Материалы по тегу: hpc
|
19.01.2025 [22:43], Сергей Карасёв
Германия запустила «переходный» 48-Пфлопс суперкомпьютер Hunter на базе AMD Instinct MI300AЦентр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии объявил о вводе в эксплуатацию НРС-системы Hunter. Этот суперкомпьютер планируется использовать для решения широко спектра задач в области инженерии, моделирования погоды и климата, биомедицинских исследований, материаловедения и пр. Кроме того, комплекс будет применяться для крупномасштабного моделирования, ИИ-приложений и анализа данных. О создании Hunter сообщалось в конце 2023 года: соглашение на строительство системы стоимостью примерно €15 млн было заключено с HPE. Проект финансируется Федеральным министерством образования и исследований Германии и Министерством науки, исследований и искусств Баден-Вюртемберга. Hunter базируется на той же архитектуре, что El Capitan — самый мощный в мире суперкомпьютер. Задействована платформа Cray EX4000, а каждый из узлов оснащён четырьмя адаптерами HPE Slingshot. Суперкомпьютер использует комбинацию из APU Instinct MI300A и процессоров EPYC Genoa. Как отмечает The Register, в общей сложности система объединяет 188 узлов с жидкостным охлаждением и насчитывает суммарно 752 APU и 512 чипов Epyc с 32 ядрами. Применена СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для суперкомпьютеров HPE Cray. 
Источник изображения: HLRS HLRS оценивает пиковую теоретическую FP64-производительность Hunter в 48,1 Пфлопс на операциях двойной точности, что практически вдвое выше, чем у предшественника Hawk. В режимах BF16 и FP8 быстродействие, как ожидается, будет варьироваться от 736 Пфлопс до 1,47 Эфлопс. При этом Hunter потребляет на 80% меньше энергии, нежели Hawk. 
Источник изображения: Штутгартский университет Отмечается, что Hunter задуман как переходная система, которая подготовит почву для суперкомпьютера HLRS следующего поколения под названием Herder. Ввести этот комплекс в эксплуатацию планируется в 2027 году. Предполагается, что он обеспечит производительность «в несколько сотен петафлопс».
17.01.2025 [22:46], Руслан Авдеев
Aligned Data Centers получила $12 млрд на расширение парка ИИ ЦОДТехасский оператор ЦОД Aligned Data Centers объявил о привлечении $12 млрд на постройку ИИ ЦОД мощностью 5 ГВт в Северной и Южной Америках. $5 млрд поступило в виде акционерного капитала из фондов, подконтрольных Macquarie Asset Management, ещё $7 млрд — в виде долговых обязательств, сообщает SiliconAngle. В Aligned заявляют, что у неё уникальное положение на рынке — у компании более 10 лет опыта в создании систем охлаждения энергоёмких дата-центров. Последнее поколение фирменных СЖО DeltaFlow~ позволяет повысить плотность размещения ресурсов до 300 кВт на стойку. Также компания разработала систему воздушного охлаждения Delta3 (Delta Cube). Aligned Data Centers управляет многочисленными колокейшн-объектами. Также она строит дата-центры для гиперскейлеров и корпоративных клиентов. В США компания управляет объектами в Чикаго, Далласе, Финиксе, Солт-Лейк-Сити и Северной Вирджинии. Новые площадки строятся в Вирджинии, Иллинойсе, Мэриленде и Огайо. В мае 2024 года Aligned купила бразильского оператора ЦОД OData, у которого уже были объекты в Бразилии, Чили, Мексике и Колумбии. Наконец, компания инвестировала в канадского оператора QScale SEC. 
Источник изображения: Aligned Data Centers Быстрый рост ИИ в последние годы вызвал и рост спроса на высокопроизводительные дата-центры, способные вместить тысячи ускорителей одновременно. В результате бизнес Aligned значительно вырос. Упомянутая австралийская Macquarie совсем недавно сообщила, что выделит до $5 млрд на ИИ ЦОД Applied Digital — ещё одного американского оператора дата-центров.
17.01.2025 [01:07], Алексей Степин
США готовятся к созданию суперкомпьютера нового поколения с 10 Пбайт RAMСуперкомпьютеру Crossroads (ATS-3), расположенному в Лос-Аламосской национальной лаборатории (LANL) Министерства энергетики США (DoE), не так уж много лет. Система мощностью 30 Пфлопс запущена в 2023 году, но ей уже готовится замена в лице суперкомпьютера нового поколения под кодовым названием ATS-5. Министерство энергетики совместно с Национальным управлением по ядерной безопасности (NNSA) раскрыли некоторые детали, касающиеся этого проекта. Главной задачей ATS-5 станет запуск высокоточных 3D-симуляций для оценки перспектив модернизации и поддержания в актуальном состоянии ядерного арсенала США. Симуляции со столь высокой детализацией очень сложны и относятся к классу «геройских» (hero-class). Их прогон может занимать несколько месяцев, но ATS-5 должен не только сократить это время до дней, но и обеспечить обработку нескольких таких симуляций параллельно. 
Монтаж Crossroads. Источник здесь и далее LANL NNSA не сообщает о том, будет ли ATS-5 относится к системам экзафлопсного класса, но судя по употреблению термина «post-exascale system» и сложности планируемых для запуска симуляций, новый суперкомпьютер будет достаточно мощным. Известен уровень его энергопотребления — порядка 20 МВт. Для сравнения, Frontier (1,35 Эфлопс FP64) потребляет 21 МВт, а El Capitan (1,74 Эфлопс FP64) — около 30 МВт. По замыслу DoE, ATS-5 станет модульной системой со смешанной архитектурой, сфокусированной не только на HPC-задачах (FP64), но и на ИИ-сценариях с их упрощёнными форматами вычислений. Упор делается на размещении данных ближе к вычислительным узлам, увеличении объёмов памяти (в настоящее время заявлено 10,1 Пбайт) и ускорении её работы.  В качестве интерконнекта может быть применена смесь технологий InfiniBand и Ethernet, развивающая от 100 до 300 Гбайт/с в каждом направлении. Модульность означает возможность замены ускорителей и процессоров на протяжении всего срока эксплуатации ATS-5. Помимо ускорителей NVIDIA рассматривается возможность использования квантовых ускорителей, а также чипов Cerebras, Groq и SambaNova. ПО практически целиком должно быть open source, но и от CUDA при необходимости отказываться не будут. Министерство энергетики США надеется разместить контракт на постройку ATS-5 в мае текущего года. Поставки оборудования должны начаться в конце 2026 или начале 2027 гг, а ввод системы в строй намечен на август-сентябрь 2027 года. Тогда же будет выведен из строя Crossroads (ATS-3).
16.01.2025 [17:10], Руслан Авдеев
Австралийская Macquarie выделит до $5 млрд на ИИ ЦОД Applied DigitalВенчурные капиталисты пока не боятся возможного финансового «пузыря», связанного с ИИ-технологиями, поэтому вливают миллиарды долларов в новые ИИ ЦОД. Так, австралийская финансовая компания Macquarie сообщила о намерении вложить $5 млрд в проекты американского оператора дата-центров Applied Digital, сообщает The Register. Техасский оператор работает на рынке ИИ и HPC относительно недавно, но это не мешает ему на равных соперничать с сильными конкурентами с более богатой историей. Во многом история компания напоминает путь CoreWeave, вышедшей на рынок HPC-объектов приблизительно в 2022 году и свернувшей бизнес по майнингу криптовалют. Applied Digital, как и CoreWeave и Lambda Labs, предлагает услуги ЦОД и облачные сервисы на базе ускорителей NVIDIA. Австралийские инвестиции, в том числе в ходе начального раунда финансирования в объёме $900 млн, позволят компании продолжить работу над кампусом Ellendale High Performance Computing в Северной Дакоте мощностью 100 МВт (до 400 МВт в перспективе), а также вернуть порядка $300 млн, ранее инвестированных в объект в виде акционерного капитала. 
Источник изображений: Applied Digital Кампус в Эллендейле (Ellendale) — лишь одна из площадок Applied Digital, в которые Macquarie готова вложить средства. В соответствии с новым соглашением, она получила преимущественное право участвовать в новых проектах, связанных с ИИ ЦОД в следующие 30 месяцев на сумму $4,1 млрд. В Applied Digital заявляют, что с сегодняшними ценами на строительство у компании будет значительная часть средств, необходимых для создания HPC-объектов мощностью более 2 ГВт, включая кампус в Эллендейле. Место, по-видимому, привлекательное для таких объектов — две неизвестных компании готовы потратить до $250 млрд на строительство в штате гигаваттных ИИ ЦОД. Пока не сообщается, когда, где и сколько дата-центров Applied Digital в итоге построят, но, согласно пресс-релизу, объекты получат жидкостное охлаждение. Вероятнее всего, как и в Северной Дакоте, другие объекты получат ускорители NVIDIA. Не исключено даже использование 120-кВт GB200 NVL72. В сентябре NVIDIA вместе с другими инвесторами сама вложила в оператора $160 млн. Большая часть инвестиций, вероятно, вернётся в виде заказов на чипы и подписки AI Enterprise. Что касается Macquarie, она фактически выкупила себе 15 % в бизнесе Applied HPC, а оператор сохранил за собой 85 %. 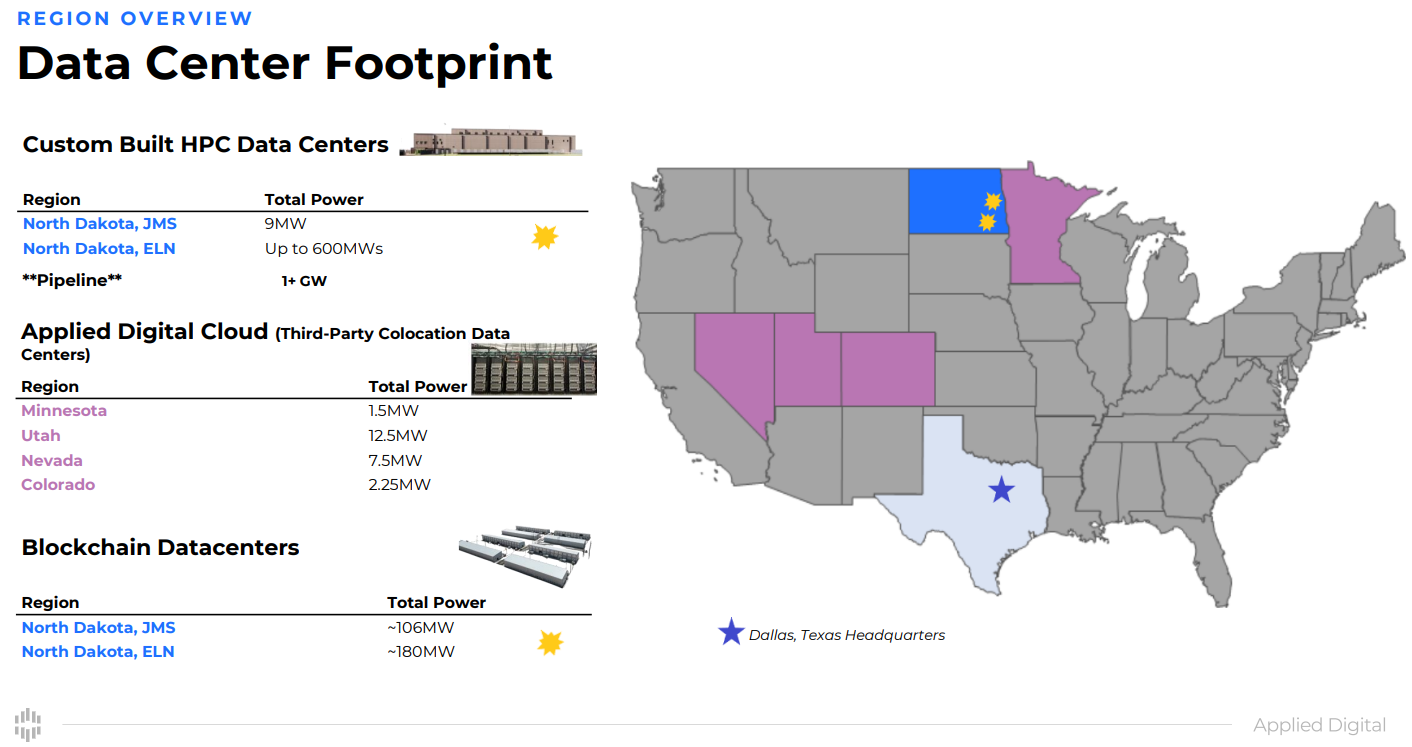 $1,5 млрд обычно достаточно для создания ЦОД с 16 тыс. ускорителей уровня NVIDIA H100 для последующей сдачи в аренду. В течение четырёх лет это принесёт около $5,27 млрд выручки при благоприятных условиях. С учётом уровня окупаемости инвестиций нетрудно понять, почему многие инвесторы желают участвовать в подобных проектах. Не мешает и высокий спрос на ускорители — иногда они используются в качестве залога при крупных кредитах. Так, в апреле 2024 года Macquarie помогла привлечь Lambda порядка $500 млн заёмного финансирования под залог ускорителей NVIDIA. Среди крупнейших бенефициаров таких сделок — CoreWeave, по данным Crunchbase, только в 2024 году получившая $9,9 млрд финансирования и заёмных средств. Деньги под залог ускорителей она брала ещё в 2023 году.
15.01.2025 [11:24], Владимир Мироненко
В совет директоров UALink вошли представители Alibaba, Apple и SynopsysКонсорциум Ultra Accelerator Link (UALink) объявил о расширении состава совета директоров представителями Alibaba Cloud, Apple и Synopsys. Новые члены совета будут использовать свои отраслевые знания для продвижения разработки и внедрения в отрасли UALink — высокоскоростного масштабируемого интерконнекта для производительных ИИ-кластеров следующего поколения, указано в пресс-релизе. Фактически UALink занят созданием более открытой альтернативы NVLink. С момента основания в конце октября 2024 года количество участников UALink выросло до более чем 65 компаний, сообщил Куртис Боуман (Kurtis Bowman), председатель совета директоров UALink. Новые участники совета директоров заявили, что совместная работа над интерконнектом для ускорителей будет способствовать повышению эффективности выполнения рабочих нагрузок ИИ. Представитель Apple отметил, что UALink демонстрирует большие перспективы в решении проблем подключения и создании новых возможностей ИИ-индустрии. В консорциум входит широкий круг компаний, от поставщиков облачных услуг и OEM-производителей до разработчиков ПО и полупроводниковых компонентов во главе с AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, представляющих основные области разработки решений для повышения производительности нагрузок ИИ. 
Источник изображения: UALink Ожидается, что выпуск спецификации UALink 1.0 состоится в I квартале 2025 года. Она предусматривает пропускную способность до 200 Гбит/с на линию и возможность объединения до 1024 ИИ-ускорителей в пределах одного домена.
15.01.2025 [08:38], Руслан Авдеев
Новые ЦОД стоимостью £14 млрд помогут Великобритании превратиться в ИИ-сверхдержавуВ рамках нового плана британского правительства по развитию ИИ-проектов анонсированы инициативы по созданию ЦОД на общую сумму £14 млрд ($16,96 млрд). Так, Vantage, Nscale и Kyndryl обязались инвестировать в местную цифровую инфраструктуру и создать 13 тыс. рабочих мест. Планом предусмотрено и строительство нового ИИ-суперкомпьютера, сообщает Datacenter Dynamics. Ещё до объявления новой программы правительства об инвестициях в британские ЦОД сообщили Blackstone (£10 млрд) и DC01UK (£3,75 млрд), а также Cloud HQ, CyrusOne, CoreWeave и ServiceNow (суммарно £6,3 млрд) В рамках программы AI Opportunities Action Plan, некоторые детали которой появились ещё в ноябре, по всей стране будут созданы «Зоны роста ИИ» с приоритетным доступом к технологиям и энергии, призванные привлечь инвестиции со всего мира. Зоны станут и полигоном для энергетических проектов, связанных с ЦОД. Особая роль отведена атомной энергетике. Первую зону построят в Калхэме (графство Оксфордшир), где находится Управление по атомной энергии Великобритании и расположены кампусы AWS и CloudHQ. Оператор NScale объявил о намерении инвестировать в Великобританию £2,5 млрд ($3 млрд), где построит свой первый ИИ ЦОД в графстве Эссекс мощностью 50 МВт с возможностью расширения до 90 МВт. В компании надеются ввести дата-центр в эксплуатацию в IV квартале 2026 года, разместив в нём до 45 тыс. NVIDIA GB200 и наняв 250 постоянных сотрудников. В других графствах NScale начнёт строить модульные ЦОД во II половине 2025 года, а впоследствии будет развивать и стационарные дата-центры. 
Источник изображения: Ben Seymour/unsplash.com Vantage Data Centers построит кампус на 10 зданий на месте бывшего автозавода Ford в Уэльсе. Речь идёт об инвестициях £12 млрд ($14,55 млрд) и создании 11,5 тыс. рабочих мест. Ещё в 2020 году Vantage приобрела Next Generation Data, управляющую дата-центрами в Уэльсе и Лондоне. Наконец, Kyndryl создаст 1 тыс. рабочих мест, связанных с ИИ, в новом технологическом центре в Ливерпуле, который построят в следующие три года. Ранее власти отнесли дата-центры к критически важной инфраструктуре (CNI) и пообещали реформировать законы о планировании, чтобы упростить строительство новых объектов. Более того, заново рассматриваются заявки, которые были отклонены. Например, в декабре дали «зелёный свет» отменённому годом ранее проекту в Бакингемшире. 
Источник изображения: Serena Repice Lentini/unsplash.com По словам премьер-министра Кира Стармера (Keir Starmer), индустрии ИИ нужно правительство, которое примет её сторону и не позволит упустить возможности развития. По словам министра, план сделает Великобританию мировым лидером в области ИИ, даст отрасли опору и импульс. Благодаря этому появится больше рабочих мест, больше денег у населения и, наконец, будет реформирована система государственных услуг. Подробнее о плане рассказывается на сайте самого британского правительства. Также Великобритания планирует построить ИИ-суперкомпьютер. Данных о нём пока немного, но Департамент науки, инноваций и технологий (DSIT) сообщил, что его создание — один из элементов плана по двадцатикратному увеличению вычислительных мощностей страны к 2030 году. Примечательно, что в прошлом году власти отложили реализацию HPC-проектов на £1,3 млрд, сославшись на нехватку средств. В том числе было отменено создание первого в стране экзафлопсного суперкомпьютера при Эдинбургском университете.
28.12.2024 [12:42], Сергей Карасёв
Итальянская нефтегазовая компания Eni запустила суперкомпьютер HPC6 с производительностью 478 ПфлопсИтальянский нефтегазовый гигант Eni запустил вычислительный комплекс HPC6. На сегодняшний день это самый мощный суперкомпьютер в Европе и один из самых производительных в мире: в свежем рейтинге TOP500 он занимает пятую позицию. О подготовке HPC6 сообщалось в начале 2024 года. В основу системы положены процессоры AMD EPYC Milan и ускорители AMD Instinct MI250X. Комплекс выполнен на платформе HPE Cray EX4000 с хранилищем HPE Cray ClusterStor E1000 и интерконнектом HPE Slingshot 11. В общей сложности в состав HPC6 входят 3472 узла, каждый из которых несёт на борту 64-ядерный CPU и четыре ускорителя. Таким образом, суммарное количество ускорителей Instinct MI250X составляет 13 888. Суперкомпьютер обладает FP64-быстродействием 477,9 Пфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 606,97 Пфлопс. Максимальная потребляемая мощность системы составляет 10,17 МВА. Комплекс HPC6 смонтирован на площадке Eni Green Data Center в Феррера-Эрбоньоне: это, как утверждается, один из самых энергоэффективных и экологически чистых дата-центров в Европе. Новый суперкомпьютер оснащён системой прямого жидкостного охлаждения, которая способна рассеивать 96 % вырабатываемого тепла. ЦОД, где располагается HPC6, оборудован массивом солнечных батарей мощностью 1 МВт. 
Источник изображения: Eni Как отмечает ресурс Siliconangle, на создание суперкомпьютера потрачено более €100 млн. Применять комплекс планируется, в частности, для оптимизации работы промышленных предприятий, повышения точности геологических и гидродинамических исследований, разработки источников питания нового поколения, оптимизации цепочки поставок биотоплива, создания инновационных материалов и моделирования поведения плазмы при термоядерном синтезе с магнитным удержанием.
28.12.2024 [12:16], Сергей Карасёв
Xiaomi создаст ИИ-кластер с 10 тыс. GPUКитайская компания Xiaomi, по сообщению Jiemian News, намерена создать собственный вычислительный кластер для решения ресурсоёмких задач в области ИИ. Предполагается, что в основу системы лягут около 10 тыс. ускорителей на базе GPU. Отмечается, что Xiaomi активно развивает направление ИИ. Соответствующее подразделение было сформировано ещё в 2016 году, и с тех пор его штат увеличился примерно в шесть раз — до более чем 3000 сотрудников (включая специалистов, задействованных в смежных областях). С начала 2024 года Xiaomi использует для проектов ИИ вычислительную платформу, насчитывающую около 6500 ускорителей на основе GPU. В дальнейшем количество GPU планируется наращивать. Инициативы Xiaomi в области ИИ курирует генеральный директор компании Лэй Цзюнь (Lei Jun). 
Источник изображения: Xiaomi Проекты Xiaomi в сфере ИИ охватывают самые разные направления, включая компьютерное зрение, обработку естественного языка, графы знаний, машинное обучение, большие языковые модели (LLM) и мультимодальные технологии. Эти технологии по мере развития интегрируются в смартфоны, автомобильные бортовые системы, робототехнику, а также в интеллектуальные устройства Интернета вещей (AIoT). Ранее Цзюнь сообщил, что Xiaomi успешно адаптировала LLM для локального использования на мобильных устройствах: утверждается, что модель с 1,3 млрд параметров достигла сопоставимой с облаком производительности в некоторых сценариях. Кроме того, компания создала более мощную LLM с 6 млрд параметров. Говорится также, что Xiaomi сотрудничает с другими участниками рынка в рамках развития проектов ИИ: в число партнёров входят Qualcomm и MediaTek.
28.12.2024 [11:35], Сергей Карасёв
Обнародован рейтинг Тор-100 суперкомпьютеров Китая: систем экзафлопсного класса в нём нетОбщество компьютерных наук Китая обнародовало свежий рейтинг 100 самых производительных суперкомпьютеров страны. Как отмечает ресурс Tom's Hardware, власти КНР, похоже, скрывают свой истинный вычислительный потенциал. Дело в том, что в опубликованном списке Тор-100 не только нет систем экзафлопсного класса, но и не представлено ни одной новой машины за год. В тройку лидеров в 2024 году вошли те же самые гетерогенные системы (CPU + GPU), которые возглавляли рейтинг в 2023-м. На первом месте располагается комплекс, обладающий FP64-быстродействием 487,94 Пфлопс в тесте Linpack (HPL) и пиковой производительностью на уровне 620 Пфлопс. Эта система, введённая в эксплуатацию в 2023 году, насчитывает в общей сложности 15 974 400 ядер CPU. 
Источник изображения: Xinhua На второй позиции списка находится машина, запущенная в 2022 году: она использует 460 000 ядер CPU. Заявленное быстродействие составляет 208,26 Пфлопс, пиковое значение — 390 Пфлопс. Замыкает тройку система с 285 000 тыс. CPU-ядер, введённая в эксплуатацию в 2021-м: у неё показатели производительности достигают 125,04 и 240 Пфлопс. Фактически, как отмечается, единственное различие между списками Тор-100 суперкомпьютеров Китая от 2023 и 2024 годов заключается в их совокупной мощности, но даже этот показатель вырос незначительно — с 1,398 Эфлопс до 1,406 Эфлопс. Для сравнения: самый производительный в мире суперкомпьютер — американская система El Capitan — обладает быстродействием 1,742 Эфлопс. 
Источник: Hyperion Research По косвенным признакам понятно, что у Китая есть несколько машин экзафлопсного класса. По оценкам Hyperion Research, в КНР развёрнуто уже пять подобных систем. Эти сведения официально не подтверждены, но участники рынка говорят, что китайские организации намеренно скрывают информацию о своих самых мощных НРС-системах, чтобы не спровоцировать дополнительные ограничения со стороны США. С 2021 года китайские компании не подают заявки на участие в рейтинге TOP500.
19.12.2024 [23:05], Руслан Авдеев
Терабитный «гиперинтернет» напрямую свяжет европейские квантовые и суперкомпьютерыЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) начло подгтовку к созданию передовых сетей, которые соединят суперкомпьютеры, квантовые компьютеры и дата-центры Евросоюза. Это позволит создать гиперсвязанную объединённую экосистему HPC и квантовых вычислений, сообщает HPC Wire. Сеть с пропускной способностью в несколько Тбит/с охватит не только площадки EuroHPC, но и национальные и региональные суперкомпьютеры и ЦОД, которые в консорциум не входят. Это позволит сформировать инфраструктуру будущего, поддерживающую самые передовые разработки, ИИ и цифровые инновации в континентальном масштабе, учитывающие критические проблемы вроде климатической устойчивости и общественного здоровья. 
Истчоник изображения: EuroHPC JU «Гиперинтернет» объединит европейские системы в единую цифровую экосистему, позволяющую совместить самые разные технологии. Разработанная для HPC и Big Data сеть будет использовать самые передовые архитектуры, обеспечивая высокую скорость и производительность в целом. Объединённая инфраструктура, как ожидается, будет способствовать европейскому лидерству в суперкомпьютерных вычислениях и инновациях, обеспечивая качественную устойчивую связь в зоне обслуживания. Инициатива EuroHPC пока касается исключительно членов Евросоюза, дополнительные критерии соответствия требованиям можно найти на специальной странице. Создание сервисов «гиперсвязи» планируется с середины 2025 по середину 2029 гг. |
|

