Материалы по тегу: dpu
|
28.01.2024 [00:15], Сергей Карасёв
NVMe RAID для начинающих: Graid представила ускоритель SupremeRAID SR-1001 на базе GPU для восьми SSDКомпания Graid Technology анонсировала новый RAID-ускоритель на базе GPU для формирования NVMe-хранилищ. Решение под названием SupremeRAID SR-1001 ориентировано на edge-оборудование, серверы башенного типа, а также на рабочие станции. Новинка представляет собой упрощённую модификацию модели SupremeRAID SR-1000 на базе NVIDIA T1000. Допускается использование до восьми NVMe SSD в четырёх группах (против 32 накопителей у SR-1000). Карта имеет интерфейс PCIe 3.0 х16. Ускоритель допускает формирование массивов RAID 0/1/5/6/10. Величина IOPS (операций ввода/вывода в секунду) при произвольном чтении данных блоками по 4 Кбайт достигает 6 млн, при произвольной записи — 500 тыс. Заявленная скорость последовательного чтения составляет до 80 Гбайт/с, скорость последовательной записи — до 30 Гбайт/с. 
Источник изображения: Graid Карта SupremeRAID SR-1001 имеет однослотовое исполнение. Максимальное энергопотребление — 30 Вт. Применена система активного охлаждения. Заявлена совместимость с широким спектром программных платформ, включая Windows Server 2019/2022, Windows 11, RHEL 9.0/9.1, Ubuntu 22.04 (ядро 5.15), SLES 15 SP2/SP3 (ядро 5.3), Oracle Linux 9.1, Debian 11.6 (ядро 5.10), CentOS 8.5 (ядро 4.18) и др.
09.12.2023 [23:30], Сергей Карасёв
Pliops готовит новый СУБД-ускоритель XDP с удвоенной производительностьюКомпания Pliops в рамках конференции Gartner приоткрыла завесу тайны над ускорителем Extreme Data Processor (XDP) следующего поколения. По заявления разработчика, новинка обеспечит приблизительно двукратное увеличение производительности по сравнению с предшественником. Изделия XDP предназначены для ускорения широкого спектра приложений. Среди них названы реляционные базы данных, разнородные СУБД NoSQL, резидентные базы данных, платформы 5G и IoT, задачи ИИ и машинного обучения, а также другие системы с интенсивным использованием информации. Сервисы XDP Data, работающие на базе ускорителей XDP, как отмечает Pliops, позволяют операторам дата-центров максимизировать инвестиции в свои инфраструктуры благодаря экспоненциальному увеличению производительности и надёжности хранилища, а также улучшению общей эффективности. Утверждается, в частности, что решение XDP-AccelDB обеспечивает десятикратное повышение быстродействия СУБД MongoDB и снижение совокупной стоимости владения до 95 %. 
Источник изображения: Pliops Для администраторов Mongo DB и IT-специалистов платформа Pliops обеспечивает такие преимущества, как оптимизация ёмкости на уровне узла и кластера; экономически эффективная масштабируемость; оптимизация операций с базой данных, включая резервное копирование и восстановление; инфраструктура, отвечающая требованиям приложений и производительности. Ускорители Pliops XDP для MongoDB станут доступны в I квартале 2024 года. Компания Pliops также сообщила о сотрудничестве с Lenovo по выводу на рынок новых решений для работы с данными.
08.12.2023 [16:17], Сергей Карасёв
Marvell представила новые DPU серии Octeon 10Компания Marvell расширила семейство чипов Octeon 10, анонсировав изделия CN102 и CN103, которые относятся к классу DPU (Data Processing Unit). Новинки предназначены для построения высокопроизводительного сетевого оборудования, в частности, брандмауэров, маршрутизаторов, устройств SD-WAN, малых сот 5G, коммутаторов и пр. Представленные чипы объединяют до восьми 64-битных ядер Arm Neoverse N2 с частотой до 2,7 ГГц. Объём кеш-памяти L2/L3 составляет 8/16 Мбайт. Заявлена поддержка DDR5-5600 и интерфейсов PCIe 3.0 (у CN102) и PCIe 5.0 (только CN103). Изделия производятся по 5-нм техпроцессу. Утверждается, что они обеспечивают в три раза более высокую производительность по сравнению с решениями Marvell DPU предыдущего поколения при одновременном снижении энергопотребления на 50 % — до 25 Вт. Чипы могут применяться в качестве разгрузочного сопроцессора или в качестве основного процессора в сетевых устройствах. 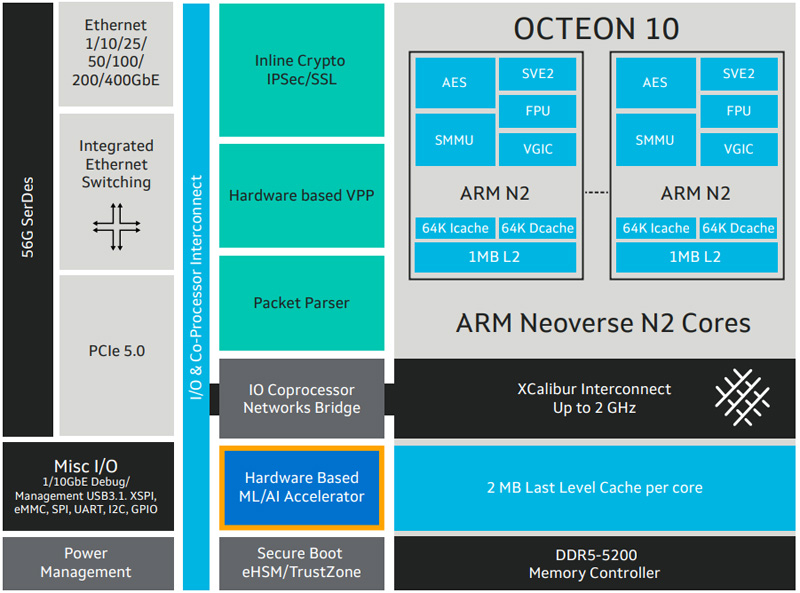
Источник изображения: Marvell Модель CN102 имеет поддержку сетевых портов в следующей конфигурации: 4 × 10GbE + 2 × 10GbE или 16 × 1GbE. У версии CN103 схема такова: 4 × 50/25/10GbE + 2 × 10GbE или 16 × 1GbE. Энергопотребление составляет соответственно 10–20 Вт и 10–25 Вт. Старшая версия получила SerDes-блоки 56G. Среди прочего упомянуты аппаратное ускорение пакетов с оптимизацией VPP, поддержка IPsec и Secure Boot. Показатель SPECint (2017) достигает 37. Поставки образов Octeon 10 CN102 и CN103 уже начались, а массовое производство запланировано на IV квартал 2023-го и на I четверть 2024 года соответственно.
26.11.2023 [22:48], Сергей Карасёв
Nebulon представила ускорители Medusa2 на базе DPU NVIDIA BlueField-3Компания Nebulon анонсировала специализированные ускорители обработки сервисов (Services Processing Unit, SPU) — устройства серии Medusa2. Эти решения обеспечивают разгрузку, ускорение и изоляцию широкого спектра процессов в работе сети, СХД и подсистемы безопасности, включая обнаружение программ-вымогателей. В основу Medusa2 лёг DPU BlueField-3 разработки NVIDIA с шестнадцатью ядрами Arm Cortex-A78, тогда как первое поколение укорителей, изначально называвшихся Storage Processing Unit, было выполнено на собственной аппаратной платформе. Nebulon Medusa2 представляют собой карты расширения с интерфейсом PCIe 5.0 (х8). Они оснащены 48 Гбайт памяти DDR5 с пропускной способностью до 80 Гбайт/с. SPU подключается напрямую к внутренним накопителям NVMe (а также SAS и SATA). Ускорители оснащены двумя сетевыми портами 10/25/50/100GbE и портом управления 1GbE. 
Источник изображения: Nebulon SPU создает на сервере безопасную зону, отделённую от ОС и приложений — область Nebulon Secure Enclave. При этом платформа nebOS разгружает ресурсы, беря на себя выполнение таких задач, как дедупликация и сжатие данных, шифрование (AES), моментальные снимки, зеркалирование и пр. Обеспечена интеграция со средами VMware vSphere, Microsoft Server/Hyper-V и Linux/KVM. Medusa2 SPU не зависит от ОС и приложений и не требует установки каких-либо дополнительных драйверов или программных агентов. Предусмотрен криптографический сопроцессор со сверхзащищенным аппаратным хранилищем ключей и криптографическими контрмерами, которые усиливают защиту от любых потенциальных угроз, связанных с ПО. Например, обнаружение программ-вымогателей осуществляется менее чем за 2,5 мин., а на восстановление после атак таких зловредов требуется менее 4 мин. Реализованы средства безопасной загрузки. В целом, компания сравнивает свои SPU с AWS Nitro. Также анонсирован компактный ускоритель Medusa2i для edge-серверов. Он, как и старший собрат, использует DPU BlueField-3, но количество ядер Cortex-A78 уменьшено до 8, а объём памяти DDR5 — до 24 Гбайт. Возможна установка четырёх SSD формата M.2 вместимостью до 32 Тбайт каждый. Утверждается, что благодаря Medusa2 количество рабочих нагрузок на один сервер может быть увеличено на 33 %, что снижает эксплуатационные расходы и затраты на приобретение лицензий на ПО. При этом требования к мощности и площади дата-центра снижаются на 25 %. Интерес к ускорителям проявили Dell, HPE, Lenovo и Supermicro.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для гипермасштабируемых ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
19.10.2023 [01:40], Алексей Степин
Axiado представила новый класс сопроцессоров — TCUНа мероприятии 2023 OCP Global Summit компания Axiado представила новый класс аппаратных сопроцессоров — TCU (Trusted Control/Compute Unit), предназначенный для управления и защиты IT-инфраструктуры от различного рода атак. Защитных механик в мире ИТ существует множество, но и киберпреступники постоянно совершенствуют методы атак, задействуя порой самые экзотические атак по сторонним каналам, к примеру, используя механизмы динамического управления напряжением и частотой в современных процессорах. Не всегда спасает положение даже подход «нулевого доверия» (Zero Trust), поскольку программная реализация также уязвима ко взлому или утере ключей. 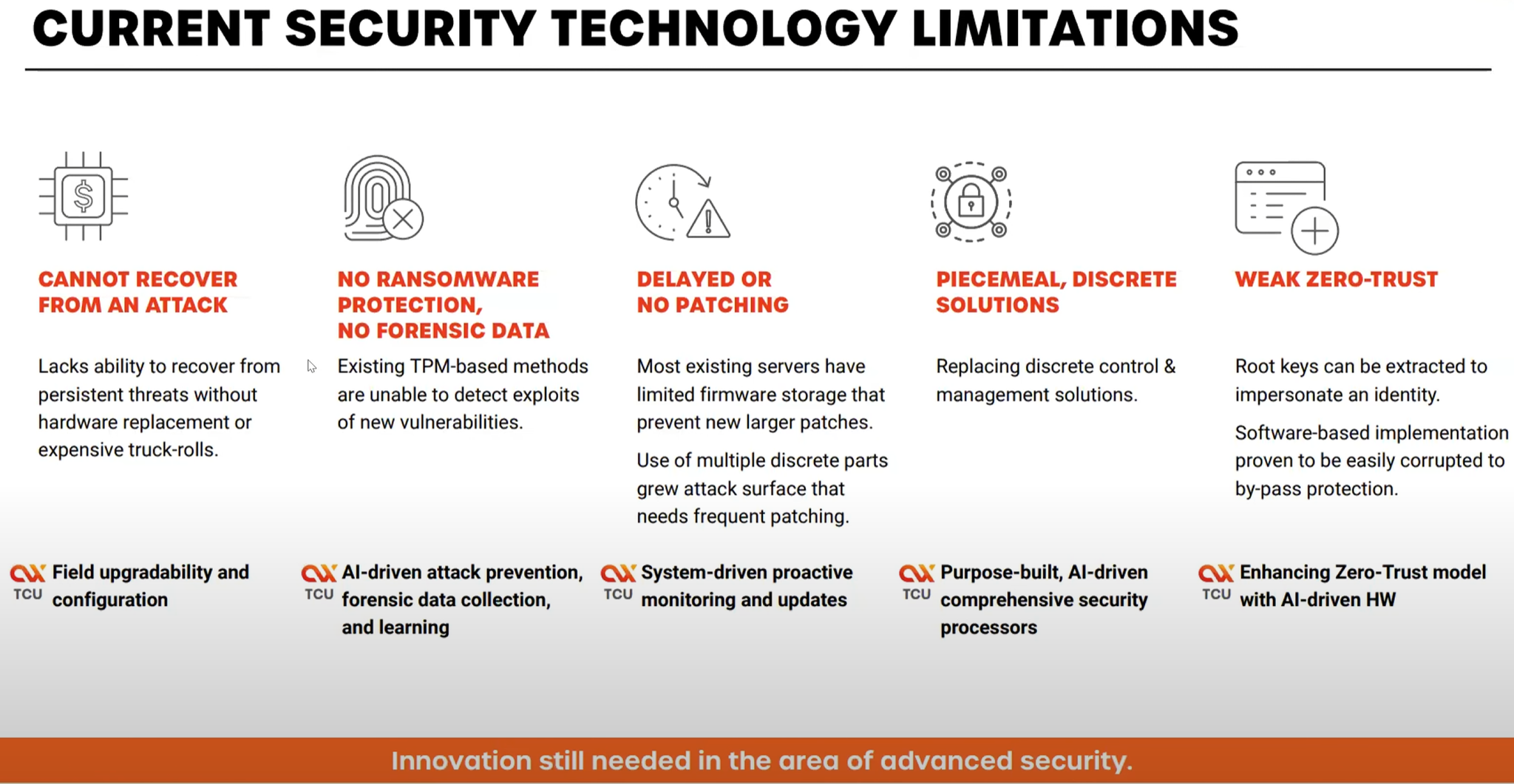
Источник изображений здесь и далее: OCP/Axiado 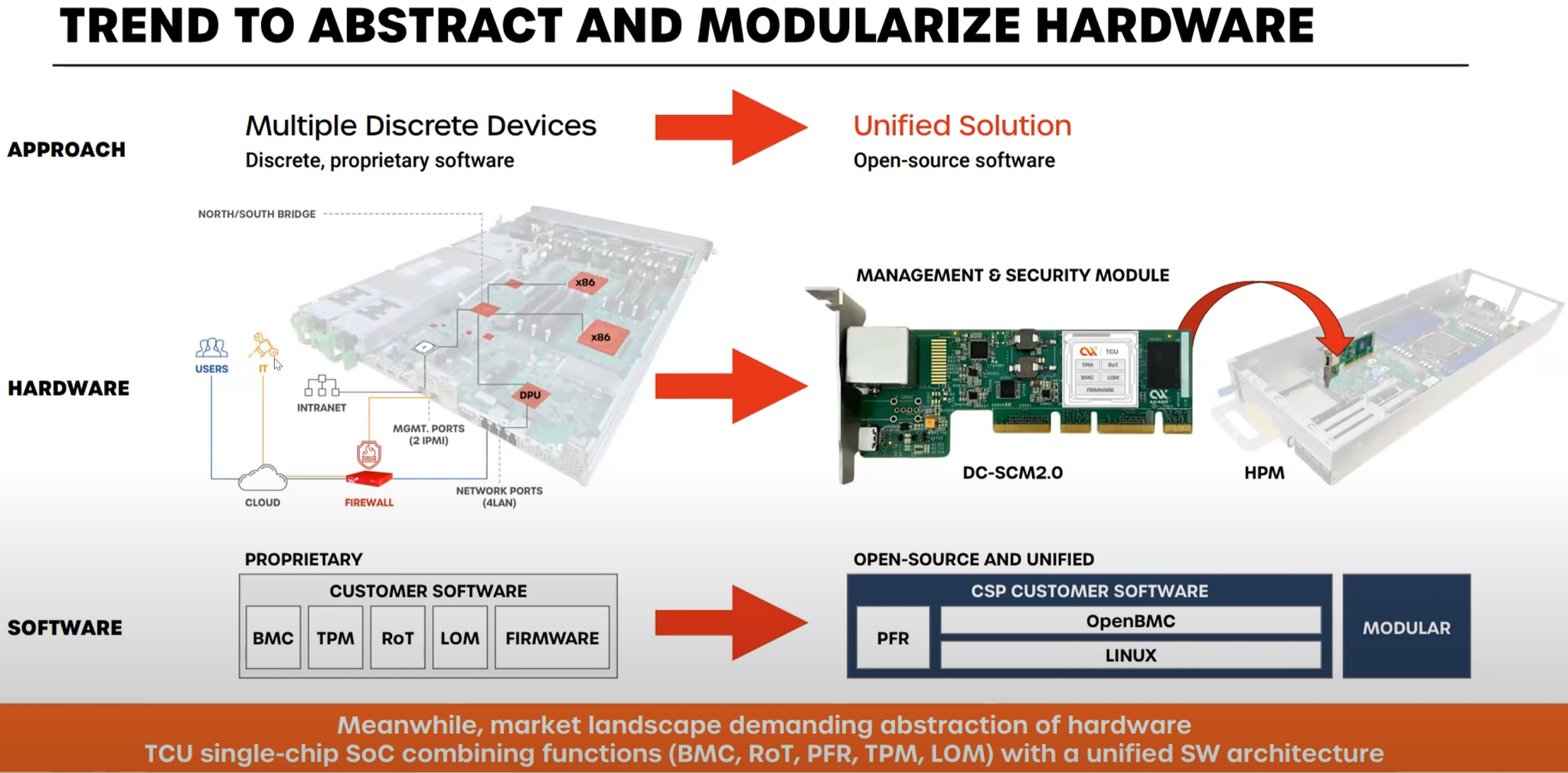 Решение Axiado — аппаратный контроль в реальном времени, использующий ИИ, который позволяет предсказывать и предотвращать разного рода атаки, дообучаясь в процессе. Последнее, по мнению компании, быть на шаг впереди злоумышленников и предотвращать возможный взлом ещё на этапе первых подозрительных действий, производимых в системе. Чипы серии AX2000/3000 способны выполнять и другие функции: Platform Root of Trust, BMC или TPM. При этом предполагается использование модульной и открытой программной архитектуры на основе PFR (Platform Firmware Resilence) и OpenBMC.  Чипы Axiado AX2000/3000 содержат четыре инференс-движка общей мощностью 4 Топс, четыре ядра общего назначения Arm Cortex A53, а также модули доверенного и привилегированного исполнения, блок брандмауэра и криптодвижок. Большая часть модулей решения Axiado работает под управлением открытой ОС реального времени Zephyr. Клиент легко может доработать платформу собственными модулями. 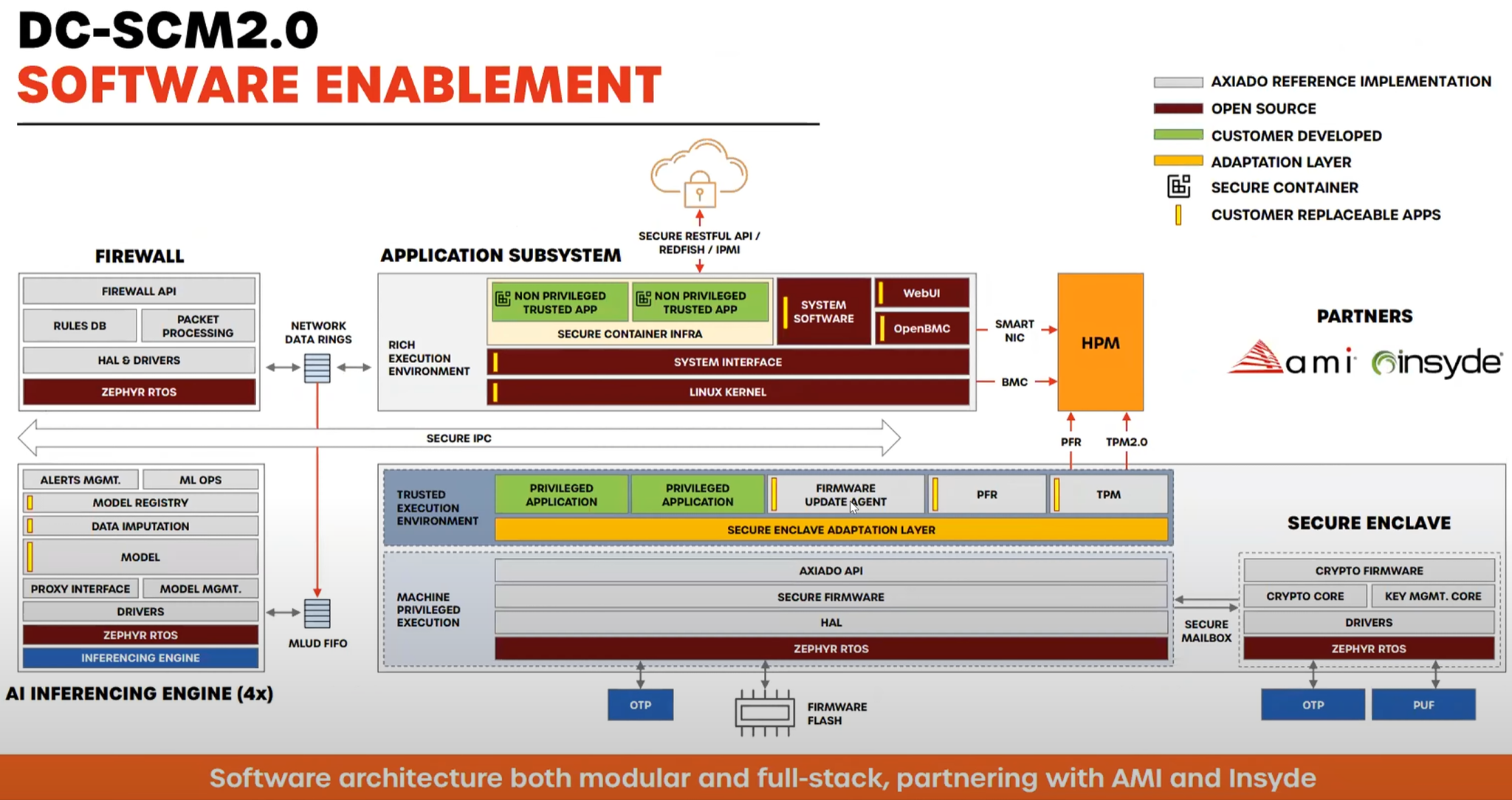 Axiado активно сотрудничает с OCP и уже разработала несколько вариантов адаптеров на базе TCU для продвигаемых консорциумом серверных форм-факторов. В портфолио компании представлены адаптеры DC-SCM 2.0 (Secure Control Module) как в вертикальном, так и в горизонтальном форм-факторах, а также в виде классического PCIe-адаптера NCM (Network Compute Module).  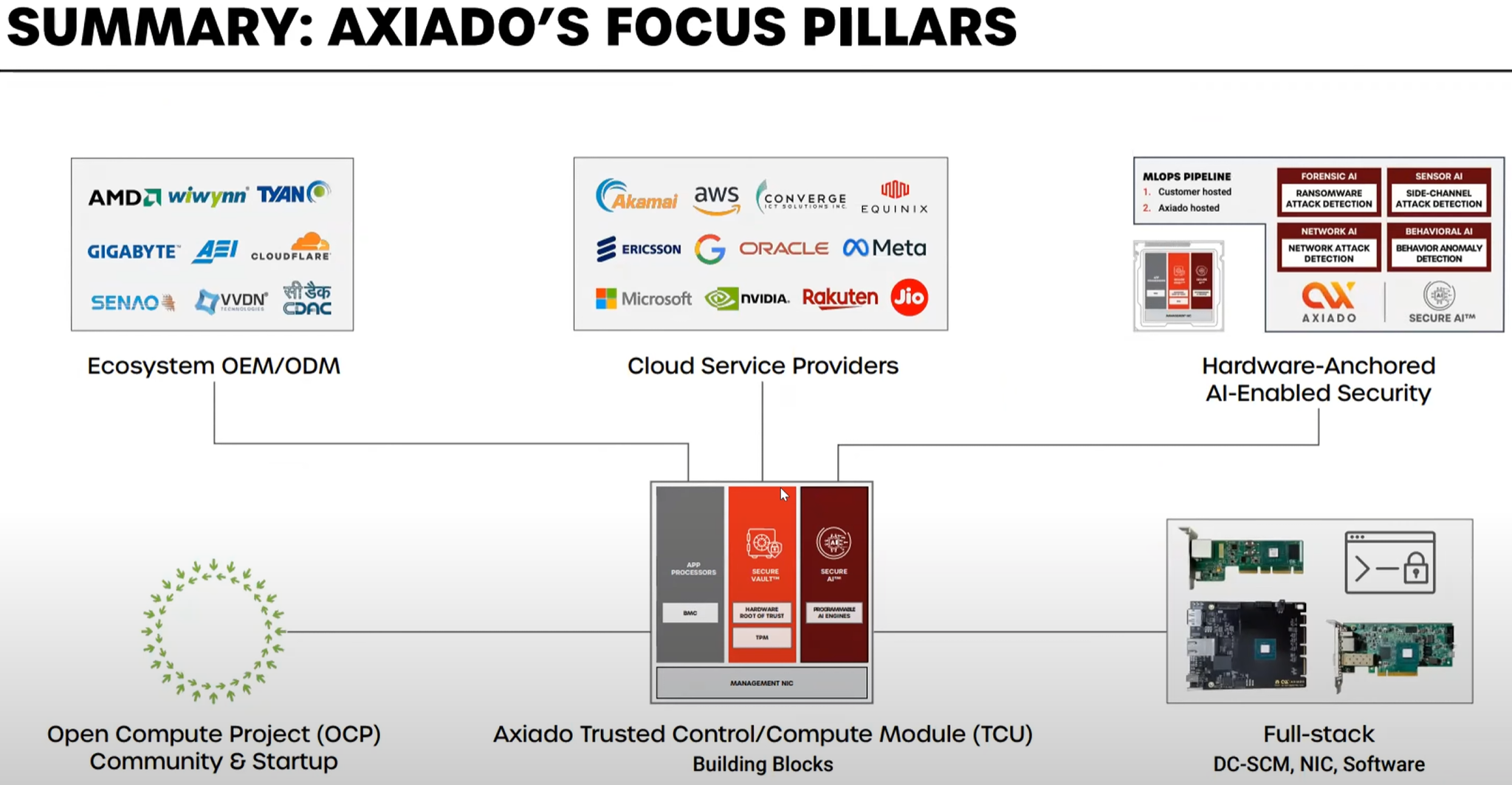 Компания уже успела договориться о сотрудничестве с GIGABYTE, VVDN, Wiwynn, Senao и Tyan. Но этим список партнёров Axiado не ограничивается: в её решениях заинтересованы также крупные облачные провайдеры, включая AWS, Microsoft, Google и Meta✴, а также ряд других компаний и системных интеграторов.
21.07.2023 [23:10], Алексей Степин
Microsoft предлагает протестировать DPU MANA с Azure BoostКрупные облачные провайдеры давно осознали пользу, которую могут принести DPU и активно применяют подобного рода решения. В частности, AWS давно использует платформу Nitro, Google разработала DPU при поддержке Intel, а Microsoft активно готовит к запуску собственную платформу под названием MANA. Основой MANA является кастомный чип SoC, разработанный специально с учётом обеспечения высокой пропускной способности, стабильности подключения и низкой латентности. DPU на его основе обеспечивает пропускную способность до 200 Гбит/с, а также поддерживает подключение удалённого хранилища данных на скоростях до 10 Гбайт/с при производительности до 400 тыс. IOPS. Отметим, что ранее AMD заявила о появлении DPU Pensando в облаке Azure, а сама Microsoft в прошлом году поглотила разработчика DPU Fungible. 
Изображение: Microsoft MANA является частью услуги Azure Boost и берёт на себя управление всеми аспектами виртуализации, включая работу с сетью и данными, а также функции управления хост-системой. Перенос этих функций на отдельную платформу не просто улучшает производительность и масштабируемость, но и обеспечивает дополнительный слой безопасности. MANA уже задействованы в инфраструктуре Azure и подтвердили высочайшую скорость при работе с внешними хранилищами данных для инстансов Ebsv5, а также отличную пропускную способность и низкую латентность сетевого канала для всех инстансов семейств Ev5 и Dv5. MANA поддерживает Windows и Linux, а для более тонкой работы с аппаратной частью ускорителя можно задействовать DPDK. В части информационной безопасности следует отметить наличие криптоядра, соответствующего стандартам FIPS 140. В настоящее время сервис Azure Boost доступен в качестве превью. Компания приглашает к сотрудничеству партнёров и клиентов с высокими запросами к характеристикам сетевого канала и хранилищ.
22.06.2023 [17:04], Алексей Степин
NVIDIA AX800: ИИ-сервер для 5G в форм-факторе PCIe-картыВ форм-факторе плат расширения PCIe существует множество устройств, включая, к примеру, маршрутизаторы. Но NVIDIA AX800 выводит это понятие на новый уровень — здесь плата расширения являет собой полноценный высокопроизводительный сервер. Плата включает DPU BlueField-3, который располагает 16 ядрами Cortex Arm-A78, дополненных 32 Гбайт RAM, а также ускоритель A100 (80 Гбайт). Новинкая является наследницей карты A100X, но с гораздо более производительным DPU. 
Источник изображений здесь и далее: NVIDIA На борту также имеется eMMC объёмом 40 Гбайт, два 200GbEпорта (QSFP56). Плата выполнена в форм-факторе FHFL, имеет пассивное охлаждение и предельный теплопакет 350 Вт. Дополнительно предусмотрен порт 1GbE для удалённого управления для BMC ASPEED AST2600, так что речь действительно идёт о полноценном сервере. На PCB имеются гребёнки разъёмов NVLink — данное решение может работать не в одиночку, а в составе высокоплотного многопроцессорного сервера. 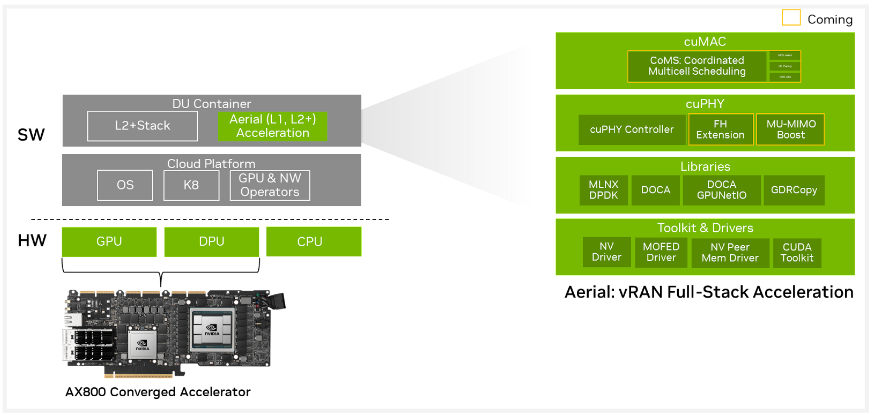
NVIDIA AX800 позволяет построить полностью ускоряемый стек 5G vRAN NVIDIA позиционирует новинку как решение для систем 5G vRAN, но также она может найти место и в высокоплотных системах периферийных системах для ИИ-задач. В качестве программной платформы предлагается Aerial 5G vRAN. Плата ускоряет обработку L1/L2-трафика 5G и способна предложить до 36,56 и 4,794 Гбит/с нисходящей и восходящей пропускной способности (4T4R). Платформа поддерживает масштабирование от 2T2R до 64T64R (massive MIMO). А поддержка MIG позволяет гибко перераспределять нагрузки ИИ и 5G.
18.06.2023 [21:42], Алексей Степин
Kalray подготовила DPU Coolidge 2 третьего поколенияКомпания Kalray, один из разработчиков сетевых сопроцессоров (DPU), сообщила о реализации в кремнии чипов Coolidge 2, которые относятся к третьему поколению фирменной архитектуры MPPA. Предыдущие решения компании успели прописаться в СХД Viking и Wistron, а также в облаке Scaleway. Компания позиционирует Coolidge 2 в качестве решения для всевозможных ИИ-систем, которые переживают сейчас бурный расцвет. 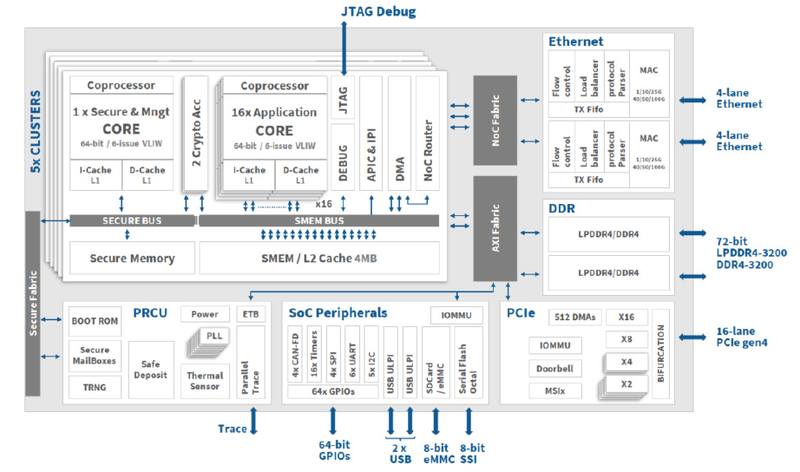
Архитектура Kalray Coolidge. Источник здесь и далее: Kalray Впрочем, данных о третьем поколении MPPA немного. В новостях компания сообщает лишь о существенной оптимизации всех компонентов чипа и заявляет, что такая оптимизация позволила ускорить процессор практически на порядок. Первые опытные партии Coolidge 2 будут доступны уже этим летом. Это важное событие для европейского рынка HPC и ИИ-вычислений, поскольку Kalray — единственный достаточно крупный игрок в этом регионе, предлагающий собственное энергоэффективное, но при этом производительное DPU-решение. В настоящее время уже начаты опытные работы по созданию чипа MPPA четвёртого поколения. 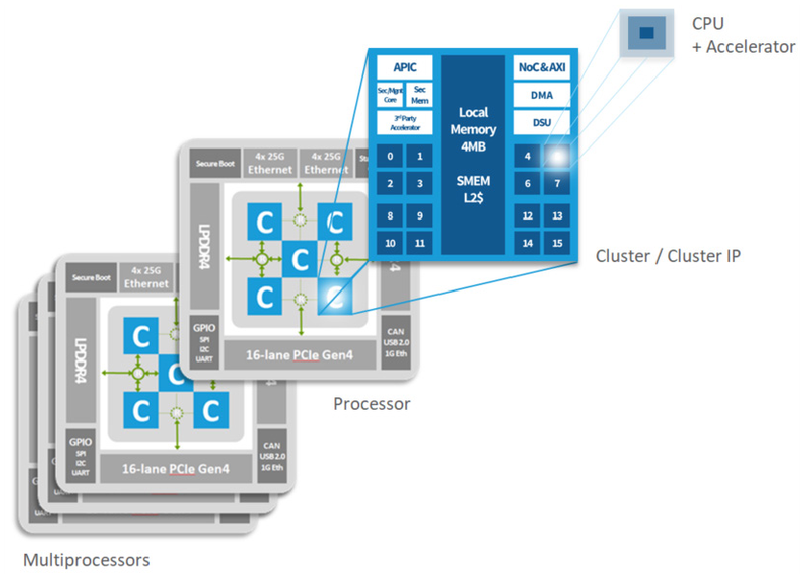
Структура мультипроцессорных ядер в Coolidge Дела у Kalray идут неплохо, особенно на фоне некоторой депрессивности IT-рынка в целом. В 2022 году компания приобрела активы Arcapix Holdings в области технологий хранения данных, что позволило ей создать законченный пул DPU-решений. За прошедший год количество сотрудников Kalray возросло на 74 %; ещё на 20 % оно должно вырасти в этом году. |
|

