Материалы по тегу: h200
|
18.11.2023 [23:57], Сергей Карасёв
ИИ-суперкомпьютер «под ключ»: HPE и NVIDIA представили HPC-платформу на базе гибридных суперчипов Grace HopperКомпании HPE и NVIDIA анонсировали модульную суперкомпьютерную систему для генеративного ИИ и обучения моделей на основе частных массивов данных. Комплекс ориентирован на крупные предприятия, исследовательские организации и государственные структуры. В основу решения положена аппаратная платформа Cray EX2500. В состав входят суперчипы NVIDIA GH200 Grace Hopper, содержащие 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Каждый узел системы использует четыре таких суперчипа. Узлы соединены друг с другом при помощи интерконнекта Slingshot. Говорится, что реализованная архитектура позволяет осуществлять масштабирование до тысяч ускорителей. При этом все мощности могут выделяться для решения одной задачи ИИ, что обеспечивает максимальную эффективность использования ресурсов. По сути, новое решение представляет собой мини-версию ИИ-суперкомпьютера Isambard-AI, который разместится в Бристольском университете (Великобритания). HPE и NVIDIA будут предлагать систему в качестве решения «под ключ» с услугами по установке и настройке. 
Источник изображения: HPE Кроме того, предусмотрен стек ПО для решения различных ИИ-задач: это среда HPE Machine Learning Development Environment, набор инструментов HPE Cray Programming Environment, а также пакет NVIDIA AI Enterprise. В целом, как отмечается, новая система предлагает заказчикам производительность и масштабируемость, которые позволяют решать наиболее сложные ИИ-задачи, включая обучение больших языковых моделей (LLM) и создание рекомендательных систем.
16.11.2023 [16:23], Сергей Карасёв
В облаке Microsoft Azure появились первые в отрасли ИИ-инстансы на базе NVIDIA H100 NVLКорпорация Microsoft объявила о том, что на базе облака Azure стали доступны виртуальные машины NC H100 v5 для HPC-вычислений и нагрузок ИИ. Это, как отмечается, первые в отрасли облачные инстансы на базе ускорителей NVIDIA H100 NVL. Данное решение объединяет два PCIe-ускорителя H100, соединённых посредством NVIDIA NVLink. Объём памяти HBM3 составляет 188 Гбайт, а заявленная FP8-производительность (с разреженностью) достигает почти 4 Пфлопс. Инстансы H100 v5 основаны на платформе AMD EPYC Genoa. В зависимости от реализации, доступны 40 или 80 vCPU и 320 и 640 Гбайт памяти соответственно. В первом случае задействован один ускоритель NVIDIA H100 NVL с 94 Гбайт памяти HBM3, во втором — два ускорителя с суммарно 188 Гбайт памяти HBM3. Пропускная способность сетевого подключения — 40 и 80 Гбит/с. 
Источник изображения: NVIDIA В отличие от виртуальных машин серии ND, рассчитанных на самые крупные модели ИИ, инстансы NC оптимизированы для обучения и инференса моделей меньшего размера, которым не требуются сверхмасштабные массивы данных. Виртуальные машины Azure NC H100 v5 также хорошо подходят для определённых НРС-нагрузок: это гидродинамика, молекулярная динамика, квантовая химия, прогнозирование погоды и моделирование климата, а также финансовая аналитика. В 2024 году Microsoft добавит в облако Azure виртуальные машины с новейшими ускорителями NVIDIA H200: оно смогут обрабатывать более крупные модели ИИ без увеличения задержки. А уже сейчас клиентам Azure стал доступен сервис DGX Cloud.
14.11.2023 [19:26], Сергей Карасёв
TACC получит ИИ-суперкомпьютер Vista с суперчипами NVIDIA GH200 Grace HopperТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) на конференции по высокопроизводительным вычислениям SC23 анонсировал суперкомпьютер Vista, ориентированный на задачи ИИ и машинного обучения. Запуск этого комплекса в эксплуатацию запланирован на начало 2024 года. Отмечается, что Vista станет связующим звеном между нынешним суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Ввод Horizon в строй намечен на 2025 год: ожидается, что этот комплекс будет на порядок быстрее Frontera. Что касается Vista, то эта система знаменует собой переход от традиционной архитектуры х86, которая применяется во Frontera и системах Stampede, в пользу Arm. В частности, будут задействованы суперчипы NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. В составе Vista чипами GH200 будут оборудованы немногим более половины всех вычислительных узлов. Оставшиеся узлы получат процессор NVIDIA Grace CPU Superchip, содержащий два кристалла Grace в одном модуле (144 ядра). 
Источник изображения: TACC Для Vista предусмотрено использование 400G-интерконнекта NVIDIA Quantum-2 InfiniBand. Компания VAST Data предоставит для суперкомпьютера высокопроизводительное флеш-хранилище, подключенное к Stampede3. Вычислительные узлы будут производиться компанией Gigabyte, а интеграцию обеспечит Dell.
14.11.2023 [19:04], Владимир Мироненко
Ускорители NVIDIA GH200 появились во всех облачных регионах VultrVultr, крупнейший в мире частный облачный провайдер, объявил о доступности суперчипа NVIDIA GH200 Grace Hopper во всех своих 32 облачных регионах. Портфолио провайдера также включает предложения на базе HGX H100, A100, L40S, A40 и A16. Vultr видит свою миссию в том, чтобы сделать HPC-решения простыми в использовании и доступными для предприятий и разработчиков по всему миру. Ускорители NVIDIA интегрированы с широким спектром предложений Vultr в области виртуализированных облачных платформ и bare metal, а также с управляемыми кластерами Kubernetes, управляемыми базами данных, блочными и объектными хранилищами и многим другим. Этот комплексный набор продуктов и услуг делает Vultr предпочтительным универсальным облачным поставщиком для предприятий любого размера с критически важными инициативами в области ИИ и машинного обучения, считает компания. 
Источник изображения: Vultr Vultr также объявила о получении статуса NVIDIA Elite в партнёрской сети NVIDIA в области вычислений — NVIDIA Partner Network for Compute Competency. Статус ориентирован на партнёров, которые предоставляют вычислительные платформы с ускорителями NVIDIA для корпоративных заказчиков. Партнёры по Compute должны обеспечивать высокую производительность, масштабируемость и безопасность для каждой платформы.
13.11.2023 [22:05], Сергей Карасёв
200+ Эфлопс: суперчип NVIDIA Grace Hopper ляжет в основу более 40 ИИ-суперкомпьютеровКомпания NVIDIA сообщила о том, что её суперчип GH200 Grace Hopper ляжет в основу более чем 40 ИИ-суперкомпьютеров по всему миру, которые используются в исследовательских центрах, на облачных площадках и пр. Отмечается, что в скором времени станут доступны десятки новых НРС-систем на базе GH200. Этот суперчип позволяет решать самые сложные научные задачи на базе ИИ, которые требуют обработки терабайт данных. В совокупности вычислительные системы на базе GH200, как сообщается, обеспечат ИИ-производительность около 200 Эфлопс. В частности, HPE объявила, что интегрирует GH200 в суперкомпьютеры HPE Cray. Узлы EX254n оснащаются двумя модулями Quad GH200 с четырьмя суперчипами в каждом, обеспечивая возможность масштабирования до десятков тысяч узлов. Аналогичный подход используется и в платформе Eviden BullSequana XH3000, которую Юлихский исследовательский центр (FZJ) в Германии получит в составе Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Источник изображения: NVIDIA Объединённый центр передовых высокопроизводительных вычислений в Японии (JCAHPC) намерен использовать суперчип в своём суперкомпьютере следующего поколения. Техасский центр передовых вычислений при Техасском университете в Остине (США) оборудует суперчипами НРС-систему Vista. Национальный центр суперкомпьютерных приложений при Университете Иллинойса в Урбане-Шампейне будет использовать решения GH200 в составе ИИ-платформы DeltaAI. А Британия получит ИИ-суперкомпьютер Isambard-AI на основе этого суперчипа, который разместится в Бристольском университете. 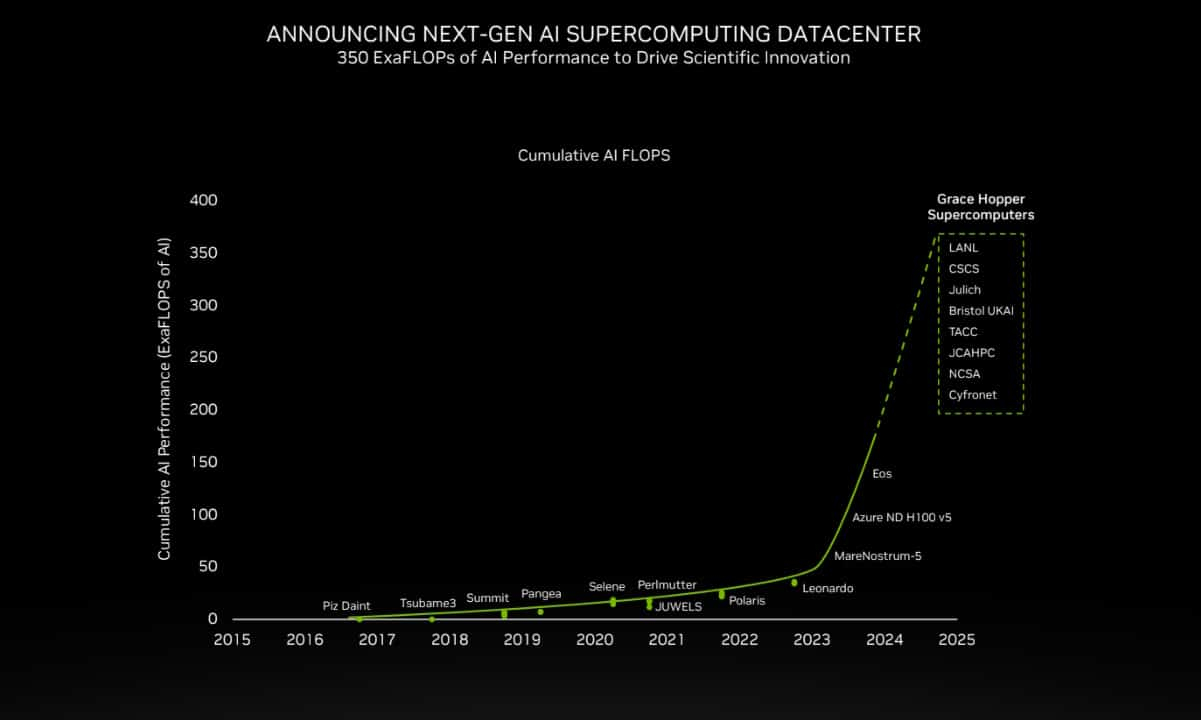
Источник изображения: NVIDIA Все эти системы присоединяются к ранее анонсированным платформам на базе GH200 от Швейцарского национального суперкомпьютерного центра (CSCS) и SoftBank Corp. GH200 уже доступен у некоторых поставщиков облачных услуг, таких как Lambda и Vultr. CoreWeave объявила о планах открыть инстансы GH200 в I квартале 2024 года. Другие производители систем, такие как ASRock Rack, ASUS, Gigabyte и Ingrasys, начнут поставки серверов с этими суперчипами к концу года.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
13.11.2023 [17:00], Сергей Карасёв
Первый в Европе экзафлопсный суперкомпьютер Jupiter получит 24 тыс. гибридных суперчипов NVIDIA Grace HopperКомпания NVIDIA в ходе конференции по высокопроизводительным вычислениям SC23 сообщила о том, что её суперчип GH200 Grace Hopper станет одной из ключевых составляющих НРС-системы Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Узел BullSequana XH3000 (Источник здесь и далее: NVIDIA) Jupiter — проект Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании суперкомпьютера участвуют NVIDIA, ParTec, Eviden и SiPearl. Архитектура системы модульная, что позволяет адаптировать её под разные классы задач. В основу одного из основных блоков Jupiter ляжет платформа Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули Quad GH200. Общее количество суперчипов составит 23752. В качестве интерконнекта будет применяться NVIDIA Quantum-2 InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность должна достичь 1 Эфлопс. При этом общая потребляемая мощность Jupiter составит всего 18,2 МВт.  Применять систему Jupiter планируется для решения наиболее сложных задач. Среди них — моделирование климата и погоды в высоком разрешении (на базе NVIDIA Earth-2), создание новых лекарственных препаратов (NVIDIA BioNeMo и NVIDIA Clara), исследования в области квантовых вычислений (NVIDIA cuQuantum и CUDA Quantum), промышленное проектирование (NVIDIA Modulus и NVIDIA Omniverse). Ввод Jupiter в эксплуатацию запланирован на 2024 год.
02.11.2023 [21:49], Руслан Авдеев
Британия получит 200-Пфлопс ИИ-суперкомпьютер Isambard-AI на гибридных Arm-чипах NVIDIA GH200Правительство Великобритании о выделении £225 млн ($273 млн) на строительство самого мощного в стране суперкомпьютера Isambard производительностью более 200 Пфлопс в FP64-вычислениях и более 21 Эфлопс в ИИ-задачах. Как сообщает The Register, новая машина на базе тысяч гибридных Arm-суперчипов NVIDIA Grace Hopper (GH200) разместится в Бристольском университете и будет построена HPE. Ожидается, что машина будет введена в эксплуатацию в следующем году и поможет в выполнении самых разных задач, от автоматизированной разработки лекарств до анализа климатических изменений, от изучения и внедрения нейросетей в робототехнике до задач, связанных с обеспечением национальной безопасности и обработкой больших данных. Isambard-AI войдёт в десятку самых быстрых суперкомпьютеров мира. Пока что самый быстрый суперкомпьютер Великобритании — это 20-Пфлопс система Archer2, занимающая 30-ю позицию в рейтинге TOP500 и введённая в строй всего пару лет назад. Isambard-AI получит 5448 гибридных чипов NVIDIA GH200 GraceHopper с 96/144 Гбайт HBM-памяти. Используется платформа HPE Cray EX с интерконнектом Slingshot 11 и СЖО. 25-Пбайт хранилище использует СХД Cray ClusterStor E1000. Система будет размещена в ЦОД с автономным охлаждением, а система утилизации избыточного тепла позволит обогревать близлежащие здания. Первыми выгодоприобретателями проекта Isambard-AI станут команды Frontier AI Task Force и AI Safety Institute, намеренные смягчить угрозу со стороны ИИ национальной безопасности Великобритании. 
Изображение: HPE Компанию Isambard-AI составит ранее анонсированный Arm-суперкомпьютер Isambard-3, который также построит HPE. Эту машину введут в эксплуатацию следующей весной, она обеспечит британским учёным ранний доступ к вычислительным мощностям на первом этапе реализации проекта Isambard-AI. Isambard-3 получит 384 суперчипа NVIDIA Grace, а его пиковое быстродействие в FP64-вычислениях составит 2,7 Пфлопс. Всего в различные ИИ-проекты британские власти вложат порядка £900 млн ($1,1 млрд). В частности, вместе с Isambard-AI был объявлен и суперкомпьютер Dawn, который разместится в Кембридже. Хотя ранее NVIDIA описывала Isambard-AI как самый быстрый в стране, создатели Dawn утверждают, что быстрейшим будет именно он. Система будет полагаться на серверы Dell PowerEdge XE9640 с процессорами Sapphire Rapids и ускорителями Max.
19.10.2023 [21:34], Сергей Карасёв
Supermicro выпустила первые в отрасли ИИ-системы NVIDIA MGX на базе гибридных суперчипов GH200 Grace HopperКомпания Supermicro сообщила о начале поставок первых в отрасли серверов на базе суперчипа NVIDIA GH200 Grace Hopper, предназначенных для поддержания ресурсоёмких нагрузок ИИ. Дебютировали стоечные решения в форм-факторах 1U и 2U с воздушным и жидкостным охлаждением. Серверы используют модульную платформу NVIDIA MGX, которая специально разработана для упрощения создания ИИ-систем. Разработчики на этапе проектирования выбирают базовую архитектуру для шасси, после чего добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. В общей сложности выпущены шесть систем (см. характеристики в таблицах ниже). Все они допускают установку накопителей стандарта E1.S с возможностью горячей замены и SSD формата M.2. Есть слоты PCIe 5.0 x16 с поддержкой NVIDIA BlueField-3 и ConnectX-7. Питание обеспечивают два или три блока мощностью 2000 или 2700 Вт. 
Источник изображений: Supermicro В список анонсированных серверов входят:

 Supermicro отмечает, что заказчики могут использовать новые серверы в комплексе с софтом NVIDIA, включая NVIDIA AI Enterprise, для решения разнообразных задач в области генеративного ИИ, компьютерного зрения, речевых приложений и машинного обучения. А набор NVIDIA HPC SDK содержит компиляторы, библиотеки и программные инструменты, необходимые для организации высокопроизводительных вычислений.
10.10.2023 [23:20], Сергей Карасёв
NVIDIA выпустит ускорители GB200 и GX200 в 2024–2025 гг.Компания NVIDIA, по сообщению ресурса VideoCardz, раскрыла планы по выпуску ускорителей нового поколения, предназначенных для применения в ЦОД и на площадках гиперскейлеров. NVIDIA указывает лишь ориентировочные сроки выхода решений, поскольку фактические даты зависят от многих факторов, таких как макроэкономическая обстановка, готовность сопутствующего ПО, доступность производственных мощностей и пр. В конце мая нынешнего года NVIDIA объявила о начале массового производства суперчипов Grace Hopper GH200, предназначенных для построения НРС-систем и платформ генеративного ИИ. Эти изделия содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100 с 96 Гбайт памяти HBM3. Как сообщается, ориентировочно в конце 2024-го или в начале 2025 года на смену Grace Hopper GH200 придет решение Blackwell GB200. Характеристики изделия пока не раскрываются. Но отмечается, что архитектура Blackwell будет применяться как в ускорителях для дата-центров, так и в потребительских продуктах для игровых компьютеров (предположительно, серии GeForce RTX 50). На 2025 год, согласно обнародованному графику, намечен анонс загадочной архитектуры «Х». Речь, в частности, идёт о решении с обозначением GX200. Изделия GB200 и GX200 подойдут для решения задач инференса и обучения моделей. Примечательно, что старшие чипы также получат NVL-версии. Вероятно, вариант GH200 с увеличенным объёмом набортной памяти как раз и будет называться GH200NVL. 
Источник изображения: NVIDIA При этом теперь компания разделяет продукты на Arm- и x86-направления. Первое, судя по всему, так и будет включать гибридные решения GB200 и GX200, а второе, вероятно, вберёт в себя в первую очередь ускорители в форм-факторе PCIe-карт и универсальные ускорители начального уровня серии 40: B40 и X40. Сопутствовать новым чипам будут сетевые решения Quantum (InfiniBand XDR/GDR) и Spectrum-X (Ethernet) классов 800G и 1600G (1.6T). И если в области InfiniBand компания фактически является монополистом, то в Ethernet-сегменте она несколько отстаёт от, например, Broadcom, у которой теперь есть даже выделенные ИИ-решения, Cisco и Marvell. А вот про будущее NVLink компания пока ничего не рассказала. |
|

