Материалы по тегу: gpu
|
29.03.2025 [10:11], Алексей Степин
Bolt Graphics анонсировала универсальную видеокарту со слотами SO-DIMM, которая может потягаться с RTX 5080Все современные графические ускорители предлагаются с жёстко заданным при производстве объёмом видеопамяти, а в наиболее производительных моделях память типа HBM вообще интегрирована на одной с основным кристаллом подложке. Однако требования к объёму памяти в последнее время растут быстрее, а за дополнительный объём вендор просят всё больше. Кардинально иной подход предлагает компания Bolt Graphics, недавно анонсировавшая серию ускорителей Zeus. Несмотря на «ИИ-пандемию», Bolt Graphics в своём анонсе не делает упор на искусственный интеллект, а называет Zeus первым GPU, специально созданным для целей HPC, рендеринга, трассировки лучей и даже компьютерных игр. Что интересно, в основе Zeus лежит не некая закрытая архитектура: скалярная часть нового GPU построена на базе спецификации RISC-V RVA23, векторная представлена FP64 ALU на базе несколько модифицированной RVV 1.0. Прочие функции реализованы путём кастомных расширений и отдельных блоков-ускорителей. Все они пользуются общим кешем объёмом 128 Мбайт. Дополняет картину блок телеметрии и внутренний интерконнект для общения с другими вычислительным блоками. 
Zeus 1c26-032 (Источник изображений: Bolt Graphics) Используется чиплетный подход. Базовый «строительный блок» Zeus 1c26-032 включает GPU-чиплет, который соединён с 32 Гбайт набортной памяти LPDDR5x (273 Гбайт/с) и контроллером внешней памяти DDR5 (90 Гбайт/с), т.е. при желании можно установить ещё 128 Гбайт RAM (два модуля SO-DIMM). В GPU-чиплет встроены контроллеры DisplayPort 2.1a и HDMI 2.1b, а с внешним миром он общается посредством IO-чиплета, с которым он соединён 256-Гбайт/с каналом. IO-чиплет предлагает необычный набор портов. Помимо сразу двух интерфейсов PCIe 5.0 x16 (64 Гбайт/с каждый) имеется выделенный порт RJ-45 для BMC и 400GbE-порт QSFP-DD. Наконец, есть аппаратный блок видеокодирования, способный справиться с двумя потоками 8K@60 AV1/H.264/H.265.  Заявленный уровень производительности в векторных FP64/FP32/FP16-вычислениях составляет 5/10/20 Тфлопс, а в матричных INT16/INT8 — 307,2/614,4 Топс. Аппаратный блок ускорения лучей (path tracing) выдаёт до 77 гигалучей. Для сравнения: NVIDIA RTX 5090 способна выдавать 32 гигалуча, а FP64-производительность составляет 1,6 Тфлопс. В то же время в расчётах пониженной точности актуальные решения NVIDIA всё равно быстрее Zeus 1c26-032. Однако у новинки есть важное преимущество — её уровень TDP составляет всего 120 Вт. Второй интерфейс PCIe 5.0 x16 можно использовать для прямого объединения двух карт. 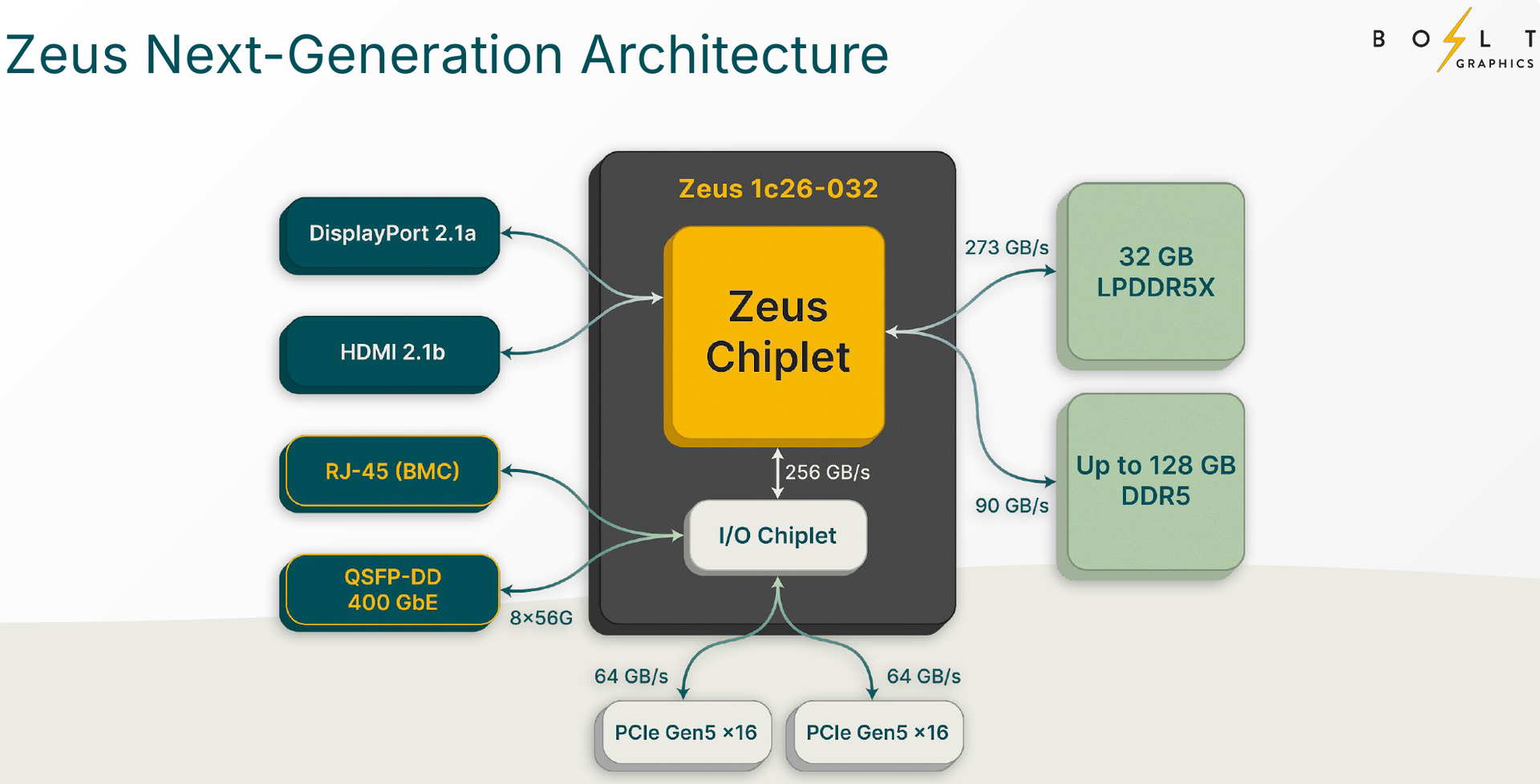 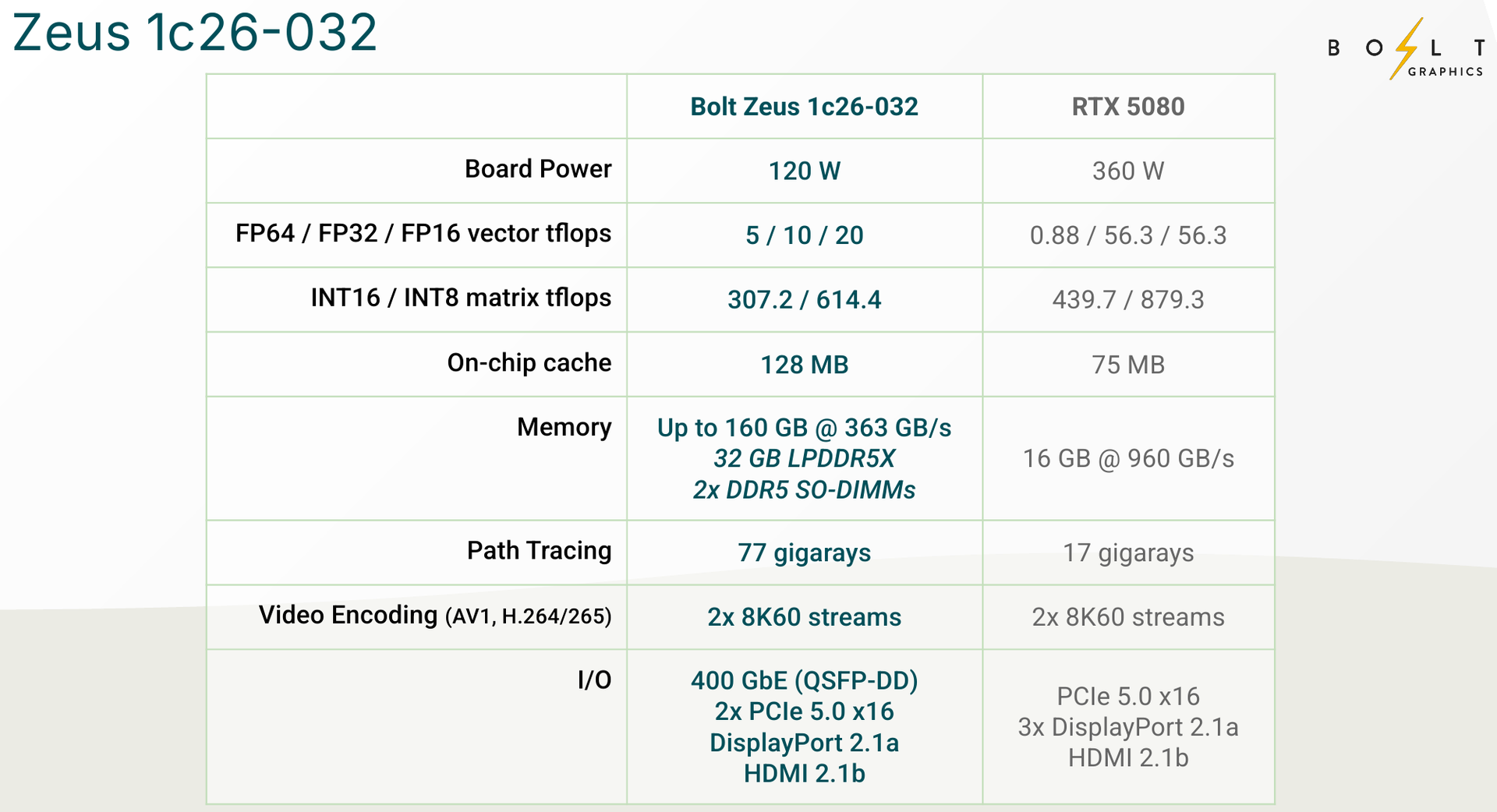 Вариант ускорителя с двумя чиплетами носит название Zeus 2c26-064/128, а с четырьмя — 4c26-256. Последние числа обозначают объём распаянной памяти LPDDR5X. Что касается расширяемой памяти, то количество доступных разъёмов SO-DIMM также зависит от модели и составляет до восьми, так что во флагманской конфигурации базовые 256 Гбайт LPDDR5x можно дополнить аж 2 Тбайт DDR5. Производительность с увеличением количеств GPU-чиплетов растёт практически пропорционально, но есть некоторые другие нюансы. Так, в Zeus 2c26-064 и Zeus 2c26-128 (оба варианта имеют TDP 250 Вт) есть только один IO-чиплет, а GPU-чиплеты объединены шиной со скоростью 768-Гбайт. 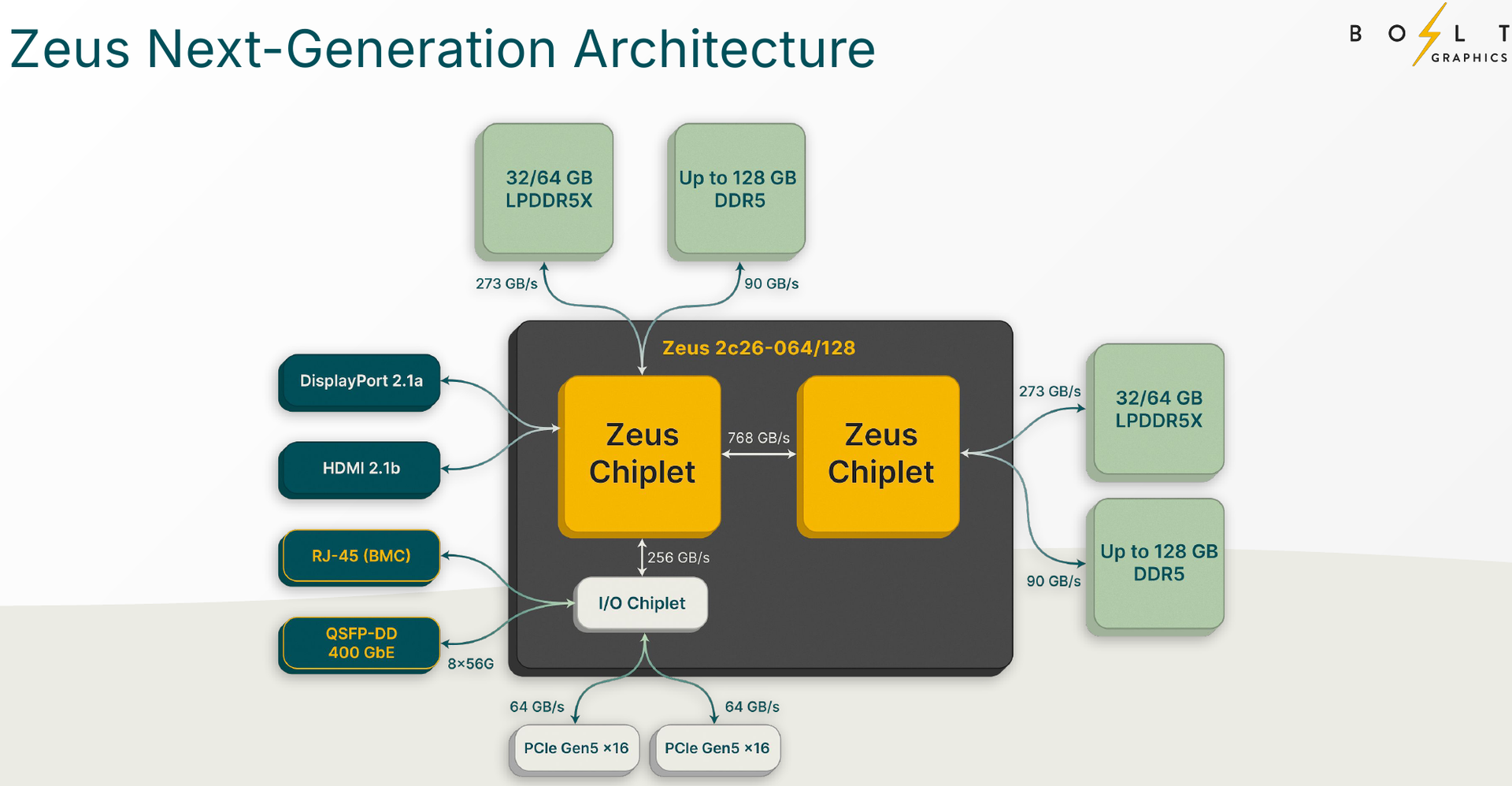  Zeus 4c26-256 имеет сразу четыре I/O чиплета в составе, которые дают восемь контроллеров PCIe 5.0 x4 (один чиплет, совокупно 32 линии) и шесть 800GbE-портов OSFP (три чиплета). Между собой GPU-чиплеты объединены шиной со скоростью 512-Гбайт/с. Каждый из них соединён с собственным IO-чиплетом на скорости 256 Гбайт/с. Теплопакет флагмана составляет 500 Ватт, ускоритель, если верить Bolt Graphnics, развивает 20 Тфлопс в режиме FP64, почти 2500 Топс на вычислениях FP8 и способен обрабатывать до 307 гигалучей. 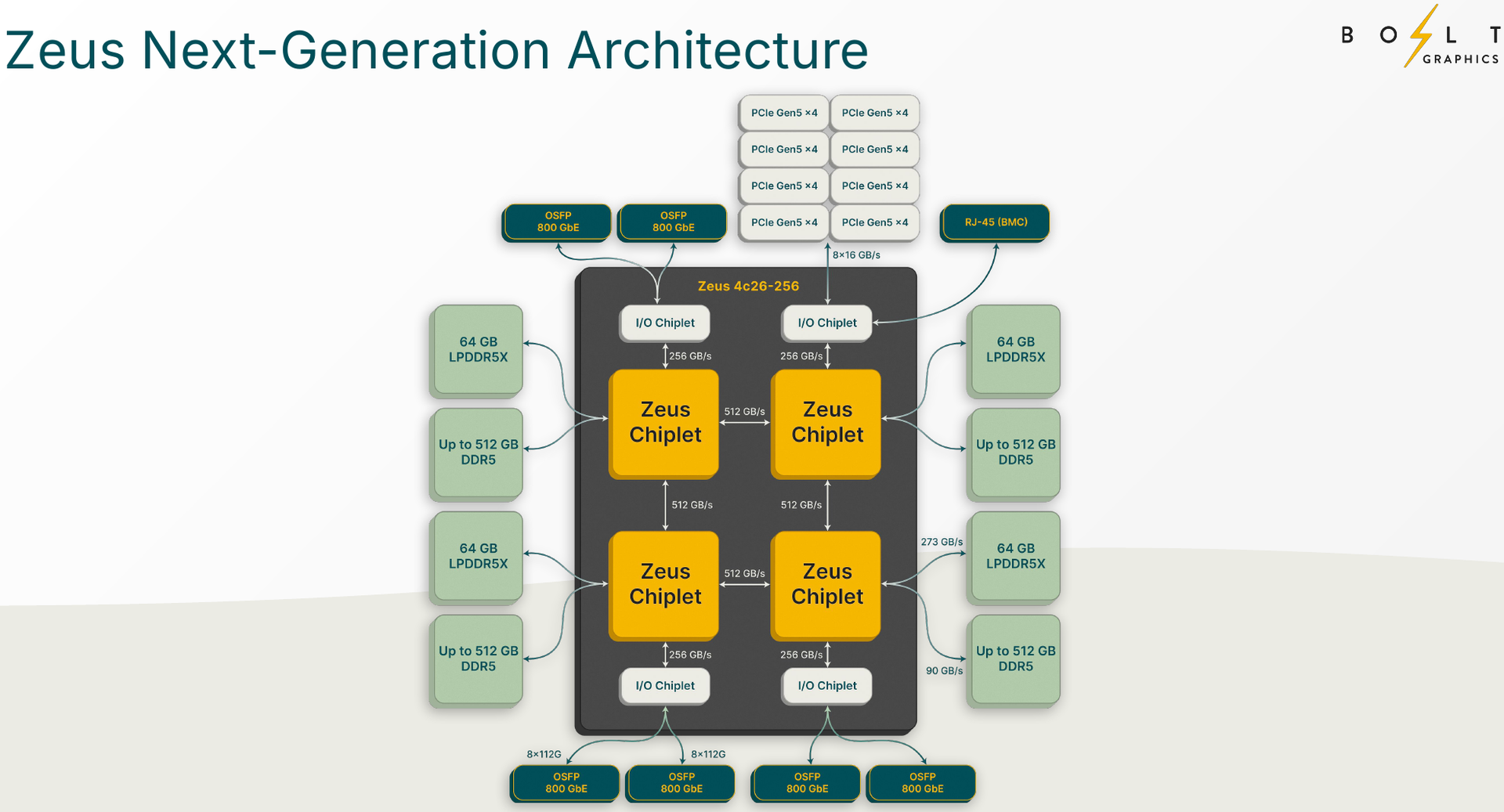 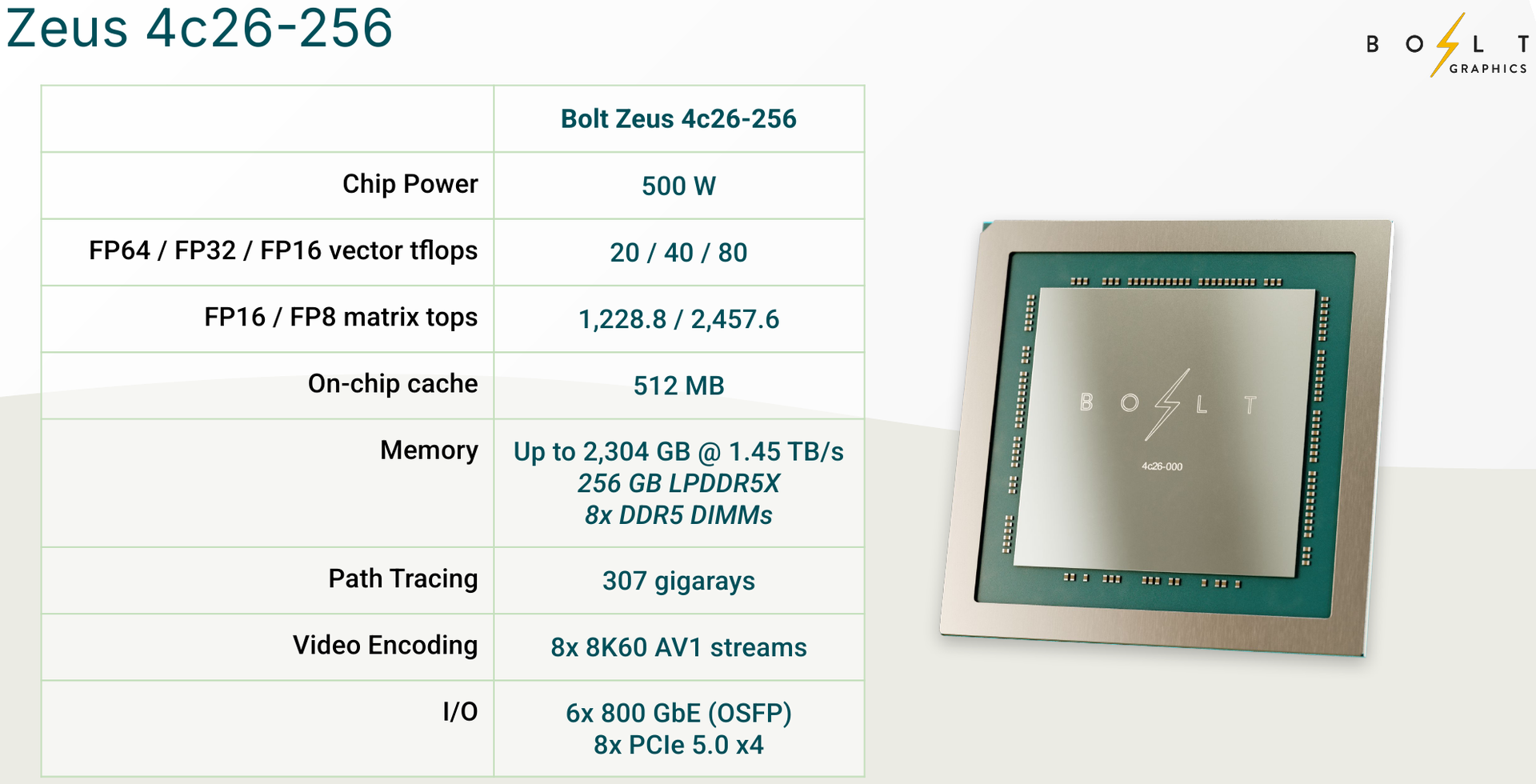 Разработчики явно заложили в своё детище широкие возможности кластеризации, о чём свидетельствует наличие мощной сетевой подсистемы. Поддерживаются как скромные конфигурации из двух GPU, соединённых непосредственно по Ethernet 400GbE, так и масштабные системы уровня стойки, содержащей 80 плат Zeus 4c26-256, соединённых как с коммутатором, так и напрямую друг с другом. Такой кластер потребляет 44 кВт, но зато способен обеспечивать запуск крупных физических симуляций или обучение ИИ моделей за счёт огромного массива общей памяти, составляющего 160 Тбайт. Вычислительная производительность такого кластера достигает 1,6 Пфлопс в режиме FP64 и 196 Попс в режиме FP8. 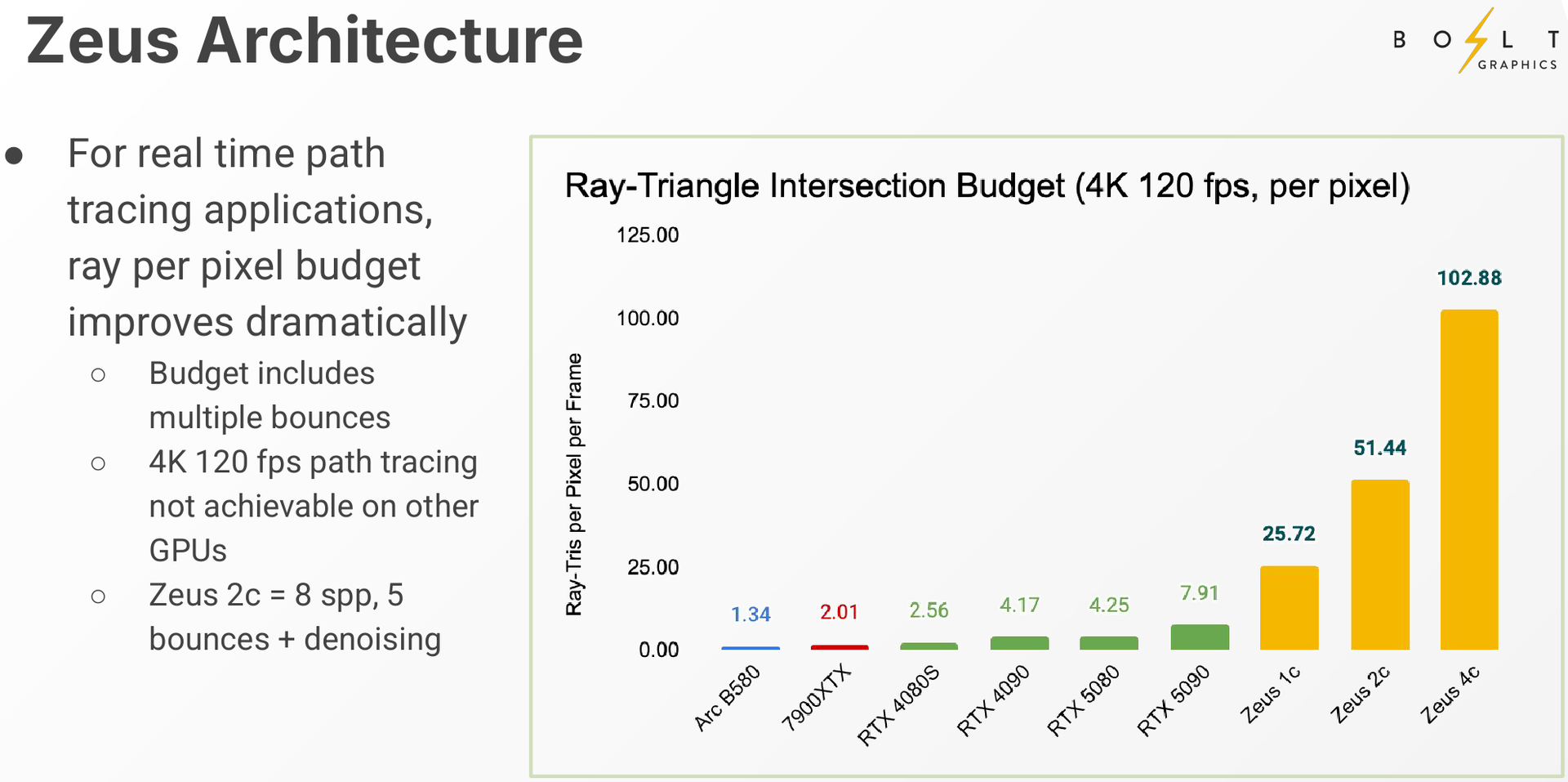  Одной из особенностей новинок является трассировщик лучей Glowstick, способный работать в режиме реального времени практически во всех современных пакетах 3D-моделирования или видеоредактирования, таких как Maya, 3ds Max, Blender, SketchUp, Houdini и Nuke. Он будет дополнен фирменной библиотекой Bolt MaterialX, содержащей более 5000 текстур высокого качества. А благодаря поддержке стандарта OpenUSD он сможет легко интегрироваться в любую цепочку рендеринга и пост-обработки. Также запланирован электромагнитный симулятор Bolt Apollo. Обещаны фирменные драйверы Vulkan/DirectX и SDK с использованием LLVM. 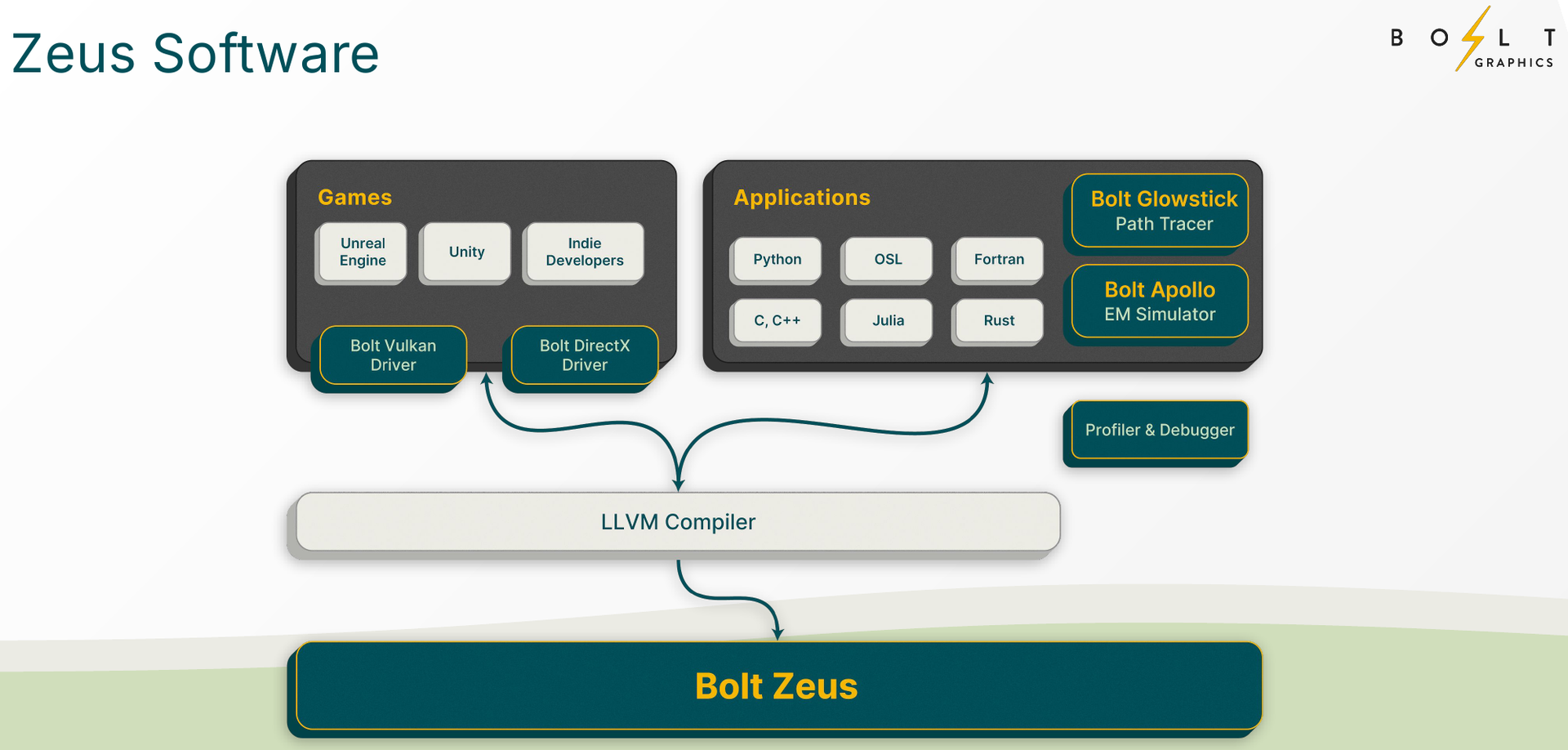 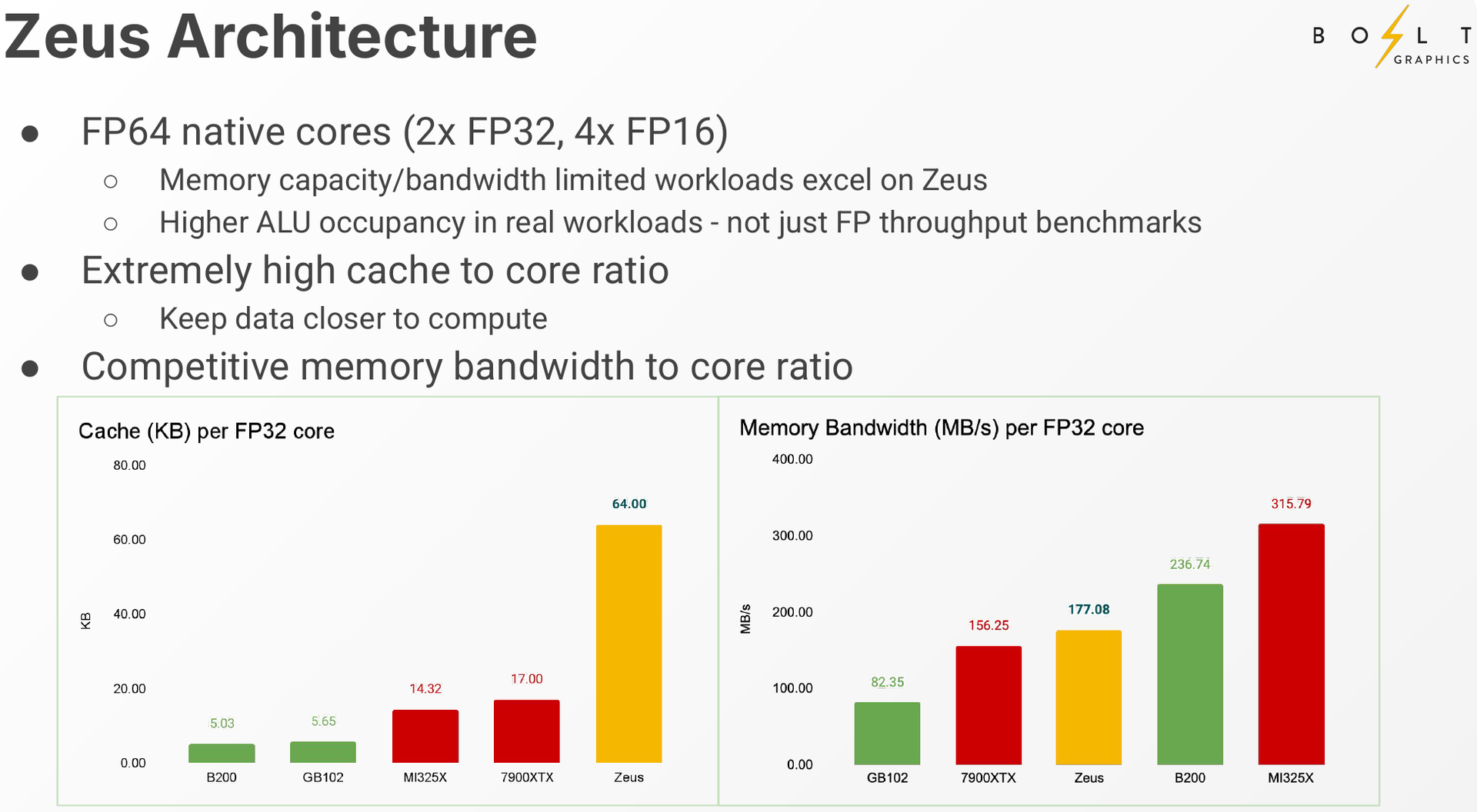 Ранний доступ к комплектам разработчика Bolt Graphics наметила на IV квартал текущего года. В III квартале 2026 года должны появиться 2U-серверы на базе Zeus, а массовые поставки серверов и PCIe-карт начнутся не ранее IV квартала того же года. Пока сложно сказать, насколько хорошо новая архитектура себя проявит, но если верить предварительным тестам Zeus, выигрыш в сравнении с существующими ускорителями существенен, особенно в энергопотреблении.
27.03.2025 [10:21], Сергей Карасёв
HighPoint представила шасси RocketStor для подключения мощных ИИ-ускорителей к компактным рабочим станциямКомпания HighPoint анонсировала внешние шасси серии RocketStor, предназначенные для подключения мощных ИИ-ускорителей к рабочим станциям, у которых внутри корпуса отсутствует необходимое пространство для установки двух- или трёхслотовых карт расширения. Дебютировали изделия RocketStor 8531AW и RocketStor 8631CW с поддержкой интерфейса PCIe 4.0 x16 и PCIe 5.0 x16 соответственно. Применён PCIe-коммутатор roadcom PEX 89048. Устройства, как утверждается, позволяют полностью раскрыть потенциал новейших ускорителей NVIDIA, AMD и Intel. Соединение с хостом осуществляется через низкопрофильную карту расширения Rocket 1634C посредством метрового кабеля CDFP. Заявлены «надёжность корпоративного уровня и подключение с малой задержкой». 
Источник изображений: HighPoint Корпуса RocketStor оборудованы активным охлаждением с двумя вентиляторами с интеллектуальным управлением скоростью вращения крыльчатки: применённая система предотвращает перегрев, обеспечивая стабильную высокопроизводительную работу, говорит компания. Возможно также ручное управление с пятью режимами. Диапазон рабочих температур простирается от +5 до +55 °C. Заявлена совместимость с картами полной высоты в двух- и трёхслотовом исполнении с габаритами до 360 × 120 × 75 мм. Обеспечивается возможность подачи до 600 Вт для установленного GPU.  Среди областей применения изделий RocketStor названы приложения ИИ, машинного обучения и аналитики больших данных, высокопроизводительные вычисления, создание и рендеринг контента, научные исследования, рабочие нагрузки корпоративного класса и пр.
19.03.2025 [08:28], Сергей Карасёв
NVIDIA представила ускоритель RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 6000 Blackwell Server Edition для требовательных приложений ИИ и рендеринга высококачественной графики. Ожидается, что новинка будет востребована среди заказчиков из различных отраслей, включая архитектуру, автомобилестроение, облачные платформы, финансовые услуги, здравоохранение, производство, игры и развлечения, розничную торговлю и пр. Как отражено в названии, в основу решения положена архитектура Blackwell. Задействован чип GB202: конфигурация включает 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. Устройство несёт на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Ускоритель RTX Pro 6000 Blackwell Server Edition использует интерфейс PCIe 5.0 x16. Энергопотребление может настраиваться в диапазоне от 400 до 600 Вт. Реализована поддержка DisplayPort 2.1 с возможностью вывода изображения в форматах 8K / 240 Гц и 16K / 60 Гц. Аппаратный движок NVIDIA NVENC девятого поколения значительно повышает скорость кодирования видео (упомянута поддержка 4:2:2 H.264 и HEVC). Всего доступно по четыре движка NVENC/NVDEC. 
Источник изображения: NVIDIA По заявлениям NVIDIA, по сравнению с ускорителем предыдущего поколения L40S Ada Lovelace модель RTX PRO 6000 Blackwell Server Edition обеспечивает многократное увеличение производительности в широком спектре рабочих нагрузок. В частности, скорость инференса больших языковых моделей (LLM) повышается в пять раз для приложений агентного ИИ. Геномное секвенирование ускоряется практически в семь раз, а быстродействие в задачах генерации видео на основе текстового описания увеличивается в 3,3 раза. Достигается также двукратный прирост скорости рендеринга и примерно такое же повышение скорости инференса рекомендательных систем. Ускоритель RTX PRO 6000 Blackwell Server Edition может использоваться в качестве четырёх полностью изолированных экземпляров (MIG) с 24 Гбайт памяти GDDR7 каждый. Это обеспечивает возможность одновременного запуска различных рабочих нагрузок — например, ИИ-задач и обработки графики. Упомянута поддержка TEE.
17.03.2025 [10:21], Сергей Карасёв
MiTAC представила ИИ-серверы на базе Intel Xeon 6 и AMD EPYC 9005/9004Компания MiTAC Computing Technology (подразделение MiTAC Holdings) на конференции Supercomputing Asia 2025 анонсировала серверы G4520G6 и TN85-B8261, построенные на аппаратной платформе Intel и AMD соответственно. Новинки ориентированы на ресурсоёмкие задачи, связанные с ИИ, машинным обучением и НРС-нагрузками. Модель G4520G6 выполнена в форм-факторе 4U: допускается установка двух процессоров Intel Xeon 6700 в исполнении LGA4710 с показателем TDP до 350 Вт. Есть 32 слота для модулей RDIMM/RDIMM-3DS DDR5-5200/6400 и MRDIMM DDR5-8000 суммарным объёмом до 8 Тбайт. Во фронтальной части расположены восемь отсеков для SFF-накопителей NVMe U.2. Кроме того, доступны три внутренних коннектора для SSD формата М.2 22110/2280 с интерфейсом PCIe 4.0. Сервер располагает 11 слотами PCIe 5.0 x16 FHFL и тремя слотами OCP 3.0 (PCIe 5.0 x16). Возможна установка до восьми двуслотовых GPU-ускорителей. Упомянуты контроллер Aspeed AST2600, сетевой порт управления 1GbE (Realtek RTL8211F), разъёмы USB 3.0 (×2), USB 3.2 Gen1 (×2), D-Sub и последовательный порт. Питание обеспечивают четыре блока мощностью 9000 Вт с сертификатом 80 Plus Titanium. Применяется воздушное охлаждение. 
Источник изображений: MiTAC В свою очередь, модель TN85-B8261 типоразмера 2U может нести на борту два чипа AMD EPYC 9005 Turin или EPYC 9004 Genoa c величиной TDP до 500 Вт. Есть 24 слота для модулей DDR5-6000 суммарным объёмом до 6 Тбайт, восемь посадочных мест для SFF-накопителей NVMe U.2, шесть слотов PCIe 5.0 x16. Могут быть установлены до четырёх двуслотовых GPU-ускорителей полной высоты.  Предусмотрены два сетевых порта 10GbE (Intel X550-AT2), выделенный сетевой порт управления 1GbE (Realtek RTL8211F), контроллер Aspeed AST2600, четыре порта USB 3.2 Gen1 и интерфейс D-Sub. Реализовано воздушное охлаждение. Установлены два блока питания мощностью 2700 Вт с сертификатом 80 Plus Titanium. Серверы могут эксплуатироваться при температурах от +10 до +35 °C.
17.02.2025 [12:19], Сергей Карасёв
Платформа Graid SupremeRAID SE для создания массивов NVMe RAID получила поддержку NVIDIA GeForce RTX 5000Компания Graid Technology сообщила о том, что её платформа SupremeRAID SE, предназначенная для формирования высокопроизводительных массивов NVMe RAID, теперь поддерживает работу с ускорителями семейства NVIDIA GeForce RTX 5000. SupremeRAID — это программно-определяемое решение на базе GPU, предназначенное для обеспечения максимальной производительности SSD. Отмечается, что SupremeRAID SE позволяет формировать массивы RAID на 4–8 накопителях NVMe с высокой отказоустойчивостью, одновременно освобождая ресурсы CPU для других задач. Платформу SupremeRAID SE можно использовать с такими ускорителями, как GeForce RTX 5090, GeForce RTX 5080, GeForce RTX 5070 Ti, GeForce RTX 5070 и GeForce RTX 5060. Решение ориентировано прежде всего на мощные рабочие станции, предназначенные для приложений ИИ, машинного обучения, 3D-рендеринга, редактирования видеоматериалов высокого разрешения и разработки игр. По заявлениям Graid Technology, программно-определяемый RAID обладает упрощённой настройкой, которая избавлена от сложностей, присущих традиционным аппаратным решениям RAID. 
Источник изображения: Graid Technology В целом, благодаря SupremeRAID SE можно задействовать имеющиеся мощности GPU для формирования высокопроизводительных и высокоустойчивых RAID-конфигураций: поддерживаются режимы RAID 0, 1, 10, 5. Говорится о совместимости с Windows Server 2011/2022 и Windows 11, а также с широким перечнем ОС на ядре Linux, включая AlmaLinux 8.8, CentOS 7.9/8.5, Fedora 40, openSUSE Leap 15.3 (Kernel 5.3), Oracle Linux 7.9/8.7/9.1, RHEL 7.9/8.8 и Ubuntu 24.04.0, а также с более ранними версиями указанных дистрибутивов.
16.02.2025 [00:22], Сергей Карасёв
HBF вместо HBM: SanDisk предлагает увеличить объём памяти ИИ-ускорителей в 16 раз, заменив DRAM на сверхбыструю флеш-памятьКомпания SanDisk, которая вскоре станет независимой, отделившись от Western Digital, предложила способ многократного увеличения объёма памяти ИИ-ускорителей. Как сообщает ресурс ComputerBase.de, речь идёт о замене HBM (High Bandwidth Memory) на флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). На первый взгляд, идея может показаться абсурдной, поскольку флеш-память NAND значительно медленнее DRAM, которая служит основой HBM. Но, по заявлениям SanDisk, архитектура HBF позволяет обойти ограничения, присущие традиционным NAND-изделиям, что сделает память нового типа пригодной для применения в ИИ-ускорителях. При этом HBF планируется использовать прежде всего для задач инференса, а не обучения моделей ИИ. С каждым новым поколением HBM растёт объём памяти, которым оснащаются ИИ-карты: у современных ускорителей AMD и NVIDIA он достигает 192 Гбайт. Благодаря внедрению HBF компания SanDisk рассчитывает увеличить показатель в 8 или даже 16 раз при сопоставимой цене. Компания предлагает две схемы использования флеш-памяти с высокой пропускной способностью: одна предусматривает полную замену HBM на HBF, а другая — совмещение этих двух технологий. 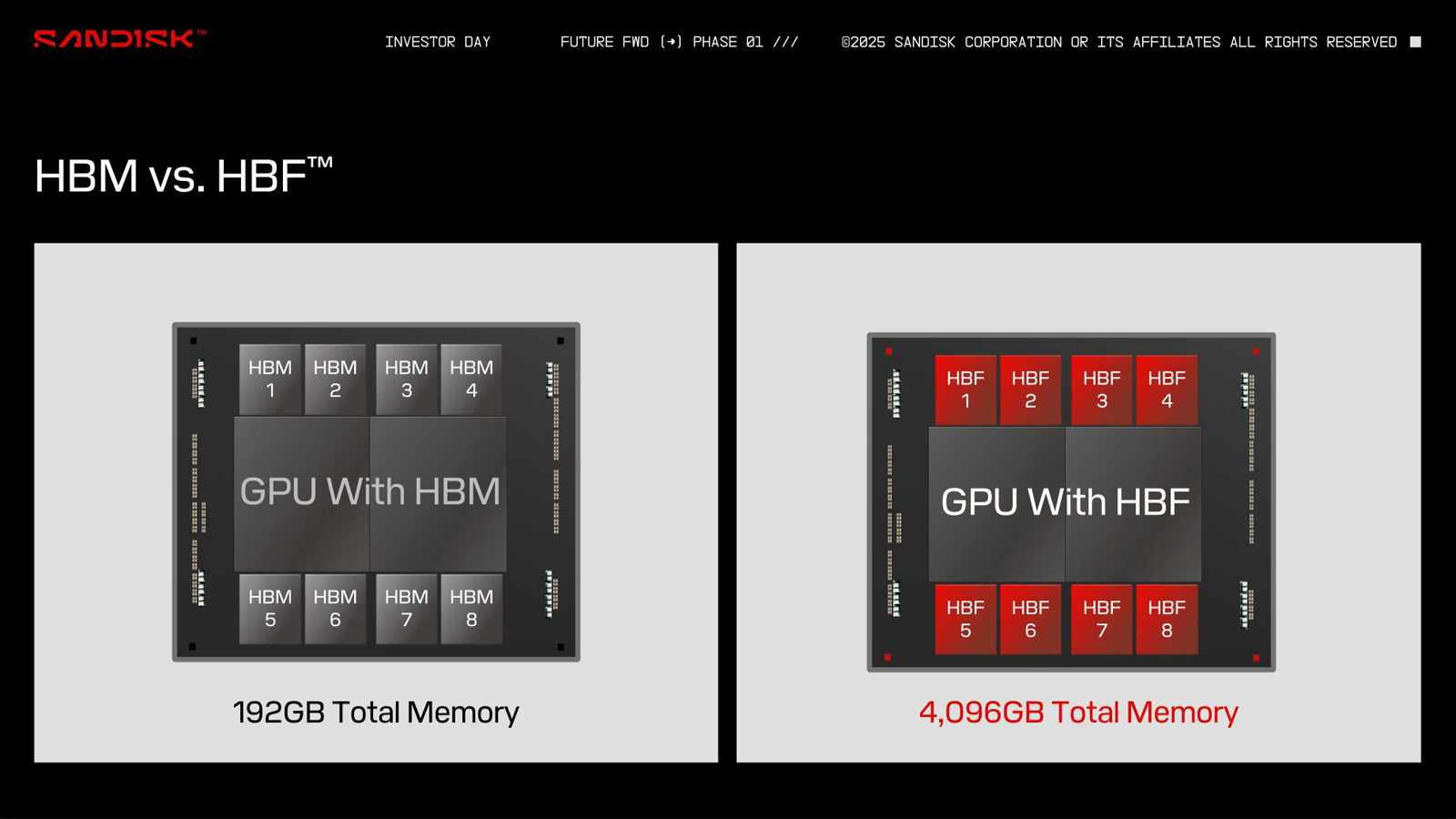
Источник изображений: ComputerBase.de В качестве примера SanDisk приводит GPU со 192 Гбайт памяти HBM, которая разделена на восемь стеков по 24 Гбайт. В случае HBF каждый такой стек сможет иметь ёмкость 512 Гбайт. Таким образом, при полной замене HBM ускоритель сможет нести на борту 4 Тбайт памяти: это позволит полностью загрузить большую языковую модель Frontier с 1,8 трлн параметров размером 3,6 Тбайт. В гибридной конфигурации можно, например, использовать связку стеков 2 × HBM плюс 6 × HBF, что в сумме даст 3120 Гбайт памяти. 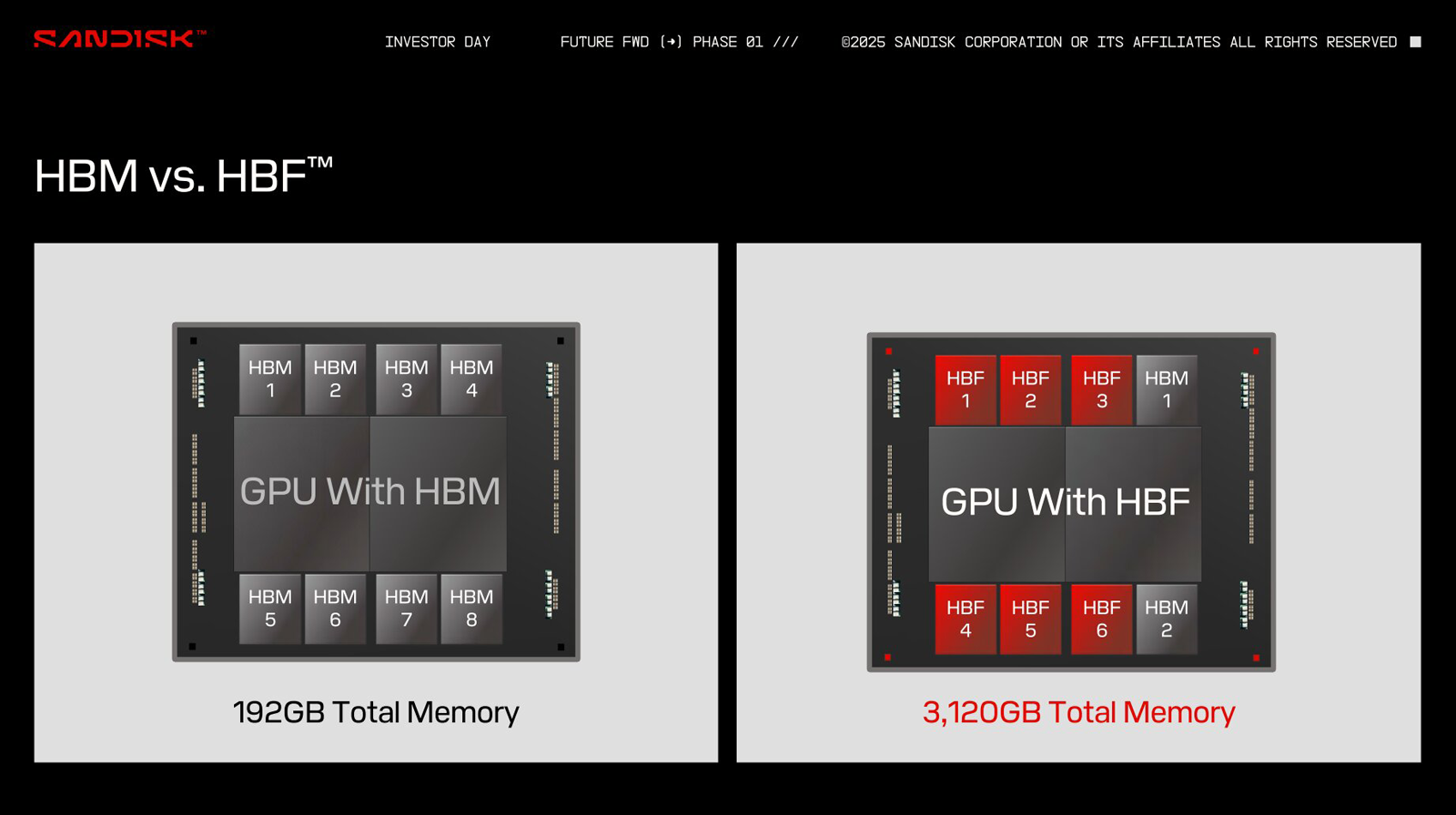 Архитектура HBF предполагает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. Обычная флеш-память NAND приближается к DRAM по пропускной способности, но не может сравниться с ней по времени доступа. SanDisk предлагает решить проблему путём разделения HBF на массив областей с большим количеством линий данных: это позволит многократно увеличить скорость доступа.  SanDisk разработала архитектуру HBF в 2024 году под «влиянием ключевых игроков в области ИИ». В дальнейшие планы входят формирование технического консультативного совета, включающего партнёров и лидеров отрасли, и создание открытого стандарта. Впрочем, есть и другие методы увеличения объёма памяти ускорителей. Один из них — использование CXL-пулов.
31.01.2025 [06:24], Сергей Карасёв
Intel решила не поставлять ускорители Falcon Shores на рынокСо-генеральный директор Intel Мишель Джонстон Холтхаус (Michelle Johnston Holthaus) дала комментарии по поводу ускорителей Falcon Shores, которые должны были поступить в продажу в 2025 году. По её словам, эти изделия не появятся на коммерческом рынке. Ожидалось, что Falcon Shores выйдут после ускорителей Rialto Bridge, которые должны были прийти на смену Ponte Vecchio. Но в марте 2023 года Intel отменила выпуск Rialto Bridge. Тогда же сообщалось, что дебют Falcon Shores откладывается. После того, как гендиректор Intel Пэт Гелсингер (Pat Gelsinger) подал в отставку, будущее Falcon Shores оказалось под вопросом. Пытаясь прояснить ситуацию, Intel заявила, что планы по выпуску этих решений сохраняются — их планировалось поставлять в качестве GPU, а не гибридных ускорителей, как говорилось изначально. Однако в конце 2024 года появилась информация, что Intel рассматривает Falcon Shores как тестовый продукт. 
Источник изображения: Intel Как теперь заявила Холтхаус, Intel действительно использует Falcon Shores «в качестве внутреннего тестового чипа» — без планов по его выводу на коммерческий рынок. По её словам, основное внимание будет уделено ускорителям Jaguar Shores, которые, как предполагается, помогут разработать «системное решение в масштабе стойки» для укрепления позиций в области дата-центров, ориентированных на задачи ИИ. «ИИ ЦОД являются привлекательным рынком для нас. Но мы пока не закрепились в данном сегменте должным образом. Поэтому мы упрощаем дорожную карту и концентрируем ресурсы», — сказала Холтхаус. Она также добавила, что заказчики хотят получить полномасштабное стоечное решение, а не просто чипы. Ожидается, что проект Falcon Shores поможет в создании комплексной платформы, охватывающей системные компоненты, сеть и память. Вероятно, речь идёт об аналоге суперускорителей NVIDIA GB200 NVL72. В целом, Intel пытается скорректировать план дальнейшей работы после ряда неудач. Корпорация катастрофически отстала от NVIDIA и AMD по продажам ИИ-ускорителей — так, объём реализации Gaudi не достиг даже $500 млн. На этом фоне Intel приходится в спешном порядке менять стратегию.
16.01.2025 [08:04], Алексей Степин
Терабайтные GPU: Panmnesia продемонстрировала CXL-память для ИИ-ускорителейКомпания Panmnesia работает в области проектирования CXL-пулов DRAM довольно давно: в 2023 году она демонстрировала систему, оставляющую позади все решения на базе RDMA и обеспечивающую доступ к 6 Тбайт оперативной памяти. Но большие объёмы памяти сегодня, в эпоху всё более усложняющихся ИИ-моделей, нужны не только и не столько процессорам, сколько ускорителям, априори лишённым возможности апгрейда набортной RAM. На выставке CES 2025 компания продемонстрировала решение данной проблемы. По мнению разработчиков Panmnesia, производительность при обучении масштабных ИИ-моделей упирается именно в объёмы набортной памяти ускорителей: вместо десятков гигабайт требуются уже терабайты, а установка дополнительных ускорителей может обходиться слишком дорого при том, что вычислительные мощности окажутся избыточными. 
Источник здесь и далее: Panmnesia Продемонстрированная на выставке CXL-система построена на базе новейшего контроллера Panmnesia с поддержкой CXL 3.1. В двунаправленном режиме латентность доступа составила менее 100 нс и находится примерно на уровне 80 нс. 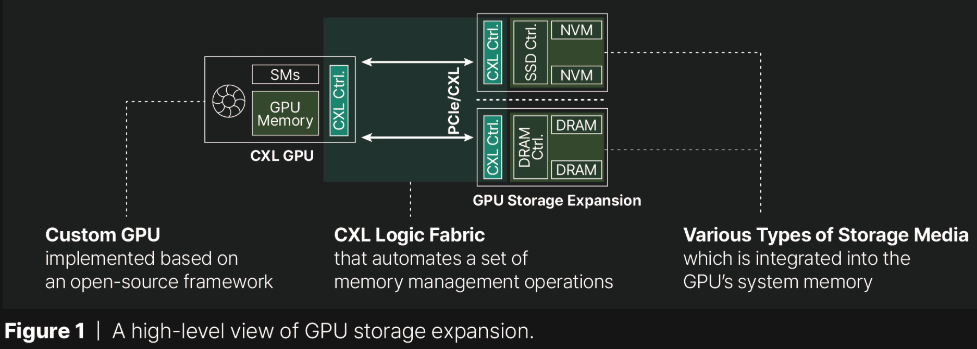 Ключ к успеху здесь кроется в фирменной реализации CXL 3.1, включая программную часть, благодаря которой GPU могут обращаться к общему пулу памяти, используя те же инструкции типа load/store, что при доступе к набортной HBM или GDDR.  Однако технология требует наличия на борту GPU фирменного контроллера CXL Root Complex, одной из важнейших частей которого является декодер HDM, отвечающий за управление адресным пространством памяти (host physical address, HPA), так что уже выпущенные ускорители напрямую работать с системой Panmnesia не смогут.  Тем не менее, технология выглядит многообещающей. Она уже привлекла внимание со стороны компаний, занимающихся ИИ, как потенциально позволяющая снизить стоимость инфраструктуры ЦОД.
30.12.2024 [15:26], Сергей Карасёв
Китайский ускоритель Moore Threads MTT X300 обеспечивает FP32-быстродействие до 14,4 ТфлопсКитайская компания Moore Threads, по сообщению ресурса TechPowerUp, подготовила к выпуску профессиональный GPU-ускоритель MTT X300. Изделие предназначено для работы с системами автоматизированного проектирования (CAD), платформами информационного моделирования зданий и сооружений (BIM), видеоредакторами и пр. Новинка выполнена в виде двухслотовой карты расширения с интерфейсом PCIe 5.0 x16. В основе лежит архитектура MUSA второго поколения с 4096 ядрами MUSA и 16 Гбайт памяти GDDR6 с 256-бит шиной (пропускная способность достигает 448 Гбайт/с). Производительность на операциях ИИ в режиме FP32 составляет до 14,4 Тфлопс. Показатель TDP равен 255 Вт. 
Источник изображения: Moore Threads @Olrak29_ on X Ускоритель оснащён тремя разъёмами DisplayPort 1.4a и одним коннектором HDMI 2.1 с возможностью вывода изображения одновременно на четыре монитора. Поддерживается разрешение до 7680 × 4320 пикселей (8К). Реализовано аппаратное ускорение при декодировании материалов AV1, H.264, H.265, VP8, VP9, AVS, AVS2, MPEG4 и MPEG2, а также при кодировании видео AV1, H.264 и H.265. Устройство поддерживает до 36 параллельных потоков 1080p (30 кадров в секунду) как для декодирования, так и для кодирования. Подчёркивается, что Moore Threads разработала для MTT X300 драйверы, обеспечивающие совместимость со всеми распространёнными архитектурами CPU, включая x86, Arm и LoongArch. 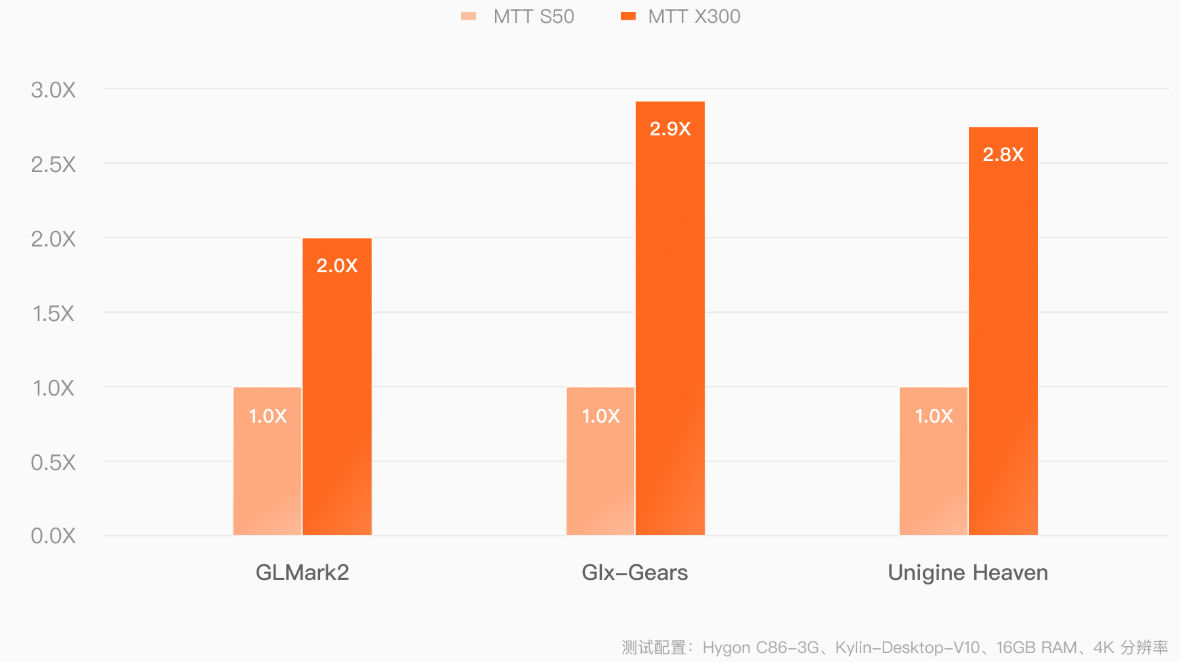
Источник: Moore Threads Нужно отметить, что ещё год назад Moore Threads представила ускоритель MTT S4000 на архитектуре MUSA третьего поколения с 48 Гбайт памяти GDDR6 с пропускной способностью до 768 Гбайт/с. Это решение демонстрирует производительность до 25 Тфлопс на операциях FP32, до 50 Тфлопс на операциях TF32, до 100 Тфлопс на операциях FP16/BF16 и 200 TOPS на операциях INT8. Карта способна обрабатывать одновременно до 96 видеопотоков 1080p.
27.12.2024 [13:44], Сергей Карасёв
Стартап Ubitium создал универсальный чип на базе RISC-V с функциями CPU, GPU, DSP и FPGAСтартап Ubitium, основанный в 2024 году, анонсировал проект по созданию чипа с универсальной архитектурой, которая полностью независима от рабочих нагрузок. Речь идёт об объединении в одном изделии решений разного типа: CPU, GPU, DSP и FPGA. Отмечается, что на протяжении более 50 лет полупроводниковая промышленность занималась созданием самостоятельных центральных, графических и других процессоров, предназначенных для решения конкретных вычислительных задач. Ubitium предлагает пересмотреть данный подход, создав универсальный чип на открытой архитектуре RISC-V, который сможет одинаково хорошо справляться с нагрузками разного типа. Стартап отмечает, что основным препятствием для внедрения новых процессоров являются проприетарные ISA, которые требуют использования специализированных программных инструментов. Кроме того, трудности может создавать отсутствие зрелой программной экосистемы, предоставляющей необходимые фреймворки и приложения. Чипы Ubitium, как утверждается, будут на 100 % совместимы с RISC-V, что упростит и ускорит разработку и внедрение конечных продуктов. 
Источник изображения: Ubitium В отличие от традиционных процессоров со специализированными ядрами, предназначенными для определённых задач, блоки универсального чипа Ubitium могут динамически «переназначаться» для обработки широкого спектра вычислительных нагрузок, включая простую логику управления, общие вычисления, ИИ и рендеринг графики. Ещё одним преимуществом предлагаемой концепции стартап называет масштабируемость. Ubitium планирует выпускать изделия разного уровня, которые при этом будут иметь идентичную архитектуру и использовать одни и те же программные инструменты. Компания рассчитывает, что её чипы смогут применяться в самых разных сферах — от встраиваемых устройств, бытовой электроники и домашней техники до систем промышленной автоматизации, роботов и космического оборудования. 
Источник изображения: Ubitium По сравнению с традиционными процессорами, использование решений Ubitium, как утверждается, обеспечит повышение гибкости, снижение стоимости и ускорение разработки. Компания заявляет, что универсальный чип может обеспечить в 10–100 раз большую производительность в расчёте на доллар по сравнению с современными специализированными решениями. В команду Ubitium входят выходцы из Intel, NVIDIA и Texas Instruments. Головной офис компании находится в Дюссельдорфе (Германия). Генеральным директором является Хён Шин Чо (Hyun Shin Cho) из Университета Пердью (Purdue University). Пост технического директора занимает Мартин Форбах (Martin Vorbach), на имя которого зарегистрированы более 200 патентов. Стартап Ubitium уже привлёк $3,7 млн начального финансирования. На данный момент компания создала экспериментальную эмуляцию, которая подтверждает, что универсальный процессор работоспособен. Первые коммерческие решения планируется выпустить к 2026 году. |
|

