Финансовая фирма Bloomberg решила доказать, что существуют более разумные способы тонкой настройки ИИ-приложений, не имеющих проблем с соблюдением принципов этики или с безопасностью, с которыми сталкиваются при использовании, например, ChatGPT.
Bloomberg выпустила собственную большую языковую модель BloombergGPT с 50 млрд параметров, предназначенную для финансовых приложений. Она меньше ChatGPT, основанной на усовершенствованной версии GPT-3 со 175 млрд параметров. Но, как утверждают исследователи из Bloomberg и Johns Hopkins, малые модели — то что нужно для предметно-ориентированных приложений. Bloomberg заявила, что не будет открывать BloombergGPT из-за риска утечки конфиденциальных данных, например, из базы FINPILE, использовавшейся для обучения.

Источник изображения: Pixabay
По словам исследователей, BloombergGPT функционально схожа с ChatGPT, но предлагает большую точность, чем сопоставимые модели с бо́льшим количеством параметров. Они также утверждают, что общие модели не могут заменить предметно-ориентированные. Малые модели отличаются большей точностью результатов и могут обучаться значительно быстрее, чем универсальные модели, такие как GPT-3. К тому же для них требуется меньше вычислительных ресурсов.
Bloomberg потратила около 1,3 млн GPU-часов на обучение BloombergGPT на ускорителях NVIDIA A100 в облаке AWS. Обучение проводилось на 64 кластерах ускорителей, в каждом из которых было по восемь A100 (40 Гбайт), объединённых NVswitch. Для связи использовались 400G-подключения посредством AWS Elastic Fabric и NVIDIA GPUDirect Storage, а для хранения данных была задействована распределённая параллельная файловая система Lustre с поддержкой скорости чтения и записи до 1000 Мбайт/с.
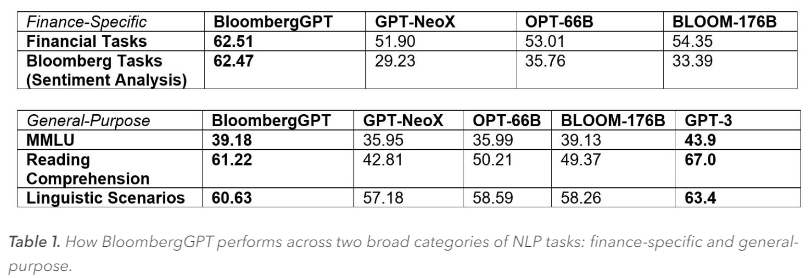
Источник: Bloomberg
Общего объёма памяти всех ускорителей оказалось недостаточно, поэтому Bloomberg произвела оптимизацию для обучения модели: разбиение на отдельные этапы, использование вычислений смешанной точности (BF16/FP32) и т.д. «После экспериментов с различными технологиями мы достигли [производительности] в среднем 102 Тфлопс, а каждый этап тренировки занимал 32,5 с», — сообщили исследователи.
Bloomberg задействовала чуть больше половины (54 %) имеющегося у неё набора данных — 363 млрд документов (с 2007 года) из внутренней базы данных Bloomberg. Остальные 345 млрд документов были получены из общедоступных пресс-релизов, новостей Bloomberg, публичных документов и даже Википедии. Документы получили название «токен». Исследователи стремились, чтобы обучающие последовательности имели длину 2048 токенов, чтобы поддерживать максимально высокий уровень использования ускорителей.
Источник:

