Материалы по тегу: instinct
|
13.07.2023 [23:49], Алексей Степин
Младший напарник El Capitan: кластер Tuolumne будет использоваться для открытых исследованийЛиверморская национальная лаборатория (LLNL) вовсю ведёт монтаж суперкомпьютера El Capitan, мощность которого превзойдёт 2 Эфлопс. Дебютирует новая система в середине следующего года. Однако это не единственный суперкомпьютер LLNL. Помимо тестовых кластеров rzVernal, Tioga и Tenay, в строй будет введён и суперкопмьютер Tuolumne производительностью более 200 Пфлопс. El Capitan получит уникальные серверные APU AMD Instinct MI300A, содержащие 24 ядра Zen 4 и массив ускорителей с архитектурой CDNA3, дополненный собственным стеком памяти HBM3 объёмом 128 Гбайт. El Capitan будет использоваться в том числе для секретных и закрытых проектов, но, как сообщают зарубежные источники, кластер Tuolumne на базе той же аппаратной платформы HPE станет открытой платформой, практически самой мощной в своём классе. Сообщается о том, что производительность Tuolumne составит около 15 % от таковой у El Capitan, то есть от 200 до 300 Пфлопс. Хотя это не позволяет отнести Tuolumne к экза-классу, такие цифры позволяют претендовать на вхождении в первую пятёрку рейтинга TOP500. 
Тестовые стойки в ЦОД LLNL Впервые имя Tuolumne было упомянуто в 2021 году, когда речь шла о системе раннего доступа RZNevada, целью которой была тестирование и отработка аппаратного и программного стеков El Capitan. Также известно, что система охлаждения и питания в главном ЦОД LLNL была модернизирована, в результате чего её мощность выросла с 85 до 100 МВт, и часть этих мощностей достанется Tuolumne. Правда, когда суперкомпьютер будет введён в строй, не говорится.
06.07.2023 [20:49], Владимир Мироненко
Начата сборка 2-Эфлопс суперкомпьютера El Capitan на базе серверных APU AMD Instinct MI300AЛиверморская национальная лаборатория (LLNL) объявила о получении первой партии компонентов суперкомпьютера El Capitan, которые сразу же начала устанавливать. Система будет запущена в середине 2024 года и, согласно данным LLNL, будет обеспечивать производительность более 2 Эфлопс. Стоимость El Capitan составляет около $600 млн. El Capitan будет использоваться для выполнения задач лабораторий Национальной администрации по ядерной безопасности США, чтобы они «могли поддерживать уверенность в национальных силах ядерного сдерживания», — сообщила LLNL. «На момент принятия проекта в следующем году El Capitan, вероятно, станет самым мощным суперкомпьютером в мире», — указано в заявлении LLNL. Он заменит машину Sierra на базе IBM POWER 9 и NVIDIA Volta, обойдя её производительности более чем на порядок. 
Источник изображений: LLNL El Capitan базируется на платформе HPE Cray Shasta, как и две другие экзафлопсные системы, Frontier и Aurora. В отличие от этих систем, использующих традиционную конфигурацию дискретных CPU и ускорителей, El Capitan станет первым суперкомпьютером на базе гибридной архитектуры AMD. APU Instinct MI300A включает 24 ядра с микроархитектурой Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. Правда, пока не уточняется, устанавливаются ли узлы уже с финальной конфигурации «железа» или же пока что предсерийные образцы. 
04.07.2023 [17:20], Владимир Мироненко
Обойдёмся без NVIDIA: MosaicML перенесла обучение ИИ на ускорители AMD Instinct MI250 без модификации кодаРазработчик решений в области генеративного ИИ MosaicML, недавно перешедший в собственность Databricks, сообщил о хороших результатах в обучении больших языковых моделей (LLM) с использованием ускорителей AMD Instinct MI250 и собственной платформы. Компания рассказала, что подыскивает от имени своих клиентов новое «железо» для машинного обучения, поскольку NVIDIA в настоящее время не в состоянии обеспечить своими ускорителями всех желающих. MosaicML пояснила, что требования к таким чипам просты:

Источник изображений: MosaicML Как отметила компания, ни один из чипов до настоящего времени смог полностью удовлетворить все требования MosaicML. Однако с выходом обновлённых версий фреймворка PyTorch 2.0 и платформы ROCm 5.4+ ситуация изменилась — обучение LLM стало возможным на ускорителях AMD Instinct MI250 без изменений кода при использовании её стека LLM Foundry. 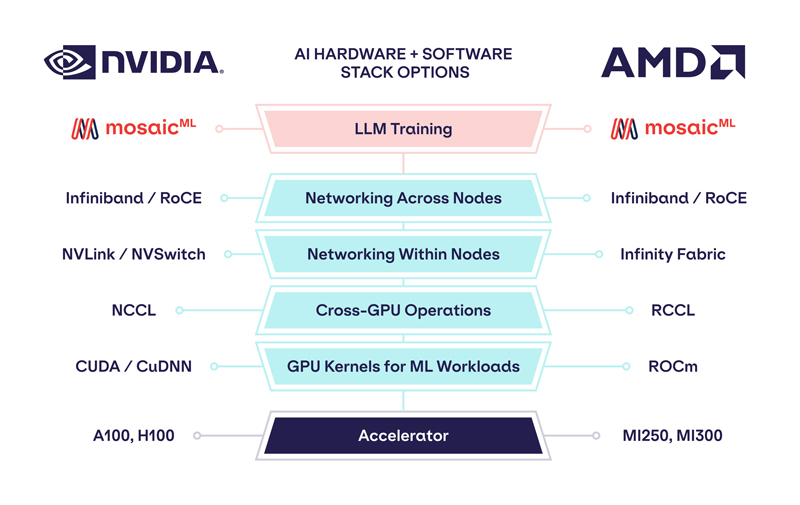 Некоторые основные моменты:
При этом никаких изменений в коде не потребовалось. 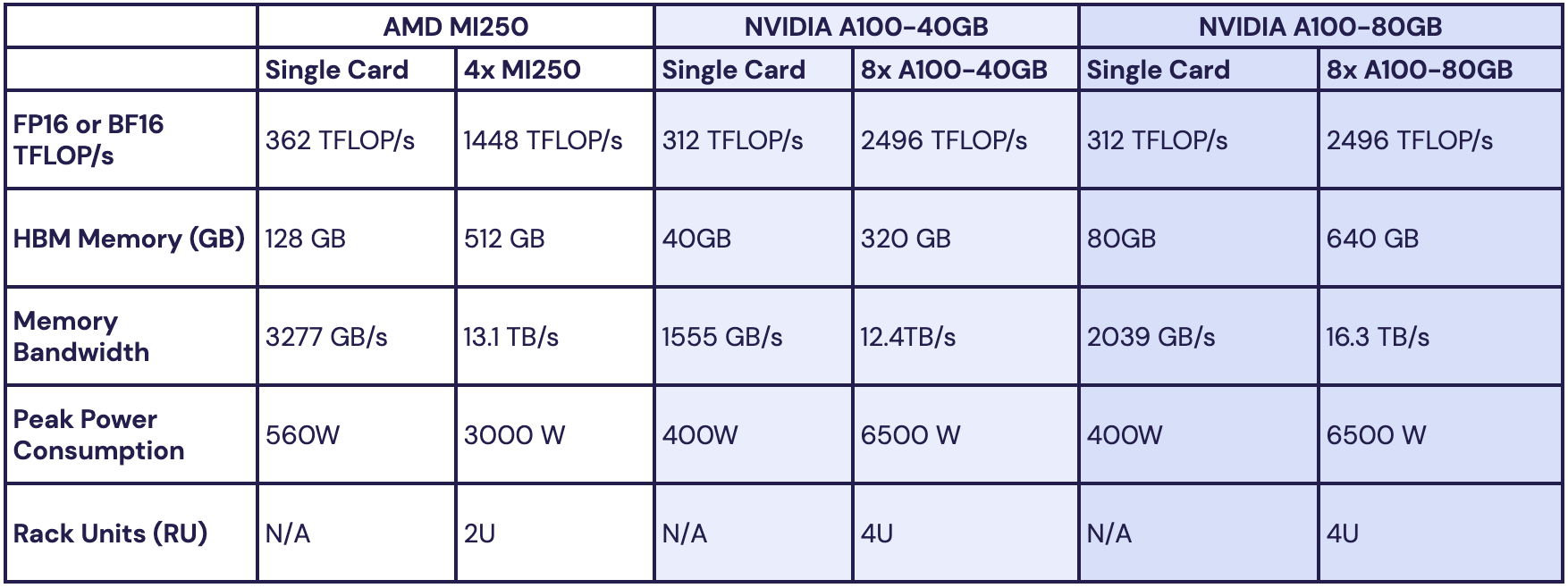 Все результаты получены на одном узле из четырёх MI250, но компания работает с гиперскейлерами для проверки возможностей обучения на более крупных кластерах AMD Instinct. «В целом наши первоначальные тесты показали, что AMD создала эффективный и простой в использовании программно-аппаратный стек, который может конкурировать с NVIDIA», — сообщила MosaicML. Это важный шаг в борьбе с доминирующим положением NVIDIA на рынке ИИ.
15.06.2023 [01:22], Владимир Мироненко
AWS присматривается к новым ИИ-ускорителям AMD Instinct MI300Amazon Web Services (AWS), крупнейший в мире провайдер облачных вычислений, рассматривает возможность использования новых ИИ-ускорителей AMD Instinct MI300. Об этом сообщил агентству Reuters Дейв Браун (Dave Brown), вице-президент Amazon по EC2, уточнив, что окончательное решение по данному вопросу пока не принято. При этом у компании уже есть ИИ-ускорители собственной разработки: Trainium и Inferentia2. Браун рассказал, что AWS отказалась сотрудничать с NVIDIA в деле развёртывания её платформы DGX Cloud, которая пока что доступна только в облаке Oracle. «Они обратились к нам, мы рассмотрели бизнес-модель, но она не имела особого смысла для AWS, которая сама обладает большим опытом в создании надёжных серверов и работе с цепочками поставок», — сообщил Браун, отметив, что AWS предпочитает разрабатывать свои серверы с нуля. В интервью Reuters гендиректор AMD Лиза Су (Lisa Su) рассказала, что для привлечения клиентов компания предлагает широкий перечень всех компонентов, необходимых для создания систем для запуска ИИ-решений, подобных ChatGPT, оставляя за ними возможность выбора того, что именно подойдёт с учётом использования стандартных отраслевых соединений. Браун сообщил, что команды Amazon и AMD уже сотрудничают какое-то время. 
Изображение: AMD Добавим, что AWS уже предлагает собственные системы с актуальными ускорителями NVIDIA H100. Аналитики отмечают, что интерес Amazon к MI300 указывает на стремление технологических компаний диверсифицировать парк ИИ-оборудования. А это открывает новые возможности для разработчиков чипов. При этом, как отмечал ресурс The Information, NVIDIA пока что благосклонна к небольшим облачным провайдерам, которые не занимаются созданием собственных ИИ-ускорителей.
14.06.2023 [03:00], Игорь Осколков
AMD представила ИИ-ускорители Instinct MI300X: 192 Гбайт HBM3 и 153 млрд транзисторовВместе с Bergamo и Genoa-X компания AMD представила и новый ИИ-ускоритель, а точнее два варианта одного и того же продукта — Instinct MI300A и MI300X. Как и в случае с EPYC, модульный подход к построению чипов позволил компании с минимумом усилий расширить портфолио. Об Instinct MI300A компания рассказывала неоднократно. Это самодостаточный APU (или XPU), объединяющий 24 ядра EPYC Genoa (три CCD), ускоритель на базе CDNA3 и 128 Гбайт общей памяти HBM3. Конкурировать он будет с решением NVIDIA Grace Hopper, которое включает 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100 с 96 Гбайт HBM3. Intel же из гонки гибридов временно выбыла, отказавшись в Falcon Shores от блока CPU. 
Изображения: AMD Правда, подход у компаний разный. NVIDIA предпочитает использовать NVLink и для объединения кристаллов внутри Grace Hopper (C2C), и для связи между узлами, что упрощает масштабирование. AMD в случае Instinct MI300 использует большую подложку-интерпозер, которая объединяет HBM-стеки (8 шт.) и блоки Zen 4/CDNA3 (4 шт.), что даёт определённую гибкость в выборе конфигурации чипа.  Этим компания и воспользовалась, представив OAM-ускорители MI300X, которые напрочь лишены CPU-блоков. Весьма своевременное появление 24-Гбайт модулей HBM3 позволило поднять общий объём памяти до 192 Гбайт, а её пропускную способность (ПСП) — до 5,2 Тбайт/с. Впрочем, о характеристиках новинки AMD больше ничего и не говорит, если не считать упоминания ПСП шины Infinity Fabric (896 Гбайт/с) и количества транзисторов (153 млрд шт.).  Столь большой объём памяти выгодно отличает MI300X от SXM-версии NVIDIA H100, которая может предложить только 80 Гбайт HBM3 и ПСП 3,35 Тбайт/с. Да, у NVIDIA есть «сендвич» H100 NVL, у которого имеется уже 188 Гбайт HBM3 (7,8 Тбайт/с). Но это всё же совсем иной форм-фактор, хотя, как и MI300X, ориентированный на работу с действительно большими ИИ-моделями.  Больший объём набортной памяти позволяет избавиться от лишних перемещений данных между ускорителем и основной памятью системы или несколькими ускорителями. Как и полагается, AMD анонсировала Instinct Platform — плату наподобие NVIDIA HGX, которая объединяет восемь ускорителей MI300X и, по-видимому, соответствует стандарту OCP UBB, что упрощает создание узлов на её основе.  Первые образцы Instinct MI300X появятся в следующем квартале, а образцы MI300A уже поставляются заказчикам. Впрочем, одним «железом» сыт не будешь — компания активно развивает программную платформу, в том числе ROCm, поскольку в области ПО для ИИ догнать, а уж тем более перегнать NVIDIA будет непросто. Это настолько важный пункт для AMD, что даже в презентации речь сначала долго шла о ПО, а уж потом были представлены новые ускорители. 
24.05.2023 [14:14], Сергей Карасёв
AMD рассказала об архитектуре гигантского APU Instinct MI300: 24 ядра EPYC Genoa, ускоритель CDNA 3 и 128 Гбайт HBM3Компания AMD на суперкомпьютерной конференции ISC 2023, по сообщению ресурса Tom's Hardware, раскрыла дополнительную информацию о гибридном изделии Instinct MI300. Новый APU найдёт применение в HPC-системах, а также в высокопроизводительных серверах для дата-центров. Как говорилось ранее, MI300 — это самый крупный и сложный чип, когда-либо созданный специалистами AMD. Он содержит в общей сложности около 146 млрд транзисторов. Конструкция включает ядра CPU (Zen 4) и GPU (CDNA 3), вспомогательную логику, I/O-контроллер, а также память HBM3. В общей сложности задействованы 13 чиплетов, четыре из которых изготавливаются по 6-нм технологии, а ещё девять — по 5-нм. По сравнению с Instinct MI250 новинка получила ряд архитектурных изменений. В частности, узел с Instinct MI250 (как у Frontier) имеет отдельные блоки CPU и GPU, дополненные единственным процессором EPYC для координации рабочих нагрузок. В свою очередь, узел Instinct MI300 содержит интегрированный 24-ядерный чип EPYC Genoa, а поэтому необходимость во внешнем CPU отпадает. 
Источник изображений: AMD  Вместе с тем сохранена топология, позволяющая каждому из блоков обмениваться данными со всеми другими. Причём в случае Instinct MI300 снижается задержка и повышается общая производительность. Компоненты чипа объединены посредством Infinity Fabric четвёртого поколения. В оснащение ходят 128 Гбайт общей для CPU и GPU памяти HBM3. Похожий подход реализован в чипах NVIDIA Grace Hopper, а вот Intel от гибридности в ускорителях Falcon Shores пока отказалась.
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 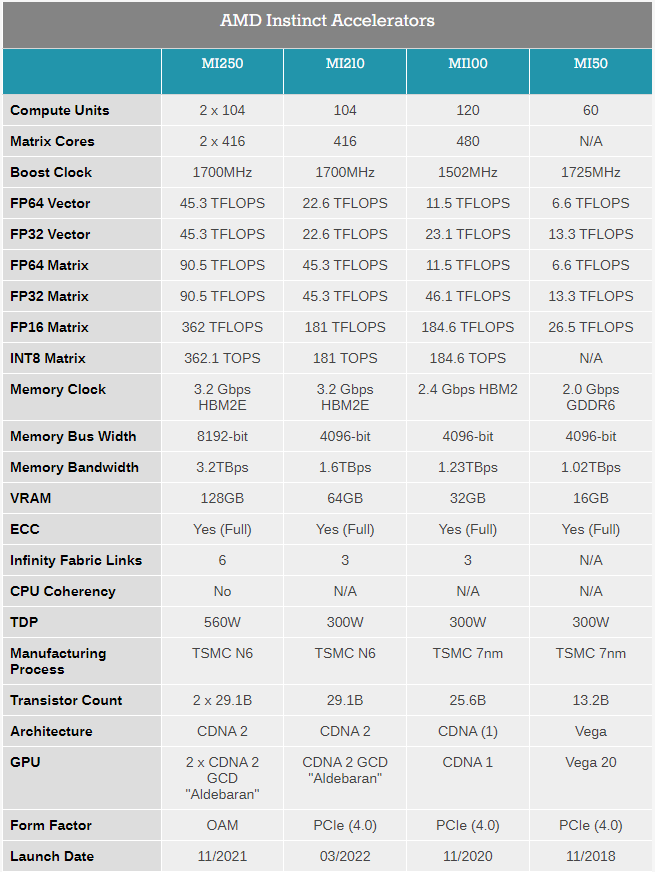
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 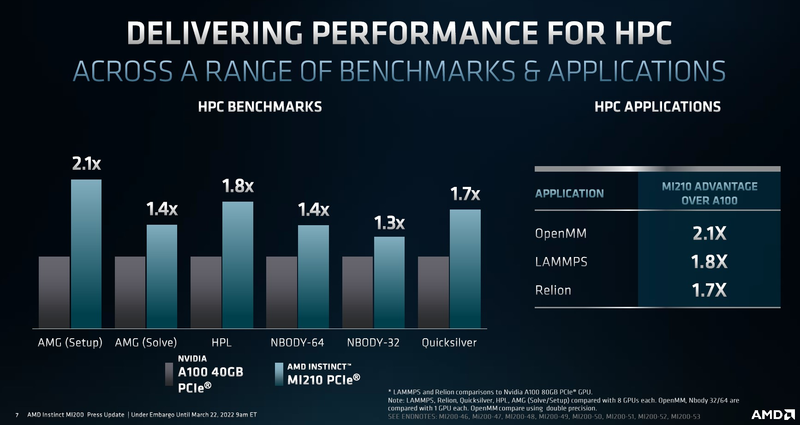
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала Instinct MI200, самые быстрые в мире ускорители вычислений на базе CDNA 2В прошлом году AMD окончательно развела ускорители для графики и вычислений, представив Instinct MI100, первый продукт на базе архитектуры CDNA, который позволил компании противостоять NVIDIA. Теперь же AMD подготовила новую версию архитектуры CDNA 2 и ускорители MI200 на неё основе. Новинки, согласно внутренним тестам, в ряде задач на голову выше того, что сейчас может предложить NVIDIA. 
AMD Instinct MI200 в OAM-варианте (Здесь и ниже изображения AMD) Циркулировавшие ранее слухи оказались верны — MI200 являются двухчиповыми решениями с 2.5D-упаковкой кристаллов (GCD) самих ускорителей, четырёх линий Infinity Fabric между ними и восьми стеков памяти HBM2e (8192 бит, 1600 МГц, 128 Гбайт, 3,2 Тбайт/c). В данном случае используется мостик EFB (Elevated Fanout Bridge), который позволяет задействовать стандартные подложки, что удешевляет и упрощает производство и тестирование ускорителей, не потеряв при этом в производительности и, что важнее, без существенного увеличения задержек в обмене данными. 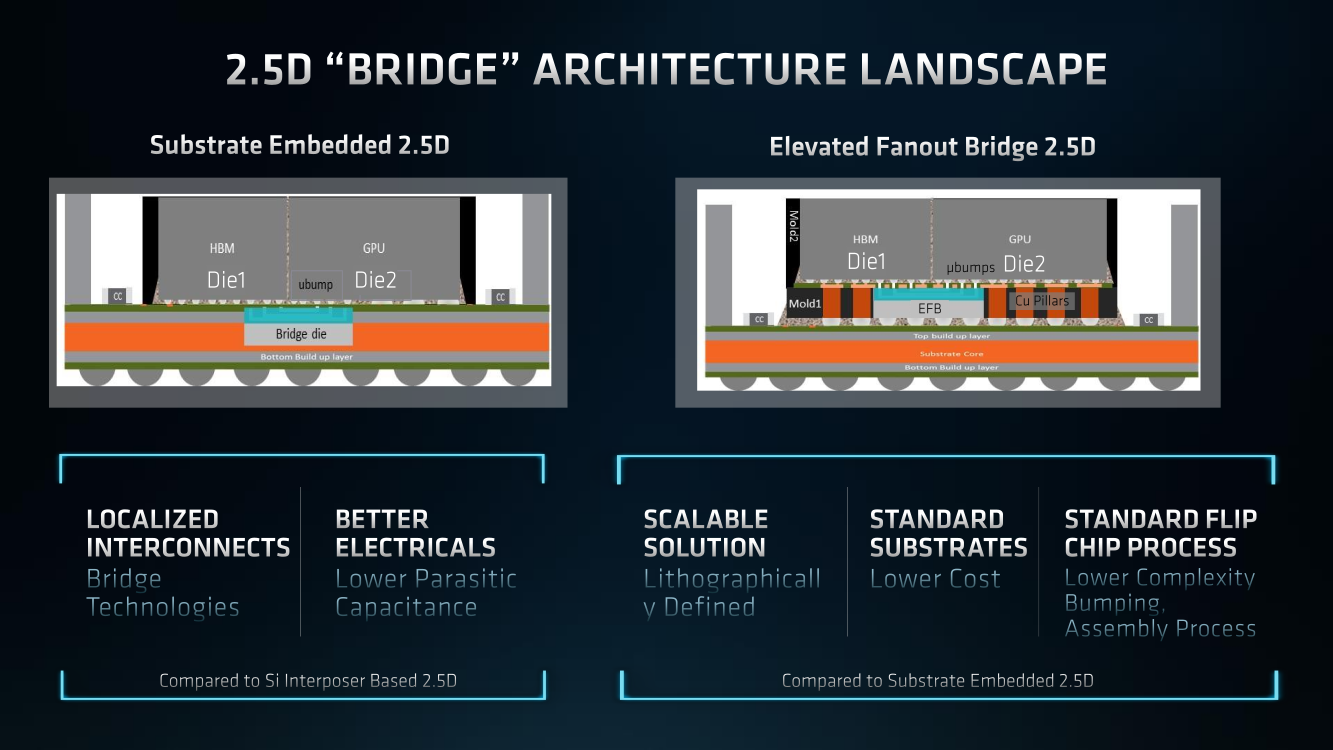 Несмотря на то, что в составе ускорителя два GCD, системе они представляются как единое целое с общей же памятью. Каждый GCD в случае CDNA 2 включает 112 CU (Compute Unit), но в конечных продуктах они задействованы не все. CU разбиты на четыре группы (с индивидуальным планировщиком) с общим L2-кешем объёмом 8 Мбайт и пропускной способностью 6,96 Тбайт/с, который поделён на 32 отдельных блока. А сами блоки имеют индивидуальные подключения к контроллерам памяти в GCD.  Важное отличие CDNA 2 заключается в «подтягивании» производительности векторных FP64- и FP32-вычислений — они исполняются с одинаковой скоростью в отличие от CDNA первого поколения. Кроме того, появилась поддержка сжатых (packed) инструкций для операций FMA/FADD/FMUL для FP32-векторов. Второй крупный апдейт касается матричных вычислений. Для них теперь тоже есть отдельная поддержка FP64, и с той же производительностью, что и для FP32. Новые инструкции рассчитаны на блоки 16×16×4 и 4×4×4.  Поддержка FP16/BF16 в матричных ядрах, конечно, тоже есть, что позволяет задействовать их и для ИИ-задач, а не только HPC. Подспорьем для них в некоторых задачах будут два блока VCN (Video Codec Next) в каждом GCD. Они поддерживают декодирование H.264/AVC, H.265/HEVC, VP9 и JPEG, а также кодирование H.264/H.265, что потенциально позволит более эффективно работать ИИ-алгоритмам с изображениями и/или видео.  Для обмена данными между ускорителями и CPU используется единая шина Infinity Fabric (IF) с поддержкой кеш-когерентности. Всего на ускоритель приходится до восьми внешних линий IF, а суммарная скорость обмена данными может достигать 800 Гбайт/c. В наиболее плотной компоновке из четырёх MI200 и одного EPYC каждый ускоритель имеет по две линии для связи с CPU и со своим соседом. Причём внутренние и внешние IF-линии образуют два двунаправленных кольца между ускорителями. Каждая IF-линия опирается на x16-подключение PCIe 4.0, но в данном случае есть ряд оптимизаций конкретно под HPC-системы HPE Cray.  Дополнительно у каждого ускорителя есть собственный root-комплекс, что позволяет напрямую подключить сетевой адаптер класса 200G. И это явный намёк на возможность непосредственного RDMA-соединения с внешними хранилищами, поскольку в такой схеме на локальные NVMe-накопители линий попросту не остаётся. Более простые топологии уже предполагают использование половины линий IF в качестве обычного PCIe-подключения и задействуют коммутатор(-ы) для связи с CPU и NIC. В этом случае IF-подключение остаётся только между процессорами. Зато в одной системе можно объединить восемь MI200.  Чипы ускорителей MI250X изготовлены по 6-нм техпроцессу FinFet, содержат 58 млрд транзисторов и предлагают 220 CU, включающих 880 ядер для матричных вычислений и 14080 шейдерных ядер второго поколения. У MI250 их 208, 832 и 13312 соответственно. Для обеих моделей уровень TDP составляет 500 или 560 Вт, поэтому поддерживается как воздушное, так и жидкостное охлаждение. В дополнение к OAM-версиям MI250(X) чуть позже появится и более традиционная PCIe-модель MI210.  Для сравнения — у NVIDIA A100 объём и пропускная способность памяти (тоже HBM2e) составляют до 80 Гбайт и 2 Тбайт/с соответственно. Шина же NVLink 3.0 имеет пропускную способность 600 Гбайт/c, а коммутатор NVSwitch для связи между восемью ускорителями — 1,8 Тбайт/с. Потребление SXM3-версии составляет 400 Вт. Стоит также отметить, что первая версия A100 появилась ещё весной 2020 года, и скоро ожидается анонс следующего поколения ускорителей на базе архитектуры Hopper. На носу и выход ускорителей Intel Xe Ponte Vecchio.  И если про первые мы пока ничего толком не знаем, то вторые, похоже, уже проиграли MI250X в «голой» производительности как минимум по одной позиции (FP32). AMD говорит, что создавала Instinct MI200 как серию универсальных ускорителей, пригодных и для «классических» HPC-задач, и для ИИ. Отсюда и практически пятикратная разница в пиковой FP64-производительности с NVIDIA A100. 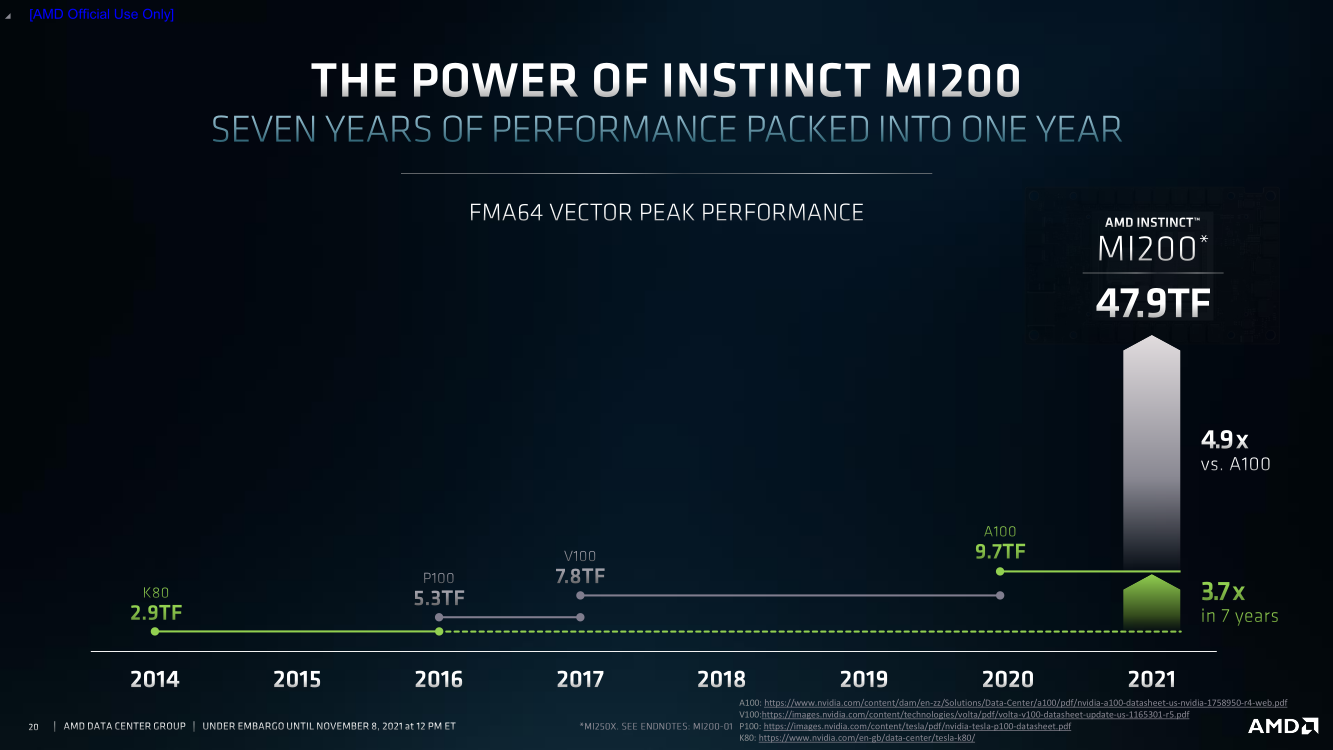 Но вот с нейронками всё не так однозначно. Предпочтительным форматом для обучения у NVIDIA является собственный TF32, поддержка которого есть в Tensor-ядрах Ampere. Ядра для матричных вычислений в CDNA2 про него ничего не знают, поэтому сравнить производительность в лоб нельзя. Разница в BF16/FP16 между MI250X и A100 уже не так велика, так что AMD говорит о приросте в 1,2 раза для обучения со смешанной точностью. 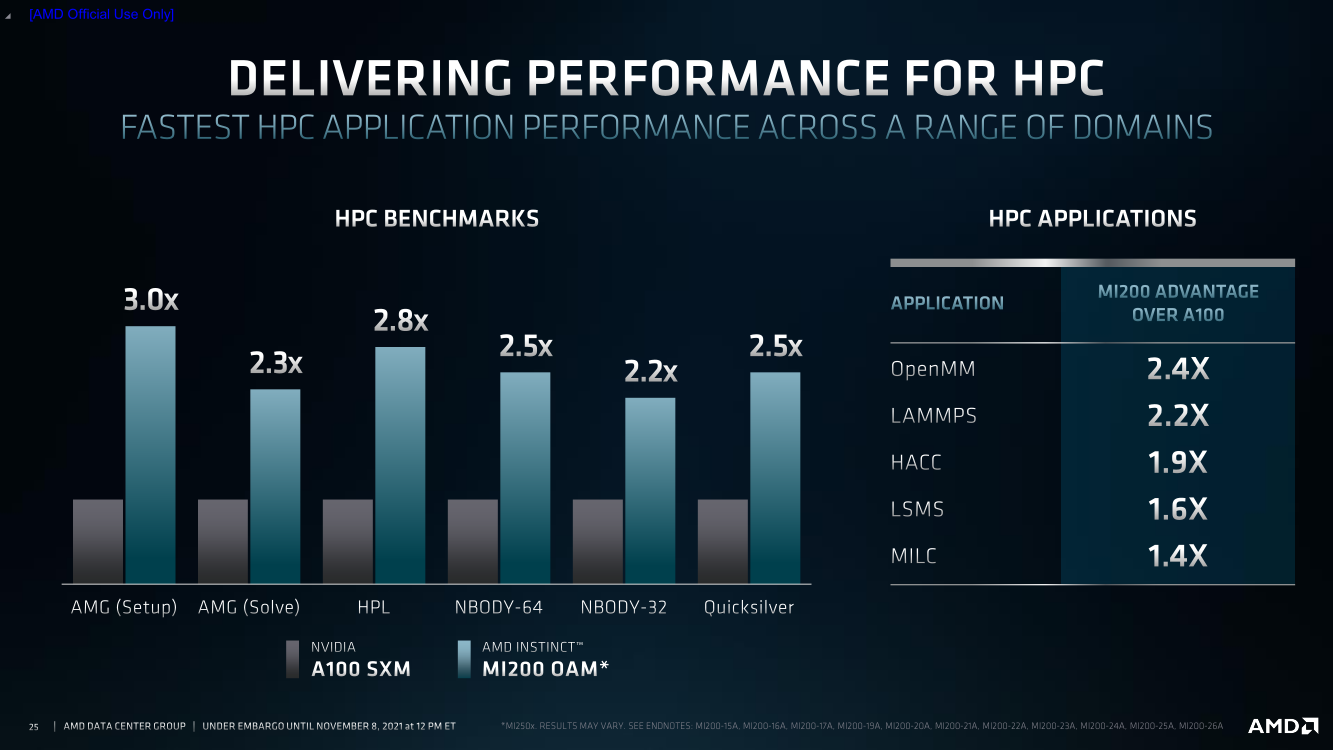 Данные по INT8 и INT4 в презентацию не вынесены, что неудивительно. Пиковый показатель для обоих форматов у MI250X составляет 383 Топс, тогда как тензорные ядра NVIDIA A100 выдают 624 и 1248 Топс соответственно. В данном случае больший объём памяти сыграл бы на руку MI200 в задачах инференса для крупных моделей. Наконец, у A100 есть ещё одно преимущество — поддержка MIG (Multi-Instance GPU), которая позволяет более эффективно задействовать имеющиеся ресурсы, особенно в облачных системах.  Вместе с Instinct MI200 была анонсирована и новая версия открытой (open source) платформы ROCm 5.0, которая обзавелась поддержкой и различными оптимизациями не только для этих ускорителей, но и, например, Radeon Pro W6800. В этом релизе компания уделит особое внимание расширению программной экосистемы и адаптации большего числа приложений. Кроме того, будет развиваться и новый портал Infinity Hub, где будет представлено больше готовых к использованию контейнеров с популярным ПО с рекомендациями по настройке и запуску.  AMD Instinct MI200 появятся в I квартале 2022 года. Новинки, в первую очередь MI210, будут доступны у крупных OEM/ODM-производителей: ASUS, Atos (X410-A5 2U1N2S), Dell Technologies, Gigabyte (G262-ZO0), HPE, Lenovo и Supermicro. Ускорители Instinct MI250X пока остаются эксклюзивом для систем HPE Cray Ex. Именно они вместе с «избранными» процессорами AMD EPYC (без уточнения, будут ли это Milan-X) станут основой для самого мощного в США суперкомпьютера Frontier.  Окончательный ввод в эксплуатацию этого комплекса запланирован на будущий год. Ожидается, что его пиковая производительность превысит 1,5 Эфлопс. При этом он должен стать самой энергоэффективной системой подобного класса. А адаптация ПО под него позволит несколько потеснить NVIDIA CUDA в некоторых областях. И это для AMD сейчас, пожалуй, гораздо важнее, чем победа по флопсам.
16.11.2020 [20:44], Алексей Степин
Подробности об архитектуре AMD CDNA ускорителей Instinct MI100Лидером в области использования графических архитектур для вычислений долгое время была NVIDIA, однако давний соперник в лице AMD вовсе не собирается сдавать свои позиции. В ответ на анонс архитектуры Ampere и ускорителей нового поколения A100 на её основе компания AMD сегодня ответила своим анонсом первого в мире ускорителя на основе архитектуры CDNA — сверхмощного процессора Instinct MI100. Достаточно долго подход к проектированию графических чипов оставался унифицированным, однако быстро выяснилось, что то, что хорошо для игр, далеко не всегда хорошо для вычислений, а некоторые возможности для областей применения, не связанных с рендерингом 3D-графики, попросту избыточны. Примером могут служить модули растровых операций (RBE/ROP) или наложения текстур. Произошло то, что должно было произойти: слившиеся на какое-то время воедино ветви эволюции «графических» и «вычислительных» процессоров вновь начали расходиться. И новый процессор AMD Instinct MI100 относится к чисто вычислительной ветви развития подобного рода чипов.  Теперь AMD имеет в своём распоряжении две основных архитектуры, RDNA и CDNA, которые и представляют собой вышеупомянутые ветви развития GPU. Естественно, новый процессор Instinct MI100 унаследовал у своих собратьев по эволюции многое — в частности, блоки исполнения скалярных и векторных инструкций: в конце концов, всё равно, работают ли они для расчёта графики или для вычисления чего-либо иного. Однако новинка содержит и ряд отличий, позволяющих ей претендовать на звание самого мощного и универсального в мире ускорителя на базе GPU. 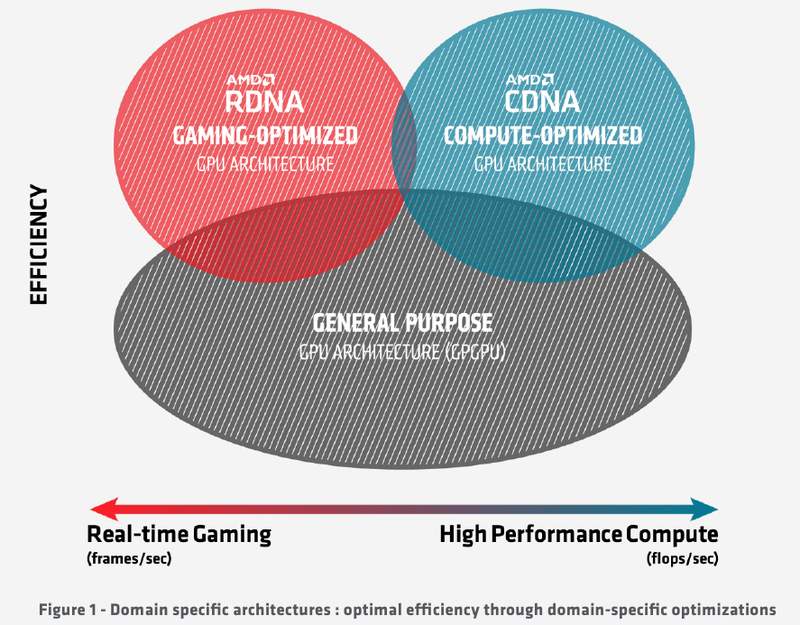
Схема эволюции графических процессоров: налицо дивергенция признаков AMD в последние годы существенно укрепила свои позиции, и это отражается в создании собственной единой IP-инфраструктуры: новый чип выполнен с использованием 7-нм техпроцесса и все системы интерконнекта, как внутренние, так и внешние, в MI100 базируются на шине AMD Infinity второго поколения. Внешние каналы имеют ширину 16 бит и оперируют на скорости 23 Гт/с, однако если в предыдущих моделях Instinct их было максимум два, то теперь количество каналов Infinity Fabric увеличено до трёх. Это позволяет легко организовывать системы на базе четырёх MI100 с организацией межпроцессорного общения по схеме «все со всеми», что минимизирует задержки. 
Ускорители Instinct MI100 получили третий канал Infinity Fabric Общую организацию внутренней архитектуры процессор MI100 унаследовал ещё от архитектуры GCN; его основу составляют 120 вычислительных блоков (compute units, CU). При принятой AMD схеме «64 шейдерных блока на 1 CU» это позволяет говорить о 7680 процессорах. Однако на уровне вычислительного блока архитектура существенно переработана, чтобы лучше отвечать требованиям, предъявляемым современному вычислительному ускорителю. В дополнение к стандартным блокам исполнения скалярных и векторных инструкций добавился новый модуль матричной математики, так называемый Matrix Core Engine, но из кремния MI100 удалены все блоки фиксированных функций: растеризации, тесселяции, графических кешей и, конечно, дисплейного вывода. Универсальный движок кодирования-декодирования видеоформатов, однако, сохранён — он достаточно часто используется в вычислительных нагрузках, связанных с обработкой мультимедийных данных. 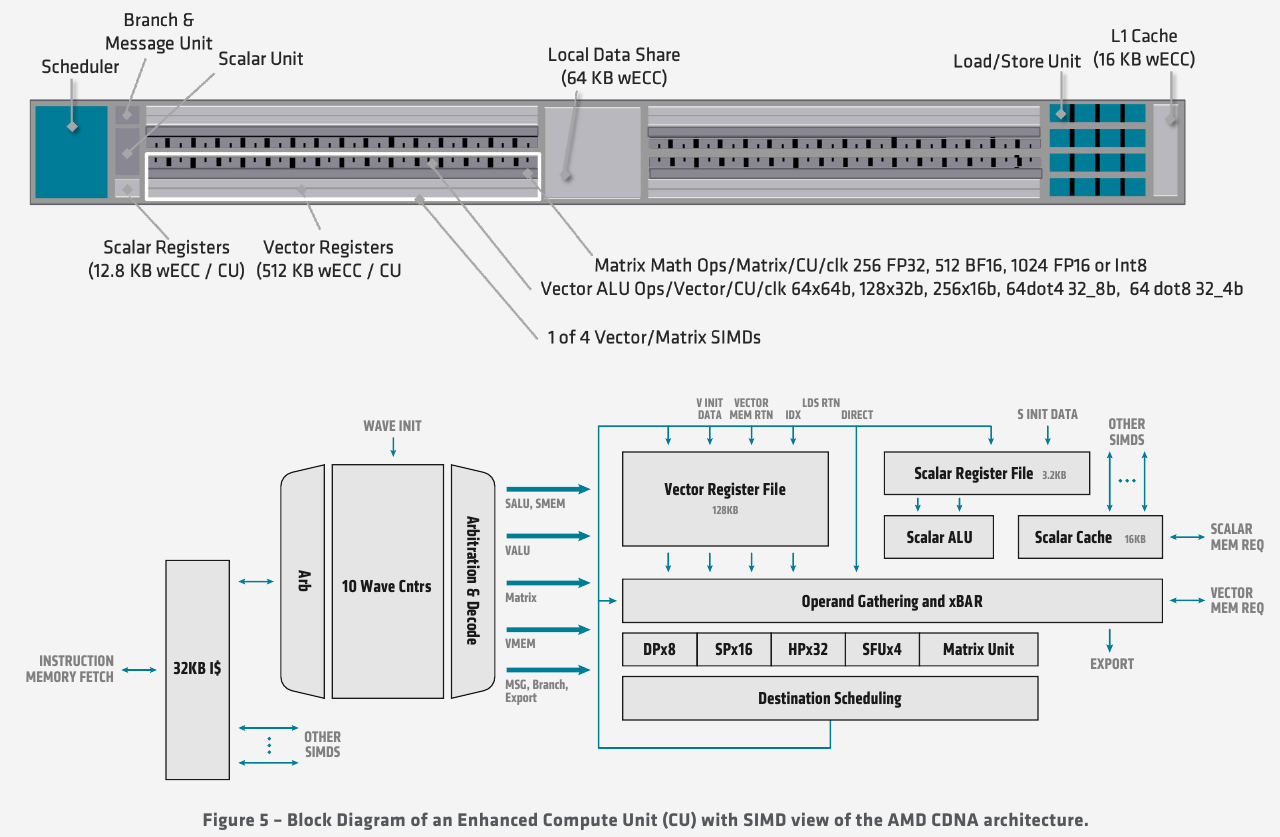
Структурная схема вычислительных модулей в MI100 Каждый CU содержит в себе по одному блоку скалярных инструкций со своим регистровым файлом и кешем данных, и по четыре блока векторных инструкций, оптимизированных для вычислений в формате FP32 саналогичными блоками. Векторные модули имеют ширину 16 потоков и обрабатывают 64 потока (т.н. wavefront в терминологии AMD) за четыре такта. Но самое главное в архитектуре нового процессора — это новые блоки матричных операций. Наличие Matrix Core Engines позволяет MI100 работать с новым типом инструкций — MFMA (Matrix Fused Multiply-Add). Операции над матрицами размера KxN могут содержать смешанные типы входных данных: поддерживаются режимы INT4, INT8, FP16, FP32, а также новый тип Bfloat16 (bf16); результат, однако, выводится только в форматах INT32 или FP32. Поддержка столь многих типов данных введена для универсальности и MI100 сможет показать высокую эффективность в вычислительных сценариях разного рода. 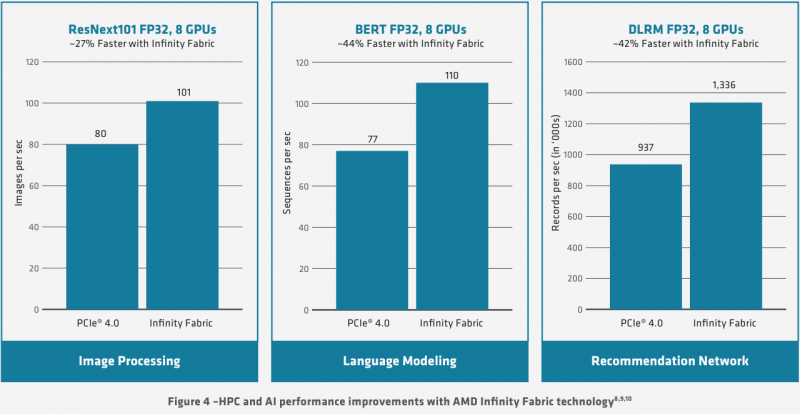
Использование Infinity Fabric 2.0 позволило ещё более увеличить производительность MI100 Каждый блок CU имеет свой планировщик, блок ветвления, 16 модулей load-store, а также кеши L1 и Data Share объёмами 16 и 64 Кбайт соответственно. А вот кеш второго уровня общий для всего чипа, он имеет ассоциативность 16 и объём 8 Мбайт. Совокупная пропускная способность L2-кеша достигает 6 Тбайт/с. Более серьёзные объёмы данных уже ложатся на подсистему внешней памяти. В MI100 это HBM2 — новый процессор поддерживает установку четырёх или восьми сборок HBM2, работающих на скорости 2,4 Гт/с. Общая пропускная способность подсистемы памяти может достигать 1,23 Тбайт/с, что на 20% быстрее, нежели у предыдущих вычислительных ускорителей AMD. Память имеет объём 32 Гбайт и поддерживает коррекцию ошибок. 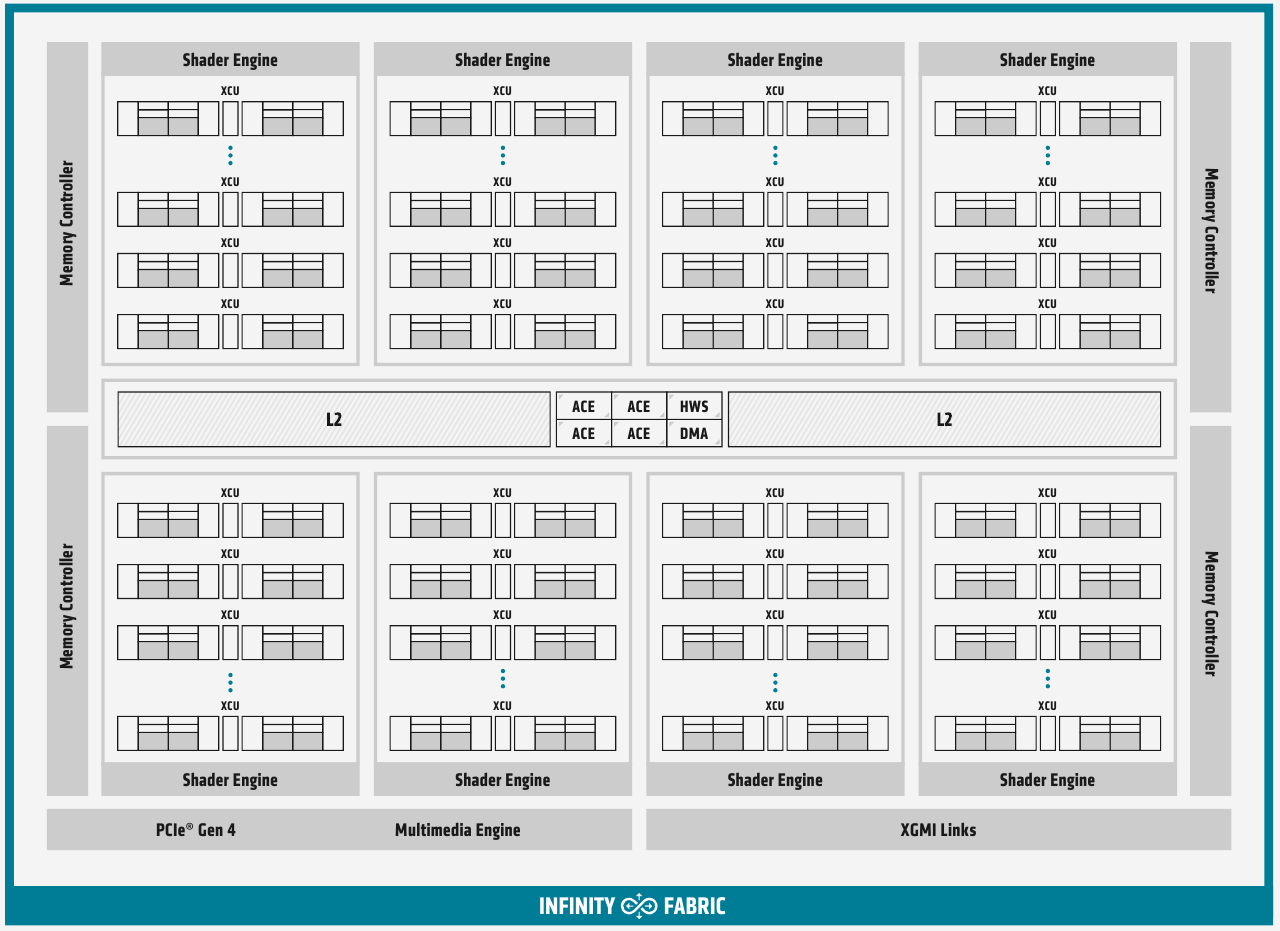
Общая блок-схема Instinct MI100 «Мозг» чипа Instinct MI100 составляют четыре командных процессора (ACE на блок-схеме). Их задача — принять поток команд от API и распределить рабочие задания по отдельным вычислительным модулям. Для подключения к хост-процессору системы в составе MI100 имеется контроллер PCI Express 4.0, что даёт пропускную способность на уровне 32 Гбайт/с в каждом направлении. Таким образом, «уютнее всего» ускоритель Instinct MI100 будет чувствовать себя совместно с ЦП AMD EPYC второго поколения, либо в системах на базе IBM POWER9/10. Избавление от лишних архитектурных блоков и оптимизация архитектуры под вычисления в как можно более широком числе форматов позволяют Instinct MI100 претендовать на универсальность. Ускорители с подобными возможностями, как справедливо считает AMD, станут важным строительным блоком в экосистеме HPC-машин нового поколения, относящихся к экзафлопсному классу. AMD заявляет о том, что это первый ускоритель, способный развить более 10 Тфлопс в режиме двойной точности FP64 — пиковый показатель составляет 11,5 Тфлопс. 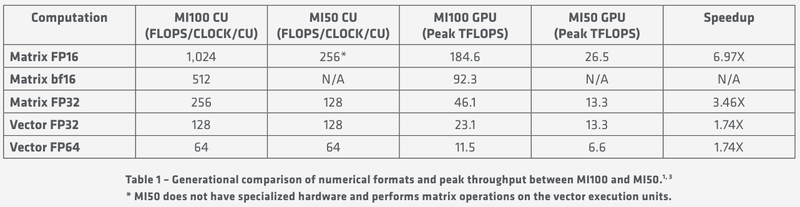
Удельные и пиковые показатели производительности MI100 В менее точных форматах новинка пропорционально быстрее, и особенно хорошо ей даются именно матричные вычисления: для FP32 производительность достигает 46,1 Тфлопс, а в новом, оптимизированном под задачи машинного обучения bf16 — и вовсе 92,3 Тфлопс, причём, ускорители Instinct предыдущего поколения таких вычислений выполнять вообще не могут. В зависимости от типов данных, превосходство MI100 перед MI50 варьируется от 1,74х до 6,97x. Впрочем, NVIDIA A100 в этих задача всё равно заметно быстрее, а вот в FP64/FP32 проигрывают. |
|

