Компания SambaNova Systems объявила о запуске облачного сервиса SambaNova Cloud: утверждается, что на сегодняшний день это самая быстрая в мире платформа для ИИ-инференса. Она ориентирована на работу с большими языковыми моделями Llama 3.1 405B и Llama 3.1 70B, насчитывающими соответственно 405 и 70 млрд параметров.
В основу сервиса положены ИИ-чипы собственной разработки SN40L. Эти изделия состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной памяти HBM3. Утверждается, что восьмипроцессорная система на базе SN40L способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256к.
Источник изображения: SambaNova
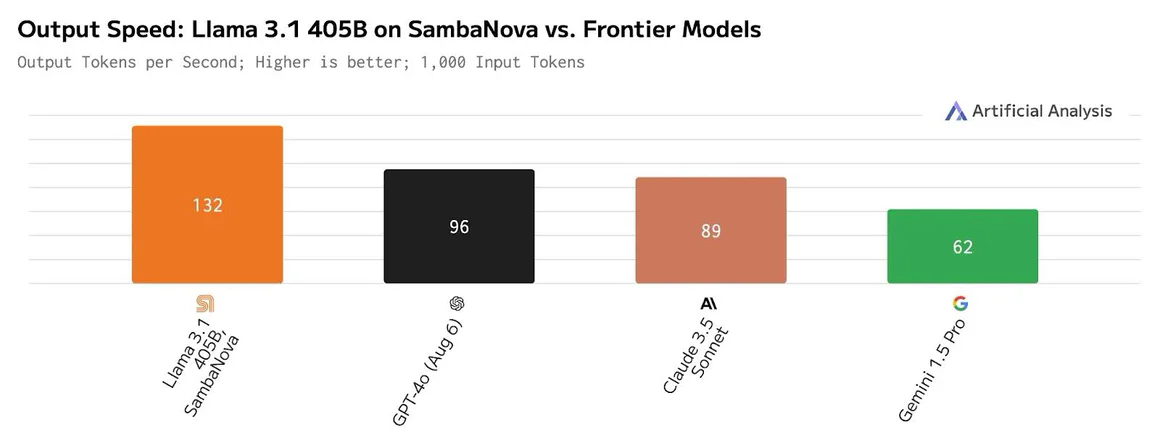
Платформа SambaNova Cloud, по заявлениям разработчиков, демонстрирует производительность до 132 токенов в секунду при работе с Llama 3.1 405B и до 461 токена в секунду при использовании Llama 3.1 70B. Для сравнения, по оценкам Artificial Analysis, даже самые мощные системы на базе GPU могут обслуживать модель Llama 3.1 405B только со скоростью 72 токена в секунду, а большинство из них намного медленнее. Подчёркивается, что SambaNova Cloud демонстрирует рекордную скорость при сохранении полной 16-битной точности. Однако без компромиссов всё же не обошлось: модель работает не в полном контекстном окне в 128k, а при 8k.
Доступ к SambaNova Cloud предоставляется по трём схемам — Free, Developer и Enterprise. Первая предусматривает бесплатное базовое использование через API. Схема для разработчиков Developer (появится к концу 2024 года) позволяет работать с моделями Llama 3.1 8B, 70B и 405B с более высокими лимитами. Наконец, план Enterprise предлагает корпоративным клиентам возможность масштабирования для поддержки ресурсоёмких рабочих нагрузок.
Ранее Cerebras Systems тоже объявила о запуске «самой мощной в мире» ИИ-платформы для инференса, а Groq ещё в прошлом году говорила о преимуществах своих решений и тоже переключилась на создание облачных сервисов. Впрочем, в бенчмарках MLPerf Inference по-прежнему бессменно лидируют решения NVIDIA.
Источник:

