Материалы по тегу: кластер
|
10.04.2025 [15:01], Руслан Авдеев
В Эдинбургском университете заработал ИИ-кластер на базе Cerebras CS-3Эдинбургский университет и Cerebras Systems развернули в суперкомпьютерным центре EPCC кластера из четырёх ИИ-систем CS-3 на базе царь-ускорителей WSE-3. Новые мощности являются частью Edinburgh International Data Facility. По словам EPCC, это крупнейший кластер CS-3 в Европе. EPCC уже имеет опыт работы с системами CS-1 и CS-2. В Cerebras заявили, что гордятся расширением сотрудничества с EPCC, которое поможет стать Великобритании одним из ключевых мировых ИИ-хабов. Как заявляют в EPCC, ИИ сегодня изменяет все сферы жизни, поэтому новые системы помогут университетам, государственным организациям и компаниям обучать и использовать ИИ-модели на скоростях и с лёгкостью, недоступной другим ИИ-решениям. Платформы Cerebras оптимизированы не только для масштабного обучения моделей, но и для сверхбыстрого инференса — пользователям кластера теперь доступна платформа-рекордсмен Cerebras AI Inference. Системы CS-3 способны выдавать до 2000 токенов/с для популярных ИИ-моделей. 
Источник изображения: Nadia Ramella/unsplash.com С новыми кластерами на основе Cerebras CS-3, EPCC сможет обучать модели от 240 млрд до 1 трлн параметров, а также ежедневно тюнинговать модели с 70 млрд параметров. Лёгкость использования технологий Cerebras позволяет использовать ИИ-модели и в дисциплинах, не относящихся к компьютерным наукам. Технологии Cerebras обеспечивают линейную масштабируемость, что ускоряет инновации и повышает продуктивность команды EPCC, говорится в сообщении. Эдинбургский университет считается одним из лидеров в разработке ИИ-систем в последние 60 лет. Системы CS-2 в распоряжении EPCC уже позволили исследователям разработать высокоэффективное ПО для инференса для больших языковых моделей (LLM) — как для местного применения, так и для помощи исследователям из Индии в разработке ИИ-моделей для материаловедения и из Швейцарии — для адаптации LLM к местному диалекту немецкого языка. Кроме того, платформы CS-3 с миллионами вычислительных ядер позволят продолжить исследования EPCC в областипараллельных вычислений и энергоэффективности.
25.03.2025 [12:52], Сергей Карасёв
«Скала^р» представила Машину для искусственного интеллекта — отечественный аналог NVIDIA DGX SuperPODКомпания «Скала^р» анонсировала специализированный программно-аппаратный комплекс (ПАК) для работы с ИИ-моделями — Машину Скала^р МБД.ИИ. Эта система, как утверждается, представляет собой функциональный аналог платформ NVIDIA DGX SuperPOD и Huawei Atlas 900 PoD. 
Источник изображения: «Скала^р» Полностью технические характеристики новинки пока не раскрываются. Известно, что Машина Скала^р МБД.ИИ использует интерконнект NVLink с возможностью объединения двух, четырёх или восьми ускорителей. Задействованы технологии GPUDirect и NVMe-oF для обработки и передачи данных, а также система прямого доступа к ресурсам RDMA. Заявлена поддержка всех популярных фреймворков для машинного обучения: TensorFlow, PyTorch, Keras и др. Вычислительный комплекс будет предлагаться в конфигурациях с ускорителями NVIDIA и в вариантах с альтернативными ИИ-картами, в том числе на основе неназванных тензорных процессоров. Кроме того, в разработке находятся решения с поддержкой отечественных ускорителей. Возможно развёртывание системы как в дата-центре заказчика, так и в составе частных и гетерогенных облачных систем. Машина может интегрироваться с другими ПАК семейства Скала^р, предназначенными для работы с большими данными. Для нового комплекса подтверждена совместимость с различными платформами машинного обучения и моделями ИИ, в том числе MTS AI Cotype Pro, T1 Сайбокс, Red_Mad_Robot Neuraldeep.tech, WaveAccess ValueAI, DeepSeek и LLaMA. По заявлениям разработчика, система имеет гибкую унифицированную архитектуру, соответствующую отраслевым стандартам, что позволяет использовать её с YandexGPT, GigaChat и др. Развёртывание приложений ИИ в контейнерной среде обеспечивает эффективное использование аппаратных ресурсов, а реализация интерконнекта с применением топологий Fat-tree, HyperCube, DragonFly или классической архитектуры Leaf-Spine даёт возможность более гибко масштабировать вычислительный кластер. Среди преимуществ Машины Скала^р МБД.ИИ названы:
«Машина Скала^р МБД.ИИ позволяет создать надёжную и производительную инфраструктуру для работы с искусственным интеллектом, используя проверенные технологии и компоненты из реестра Минпромторга и Минцифры РФ с подтверждённой производительностью до 1,5 Пфлопс на вычислительный кластер. Мы видим большой потенциал применения комплекса в различных отраслях экономики, включая промышленность и финансы, где использование ИИ помогает существенно повысить эффективность бизнес-процессов», — говорит директор по технологическим инновациям Скала^р.
17.02.2025 [17:42], Руслан Авдеев
Исследователи DeepMind предложили распределённое обучение больших ИИ-моделей, которое может изменить всю индустриюПосле того, как ИИ-индустрия немного отошла от шока, вызванного неожиданным триумфом китайской DeepSeek, эксперты пришли к выводу, что отрасли, возможно, придётся пересмотреть методики обучения моделей. Так, исследователи DeepMind заявили о модернизации распределённого обучения, сообщает The Register. Недавно представившая передовые ИИ-модели DeepSeek вызвала некоторую панику в США — компания утверждает, что способна обучать модели с гораздо меньшими затратами, чем, например, OpenAI (что оспаривается), и использованием относительно небольшого числа ускорителей NVIDIA. Хотя заявления компании оспариваются многими экспертами, индустрии пришлось задуматься — насколько эффективно тратить десятки миллиардов долларов на всё более масштабные модели, если сопоставимых результатов можно добиться в разы дешевле, с использованием меньшего числа энергоёмких ЦОД. Дочерняя структура Google — компания DeepMind опубликовала результаты исследования, в котором описывается методика распределённого обучения ИИ-моделей с миллиардами параметров с помощью удалённых друг от друга кластеров при сохранении необходимого уровня качества обучения. В статье «Потоковое обучение DiLoCo с перекрывающейся коммуникацией» (Streaming DiLoCo with overlapping communication) исследователи развивают идеи DiLoCo (Distributed Low-Communication Training или «распределённое обучение с низким уровнем коммуникации»). Благодаря этому модели можно будет обучать на «островках» относительно плохо связанных устройств. 
Источник изображения: Igor Omilaev/unsplash.com Сегодня для обучения больших языковых моделей могут потребоваться десятки тысяч ускорителей и эффективный интерконнект с большой пропускной способностью и низкой задержкой. При этом расходы на сетевую часть стремительно растут с увеличением числа ускорителей. Поэтому гиперскейлеры вместо одного большого кластера создают «острова», скорость сетевой коммуникации и связность внутри которых значительно выше, чем между ними. DeepMind же предлагает использовать распределённые кластеры с относительно редкой синхронизацией — потребуется намного меньшая пропускная способность каналов связи, но при этом без ущерба качеству обучения. Технология Streaming DiLoCo представляет собой усовершенствованную версию методики с синхронизацией подмножеств параметров по расписанию и сокращением объёма подлежащих обмену данных без потери производительности. Новый подход, по словам исследователей, требует в 400 раз меньшей пропускной способности сети. 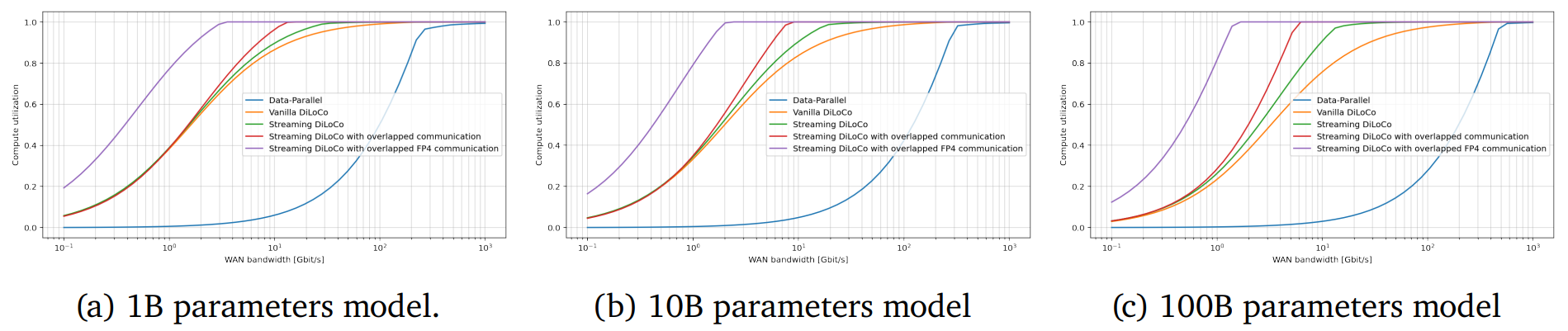
Источник изображения: DeepMind Важность и потенциальную перспективность DiLoCo отмечают, например, и в Anthropic. В компании сообщают, что Streaming DiLoCo намного эффективнее обычного варианта DiLoCo, причём преимущества растут по мере масштабирования модели. В результате допускается, что обучение моделей в перспективе сможет непрерывно осуществляться с использованием тысяч разнесённых достаточно далеко друг от друга систем, что существенно снизит порог входа для мелких ИИ-компаний, не имеющих ресурсов на крупные ЦОД. В Gartner утверждают, что методы, уже применяемые DeepSeek и DeepMind, уже становятся нормой. В конечном счёте ресурсы ЦОД будут использоваться всё более эффективно. Впрочем, в самой DeepMind рассматривают Streaming DiLoCo лишь как первый шаг на пути совершенствования технологий, требуется дополнительная разработка и тестирование. Сообщается, что возможность объединения многих ЦОД в единый виртуальный мегакластер сейчас рассматривает NVIDIA, часть HPC-систем которой уже работает по схожей схеме.
03.02.2025 [15:21], Сергей Карасёв
Реальные затраты DeepSeek на создание ИИ-моделей на порядки выше заявленных, но достижений компании это не умаляетКитайский стартап DeepSeek наделал много шума в Кремниевой долине, анонсировав «рассуждающую» ИИ-модель DeepSeek R1 c 671 млрд параметров. Утверждается, что при её обучении были задействованы только 2048 ИИ-ускорителей NVIDIA H800, а затраты на данные работы составили около $6 млн. Это бросило вызов многим западным конкурентам, таким как OpenAI, а акции ряда крупных ИИ-компаний начали падать в цене. Однако, как сообщает ресурс SemiAnalysis, фактические расходы DeepSeek на создание ИИ-инфраструктуры и обучение нейросетей могут быть гораздо выше. Стартап DeepSeek берёт начало от китайского хедж-фонда High-Flyer. В 2021 году, ещё до введения каких-либо экспортных ограничений, эта структура приобрела 10 тыс. ускорителей NVIDIA A100. В мае 2023 года с целью дальнейшего развития направления ИИ из High-Flyer была выделена компания DeepSeek. После этого стартап начал более активное расширение вычислительной ИИ-инфраструктуры. По данным SemiAnalysis, на сегодняшний день DeepSeek имеет доступ примерно к 10 тыс. изделий NVIDIA H800 и 10 тыс. NVIDIA H100. Кроме того, говорится о наличии около 30 тыс. ускорителей NVIDIA H20, которые совместно используются High-Flyer и DeepSeek для обучения ИИ, научных исследований и финансового моделирования. Таким образом, в общей сложности DeepSeek может использовать до 50 тыс. ускорителей NVIDIA при работе с ИИ, что в разы больше заявленной цифры в 2048 ускорителей. 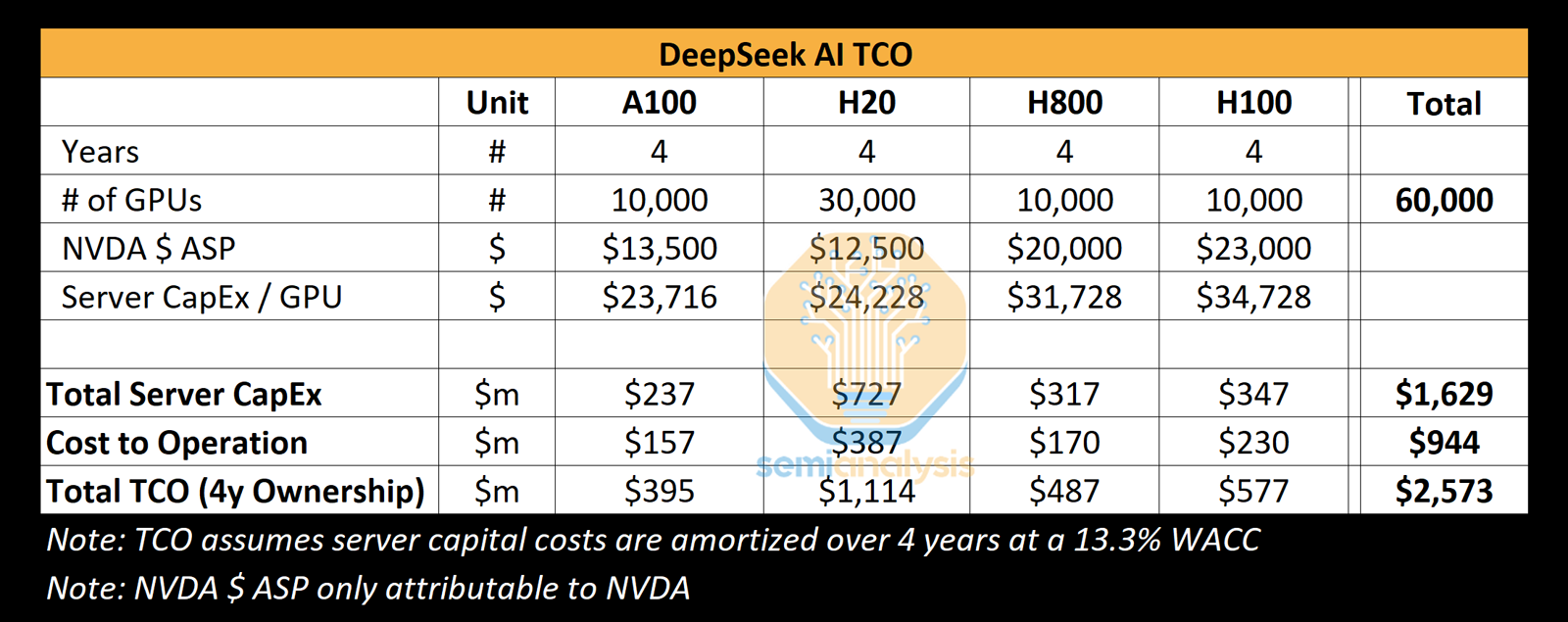
Источник изображения: SemiAnalysis Кроме того, SemiAnalysis сообщает, что общие капитальные затраты на ИИ-серверы для DeepSeek составили около $1,6 млрд, тогда как операционные расходы могут достигать $944 млн. Это подрывает заявления о том, что DeepSeek заново изобрела процесс обучения ИИ и инференса с существенно меньшими инвестициями, чем лидеры отрасли. Цифра в $6 млн не учитывает затраты на исследования, тюнинг модели, обработку данных и пр. На самом деле, как подчёркивается, DeepSeek потратила более $500 млн на разработки с момента своего создания. И всё же DeepSeek имеет ряд преимуществ перед другими участниками глобального ИИ-рынка. В то время как многие ИИ-стартапы полагаются на внешних поставщиков облачных услуг, DeepSeek эксплуатирует собственные дата-центры, что позволяет быстрее внедрять инновации и полностью контролировать разработку, оптимизируя расходы. Кроме того, DeepSeek остаётся самофинансируемой компанией, что обеспечивает гибкость и позволяет более оперативно принимать решения. Плюс к этому DeepSeek нанимает специалистов исключительно из Китая, уделяя особое внимание не формальным записям в аттестатах, а практическим навыкам работы и способностям эффективно выполнять поставленные задачи. Некоторые ИИ-исследователи в DeepSeek зарабатывают более $1,3 млн в год, что говорит об их высочайшей квалификации.
30.12.2024 [12:56], Сергей Карасёв
Firefly представила серверы CSB1-N10 для создания ИИ-кластеров из одноплатных компьютеровКомпания Firefly Technology, по сообщению ресурса CNX-Software, выпустила серверы серии CSB1-N10 для построения ИИ-кластеров. Устройства, выполненные в форм-факторе 1U, подходят для дата-центров, периферийных развёртываний и локальных площадок. В семейство вошли пять моделей: CSB1-N10S1688, CSB1-N10R3588, CSB1-N10R3576, CSB1-N10NOrinNano и CSB1-N10NOrinNX. Узлы систем оснащены соответственно процессором Sophgo Sophon BM1688 (8 ядер, до 1,6 ГГц), Rockchip RK3588 (8 ядер, до 2,4 ГГц), Rockchip RK3576 (8 ядер, до 2,2 ГГц), NVIDIA Jetson Orin Nano (6 ядер, до 1,5 ГГц) и Jetson Orin NX (8 ядер, до 2,0 ГГц). Первые три из перечисленных узлов комплектуются оперативной памятью LPDDR4 объёмом 8, 16 и 8 Гбайт соответственно, а также флеш-модулем eMMC вместимостью 32, 256 и 64 Гбайт. Варианты Orin оборудованы 8 и 16 Гбайт памяти LPDDR5 и накопителем NVMe SSD на 256 Гбайт. Все серверы содержат десять вычислительных узлов и дополнительный управляющий узел на чипе RK3588. Присутствует слот для SSD с интерфейсом SATA-3. В оснащение входят по два сетевых порта 10GbE (SFP+) и 1GbE (RJ45), выделенный сетевой порт управления 1GbE, аналоговый разъём D-Sub (1080p60), два порта USB 3.0, а также последовательный порт. Применяется воздушное охлаждение. За питание отвечает блок мощностью 550 Вт. Диапазон рабочих температур — от 0 до +45 °C. 
Источник изображения: Firefly Кластер на базе CSB1-N10S1688 обеспечивает ИИ-производительность до 160 TOPS на операциях INT8. В случае CSB1-N10R3588 и CSB1-N10R3576 это показатель составляет 60 TOPS. Эти три системы поддерживают работу с большими языковыми моделями (LLM), а также фреймворками TensorFlow, PyTorch, PaddlePaddle, ONNX, Caffe. В случае CSB1-N10NOrinNano и CSB1-N10NOrinNX быстродействие достигает 400 и 1000 TOPS. Говорится о поддержке LLaMa3 и Phi-3 Mini, фреймворков TensorFlow, PyTorch, Matlab и др. Цена варьируется от $2059 до $14 709.
28.12.2024 [12:16], Сергей Карасёв
Xiaomi создаст ИИ-кластер с 10 тыс. GPUКитайская компания Xiaomi, по сообщению Jiemian News, намерена создать собственный вычислительный кластер для решения ресурсоёмких задач в области ИИ. Предполагается, что в основу системы лягут около 10 тыс. ускорителей на базе GPU. Отмечается, что Xiaomi активно развивает направление ИИ. Соответствующее подразделение было сформировано ещё в 2016 году, и с тех пор его штат увеличился примерно в шесть раз — до более чем 3000 сотрудников (включая специалистов, задействованных в смежных областях). С начала 2024 года Xiaomi использует для проектов ИИ вычислительную платформу, насчитывающую около 6500 ускорителей на основе GPU. В дальнейшем количество GPU планируется наращивать. Инициативы Xiaomi в области ИИ курирует генеральный директор компании Лэй Цзюнь (Lei Jun). 
Источник изображения: Xiaomi Проекты Xiaomi в сфере ИИ охватывают самые разные направления, включая компьютерное зрение, обработку естественного языка, графы знаний, машинное обучение, большие языковые модели (LLM) и мультимодальные технологии. Эти технологии по мере развития интегрируются в смартфоны, автомобильные бортовые системы, робототехнику, а также в интеллектуальные устройства Интернета вещей (AIoT). Ранее Цзюнь сообщил, что Xiaomi успешно адаптировала LLM для локального использования на мобильных устройствах: утверждается, что модель с 1,3 млрд параметров достигла сопоставимой с облаком производительности в некоторых сценариях. Кроме того, компания создала более мощную LLM с 6 млрд параметров. Говорится также, что Xiaomi сотрудничает с другими участниками рынка в рамках развития проектов ИИ: в число партнёров входят Qualcomm и MediaTek.
15.12.2024 [13:00], Сергей Карасёв
Vultr запустил облачный ИИ-кластер на базе AMD Instinct MI300XКрупнейший в мире частный облачный провайдер Vultr объявил о заключении соглашения о четырёхстороннем стратегическом сотрудничестве с целью развёртывания нового суперкомпьютерного кластера. В проекте принимают участие AMD, Broadcom и Juniper Networks. Применяются ускорители AMD Instinct MI300X и открытый программный стек ROCm. Данные о количестве ускорителей и общей производительности платформы пока не раскрываются. Кластер размещён в дата-центре Vultr Centersquare в Лайле (юго-западный пригород Чикаго; Иллинойс; США). Новая НРС-система построена с использованием Ethernet-коммутаторов Broadcom и оптимизированных для ИИ-задач сетевых Ethernet-решений Juniper Networks. Благодаря этим компонентам, как утверждается, возможно построение безопасной высокопроизводительной инфраструктуры. Кластер ориентирован прежде всего на обучение ИИ-моделей и ресурсоёмкие нагрузки инференса. «Сотрудничество с AMD, Broadcom и Juniper Networks позволяет предприятиям и специалистам в области ИИ использовать весь потенциал ускоренных вычислений при одновременном обеспечении гибкости, масштабируемости и безопасности», — говорит Джей Джей Кардвелл (J.J. Kardwell), генеральный директор Vultr. 
Источник изображения: AMD О доступности Instinct MI300X в своей облачной инфраструктуре компания Vultr сообщила в сентябре нынешнего года. Ускорители AMD интегрируются с Vultr Kubernetes Engine for Cloud GPU для формирования кластеров Kubernetes, использующих ускорители. Предложение ориентировано на задачи ИИ и НРС. Vultr ставит своей целью сделать высокопроизводительные облачные вычисления простыми в использовании и доступными для предприятий и разработчиков по всему миру. На сегодняшний день экосистема Vultr включает 32 облачные зоны, в том числе площадки в Северной Америке, Южной Америке, Европе, Азии, Австралии и Африке.
20.11.2024 [10:59], Сергей Карасёв
Nebius, бывшая Yandex, развернёт в США своей первый ИИ-кластер на базе NVIDIA H200Nebius, бывшая материнская компания «Яндекса», объявила о создании своего первого вычислительного ИИ-кластера на территории США. Система будет развёрнута на базе дата-центра Patmos в Канзас-Сити (штат Миссури), а её ввод в эксплуатацию запланирован на I квартал 2025 года. На начальном этапе в составе кластера Nebius будут использоваться ИИ-ускорители NVIDIA H200. В следующем году планируется добавить решения поколения NVIDIA Blackwell. Мощность площадки может быть увеличена с первоначальных 5 МВт до 40 МВт: это позволит задействовать до 35 тыс. GPU. По заявлениям Nebius, фирма Patmos была выбрана в качестве партнёра в связи с гибкостью и опытом в поэтапном строительстве ЦОД. Первая фаза проекта включает развёртывание необходимой инфраструктуры, в том числе установку резервных узлов, таких как генераторы. Новая зона доступности, как ожидается, позволит Nebius более полно удовлетворять потребности американских клиентов, занимающихся разработками и исследованиями в области ИИ. 
Источник изображения: Nebius Говорится, что Nebius активно наращивает присутствие в США в рамках стратегии по формированию ведущего поставщика инфраструктуры для ИИ-задач. На 2025 год намечено создание второго — более масштабного — кластера GPU в США. Кроме того, компания открыла два центра по работе с клиентами — в Сан-Франциско и Далласе, а третий офис до конца текущего года заработает в Нью-Йорке. Напомним, что ранее Nebius запустила первый ИИ-кластер во Франции на базе NVIDIA H200. У компании также есть площадка в Финляндии. К середине 2025 года Nebius намерена инвестировать более $1 млрд в инфраструктуру ИИ в Европе. А около месяца назад компания представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200.
26.10.2024 [00:53], Владимир Мироненко
Tesla до конца месяца запустит ИИ-кластер из 50 тыс. NVIDIA H100Tesla планирует ввести в эксплуатацию ЦОД с 50 тыс. ускорителей NVIDIA H100 в конце этого месяца, пишет Data Center Dynamics (DCD) со ссылкой на заявление компании. «Мы начали использовать кластер на базе нашего завода раньше срока и находимся на пути к развертыванию 50 тыс. GPU в Техасе к концу этого месяца», — сообщил финансовый директор Вайбхав Танеджа (Vaibhav Taneja) в ходе отчёта о финансовых результатах за III квартал. Предполагается, что именно этот кластер, размещённый в Остине (Техас) отставал от графика, из-за чего гендиректор Илон Маск (Elon Musk) уволил в апреле руководителя строительства. В июне по распоряжению Маска 12 тыс. ускорителей H100, предназначавшихся Tesla, были переданы xAI. Сама xAI в сентябре запустила ИИ-кластер со 100 тыс. ускорителей NVIDIA H100. Капитальные затраты Tesla достигли $3,5 млрд в отчётном квартале, «последовательно увеличившись в основном из-за инвестиций в ИИ-вычисления», а капитальные затраты за год, как ожидается, превысят $11 млрд, что на $1 млрд больше год к году. При этом Танеджа сообщил, что компания «очень разумно подходит к расходам на ИИ», пытаясь наилучшим способом использовать существующую инфраструктуру, прежде чем делать дальнейшие инвестиции. 
Источник изображения: Taylor Vick / Unsplash Маск заявил, что Tesla продолжает расширять возможности обучения ИИ, чтобы удовлетворить как потребности в обучении автопилота Full Self Driving (FSD), так и роботов Optimus, отметив, что в настоящее время компания не испытывает дефицита вычислительных ресурсов. В квартальном отчёте не упоминается Dojo, ИИ-инфраструктура Tesla на базе ускорителей собственной разработки.
21.10.2024 [18:06], Владимир Мироненко
«Инфосистемы Джет» и «Аэродиск» с успехом протестировали первый российский метрокластер на устойчивость к различным отказам
hardware
аквариус
аэродиск
инфосистемы джет
кластер
резервирование
резервное копирование
сделано в россии
схд
«Инфосистемы Джет» и «Аэродиск» сообщили об успешных испытаниях первого отечественного метрокластера на базе СХД с использованием сценариев эмуляции различных отказов и сбоев. В «Инфосистемы Джет» отметили, что протестированный метрокластер является первым отечественным решением такого класса. Метрокластер представляет собой отказоустойчивую ИТ-инфраструктуру на базе синхронной репликации данных средствами СХД. Метрокластер включает две идентичные СХД, размещённые в разных локациях с зеркалированием данных в синхронном режиме. Выход из строя одной СХД или целой площадки не отражается на сохранности данных, которые остаются доступны на второй СХД, а функционирование прикладных систем продолжается. Работа такого кластера полностью автоматизирована и не требует вмешательства администратора в случае сбоя. Тестируемая конфигурация была построена на отечественных решениях «Аквариуса»: две СХД «Аэродиск» Engine AQ 440, соединённые между собой оптическими каналами связи через 25GbE-коммутаторы AQ-N5001, и ферма виртуализации на серверах T50 с использованием отечественного ПО. В ходе испытания проводилась эмуляции прикладной тестовой нагрузки на СХД со стороны СУБД PostgreSQL, запущенной в виртуальной машине. Также вносились сетевые задержки для эмуляции протяжённой линии связи межу ЦОД. 
Источник изображения: «Инфосистемы Джет» Как сообщается, сначала работу кластера проверили при смоделированном отказе СХД на одной площадке из-за аварийного отключения электропитания. Для миграции виртуального интерфейса (VIP) метрокластера на другую СХД потребовалось 30 секунд, что не отразилось на стабильности работы виртуальной машины. Затем провели эмуляцию отказа всей площадки из-за отключения электропитания оборудования (сервер, коммутатор, СХД). В этом случае помимо переключения VIP СХД метрокластера на другую СХД произошло переключение виртуальной машины из-за отказа хоста виртуализации. После этого тестовая нагрузка была перезапущена на второй площадке. Всего на восстановление нагрузки после крушения системы ушло не более трёх минут. В третьем тесте проверили работу метрокластера при сбое каналов связи, который приводит к изоляции узлов кластера. В ходе теста эксперты проверили работу механизма арбитража между двумя СХД при участии сервера-арбитра. В этом случае СХД, сохраняющая с ним связь, становится основной и принимает на себя нагрузку, а вторая СХД исключается из кластера. |
|

