Материалы по тегу: intel
|
12.04.2024 [21:28], Сергей Карасёв
Dell сумела сократить сроки поставок ИИ-серверов, но теперь компания полагается не только на ускорители NVIDIA, но и на Intel Gaudi3Компании Dell, по сообщению The Register, удалось сократить сроки поставок серверов для задач ИИ в несколько раз. Речь идёт о высокопроизводительных системах с ускорителями на основе GPU, в том числе NVIDIA H100. Спрос на них настолько высок, что производители не справляются с потоком заказов. О текущей ситуации в отрасли рассказал руководитель тайваньского подразделения Dell Теренс Ляо (Terence Liao). В конце 2023 года срок поставок серверов Dell, оборудованных ускорителями H100, составлял в среднем 39 недель, или около 8–9 месяцев. По словам Ляо, с февраля 2024-го отгрузки продукции NVIDIA значительно улучшились, и Dell смогла уменьшить сроки поставок серверов до 8–12 недель, или 2–3 месяцев. Таким образом, время выполнения заказов уменьшилось в три–четыре раза. Тем не менее, дефицит высокопроизводительных ИИ-ускорителей сохраняется. Связано это в том числе с возможностями TSMC по выпуску чипов с применением технологии CoWoS (Chip on Wafer on Substrate). Именно компоновка CoWoS применяется при изготовлении Н100. 
Источник изображения: NVIDIA В сентябре 2023 года спрос на передовые технологии упаковки чипов был настолько высоким, что TSMC заявила о способности удовлетворить только 80 % заказов. Вместе с тем TSMC сообщила о намерении расширить производственные мощности CoWoS на 20 % — это поможет смягчить проблему дефицита ИИ-ускорителей. Между тем Dell приходится искать альтернативы ускорителям NVIDIA. В частности, она намерена использовать ИИ-ускорители Intel Gaudi3. Поддержка Gaudi3 заявлена для сервера Dell XE9680, который также поддерживает ускорители AMD Instinct MI300X. Эта ИИ-платформа наделена 32 слотами для модулей памяти DDR5, восемью разъёмами PCIe 5.0 и шестью портами OSFP 800GbE. Возможна установка 16 накопителей EDSFF3.
12.04.2024 [12:58], Сергей Карасёв
Модуль LattePanda Mu для IoT- и edge-устройств оснащён процессором Intel Alder Lake-NДебютировал вычислительный модуль (SoM) под названием LattePanda Mu на аппаратной платформе Intel Alder Lake-N. Изделие, как сообщает ресурс CNX Software, предназначено для создания IoT-устройств, edge-систем, робототехнических платформ и пр. Новинка использует нестандартный форм-фактор с размерами 69,6 × 60 мм, а для подключения служит 260-контактный разъём SO-DIMM. Задействован чип Intel Processor N100 с четырьмя ядрами (до 3,4 ГГц) и графическим ускорителем Intel HD Graphics (750 МГц). Объём оперативной памяти LPDDR5-4800 составляет 8 Гбайт. 
Источник изображений: CNX Software Модуль несёт на борту флеш-чип eMMC 5.1 вместимостью 64 Гбайт. Заявлена поддержка следующих интерфейсов: 2 × SATA-3, 1 × eDP 1.4, 3 × HDMI 2.0/DisplayPort 1.4, 4 × USB 3.2 Gen2 (10 Гбит/с), 8 × USB 2.0, 4 × UART, 4 × I2C, PCIe 3.0 (до 9 линий) и 64 × GPIO. Диапазон рабочих температур простирается от 0 до +60 °C. Напряжение питания — от 9 до 20 В.  Команда LattePanda предоставляет для новинки драйверы Windows 10/11. При этом рекомендуется использовать дистрибутивы Linux с ядром 5.18 и выше. Для модуля LattePanda Mu разработаны интерфейсные платы Lite и Full с набором всевозможных разъёмов, включая порты USB, аудиогнёзда и коннекторы для подключения дисплеев (поддерживается вывод изображения одновременно на три монитора). Стоимость LattePanda Mu SoM составляет $139. Комплект с интерфейсной платой Lite и активным кулером обойдётся приблизительно в $190.
10.04.2024 [22:45], Алексей Степин
Intel Gaudi3 готов бросить вызов ИИ-ускорителям NVIDIAС момента анонса ускорителей Intel Habana Gaudi2 минуло два года и всё это время они достойно сражались с решениями NVIDIA, хоть и уступая в чистой производительности, но нередко выигрывая по показателю быстродействия в пересчёте на доллар. Теперь пришло время нового поколения — корпорация Intel анонсировала выпуск чипов Gaudi3 и ускорителей на их основе. Новый ИИ-процессор Gaudi3 взял на вооружение 5-нм техпроцесс TSMC, а также получил чиплетную компоновку, которая, впрочем, на логическом уровне никак себя не проявляет — Gaudi3 с точки зрения хоста остаётся монолитным ускорителем. Был увеличен с 96 до 128 Гбайт объём набортной памяти, но это по-прежнему HBM2e в отличие от решений основного соперника, давно перешедшего на HBM3. 
Источник изображений здесь и далее: Intel Intel выступила с достаточно серьёзным заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при существенно меньшей стоимости. Звучит многообещающе, особенно на фоне сочетания высоких цен с дефицитом со стороны «зелёных».  Физически, как уже упоминалось, Gaudi3 состоит из двух одинаковых кристаллов, «сшитых» между собой быстрым низколатентным интерконнектом. Архитектурно чип подобен предшественнику и по-прежнему включает блоки матричной математики (MME) и кластеры программируемых тензорных процессоров (TPC), имеющих доступ к разделу быстрой памяти SRAM.  Однако в сравнении с Gaudi2 количество блоков серьёзно выросло: вместо 2 MME в составе Gaudi3 теперь 8 таких блоков, а число тензорных процессоров увеличилось с 24 до 64. Вдвое, то есть с 48 до 96 Мбайт, вырос объём SRAM, а её пропускная способность возросла с 6,4 Тбайт/с до 12,8 Тбайт/с. Логически Gaudi3 делится на ядра DCORE (Deep Learning Core), в состав каждого входит два движка MME, 16 тензорных ядер и 24 Мбайт кеша L2. 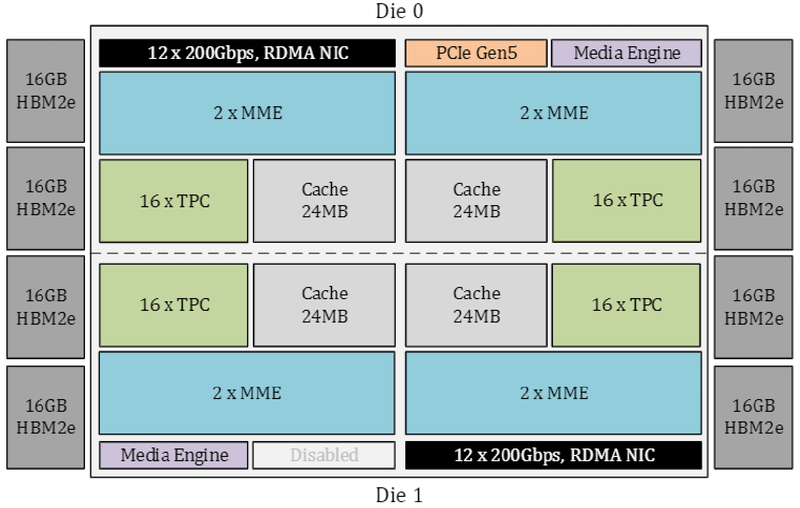
Блок-схема Gaudi3 Усилен также блок медиадвижков, их в новом чипе 14 против 8 у Gaudi2. Всё это не могло не сказаться на тепловыделении: несмотря на применение 5-нм техпроцесса теплопакет у флагманского варианта составляет целых 900 Вт, хотя в новом модельном ряду есть и не столь горячие версии с TDP 600 и 450 Вт. Последний вариант предназначен для экспорта в КНР. 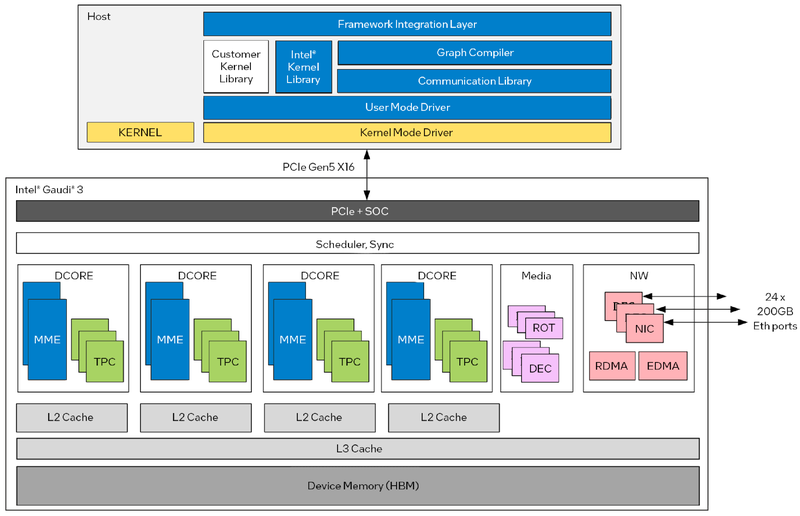
Архитектура Gaudi3 и его программная прослойка Поскольку объём HBM2e был увеличен с 96 до 128 Гбайт, в сборке используется не шесть, а восемь 16-Гбайт кристаллов, что позволило увеличить ПСП с 2,46 до 3,7 Тбайт/с. Работает память на частоте 3,6 ГГц. В составе Gaudi3 также имеется специализированный программируемый блок управления. Он отвечает за формирование очередей, управление прерываниями, синхронизацию, работу планировщика и имеет выход непосредственно на шину PCIe. 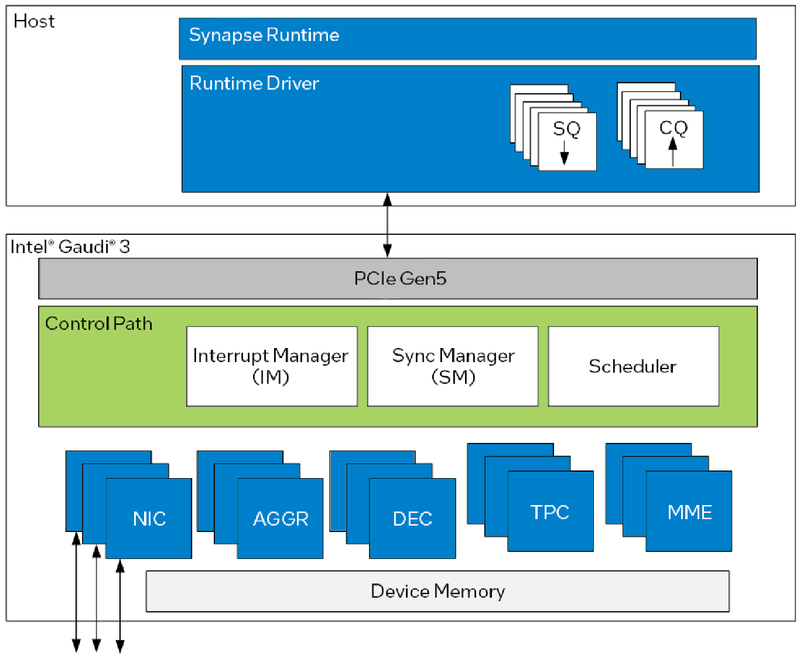
Управляющая подсистема (Control Path) Gaudi3 Сетевая часть всё ещё состоит из 24 контроллеров Ethernet (c RoCE), но появилась поддержка скорости 200 Гбит/с, а значит, вдвое возросла и совокупная производительность сети. Intel подчёркивает, что для масштабирования кластеров на базе Gaudi3 нужна обычная Ethernet-фабрика (а ещё лучше Ultra Ethernet) и нет никакой привязки к конкретному вендору, что является упрёком NVIDIA с её InfiniBand. Наконец, в качестве хост-интерфейса на смену PCI Express 4.0 пришёл PCI Express 5.0 (x16), что также означает подросшую с 64 до 128 Гбайт/с пропускную способность. 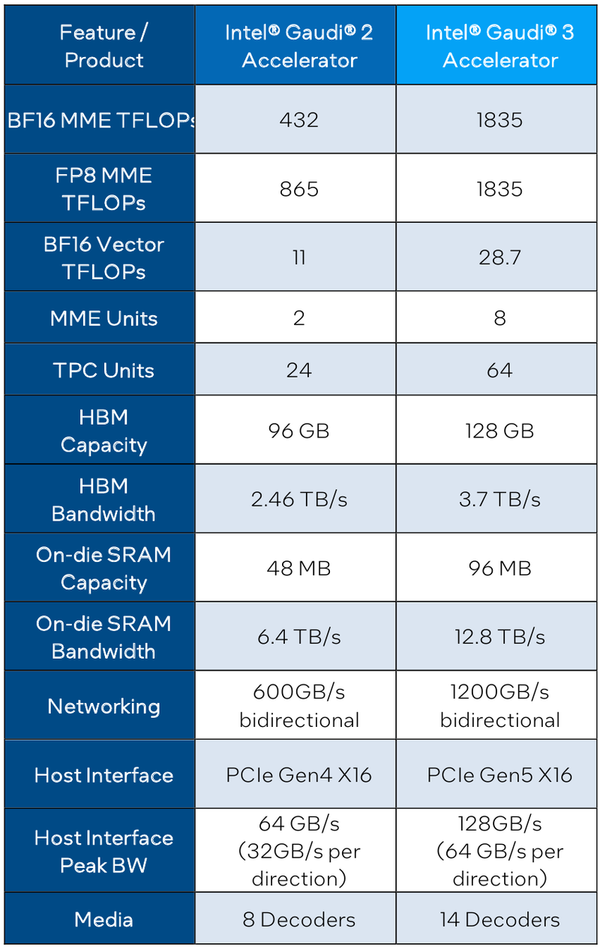
Сравнительные характеристики Gaudi2 и Gaudi3 Все эти улучшения позволяют Intel говорить о теоретической производительности в 2–4 раза более высокой, нежели было достигнуто в поколении Gaudi2. Наибольший прирост заявлен для операций с форматом BF16 на MME, что вполне закономерно, учитывая большее количество самих MME. 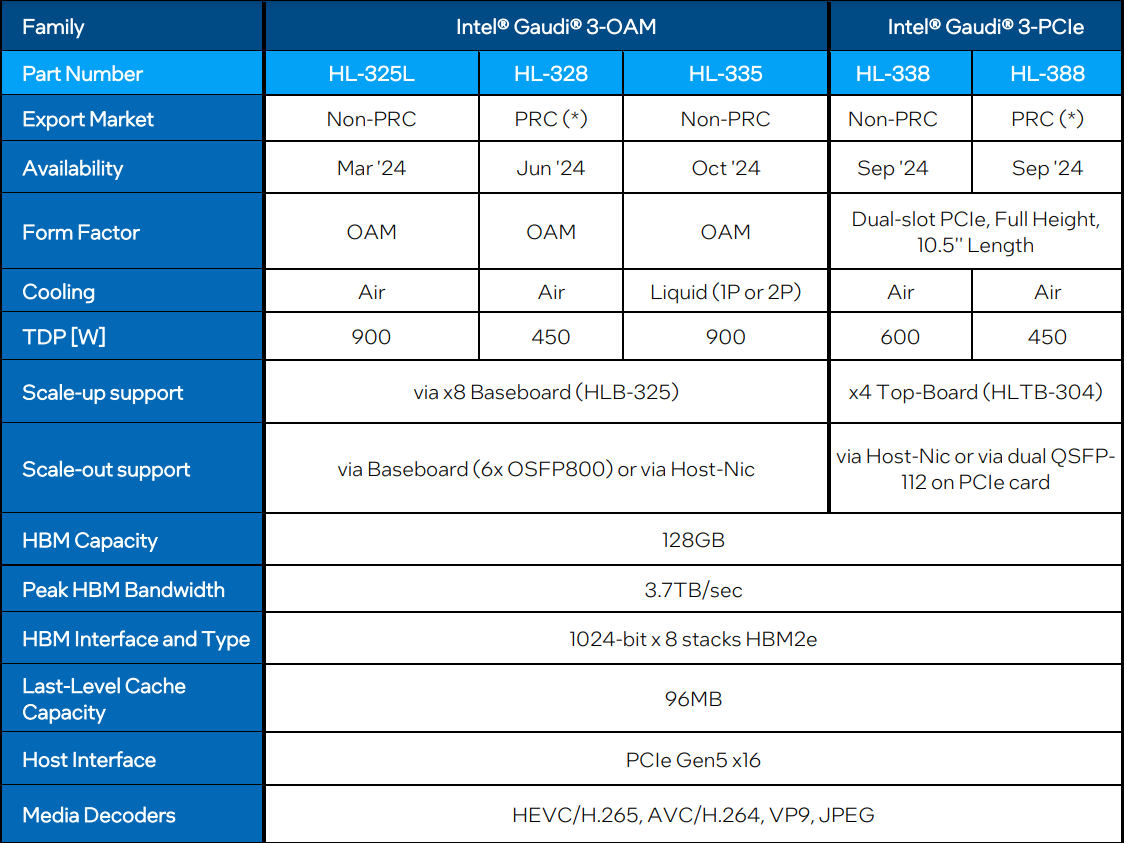 На практике результаты, демонстрируемые Gaudi3, выглядят также достаточно многообещающе: в тестах на обучение популярных нейросетей преимущество над Gaudi2 ни разу не составило менее 1,5x, а в отдельных случаях даже превысило 2,5x. 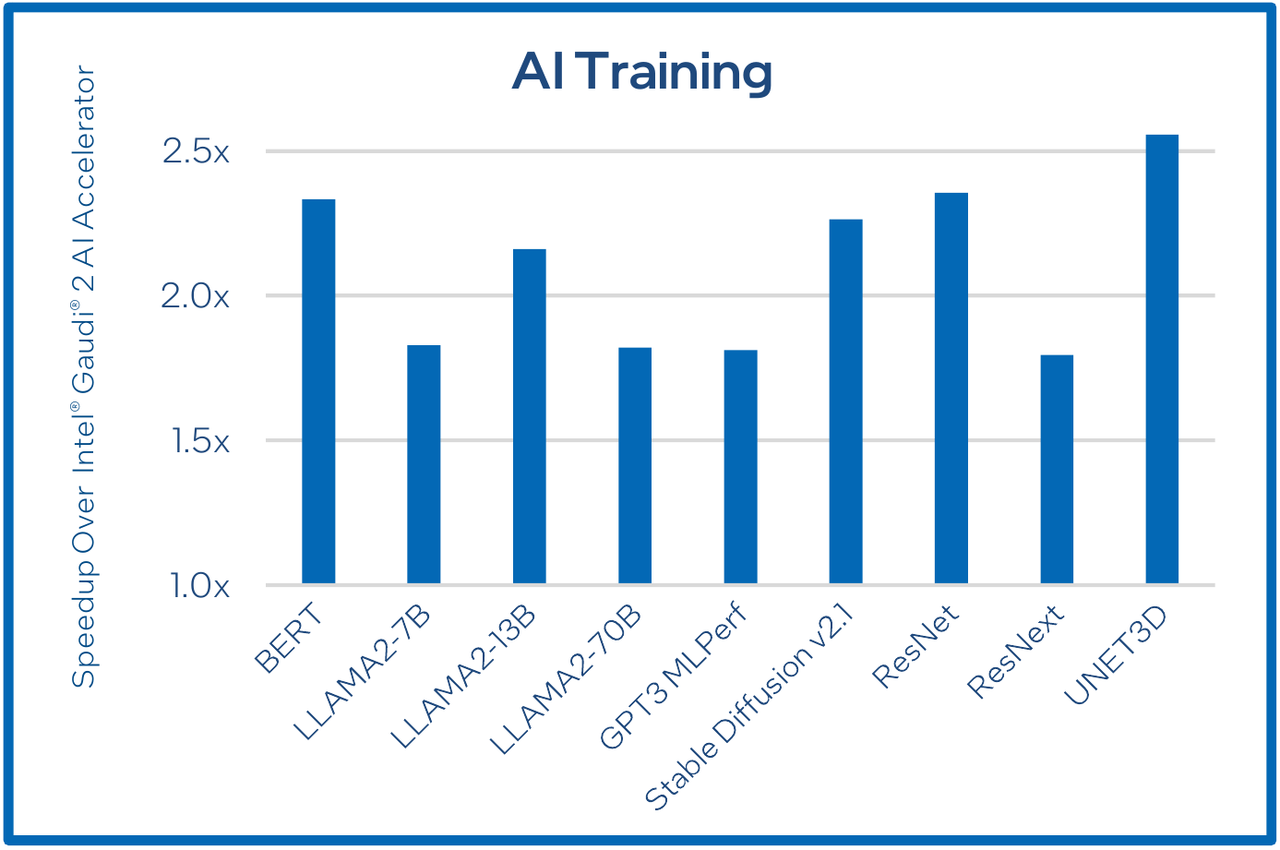 В инференс-тестах отрыв оказался чуть меньше, но и здесь минимальна разница составляет полтора раза. Что немаловажно для инференс-сценариев, серьёзно улучшились показатели латентности. Отчасти это заслуга не только серьёзно подросших «мускул» нового процессора, но и наличие большего объёма HBM, что позволяет разместить в памяти больше параметров и расширить контекстное окно. 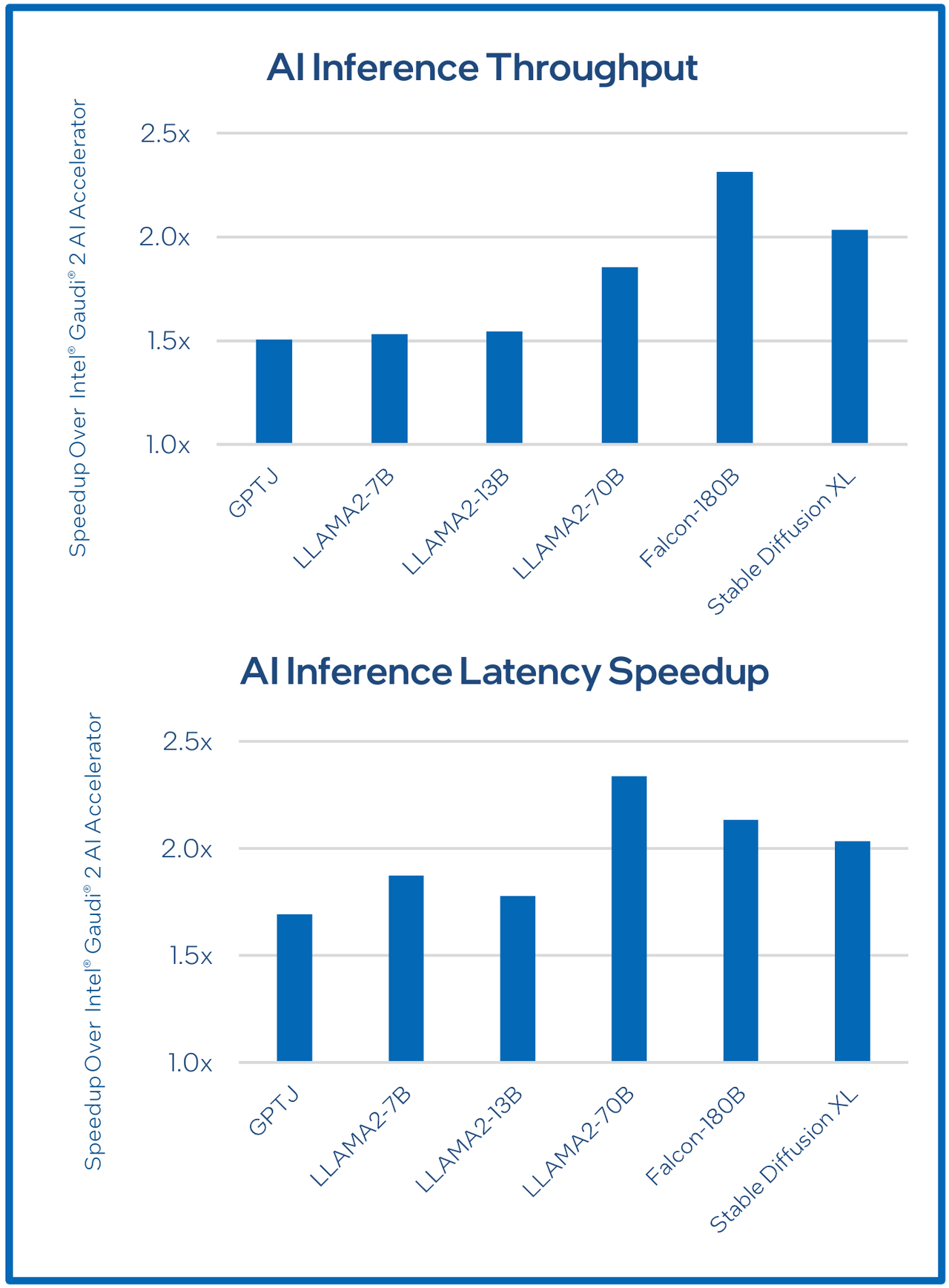 Опубликовала Intel и результаты сравнительного тестирования Gaudi3 против NVIDIA H100 в MLPerf, где новинка действительно выступила весьма достойно, в худшем случае демонстрируя 90% от производительности H100, а в отдельных тестах опережая конкурента более чем в 2,5 раза. Примерно так же распределились результаты и в тестах на энергоэффективность. 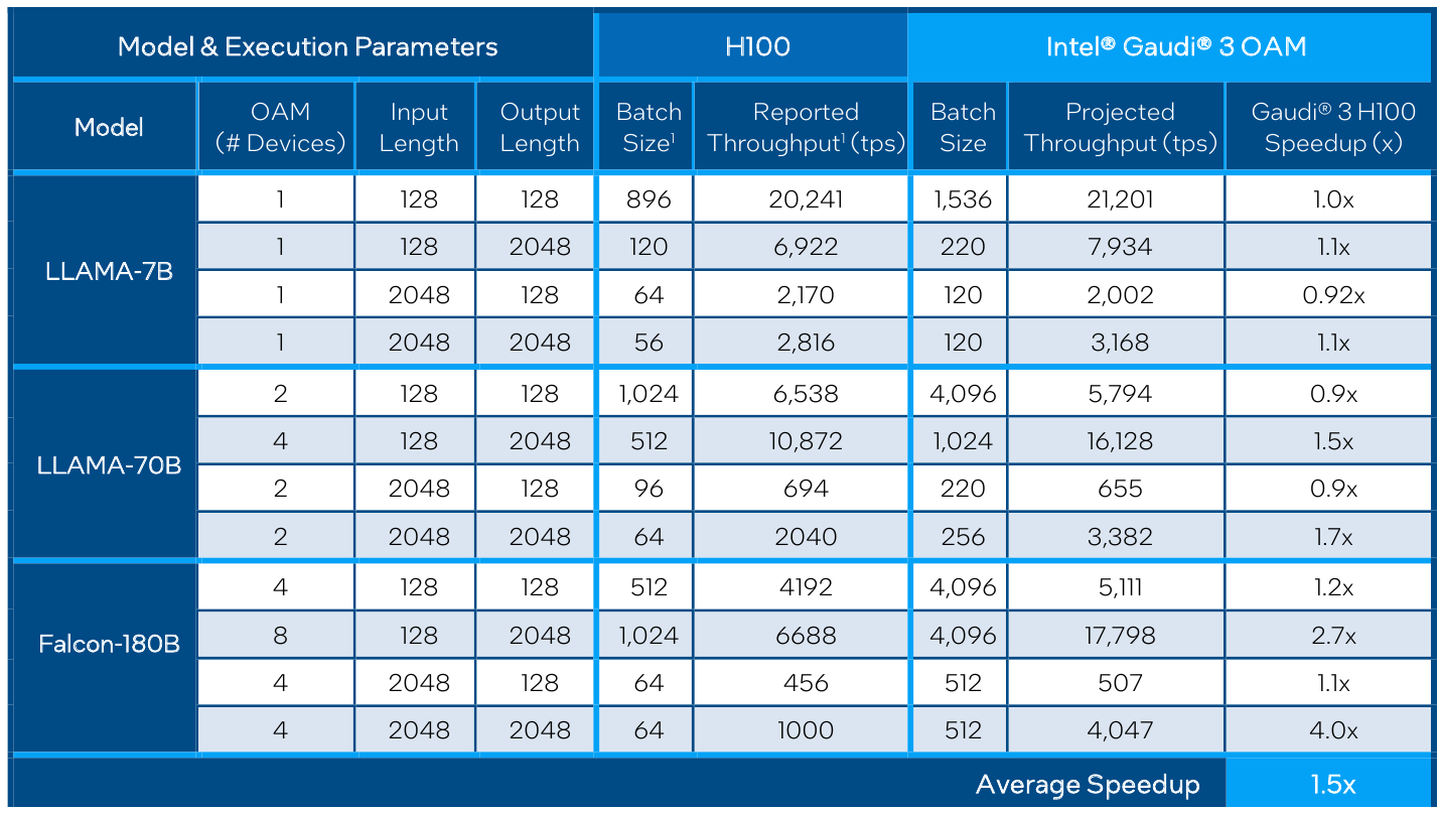 Что же касается инженерно-технической реализации, то на этот раз Intel представила сразу несколько вариантов ускорителей на базе Gaudi3, отличающихся как теплопакетом, так и конструктивом. Самым быстрым вариантом в семействе является модуль HL-325L OCP. Он выполнен в формате мезонинной платы OCP OAM 2.0 и поддерживает теплопакет 900 Вт для воздушного охлаждения и 1200 Вт — для жидкостного. 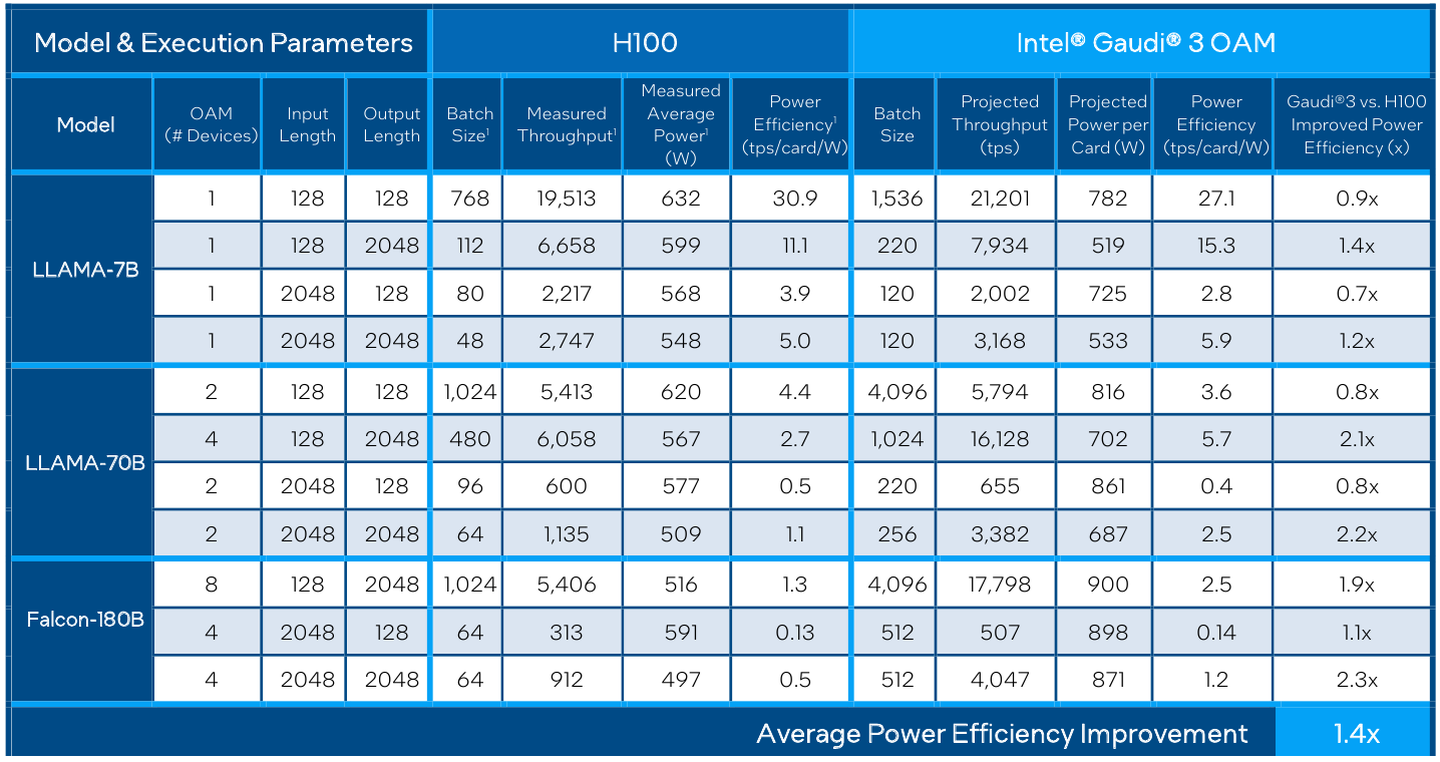 Для этой модели была специально разработана новая UBB-плата HLB-325L, приходящая на смену HLBA-225. Она поддерживает установку восьми ускорителей HL-325L, причём 21 сетевое подключение на каждом из них позволяет реализовать интерконнект по схеме «все со всеми», а оставшиеся подключения сведены через PAM4-ретаймеры в шесть 800GbE-портов OSFP для дальнейшего масштабирования кластера. Имеется и вывод PCI Express 5.0 с помощью PCIe-ретаймеров, также установленных на плате. HLB-325L рассчитана на питание 54 В, которое в последнее время становится всё популярнее в новых ЦОД и HPC-системах. 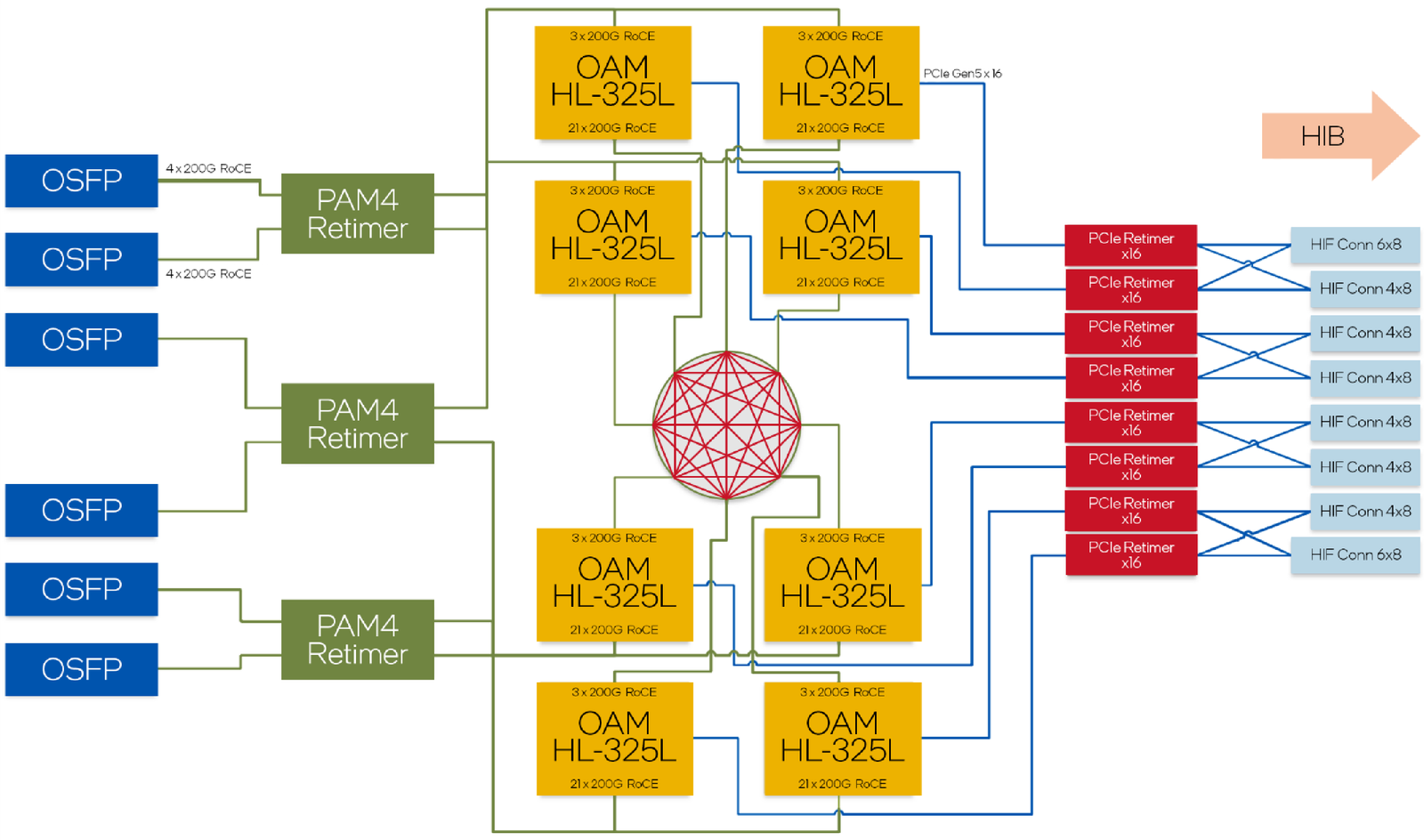
Топология базовой платы HLB-325L с восемью Gaudi3 Другой вариант Gaudi3 — ускоритель HL-338. Он представляет собой стандартную плату расширения PCIe с двумя внешними портами QSFP112 400GbE. Поддерживаются теплопакеты вплоть до 600 Вт при стандартном воздушном охлаждении. Дополнительный мостик HLTB-304, устанавливаемая поверх четырёх ускорителей HL-338, обеспечивает интерконнект за счёт 18 набортных линков 200GbE. Такая реализация кластера на базе Gaudi3 по понятным причинам будет несколько менее производительной, нежели вариант с OAM-модулями, но позволит обойтись стандартными аппаратными средствами и корпусами серверов. 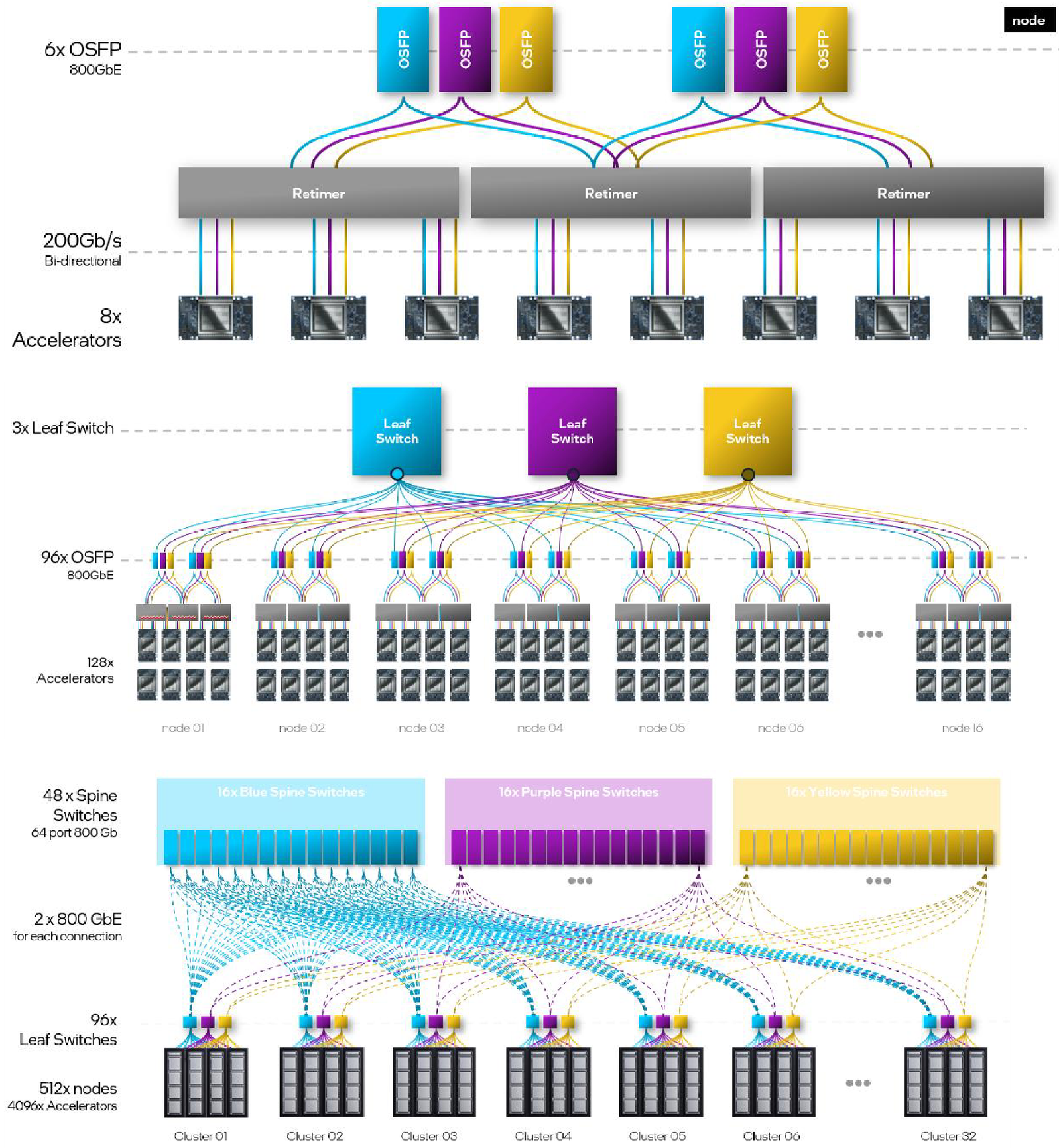
Масштабирование и кластеризация Gaudi3 Первые пробные партии ускорителей на базе Gaudi3 поступят избранным партнёрам Intel уже в этом полугодии. Вариант OAM с воздушным охлаждением уже тестируется в квалификационных лабораториях компании, а образцы с жидкостным охлаждением появятся позднее в этом квартале. В новинке заинтересованы Dell, HPE, Lenovo и Supermicro. Массовые поставки стартуют в III квартале 2024 года. Последними на рынке появятся PCIe-версии, их поставки намечены на IV квартал. 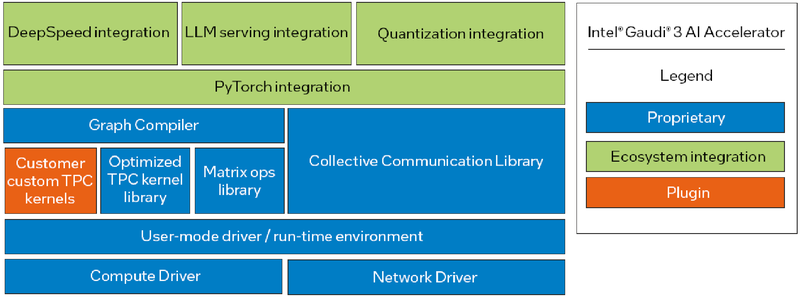
Программная экосистема Intel Gaudi Intel Gaudi3 выглядит весьма неплохо. В нём устранены узкие места, свойственные Gaudi2, что позволяет тягаться на равных с NVIDIA H100 и H200, и даже заметно превосходить их в некоторых сценариях. Однако NVIDIA уже анонсировала архитектуру Blackwell. Впрочем, основная борьба развернётся не на аппаратном, а на программном уровне — Intel вслед за AMD упростила работу с PyTorch, что позволит перенести множество нагрузок на Gaudi. А там, глядишь, и UXL станет хоть какой-то альтернативой CUDA.
10.04.2024 [14:34], Сергей Карасёв
Intel и Altera представили Agilex 5 — первую FPGA с ИИ-архитектуройВозродив бренд Altera, корпорация Intel анонсировала FPGA серии Agilex 5, рассчитанные на широкий спектр применений. Это могут быть различные встраиваемые и промышленные устройства, решения для систем связи, обеспечения безопасности, видеоаналитики и пр. Intel называет Agilex 5 первыми в отрасли FPGA с ИИ-архитектурой. Изделия производятся по технологии Intel 7. Это первые FPGA в своём классе, оснащённые усовершенствованным (Enhanced) DSP с тензорным ИИ-блоком (AI Tensor Block), который отвечает за высокоэффективную обработку операций, связанных с ИИ. 
Источник изображений: Intel Кроме того, как утверждается, Agilex 5 — это первые на рынке FPGA с асимметричным блоком процессора приложений, состоящим из двух ядер Arm Cortex-A76 и двух ядер Cortex-A55. Такая конфигурация в зависимости от рабочих нагрузок позволяет оптимизировать производительность и энергоэффективность. Тактовая частота ядер Cortex-A76 достигает 1,8 ГГц, ядер Cortex-A55 — 1,5 ГГц. 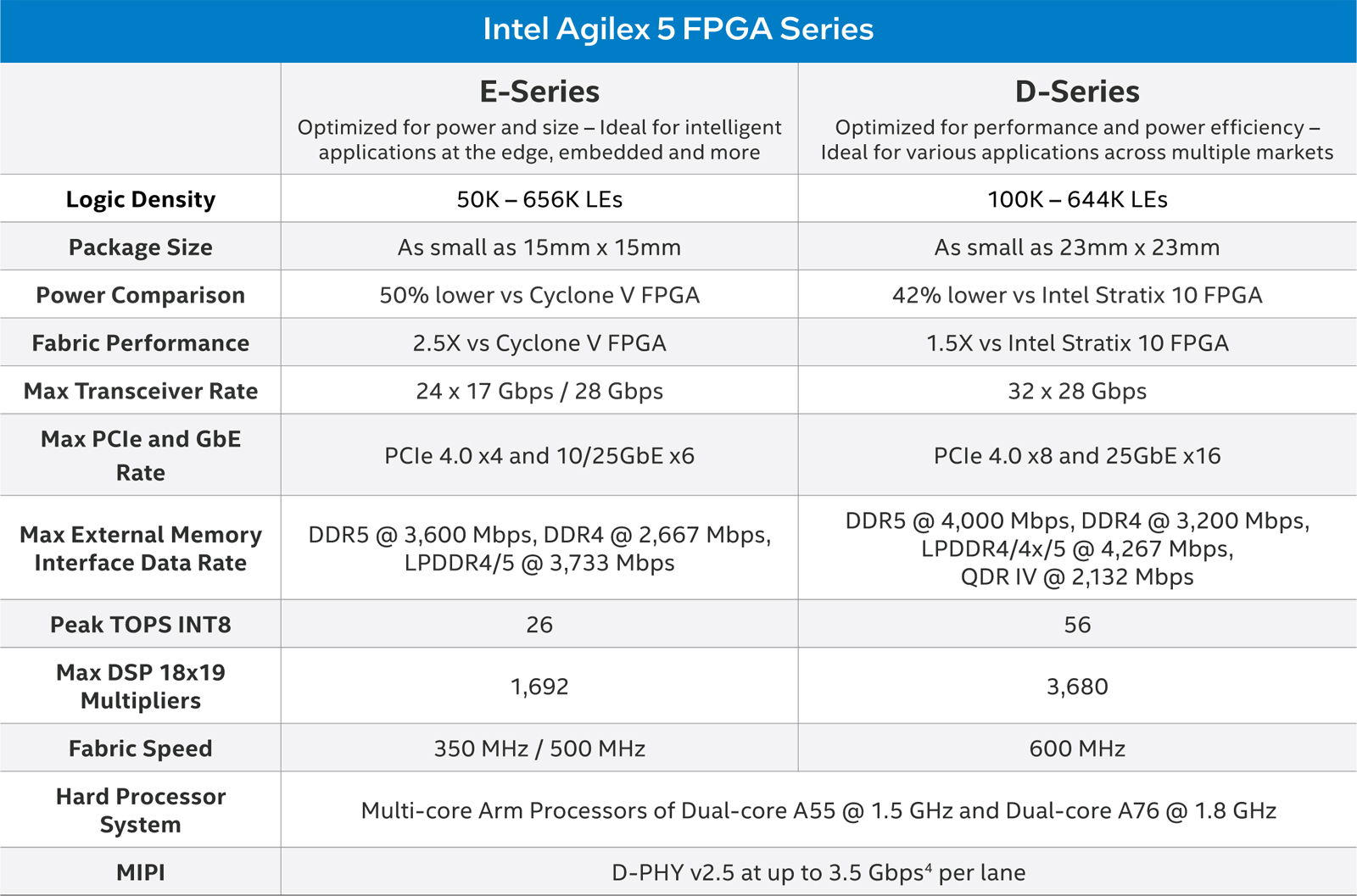 В семейство Agilex 5 вошли модели E-Series и D-Series. Первые оптимизированы для edge-устройств с небольшим энергопотреблением, а вторые предлагают более высокую производительность. Быстродействие INT8 достигает соответственно 26 и 56 TOPS. Решения E-Series могут работать с памятью DDR5-3600, DDR4-2667 и LPDDR4/5-3733. Реализована поддержка PCIe 4.0 x4 и шести интерфейсов 10/25GbE. В случае D-Series заявлена возможность использования памяти DDR5-4000, DDR4-3200, LPDDR4/4x/5-4267 и QDR-IV-2132. Обеспечена поддержка PCIe 4.0 x8 и 16 интерфейсов 25GbE.
10.04.2024 [14:22], Сергей Карасёв
Intel перешла на новую схему обозначения процессоров Xeon — от бренда Scalable решено отказатьсяКорпорация Intel, по сообщению AnandTech, объявила о внедрении новой схемы обозначения серверных процессоров Xeon. Ради упрощения маркировки от бренда Xeon Scalable решено отказаться: чипы следующего поколения войдут в семейство Xeon 6. Речь идёт об изделиях под кодовыми именами Xeon Sierra Forest и Xeon Granite Rapids. Эти процессоры были официально представлены в феврале нынешнего года. Известно, что чипы Xeon Sierra Forest будут оснащены исключительно энергоэффективными E-ядрами, количество которых составит до 288. Такие решения начнут поступать на коммерческий рынок в текущем квартале. В свою очередь, Xeon Granite Rapids получат высокопроизводительные P-ядра, а их выход состоится позднее — ориентировочно во II половине нынешнего года. 
Источник изображений: Intel Впервые Intel начала использовать бренд Xeon Scalable в 2017 году, представив семейство чипов Skylake-SP. В то время бренд Xeon Scalable пришёл на смену прежней маркировке Xeon E/EP/EX vX, что позволило сбросить «счётчик поколений».
Отмечается, что Intel стремится сформировать экосистему, соответствующую современным требованиям отрасли. Фактически закладывается основа так называемой инфраструктуры Intel Enterprise AI: она охватит решения для дата-центров, периферийных систем и ПК корпоративного класса. Именно Xeon 6 в обозримом будущем сыграют ключевую роль в реализации данной стратегии. Intel намерена сотрудничать с отраслевыми партнёрами, независимыми поставщиками ПО и аппаратных изделий для создания широкой и открытой экосистемы.
10.04.2024 [14:14], Сергей Карасёв
Intel представила видеокарты Arc для встраиваемых решенийКорпорация Intel анонсировала видеокарты серии Arc Aхx0E, предназначенные для применения в различных встраиваемых устройствах и системах небольшого форм-фактора. В общей сложности дебютировали шесть моделей: Arc A310E, Arc A350E, Arc A370E, Arc A380E, Arc A580E и Arc A750E. В основном это встраиваемые версии видеокарт, которые уже доступны на рынке. При этом изделия подверглись некоторым доработкам с учётом сферы их применения. Ускорители насчитывают от 6 до 28 ядер Xe. Количество исполнительных блоков варьируется от 96 до 448. Объём памяти GDDR6 у младших вариантов составляет 4 Гбайт, а пропускная способность памяти у версий начального уровня составляет 112 Гбайт/с. Для A380E указаны 6 Гбайт и 186 Гбайт/с. А вот для A580E и A750E параметры памяти не указаны. 
Источник изображения: Advantech Производительность INT8 варьируется от 49 до 235 TOPS. Быстродействие на операциях FP16 составляет от 24,6 до 117,6 Тфлопс, на операциях FP32 — от 3,1 до 14,7 Тфлопс. Говорится о совместимости с Windows 10/11, Windows 10 LTSC и Linux. 
Источник изображения: Intel В зависимости от модификации видеокарты Arc Aхx0E могут использоваться для решения таких задач, как распознавание лиц и речи, приложения ИИ, обработка медиаданных и пр. Поставки начнутся в текущем месяце. Решение будут доступны для заказа в течение пяти лет. 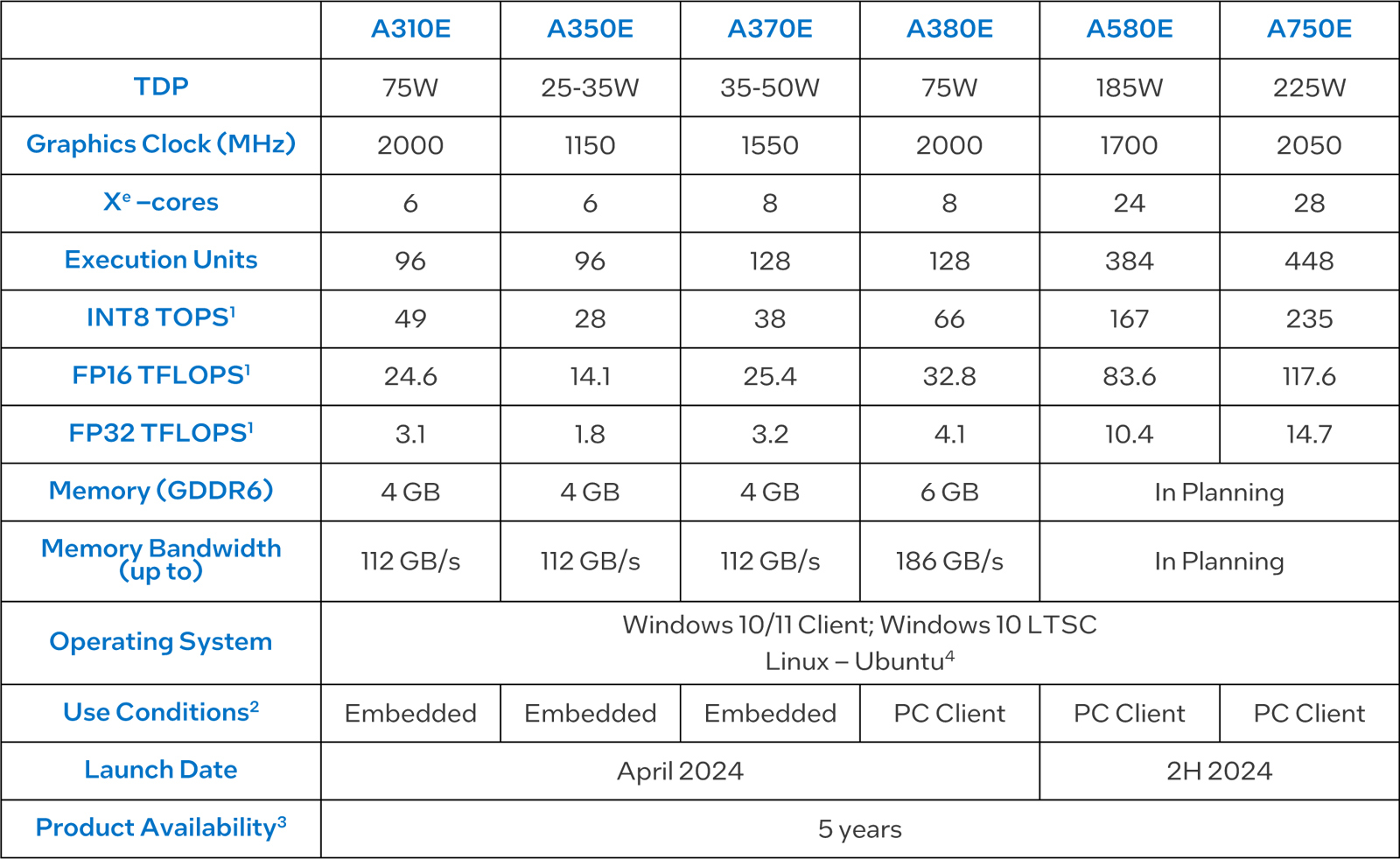
Источник изображения: Intel
10.04.2024 [00:00], Сергей Карасёв
Supermicro готовит серверы серии X14 на чипах Intel Xeon Sierra Forest и Granite RapidsКомпания Supermicro сообщила о подготовке серверов семейства X14, в основу которых лягут процессоры Intel Xeon Sierra Forest и Granite Rapids (Xeon 6). Речь идёт о стоечных системах, оптимизированных для обеспечения высокой производительности и энергетической эффективности. Для устройств серии X14 заявлена поддержка GPU и DPU нового поколения, оперативной памяти DDR5, интерфейса PCIe 5.0, накопителей NVMe с поддержкой PCIe 5.0 и стандарта CXL 2.0. Говорится о подготовке серверов с воздушным охлаждением и прямым жидкостным охлаждением Direct-to-chip. Системы рассчитаны на работу в дата-центрах с температурой окружающего воздуха до +40 °C. Серверы спроектированы в соответствии со стандартом NIST 800-193. Питание обеспечат надёжные блоки с сертификатом 80 Plus Titanium. 
Источник изображения: Supermicro В семейство Supermicro X14 войдут решения для задач ИИ с ускорителями на базе GPU, универсальные серверы, модели SuperBlade для НРС-задач, аналитики данных и облачных платформ, СХД формата 1U и 2U с поддержкой накопителей DSFF E1.S и E3.S, а также серверы серий Hyper, Hyper-E, CloudDC, BigTwin, GrandTwin и Edge. 
Источник изображения: Supermicro Компания Supermicro также сообщает, что будут доступны двухпроцессорные серверы общего назначения для решения повседневных задач корпоративного уровня. Помимо этого, готовятся рабочие станции для приложений ИИ, 3D-дизайна и пр.
09.04.2024 [23:45], Сергей Карасёв
Intel представила чипы Meteor Lake PS, Raptor Lake PS и Atom x7000RE для edge-устройствКорпорация Intel анонсировала сразу три семейства процессоров для встраиваемых устройств и edge-оборудования: это чипы Core Ultra Meteor Lake PS, Core Raptor Lake PS и Atom x7000RE. Изделия серии Core Ultra PS (Meteor Lake) изготавливаются по технологии Intel 4. Они рассчитаны на установку в разъём нового поколения LGA 1851. Конструкция включает ядра P-cores и E-cores, графический блок Intel Arc GPU, а также нейропроцессорный движок (NPU), предназначенный для ускорения ИИ-операций. 
Источник изображения: Intel Семейство Core Ultra PS представлено моделями HL со стандартным значением TDP в 45 Вт и UL с базовым TDP в 15 Вт. Реализована поддержка оперативной памяти DDR5-5600 и до 20 линий PCIe 4.0. В общей сложности в серию Core Ultra PS вошли девять моделей. Количество ядер достигает 16, число одновременно обрабатываемых потоков инструкций — 22. Объём кеша L3 составляет до 24 Мбайт, тактовая частота — до 5,0 ГГц. 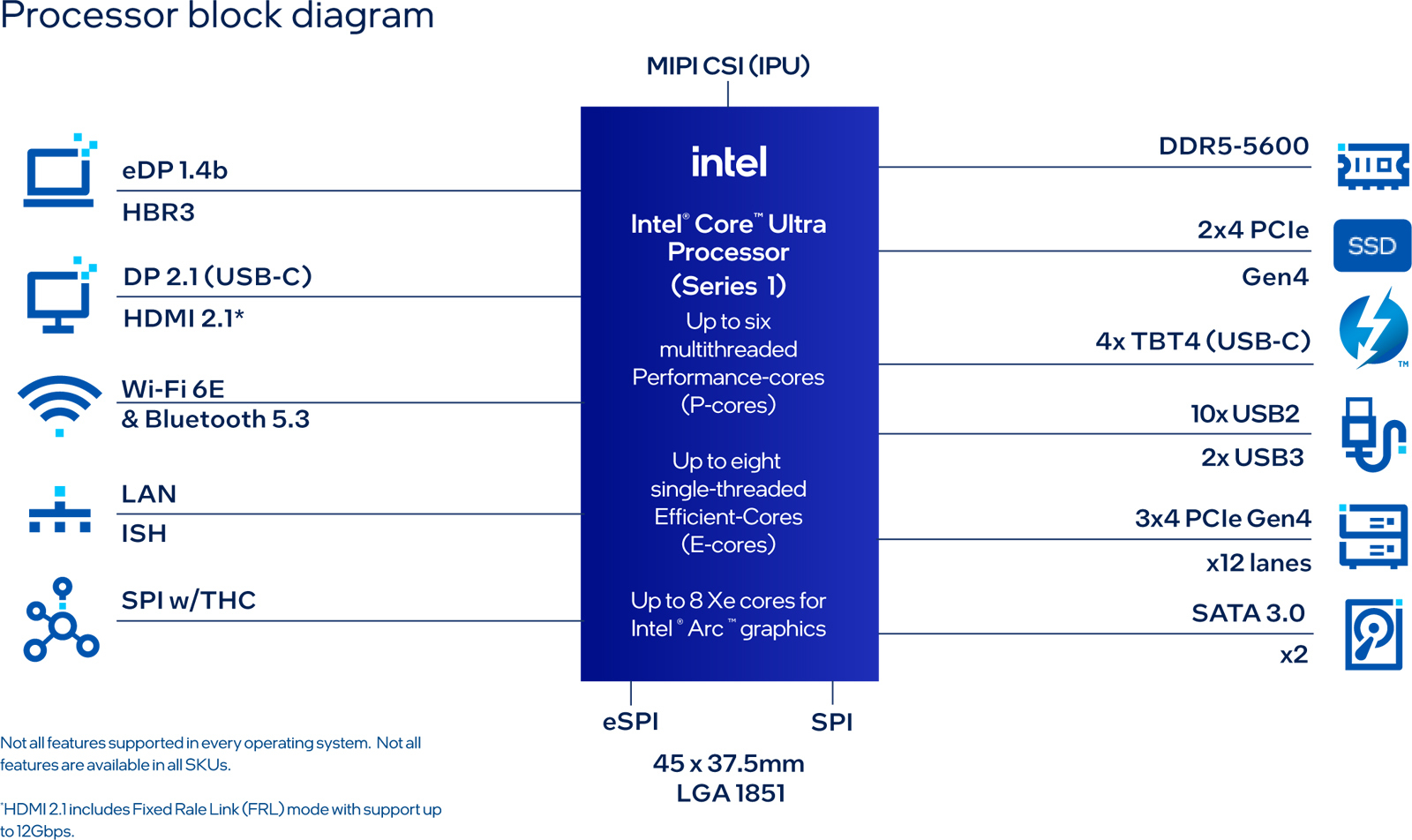
Источник изображения: Intel В свою очередь, процессоры семейства Core PS (Raptor Lake) используют сокет LGA 1700. Эти чипы также подразделяются на подсерии HL и UL с базовым TDP соответственно 45 и 15 Вт. Они содержат до 14 ядер с поддержкой до 20 потоков инструкций. Поддерживается работа с оперативной памятью DDR5–5200 и DDR4-3200. Возможно использование 8 линий PCIe 4.0 в дополнение к 12 линиям PCIe 3.0 в составе интегрированного PCH. Используется графика Intel Graphics. Объём кеша L3 достигает 24 Мбайт, тактовая частота — до 5,2 ГГц. В семейство Core PS на сегодняшний день входят 14 моделей.
Наконец, изделия Atom x7000RE (Amston Lake) выполнены по технологии Intel 7. Они насчитывают до восьми ядер E-cores, а показатель TDP варьируется от 6 до 12 Вт. Поддерживаются память LPDDR5-4800, DDR5-4800 и DDR4-3200, до девяти линий PCIe 3.0, графика Intel UHD Graphics. Максимальная тактовая частота — 3,6 ГГц.
06.04.2024 [20:53], Сергей Карасёв
Плата CWWK CW-J6-NAS получила шесть портов SATA-3, два разъёма M.2 2280 и три 2.5GbE-портаПо сообщению ресурса CNX-Software, в продаже появилась плата CWWK CW-J6-NAS, предназначенная для построения сетевых хранилищ данных. Решение выполнено в форм-факторе Mini-ITX с габаритами 170 × 170 мм, а в основу положена платформа Intel Elkhart Lake. Примечательно, что на официальном сайте CWWK страница продукта была доступна некоторое время назад, но потом пропала. В зависимости от модификации задействован процессор Celeron J6412 (до 2,6 ГГц) или Celeron J6413 (до 3,0 ГГц). Эти 10-Вт чипы содержат четыре вычислительных ядра (SMT нет) и ускоритель Intel UHD Graphics. Доступны два слота для модулей DDR4-2400/2666/3200 SO-DIMM суммарным объёмом до 64 Гбайт. 
Источник изображения: CNX-Software Плата располагает шестью портами SATA-3 для подключения накопителей (пять реализованы на контроллере JMB585) и двумя коннекторами M.2 2280 NVMe. Предусмотрены три сетевых порта 2.5GbE RJ-45, два из которых используют чип Intel i226-V, а третий — RTL8125BG. Кроме того, имеется консольный порт с разъёмом RJ-45. Новинка оборудована четырьмя интерфейсами USB 2.0, двумя — USB 3.0, колодкой GPIO и колодкой USB 2.0, двумя 4-контактными коннекторами для подключения вентиляторов охлаждения, а также стандартными разъёмами питания ATX (24+4). Среди прочего упомянуты аудиогнездо на 3,5 мм, интерфейсы HDMI и DP 1.4a с поддержкой видео в формате 4K@60 и разъём PCIe х1, в который может быть установлена, например, дополнительная сетевая карта. Цена CWWK NAS варьируется от $175 до $200.
28.03.2024 [14:31], Сергей Карасёв
Intel Gaudi2 остаётся единственным конкурентом NVIDIA H100 в бенчмарке MLPerf InferenceКорпорация Intel сообщила о том, что её ИИ-ускоритель Habana Gaudi2 остаётся единственной альтернативой NVIDIA H100, протестированной в бенчмарке MLPerf Inference 4.0. При этом, как утверждается, Gaudi2 обеспечивает высокое быстродействие в расчёте на доллар, хотя именно чипы NVIDIA являются безоговорочными лидерами. Отмечается, что для платформы Gaudi2 компания Intel продолжает расширять поддержку популярных больших языковых моделей (LLM) и мультимодальных моделей. В частности, для MLPerf Inference v4.0 корпорация представила результаты для Stable Diffusion XL и Llama v2-70B. Согласно результатам тестов, в случае Stable Diffusion XL ускоритель H100 превосходит по производительности Gaudi2 в 2,1 раза в оффлайн-режиме и в 2,16 раза в серверном режиме. При обработке Llama v2-70B выигрыш оказывается более значительным — в 2,76 раза и 3,35 раза соответственно. Однако на большинстве этих задач (кроме серверного режима Llama v2-70B) решение Gaudi2 выигрывает у H100 по показателю быстродействия в расчёте на доллар. 
Источник изображений: Intel В целом, ИИ-ускоритель Gaudi2 в Stable Diffusion XL показал результат в 6,26 и 6,25 выборок в секунду для оффлайн-режима и серверного режима соответственно. В случае Llama v2-70B достигнут показатель в 8035,0 и 6287,5 токенов в секунду соответственно. 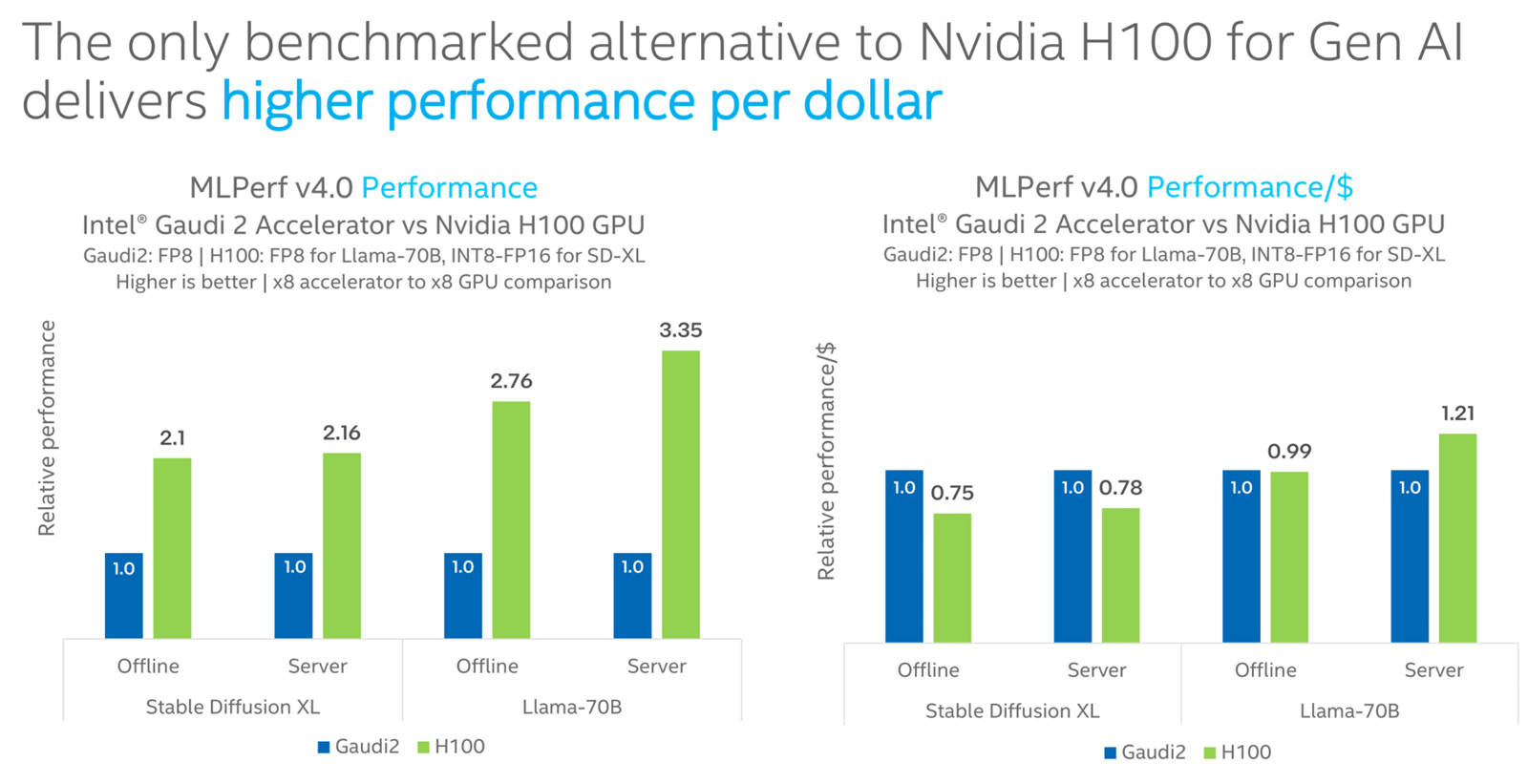 Говорится также, что серверные процессоры Intel Xeon Emerald Rapids благодаря улучшениям аппаратной и программной составляющих в бенчмарке MLPerf Inference v3.1 демонстрируют в среднем в 1,42 раза более высокие значения по сравнению с чипами Xeon Sapphire Rapids. Например, для GPT-J с программной оптимизацией и для DLRMv2 зафиксирован рост быстродействия примерно в 1,8 раза. |
|


