Материалы по тегу: nvidia
|
02.03.2025 [18:02], Сергей Карасёв
NVIDIA втихую приобрела разработчика сетевых AIOps-решений Augtera NetworksКомпания NVIDIA, по сообщению Datacenter Dynamics, без лишнего шума приобрела стартап Augtera Networks, занимающийся решениями в области AIOps. Финансовые и прочие условия сделки не раскрываются, но известно, что основатели купленной фирмы присоединились к NVIDIA. Концепция AIOps, или ИИ для IT-операций, предполагает применение ИИ для обслуживания IT-инфраструктуры. Могут быть автоматизированы такие задачи, как мониторинг производительности, планирование рабочих нагрузок, резервное копирование данных и пр. Стартап Augtera Networks был основан в 2016 году. Компания привлекла около $18 млн в качестве посевного раунда финансирования и программы Series A, а в число основных инвесторов вошли Bain Capital Ventures, Acrew Capital, Intel Capital и Dell Capital. Стартап разработал инструменты на базе ИИ для автоматизации сетевых операций. В частности, Augtera Networks создала технологию мониторинга сети, предназначенную для обнаружения аномалий, предотвращения сбоев и обеспечения обозреваемости инфраструктуры в режиме реального времени. 
Источник изображения: NVIDIA В рамках сделки разработки Augtera Networks будут переданы команде NVIDIA Spectrum-X. Основатель и генеральный директор стартапа Рахул Аггарвал (Rahul Aggarwal) занял пост старшего директора по системному ПО для ИИ-платформ в NVIDIA. Соучредитель Augtera Networks Бхупеш Котари (Bhupesh Kothari) также перешёл в NVIDIA, заняв одну из руководящих должностей. Отмечается, что у Augtera Networks были контракты с Orange, Vyve Broadband и Colt Technologies. А финтех-компания MX Technologies применяла решения Augtera Networks для мониторинга своей сети дата-центров. Будут ли поддерживаться существующие клиенты после сделки, не уточняется.
27.02.2025 [16:27], Владимир Мироненко
NVIDIA увеличила выручку, но снизила валовую прибыль — продукты стали сложнее и дороже, а спрос на Blackwell потрясающийNVIDIA объявила финансовые результаты за IV квартал и 2025 финансовый год, завершившийся 26 января 2025 года. Выручка компании в IV квартале составила $39,3 млрд, что на 12 % выше результата предыдущего квартала и на 78 % больше год к году при консенсус-прогнозе аналитиков, опрошенных LSEG, в размере $38,05 млрд. Вместе с тем компания сообщила о снижении валовой прибыли в отчётном квартале на 3 п.п. в годовом исчислении 73 %, объяснив это выходом новых продуктов для ЦОД, которые стали сложнее и дороже. Чистая прибыль (GAAP) выросла год к году на 80 % до $22,09 млрд. Чистая прибыль на разводнённую акцию (GAAP) составила $0,89, что на 14 % больше, чем в предыдущем квартале и на 82 % больше год к году. Скорректированная чистая прибыль на разводнённую акцию (Non-GAAP) составила $0,89, что на 10 % больше, чем в предыдущем квартале и на 71% больше, чем годом ранее, а также больше консенсус-прогноза аналитиков Уолл-стрит согласно опросу LSEG в размере $0,84. 
Источник изображений: NVIDIA Выручка компании в 2025 финансовом году выросла на 114 % до $130,5 млрд. Чистая прибыль (GAAP) увеличилась на 145 % с $29,76 млрд или $1,19 на разводнённую акцию в предыдущем финансовом году до $72,88 млрд или $2,94 на акцию в отчётном. Скорректированная чистая прибыль (Non-GAAP) выросла за год на 130 % до $2,99 на разводнённую акцию. В сегменте решений для ЦОД выручка за IV квартал составила $35,6 млрд, увеличившись на 93 % в годовом исчислении и опередив прогноз Уолл-стрит в $33,65 млрд. За год выручка этого сегмента увеличилась на 142 % до $115,2 млрд. Как отметил ресурс SiliconANGLE, на данный сегмент пришлось 91 % от общего дохода компании за IV квартал, по сравнению с 83 % год назад и всего 60 % в аналогичном квартале 2023 финансового года. Доход компании от продуктов для ЦОД вырос за последние два года почти в десять раз. Вместе с тем выручка от продаж сетевого оборудование упала за квартал на 9 % до $3 млрд, но компания наверняка увеличит продажи, т.к. решениями Spectrum-X буду оснащатсья первые ЦОД ИИ-мегапроекта Stargate. 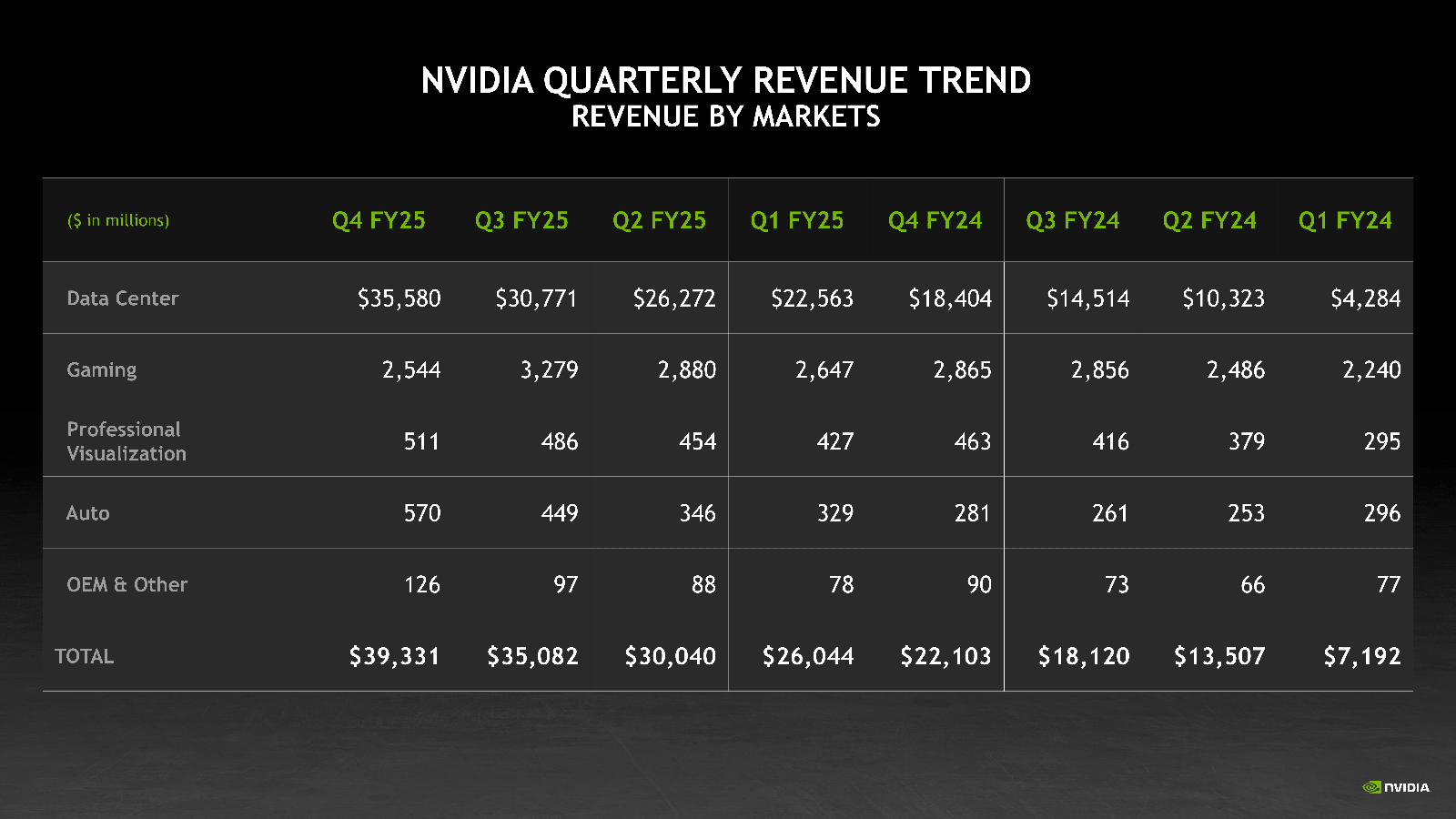 NVIDIA сообщила, что доход от продаж чипов с архитектурой Blackwell составил за квартал $11 млрд, что является «самым быстрым ростом продукта» в её истории. «Спрос на Blackwell потрясающий», — цитирует Bloomberg заявление гендиректора NVIDIA Дженсена Хуанга (Jensen Huang). Финансовый директор NVIDIA Колетт Кресс (Colette Kress) сообщила, что чипы Blackwell были лидерами по продажам для дата-центров и принесли порядка 50 % всего дохода сегмента ЦОД. В ходе телефонной конференции Хуанг сообщил, что предыдущие поколения чипов компании в основном использовались для обучения моделей ИИ, а новые чипы Blackwell в основном применяются для инференса. Некоторые инвесторы высказывали опасения, что спрос на самые мощные чипы NVIDIA может упасть из-за прогресса китайской DeepSeek, чья недорогая модель со способностью к рассуждениям DeepSeek R1 произвела фурор в отрасли, хотя на её разработку якобы ушло всего несколько миллионов долларов.  В ответ на это Кресс сообщила, что новые модели, разработанные для более тщательного «обдумывания» своих ответов, вероятно, потребуют гораздо больше вычислительной мощности по сравнению с более ранними моделями генеративного ИИ. «Для продолжительно думающего, рассуждающего ИИ может потребоваться в 100 раз больше вычислений на задачу по сравнению с однократными инференсами», — сказала она. Хуанг поддержал её, заявив, что «подавляющее большинство вычислений сегодня на самом деле относится к инференсу». Он выразил мнение, что в ближайшие годы ИИ-модели нового поколения могут потребовать «в миллионы раз» больше вычислительных мощностей, чем доступно сейчас. Опасения инвесторов также вызывает то, что AWS, Google и Microsoft, разрабатывающие собственные, кастомизированные ускорители, могут создать сильную конкуренцию NVIDIA. В ответ Хуанг заявил, что этим конкурентам ещё предстоит пройти долгий путь, и то, что чип разработан вовсе не означает, что он будет выпускаться.  Что касается результатов остальных подразделений компании, то игровой бизнес компании, включающий графические процессоры для 3D-игр, принёс ей $2,5 млрд, что меньше год к году на 11 %, а также меньше прогноза StreetAccount в размере $3,04 млрд. В сегменте профессиональной визуализации продажи за квартал составили $511 млн, что на 10 % больше год к году. За весь год выручка подразделения увеличилась на 21 % до $1,9 млрд. В автомобильном секторе выручка компании за отчётный квартал увеличилась в годовом исчислении на 103 % до $570 млн. За год выручка составила $1,7 млрд (рост — 55 %). Прогноз NVIDIA на I квартал 2026 финансового года по выручке равен $43 млрд ± 2 %, против $41,78 млрд, ожидаемых по оценкам LSEG. Это означает рост примерно на 65 % год к году, что является замедлением темпов роста компании по сравнению с ростом на 262 % за тот же период годом ранее. Компания также предупредила, что валовая прибыль будет меньше, чем ожидалось, поскольку она спешит выпустить новый дизайн чипа с архитектурой Blackwell. И также есть риск, что введение пошлин на импорт Соединёнными Штатами повлияет на результаты её работы. Акции NVIDIA выросли чуть более чем на 1 % в ходе расширенных торгов, что добавилось к росту более чем на 3 % в ходе обычной торговой сессии, отметил Bloomberg.
27.02.2025 [12:33], Сергей Карасёв
Cisco представила MGX-сервер UCS C845A M8 на базе AMD EPYC 9005 Turin с поддержкой восьми PCIe-ускорителей NVIDIAКомпания Cisco анонсировала сервер UCS C845A M8 для рабочих нагрузок ИИ, построенный на модульной архитектуре NVIDIA MGX. Устройство поддерживает установку от двух до восьми ускорителей NVIDIA H200 NVL, H100 NVL и L40S), а также адаптеров NVIDIA BlueField-3 SuperNIC и ConnectX-7. Новинка выполнена в форм-факторе 4U с применением аппаратной платформы AMD EPYC 9005 Turin: максимальная конфигурация включает два 96-ядерных процессора EPYC 9655. Доступны 32 слота для модулей DDR5-4400/5200. Система может нести на борту два загрузочных SSD формата M.2 с интерфейсом SATA вместимостью 960 Гбайт каждый, а также до 20 накопителей E1.S NVMe. Предусмотрены пять слотов PCIe 5.0 x16 для сетевых 400G-адаптеров типоразмера FHHL: один для внешней сети, четыре для внутренней сети кластера. Задействовано воздушное охлаждение. За питание отвечают четыре блока мощностью 3200 Вт с возможностью горячей замены. Имеется слот OCP 3.0 под сетевую карту Intel X710-DA2 с двумя портами 10GbE для управления. По заявлениям Cisco, при разработке модели UCS C845A M8 особое внимание было уделено конструкции системы: говорится об улучшенной прокладке кабелей для оптимального воздушного потока и упрощении обслуживания, включая замену компонентов. 
Источник изображения: Cisco В зависимости от количества установленных GPU и объема памяти сервер подходит для решения таких задач, как обучение и тонкая настройка ИИ-моделей, аналитика и визуализация данных, приложения НРС, проектирование и моделирование, обработка естественного языка, разговорный ИИ, рендеринг, облачные приложения и пр. В качестве потенциальных покупателей названы крупные предприятия, научно-исследовательские институты, государственные учреждения и облачные провайдеры.
26.02.2025 [23:40], Владимир Мироненко
Неожиданный союз: Cisco и NVIDIA поделятся друг с другом сетевыми чипами и решениями для ИИ-инфраструктурCisco объявила о расширенном партнёрстве с NVIDIA. Совместно компании намерены предоставить заказчикам гибкость выбора сетевых инфраструктур для обслуживания всё более интенсивных рабочих нагрузках ИИ и высокую производительность обмена данными между и внутри ЦОД, а также между облаками и между пользователями. По словам Чака Роббинса (Chuck Robbins), председателя и генерального директора Cisco, сотрудничество «устранит барьеры для клиентов» и позволит им «оптимизировать свои инвестиции в инфраструктуру, чтобы раскрыть потенциал ИИ». Гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) добавил, что ИИ развивается со «скоростью света», отметив преобразующий потенциал объединения глобального охвата Cisco с оптимизированными для ИИ Ethernet-решениями NVIDIA, что поможет компаниям по всему миру создать современную ИИ-инфраструктуру. 
Источник изображения: Cisco В рамках расширенного сотрудничества сетевая платформа NVIDIA Spectrum-X Ethernet на базе ASIC Cisco и NVIDIA послужит основой для многих корпоративных рабочих нагрузок ИИ. Использование унифицированной архитектуры, которая упрощает интеграцию и стандартизацию технологий Cisco и NVIDIA в корпоративных средах, позволит клиентам оптимизировать свои инвестиции в инфраструктуру, используя имеющиеся инструменты и процессы управления, охватывающие разные виды сетей. Партнёрство двух компаний позволит их клиентам получать выгоду от текущих и будущих технологических достижений платформы NVIDIA Spectrum-X, таких как адаптивная маршрутизация, телеметрия, управление заторами и низкая задержка, а также предоставит им доступ к более широкому портфелю сетевых решений, безопасности и цифровой устойчивости Cisco, включая платформу Splunk. Поскольку компании развивают возможности ИИ и обучают модели на собственных данных, наличие комплексной стратегии безопасности становится критически важным, отмечено в пресс-релизе. 
Источник изображения: NVIDIA Если отбросить красивые маркетинговые слова, то новое сотрудничество сводится к двум основным пунктам. Во-первых, в состав платформы NVIDIA Spectrum-X теперь будут входить решения на базе ASIC Cisco Silicon One и DPU NVIDIA SuperNIC, причём допущены к платформе будут только чипы Cisco. У самой Cisco уже есть похожее решение на базе DPU Pensando от AMD. Во-вторых, Cisco портирует на ASIC NVIDIA Spectrum фирменную сетевую ОС NX-OS, что позволит стандартизировать сетевые инфраструктуры в ЦОД, организовать единую точку управления всей сетью и интегрировать решения NVIDIA со стеком Nexus и с другими сервисами и продуктами Cisco, включая Nexus Dashboard, Nexus Hyperfabric AI, UCS и др. Cisco сама будет выпускать продукты на базе ASIC NVIDIA Spectrum. 
Источник изображения: Cisco Сотрудничество Cisco и NVIDIA распространяется на совместную разработку эталонных архитектур, включая NVIDIA Cloud Partner (NCP) и Enterprise Reference Architectures. Также Cisco и NVIDIA планируют продолжить сотрудничество для решения важных задач, таких как управление перегрузками и балансировка, и других эксплуатационных проблем, с которыми сталкиваются предприятия при масштабировании рабочих нагрузок ИИ. Любопытно, что NVIDIA в конце концов присоединилась к консорциуму Ultra Ethernet, основанному Arista, Broadcom, Cisco и др. с целью создания современного интерконнекта для HCP- и ИИ-нагрузок на базе Ethernet. Фактически же консорциум во многом призван создать работающую альтернативу технологии Infiniband, которая монопольно контролируется и продвигается NVIDIA.
26.02.2025 [17:15], Руслан Авдеев
Триумф ИИ-моделей DeepSeek подстегнул спрос на ускорители NVIDIA H20 в КитаеКитайские техногиганты Alibaba, ByteDance и Tencent наращивают закупки урезанных ускорителей NVIDIA H20. Даже ослабленные чипы весьма востребованы китайским бизнесом для обеспечения работы ИИ-моделей, сообщает Reuters. Это опровергает опасения относительно падения спроса на фоне того, что модели DeepSeek для обучения и инференса требуют гораздо менее производительного оборудования. Несмотря на введённые США экспортные ограничения в отношении Китая, запрещающие поставки наиболее передовых ускорителей, NVIDIA продала в 2024 году около 1 млн чипов H20, выручив порядка $12 млрд. Это свидетельствует о том, что спрос на строительство ИИ-инфраструктуры в Китае по-прежнему высок. Стоимость H20 составляет $12-15 тыс., но модель стала критически важным компонентом в гонке китайских ИИ-платформ после новых ограничений, введённых в отношении КНР в 2023 году. Кроме того, есть риск, что новая администрация США запретит продажи Китаю ускорителей H20. Источник изображения: NVIDIA Спрос на вычислительные ИИ-мощности в Китае подстегнул триумф местного стартапа DeepSeek, представившего удивительно экономичные и эффективные ИИ-модели. Закупки наращивают Alibaba, ByteDance и Tencent, в частности, для облачных сервисов на базе DeepSeek-R1. ИИ-серверы на базе H20 с DeepSeek также востребованы медицинскими организациями и образовательными ведомствами. Ускорители Huawei Ascend тоже активно закупаются для снижения зависимости от американских технологий. И хотя они не слишком хороши в обучении моделей в сравнении с продуктами NVIDIA, для инференса их возможностей хватает, а это одна из ключевых ИИ-нагрузок. Инференс-платформы для DeepSeek предлагают и американские компании Cerebras и SambaNova.
22.02.2025 [22:45], Сергей Карасёв
В облаке Google Cloud появились инстансы A4X на базе суперускорителей NVIDIA GB200 NVL72Облачная платформа Google Cloud объявила о запуске виртуальных машин A4 с ускорителями NVIDIA B200 и A4X на основе суперускорителей NVIDIA GB200 NVL72 поколения Blackwell. Эти инстансы ориентированы на ресурсоёмкие приложения ИИ. 
Источник изображения: Google По заявлениям Google, виртуальные машины A4 обеспечивают высокий уровень производительности при работе с ИИ-моделями на различных архитектурах. Инстансы подходят для таких рабочих нагрузок, как обучение и тонкая настройка. В свою очередь, экземпляры A4X специально созданы для обучения и обслуживания самых требовательных и сверхмасштабных задач ИИ, включая большие языковые модели (LLM) с наиболее ёмкими контекстными окнами и «рассуждающие» модели. Суперускорители GB200 NVL72 объединяют в одной стойке 72 чипа B200 и 36 процессоров Grace. Применяются шина NVLink 5 и инфраструктура жидкостного охлаждения Google третьего поколения. Каждая система GB200 NVL72 обеспечивает быстродействие до 1,44 Эфлопс в режиме FP4 и до 720 Пфлопс в режиме FP8. По заявлениям Google, достигается четырёхкратное увеличение производительности при обучении LLM по сравнению с виртуальными машинами A3 на базе ускорителей NVIDIA H100. Инстансы A4X допускают масштабирование до десятков тысяч графических процессоров Blackwell. Говорится об интеграции с сервисами хранения Cloud Storage FUSE, Parallelstore и Hyperdisk ML, что обеспечивает доступ к данным с малой задержкой (менее 1 мс) и высокую пропускную способность. Новые виртуальные машины будут развёрнуты в различных регионах Google Cloud. Нужно отметить, что ранее о запуске общедоступных инстансов на базе NVIDIA GB200 NVL200 объявила компания CoreWeave, предоставляющая облачные услуги для ИИ-задач. Скоро эти суперускорители станут доступны и в облаке Lambda Labs.
17.02.2025 [12:19], Сергей Карасёв
Платформа Graid SupremeRAID SE для создания массивов NVMe RAID получила поддержку NVIDIA GeForce RTX 5000Компания Graid Technology сообщила о том, что её платформа SupremeRAID SE, предназначенная для формирования высокопроизводительных массивов NVMe RAID, теперь поддерживает работу с ускорителями семейства NVIDIA GeForce RTX 5000. SupremeRAID — это программно-определяемое решение на базе GPU, предназначенное для обеспечения максимальной производительности SSD. Отмечается, что SupremeRAID SE позволяет формировать массивы RAID на 4–8 накопителях NVMe с высокой отказоустойчивостью, одновременно освобождая ресурсы CPU для других задач. Платформу SupremeRAID SE можно использовать с такими ускорителями, как GeForce RTX 5090, GeForce RTX 5080, GeForce RTX 5070 Ti, GeForce RTX 5070 и GeForce RTX 5060. Решение ориентировано прежде всего на мощные рабочие станции, предназначенные для приложений ИИ, машинного обучения, 3D-рендеринга, редактирования видеоматериалов высокого разрешения и разработки игр. По заявлениям Graid Technology, программно-определяемый RAID обладает упрощённой настройкой, которая избавлена от сложностей, присущих традиционным аппаратным решениям RAID. 
Источник изображения: Graid Technology В целом, благодаря SupremeRAID SE можно задействовать имеющиеся мощности GPU для формирования высокопроизводительных и высокоустойчивых RAID-конфигураций: поддерживаются режимы RAID 0, 1, 10, 5. Говорится о совместимости с Windows Server 2011/2022 и Windows 11, а также с широким перечнем ОС на ядре Linux, включая AlmaLinux 8.8, CentOS 7.9/8.5, Fedora 40, openSUSE Leap 15.3 (Kernel 5.3), Oracle Linux 7.9/8.7/9.1, RHEL 7.9/8.8 и Ubuntu 24.04.0, а также с более ранними версиями указанных дистрибутивов.
13.02.2025 [00:07], Владимир Мироненко
Supermicro спрогнозировала невероятный рост выручки, но потомSupermicro объявила предварительные финансовые результаты за II квартал 2025 финансового года, закончившийся 31 декабря 2024 года. Цифры ещё не окончательные, поскольку у компании не было возможности провести полноценный аудит после того, как в ноябре прошлого года Ernst & Young LLP отказалась от дальнейшей проверки её отчётности. Supermicro заявила, что ожидает получить выручку за II квартал в размере от $5,6 до $5,7 млрд, что на 54 % больше год к году в среднем значении, но меньше предыдущего прогноза в пределах от $5,4 до $6,1 млрд, а также консенсус-прогноза аналитиков Уолл-стрит в размере $5,8 млрд. Чистая прибыль (GAAP) на обыкновенную разводнённую акцию находится в диапазоне от $0,50 до $0,52. Скорректированная чистая прибыль (non-GAAP) на обыкновенную акцию составляет от $0,58 до $0,60, что отражает рост на 5 % в годовом исчислении, но ниже целевого показателя Уолл-стрит в $0,61. Компания предупредила, что неаудированная промежуточная финансовая информация, представленная в её пресс-релизе, является предварительной. Окончательные финансовые результаты за этот период также могут отличаться от этих показателей.  Supermicro ожидает получить в III финансовом квартале, заканчивающемся 31 марта 2025 года, выручку в пределах от $5,0 до $6,0 млрд, чистую прибыль (GAAP) на разводнённую акцию от $0,36 до $0,53 и скорректированную чистую прибыль (non-GAAP) на разводнённую акцию от $0,46 до $0,62. Компания обновила и прогноз по выручке на 2025 финансовый год, заявив, что она составит от $23,5 до $25 млрд, что ниже предыдущего прогноза в размере от $26 до $30 млрд и примерно соответствует ожиданиям Уолл-стрит в размере $24,5 млрд. Основатель, президент и генеральный директор Supermicro Чарльз Лян (Charles Liang) сообщил, что в 2026 финансовом году, завершающемся в середине следующего календарного года, выручка компании вырастет до $40 млрд, что, по его словам, является «относительно консервативной оценкой». Это гораздо выше прогноза аналитиков Уолл-стрит в размере $29,18 млрд. После этого акции компании показали рост на 9 %, впервые за длительный период продолжающегося падения.  Драйвером роста Лян назвал более широкое внедрение технологии прямого жидкостного охлаждения (DLC) Supermicro в ЦОД, которую, по его словам, возьмут на вооружение 30 % новых дата-центров в течение следующих 12 месяцев. Supermicro имеет все возможности для роста проектов ИИ-инфраструктуры, основанных на NVIDIA Blackwell и других решениях, отметил Лян, добавив, что компания начала массовые поставки NVIDIA HGX B200 с воздушным (10U) и жидкостным (4U) охлаждением. GB200 NVL72 также полностью готовы, но задержки с получением ускорителей Blackwell привели к снижению диапазона доходов Supermicro. Лян сообщил, что линейка продуктов Supermicro продолжает расти, отметив, что у компании есть «линейка продукции, соответствующая отраслевым стандартам, плюс множество наборов микросхем», включая некоторые «конфиденциальные продукты, находящиеся в разработке». По его словам, у Supermicro уже есть клиент, работающий с компанией по этим продуктам, передаёт DataCenter Dynamics.  Лян также сообщил, что финансовая команда Supermicro и её новый аудитор BDO, «полностью вовлечены в завершение аудиторского процесса», и он «уверен», что отчёт будет подан в Комиссию по ценным бумагам и биржам (SEC) США к крайнему сроку 25 февраля. В случае невыполнения этого условия компании грозит делистинг с фондовой биржи Nasdaq. За последние пять дней акции Supermicro выросли на 59 %, а с начала года — на 40 %, тогда как у Nasdaq рост составил всего 2 %, пишет SiliconANGLE. Вместе с тем за последние 12 месяцев акции компании упали на 48 %, а из биржевого индекса Nasdaq 100 компания выбыла в конце 2024 года.
11.02.2025 [13:47], Руслан Авдеев
Tesla запустила суперкомпьютер Cortex с 50 тыс. ускорителей NVIDIA H100, а общие затраты компании на ИИ уже превысили $5 млрдКомпания Tesla завершила ввод в эксплуатацию ИИ-кластера из 50 тыс. ИИ-ускорителей NVIDIA H100 в IV квартале прошлого года. В презентации для акционеров отмечалось, что кластер Cortex заработал на принадлежащем Tesla объекте Gigafactory в Остине (Техас), сообщает Datacenter Dynamics. Информация впервые появилась в отчёте компании за IV квартал и 2024 финансовый год. Новый кластер не имеет отношения к суперкомпьютеру Dojo, предназначенному для технологий автономного вождения FSD, имеющего собственную архитектуру и оснащенного кастомными чипами D1. При этом в презентации, посвящённой отчёту, Dojo не упоминается вообще. Хотя компания не уточняет, когда именно в IV квартале началось развёртывание системы, на конференции по финансовым вопросам в октябре 2024 года представитель Tesla заявил, что компания находится «на пути к развёртыванию 50 тыс. ускорителей в Техасе к концу текущего месяца». По имеющимся данным, проект реализован с опозданием, поскольку Илон Маск уволил руководителя строительством ещё в апреле, а также приказал передать xAI 12 тыс. ускорителей H100, изначально предназначавшихся Tesla. 
Источник изображения: Tesla В презентации сообщается, что именно Cortex уже помог в создании «автопилота» FSD V13 (Supervised). Новая версия повысила безопасность и комфорт вождения благодаря увеличению объёма данных в 4,2 раза, повышению разрешения видеопотока, а также другим усовершенствованиям. Заодно компания сообщила о продолжении работ над программной и аппаратной частями робота Optimus, в т.ч. рук нового поколения и механизмов передвижения. Также осуществлялось обучение выполнению дополнительных задач перед началом пилотного производства в 2025 году. Что касается доходов компании в IV квартале, в конце января Илон Маск (Elon Musk) сообщил, что бизнес продолжает инвестировать в обучающую инфраструктуру за пределами штаб-квартиры в Техасе. В конце января сообщалось, что Tesla наращивает вычислительные мощности для обучения Optimus. По словам миллиардера, на обучение Optimus необходимо потратить, как минимум, в 10 раз больше ресурсов в сравнении с полноценным обучением систем автомобиля. Капитальные затраты Tesla в 2024 году составили $10 млрд, столько же компания намерена потратить в ближайшие два года, хотя большая часть затрат придётся на инфраструктуру для электромобилей. В отчёте о доходах за IV квартал упоминалось, что общие капитальные затраты компании, связанные с ИИ, включая инфраструктуру, превысили $5 млрд.
05.02.2025 [12:07], Сергей Карасёв
В облаке CoreWeave появились суперускорители NVIDIA GB200 NVL72Компания CoreWeave, предоставляющая облачные услуги для ИИ-задач, объявила о запуске первых в отрасли общедоступных инстансов на базе NVIDIA Blackwell. Они предназначены для наиболее ресурсоёмких нагрузок, включая работу с «рассуждающими» моделями ИИ. Инстансы используют суперускорители NVIDIA GB200 NVL72. Такие устройства объединяют в одной стойке 18 узлов 1U, каждый из которых содержит два ускорителя GB200: в сумме это даёт 72 чипа B200 и 36 процессоров Grace. Применяются шина NVLink 5 и система жидкостного охлаждения. Экземпляры CoreWeave на основе GB200 NVL72 оснащены интерконнектом NVIDIA Quantum-2 InfiniBand, который обеспечивает пропускную способность 400 Гбит/с в расчёте на GPU. Возможно формирование кластеров, насчитывающих до 110 тыс. графических процессоров. Платформа мониторинга CoreWeave Observability Platform в режиме реального времени предоставляет информацию о производительности NVLink, загрузке GPU и температуре узлов. В составе инстансов также задействованы DPU NVIDIA BlueField-3. 
Источник изображения: NVIDIA По заявлениям CoreWeave, новые экземпляры обеспечивают прирост производительности до четырёх раз при обучении больших языковых моделей (LLM) по сравнению с решениями предыдущего поколения. Совокупная стоимость владения сокращается в 25 раз и во столько же снижается энергопотребление на задачах инференса в реальном времени. Вместе с тем быстродействие инференса может быть увеличено до 30 раз. Ожидается, что запуск инстансов с суперускорителями NVIDIA GB200 NVL72 поможет в создании моделей следующего поколения и ИИ-агентов. На сегодняшний день экземпляры доступны через CoreWeave Kubernetes Service в регионе US-WEST-01 — пара GB200 обойдётся в $42/час. |
|

