Материалы по тегу: trainium
|
13.11.2024 [22:21], Руслан Авдеев
Поработайте за нас: AWS предоставит учёным кластеры из 40 тыс. ИИ-ускорителей TrainiumAWS намерена привлечь больше людей к разработке ИИ-приложений и фреймворков, использующих разработанные Amazon ускорители семейства Tranium. В рамках нового инициативы Build on Trainium с финансированием в объёме $110 млн академическим кругам будет предоставлен доступ к кластерам UltraClaster, включающим до 40 тыс. ускорителей, сообщает The Register. В рамках программы Build on Trainium предполагается обеспечить доступ к кластеру представителям университетов, которые заняты разработкой новых ИИ-алгоритмов, которые позволяет повысить эффективность использования ускорителей и улучшить масштабирование вычислений в больших распределённых системах. На каком поколении чипов, Trainium1 или Trainium2, будут построены кластеры, не уточняется. 
Источник изображений: AWS Как поясняют в самом блоге AWS, исследователи могут придумать новую архитектуру ИИ-моделей или новую технологию оптимизации производительности, но у них может не оказаться доступа к HPC-ресурсам для крупных экспериментов. Не менее важно, что плоды трудов, как ожидается, будут распространяться по модели open source, поэтому от этого выиграет вся экосистема машинного обучения. Впрочем, со стороны AWS альтруизма мало. Во-первых, $110 млн будут выданы выбранным проектам в виде облачных кредитов, такое происходит не впервые. Во-вторых, компания фактически пытается переложить часть своих задач на других людей. Кастомные чипы AWS, включая ИИ-ускорители для обучения и инференса, изначально разрабатывались для повышения эффективности выполнения внутренних задач компании. Однако низкоуровневые фреймворки и т.п. ПО не предназначены для того, чтобы с ними мог свободно работать широкий круг лиц как, например, происходит с NVIDIA CUDA.  Иными словам, AWS для популяризации Trainium необходимо более простое в освоение ПО, а ещё лучше готовые решения прикладных задач. Неслучайно Intel и AMD склонны предлагать разработчикам готовые оптимизированные под их ускорители фреймворки вроде PyTorch и TensorFlow, а не пытаться заставить их заниматься достаточно низкоуровневым программированием. AWS занимается тем же самым, предлагая продукты вроде SageMaker. Во многом реализация проекта возможна благодаря новому интерфейсу Neuron Kernel Interface (NKI) для AWS Tranium и Inferentia, обеспечивающему прямой доступ к набору инструкций чипов и позволяющему исследователям строить оптимизированные вычислительные ядра для работы новых моделей, оптимизации производительности и инноваций в целом. Впрочем, учёным — в отличие от обычных разработчиков — часто интересно работать именно с низкоуровневыми системами.
29.06.2024 [13:08], Сергей Карасёв
Энергопотребление ИИ-ускорителя AWS Trainium 3 может достигать 1000 ВтОблачная платформа Amazon Web Services (AWS) готовит ИИ-ускоритель нового поколения — изделие Trainium 3. Завесу тайны над этим решением, как сообщает ресурс Fierce Networks, приоткрыл вице-президент компании по инфраструктурным услугам Прасад Кальянараман (Prasad Kalyanaraman). Оригинальный ускоритель AWS Trainium дебютировал в конце 2021 года. Его производительность — 3,4 Пфлопс на вычислениях малой точности и до 840 Тфлопс в FP32-расчётах. В ноябре 2023-го было представлено решение AWS Trainium 2, которое, как утверждается, вчетверо производительнее первой версии. Теперь AWS готовит изделие третьего поколения. Кальянараман намекнул, что энергопотребление Trainium 3 достигнет 1000 Вт или более. Он не стал называть конкретные цифры, но сказал, что для ускорителя планируется применение СЖО. «Текущее поколение ускорителей не требует СЖО, но следующему она понадобится. Когда мощность чипа превышает 1000 Вт, ему необходимо жидкостное охлаждение», — отметил Кальянараман. 
Источник изображения: AWS В настоящее время единственными ИИ-изделиями, показатель TDP которых достигает 1000 Вт, являются ускорители NVIDIA Blackwell. Вместе с тем, по имеющимся сведениям, Intel разрабатывает устройство в соответствующей категории с энергопотреблением на уровне 1500 Вт. На текущий момент почти все дата-центры AWS используют технологию воздушного охлаждения. Но Кальянараман сказал, что компания рассматривает возможность внедрения технологии однофазной СЖО (а не иммерсионного охлаждения) для поддержки ресурсоёмких рабочих нагрузок. К внедрению СЖО вынужденно пришли и Meta✴ с Microsoft — компании используют гибридный подход с водоблоками на чипах и теплообменниками на дверях стойки или же в составе отдельной стойки. Кроме того, отметил Кальянараман, AWS стремится к дальнейшей оптимизации своих ЦОД путём «стратегического позиционирования стоек» и модернизации сетевой архитектуры. Речь идёт о применении коммутаторов следующего поколения с пропускной способностью до 51,2 Тбит/с, а также оптических компонентов.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев. Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
07.12.2021 [00:36], Алексей Степин
ИИ-ускорители AWS Trainium: 55 млрд транзисторов, 3 ГГц, 512 Гбайт HBM и 840 Тфлопс в FP32GPU давно применяются для ускорений вычислений и в последние годы обросли поддержкой специфических форматов данных, характерных для алгоритмов машинного обучения, попутно практически лишившись собственно графических блоков. Но в ближайшем будущем их по многим параметрам могут превзойти специализированные ИИ-процессоры, к числу которых относится и новая разработка AWS, чип Trainium. На мероприятии AWS Re:Invent компания рассказала о прогрессе в области машинного обучения на примере своих инстансов P3dn (Nvidia V100) и P4 (Nvidia A100). Первый вариант дебютировал в 2018 году, когда модель BERT-Large была примером сложности, и благодаря 256 Гбайт памяти и сети класса 100GbE он продемонстрировал впечатляющие результаты. Однако каждый год сложность моделей машинного обучения растёт почти на порядок, а рост возможностей ИИ-ускорителей от этих темпов явно отстаёт. 
Сложность моделей машинного обучения будет расти всё быстрее Когда в прошлом году был представлен вариант P4d, его вычислительная мощность выросла в четыре раза, а объём памяти и вовсе на четверть, в то время как знаменитая модель GPT-3 превзошла по сложности BERT-Large в 500 раз. А теперь и 175 млрд параметров последней — уже ничто по сравнению с 10 трлн в новых моделях. Приходится наращивать и объём локальной памяти (у Trainium имеется 512 Гбайт HBM с суммарной пропускной способностью 13,1 Тбайт/с), и активнее использовать распределённое обучение.  Для последнего подхода узким местом стала сетевая подсистема, и при разработке стека Elastic Fabric Adapter (EFA) компания это учла, наделив новые инстансы Trn1 подключением со скоростью 800 Гбит/с (вдвое больше, чем у P4d) и с ультранизкими задержками, причём доступен и более оптимизированный вариант Trn1n, у которого пропускная способность вдвое выше и достигает 1,6 Тбит/с. Для связи между самими чипами внутри инстанса используется интерконнект NeuroLink со скоростью 768 Гбайт/с. 
Прогресс подсистем сети и памяти в ИИ-инстансах AWS Но дело не только в возможности обучить GPT-3 менее чем за две недели: важно и количество используемых для этого ресурсов. В случае P3d это потребовало бы 600 инстансов, работающих одновременно, и даже переход к архитектуре Ampere снизил бы это количество до 200. А вот обучение на базе чипов Trainium требует всего 130 инстансов Trn1. Благодаря оптимизациям, затраты на «общение» у новых инстансов составляют всего 7% против 14% у Ampere и целых 49% у Volta. 
Меньше инстансов, выше эффективность при равном времени обучения — вот что даст Trainium Trainium опирается на систолический массив (Google использовала тот же подход для своих TPU), т.е. состоит из множества очень тесно связанных вычислительных блоков, которые независимо обрабатывают получаемые от соседей данные и передают результат следующему соседу. Этот подход, в частности, избавляет от многочисленных обращений к регистрам и памяти, что характерно для «классических» GPU, но лишает подобные ускорители гибкости.  В Trainium, по словам AWS, гибкость сохранена — ускоритель имеет 16 полностью программируемых (на С/С++) обработчиков. Есть и у него и другие оптимизации. Например, аппаратное ускорение стохастического округления, которое на сверхбольших моделях становится слишком «дорогим» из-за накладных расходов, хотя и позволяет повысить эффективность обучения со смешанной точностью. Всё это позволяет получить до 3,4 Пфлопс на вычислениях малой точности и до 840 Тфлопс в FP32-расчётах. 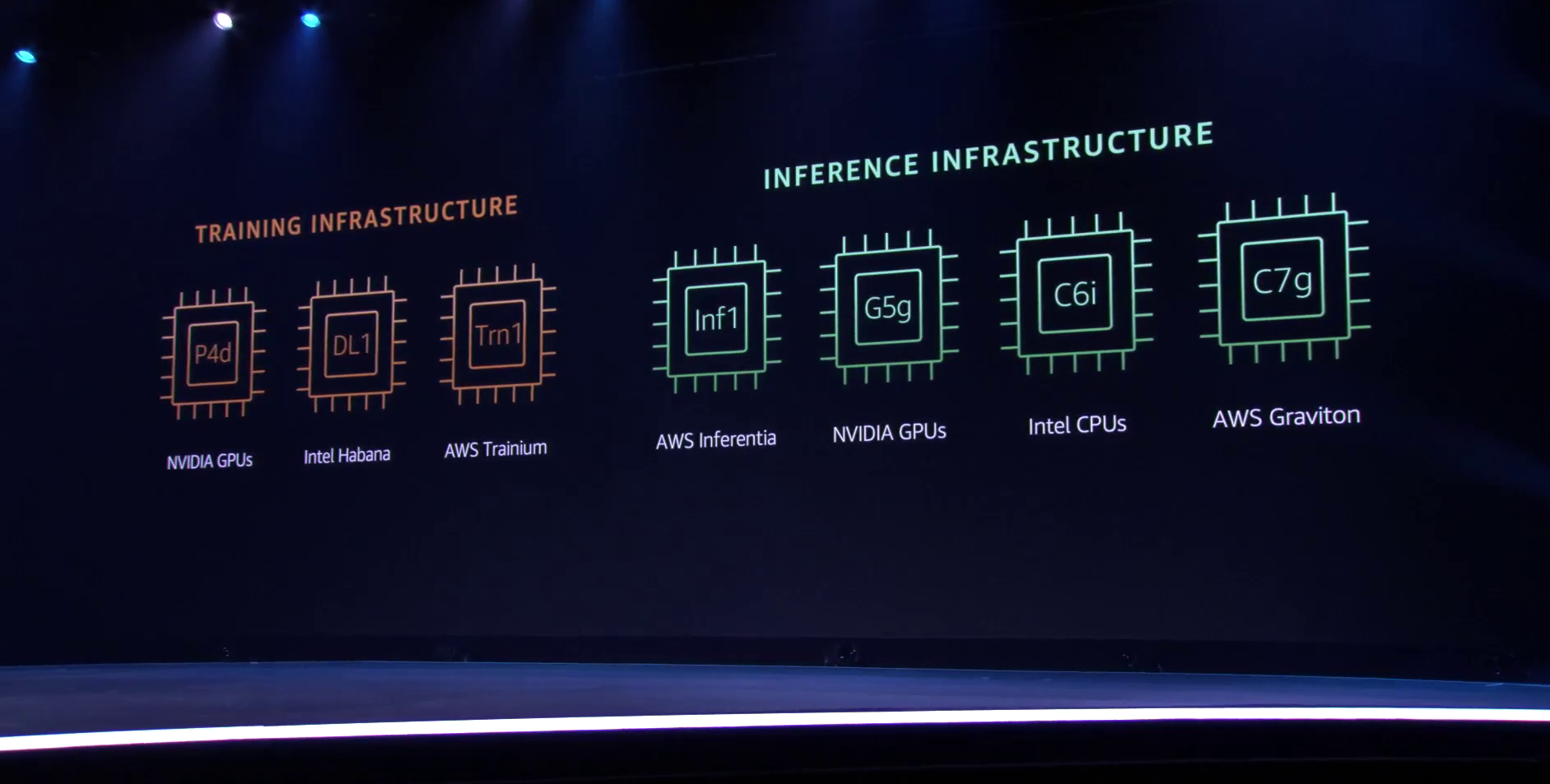 AWS постаралась сделать переход к Trainium максимально безболезненным для разработчиков, поскольку SDK AWS Neuron поддерживает популярные фреймворки машинного обучения. Впрочем, насильно загонять заказчиков на инстансы Trn1 компания не собирается и будет и далее предоставлять на выбор другие ускорители поскольку переход, например, с экосистемы CUDA может быть затруднён. Однако в вопросах машинного обучения для собственных нужд Amazon теперь полностью независима — у неё есть и современный CPU Graviton3, и инфереренс-ускоритель Inferentia. |
|


