Материалы по тегу: nvidia
|
21.03.2025 [08:56], Руслан Авдеев
NVIDIA инвестировала в CoreWeave, дала ей дефицитные ИИ-ускорители, а потом сама же арендовала ихКлиентам NVIDIA необходимо постоянно вкладывать миллиарды долларов в построение ИИ-инфраструктуры. При этом финансовая поддержка может прийти из самых неожиданных мест. Иногда — от самой NVIDIA, сообщает The Information. NVIDIA и её крупнейшим клиентам постоянно приходится искать баланс. С одной стороны, они поддерживают друг друга в краткосрочной перспективе, с другой — на длинной дистанции с NVIDIA намерены конкурировать многие гиперскейлеры. Microsoft, Meta✴, Google и Amazon (AWS) активно используют ИИ-чипы NVIDIA, одновременно пытаясь избавиться от такой зависимости и работая над собственными решениями: Maia, MTIA, TPU, Trainium и Inferentia. Поэтому NVIDIA инвестирует в т.н. неооблака (neocloud), ориентированные на предоставление ИИ-мощностей. Такие компании до некоторой степени способны стать альтернативой гиперскейлерам и вряд ли смогут разработать продукты, конкурирующие с чипами NVIDIA. К таковым относится и CoreWeave, которой NVIDIA активно помогает развиваться. В рамках подготовки к IPO компания раскрыла, что около 77 % выручки 2024 году ей принесли всего два клиента. Крупнейшим из них была Microsoft (62 %), которая к тому же обогнала по объёму закупок ускорителей NVIDIA всех ближайших конкурентов. А вот вторым по величине клиентом CoreWeave оказалась… сама NVIDIA (15 %). В начале 2023 года, когда спрос на ИИ-ускорители со стороны гиперскейлеров был фантастическим, NVIDIA сделала любопытный ход — в рамках т. н. Project Osprey она согласилась потратить в течение четырёх лет $1,3 млрд на аренду собственных чипов у CoreWeave, одновременно инвестировав в неё $100 млн. CoreWeave получила сотни тысяч современных ИИ-ускорителей и контракт с NVIDIA до августа 2027 года. NVIDIA действительно активно использует арендованные ускорители, не отвлекаясь на развёртывание ИИ ЦОД. В случае успешного выхода CoreWeave на биржу с оценкой более $30 млрд. заблаговременные инвестиции NVIDIA в акционерный капитал компании всего за два года превратятся в более чем $1 млрд. Однако для потенциальных инвесторов такое сотрудничество — повод для беспокойства, поскольку контракты с Microsoft и NVIDIA истекают в 2027–2029 гг. 
Источник изображения: Kelly Sikkema / Unsplash Подобные сделки на рынке ИИ — довольно распространённое явление. «Циклические» финансовые соглашения показывают, как деньги в отрасли уходят из компаний и возвращаются к ним же. SoftBank, намеренная стать одним из крупнейших инвесторов OpenAI, согласилась платить компании $3 млрд за использование её ИИ-продуктов. Microsoft вложила в OpenAI более $13 млрд, в результате чего получает долю в растущих доходах компании. В то же время OpenAI ежегодно выплачивает Microsoft миллиарды долларов за облачные сервисы. Amazon и Google заключили аналогичные сделки с Anthropic. Тем временем CoreWeave подпитывает расширение бизнеса за счёт долговых обязательств на $8 млрд и $15 млрд договоров долгосрочной аренды ЦОД и офисов. В своё время CoreWeave даже взяла в долг $2,3 млрд под залог ускорителей NVIDIA, чтобы купить ещё больше ускорителей NVIDIA. Пока инвесторы сомневаются, как оценивать компанию, поскольку малое количество якорных клиентов в совокупности с высокими темпами роста и большими долгами — довольно редкое явление. CoreWeave может сыграть роль и в развитии других компаний и проектов. В частности, речь идёт о намерении OpenAI подписаться на сервисы CoreWeave — пятилетний контракт на $11,9 млрд предполагает получение доли в компании. В этот период CoreWeave сможет получать дополнительные средства ежегодно, что несколько снизит её зависимость от NVIDIA и Microsoft. Однако данный контракт является лишь дополнением к контрактам с Microsoft и Oracle. Кроме того, идёт строительство ИИ ЦОД для проекта Stargate, поддерживаемого SoftBank и Oracle. Своим инвесторам OpenAI заявила, что к 2030 году Stargate обеспечит ¾ вычислительных мощностей, необходимых компании.
21.03.2025 [08:15], Руслан Авдеев
NVIDIA и xAI присоединились к $30-млрд инфраструктурному ИИ-консорциуму, возглавляемому Microsoft и BlackRock
blackrock
hardware
microsoft
nvidia
xai
возобновляемая энергия
ии
инвестиции
строительство
сша
финансы
цод
энергетика
NVIDIA и xAI присоединились к консорциуму, намеренному инвестировать $30 млрд в развитие ИИ-инфраструктуры. Консорциум AI Infrastructure Partnership (AIP), ранее известный как Global AI Infrastructure Investment Partnership, был сформирован Microsoft, BlackRock, Global Infrastructure Partners (GIP, принадлежит BlackRock) и дубайской государственной инвесткомпанией MGX (создана при участии Mubadala и G42) в сентябре 2024 года, Silicon Angle. 
Источник изображения: Troy Mortier/Unsplash.com На начальном этапе консорциум намерен инвестировать в ИИ-проекты более $30 млрд, а в долгосрочной перспективе — $100 млрд. В основном речь идёт об инвестициях в дата-центры и энергетическую инфраструктуру, преимущественно в США. Консорциум сообщил, что уже привлёк значительные средства и вызвал интерес у бизнеса. До того, как NVIDIA объявила о намерении присоединиться к AIP, она выступала техническим консультантом консорциума в области ИИ ЦОД. Эту роль она сохранит. Также стало известно, что с AIP работают производитель оборудования для энергетической отрасли GE Vernova, в прошлом году отделившийся от General Electric, и крупнейшая в США коммунальная компания NextEra Energy, занимающаяся электроснабжением. Она же является крупнейшим в мире провайдером в области ветроэнергетики. GE Vernova будет работать с AIP и партнёрами над формированием цепочек поставок. NextEra Energy поможет в масштабировании критически важных и разнообразных энергетических решений для ИИ ЦОД. Некоторые из поддерживающих AIP компаний также участвуют и в других инициативах по финансированию развития ИИ-инфраструктуры. В прошлом году Microsoft с Constellation Energy Generation объявили о возобновлении работы АЭС Three Mile Island. Обновление объекта обойдётся в $1,6 млрд. После того, как тот заработает приблизительно в 2026 году, все 837 МВт пойдут на питание дата-центров Microsoft. NVIDIA параллельно участвует в проекте Stargate.
20.03.2025 [15:58], Сергей Карасёв
Supermicro анонсировала петабайтное 1U-хранилище All-Flash на базе Arm-суперчипа NVIDIA GraceКомпания Supermicro представила сервер ARS-121L-NE316R в форм-факторе 1U, на базе которого могут формироваться системы хранения данных петабайтной вместимости. В основу новинки положен суперчип NVIDIA Grace со 144 ядрами Arm Neoverse V2 и 960 Гбайт памяти LPDDR5x. Устройство оборудовано 16 фронтальными отсеками для NVMe-накопителей E3.S 1T. При использовании SSD ёмкостью 61,44 Тбайт суммарная вместимость может достигать 983 Тбайт. При этом до 40 серверов могут быть установлены в одну стойку, что обеспечит 39,3 Пбайт «сырой» ёмкости. Новинка располагает двумя внутренними посадочными местами для M.2 NVMe SSD и двумя слотами PCIe 5.0 x16 для карт типоразмера FHHL. Присутствуют сетевой порт управления 1GbE (RJ45), порт USB 3.0 Type-A и разъём mini-DP. Габариты сервера составляют 772,15 × 438,4 × 43,6 мм, масса — 19,8 кг без установленных накопителей. 
Источник изображения: Supermicro Питание обеспечивают два блока мощностью 1600 Вт с сертификатом 80 Plus Titanium. Применена система воздушного охлаждения с восемью съёмными вентиляторами диаметром 40 мм. Диапазон рабочих температур — от +10 до +35 °C. При необходимости сервер может быть оснащён двумя DPU NVIDIA BlueField-3 или двумя адаптерами ConnectX-8. Система подходит для поддержания рабочих нагрузок с интенсивным обменом данными, таких как ИИ-инференс, аналитика и пр. Отмечается, что при создании новинки Supermicro тесно сотрудничала с NVIDIA и WEKA (разработчик платформ хранения данных).
20.03.2025 [01:10], Владимир Мироненко
Анонсированы суперускорители на Rubin и Rubin Ultra, в которых NVIDIA не будет ошибаться в подсчётахNVIDIA анонсировала ИИ-ускорители следующего поколения Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Выход Rubin Ultra запланирован на II половину 2027 года. Компанию им составят Arm-процессоры Vera. Серия названа в честь астронома Веры Купер Рубин (Vera Florence Cooper Rubin), известной своими исследованиями тёмной материи. NVIDIA отметила, что в названии предыдущих ускорителей была «допущена ошибка». В Blackwell каждый чип состоит из двух GPU, но, например, в названии GB200/GB300 NVL72 упоминается только 72 GPU, хотя речь фактически идёт о 144 GPU. Поэтому, начиная с Rubin компания будет использовать новую схему наименований, которая больше не учитывает количество чипов, а относится исключительно к количеству GPU. Таким образом, следующее поколение суперускорителей, упакованных в ту же стойку Oberon, что используется для Grace Blackwell, получило название Vera Rubin NVL144. Rubin во многом повторяет дизайн Blackwell, поскольку R200 всё так же включает два кристалла GPU (в составе SXM7), способных выдавать до 50 Пфлопс в вычислениях FP4 (без разреженности), и 288 Гбайт памяти в восьми стеках 12-Hi, но на этот раз уже HBM4 с общей пропускную способностью 13 Тбайт/с (2048-бит шина). Кристаллы GPU будут изготовлены по техпроцессу TSMC N3P, а компанию им составят два IO-чиплеты, отвечающие за все внешние коммуникации, пишет SemiAnalysis. Всё вместе будет упаковано посредством CoWoS-L. TDP новинок не указывается. 
Источник изображений: NVIDIA Чипы перейдут на интерконнект NVLink 6 со скоростью 1,8 Тбайт/с в каждую сторону (3,6 Тбайт/с в дуплексе), что вдвое выше, чем у текущего поколения NVLink 5. Аналогичным образом вырастет и коммутационная способность NVSwitch, а также NVLink C2C. Впрочем, при сохранении прежней схемы, когда один CPU обслуживает два модуля GPU, каждому из последних, по-видимому, достанется половина пропускной способности шины. Собственно процессор Vera получит 88 кастомных (а не Neoverse CSS в случае Grace) 3-нм Arm-ядра, причём с SMT, что даст 176 потоков. Каждый CPU получит порядка 1 Тбайт LPDRR-памяти и будет вдвое быстрее Grace при теплопакете в районе 50 Вт.  По словам NVIDIA, VR200 NVL144 будет в 3,3 раза быстрее: 3,6 Эфлопс в FP4-вычислениях для инференса и 1,2 Эфлопс в FP8 для обучения. Суммарный объём HBM-памяти составит более 20,7 Тбайт, системной памяти — 75 Тбайт. Внешняя сеть будет представлена адаптерами ConnectX-9 SuperNIC со скоростью 1,6 Тбит/с на порт, что вдвое больше, чем у ConnectX-8, обслуживающих GB300.  Во II половине 2027 года появится ускоритель Rubin Ultra (R300) с FP4-производительностью более 100 Пфлопс (без разреженности), объединяющий сразу четыре GPU, два IO-чиплета и 16 стеков HBM4e-памяти 16-Hi общим объёмом 1 Тбайт (32 Тбайт/с) в упаковке SXM8. Более того, ускорители, по-видимому, получат ещё и LPDDR-память. Процессор Vera перекочует в новую платформу без изменений, один CPU будет приходиться на четыре GPU. Внутренней шиной станет NVLink 7, которая сохранит скорость NVLink 6, зато получит вчетверо более производительные коммутатор NVSwitch. А вот внешнее подключение по-прежнему будут обслуживать адаптеры ConnectX-9.  Новая стойка Kyber полностью поменяет компоновку. Узлы теперь напоминают вертикальные блейд-серверы, используемые в суперкомпьютерах. Каждый узел (VR300) будет включать один процессор Vera и один ускоритель Rubin Ultra. Всего таких узлов будет 144, что в сумме даёт 144 CPU, 576 GPU и 144 Тбайт HBM4e. Суперускоритель Rubin Ultra NVL576 будет потреблять 600 кВт и обеспечит быстродействие в 15 Эфлопс для инференса (FP4) и 5 Эфлопс для обучения (FP8). При этом упоминается, что объём быстрой (fast) памяти составит 365 Тбайт, но сколько из них достанется CPU, не уточняется. Дальнейшие планы NVIDIA включают выход во II половине 2028 года первого ускорителя на новой архитектуре Feynman, названной в честь физика-теоретика Ричарда Филлипса Фейнмана (Richard Phillips Feynman). Сообщается, что Feynman будет полагаться на память HBM «следующего поколения» и, вероятно, на CPU Vera. Это поколение также получит коммутаторы NVSwitch 8 (NVL-Next), сетевые коммутаторы Spectrum7 и адаптеры ConnectX-10.
19.03.2025 [11:49], Сергей Карасёв
NVIDIA анонсировала мини-суперкомпьютер DGX Spark для ИИ-задачВместе с рабочей станцией DGX Station компания NVIDIA представила и мини-систему DGX Spark: это, как утверждается, самый компактный в мире суперкомпьютер для ИИ-задач. Система заключена в корпус с размерами всего 150 × 150 × 50,5 мм, а масса составляет около 1,2 кг. Новинка создавалась по проекту DIGITS. Основой служит платформа Blackwell Ultra с суперчипом Grace Blackwell GB10. Изделие содержит ускоритель Blackwell с тензорными ядрами пятого поколения, связанный посредством NVLink-C2C с 20-ядерным процессором Grace, который объединяет по 10 ядер Arm Cortex-X925 и Arm Cortex-A725. Заявленная ИИ-производительность достигает 1 Пфлопс на операциях FP4. Мини-ПК располагает 128 Гбайт памяти LPDDR5x с 256-бит шиной и пропускной способностью до 273 Гбайт/с. Установлен M.2 NVMe SSD вместимостью 1 или 4 Тбайт с шифрованием информации. Применяется сетевой адаптер NVIDIA ConnectX-7 SmartNIC. Кроме того, присутствуют контроллеры Wi-Fi 7 и Bluetooth 5.3. 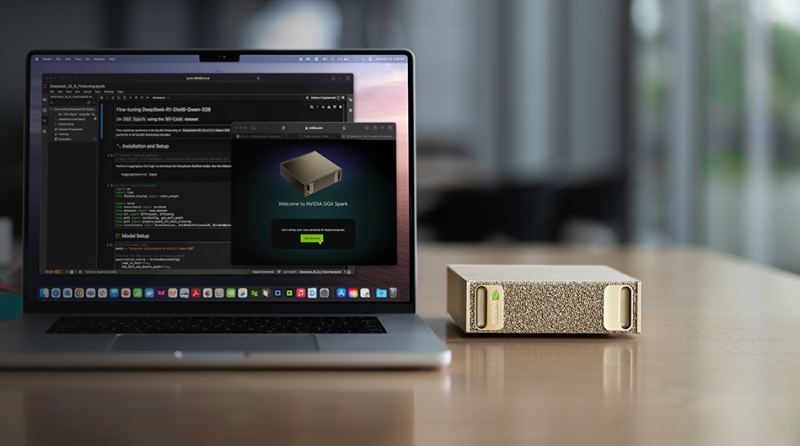
Источник изображений: NVIDIA В набор интерфейсов входят четыре порта USB 4 Type-C (до 40 Гбит/с), коннектор RJ45 для сетевого кабеля (10GbE), разъём HDMI 2.1a. Заявленное энергопотребление составляет 170 Вт. Компьютер функционирует под управлением NVIDIA DGX OS — модификации Ubuntu, адаптированной для работы с ИИ.  Отмечается, что новинка позволяет локально запускать «рассуждающие» ИИ-модели DeepSeek, Meta✴, Google и другие с 200 млрд параметров. Программный стек NVIDIA AI предоставляет доступ к необходимым ИИ-инструментам, фреймворкам, библиотекам и предварительно обученным моделям. Приём заказов на DGX Spark уже начался. Выпуском систем на данной платформе займутся ASUS, Dell и HP.
19.03.2025 [09:56], Сергей Карасёв
NVIDIA представила персональный ИИ-суперкомпьютер DGX Station на базе GB300NVIDIA анонсировала настольный ИИ-суперкомпьютер DGX Station на аппаратной платформе Blackwell Ultra. Устройство, оснащённое суперчипом Grace Blackwell GB300, ориентировано на ресурсоёмкие нагрузки ИИ, включая задачи инференса. По заявлениям NVIDIA, система DGX Station обеспечивает производительность уровня ЦОД в настольном формате. Задействован ускоритель GB300 с 288 Гбайт памяти HBM3E, которая обеспечивает пропускную способность до 8 Тбайт/с. Ускоритель Blackwell Ultra связан с процессором Grace с 72 Arm-ядрами Neoverse V2 посредством NVLink-C2C (900 Гбайт/с). При это сам модуль ускорителя съёмный. Система несёт на борту 496 Гбайт памяти LPDDR5X (четыре модуля SOCAMM) с пропускной способностью до 396 Гбайт/с. 
Источник изображения: NVIDIA DGX Station оснащён 800G-адаптером NVIDIA ConnectX-8 SuperNIC (два порта QSFP или OSFP), а также два порта RJ45. На заднюю панель выведены четыре USB-порта Type-A и один Type-C, видеовыход MiniDP и шесть аудиоразъёмов. На самой плате присутствуют три PCIe-разъёма x16 и три слотам M.2. Кроме того, есть слот для карты с BMC. Прочие технические характеристики новинки пока не раскрываются. В качестве программной платформы применяется NVIDIA DGX OS — специализированная модификация Ubuntu, оптимизированная для работы с ИИ. Пользователи могут получить доступ к микросервисам NVIDIA NIM для быстрого развёртывания ИИ-моделей и программной экосистеме NVIDIA AI Enterprise в целом. Система демонстрирует ИИ-производительность до 20 Пфлопс в режиме FP4. Устройства DGX Station будут предлагаться такими партнёрами NVIDIA, как ASUS, Box, Dell, HPE, Lambda и Supermicro. Продажи начнутся позднее в текущем году.
19.03.2025 [08:28], Сергей Карасёв
NVIDIA представила ускоритель RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 6000 Blackwell Server Edition для требовательных приложений ИИ и рендеринга высококачественной графики. Ожидается, что новинка будет востребована среди заказчиков из различных отраслей, включая архитектуру, автомобилестроение, облачные платформы, финансовые услуги, здравоохранение, производство, игры и развлечения, розничную торговлю и пр. Как отражено в названии, в основу решения положена архитектура Blackwell. Задействован чип GB202: конфигурация включает 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. Устройство несёт на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Ускоритель RTX Pro 6000 Blackwell Server Edition использует интерфейс PCIe 5.0 x16. Энергопотребление может настраиваться в диапазоне от 400 до 600 Вт. Реализована поддержка DisplayPort 2.1 с возможностью вывода изображения в форматах 8K / 240 Гц и 16K / 60 Гц. Аппаратный движок NVIDIA NVENC девятого поколения значительно повышает скорость кодирования видео (упомянута поддержка 4:2:2 H.264 и HEVC). Всего доступно по четыре движка NVENC/NVDEC. 
Источник изображения: NVIDIA По заявлениям NVIDIA, по сравнению с ускорителем предыдущего поколения L40S Ada Lovelace модель RTX PRO 6000 Blackwell Server Edition обеспечивает многократное увеличение производительности в широком спектре рабочих нагрузок. В частности, скорость инференса больших языковых моделей (LLM) повышается в пять раз для приложений агентного ИИ. Геномное секвенирование ускоряется практически в семь раз, а быстродействие в задачах генерации видео на основе текстового описания увеличивается в 3,3 раза. Достигается также двукратный прирост скорости рендеринга и примерно такое же повышение скорости инференса рекомендательных систем. Ускоритель RTX PRO 6000 Blackwell Server Edition может использоваться в качестве четырёх полностью изолированных экземпляров (MIG) с 24 Гбайт памяти GDDR7 каждый. Это обеспечивает возможность одновременного запуска различных рабочих нагрузок — например, ИИ-задач и обработки графики. Упомянута поддержка TEE.
19.03.2025 [02:06], Владимир Мироненко
Dell представили рабочие станции Pro Max с суперускорителями GB10 и GB300Dell представила рабочие станции Dell Pro Max with GB10 и Dell Pro Max with GB300, специально созданные для разработчиков ИИ-технологий, и базирующиеся на архитектуре NVIDIA Grace Blackwell, ранее эксклюзивной для систем ЦОД. Как сообщает компания, решения Dell Pro Max легко интегрируются в экосистему Dell AI Factory, предлагая единый опыт работы с ПО NVIDIA AI Enterprise. Это гарантирует, что разработчики, использующие Dell Pro Max with GB10 и Dell Pro Max with GB300, могут свободно перемещать свои модели между средами — с рабочего стола в DGX Cloud или инфраструктуры ЦОД Dell — практически без изменений кода. 
Dell Pro Max with GB10 Источник изображений: Dell Новинки работают под управлением DGX OS и поставляются с предварительно настроенным стеком NVIDIA AI Enterprise, который в том числе включает инструменты NVIDIA Blueprints. Такой целостный подход ускоряет рабочие процессы и упрощает масштабирование, позволяя создавать и тестировать прототипы решений локально, а затем бесшовно масштабировать их в облаке или ЦОД. Объединяя эксперименты на рабочем столе и масштабируемость на уровне предприятия, Dell позволяет разработчикам ИИ с легкостью внедрять инновации, говорит компания. Dell Pro Max with GB10, созданный для разработчиков, исследователей и студентов, представляет собой компактный мощный ПК с FP4-производительностью до 1 Пфлопс. Он позволяя создавать прототипы, настраивать и развёртывать рассуждающие ИИ-модели, включащие до 200 млрд параметров. 
Dell Pro Max with GB300 В свою очередь, Dell Pro Max with GB300 позиционируется как идеальное решение для продвинутых разработчиков ИИ, которым требуется производительность ИИ-сервера на рабочем столе. Dell Pro Max with GB300 базируется на суперускорителе NVIDIA GB300 (Blackwell Ultra) с 784 Гбайт унифицированной памяти (288 Гбайт памяти HBME3e у ускорителя и 496 Гбайт LPDDR5X у CPU) и 800GbE-адаптером (ConnectX-8 SuperNIC). FP4-производительность составляет до 20 Пфлопс, что делает его идеальным решением для обучения и инференса крупномасштабных рабочих ИИ-нагрузок с использованием больших языковых моделей (LLM) с 460 млрд параметров.
18.03.2025 [23:26], Владимир Мироненко
Dell представила сервер PowerEdge XE8712 на базе NVIDIA GB200 NVL4Компания Dell представила сервер PowerEdge XE8712, предназначенный для обработки разнообразных ИИ-нагрузок и HPC, включая обучение ИИ-моделей, молекулярное моделирование, геномное секвенирование, а также моделирование процессов на финансовых рынках. 
Источник изображений: Dell В основе PowerEdge XE8712 лежит плата NVIDIA GB200 NVL4. Сервер оснащён суперчипом GB200 Grace Blackwell Superchip, включающим четыре ускорителя B200 Blackwell и два 72-ядерных Arm-процессора NVIDIA Grace.  Как отмечает производитель, благодаря возможности установки до 144 ускорителей NVIDIA Blackwell (36 узлов) в одну стойку Dell серии IR7000, XE8712 обеспечивает одну из самых высоких в отрасли плотностей размещения GPU. Это позволяет выполнять больше рабочих нагрузок ИИ и HPC в меньшем физическом пространстве, снижая эксплуатационные расходы без ущерба для вычислительной мощности.  Для отвода тепла в XE8712 используется технология прямого жидкостного охлаждения (DLC) — до 264 кВт на стойку. Dell IR7000 отличается раздельными полками питания с общей шиной питания мощностью до 480 кВт. Эта модульная ORv3-стойка легко интегрируется в различное окружения и будет совместима с серверами Dell PowerEdge следующего поколения.
18.03.2025 [23:12], Алексей Степин
Интегрированная фотоника и СЖО: NVIDIA анонсировала 800G-коммутаторы Spectrum-X и Quantum-XГонка в области ИИ накладывает отпечаток на облик ЦОД: сетевая инфраструктура становится всё сложнее и сложнее в погоне за высокой пропускной способностью и минимальными задержками. За это приходится платить повышенным расходом энергии на обеспечение работы оптических трансиверов. Поэтому NVIDIA представила новое поколение коммутаторов с интегрированной кремниевой фотоникой, которое должно решать эту проблему, а заодно обеспечить повышенную надёжность и скорость развёртывания сетевой инфраструктуры. По оценкам NVIDIA, традиционный облачный дата-центр на каждые 100 тысяч серверов расходует 2,3 МВт энергии на обеспечение работы оптических трансиверов, но в ИИ-кластерах, где каждому ускорителю нужно своё быстрое сетевое подключение, эта величина может достигать уже 40 МВт, т.е. до 10 % от общего уровня энергопотребления всего комплекса. Гораздо разумнее было тратить эту энергию на вычислительную, а не сетевую инфраструктуру. 
Источник здесь и далее: NVIDIA Новые коммутаторы Spectrum-X и Quantum-X должны решить эту проблему кардинально. В них применены новые ASIC, объединяющие на одной подложке чип-коммутатор и фотонные модули. Такой подход позволяет отказаться сразу от нескольких звеньев традиционной цепочки, входящих в классический оптический трансивер. Современный высокоскоростной трансивер включает восемь лазеров, которые потребляют порядка 10 Вт, и DSP-блок, который требует 20 Вт. 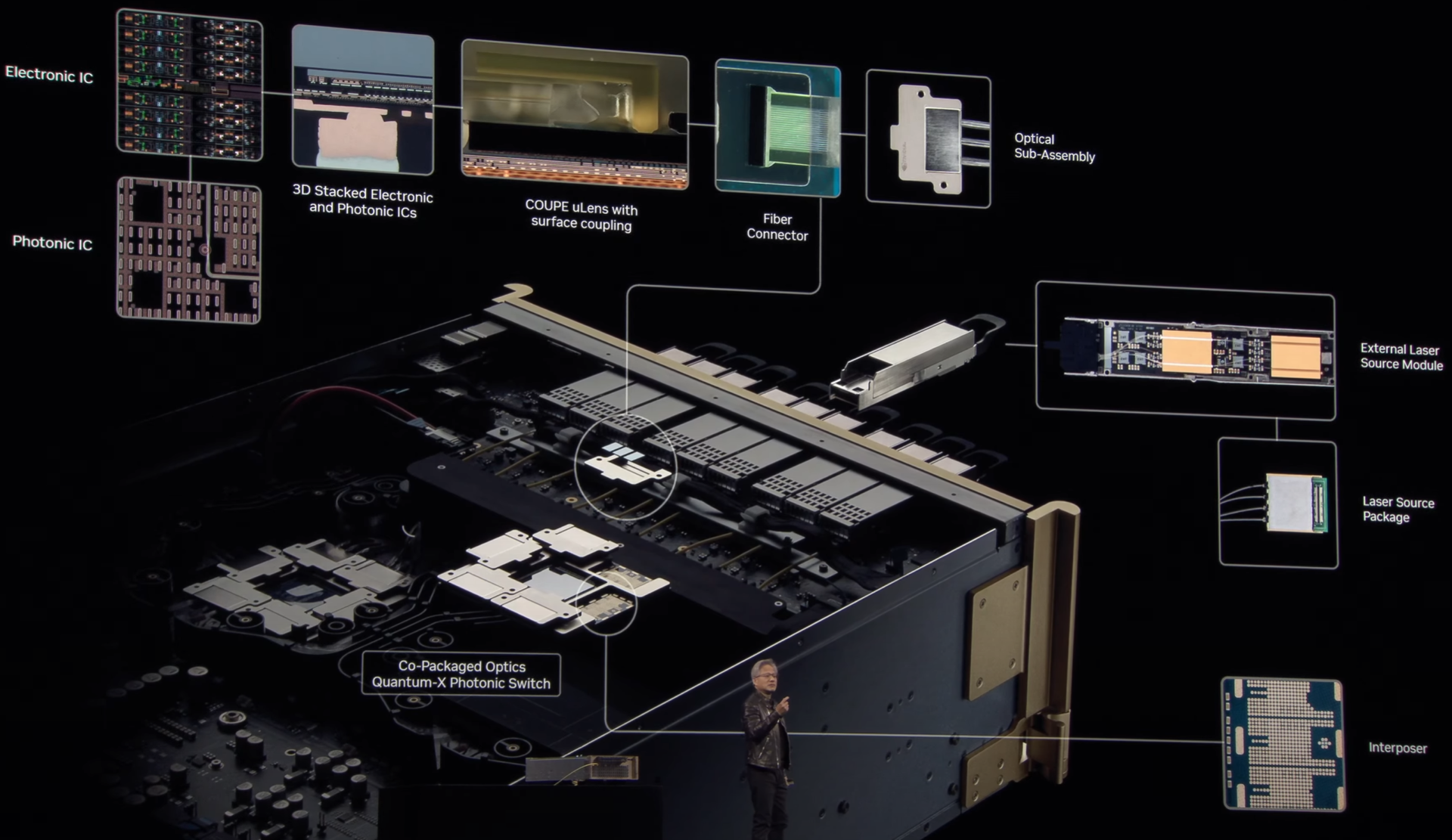 Интегрированная фотоника позволяет обойтись всего двумя внешними лазерами для обеспечения работы одного порта 1,6 Тбит/с. Лазеры соединяется в этой схеме непосредственно с фотонным модулем на борту новых ASIC. Собственно оптический движок в составе ASIC потребляет всего 7 Вт, ещё 2 Вт требует лазер. Разница в энергопотреблении минимум трёхкратная.  Кроме того, упрощение схемы соединений способствует повышению надёжности: NVIDIA говорит о 63-кратном улучшении целостности сигнала, которому не приходится добираться через несколько электрических соединений от ASIC до трансивера и внутри последнего, и о десятикратном повышении общей надёжности сети. Если в традиционной схеме потери сигнала на его электрическом пути могут составлять 22 дБ, то для схемы с фотонным модулем этот показатель составляет всего 4 дБ.  Новая схема упаковки ASIC достаточно сложна: в ней реализованы разъёмные оптические соединители, позволяющие реализовывать сценарии с различной конфигурацией портов коммутаторов, со скоростями от 200 до 800 Гбит/с. Флагманский коммутатор Spectrum SN6800 включает 512 портов 800GbE с совокупной скоростью коммутации 409,6 Тбит/с. Модель SN6810 компактнее, она предлагает 128 портов 800GbE и коммутацию до 102,4 Тбит/с.  Серия Quantum-X пока представлена моделью Quantum 3450-LD: 144 порта 800G InfiniBand с совокупной производительностью 115 Тбит/с. Сочетание высокой плотности с такими скоростями потребовала разработки и интеграции кастомной системы жидкостного охлаждения. Новые коммутаторы Quantum-X станут доступны во II половине этого года, а Spectrum-X — во II половине 2026 года.  В оптических движках собственной разработки NVIDIA использованы микрокольцевые модуляторы (MRM), реализация которых стала доступной благодаря сотрудничеству NVIDIA с TSMC в области упаковки «многоэтажных» чипов COUPE. Помимо TSMC в создании новых коммутаторов приняли участие компании Browave, Coherent, Corning Incorporated, Fabrinet, Foxconn, Lumentum, SENKO, SPIL, Sumitomo Electric Industries и TFC Communication.  Особенно серьёзно преимущества новой схемы проявляют себя в больших масштабах, на уровне сотен тысяч ускорителей. Время развёртывания снижается в 1,3 раза, а общая надёжность сети становится на порядок выше. Правда, пока что речь идёт только о коммутаторах — оптические кабели будут напрямую подключаться к их портам. Однако другой конец кабеля всё равно будет уходить в трансивер, обслуживающий отдельный ускоритель или узел. Также пока нет никаких планов по переводу NVLink на «оптику», поскольку внутри узла и NVL-стойки работать с «медью» по-прежнему проще и выгоднее. |
|

