Материалы по тегу: nvidia
|
29.12.2024 [17:40], Владимир Мироненко
Конструктор вместо монолита: NVIDIA дала больше свободы в кастомизации GB300 NVL72Для новых суперускорителей (G)B300 компания NVIDIA существенно поменяла цепочку поставок, сделав её более дружелюбной к гиперскейлерам, то есть основным заказчиком новинок, передаёт SemiAnalysis. В случае GB200 компания поставляла готовые, полностью интегрированные платы Bianca, включающие ускорители Blackwell, CPU Grace, 512 Гбайт напаянной LPDDR5X, VRM и т.д. GB300 будут поставляться в виде модулей: SXM Puck B300, CPU Grace в корпусе BGA, HMC от Axiado (вместо Aspeed). А в качестве системной RAM будут применяться модули LPCAMM, преимущественно от Micron. Переход на SXM Puck даст возможность создавать новые системы большему количеству OEM- и ODM-поставщиков, а также самим гиперскейлерам. Если раньше только Wistron и Foxconn могли производить платы Bianca, то теперь к процессу сборки ускорителей могут подключиться другие. Wistron больше всех потеряет от этого решения, поскольку потеряет долю рынка производителей Bianca. Для Foxconn же, которая благодаря NVIDIA вот-вот станет крупнейшим в мире поставщиком серверов, потеря компенсируется эксклюзивным производством SXM Puck. 
Источник изображений: NVIDIA Еще одно важное изменение касается VRM. Хотя на SXM Puck есть некоторые компоненты VRM, большая часть остальных комплектующих будет закупаться гиперскейлерами и вендорами напрямую у поставщиков VRM. Стоечные NVSwitch-коммутаторы и медный backplane по-прежнему будут поставляться самой NVIDIA. Для GB300 компания предлагает 800G-платформу InfiniBand/Ethernet Quantum-X800/Spectrum-X800 с адаптерами ConnectX-8, которые не попали GB200 из-за нестыковок в сроках запуска продуктов. Кроме того, у ConnectX-8 сразу 48 линий PCIe 6.0, что позволяет создавать уникальные архитектуры, такие как MGX B300A с воздушным охлаждением.  Сообщается, что все ключевые гиперскейлеры уже приняли решение перейти на GB300. Частично это связано с более высокой производительностью и экономичностью GB300, но также вызвано и тем, что теперь они сами могут кастомизировать платформу, систему охлаждения и т.д. Например, Amazon сможет, наконец, использовать собственную материнскую плату с водяным охлаждением и вернуться к архитектуре NVL72, улучшив TCO. Ранее компания единственная из крупных игроков выбрала менее эффективный вариант NVL36 из-за использования собственных 200G-адаптеров и PCIe-коммутаторов с воздушным охлаждением. Впрочем, есть и недостаток — гиперскейлерам придётся потратить больше времени и ресурсов на проектирование и тестирование продукта. Это, пожалуй, самая сложная платформа, которую когда-либо приходилось проектировать гиперскейлерам (за исключением платформ Google TPU), отметил ресурс SemiAnalysis.
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 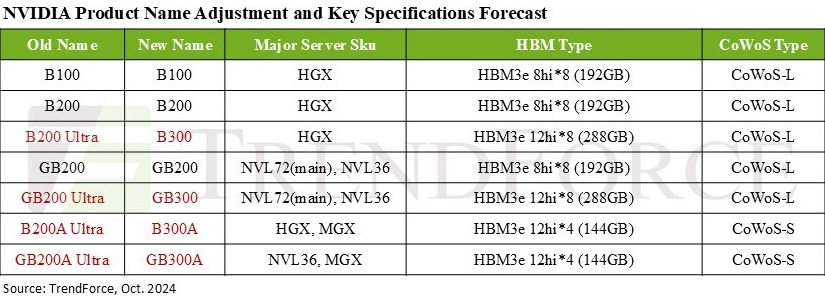
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
26.12.2024 [16:50], Руслан Авдеев
Equinix предложил ИИ-фабрики на базе систем Dell с ускорителями NVIDIAОператор ЦОД Equinix совместно с Dell Technologies предложил частные ИИ-облака на базе Dell AI Factory. Использование комплекса Dell AI Factory with NVIDIA в ЦОД IBX позволяет комбинировать различные продукты, решения и сервисы на нейтральной площадке, где клиенты смогут безопасно и экономически эффективно объединить ресурсы публичных облаков, колокейшн-объектов, а также собственных облачных и локальных инфраструктур. Dell AI Factory with NVIDIA включает серверы Dell PowerEdge XE9680 с ускорителями NVIDIA, Ethernet-решения NVIDIA Spectrum-X и BlueField-3, а также СХД Dell PowerScale F710. Кроме того, будут доступны и 4U-серверы PowerEdge XE9680L, поддерживающие до восьми новейших ускорителей NVIDIA Blackwell. Решение будет доступно в более чем 260 ЦОД Equinix IBX. В Equinix объявили, что намерены обеспечить клиентов передовой ИИ-инфраструктурой, отвечающей самым высоким стандартам производительности, безопасности и надёжности, а сотрудничество с Dell и NVIDIA позволит использовать максимум ресурсов систем генеративного ИИ, сохраняя контроль над данными и поддерживая собственные корпоративные цели достижения экоустойчивости. 
Источнки изображения: Dell Наличие площадок Equinix в более 70 мегаполисах мира, время бесперебойной работы 99,999 %, масштабируемость проектов и сотрудничество с тысячами сетей и провайдеров, а также обеспечение ЦОД на 96 % возобновляемой энергией (100 % на ключевых рынках) в сочетании с платформой Dell AI Factory with NVIDIA, которая уже доступна в ЦОД Equinix в большинстве регионов мира, позволит заказчикам повысить удобство, безопасность и экологичность работы с генеративным ИИ.
25.12.2024 [01:00], Владимир Мироненко
Гладко было на бумаге: забагованное ПО AMD не позволяет раскрыть потенциал ускорителей Instinct MI300XАналитическая компания SemiAnalysis опубликовала результаты исследования, длившегося пять месяцев и выявившего большие проблемы в ПО AMD для работы с ИИ, из-за чего на данном этапе невозможно в полной мере раскрыть имеющийся у ускорителей AMD Instinct MI300X потенциал. Проще говоря, из-за забагованности ПО AMD не может на равных соперничать с лидером рынка ИИ-чипов NVIDIA. При этом примерно три четверти сотрудников последней заняты именно разработкой софта. Как сообщает SemiAnalysis, из-за обилия ошибок в ПО обучение ИИ-моделей с помощью ускорителей AMD практически невозможно без значительной отладки и существенных трудозатрат. Более того, масштабирование процесса обучения как в рамках одного узла, так и на несколько узлов показало ещё более существенное отставание решения AMD. И пока AMD занимается обеспечением базового качества и простоты использования ускорителей, NVIDIA всё дальше уходит в отрыв, добавляя новые функции, библиотеки и повышая производительность своих решений, отметили исследователи. 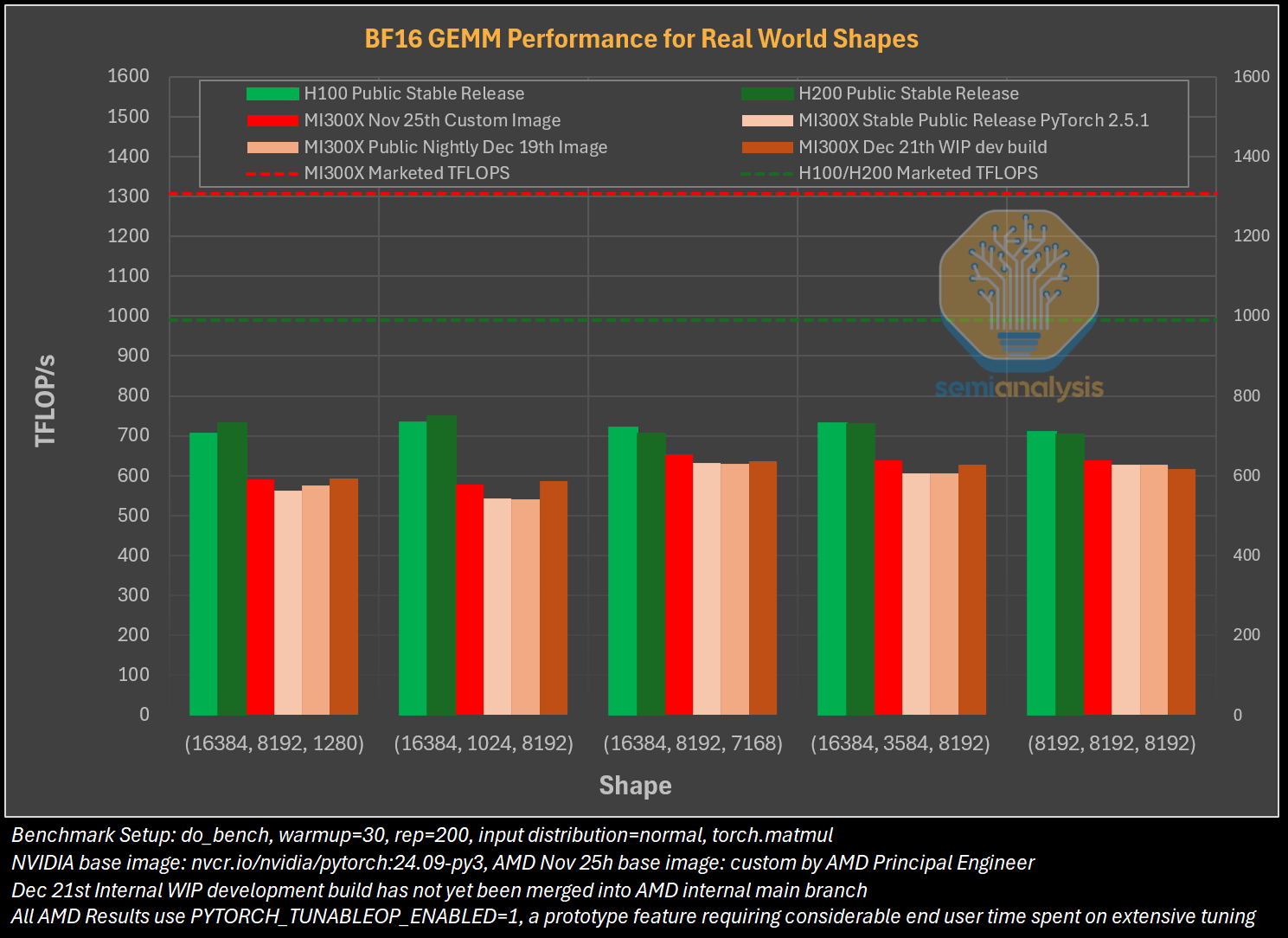
Источник изображений: SemiAnalysis На бумаге чип AMD Instinct MI300X выглядит впечатляюще с FP16-производительностью 1307 Тфлопс и 192 Гбайт памяти HBM3 в сравнении с 989 Тфлопс и 80 Гбайт памяти у NVIDIA H100. К тому же чипы AMD предлагают более низкую общую стоимость владения (TCO) благодаря более низким ценам и использованию более дешёвого интерконнекта на базе Ethernet. Но проблемы с софтом сводят это преимущество на нет и не находят реализации на практике. При этом исследователи отметили, что в NVIDIA H200 объём памяти составляет 141 Гбайт, что означает сокращение разрыва с чипами AMD по этому параметру. Кроме того, внутренняя шина xGMI лишь формально обеспечивает пропускную способность 448 Гбайт/с для связки из восьми ускорителей MI300X. Фактически же P2P-общение между парой ускорителей ограничено 64 Гбайт/с, тогда как для объединения H100 используется NVSwitch, что позволяет любому ускорителю общаться с другим ускорителем на скорости 450 Гбайт/с. А включённый по умолчанию механизм NVLink SHARP делает часть коллективных операций непосредственно внутри коммутатора, снижая объём передаваемых данных. 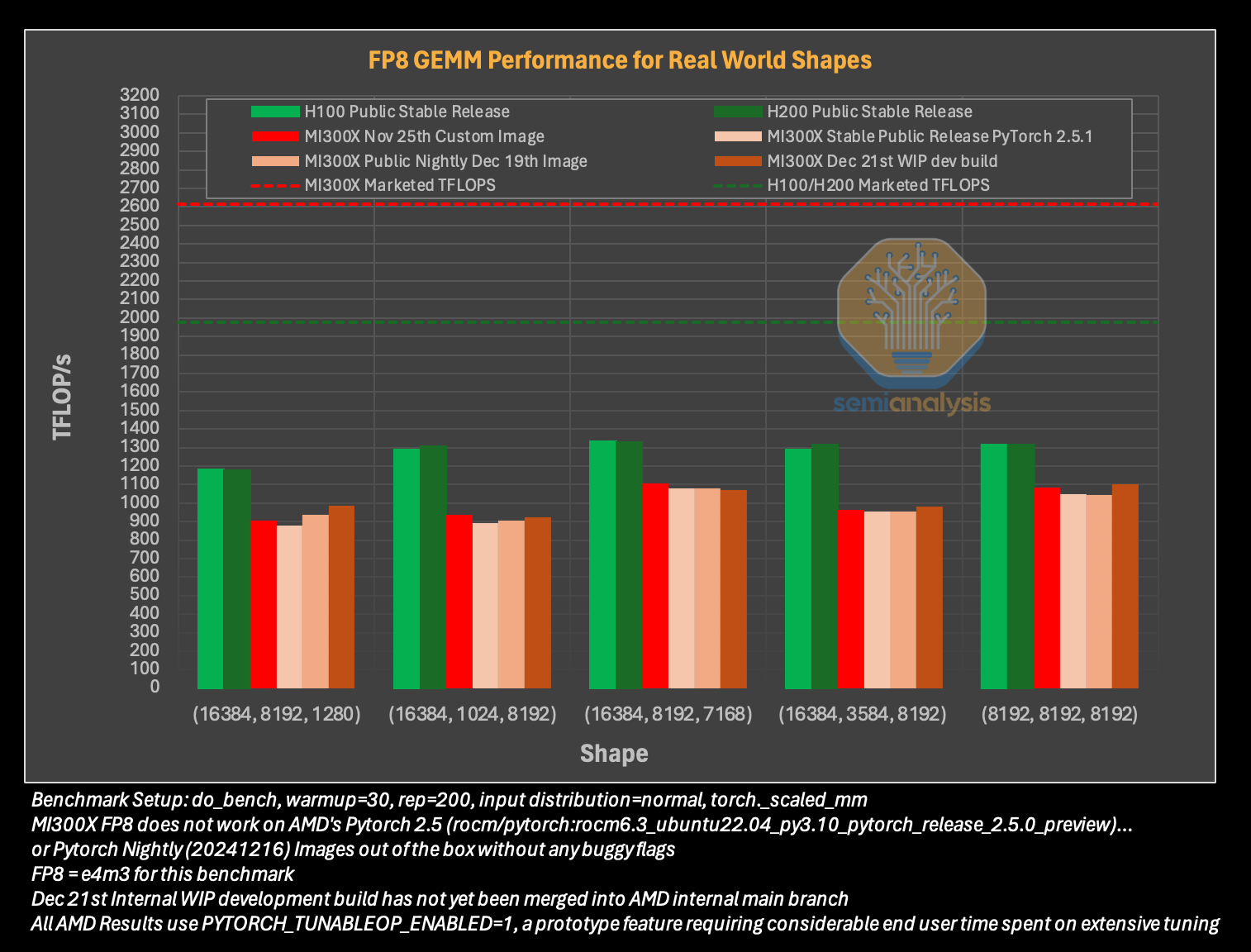 Как отметили в SemiAnalysis, сравнение спецификаций чипов двух компаний похоже на «сравнение камер, когда просто сверяют количество мегапикселей», и AMD просто «играет с числами», не обеспечивая достаточной производительности в реальных задачах. Чтобы получить пригодные для аналитики результаты тестов, специалистам SemiAnalysis пришлось работать напрямую с инженерами AMD над исправлением многочисленных ошибок, в то время как системы на базе NVIDIA работали сразу «из коробки», без необходимости в дополнительной многочасовой отладке и самостоятельной сборке ПО. В качестве показательного примера SemiAnalysis рассказала о случае, когда Tensorwave, крупнейшему провайдеру облачных вычислений на базе ускорителей AMD, пришлось предоставить целой команде специалистов AMD из разных отделов доступ к оборудованию с её же ускорителями, чтобы те устранили проблемы с софтом. Обучение с использованием FP8 в принципе не было возможно без вмешательства инженеров AMD. Со стороны NVIDIA был выделен только один инженер, за помощью к которому фактически не пришлось обращаться. 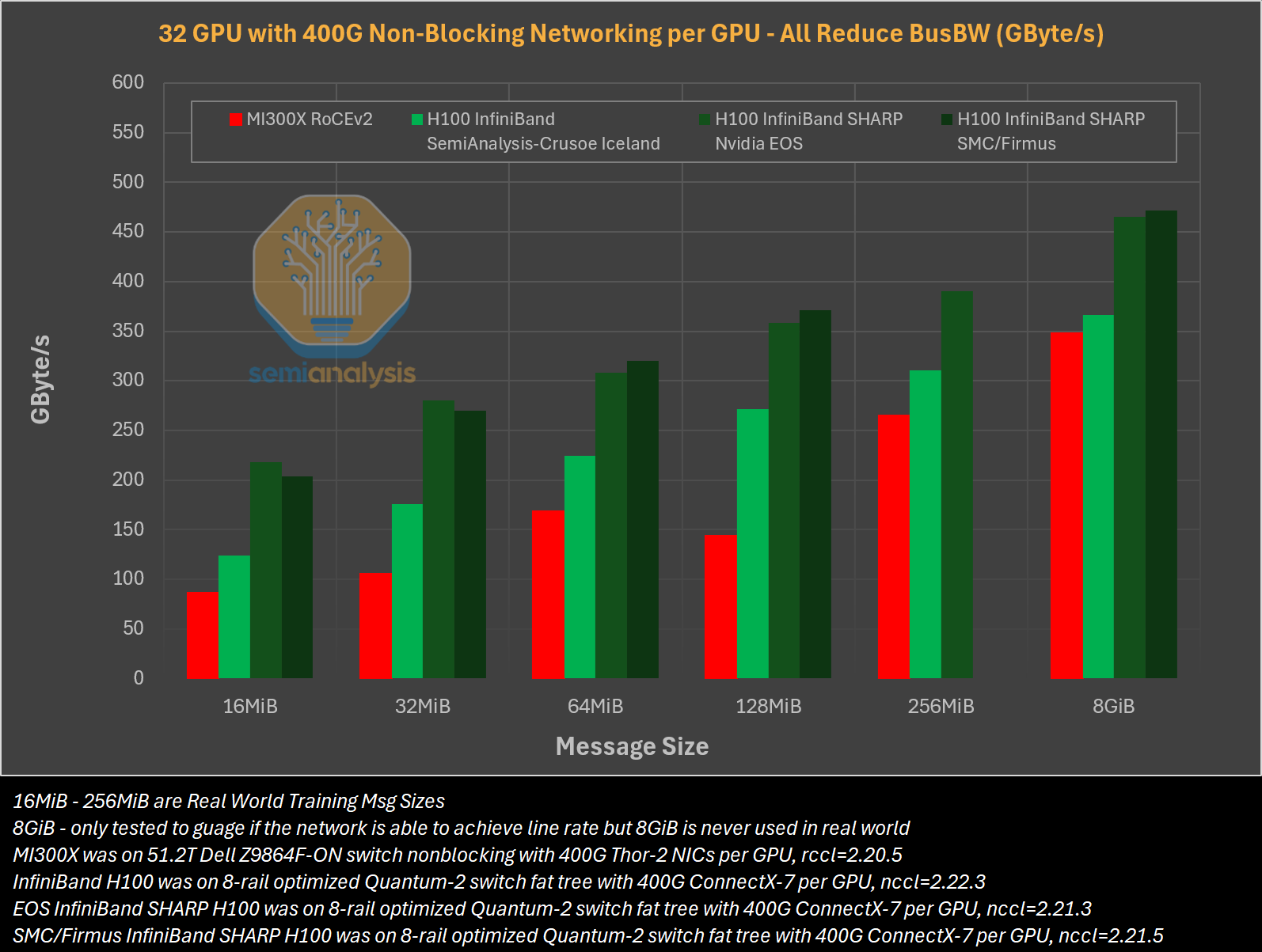 У AMD есть лишь один выход — вложить значительные средства в разработку и тестирование ПО, считают в SemiAnalysis. Аналитики также предложили выделить тысячи чипов MI300X для автоматизированного тестирования, как это делает NVIDIA, и упростить подготовку окружения, одновременно внедряя лучшие настройки по умолчанию. Проблемы с ПО — основная причина, почему AMD не хотела показывать результаты бенчмарка MLPerf и не давала такой возможности другим. В SemiAnalysis отметили, что AMD предстоит немало сделать, чтобы устранить выявленные проблемы. Без серьёзных улучшений своего ПО AMD рискует еще больше отстать от NVIDIA, готовящей к выпуску чипы Blackwell следующего поколения. Для финальных тестов Instinct использовался специально подготовленный инженерами AMD набор ПО, который станет доступен обычным пользователям лишь через один-два квартала. Речь не идёт о Microsoft или Meta✴, которые самостоятельно пишут ПО для Instinct. Один из автором исследования уже провёл встречу с главой AMD Лизой Су (Lisa Su), которая пообещала приложить все усилия для исправления ситуации.
21.12.2024 [14:00], Сергей Карасёв
Еврокомиссия разрешила NVIDIA купить израильский стартап Run:aiЕвропейская комиссия одобрила сделку по приобретению компанией NVIDIA стартапа Run:ai из Тель-Авива (Израиль), который специализируется на разработке ПО для управления рабочими нагрузками ИИ и оркестрации на базе Kubernetes. Регуляторы пришли к выводу, что слияние не создаст проблем с конкуренцией в Европейской экономической зоне. Стартап Run:ai основан в 2018 году. В марте 2022-го он получил $75 млн в ходе раунда финансирования Series C. Компания создаёт специализированные инструменты, которые позволяют более эффективно использовать вычислительные ресурсы при работе с ИИ-приложениями. NVIDIA объявила о планах по поглощению Run:ai в апреле нынешнего года. Тогда говорилось, что стоимость сделки может составлять до $1 млрд. Вместе с тем израильская газета Calcalist оценила актив в $700 млн. Изучением возможных последствий слияния занялись регулирующие органы в США и Европе. В частности, американское Министерство юстиции заподозрило, что NVIDIA покупает Run:ai с тем, чтобы в дальнейшем «похоронить» технологии этого стартапа. Дело в том, что платформа Run:ai позволяет уменьшить потребность в вычислительных ресурсах при работе с ИИ, а следовательно, снизить количество необходимых ускорителей. Это может привести к тому, что некоторые клиенты станут покупать меньше продуктов NVIDIA. 
Источник изображения: Run:ai Еврокомиссия дала сделке зелёный свет. В официальном заявлении регулятора сказано, что деятельность NVIDIA и Run:ai не пересекается. Подчёркивается, что NVIDIA занимает доминирующее положение на мировом рынке GPU. Однако у этой компании не будет «ни технических возможностей, ни стимулов для того, чтобы препятствовать совместимости своих GPU с конкурирующим ПО для оркестрации». Кроме того, как отмечается, Run:ai сейчас «не занимает существенной позиции» на рассматриваемом рынке ПО. Клиенты по-прежнему будут иметь доступ к альтернативным продуктам с функциями, аналогичными тем, что предлагает Run:ai. «Комиссия пришла к выводу, что предлагаемое приобретение не вызовет проблем с конкуренцией ни на одном из рассмотренных рынков в Европейской экономической зоне. Поэтому сделка безоговорочно одобрена», — сказано в заявлении регулятора.
20.12.2024 [12:50], Сергей Карасёв
Провайдер mClouds запустил облачную GPU-платформу с чипами AMD EPYC Genoa и ускорителями NVIDIAРоссийский облачный провайдер mClouds объявил о запуске новой платформы на базе GPU для решения ресурсоёмких задач, таких как проектирование в BIM и CAD, рендеринг и обработка видео, машинное обучение, работа с нейросетями и пр. В основу платформы положены процессоры AMD EPYC 9374F поколения Genoa. Эти чипы насчитывают 32 ядра (64 потока инструкций) с тактовой частотой 3,85 ГГц и возможностью повышения до 4,1 ГГц. Стандартный показатель TDP равен 320 Вт. Доступны три базовые конфигурации облачной GPU-платформы: с ускорителями NVIDIA A16 (64 Гбайт памяти) для задач BIM и CAD, NVIDIA L40S (48 Гбайт) для сложных вычислений и рендеринга, а также с NVIDIA L4 (24 Гбайт) для нейросетевого обучения и аналитики. При этом можно добавлять необходимые ресурсы — vCPU, RAM и SSD. Доступны также средства резервного копирования и антивирусная защита Kaspersky Endpoint Security. Провайдер mClouds предлагает гибкие варианты конфигурирования под собственные нужды. Платформа размещена в аттестованном московском дата-центре NORD4 уровня Tier III Gold. Доступность сервиса заявлена на отметке 99,9998 % (по итогам 2023 года), а время реагирования на инциденты составляет менее 15 минут. В тарифы при аренде мощностей на базе GPU входят защита от DDoS-атак, каналы связи с пропускной способностью до 120 Мбит/с на каждый сервер, ОС Windows Server или Linux. 
Источник изображения: mClouds «Наша платформа на базе AMD EPYC и NVIDIA выводит вычислительные возможности клиентов на совершенно новый уровень. Мы предоставляем клиентам не просто облачные ресурсы, а инструмент, который поможет им оставаться конкурентоспособными в условиях цифровой трансформации и ускорения внедрения ИИ в бизнесе», — говорит Александр Иванников, директор по развитию провайдера облачной инфраструктуры mClouds.
19.12.2024 [10:27], Сергей Карасёв
Стартап xAI начал монтаж суперускорителей NVIDIA GB200 NVL72 для ИИ-кластера ColossusСтартап xAI Илона Маска (Elon Musk), по сообщению ресурса ServeTheHome, приступил к расширению мощности ИИ-кластера Colossus. Речь идёт о монтаже суперускорителей NVIDIA GB200 NVL72 на архитектуре Blackwell. В начале сентября уходящего года компания xAI запустила ИИ-суперкомпьютер Colossus, в основу которого изначально легли 100 тыс. ускорителей NVIDIA H100. Сообщалось, что в дальнейшем количество ускорителей NVIDIA планируется увеличить вдвое. В начале декабря стартап получил $6 млрд инвестиций с целью увеличения числа ускорителей в составе Colossus до 1 млн штук. Отмечалось, что проект по расширению ИИ-кластера реализуется в партнёрстве с NVIDIA, Dell и Supermicro. Вместе с тем ранее появилась информация, что Dell перехватила у Supermicro крупный заказ на ИИ-серверы для xAI. Судя по всему, именно Dell является поставщиком систем GB200 NVL72 для комплекса Colossus. 
Источник изображения: Uday Ruddarraju На днях специалист xAI Удай Руддарраджу (Uday Ruddarraju) опубликовал на своей странице в социальной сети Х фотографию новых серверных модулей в составе Colossus. На снимке видны вычислительные узлы и лотки с коммутаторами NVLink. Наблюдатели отмечают, что компоненты пока не подключены к основной сети, на что указывает отсутствие оптоволоконных соединений. Вместе с тем уже подсоединены низкоскоростные сети управления. В узлах установлены карты NVIDIA Bluefield-3. 
Источник изображения: Michael Dell В отражении от шара с логотипом xAI просматриваются стойки с оборудованием. Предположительно, это системы производства Dell. Ранее глава этой компании Майкл Делл (Michael Dell) объявил о начале поставок первых в мире серверных стоек GB200 NVL72. Кроме того, Dell представила систему PowerEdge XE9712, которая использует архитектуру суперускорителя GB200 NVL72.
18.12.2024 [15:45], Руслан Авдеев
Microsoft купила как минимум вдвое больше ускорителей NVIDIA, чем любой из конкурентовПо оценкам аналитиков Omdia, Microsoft приобрела вдвое больше флагманских ускорителей NVIDIA в сравнении с любым из своих конкурентов. В Omdia подсчитали, что в 2024 году IT-гигант приобрёл 485 тыс. ускорителей NVIDIA Hopper, следующий по масштабу покупатель из США — компания Meta✴ купила всего 224 тыс. ускорителей. Заметно отстают и AWS с Google, сообщает The Financial Times В последние пару лет спрос на передовые ускорители превышает предложение. В этом году техногиганты потратили на ЦОД на основе новейших чипов NVIDIA Blackwell десятки миллиардов долларов, а венчурные инвесторы вкладывают огромные средства в ИИ-технологии несмотря на пока низкую отдачу. Облачная инфраструктура Microsoft активно используется не только самой корпорацией, но и OpenAI, в том числе для обучения новейшей модели o1. Идёт непрекращающееся соревнование с Google, стартапами вроде Anthropic и xAI, не говоря уж о китайских конкурентах. Так, по оценкам Omdia китайские ByteDance и Tencent заказали по 230 тыс. ускорителей NVIDIA только в этом году, включая ослабленную модель H20. Amazon и Google, наряду с Meta✴ работающие над внедрением собственных ускорителей, пока приобрели 196 тыс. и 169 тыс. Hopper соответственно. 
Источник изображений: NVIDIA Microsoft, инвестировавшая $13 млрд в OpenAI, является наиболее агрессивно среди других американским IT-гигантов наращивает инфраструктуру ИИ ЦОД. Кроме того, она предлагает и собственные ИИ-сервисы вроде Copilot. В этом году компания заказала втрое больше чипов NVIDIA того же поколения, чем в 2023-м. Во второй половине октября сообщалось, что компания стремительно наращивает закупки суперускорителей NVIDIA GB200 NVL. Про данным Omdia, на серверы технологические компании мира потратят в 2024 году $229 млрд. Впереди Microsoft с $31 млрд капитальных расходов и Amazon c $26 млрд. 10 ведущих покупателей инфраструктуры ЦОД, включая xAI и CoreWeave, обеспечивают 60 % вложений в вычислительные мощности. На NVIDIA приходится 43 % трат на серверы.  Хотя NVIDIA всё ещё доминирует на рынке ИИ-чипов, AMD активно пытается составить ей конкуренцию. В этом году Meta✴ приобрела 173 тыс. ускорителей MI300, а Microsoft — 96 тыс. Также крупные компании используют и чипы собственной разработки. Google уже десять лет разрабатывает TPU, а у Meta✴ есть два поколения MTIA — обе компании внедрили по 1,5 млн собственных чипов. Amazon развернула 1,3 млн ускорителей Trainium и Inferentia. Для Anthropic компания намерена построить кластер из сотен тысяч Trainium для обучения новейшего поколения ИИ-моделей. Amazon уже инвестировала в стартап $8 млрд. При этом сама Microsoft, хоть и выпускает собственные полупроводниковые продукты, конкурирующие с NVIDIA, но внедрила в этом году только 200 тыс. чипов Maia. Чипы NVIDIA всё ещё нужны Microsoft для предоставления «уникальных» сервисов. Правда, для этого компании дополнительно нужны инфраструктура, ПО и другие компоненты экосистемы. В начале ноября появилась информация, что Microsoft по итогам I квартала 2025 финансового года не хватает ресурсов для обслуживания ИИ, но компания готова и далее вкладываться в ЦОД, хотя инвесторам это не по нраву. Более того, Microsoft потратит $10 млрд на аренду ИИ-серверов у CoreWeave.
18.12.2024 [13:05], Сергей Карасёв
NVIDIA представила одноплатный ИИ-компьютер Jetson Orin Nano Super с производительностью 67 TOPSКомпания NVIDIA анонсировала одноплатный компьютер Jetson Orin Nano Super для разработчиков, проектирующих различные устройства с функциями ИИ. Это могут быть всевозможные роботы, периферийное оборудование, системы машинного зрения и пр. Сама компания называет новинку «самым доступным суперкомпьютером для генеративного ИИ». Новинка наделена процессором с шестью вычислительными ядрами Arm Cortex-A78AE, работающими на тактовой частоте 1,7 ГГц. Объём оперативной памяти LPDDR5 составляет 8 Гбайт, её пропускная способность — 102 Гбайт/с. В оснащение входит GPU на архитектуре NVIDIA Ampere с 1024 ядрами CUDA и 32 тензорными ядрами; частота составляет 1020 МГц. 
Источник изображения: NVIDIA Утверждается, что ИИ-производительность достигает 67 TOPS на операциях INT8. Обеспечивается возможность кодирования видео 1080p30 при использовании 1–2 ядер CPU, а также декодирования материалов 4K60 (H.265; один поток), 4K30 (H.265; два потока); 1080p60 (H.265; пять потоков), 1080p30 (H.265; 11 потоков). Энергопотребление находится в диапазоне от 7 до 25 Вт. 
Источник изображения: NVIDIA Для Jetson Orin Nano Super создана эталонная интерфейсная плата. Она располагает двумя коннекторами MIPI CSI, слотами M.2 Key M PCIe 3.0 х4, M.2 Key M PCIe 3.0 х2 и M.2 Key E, четырьмя портами USB 3.2 Gen2 Type-A, портом USB Type-C, сетевым портом 1GbE RJ-45, разъёмом DisplayPort 1.2 (+MST), а также 40-контактной колодкой с поддержкой UART, SPI, I2S, I2C, GPIO. Габариты составляют 103 × 90,5 × 34,77 мм. Допускается подключение кулера с вентилятором. Питание может подаваться через порт USB Type-C или DC-коннектор. Новинка предлагается по ориентировочной цене $250.
14.12.2024 [15:25], Сергей Карасёв
HPE создаст HPC-систему Blue Lion для Суперкомпьютерного центра имени ЛейбницаСуперкомпьютерный центр имени Лейбница (LRZ) в Германии, управляемый Баварской академией наук в Мюнхене (BADW), объявил о подписании соглашения с HPE на строительство HPC-комплекса нового поколения. Проект получил название Blue Lion. LRZ, входящий в состав Суперкомпьютерный центр имени Гаусса (GCS), намерен запустить систему Blue Lion в 2027 году. Предполагается, что комплекс не только ускорит выполнение задач в области классического моделирования, но и откроет новые возможности для достижений в сфере ИИ. В основу Blue Lion ляжет платформа HPE Cray нового поколения с ускорителями NVIDIA. Говорится о применении интерконнекта HPE Slingshot с пропускной способностью до 400 Гбит/с. По производительности Blue Lion примерно в 30 раз превзойдёт предшественника — систему SuperMUC-NG, которая обеспечивает теоретическое пиковое быстродействие в 26,9 Пфлопс. 
Источник изображения: GCS Blue Lion будет использовать на 100 % прямое жидкостное охлаждение тёплой водой температурой до +40 °C, протекающей по медным трубкам. Нагретую воду планируется повторно использовать для отопления помещений самого LRZ, а также соседних учреждений в Гархинге. Утверждается, что такая СЖО расходует примерно на 94 % меньше энергии в процессе работы, чем сопоставимая по классу система воздушного охлаждения. Blue Lion также потребует значительно меньше места для размещения благодаря более высокой плотности монтажа. Проект Blue Lion в равных долях финансируется Министерством науки и искусства Баварии (StMWK) и Федеральным министерством образования и исследований (BMBF). Затраты на создание суперкомпьютера оцениваются в €250 млн с учётом эксплуатационных расходов до 2032 года. |
|

