Американский производитель ИИ-комплексов Cerebras Systems объявил о выходе 7 больших языковых моделей (LLM) на базе технологии Generative Pre-trained Transformer (GPT) для генеративного ИИ. Это первые публичные LLM, которые прошли обучение с помощью систем CS-2 в суперкластере Cerebras Andromeda на базе фирменных ИИ-чипов Cerebras WSE-2. Другими словами, это одни из первых больших языковых моделей, которые были обучены без использования систем на основе ускорителей, в частности, NVIDIA.
Серия из семи открытых моделей GPT со 111, 256, 590 млн, а также 1,3, 2,7, 6,7 и 13 млрпд параметров соответственно доступны на GitHub и Hugging Face. Обучение таких моделей обычно занимает много месяцев, но Cerebras утверждает, что ей удалось справиться всего за несколько недель благодаря Andromeda. Более того, Cerebas удалось снизить стоимость обучения, а также упростить масштабирование без модификации кода и самой модели, что часто требуется при обучении с использованием кластеров традиционных ускорителей. При этом энергоэффективность всего процесса Cerebras смогла повысить.

Источник изображения: Cerebras Systems
Cerebras отметила, что не только предлагает модели, но и инструкции по их обучению под лицензией Apache 2.0. «Мы считаем, что для того, чтобы LLM были открытой и доступной технологией, важно иметь доступ к современным моделям, которые являются открытыми, воспроизводимыми и бесплатными как для исследовательских, так и для коммерческих приложений», — заявила Cerebras.

Источник изображения: Cerebras Systems
Компания заявила, что это первый случай, когда весь набор моделей GPT, обученных с использованием самых современных методов повышения эффективности, стал общедоступным. Поскольку большие языковые модели Cerebras имеют открытый исходный код, их можно использовать как в исследовательских, так и в коммерческих целях. А предварительно обученную модель можно с минимум затрат дообучить под конкретную задачу на пользовательских данных.
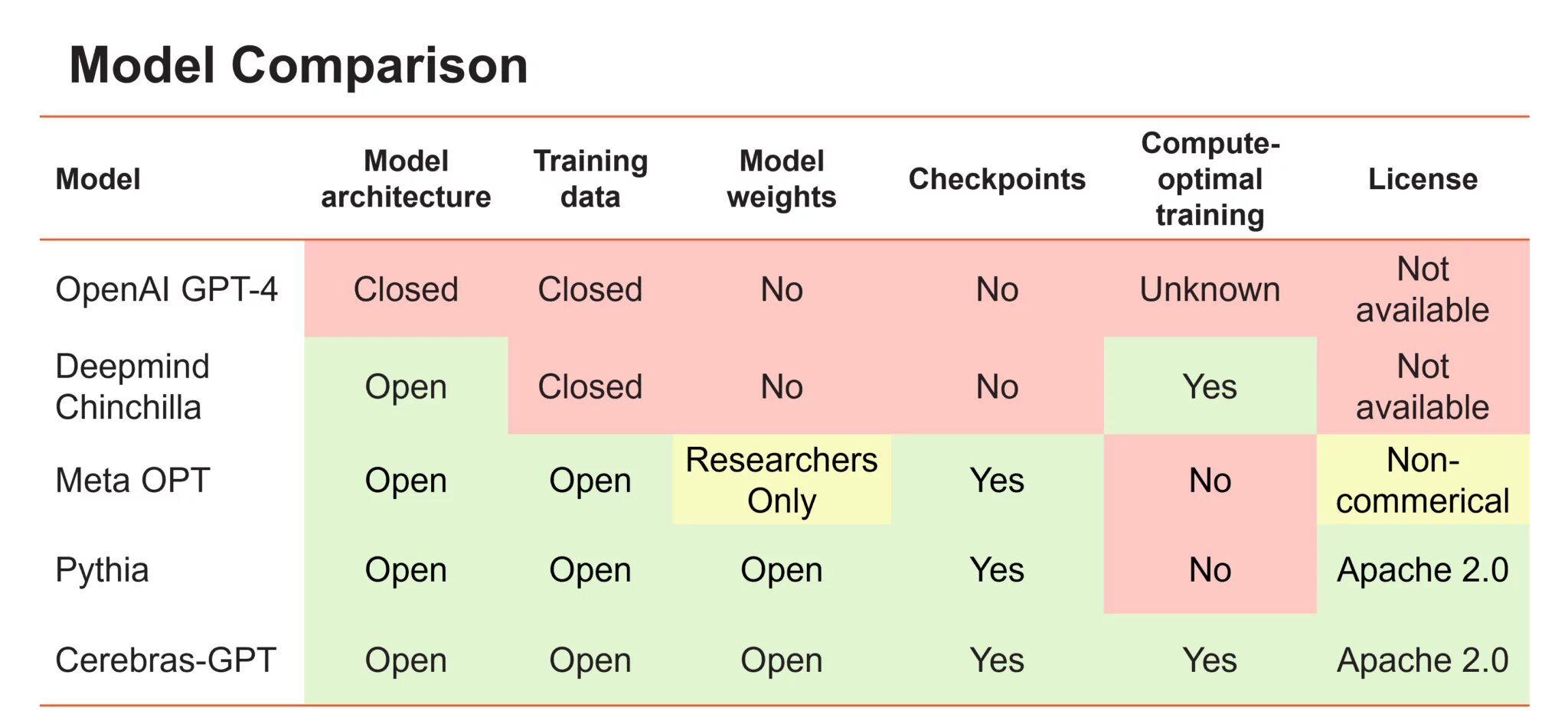
Источник изображения: Cerebras Systems
Cerebras отметила, что быстрый рост генеративного ИИ при лидерстве ChatGPT от OpenAI спровоцировал обострение состязания среди производителей ИИ-оборудования для ИИ, взявшихся за создание более мощных и специализированных чипов. Хотя многие из них обещали создать альтернативу ускорителям NVIDIA, пока никому из них не удалось продемонстрировать способность обучать крупномасштабные модели и желание раскрывать наработки под открытыми лицензиями.
По словам Cerebras, в связи с конкуренцией доступ к ИИ становится все более закрытым. Так, GPT4 была выпущена без детальной информации об архитектуре модели, параметрах, данных, оборудовании и т.д. Компании создают большие модели с использованием закрытых наборов данных и предлагают выходные данные моделей только через доступ к API.
Источники:

