Материалы по тегу: tsmc
|
11.11.2024 [11:29], Сергей Карасёв
США запретили TSMC выпускать передовые чипы для китайских ИИ-компанийTSMC, по сообщению The Register, полностью прекратит выпуск передовых изделий для китайских заказчиков, которые занимаются разработкой аппаратных ИИ-решений, включая ускорители на базе GPU. Данная мера, как утверждается, продиктована необходимостью соблюдения экспортных требований США. Власти США последовательно вводят различные санкции, призванные ограничить возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. А нидерландской компании ASML запрещено поставлять в Китай оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм продукцию. Теперь новые ограничительные меры в отношении клиентов из КНР вводит TSMC. Этот контрактный производитель объявил о том, что с 11 ноября 2024 года прекращает отгружать чипы, произведённые по 7-нм и более совершенным технологиям, китайским заказчикам, которые занимаются разработкой ИИ-устройств и GPU. Напомним, что в октябре TSMC уведомила американские власти о том, что некий китайский клиент, по всей видимости, пытается обойти экспортный контроль в отношении Huawei, размещая заказы на изделия, схожие с ИИ-ускорителем Ascend 910B. Это продукт был разработан Huawei в качестве альтернативы NVIDIA A100. Решение Ascend 910B представляет собой следующее поколение 7-нм чипа Ascend 910. По имеющейся информации, TSMC, следуя экспортным ограничения США, прекратила все поставки изделий этому неназванному клиенту. 
Источник изображения: TSMC Решение TSMC ограничит возможности китайских компаний по использованию технологий с нормами 7-нм и менее при создании ИИ-устройств. Вместе с тем, подчёркивается, что правила не распространяются на китайских клиентов, которые заказывают у TSMC 7-нм чипы для других приложений, таких как мобильные устройства и системы связи. Как отмечает TrendForce, решение TSMC «отражает осторожную позицию гиганта контрактного производства в глобальной цепочке поставок полупроводников на фоне разгорающейся войны в сфере микрочипов между двумя мировыми сверхдержавами».
30.10.2024 [11:49], Сергей Карасёв
OpenAI разрабатывает собственные ИИ-чипы совместно с Broadcom и TSMC, а пока задействует AMD Instinct MI300XКомпания OpenAI, по информации Reuters, разрабатывает собственные чипы для обработки ИИ-задач. Партнёром в рамках данного проекта выступает Broadcom, а организовать производство изделий планируется на мощностях TSMC ориентировочно в 2026 году. Слухи о том, что OpenAI обсуждает с Broadcom возможность создания собственного ИИ-ускорителя, появились минувшим летом. Тогда говорилось, что эта инициатива является частью более масштабной программы OpenAI по увеличению вычислительных мощностей компании для разработки ИИ, преодолению дефицита ускорителей и снижению зависимости от NVIDIA. Как теперь стало известно, OpenAI уже несколько месяцев работает с Broadcom над своим первым чипом ИИ, ориентированным на задачи инференса. Соответствующая команда разработчиков насчитывает около 20 человек, включая специалистов, которые ранее принимали участие в проектировании ускорителей TPU в Google, в том числе Томаса Норри (Thomas Norrie) и Ричарда Хо (Richard Ho). Подробности о проекте не раскрываются. Reuters, ссылаясь на собственные источники, также сообщает, что OpenAI в дополнение к ИИ-ускорителям NVIDIA намерена взять на вооружение решения AMD, что позволит диверсифицировать поставки оборудования. Речь идёт о применении изделий Instinct MI300X, ресурсы которых будут использоваться через облачную платформу Microsoft Azure. 
Источник изображения: Unsplash Это позволит увеличить вычислительные мощности: компания OpenAI только в 2024 году намерена потратить на обучение ИИ-моделей и задачи инференса около $7 млрд. Вместе с тем, как отмечается, OpenAI пока отказалась от амбициозных планов по созданию собственного производства ИИ-чипов. Связано это с большими финансовыми и временными затратами, необходимыми для строительства предприятий.
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
11.03.2024 [13:39], Сергей Карасёв
Marvell представила 2-нм платформу для создания кастомизированных ЦОД-решенийКомпания Marvell Technology объявила о расширении сотрудничества с TSMC с целью создания первой в отрасли технологической платформы, ориентированной на производство кастомизированных изделий для дата-центров по нормам 2 нм. Речь, в частности, идёт об оптимизированных для облака ускорителях, коммутаторах Ethernet и цифровых сигнальных процессорах. Отмечается, что разработка специализированных решений для ЦОД представляет собой трудоёмкую задачу. Дополнительные сложности создаёт необходимость адаптации под «тонкий» техпроцесс — в данном случае 2-нм методику TSMC. Новая платформа как раз и призвана решить проблемы. 
Источник изображения: Marvell В основу платформы положен обширный пакет интеллектуальной собственности Marvell, охватывающий полный спектр инфраструктурных компонентов. Это высокопроизводительные решения SerDes со скоростью свыше 200 Гбит/с, процессорные подсистемы, механизмы шифрования, межкристальные структуры, элементы интерконнекта, а также различные интерфейсы физического уровня с высокой пропускной способностью для вычислительных модулей, памяти, сетевых узлов и подсистем хранения данных. Перечисленные компоненты, по сути, становятся строительными блоками для кластеров ИИ, облачных дата-центров и других инфраструктур, которые применяются для рабочих нагрузок ИИ и задач НРС. Благодаря использованию новой платформы Marvell разработчики смогут ускорить вывод на рынок передовых изделий и многочиповых решений, устраняющих существующие узкие места в ЦОД и поддерживающих самые сложные приложения.
18.10.2023 [20:16], Владимир Мироненко
Socionext разработает к 2025 году 2-нм чипы для ЦОД, 5G и периферииКомпания Socionext из Иокогамы (Япония) объявила о планах по выпуску в 2025 году усовершенствованных 2-нм чипов, предназначенных для использования в ЦОД, беспроводной 5G-инфраструктуре и сетевой периферии. После этого её акции выросли в цене на 16 %, что является самым большим ростом в течении дня за всю историю компании, сообщил Bloomberg. Socionext также заявила, что в разработке и производстве чипов сотрудничает с ведущими производителями, такими как Arm и TSMC. Как ожидается, инженерные образцы 32-ядерного чипа Socionext, изготовленном с использованием технологии нового поколения TSMC, будут продемонстрированы в первой половине 2025 года. 
Источник изображения: Socionext Компания Socionext, созданная в 2015 году в результате объединения подразделений Fujitsu Semiconductor и Panasonic, разрабатывает кастомизированные системы на кристаллах для заказчиков из потребительской, автомобильной и промышленной сфер. Корпоративные клиенты всё чаще используют подобные чипы для конкретных приложений, и на этом рынке Socionext конкурирует с тайваньскими компаниями Faraday Technology Corp., Alchip Technologies Ltd. и Global Unichip Corp. Год назад Socionext с успехом провела первичное публичное размещение акций (IPO), в ходе которого стоимость её акций выросла на 15 % на фоне высокого спроса.
13.07.2023 [18:02], Алексей Степин
Alphawave Semi получила первые контроллеры HBM3 и UCIe в 3-нм «кремнии»Компания Alphawave Semi анонсировала успешное воплощение в «кремнии» своих PHY-контроллеров HBM3 и UCIe. Что немаловажно, новые IP-блоки производятся с использованием 3-нм техпроцесса TSMC, что делает их весьма экономичными решениями и открывает путь к ещё более быстрым чиплетным платформам для рынка ЦОД и гиперскейлеров. Компания, по её собственным словам, стала первым в мире разработчиком, представившим PHY для UCIe, который работает на скорости 24 Гбит/с на линию и обеспечивает совокупную пропускную способность 7,9 Тбит/с на миллиметр. При этом благодаря применению 3-нм техпроцесса TSMC он же обеспечивает и беспрецедентную экономичность, расходуя всего 0,3 пДж/бит. 
Изображение: Alphawave Semi Новый IP совместим с другими разработками Alphawave Semi, в частности, может работать вместе с блоками PCIe и CXL. Также он поддерживает продвинутые технологии упаковки, такие, как TSMC Chip-on-Wafer-on-Substrate (CoWoS) и Integrated Fan-Out (InFO), в том числе использующие органический субстрат, что удешевляет интеграцию. Соответствующими скоростными характеристиками может похвастаться и PHY-контроллер HBM3. Он поддерживает 16 каналов, работающих на скорости 8,6 Гбит/с, при этом очень компактен и экономичен и полностью совместим со стандартами JEDEC. Благодаря возможностям тонкой подстройки контроллер можно идеально подогнать к потребностям конкретных решений, включая ИИ и HPC. Согласно заявлению Alphawave Semi, два новых IP-блока станут ключевыми в чиплетном IP-портфолио компании. Благодаря им крупные гиперскейлеры и владельцы ЦОД-инфраструктуры смогут гибко проектировать и реализовывать кастомные SoC, отвечающие всем современным требованиям.
22.06.2023 [14:41], Владимир Мироненко
TrendForce: рост популярности ИИ подстегнёт спрос на память HBM и продвинутые методы упаковки чиповTrendForce отметила в своём новом исследовании, что в связи с резким ростом популярности приложений генеративного ИИ ведущие провайдеры облачных решений, включая Microsoft, Google, AWS, а также китайские технологические гиганты, такие как Baidu и ByteDance, значительно увеличили приобретение ИИ-серверов, необходимых для обучения и оптимизации ИИ-моделей. Ажиотаж вокруг генеративного ИИ стал стимулом для разработки более мощных ИИ-серверов и роста этого сегмента рынка. Как полагают аналитики TrendForce, производители будут расширять использование в ИИ-системах передовых технологий, применяя мощные ускорители вычислений и высокопроизводительную память HBM в сочетании с современными методами упаковки чипов. Согласно прогнозу TrendForce, в течение 2023–2024 гг. вырастет спрос на HBM, а также на 30–40 % увеличатся мощности для выпуска чипов с использованием передовых методов упаковки. 
Источник изображения: NVIDIA TrendForce отметила, что для повышения вычислительной эффективности ИИ-серверов и увеличения пропускной способности памяти ведущие производители ИИ-микросхем, включая NVIDIA, AMD и Intel, наращивают использование HBM. В настоящее время у чипов NVIDIA A100/H100 имеется 80 Гбайт памяти HBM2e/HBM3. В суперчипе GH200 Grace Hopper используется ускоритель NVIDIA H100 с 96 Гбайт памяти HBM3. В чипах серии AMD Instinct MI300 тоже используется память HBM3: у версии MI300A её ёмкость составляет 128 Гбайт, а у более продвинутой версии MI300X — 192 Гбайт. Также ожидается, что Google в рамках расширения ИИ-инфраструктуры начнёт в конце 2023 года в партнёрстве с Broadcom производство обновлённых тензорных чипов TPU, тоже с использованием памяти HBM. 
Источник изображения: AMD Согласно прогнозу TrendForce, в 2023 году будет выпущено ИИ-ускорителей с общим объёмом памяти HBM в пределах 290 млн Гбайт, что означает рост год к году на 60 %. В 2024 рост объёмов выпуска памяти HBM составит 30 % или более. Также будет расти спрос на передовые технологии упаковки чипов для сферы ИИ и высокопроизводительных вычислений (HPC). При этом преобладающим методом для ИИ-чипов будет Chip on Wafer on Substrate (CoWoS) от TSMC, позволяющий разместить на одной подложке до 12 стеков памяти HBM. По оценкам TrendForce, с начала 2023 года спрос на CoWoS вырос почти на 50 % на фоне роста популярности ускорителей NVIDIA A100 и H100. Ожидается, что к концу года ежемесячный выпуск TSMC чипов с применением CoWoS вырастет до 12 тыс. Во второй половине 2023 года возможности заказа выпуска чипов с применением CoWoS будут ограничены в связи с растущим спросом на ИИ-чипы со стороны AMD, Google и других компаний.  Высокий спрос на использование CoWoS сохранится до 2024 года с прогнозируемым ростом производственных мощностей по упаковке этим методом на 30–40 % с учётом готовности соответствующего оборудования. Аналитики TrendForce не исключают возможности использования NVIDIA альтернативных технологий упаковки для производства ускорителей в случае сохранения высокого спроса на системы ИИ. Речь идёт о разработках компаний Samsung и Amkor.
22.03.2023 [00:22], Сергей Карасёв
Решения NVIDIA в области вычислительной литографии заложат основу для выпуска чипов нового поколенияNVIDIA в рамках GTC 2023 объявила о новом решении, которое привносит возможности ускорения работы в сферу вычислительной литографии. Это позволит крупным игрокам полупроводниковой отрасли, таким как ASML, TSMC и Synopsys, ускорить разработку и производство микросхем нового поколения по мере приближения характеристик чипов к физическим ограничениям. Речь идёт о библиотеке NVIDIA cuLitho для вычислительной литографии. Говорится, что её интеграцией уже занимаются контрактный производитель TSMC, а также фирма Synopsys, работающая в области САПР для проектирования электроники. Производитель оборудования ASML также сотрудничает с NVIDIA в области GPU и cuLitho. Эти компании намерены встроить cuLitho в своё ПО, производственные процессы и системы на базе чипов с архитектурой NVIDIA Hopper. Говорится, что предприятия, использующие cuLitho, смогут ежедневно производить в 3–5 раз больше фотошаблонов при в 9 раз меньших затратах энергии по сравнению с традиционными методами. 
Источник изображения: NVIDIA Предполагается, что решение NVIDIA позволит проектировать микросхемы по более «тонкому» техпроцессу, нежели это возможно сейчас. Кроме того, сократится время выхода продуктов на рынок и повысится энергоэффективность крупных дата-центров, отвечающих за управление производственными процессами. В частности, с применением cuLitho может быть заложена основа для выпуска изделий с нормами 2 нм и менее. 
Источник изображения: NVIDIA Утверждается, что, работая на базе GPU разработки NVIDIA, платформа cuLitho обеспечивает скачок производительности до 40 раз по сравнению с обычной литографией. Это даёт возможность 500 системам NVIDIA DGX H100 заменить 40 000 CPU благодаря параллельной обработке различных элементов вычислительной литографии. Кроме того, значительно снижается энергопотребление ЦОД и сокращается негативное воздействие на окружающую среду.
15.04.2021 [01:31], Владимир Мироненко
TSMC остановит выпуск Arm-процессоров Phytium — судьба китайского экзафлопсного суперкомпьютера Tianhe-3 под вопросомТайваньская компания Taiwan Semiconductor Manufacturing Company (TSMC) приостановила поставку чипов по новым заказам китайской компании Phytium, которая на прошлой неделе была добавлена властями США в «чёрный» список Министерства торговли. Внесение компаний в этот перечень означает запрет для американских компаний на работу с ними и предоставление продуктов или услуг без получения соответствующих лицензий. Иностранные компании, такие как TSMC, теоретически могут продолжать работать с компаниями из «чёрного списка», но США могут оказывать на них давление через их американских поставщиков. Например, когда США занесли Huawei в «чёрный» список, TSMC была вынуждена отказаться от сотрудничества с ней, поскольку многие ключевые технологии, лежащие в основе её производственных процессов, были разработаны американскими фирмами. Пока неясно, оказывалось ли сейчас подобное давление на TSMC, и были ли ею прекращены поставки остальным шести суперкомпьютерным китайским фирмам из «чёрного» списка. Как сообщает South China Morning Post, TSMC выполнит заказы, размещённые Phytium до внесения в «чёрный список», но больше поставлять ей чипы не будет. 
Прототип Tianhe-3. Фото: Xinhua Предполагается, что Phytium стоит за развёртыванием систем высокопроизводительных вычислений для китайского военно-промышленного комплекса, использующего её разработки при создании гиперзвуковых ракет. Компания сотрудничает с Оборонным научно-техническим университетом Народно-освободительной армии Китая (NUDT), который ранее создал суперкомпьютеры Tianhe-1 и Tianhe-2, в своё время занимавшие первые строчки рейтинга TOP500. Tianhe-3, один из трёх проектов китайских суперкомпьютеров экзафлопсного класса, должен был быть закончен в прошлом году, однако осенью было объявлено, что из-за пандемии коронавируса сроки сдвигаются. Летом 2020 года в распоряжении исследователей уже был прототип новой машины, имевший теоретическую производительность 3,146 Пфлопс. Он включал 512 плат с тремя процессорами Phytium MT2000+ и 128 плат с четырьмя Phytium FT2000+. Точные параметры этих 7-нм Arm-чипов не приводятся, но в одной из свежих научных публикаций упоминается, что на каждый 64-ядерный FT2000+ в прототипе Tianhe-3 приходилось 64 Гбайт RAM. А каждый MT2000+ можно поделить на четыре NUMA-узла с 32 ядрами и 16 Гбайт RAM, то есть, судя по описанию, это 128-ядерный чип, о котором ранее ничего не было известно. Теперь же судьба этих CPU и суперкомпьютера Tianhe-3 и вовсе под вопросом.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 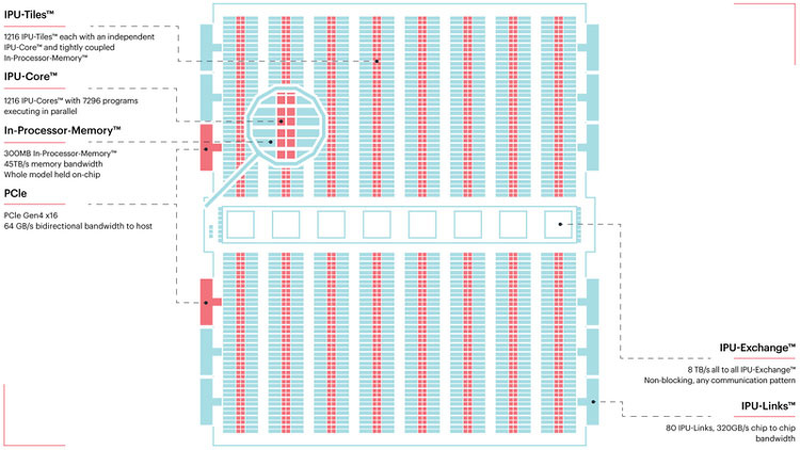
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 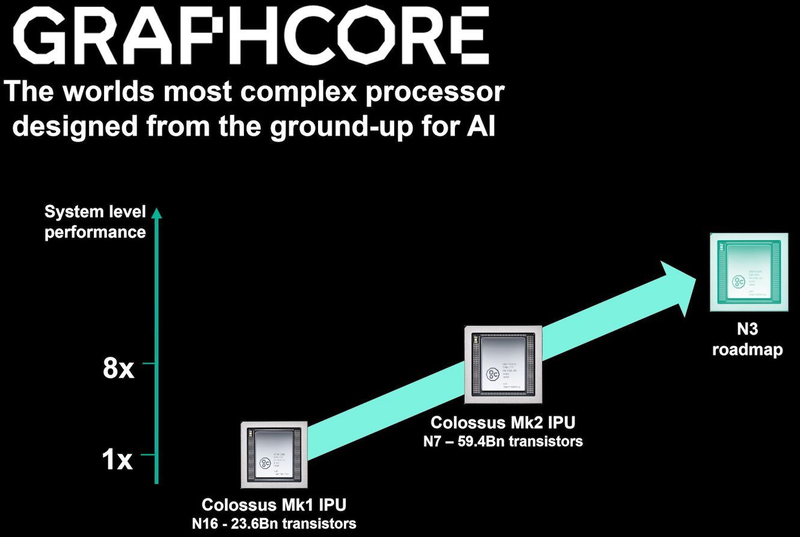
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC. |
|

