Материалы по тегу: asic
|
29.05.2023 [07:35], Сергей Карасёв
Ethernet для ИИ: NVIDIA представила 400G/800G-платформу Spectrum-XКомпания NVIDIA в ходе выставки Computex 2023 анонсировала передовую Ethernet-платформу Spectrum-X для облачных провайдеров: система поможет в масштабировании сервисов генеративного ИИ. Решение уже доступно гиперскейлерам и операторам крупных дата-центров. Платформа предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с) и 400GbE DPU NVIDIA BlueField-3. Отмечается, что BlueField-3 сочетает в себе большие вычислительные ресурсы, высокоскоростное сетевое соединение и обширные возможности программирования, что даёт возможность создавать программно-определяемые решения с аппаратным ускорением для самых требовательных задач. В результате, платформа Spectrum-X позволяет добиться 1,7-кратного увеличения производительности ИИ-нагрузок и повышения энергоэффективности по сравнению с другими решениями. 
Источник изображений: NVIDIA Для Spectrum-X заявлена возможность использования до 256 портов 200GbE (или 64 × 800GbE, или 128 × 400GbE) на базе одного коммутатора или до 16 000 портов в случае архитектуры Spine-Leaf. В набор сопутствующего ПО входят SDK-комплекты для SDKCumulus Linux, SONiC и NetQ, а также фреймворк NVIDIA DOCA. С применением решений NVIDIA Mellanox LinkX возможно формирование сквозной 400GbE-фабрики, оптимизированной для облачных ИИ-сервисов.  Платформа Spectrum-X, в частности, будет применена в составе суперкомпьютера Israel-1, который NVIDIA строит в своём израильском дата-центре. Комплекс объединит серверы Dell PowerEdge XE9680 на основе NVIDIA HGX H100 (восемь GPU), изделия BlueField-3 DPU и коммутаторы Spectrum-4.
19.05.2023 [10:20], Сергей Карасёв
Meta✴ представила ИИ-процессор MTIA для дата-центров — 128 ядер RISC-V и потребление всего 25 ВтMeta✴ анонсировала свой первый кастомизированный процессор, разработанный специально для ИИ-нагрузок. Изделие получило название MTIA v1, или Meta✴ Training and Inference Accelerator: оно оптимизировано для обработки рекомендательных моделей глубокого обучения. Проект MTIA является частью инициативы Meta✴ по модернизации архитектуры дата-центров в свете стремительного развития ИИ-платформ. Утверждается, что чип MTIA v1 был создан ещё в 2020 году. Это интегральная схема специального назначения (ASIC), состоящая из набора блоков, функционирующих в параллельном режиме. 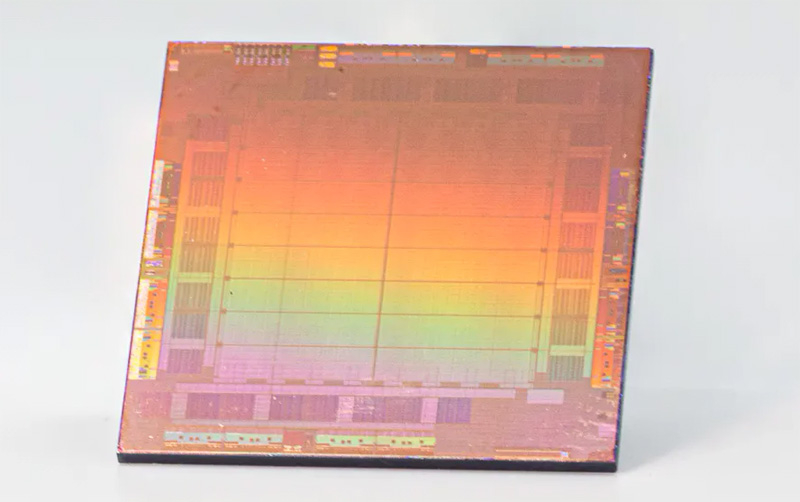
Источник изображений: Meta✴ Известно, что при производстве MTIA v1 используется 7-нм технология. Конструкция включает 128 Мбайт памяти SRAM. Чип может использовать до 64/128 Гбайт памяти LPDDR5. Задействован фреймворк машинного обучения Meta✴ PyTorch с открытым исходным кодом, который может применяться для решения различных задач в области компьютерного зрения, обработки естественного языка и пр. 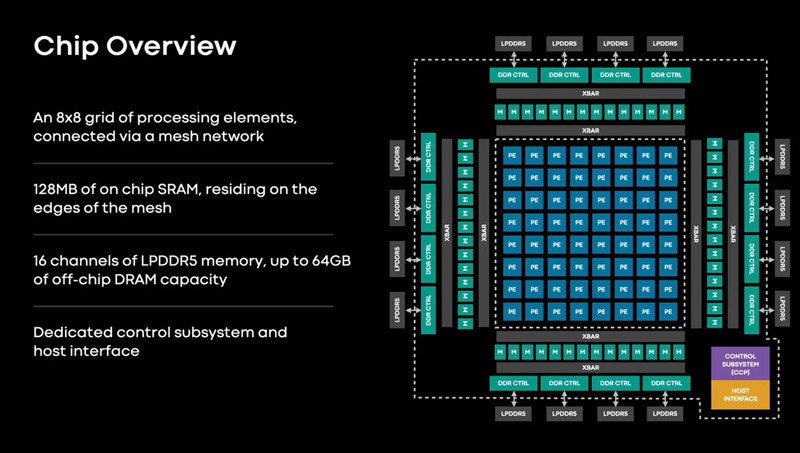 Процессор MTIA v1 имеет размеры 19,34 × 19,1 мм. Он содержит 64 вычислительных элемента в виде матрицы 8 × 8, каждый из которых объединяет два ядра с архитектурой RISC-V. Тактовая частота достигает 800 МГц, заявленный показатель TDP — 25 Вт. Meta✴ признаёт, что у MTIA v1 присутствуют «узкие места» при работе с ИИ-моделями большой сложности: требуется оптимизация подсистем памяти и сетевых соединений. Однако в случае приложений низкой и средней сложности платформа, как утверждается, обеспечивает более высокую эффективность по сравнению с GPU. 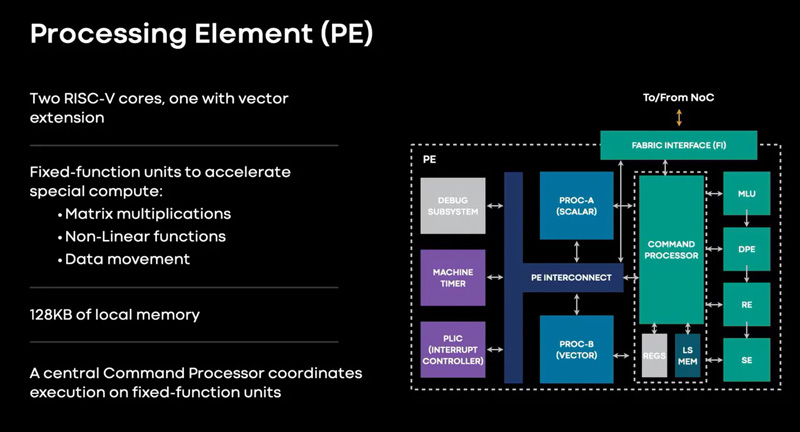 В дальнейшем в семействе MTIA появятся более производительные изделия, но подробности о них не раскрываются. Ранее говорилось, что Meta✴ создаёт некий секретный чип, который подойдёт и для обучения ИИ-моделей, и для инференса: это решение может увидеть свет в 2025 году.
19.05.2023 [10:00], Сергей Карасёв
Meta✴ анонсировала чип MSVP для ускорения обработки видеоКомпания Meta✴ представила специализированный чип MSVP, или Meta✴ Scalable Video Processor, спроектированный для ускорения выполнения операций, связанных с обработкой видеоматериалов. Это могут быть задачи по транскодированию роликов или потоковая передача контента. По данным Meta✴, пользователи соцсети Facebook✴ тратят 50 % своего времени на просмотр в общей сложности примерно 4 млрд видеороликов ежедневно. Эти материалы сжимаются после загрузки, а затем преобразовываются в другие форматы и передаются пользователям. Сложность заключается в том, чтобы быстро уменьшить размер файла, сохранить его на серверах Facebook✴ и передать в потоковом режиме с максимально возможным качеством для того или иного устройства, например, смартфона, планшета или ПК. 
Источник изображения: Meta✴ Эти задачи берёт на себя процессор MSVP. Он представляет собой интегральную схему специального назначения (ASIC). Чип предназначен для высококачественного транскодирования материалов для сервисов «видео по запросу», а также для оптимизации потоковых трансляций. В перспективе подобные процессоры, как ожидается, помогут организовать работу с видеороликами, созданными посредством генеративного ИИ. Кроме того, такие чипы будут использоваться в составе платформ AR/VR. Решение MSVP обеспечивает производительность транскодирования на уровне 4K@15в максимальном качестве в режиме «один поток на входе и пять на выходе». В стандартном качестве возможна работа в формате 4K@60.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 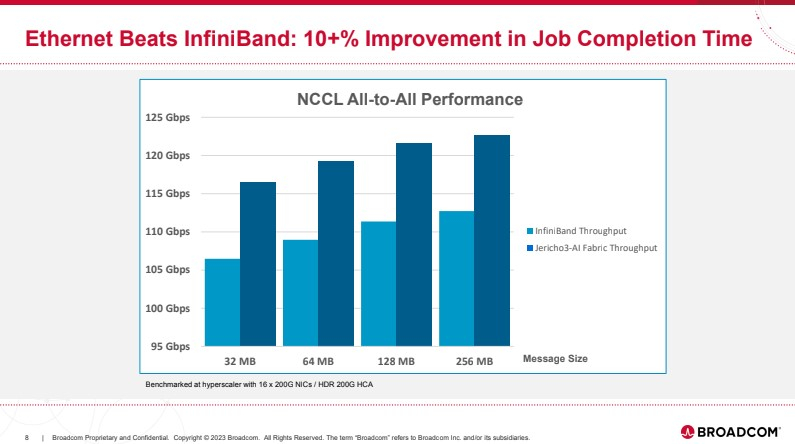 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0. |
|

