Стартап SambaNova, решивший бросить вызов NVIDIA, представил второе поколение систем машинного обучения — DataScale SN30. В основе лежит собственная разработка компании, ускоритель Cardinal SN30, для обозначения которого SambaNova использует термин Reconfigurable Data Flow Unit (RDU). На новинку уже обратили внимание такие организации, как Аргоннская национальная лаборатория (ANL) и Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL).
Cardinal SN30 состоит из 86 млрд транзисторов и производится с использованием 7-нм техпроцесса TSMC. Главной его особенностью является возможность реконфигурации: создатели уподобляют этот процессор сложным FPGA. Последним он уступает в степени гибкости, поскольку не может менять конфигурацию на уровне отдельных логических вентилей, зато выигрывает в скорости перепрограммирования и уровне энергопотребления. За это отвечает фирменный программный стек.

Источник: HPCwire
Большой упор SambaNova сделала на объёме локальной памяти, поскольку современные модели машинного обучения имеют тенденцию к гигантомании. Только SRAM-кеша у Cardinal SN30 640 Мбайт, а объём DRAM составляет 1 Тбайт. По своим параметрам SN30 вдвое превосходит чип первого поколения, SN10, но имеет такую же тайловую архитектуру с программным управлением.
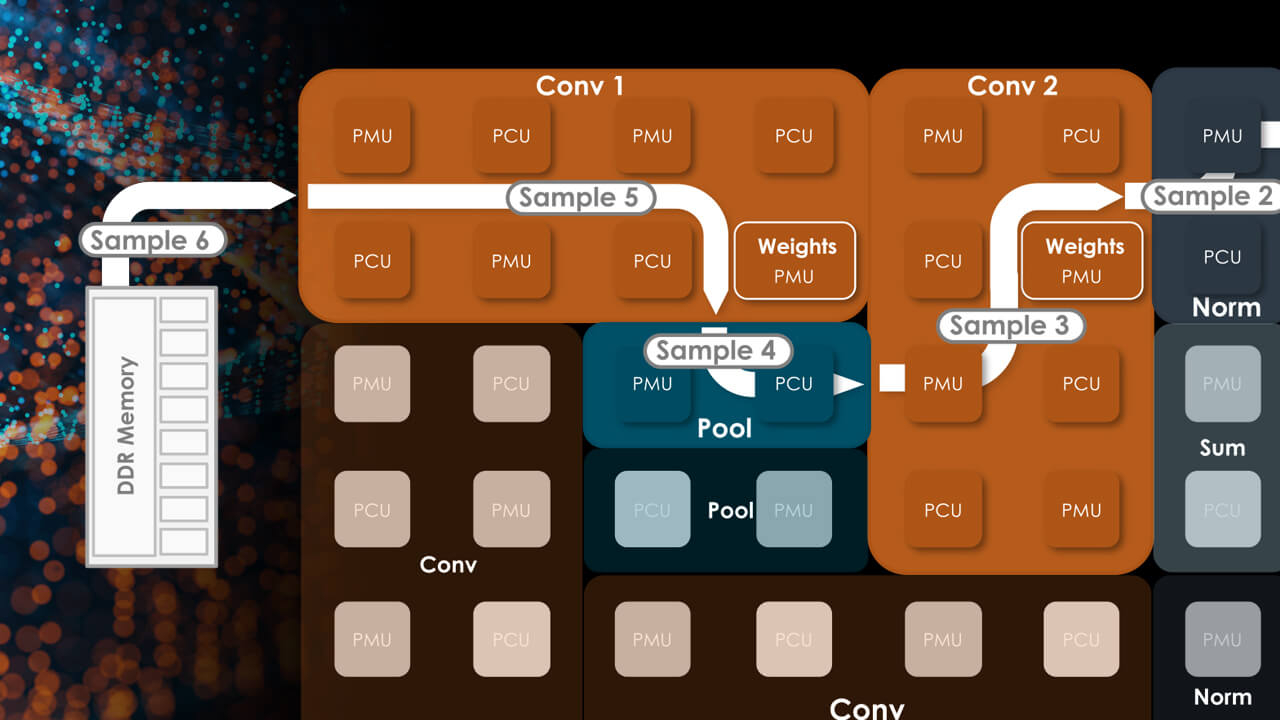
Здесь и далее источник изображений: SambaNova
Каждый тайл содержит блоки PCU, отвечающие за вычисления, блоки PMU, содержащие SRAM и обслуживающую логику, а также mesh-интерконнект, обслуживаемый блоками коммутаторов. Такой подход к построению процессора весьма напоминает Tesla D1, у которых вычислительные блоки похожим образом чередуются с блоками быстрой SRAM-памяти. Отдельно ускорители компания не поставляет, минимальная конфигурация готовой 42U-системы DataScale включает в себя 8 чипов SN30.

Комплектация может включать в себя от одного до трёх узлов SN30. Воспользоваться возможностями DataScale можно и в виде услуги, поскольку новинка легко интегрируется в облачные среды и полностью поддерживает платформу Kubernetes. Полный список провайдеров ещё уточняется, на сегодняшний момент партнерами SambaNova являются Aicadium, Cirrascale и ORock.

Высокая производительность в режиме BF16 является главным достоинством новинки — по словам вице-президента SambaNova, каждый чип развивает 688 Тфлопс. Это более чем вдвое выше показателя A100, составляющего 312 Тфлопс. По словам компании, DataScale SN30 вшестеро производительнее NVIDIA DGX A100 (40 Гбайт) и эффективнее всего проявляет себя при обучении сверхбольших моделей вроде GPT-3 с её 13 млрд параметров. Однако нельзя не отметить, что, во-первых, сравнение идёт со старым продуктом NVIDIA, которая вот-вот представит DGX H100, а во-вторых, SambaNova не упоминает в явном виде энергопотребление одного узла SN30.
Источник:

