Материалы по тегу: cerebras
|
07.09.2023 [21:25], Алексей Степин
Cerebras готова к построению масштабных ИИ-кластеров CS-2 с 163 млн ядерНа прошедшей недавно конференции Hot Chips 2023 компания Cerebras, создатель самого большого в мире ИИ-процессора WSE-2, рассказала о своём видении будущего ИИ-систем. По мнению Cerebras, сфокусировать внимание стоит не столько на наращивании сложности отдельных чипов, сколько на решениях проблем, связанных с масштабированием кластеров. Свою презентацию Cerebras начала с любопытных фактов: за прошедшие пять лет сложность ИИ-моделей возросла в 40 тыс. раз. И этот темп явно опережает темпы развития чипов-ускорителей. Хотя налицо прогресс и в техпроцессах (5x), и в архитектуре (14x), и во внедрении более эффективных для ИИ форматов данных, но наибольший прирост производительности обеспечивает именно возможность эффективного масштабирования. 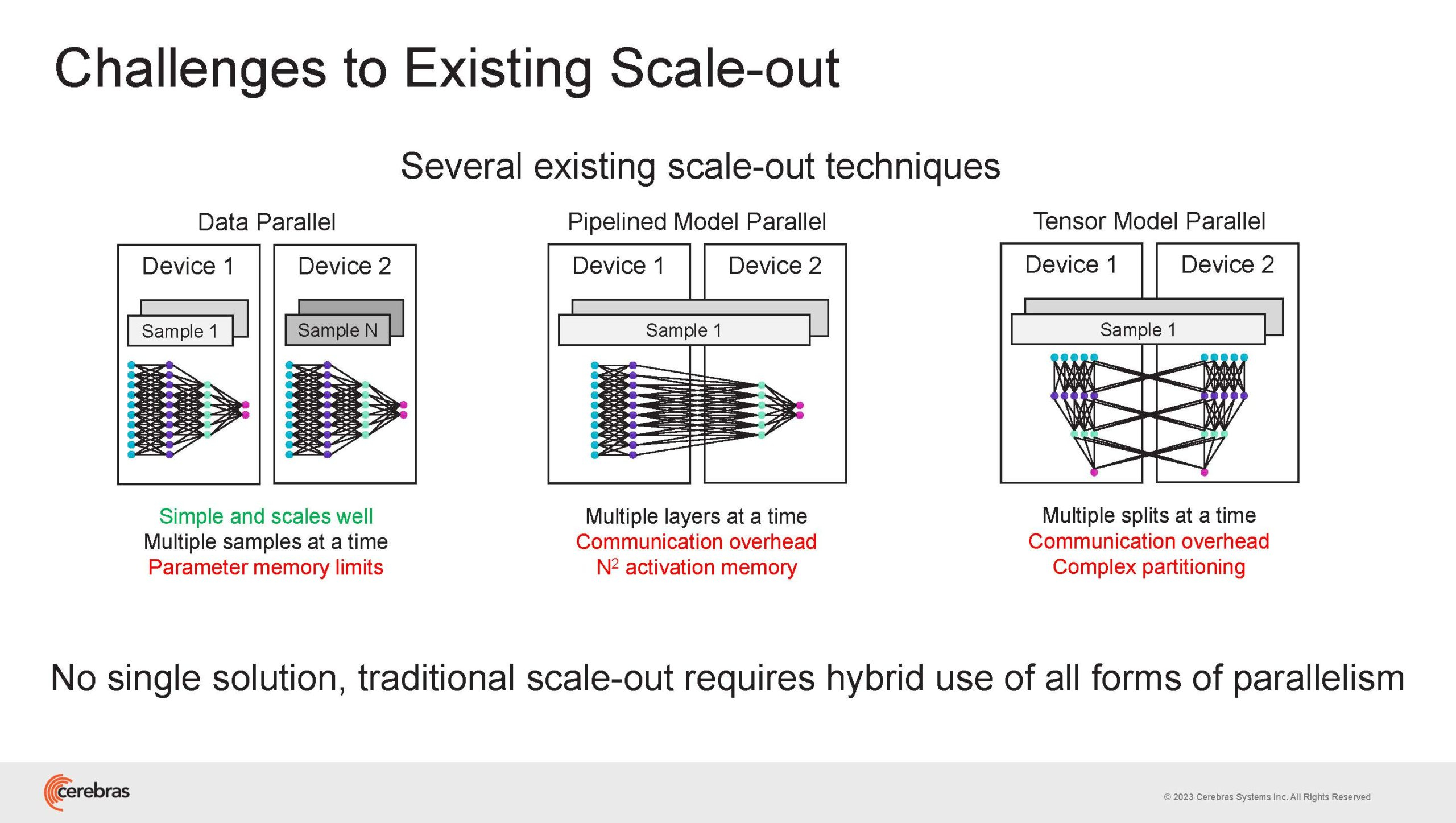
Источник изображений здесь и далее: Cerebras (via ServeTheHome) Однако и этого недостаточно — 600-кратный прирост от кластеризации явно теряется на фоне 40-тыс. усложнения самих нейросетей. А дальнейший рост масштабов ИИ-комплексов в их классическом виде, состоящих из множества «малых» ускорителей, неизбежно приводит к проблемам с организацией памяти, интерконнекта и вычислительных мощностей. 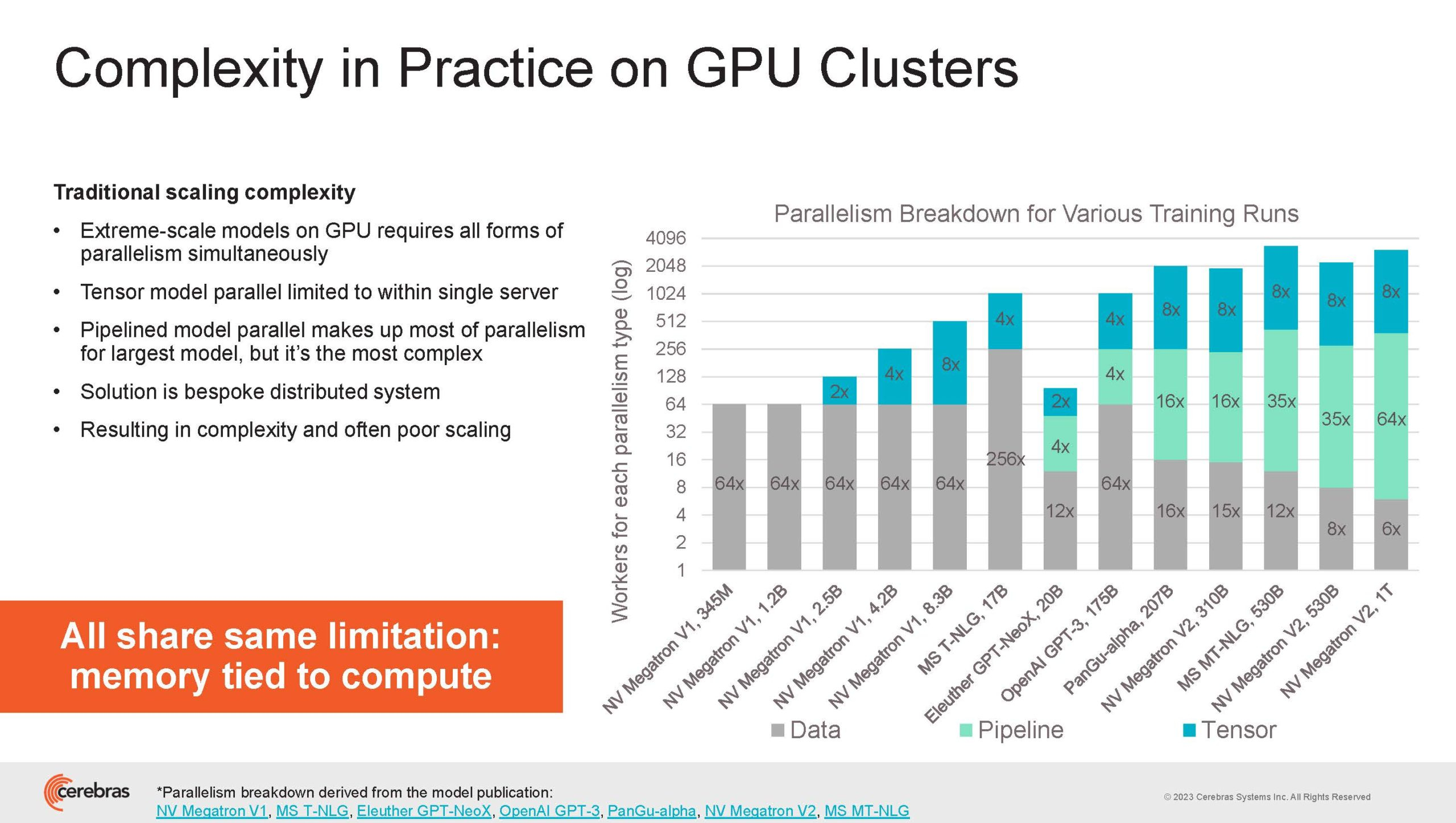 В итоге решение любой задачи в таких системах часто упирается в необходимость тончайшей, но при этом далеко не всегда эффективной оптимизации разделения ресурсов. При этом разные методы масштабирования имеют свои проблемы — узким местом могут оказаться и память, и интерконнект, и конкретный подход к организации кластера. 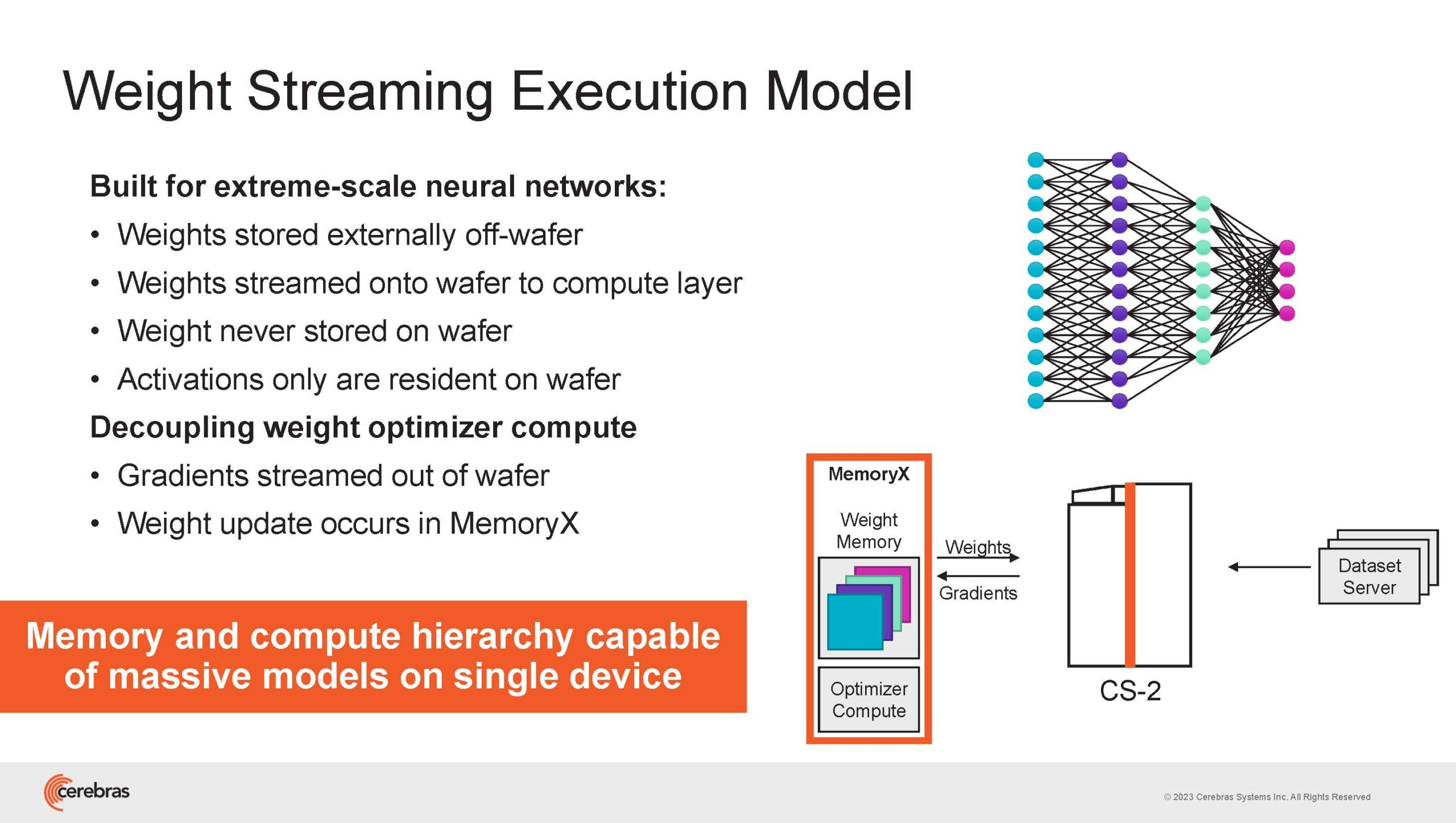 Cerebras же предлагает совершенно иной подход. Выход компания видит в создании огромных чипов-кластеров, таких, как 7-нм Cerebras WSE-2. Этот чип на сегодня можно назвать самым большим в индустрии: его площадь составляет более 45 тыс. мм2, при этом он содержит 2,6 трлн транзисторов и имеет 850 тыс. ядер, дополненных 40 Гбайт сверхбыстрой памяти. Что интереснее, кластер на базе CS-2 представляется с точки зрения исполняемой модели, как единая система. 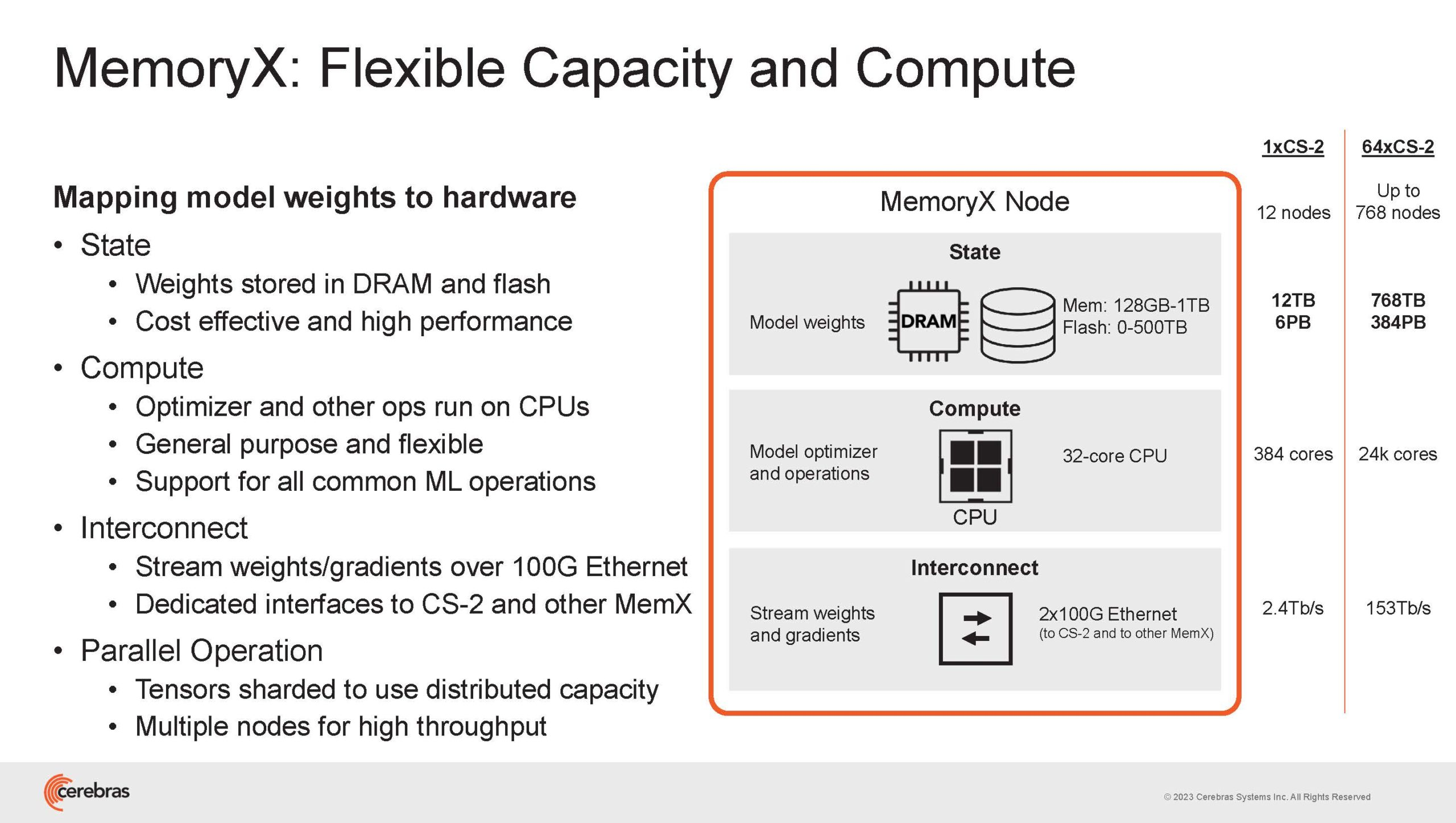 Сама по себе сложность WSE-2 и платформы CS-2 на его основе такова, что позволяет запускать модели практически любых размеров, благо весовые коэффициенты чип в себе не хранит, а подгружает извне с помощью подсистемы MemoryX. При этом сама по себе платформа CS-2 допускает и дальнейшее масштабирование: с помощью интерконнекта SwarmX в единый кластер можно объединить до 192 таких машин, что в теории позволит поднять производительность до 8+ Эфлопс. 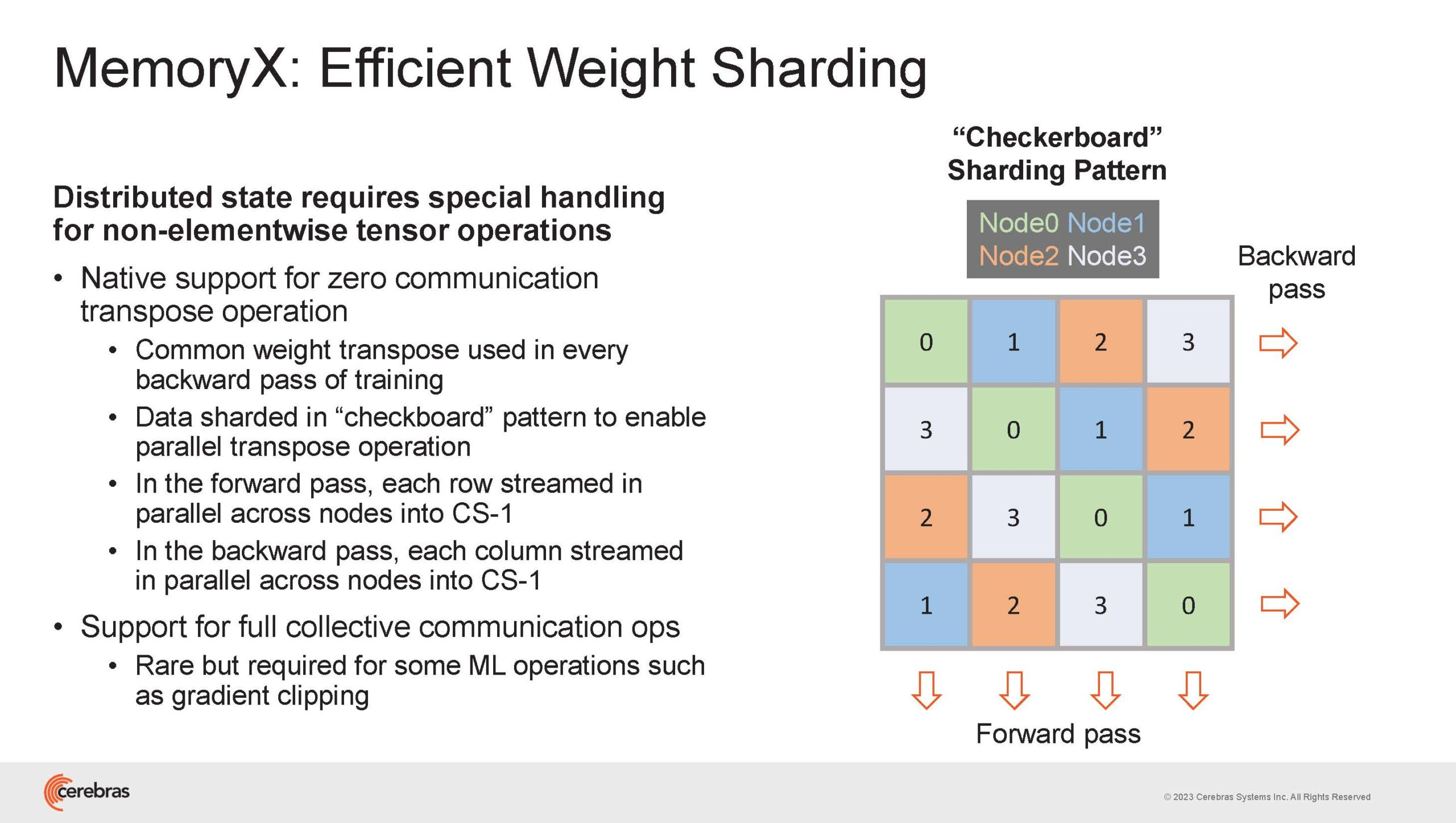 Подсистема MemoryX включает в себя 12 узлов, за оптимизацию модели в ней отвечают 32-ядерные процессоры, а веса хранятся как в DRAM, так и во флеш-памяти — объёмы этих подсистем составляют 12 Тбайт и 6 Пбайт соответственно. Каждый узел имеет по 2 порта 100GbE — один для закачки данных в CS-2, второй для общения с другими MemoryX в кластере. Оптимизация данных производится на процессорах MemoryX, «мегачипы» CS-2 для этого не используются. 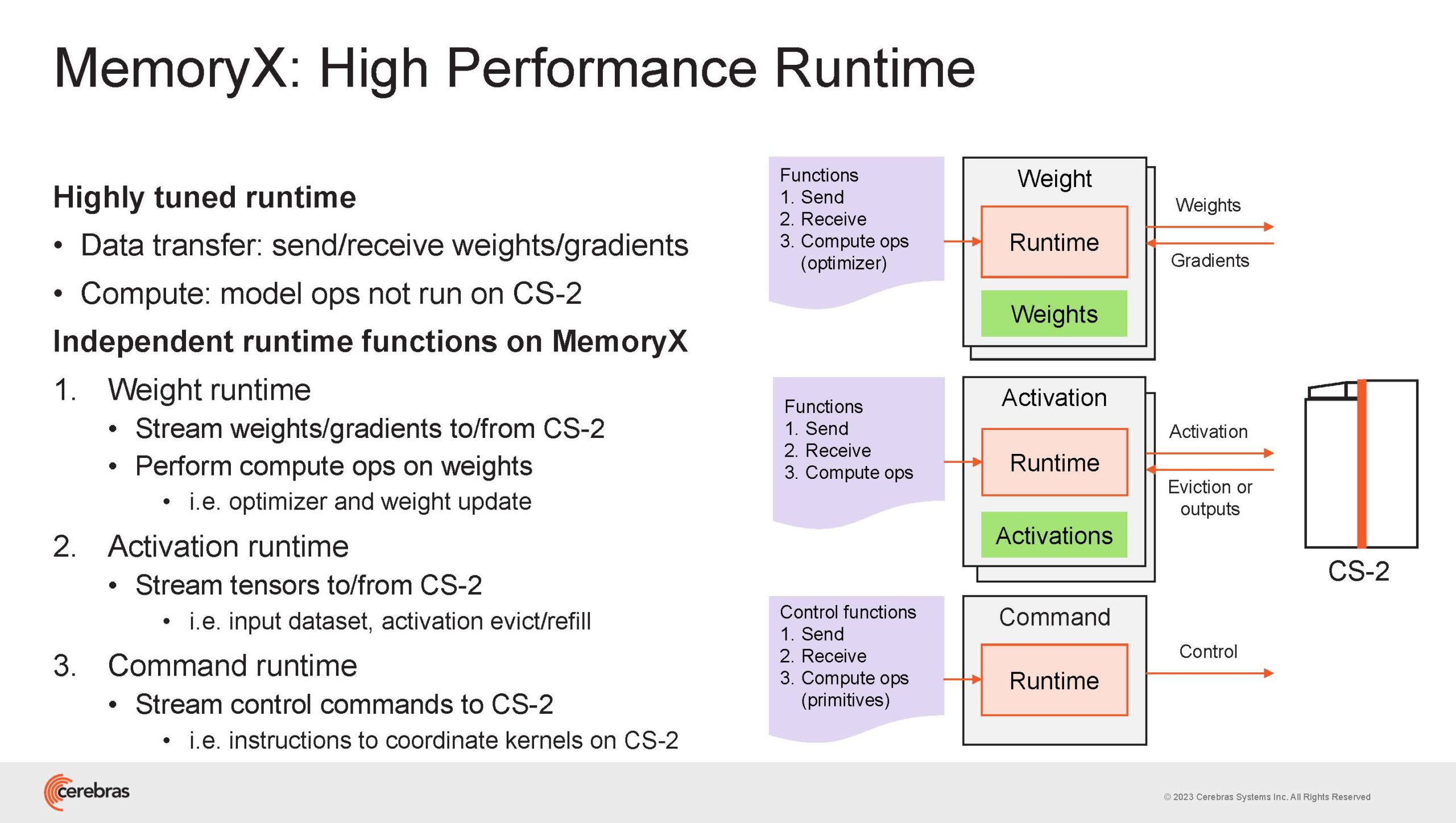 Подсистема интерконнекта SwarmX базируется на 100GbE с поддержкой RoCE DRMA, но имеет ряд особенностей: на каждые четыре системы CS-2 приходтся 12 узлов SwarmX c производительностью интерконнекта 7,2 Тбит/с. Трансляция и редуцирование данных осуществляются с коэффициентом 1:4, причём и здесь используются силы собственных 32-ядерных процессоров, а не ресурсы CS-2. Топологически SwarmX имеет двухслойную конфигурацию spine-leaf и обеспечивает соединение типа all-to-all, при этом каждая CS-2 имеет свой канал с пропускной способностью 1,2 Тбит/с. 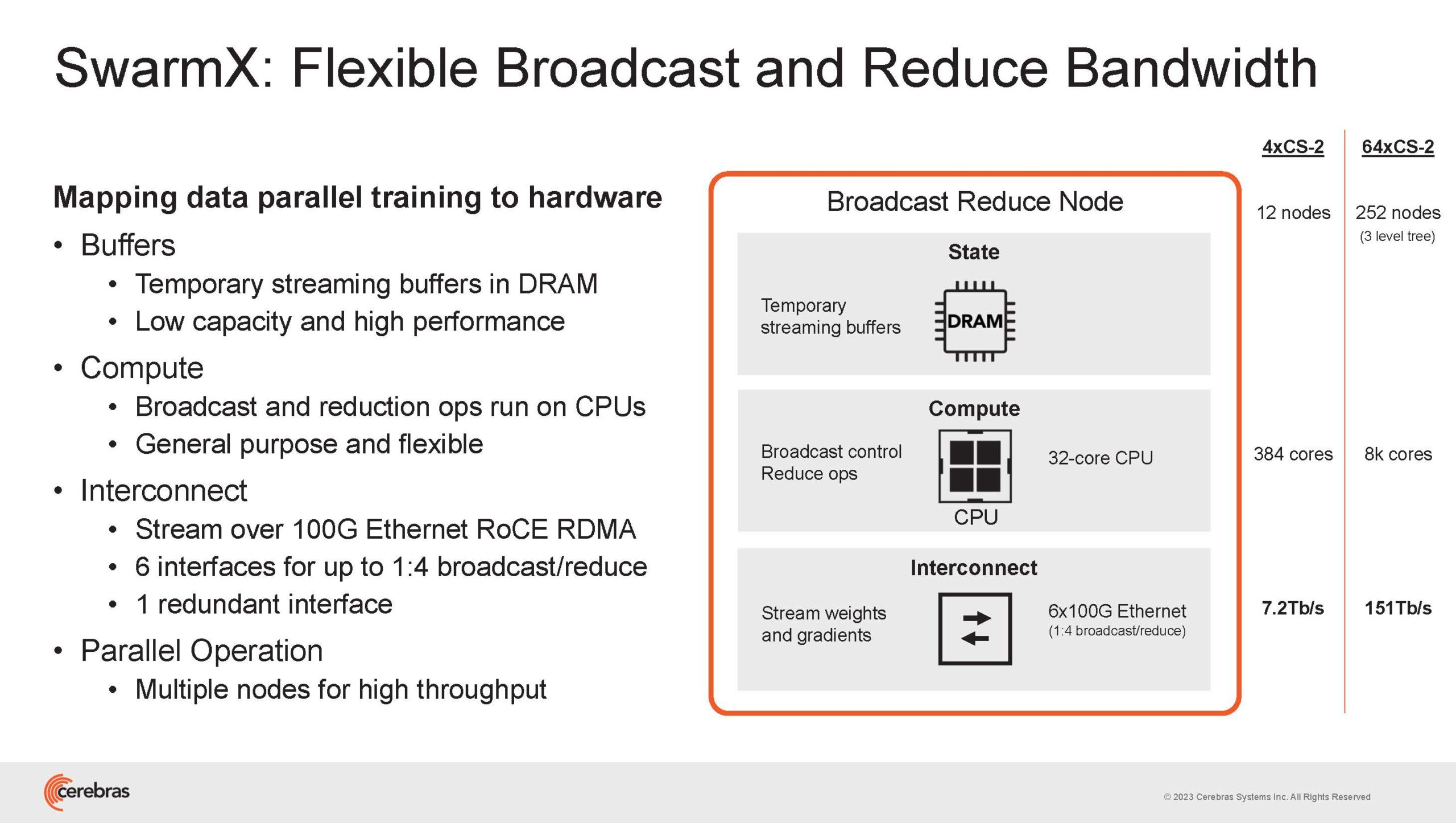 Сочетание MemoryX и SwarmX позволяет делать кластеры на базе CS-2 крайне гибкими: размер модели ограничивается лишь ёмкостью узлов MemoryX, а степень параллелизма — их количеством. При этом интерконнект обладает достаточной степенью избыточности, чтобы говорить об отсутствии единых точек отказа. 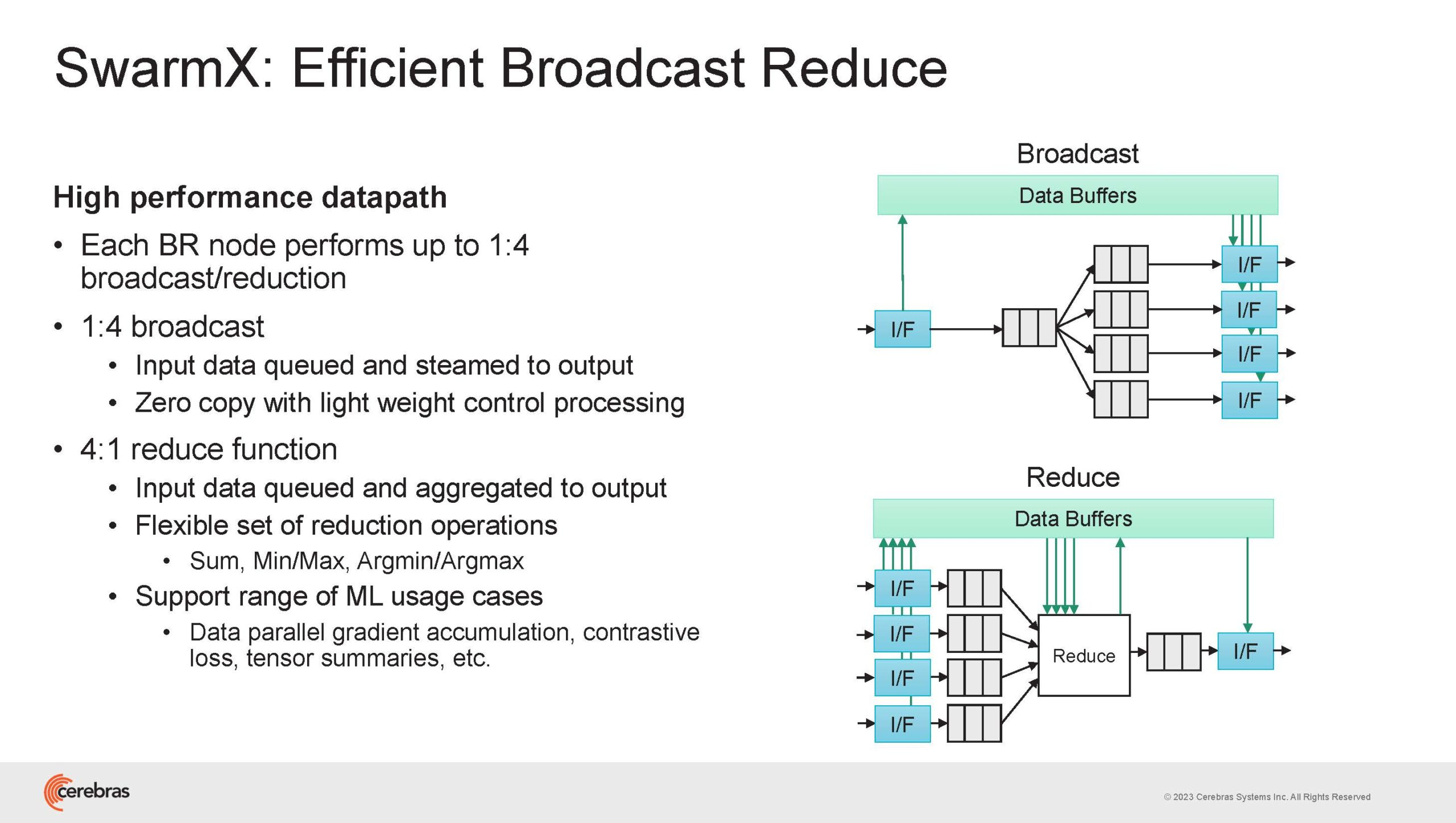 Таким образом, Cerebras имеет на руках всё необходимое для запуска самых сложных моделей искусственного интеллекта. Уже сравнительно немолодой кластер Andromeda, включающий всего 16 платформ CS-2, способен «натаскивать» за считанные недели нейросети размерностью до 13 млрд параметров. При этом масштабирование по размеру модели не требует серьёзного вмешательства в программный код, в отличие от классического подхода для ускорителей NVIDIA. Фактически для сетей и с 1, и со 100 млрд параметров используется один и тот же код. 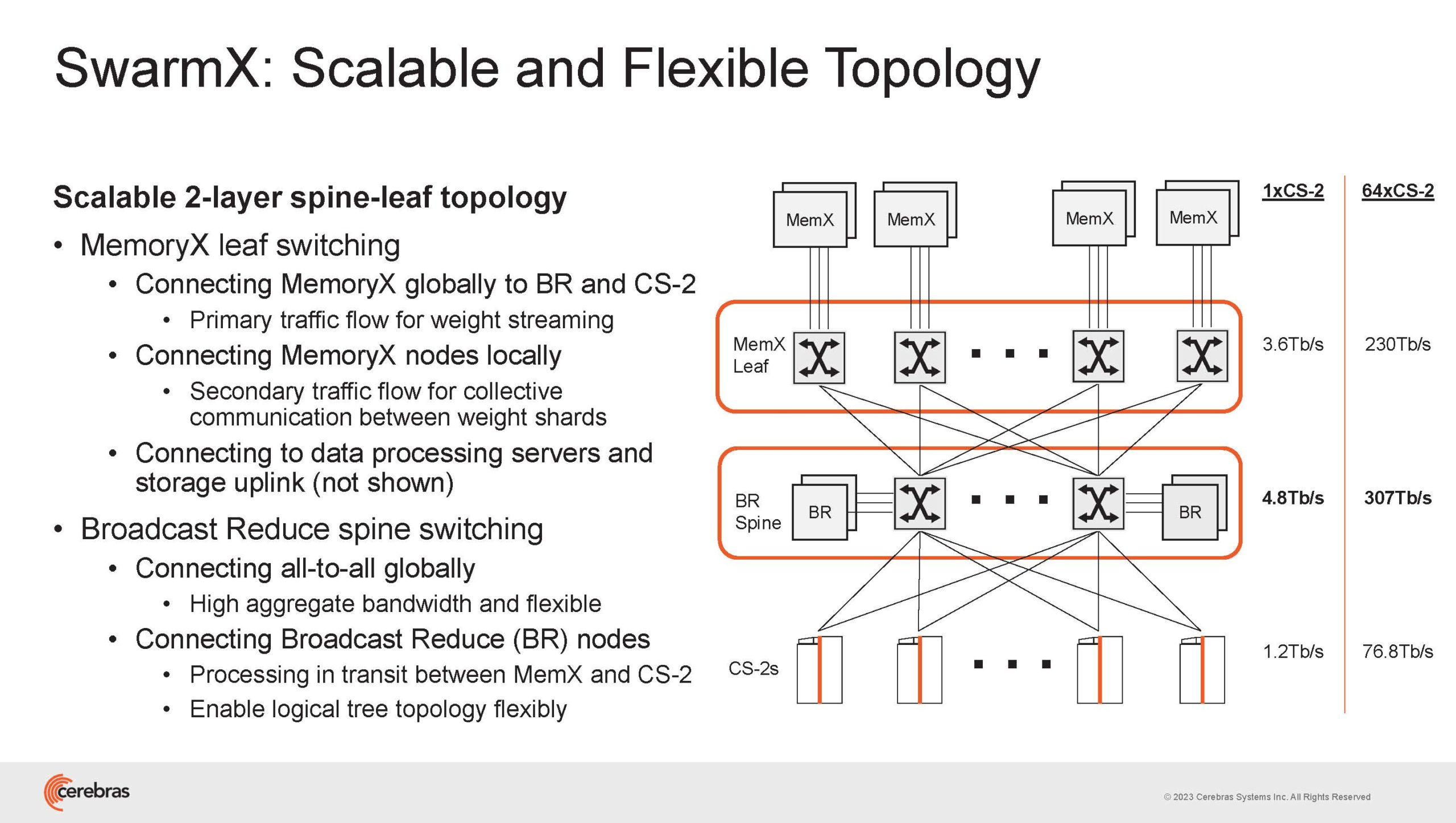 Более мощный 64-узловой комплекс Condor Galaxy 1 (CG-1), располагающий 54 млн ИИ-ядер и развивающий до 4 Эфлопс уже доказал, что подход к масштабированию, продвигаемый Cerebras, оправдывает себя. Он успешно обучил первую публичную модель с 3 млрд параметров, причём по возможностям она приближается к моделям с 7 млрд параметров. И это не предел: напомним, в текущем воплощении сочетание подсистем MemoryX и интерконнекта SwarmX допускает объединение в единый кластер до 192 узлов CS-2. 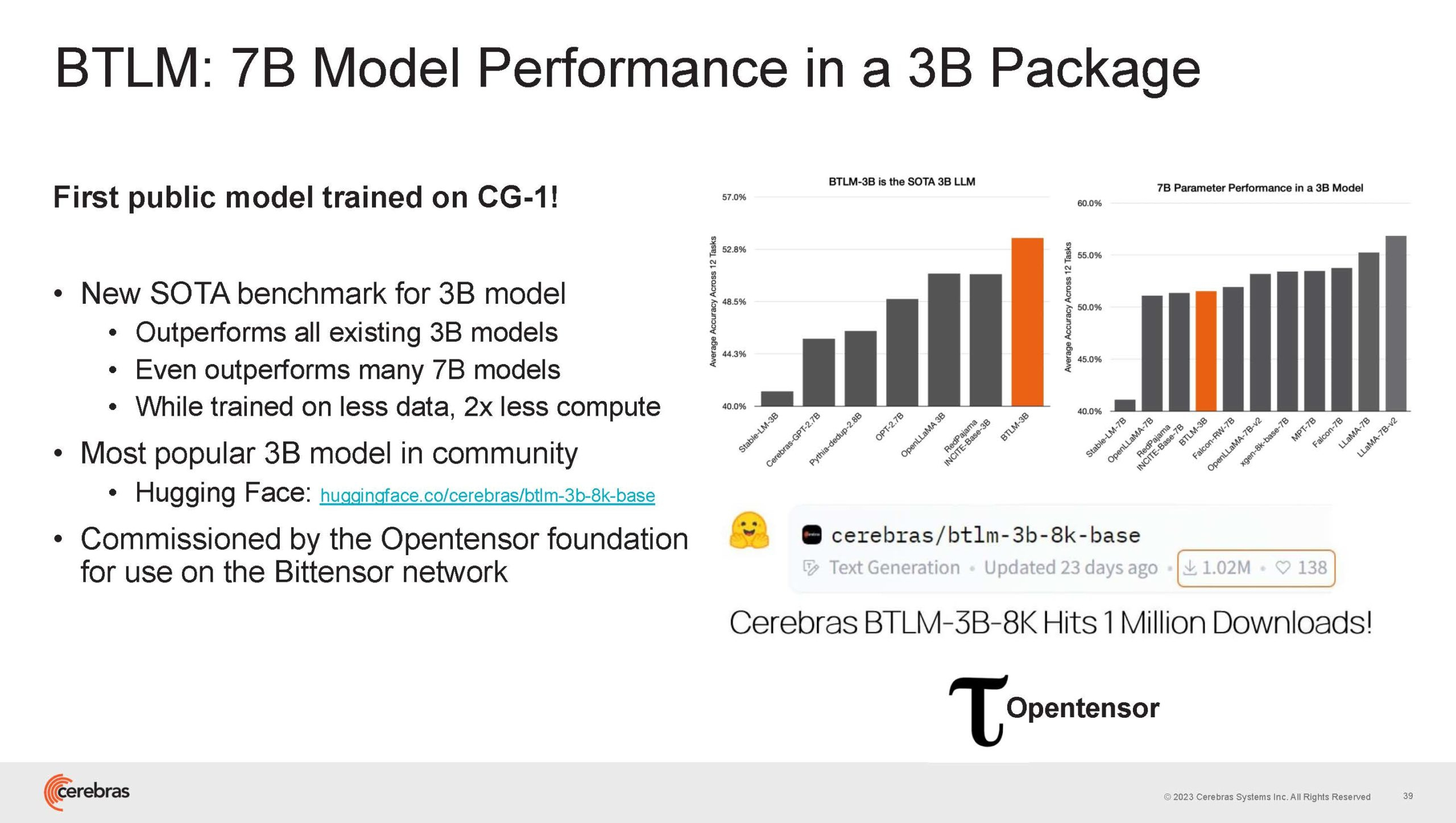 Компания считает, что она полностью готова к наплыву ещё более сложных нейросетей, а предлагаемая ей архитектура в явном виде лишена многих узких мест, свойственных традиционным GPU-архитектурам. Насколько успешным окажется такой подход в более отдалённой перспективе, покажет время.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 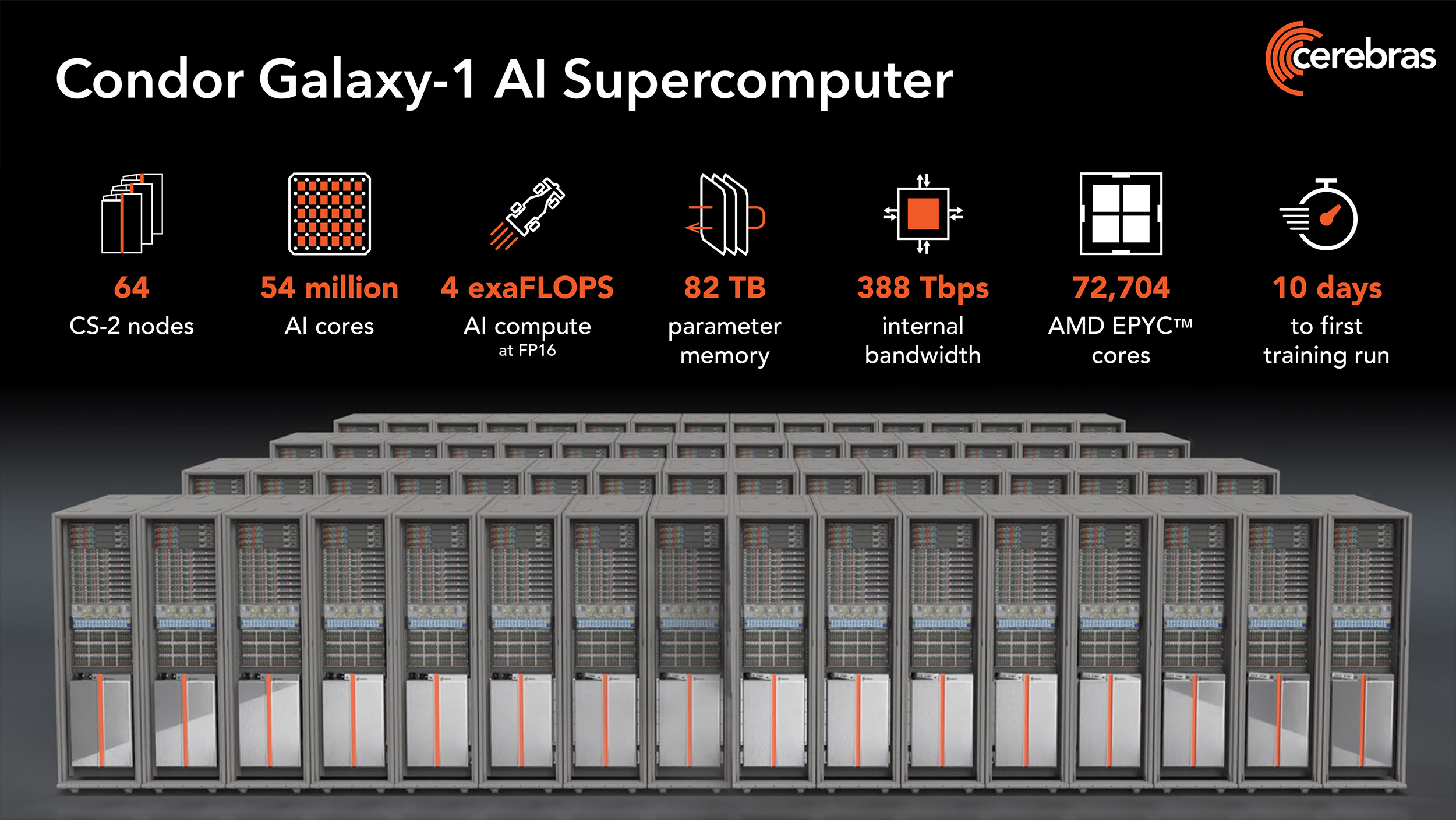
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
29.03.2023 [22:27], Владимир Мироненко
Cerebras выпустила семь GPT-моделей для генеративного ИИ под открытой лицензией, обучив их на собственных чипахАмериканский производитель ИИ-комплексов Cerebras Systems объявил о выходе 7 больших языковых моделей (LLM) на базе технологии Generative Pre-trained Transformer (GPT) для генеративного ИИ. Это первые публичные LLM, которые прошли обучение с помощью систем CS-2 в суперкластере Cerebras Andromeda на базе фирменных ИИ-чипов Cerebras WSE-2. Другими словами, это одни из первых больших языковых моделей, которые были обучены без использования систем на основе ускорителей, в частности, NVIDIA. Серия из семи открытых моделей GPT со 111, 256, 590 млн, а также 1,3, 2,7, 6,7 и 13 млрпд параметров соответственно доступны на GitHub и Hugging Face. Обучение таких моделей обычно занимает много месяцев, но Cerebras утверждает, что ей удалось справиться всего за несколько недель благодаря Andromeda. Более того, Cerebas удалось снизить стоимость обучения, а также упростить масштабирование без модификации кода и самой модели, что часто требуется при обучении с использованием кластеров традиционных ускорителей. При этом энергоэффективность всего процесса Cerebras смогла повысить. 
Источник изображения: Cerebras Systems Cerebras отметила, что не только предлагает модели, но и инструкции по их обучению под лицензией Apache 2.0. «Мы считаем, что для того, чтобы LLM были открытой и доступной технологией, важно иметь доступ к современным моделям, которые являются открытыми, воспроизводимыми и бесплатными как для исследовательских, так и для коммерческих приложений», — заявила Cerebras. 
Источник изображения: Cerebras Systems Компания заявила, что это первый случай, когда весь набор моделей GPT, обученных с использованием самых современных методов повышения эффективности, стал общедоступным. Поскольку большие языковые модели Cerebras имеют открытый исходный код, их можно использовать как в исследовательских, так и в коммерческих целях. А предварительно обученную модель можно с минимум затрат дообучить под конкретную задачу на пользовательских данных. 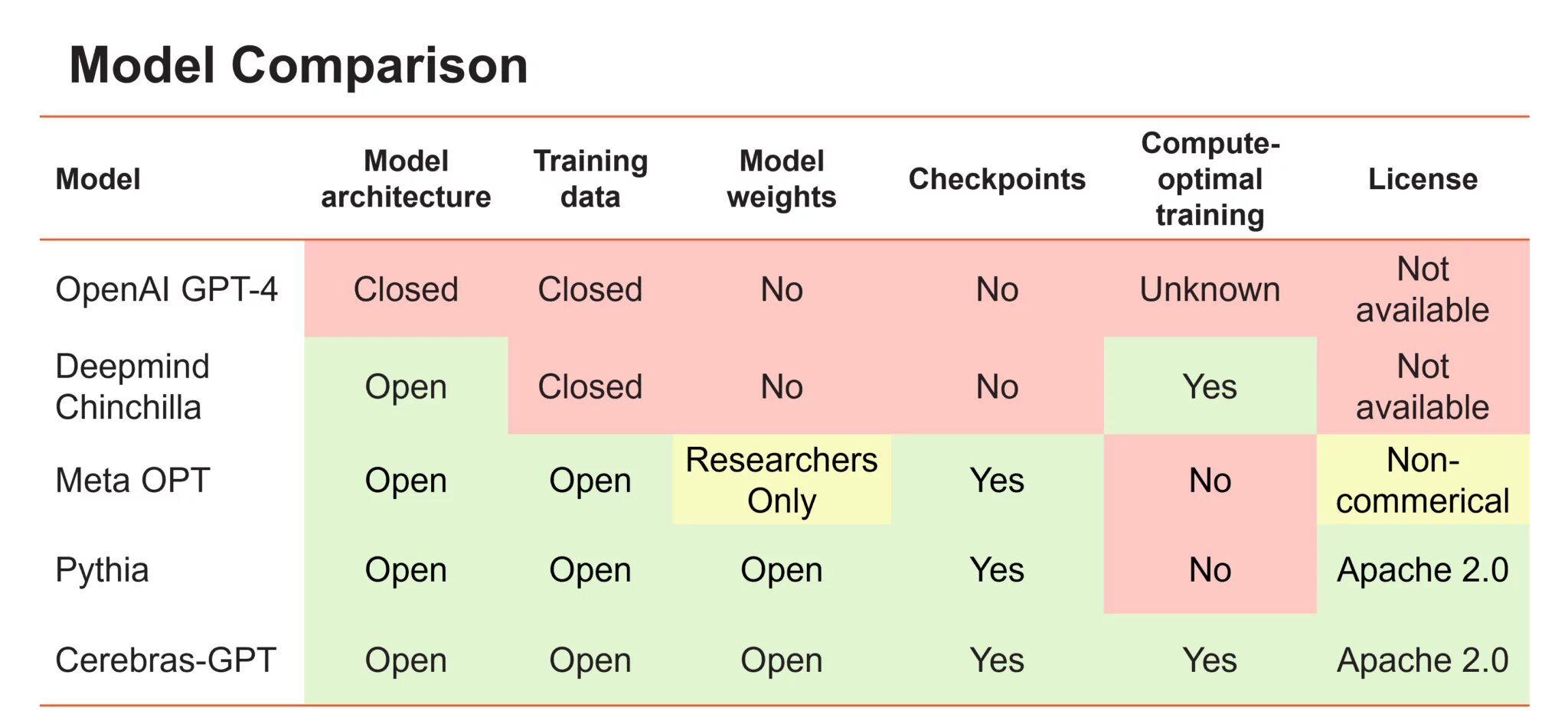
Источник изображения: Cerebras Systems Cerebras отметила, что быстрый рост генеративного ИИ при лидерстве ChatGPT от OpenAI спровоцировал обострение состязания среди производителей ИИ-оборудования для ИИ, взявшихся за создание более мощных и специализированных чипов. Хотя многие из них обещали создать альтернативу ускорителям NVIDIA, пока никому из них не удалось продемонстрировать способность обучать крупномасштабные модели и желание раскрывать наработки под открытыми лицензиями. По словам Cerebras, в связи с конкуренцией доступ к ИИ становится все более закрытым. Так, GPT4 была выпущена без детальной информации об архитектуре модели, параметрах, данных, оборудовании и т.д. Компании создают большие модели с использованием закрытых наборов данных и предлагают выходные данные моделей только через доступ к API.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 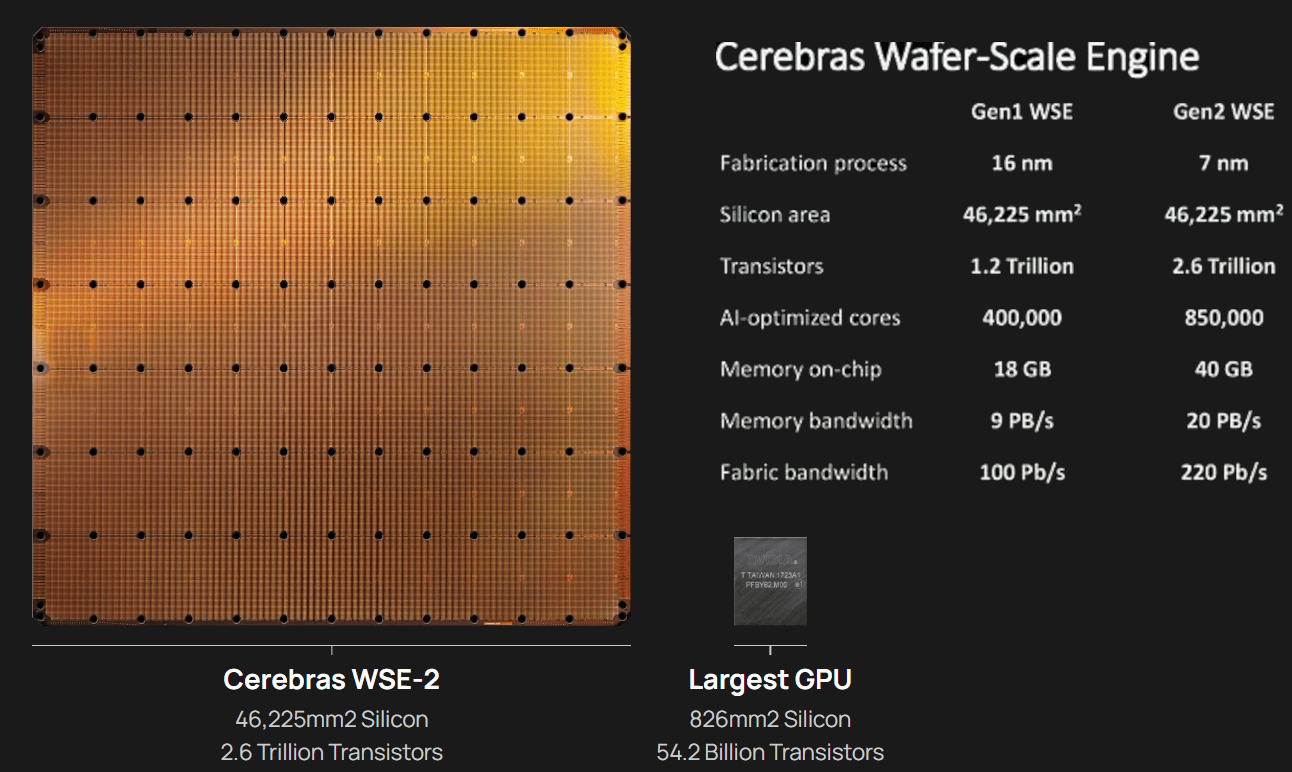 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 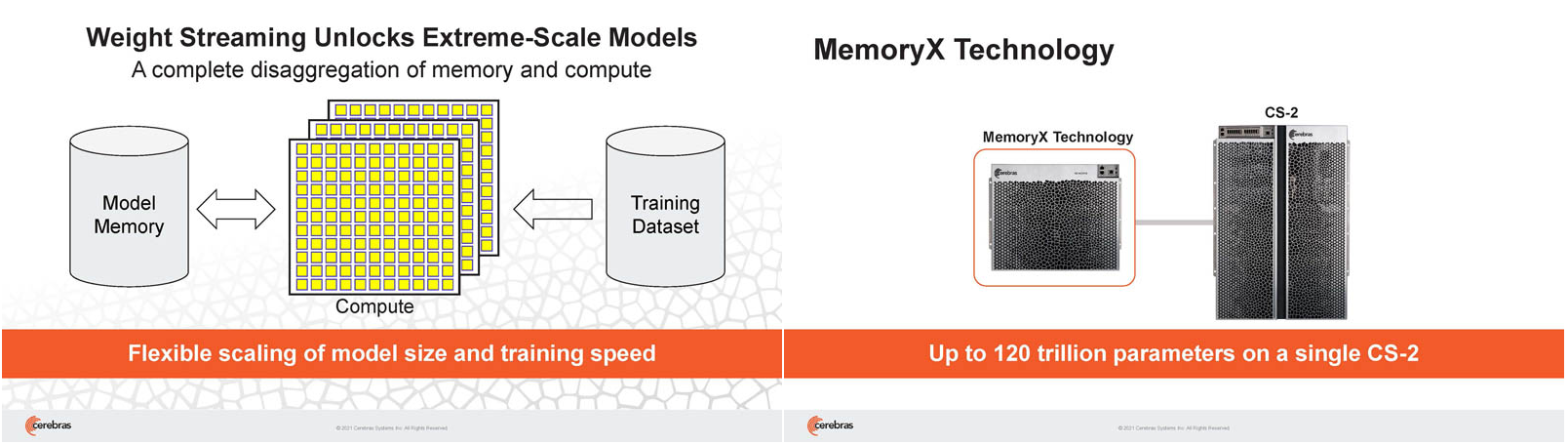 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 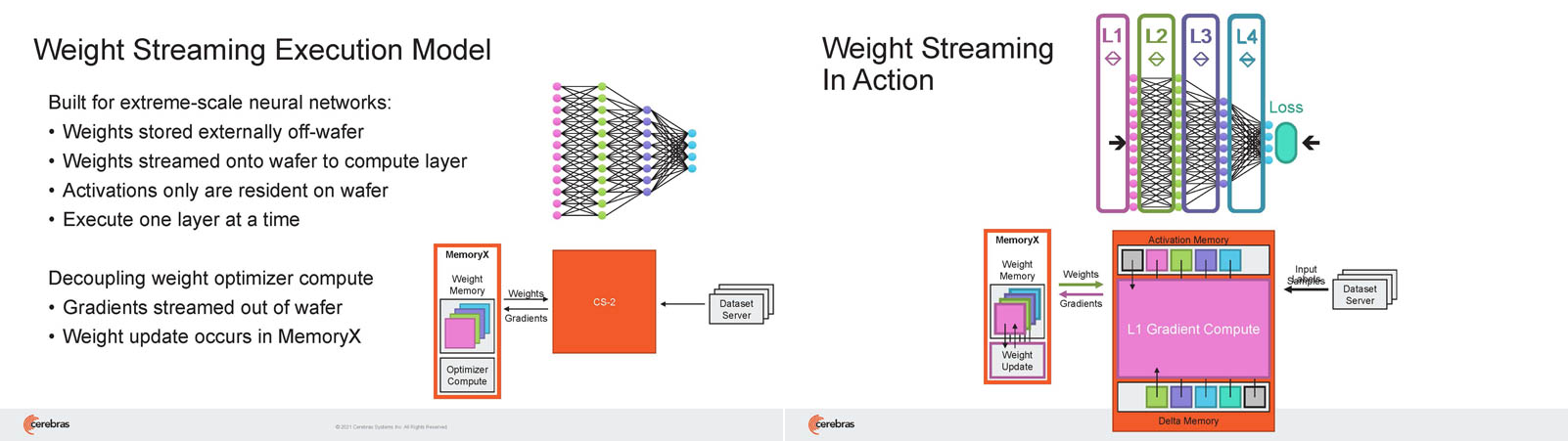 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 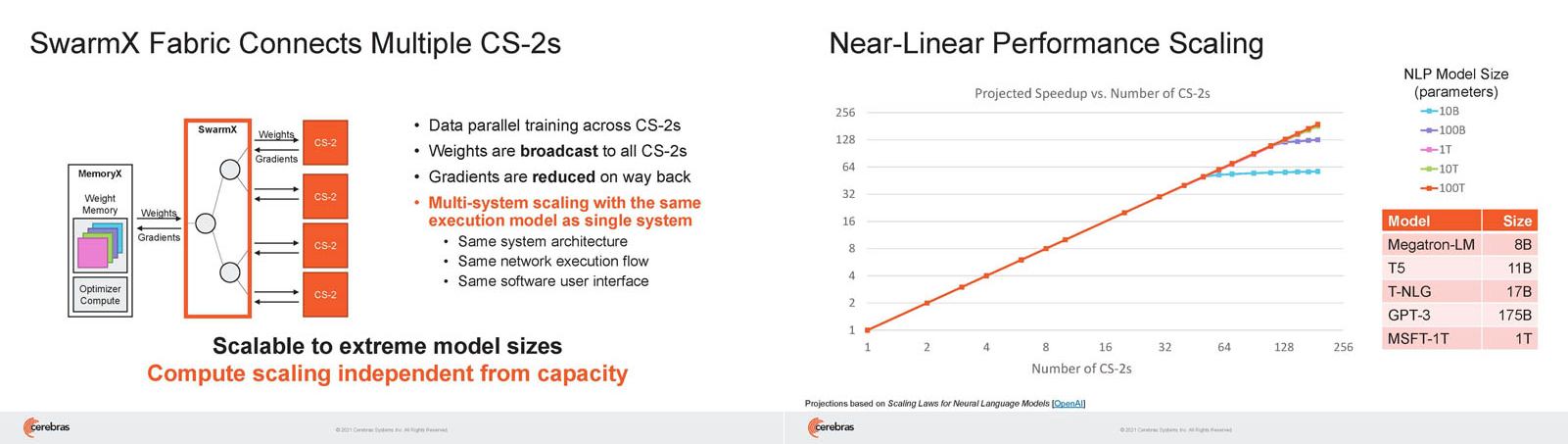 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
09.06.2020 [19:49], Юрий Поздеев
Суперкомпьютер Neocortex: 800 тыс. ядер Cerebras для ИИПиттсбургский суперкомпьютерный центр (PSC) получит $5 млн от Национального научного фонда на создание суперкомпьютера нового типа Neocortex, который объединяет ИИ-серверы Cerebras CS-1 и HPE SuperDome Flex в единую систему с общей памятью. Планируется, что решение будет введено в эксплуатацию до конца 2020 года.  Каждый сервер Cerebras CS-1 имеет процессор Cerebras Wafer Scale Engine (WSE), который содержит 400 000 ядер, оптимизированных для работы с ИИ (46 225 мм2, 1,2 трлн транзисторов). В паре с ними работает HPE SuperDome Flex, который используется для предварительной обработки информации и постобработки после Cerebras. SuperDome Flex представлен в максимальной комплектации, то есть с 32 процессорами Intel Xeon, 24 Тбайт оперативной памяти, 205 Тбайт флеш-памяти и 24 интерфейсными картами.  Каждый сервер Cerebras CS-1 подключается к SuperDome Flex через 12 каналов со скоростью 100 Гбит/с каждый. Процессор WSE способен обрабатывать 9 Пбайт данных в секунду, что, по подсчетам Nystrom, эквивалентно примерно миллиону фильмов в HD-качестве. Характеристики решения действительно впечатляют! 
Neocortex назван в честь области мозга, отвечающей за функции высокого порядка, включая когнитивные способности, сновидения и формирование речи Архитектура решения строилась таким образом, чтобы не пришлось разбивать вычислительные блоки на множество узлов — это позволило снизить задержки в обработке информации и ускорить обучение моделей ИИ. Cerebras CS-1 разрабатывался специально для ИИ, поэтому он имеет преимущества перед серверами с графическими ускорителями, которые хорошо справляются с матричными операциями, но имеют многие конструктивные ограничения.  По заявлениям Neocortex, сервер CS-1 будет на несколько порядков мощнее системы PSC Bridges-AI. Один сервер Neocortex CS-1 будет эквивалентен примерно 800-1500 серверов с традиционной архитектурой с использованием графических ускорителей. Задачи, в которых Neocortex покажет себя максимально эффективно относятся к классу нейронных сетей DCIGN (deep convolutional inverse graphics networks) и RNN (recurrent neural networks). Если говорить простыми словами, то это более точное прогнозирование погоды, анализ геномов, поиск новых материалов и разработка новых лекарств. 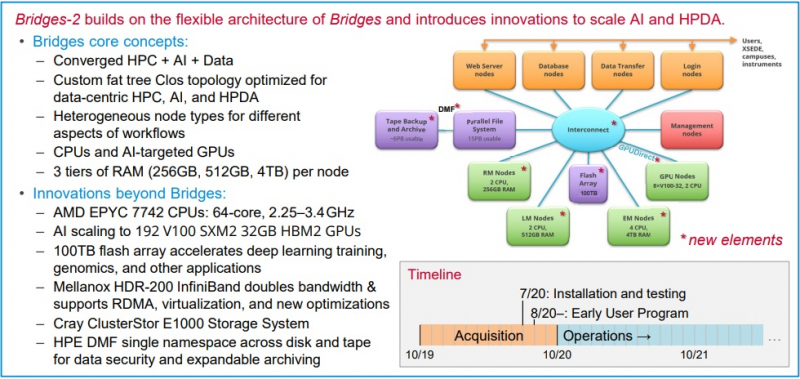 PSC, помимо Neocortex, запускает еще и новое поколение системы Bridges-2, которое будет развернуто осенью 2020 года. Таким образом, до конца этого года будут введены в эксплуатацию два мощных суперкомпьютера для ИИ. Neocortex и Bridges-2 будут поддерживать самые популярные фреймворки машинного обучения, что позволит создать гибкую и мощную экосистему для ИИ, анализа данных, моделирования и симуляции. До 90% машинного времени Neocortex будет выделяться через XSEDE (Extreme Science and Engineering Discovery Environment), финансируемую NSF организацию, которая координирует совместное использование передовых цифровых услуг, включая суперкомпьютеры и ресурсы для визуализации и анализа данных, с исследователями на национальном уровне. |
|

