072 ускорителей NVIDIA B200 (Blackwell). По словам компаний, это первая в мире система производительностью 2,4 Зфлопс (FP8). Кластер заработает в I половине 2025 года, но заказы на bare-metal инстансы и OCI Superclaster компания готова принять уже сейчас. Заказчики также смогут выбрать тип подключения: RoCEv2 (ConnectX-7/8) или InfiniBand (Quantum-2). По словам компании, новый ИИ-кластер вшестеро крупнее тех, что могут предложить AWS, Microsoft Azure и Google Cloud. Кроме того, компания предлагает и другие кластеры с ускорителями NVIDIA: 32 768 × A100, 16 384 × H100, 65 536 × H200 и 3840 × L40S. А в следующем году обещаны кластеры на основе GB200 NVL72, объединяющие более 100 тыс. ускорителей GB200. В скором времени также появятся и куда более скромные ВМ GPU.A100.1 и GPU.H100.1 с одним ускорителем A100/H100 (80 Гбайт). Прямо сейчас для заказы доступны инстансы GPU.H200.8, включающие восемь ускорителей H200 (141 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 200G-подключение. Семейство инстансов на базе NVIDIA Blackwell пока включает лишь два варианта. GPU.B200.8 предлагает восемь ускорителей B200 (192 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 400G-подключение. Наконец, GPU.GB200 фактически представляет собой суперускоритель GB200 NVL72 и включает 72 ускорителя B200, 36 Arm-процессоров Grace и локальное NVMe-хранилище ёмкостью 533 Тбайт. Агрегированная скорость сетевого подключения составляет 7,2 Тбит/с. 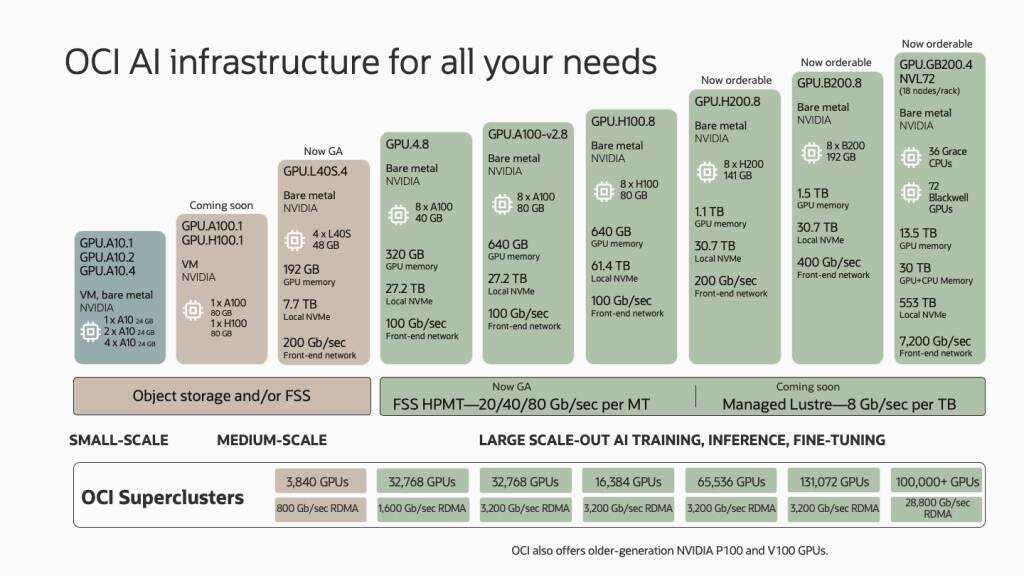
Источник изображения: Oracle Для всех новых инстансов Oracle подготовит управляемое Lustre-хранилище с производительностью до 8 Гбит/с на каждый Тбайт. Кроме того, компания предложит расширенные средства мониторинга и управления, помощь в настройке инфраструктуры для достижения желаемого уровня реальной производительности, а также набор оптимизированного ПО для работы с ИИ, в том числе для Arm.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
22.07.2024 [15:57], Руслан Авдеев
Поставки суперускорителей с чипами NVIDIA GB200 могут задержаться из-за протечек СЖОNVIDIA уже готовилась начать продажи систем на базе новейших ИИ-суперускорителей GB200, однако столкнулась с непредвиденной проблемой — TweakTown сообщает, что в системах жидкостного охлаждения этих серверов начали появляться протечки. Судя по всему, серверы на основе GB200 использовали дефектные компоненты систем СЖО охлаждения, поставляемые сторонними производителями: разветвители, быстросъёмные соединители и шланги. Некорректная работа любого из этих компонентов может привести к утечке охлаждающей жидкости. В случае с моделью GB200 NVL72 стоимостью в $3 млн это может перерасти в большую проблему. К счастью, нарушения в работе новых систем NVIDIA GB200 NVL36 и NVL72 обнаружили до начала массового производства в преддверии запуска поставок ключевым покупателям ИИ-решений. Предполагается, что на сроках поставок проблема не скажется, поскольку её успеют устранить. Впрочем, по данным источников, теперь крупные провайдеры облачных сервисов «нервничают». 
Источник изображения: NVIDIA NVIDIA предлагают свою продукцию всё больше тайваньских производителей, способных заменить бракованные компоненты для серверных систем с GB200. Однако сертификация компонентов — процесс довольно сложный, поскольку многие тайваньские компании не специализировались на их выпуске ещё в недавнем прошлом. Тем не менее, когда NVIDIA объявила, что ускорители следующего поколения получат жидкостное охлаждение, многие производители решили попробовать себя в этой сфере. Тайваньские Shuanghong и Qihong уже имеют хороший опыт в выпуске водоблоков, а теперь расширили спектр разрабатываемых товаров, предлагая разветвители, быстросъемные соединители и шланги. Именно эти компании по некоторым данным сейчас предоставляют необходимые комплектующие для замены бракованных в новых суперускорителях NVIDIA GB200 NVL36 и NVL72. Лидером на рынке серверных СЖО остаётся CoolIT, но её услугами NVIDIA, видимо, решила не пользоваться.
17.07.2024 [23:33], Игорь Осколков
Суперускоритель по суперцене — NVIDIA GB200 NVL72, вероятно, будет стоить $3 млнКомпания NVIDIA значительно увеличила заказ на ускорители Blackwell у TSMC, сообщает TrendForce со ссылкой на United Daily News (UDN). По данным источника, NVIDIA намерена получить уже не 40 тыс., а 60 тыс. суперускорителей нового поколения, причём 50 тыс. из них придётся на стоечные системы GB200 NVL36. При этом Blackwell всё равно будут в дефиците, как и обещал ещё зимой глава NVIDIA Дженсен Хуанг (Jensen Huang). B200 включает два тайла, объединённых 2,5D-упаковкой CoWoS-L и соединённых интерконнектом NV-HBI. Чип имеет 208 млрд транзисторов, изготовленных по кастомному техпроцессу TSMC 4NP. GB200 объединяет два ускорителя B200 и один 72-ядерный Arm-процессор Grace. А суперускоритель GB200 NVL72, в свою очередь, объединяет в рамках одной стойки сразу 18 1U-узлов с парой GB200 в каждом (плата Bianca, 72 × B200 и 36 × Grace), провязанных шиной NVLink 5. Вся эта система потребляет порядка 120 кВт, оснащена СЖО и единой DC-шиной питания. 
NVIDIA GB200 Однако у GB200 NVL72 довольно специфические требования к окружению, поэтому NVIDIA предлагает суперускоритель попроще — GB200 NVL36, который как раз и должен стать наиболее массовым в данной серии. Эта платформа точно так же занимает целую стойку, но использует 2U-узлы с теми же платами Bianca (суммарно 36 × B200 и 18 × Grace), потребляя всего 66 кВт. При этом всё равно подразумевается использование двух стоек GB200 NVL36, объединённых интерконнектом, так что GB200 NVL72 всё равно получается более энергоэффективным решением. 
Источник изображения: NVIDIA Как отмечает SemiAnalysis, GB200 NVL36 также будет доступен в варианте с платами Ariel, имеющими по одному чипу B200 и Grace. Наконец, во II квартале 2025 года появятся системы B200 NVL72 и B200 NVL36 с x86-процессорами (Miranda). Кроме того, NVIDIA представила и отдельные MGX-узлы GB200 NVL2 с парой GB200. В общем, ускорителей B200 компании понадобится много, чтобы наверняка удержать лидерство на рынке. По словам UDN, GB200 NVL36 будет стоить порядка $1,8 млн, а GB200 NVL72 обойдётся уже в $3 млн. Одиночный GB200 будет стоить $60–$70 тыс., а самый простой ускоритель B100 оценён в $30–$35 тыс. Нужно подчеркнуть, что это оценки сторонних аналитиков. Сама компания официально не раскрывает стоимость своих продуктов. Это устоявшаяся практика на данном рынке, против которой пошла только Intel, публично назвавшая стоимость ИИ-ускорителей Gaudi. Впрочем, ранее глава NVIDIA намекнул, что B200 будет стоить приблизительно $30–$40 тыс.
23.06.2024 [12:35], Сергей Карасёв
Между Microsoft и NVIDIA возникли разногласия по поводу использования ускорителей B200У компаний Microsoft и NVIDIA, по сообщению The Information, возникли разногласия по поводу использования новейших ускорителей B200 на архитектуре Blackwell. NVIDIA настаивает на том, чтобы клиенты приобретали эти изделия в составе полноценных серверных стоек, тогда как Microsoft с этим не согласна. Отмечается, что NVIDIA, удерживающая приблизительно 98 % рынка ускорителей для ЦОД, стремится контролировать использование своих продуктов. В частности, компания накладывает ограничения в отношении дизайна ускорителей, которые партнёры создают на чипах NVIDIA. Во время презентации Blackwell глава NVIDIA Дженсен Хуанг (Jensen Huang) неоднократно указывал на то, что теперь минимальной единицей для развёртывания должен стать суперускоритель GB200 NVL72. То есть NVIDIA призывает клиентов приобретать вместо отдельных ускорителей целые стойки и даже кластеры SuperPOD. По заявлениям компании, это позволит повысить ИИ-производительность благодаря оптимизации всех компонентов и их максимальной совместимости друг с другом. Кроме того, такая бизнес-модель позволит NVIDIA получить дополнительную выручку от распространения серверного оборудования и ещё больше укрепить позиции на стремительно развивающемся рынке ИИ. 
Источник изображения: NVIDIA Однако у Microsoft, которая оперирует огромным количеством разнообразных ускорителей и других систем в составе своей инфраструктуры, возникли возражения в отношении подхода NVIDIA. Сообщается, что вице-президент NVIDIA Эндрю Белл (Andrew Bell) попросил Microsoft приобрести специализированные серверные стойки для ускорителей Blackwell, но редмондский гигант ответил отказом. По заявлениям Microsoft, решения NVIDIA затруднят корпорации внедрение альтернативных ускорителей, таких как AMD Instinct MI300X. 
Ещё один вариант OCP-стойки с СЖО (Источник изображения: Microsoft) Дело в том, что форм-факторы стоек NVIDIA и стоек Microsoft различаются на несколько дюймов. Из-за этого могут возникнуть сложности с изменением конфигурации и модернизацией, предусматривающей использование конкурирующих компонентов. Так, Microsoft использует единую базовую платформу и для ускорителей NVIDIA, и для ускорителей AMD. Microsoft эксплуатирует вариант стоек OCP и старается максимально унифицировать инфраструктуру своих многочисленных дата-центров. NVIDIA, в конце концов, согласилась с доводами Microsoft и пошла на уступки, но это, похоже, не последнее подобное разногласие между компаниями.
11.06.2024 [17:09], Руслан Авдеев
Foxconn построит на Тайване передовой вычислительный центр на базе суперускорителей NVIDIA BlackwellПроизводитель электроники Foxconn намерен построить на острове передовой вычислительный центр в Гаосюне (Тайань). Datacenter Dynamics информирует, что центр, который будет готов в 2026 году, получит 64 суперускорителя NVIDIA Blackwell GB200 NVL72. Foxconn и NVIDIA будут сотрудничать и над созданием «цифровых двойников» для производственных компаний, электромобилей и систем умного города. Проекты будут реализованы на платформе NVIDIA Omniverse. В NVIDIA заявили, что сейчас происходит расцвет новой эры вычислений, ставшей драйвером спроса на дата-центры для генеративного ИИ. Также в компании подчеркнули, что Foxconn является ведущим поставщиком вычислительных решений NVIDIA и одним из ключевых новаторов в деле внедрения генеративного ИИ в промышленности и робототехнике. Используя платформы NVIDIA Omniverse и Isaac, компания задействует передовые ИИ-технологии и систему цифровых двойников для создания передового вычислительного центра в Гаосюне. 
Источник изображения: Foxconn Основанная в 1974 году компания Foxconn в последнее время стремится расширить долю рынка в полупроводниковой индустрии на фоне медленного роста продаж смартфонов. Дочерняя компания Ingrays выпускает серверы, системы хранения данных и HPC-компоненты, включая HPC-платформы на основе чипов NVIDIA. Ранее появилась информация о том, что компания намерена превратить опосредованно принадлежащий ей завод Sharp по выпуску LCD-панелей в дата-центр, но тот расположен в Япони и к текущему проекту не имеет прямого отношения.
09.06.2024 [12:36], Сергей Карасёв
ASUS представила ИИ-систему ESC AI POD на базе NVIDIA GB200 NVL72Компания ASUS анонсировала мощный вычислительный комплекс ESC AI POD, предназначенный для решения ресурсоёмких задач в области ИИ и НРС. В основу новинки положена платформа NVIDIA GB200 NVL72 на архитектуре Blackwell. Решение ESC NM2N721-E1 использует 72 ускорителя NVIDIA Blackwell и 36 процессоров NVIDIA Grace, объединённых интерконнекта NVIDIA NVLink 5. 
Источник изображений: ASUS Утверждается, что ESC AI POD поддерживает работу с большими языковыми моделями (LLM), насчитывающими до триллиона параметров. В состав системы входят вычислительные узлы, коммутаторы, а также полки питания 1U мощностью 33 кВт. Возможно развёртывание воздушно-жидкостного или полностью жидкостного охлаждения. Кроме того, ASUS продемонстрировала в рамках Computex 2024 другие новинки. В их числе — системы, выполненные на модульной архитектуре NVIDIA MGX. Это, в частности, сервер ESC NM1-E1 типоразмера 2U, комплектующийся суперчипом NVIDIA Grace Hoppe GH200. Он использует технологию NVIDIA NVLink-C2C и поддерживает воздушное охлаждение. Кроме того, показаны серверы ESC NM2-E1 и ESR1-511N-M1 (стандарта 1U).
Среди других решений упоминаются серверы ESC N8 на платформе Intel Xeon Emerald Rapids и ESC N8A на базе AMD EPYC 9004 (Genoa). Эти системы несут на борту ускорители NVIDIA Blackwell. Кроме того, ASUS готовит новые ИИ-решения, оснащённые сетевым ускорителем NVIDIA BlueField-3 SuperNIC.
07.06.2024 [10:33], Сергей Карасёв
Supermicro представила серверы семейства X14 на платформе Intel Xeon 6, в том числе с СЖОКомпания Supermicro анонсировала серверы нового поколения X14 на аппаратной платформе Intel Xeon 6. Дебютировало большое количество стоечных систем разного класса для облачных приложений, периферийных вычислений, телекоммуникационных сервисов и пр.  Как и ожидалось, в серию X14 вошли модели SuperBlade для НРС-задач и аналитики данных, высокопроизводительные серверы Hyper для масштабируемых облачных рабочих нагрузок, решения CloudDC для дата-центров, системы Hyper-E для периферийных задач, а также устройства WIO, BigTwin, GrandTwin и Edge/Telco. Кроме того, дебютировали серверы хранения Petascale Storage, которые, по заявлениям Supermicro, обеспечивают лучшие в отрасли показатели плотности и производительности. Эти решения в формате 1U или 2U поддерживают работу с накопителями EDSFF E1.S и E3.S. Новые серверы комплектуются процессорами Intel Xeon 6, ранее известными под кодовым именем Sierra Forest. Чипы могут содержать до 144 энергоэффективных E-ядер. В дальнейшем Supermicro выпустит серверы с процессорами Xeon 6 с производительными P-ядрами (ранее — Granite Rapids). Готовятся GPU-системы для ИИ-нагрузок, обучения больших языковых моделей (LLM) и ресурсоёмких приложений НРС. Кроме того, будут представлены многоузловые платформы. Для некоторых новинок предусмотрено использование СЖО. 
На выставке Computex 2024 компания Supermicro также демонстрирует ИИ-системы SuperCluster на базе NVIDIA Blackwell и NVIDIA HGX H100/H200. Эти мощные комплексы могут оснащаться воздушным или жидкостным охлаждением.
04.06.2024 [17:52], Руслан Авдеев
Sharp, KDDI и Supermicro построят крупнейший в Азии дата-центр для ИИ на базе суперускорителей NVIDIA GB200 NVL72Японский производитель электроники Sharp совместно с телеком-компанией KDDI готовятся построить «крупнейший в Азии» дата-центр для ИИ-вычислений на базе завода Sakai Plant по выпуску LCD-дисплеев в Осаке. По данным Datacenter Dynamics, партнёры привлекли к проекту и другие компании. В частности, подписано соглашение с Supermicro и Datasection. Вместе они переделают завод Sakai в современный дата-центр для ИИ-задач на базе аппаратных решений NVIDIA. Ранее сообщалось, что «материнская» компания данного предприятия — тайваньская Foxconn — планирует закрыть завод осенью этого года и превратить его в ЦОД из-за растущих убытков на рынке LCD. В заявлении KDDI указывается, что дата-центр будет использовать новейшие суперускорители NVIDIA GB200 NVL72, на которых возложат задачи обучения и запуска LLM. Более подробных официальных спецификаций ЦОД пока нет, но издание Nikkei Asian Rewiew сообщает, что ЦОД получит минимум 1 тыс. узлов. Говорится, что инфраструктура бывшего завода Sharp Sakai Plant отлично подойдёт для дата-центра, поскольку имеет достаточно подходящих площадей и достаточно энергии для питания мощных серверов. 
Источник изображения: NVIDIA Datasection будет поддерживать функционирование ЦОД, KDDI возьмёт на себя строительство, в том числе сетевой инфраструктуры — компания является «родительскоим» бизнесом для Telehouse, уже управляющей ЦОД по всему миру, в том числе в Азии. Supermicro обеспечит передовые комплексные системы жидкостного охлаждения (СЖО) с системами мониторинга их работы. По словам Supermicro, сотрудничество участвующих в проекте ЦОД компаний стали хорошим примером приверженности индустрии к «зелёным» вычислениям и готовности к глобальному внедрению ИИ-систем.
02.06.2024 [16:20], Сергей Карасёв
NVIDIA представила ускорители GB200 NVL2, платформы HGX B100/B200 и анонсировала экосистему следуюшего поколения Vera RubinNVIDIA сообщила о широкой отраслевой поддержке своей архитектуры нового поколения Blackwell. Эти ускорители, а также чипы Grace легли в основу многочисленных систем для ИИ-фабрик и дата-центров, которые, как ожидается, будут способствовать «следующей промышленной революции». 
Источник изображений: NVIDIA Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) объявил о том, что серверы на базе Blackwell выпустят ASRock Rack, ASUS, Gigabyte, Ingrasys, Inventec, Pegatron, QCT, Supermicro, Wistron и Wiwynn. Речь идёт об устройствах разного уровня, рассчитанных на облачные платформы, периферийные вычисления и ЦОД клиентов. «Началась очередная промышленная революция. Компании и целые страны сотрудничают с NVIDIA, чтобы трансформировать традиционные дата-центры общей стоимостью в триллионы долларов в платформы нового типа — фабрики ИИ», — говорит Хуанг. 
NVIDIA HGX B200 
NVIDIA HGX B100 Для решения ИИ-задач и поддержания других ресурсоёмких приложений будут выпущены серверы с CPU на архитектурах х86 и Arm (изделия Grace) с воздушным и жидкостным охлаждением. Заказчикам будут доступны модели с одним и несколькими ускорителями. В частности, сама NVIDIA предлагает DGX-системы Blackwell, а для сторонних производителей доступны готовые платформы HGX B100 и HGX B200.   Кроме того, компания представила ускоритель GB200 NVL2, т.е. сборку из двух GB200, объединённых NVLink 5. NVIDIA также сообщила о том, что модульная архитектура NVIDIA MGX отныне поддерживает Blackwell, включая и GB200 NVL2. В целом, NVIDIA MGX предлагает свыше 100 различных конфигураций. На сегодняшний день на базе MGX выпущены или находятся в разработке более 90 серверов от более чем 25 партнёров NVIDIA по сравнению с 14 системами от шести партнёров в 2023 году. В составе MGX, в частности, впервые будут использоваться изделия AMD EPYC Turin и чипы Intel Xeon 6 (ранее — Granite Rapids).  Отмечается, что глобальная партнёрская экосистема NVIDIA включает TSMC, а также поставщиков различных компонентов, включая серверные стойки, системы электропитания, решения для охлаждения и пр. В число поставщиков такой продукции входят Amphenol, Asia Vital Components (AVC), Cooler Master, Colder Products Company (CPC), Danfoss, Delta Electronics и Liteon. Серверы нового поколения готовят Dell Technologies, Hewlett Packard Enterprise (HPE) и Lenovo.  В скором времени NVIDIA представит улучшенные ускорители Blackwell Ultra, которые получат более современную HBM3e-память. А уже в следующем году компания покажет решения на архитектуре следующего поколения: ускорители Rubin, процессоры Vera, NVLink 6 с удвоенной пропускной способностью (3,6 Тбайт/с), коммутаторы X1600 и DPU SuperNIC CX9 для сетей 1,6 Тбит/с. |
|


