Материалы по тегу: mi300
|
20.02.2025 [13:12], Сергей Карасёв
Облако Vultr первым получило ускорители AMD Instinct MI325XVultr, крупнейший в мире частный облачный провайдер, объявил о том, что в его инфраструктуре появились ускорители AMD Instinct MI325X, предназначенные для ресурсоёмких ИИ-нагрузок. Говорится об использовании открытого программного стека ROCm и о поддержке ключевых фреймворков. Vultr стал первым поставщиком облачных услуг, взявшим на вооружение изделия AMD Instinct MI325X. Ускорители развёрнуты в дата-центре компании в Чикаго (Иллинойс, США). Внедрение этих решений является частью усилий по расширению сотрудничества с AMD: в сентябре прошлого года в облаке Vultr появились ускорители Instinct MI300X. Изделия Instinct MI325X несут на борту 256 Гбайт памяти HBM3E с пропускной способностью до 6 Тбайт/с. Пиковая производительность достигает 1,3 Пфлопс в режиме FP16 и 2,6 Пфлопс в режиме FP8. Решения подходят в том числе для задач инференса. 
Источник изображения: AMD Отмечается, что Vultr использует ускорители Instinct MI325X в составе серверов Supermicro AS-8126GS-TNMR типоразмера 8U. Эти машины комплектуются двумя процессорами AMD EPYC 9005/9004 с показателем TDP до 500 Вт. Доступны 24 слота для модулей DDR5-6000 суммарным объёмом до 9 Тбайт. Во фронтальной части расположены десять отсеков для SFF-накопителей в конфигурации 8 × NVMe и 2 × SATA. Кроме того, есть два коннектора М.2 (NVMe). Предусмотрены восемь слотов PCIe 5.0 x16 LP и два слота PCIe 5.0 x16 FHHL. За питание отвечают шесть блоков мощностью 5250 Вт с сертификатом Titanium. Применяется воздушное охлаждение. «Ускорители AMD Instinct MI325X устанавливают новые стандарты в области ИИ, обеспечивая невероятную производительность и эффективность для задач инференса», — говорит глава Vultr. Цены на новые инстансы пока не названы.
19.01.2025 [22:43], Сергей Карасёв
Германия запустила «переходный» 48-Пфлопс суперкомпьютер Hunter на базе AMD Instinct MI300AЦентр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии объявил о вводе в эксплуатацию НРС-системы Hunter. Этот суперкомпьютер планируется использовать для решения широко спектра задач в области инженерии, моделирования погоды и климата, биомедицинских исследований, материаловедения и пр. Кроме того, комплекс будет применяться для крупномасштабного моделирования, ИИ-приложений и анализа данных. О создании Hunter сообщалось в конце 2023 года: соглашение на строительство системы стоимостью примерно €15 млн было заключено с HPE. Проект финансируется Федеральным министерством образования и исследований Германии и Министерством науки, исследований и искусств Баден-Вюртемберга. Hunter базируется на той же архитектуре, что El Capitan — самый мощный в мире суперкомпьютер. Задействована платформа Cray EX4000, а каждый из узлов оснащён четырьмя адаптерами HPE Slingshot. Суперкомпьютер использует комбинацию из APU Instinct MI300A и процессоров EPYC Genoa. Как отмечает The Register, в общей сложности система объединяет 188 узлов с жидкостным охлаждением и насчитывает суммарно 752 APU и 512 чипов Epyc с 32 ядрами. Применена СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для суперкомпьютеров HPE Cray. 
Источник изображения: HLRS HLRS оценивает пиковую теоретическую FP64-производительность Hunter в 48,1 Пфлопс на операциях двойной точности, что практически вдвое выше, чем у предшественника Hawk. В режимах BF16 и FP8 быстродействие, как ожидается, будет варьироваться от 736 Пфлопс до 1,47 Эфлопс. При этом Hunter потребляет на 80% меньше энергии, нежели Hawk. 
Источник изображения: Штутгартский университет Отмечается, что Hunter задуман как переходная система, которая подготовит почву для суперкомпьютера HLRS следующего поколения под названием Herder. Ввести этот комплекс в эксплуатацию планируется в 2027 году. Предполагается, что он обеспечит производительность «в несколько сотен петафлопс».
15.12.2024 [13:00], Сергей Карасёв
Vultr запустил облачный ИИ-кластер на базе AMD Instinct MI300XКрупнейший в мире частный облачный провайдер Vultr объявил о заключении соглашения о четырёхстороннем стратегическом сотрудничестве с целью развёртывания нового суперкомпьютерного кластера. В проекте принимают участие AMD, Broadcom и Juniper Networks. Применяются ускорители AMD Instinct MI300X и открытый программный стек ROCm. Данные о количестве ускорителей и общей производительности платформы пока не раскрываются. Кластер размещён в дата-центре Vultr Centersquare в Лайле (юго-западный пригород Чикаго; Иллинойс; США). Новая НРС-система построена с использованием Ethernet-коммутаторов Broadcom и оптимизированных для ИИ-задач сетевых Ethernet-решений Juniper Networks. Благодаря этим компонентам, как утверждается, возможно построение безопасной высокопроизводительной инфраструктуры. Кластер ориентирован прежде всего на обучение ИИ-моделей и ресурсоёмкие нагрузки инференса. «Сотрудничество с AMD, Broadcom и Juniper Networks позволяет предприятиям и специалистам в области ИИ использовать весь потенциал ускоренных вычислений при одновременном обеспечении гибкости, масштабируемости и безопасности», — говорит Джей Джей Кардвелл (J.J. Kardwell), генеральный директор Vultr. 
Источник изображения: AMD О доступности Instinct MI300X в своей облачной инфраструктуре компания Vultr сообщила в сентябре нынешнего года. Ускорители AMD интегрируются с Vultr Kubernetes Engine for Cloud GPU для формирования кластеров Kubernetes, использующих ускорители. Предложение ориентировано на задачи ИИ и НРС. Vultr ставит своей целью сделать высокопроизводительные облачные вычисления простыми в использовании и доступными для предприятий и разработчиков по всему миру. На сегодняшний день экосистема Vultr включает 32 облачные зоны, в том числе площадки в Северной Америке, Южной Америке, Европе, Азии, Австралии и Африке.
20.11.2024 [13:04], Руслан Авдеев
IBM и AMD расширяют сотрудничество: Instinct MI300X появится в облаке IBM CloudКомпания IBM объявила о расширении сотрудничества с AMD для предоставления ускорителей Instinct MI300X в формате «ускорители как услуга» (Accelerators-as-a-Service). По словам IBM, новое решение расширяет возможности и энергоэффективность генеративных ИИ-моделей и HPC-приложений. AMD Instinct MI300X станут доступны в IBM watsonx, а также будут поддерживаться в Red Hat Enterprise Linux AI. Они дополнят портфолио IBM Cloud, уже включающее Intel Gaudi 3 и NVIDIA H100. Ускоритель AMD Instinct MI300X оснащён 192 Гбайт памяти HBM3. И относительно малое количество ускорителей способно обеспечить работу больших ИИ-моделей, что позволяет снизить затраты с сохранением производительности и масштабируемости. Ускорители будут доступны в составе виртуальных серверов и частных виртуальных облаков, а также в контейнеризированных средах IBM Cloud Kubernetes Service и IBM Red Hat OpenShift. 
Источник изображения: AMD Кроме того, для MI300X будут доступны LLM Granite и инструмент InstructLab. Речь идёт в том числе об интеграции программных решений IBM с ПО AMD ROCm. По словам компании, предложенные решения обеспечит клиентов гибкой, безопасной, высокопроизводительной и масштабируемой средой для рабочих нагрузок ИИ. AMD Instinct MI300X станут доступны пользователям IBM Cloud в I половине 2025 года.
20.11.2024 [10:56], Сергей Карасёв
Microsoft представила инстансы Azure HBv5 на основе уникальных чипов AMD EPYC 9V64H с памятью HBM3Компания Microsoft на ежегодной конференции Ignite для разработчиков, IT-специалистов и партнёров анонсировала облачные инстансы Azure HBv5 для HPC-задач, которые предъявляют наиболее высокие требования к пропускной способности памяти. Новые виртуальные машины оптимизированы для таких приложений, как вычислительная гидродинамика, автомобильное и аэрокосмическое моделирование, прогнозирование погоды, исследования в области энергетики, автоматизированное проектирование и пр. Особенность Azure HBv5 заключается в использовании уникальных процессоров AMD EPYC 9V64H (поколения Genoa). Эти чипы насчитывают 88 вычислительных ядер Zen4, тактовая частота которых достигает 4 ГГц. Ближайшим родственником является изделие EPYC 9634, которое содержит 84 ядра (168 потоков) и функционирует на частоте до 3,7 ГГц. По данным ресурса ComputerBase.de, чип EPYC 9V64H также фигурирует под именем Instinct MI300C: по сути, это процессор EPYC, дополненный памятью HBM3. При этом клиентам предоставляется возможность кастомизации характеристик. Отметим, что ранее x86-процессоры с набортной памятью HBM2e были доступны в серии Intel Max (Xeon поколения Sapphire Rapids). Каждый инстанс Azure HBv5 объединяет четыре процессора EPYC 9V64H, что в сумме даёт 352 ядра. Система предоставляет доступ к 450 Гбайт памяти HBM3, пропускная способность которой достигает 6,9 Тбайт/с. Задействован интерконнект NVIDIA Quantum-2 InfiniBand со скоростью передачи данных до 200 Гбит/с в расчёте на CPU. 
Источник изображений: Microsoft Применены сетевые адаптеры Azure Boost NIC второго поколения, благодаря которым пропускная способность сети Azure Accelerated Networking находится на уровне 160 Гбит/с. Для локального хранилища на основе NVMe SSD заявлена скорость чтения информации до 50 Гбайт/с и скорость записи до 30 Гбайт/с. 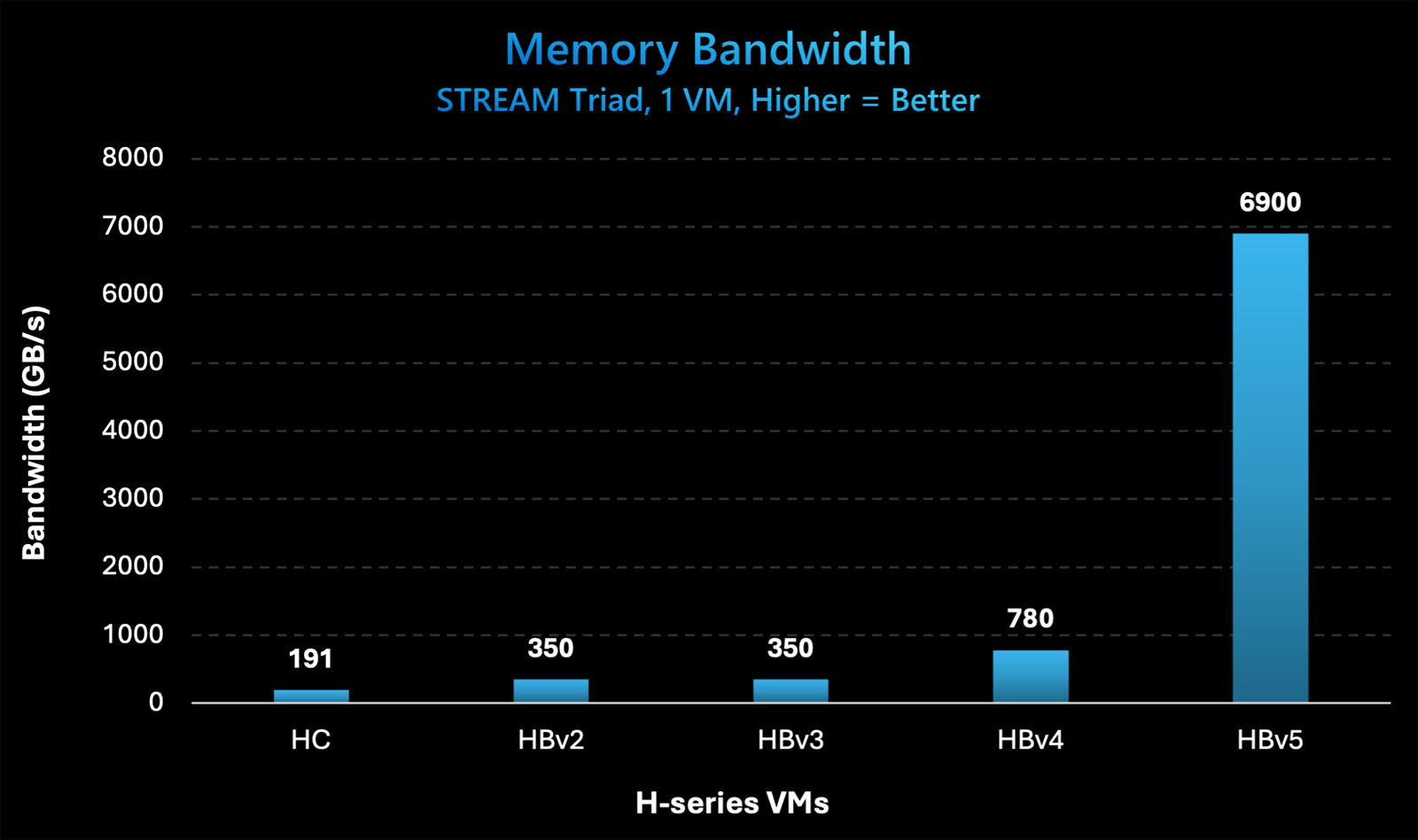 Отмечается, что по показателю пропускной способности памяти виртуальные машины Azure HBv5 примерно в 8 раз превосходят новейшие альтернативы bare-metal и cloud, в 20 раз опережают инстансы Azure HBv3 и Azure HBv2 (на базе EPYC Milan-X и EPYC Rome) и в 35 раз обходят HPC-серверы возрастом 4–5 лет, жизненный цикл которых приближается к завершению. Машины Azure HBv5 станут доступны в I половине 2025 года.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 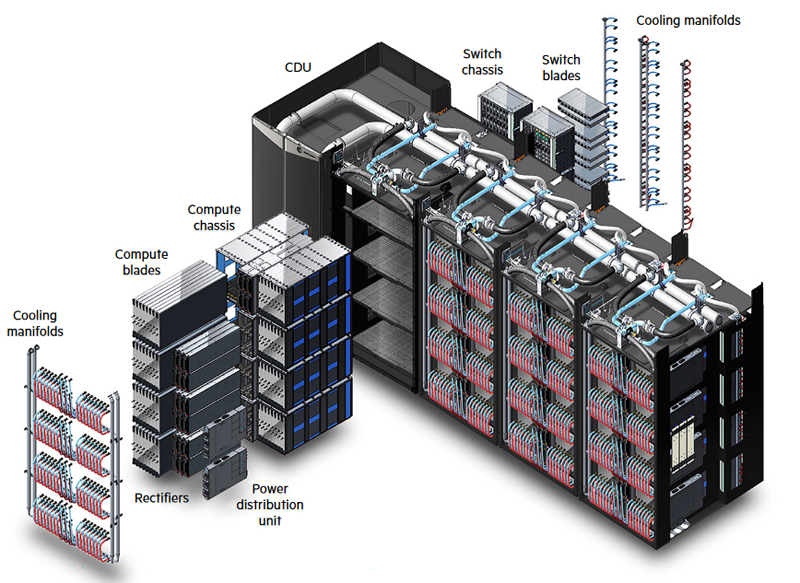 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
19.11.2024 [17:30], Сергей Карасёв
1,742 Эфлопс: El Capitan стал самым мощным в мире суперкомпьютером рейтинга TOP500Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США (DOE), Администрация по национальной ядерной безопасности США (NNSA), компании AMD и HPE официально представили El Capitan — самый производительный в мире суперкомпьютер. Эта машина возглавила ноябрьский рейтинг мощнейших вычислительных систем TOP500. Комплекс El Capitan создан специалистами HPE Cray. Суперкомпьютер обладает FP64-быстродействием 1,742 Эфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 2,746 Эфлопс. Прежний лидер TOP500 — система Frontier — с производительностью 1,353 Эфлопс теперь находится на втором месте рейтинга. Машина Aurora, так и не прибавившая в производительности, хотя и заявленная когда-то как 2-Эфлопс система, занимает теперь третье место. В основу El Capitan легла платформа HPE Cray Shasta. Используется гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. В общей сложности в составе суперкомпьютера объединены 11 136 узлов, каждый из которых несёт на борту четыре экземпляра Instinct MI300A. Применён интерконнект HPE Slingshot-11 с пропускной способностью 200 Гбит/с. Система включает узлы Rabbit, которые формируют дезагрегированное NVMe-хранилище с прямым PCIe-подключением к вычислительным узлам. 
Источник изображений: LLNL Суммарное количество ядер CPU и GPU в составе El Capitan достигает 11 039 616, объём памяти — 5,4375 Пбайт. За отвод тепла отвечает система прямого жидкостного охлаждения HPE. Заявленная энергетическая эффективность составляет 58,89 Гфлопс/Вт: с таким показателем машина оказалась на 18-м месте в списке «зелёных» суперкомпьютеров GREEN500, но с учётом масштаба и общего энергопотребления 29,58 МВт — это хороший показатель. Система охлаждения HPC-объекта использует 28 тыс. т воды. Отмечается, что El Capitan станет главным вычислительным ресурсом для Tri-lab — группы, в которую вместе с LLNL входят Сандийские национальные лаборатории (SNL) и Лос-Аламосская национальная лаборатория (LANL). Использовать мощности нового суперкомпьютера планируется для обеспечения национальной безопасности и решения сложных задач, связанных с ядерным оружием. В частности, El Capitan обеспечит беспрецедентные возможности моделирования и имитации, необходимые для Программы управления ядерными запасами NNSA. Кроме того, НРС-комплекс поможет в модернизации и создании нового оружия, такого как боеголовки W87-1 и W93, которые в настоящее время находятся на стадии разработки.  Отмечается также, что на 10-й позиции в рейтинге TOP500 оказался суперкомпьютер Tuolumne, также построенный в рамках проекта LLNL и NNSA. Фактически Tuolumne — это младший брат El Capitan: машина использует ту же архитектуру на базе Instinct MI300A, но обладает примерно на порядок меньшей FP64-производительностью 208,10 Пфлопс с пиковым значением 288,88 Пфлопс. Применять мощности Tuolumne планируется для «несекретных» задач, таких как исследования в области энергетической безопасности, изменений климата, вычислительной биологии, разработки лекарственных препаратов следующего поколения и пр. Стоит отметить, что Frontier — не единственная система, которая уступила пальму первенства более новым НРС-комплексам в ноябрьском рейтинге TOP500. Та же участь постигла самый мощный суперкомпьютер Европы LUMI, который опустился с пятого на восьмое место. На пятой позиции оказалась совершенно новая система HPC6, расположенная в центре нефтегазовой компании Eni в Феррера-Эрбоньоне (Италия). Её производительность достигает 477,9 Пфлопс при пиковом показателе 606,97 Пфлопс.
31.10.2024 [11:33], Сергей Карасёв
Cisco представила ИИ-сервер UCS C885A M8 на базе NVIDIA H100/H200 или AMD Instinct MI300XКомпания Cisco анонсировала сервер высокой плотности UCS C885A M8, предназначенный для решения задач в области ИИ, таких как обучение больших языковых моделей (LLM), тонкая настройка моделей, инференс, RAG и пр. 
Источник изображения: Cisco Устройство выполнено в форм-факторе 8U. В зависимости от модификации устанавливаются два процессора AMD EPYC 9554 поколения Genoa (64 ядра; 128 потоков; 3,1–3,75 ГГц; 360 Вт) или два чипа EPYC 9575F семейства Turin (64 ядра; 128 потоков; 3,3–5,0 ГГц; 400 Вт). Доступны 24 слота для модулей DDR5-600 суммарным объёмом 2,3 Тбайт. В максимальной конфигурации могут быть задействованы восемь SXM-ускорителей NVIDIA H100, H200 или AMD Instinct MI300X. Каждый ускоритель дополнен сетевым адаптером NVIDIA ConnectX-7 или NVIDIA BlueField-3 SuperNIC. Кроме того, в состав сервера входит DPU BlueField-3. Слоты расширения выполнены по схеме 5 × PCIe 5.0 x16 FHHL плюс 8 × PCIe 5.0 x16 HHHL и 1 × OCP 3.0 PCIe 5.0 x8 (для карты X710-T2L 2x10G RJ45 NIC). 
Источник изображения: Cisco Новинка оборудована загрузочным SSD вместимостью 1 Тбайт (M.2 NVMe), а также 16 накопителями U.2 NVMe SSD на 1,92 Тбайт каждый. Установлены два блока питания мощностью 2700 Вт и шесть блоков на 3000 Вт с возможностью горячей замены. Cisco также представила инфраструктурные стеки AI POD, адаптированные для конкретных вариантов использования ИИ в различных отраслях. Они объединяют вычислительные узлы, сетевые компоненты, средства хранения и управления. Стеки, как утверждается, обеспечивают хорошую масштабируемость и высокую эффективность при решении ИИ-задач.
30.10.2024 [11:49], Сергей Карасёв
OpenAI разрабатывает собственные ИИ-чипы совместно с Broadcom и TSMC, а пока задействует AMD Instinct MI300XКомпания OpenAI, по информации Reuters, разрабатывает собственные чипы для обработки ИИ-задач. Партнёром в рамках данного проекта выступает Broadcom, а организовать производство изделий планируется на мощностях TSMC ориентировочно в 2026 году. Слухи о том, что OpenAI обсуждает с Broadcom возможность создания собственного ИИ-ускорителя, появились минувшим летом. Тогда говорилось, что эта инициатива является частью более масштабной программы OpenAI по увеличению вычислительных мощностей компании для разработки ИИ, преодолению дефицита ускорителей и снижению зависимости от NVIDIA. Как теперь стало известно, OpenAI уже несколько месяцев работает с Broadcom над своим первым чипом ИИ, ориентированным на задачи инференса. Соответствующая команда разработчиков насчитывает около 20 человек, включая специалистов, которые ранее принимали участие в проектировании ускорителей TPU в Google, в том числе Томаса Норри (Thomas Norrie) и Ричарда Хо (Richard Ho). Подробности о проекте не раскрываются. Reuters, ссылаясь на собственные источники, также сообщает, что OpenAI в дополнение к ИИ-ускорителям NVIDIA намерена взять на вооружение решения AMD, что позволит диверсифицировать поставки оборудования. Речь идёт о применении изделий Instinct MI300X, ресурсы которых будут использоваться через облачную платформу Microsoft Azure. 
Источник изображения: Unsplash Это позволит увеличить вычислительные мощности: компания OpenAI только в 2024 году намерена потратить на обучение ИИ-моделей и задачи инференса около $7 млрд. Вместе с тем, как отмечается, OpenAI пока отказалась от амбициозных планов по созданию собственного производства ИИ-чипов. Связано это с большими финансовыми и временными затратами, необходимыми для строительства предприятий.
18.10.2024 [00:10], Алексей Степин
Meta✴ представила свой вариант суперускорителя NVIDIA GB200 NVL72Meta✴ поделилась своими новинками в области аппаратной инфраструктуры и рассказала, каким именно видит будущее открытых ИИ-платформ. В своей презентации Meta✴ рассказала о новой ИИ-платформе, новых дизайнах стоек, включая варианты с повышенной мощностью питания, а также о новинках в области сетевой инфраструктуры. 
Источник изображений: Meta✴ В настоящее время компания использует нейросеть Llama 3.1 405B. Контекстное окно у этой LLM достигает 128 тыс. токенов, всего же токенов свыше 15 трлн. Чтобы обучать такие модели, требуются очень серьёзные ресурсы и глубокая оптимизация всего программно-аппаратного стека. В обучении базовой модели Llama 3.1 405B участвовал кластер 16 тыс. ускорителей NVIDIA H100, один из первых такого масштаба. Но уже сейчас для обучения ИИ-моделей Meta✴ использует два кластера, каждый с 24 тыс. ускорителей. Проекты такого масштаба зависят не только от ускорителей. На передний план выходят проблемы питания, охлаждения и, главное, интерконнекта. В течение нескольких следующих лет Meta✴ ожидает скоростей в районе 1 Тбайт/с на каждый ускоритель. Всё это потребует новой, ещё более плотной архитектуры, которая, как считает Meta✴, должна базироваться на открытых аппаратных стандартах.  Одной из новинок стала платформа Catalina. Это Orv3-стойка, сердцем которой являются гибридные процессоры NVIDIA GB200. Стойка относится к классу HPR (High Power Rack) и рассчитана на 140 КВт. Сейчас Microsoft и Meta✴ ведут работы над модульной и масштабируемой системой питания Mount Diablo. Свой вариант GB200 NVL72 у Microsoft тоже есть. Также Meta✴ обновила ИИ-серверы Grand Teton, впервые представленные в 2022 году. Это по-прежнему монолитные системы, но теперь они поддерживают не только ускорители NVIDIA, но и AMD Instinct MI300X и будущие MI325X.  Интерконнектом будущих платформ станет сеть DSF (Disaggregated Scheduled Fabric). Благодаря переходу на открытые стандарты компания планирует избежать ограничений, связанных с масштабированием, зависимостью от вендоров аппаратных компонентов и плотностью подсистем питания. В основе DSF лежит стандарт OCP-SAI и ОС Meta✴ FBOSS для коммутаторов. Аппаратная часть базируется на стандартном интерфейсе Ethernet/RoCE. Meta✴ уже разработала и воплотила в металл новые коммутаторы класса 51Т на базе кремния Broadcom и Cisco, а также сетевые адаптеры FBNIC, созданные при поддержке Marvell. FBNIC может иметь до четырёх 100GbE-портов. Используется интерфейс PCIe 5.0, причём могущий работать как четыре отдельных слайса. Новинка соответствует открытому стандарту OCP NIC 3.0 v1.2.0. |
|

