Материалы по тегу: суперкомпьютер
|
14.06.2022 [16:33], Владимир Мироненко
В Финляндии официально запущен LUMI, самый мощный суперкомпьютер в ЕвропеHPE и EuroHPC официально ввели в эксплуатацию вычислительную систему LUMI, установленную в ЦОД центре IT Center for Science (CSC) в Каяани (Финляндия), которая на данный момент считается самым мощным суперкомпьютером в Европе. LUMI — это первая система предэкзафлопсного класса, созданная в рамках совместного европейского проекта EuroHPC. LUMI будет в основном использоваться для решения важных для общества задач, включая исследования в области изменения климата, медицины, наук о жизни и т.д. Система будет применяться для приложений, связанных с высокопроизводительными вычислениями (HPC), искусственным интеллектом и аналитикой данных, а также в областях их пересечения. Для отдельных пользователей суперкомпьютер будет доступен в рамках второй пилотной фазы в августе, а полностью укомплектованная система станет общедоступной в конце сентября. 
Суперкомпьютер LUMI (Фото: Pekka Agarth) Суперкомпьютер стоимостью €202 млн принадлежит EuroHPC (JU). Половина из этой суммы была предоставлена Евросоюзом, четверть — Финляндией, а остальная часть средств поступила от остальных членов консорциума, включающего 10 стран. По состоянию на 30 мая LUMI занимал третье место в списке TOP500 самых быстрых суперкомпьютеров мира. Сейчас его производительность составляет 151,9 Пфлопс при энергопотреблении 2,9 МВт. LUMI (снег в переводе с финского) базируется на системе HPE Cray EX. Система состоит из двух комплексов. Блок с ускорителями включает 2560 узлов, каждый из которых состоит из одного 64-ядерного кастомного процессора AMD EPYC Trento и четырёх AMD Instinct MI250X. Второй блок под названием LUMI-C содержит только 64-ядерные CPU AMD EPYC Milan в 1536 двухсокетных узлах, имеющих от 256 Гбайт до 1 Тбайт RAM. 
Дата-центр LUMI (Фото: Fade Creative) LUMI также имеет 64 GPU NVIDIA A40, используемых для рабочих нагрузок визуализации, и узлы с увеличенным объёмом памяти (до 32 Тбайт на кластер). Основной интерконнект — Slingshot 11. Хранилище LUMI построено на базе СХД Cray ClusterStor E1000 c ФС Lustre: 8 Пбайт SSD + 80 Пбайт HDD. Также есть объектное Ceph-хранилище ёмкостью 30 Пбайт. Агрегированная пропускная способность СХД составит 2 Тбайт/с. В ближайшее время суперкомпьютер получит дополнительные узлы. После завершения всех работ производительность суперкомпьютера, как ожидается, вырастет примерно до 375 Пфлопс, а пиковая производительность потенциально превысит 550 Пфлопс. Общая площадь комплекса составит порядка 300 м2, а энергопотребление вырастет до 8,5 МВт. Впрочем, запас у площадки солидный — от ГЭС она может получить до 200 МВт. «Мусорное» тепло идёт на обогрев местных домов.
13.06.2022 [16:34], Руслан Авдеев
Площадка для будущего 2-Эфлопс суперкомпьютера El Capitan готова: 85 МВт + мощная система охлажденияНациональное управление ядерной безопасности (NNSA) при Министерстве энергетики США официально закончило реконструкцию ЦОД при Ливерморской национальной лаборатории (LLNL) в рамках проекта Exascale Computing Facility Modernization. Обновлены энергетическая система и система охлаждения местного вычислительного центра для использования вычислительных мощностей экзафлопсного уровня. Первой новой действующей системой NNSA станет 2-Эфлопс суперкомпьютер El Capitan, предназначенный для выполнения задач Ливерморской лаборатории, Лос-Аламосской национальной лаборатории и Сандийской национальной лаборатории. По словам представителя NNSA, экзафлопсные вычисления помогут стране в важных, неотложных проектах модернизации вооружений. 
Источник изображения: Department of Energy Обновление позволит Ливерморской лаборатории выполнять ресурсоёмкие задачи, 3D-моделирование и симуляцию процессов, связанных с реализацией военных проектов — это необходимо для того, чтобы соответствовать требованиям к сертификации Программы сопровождения ядерного арсенала, реализуемой под эгидой NNSA, основной миссией которой декларируется расширение возможностей американских средств ядерного сдерживания. Сейчас стадия обновления ЦОД завершена и намечен переход к следующим этапам. В результате реализации проекта более, чем удвоилась охлаждающая мощность объекта — теперь он способен ежедневно поглощать количество тепла, достаточного для того, чтобы растопить 28 тыс. тонн льда. Энергетическая мощность ЦОД увеличена с 45 до 85 МВт, а в процессе строительства были обновили линии электропередач, подстанции и управляющее оборудование. Ожидается, что итоговая производительность El Capitan составит более 2 Эфлопс, а потреблять он будет порядка 30–35 МВт. Проработать он должен до 2029 года, однако параллельно будет строиться ещё один суперкомпьютер нового поколения. Некоторые предполагают, что подобные площадки станут последними в своём роде, в первую очередь из-за проблем с электропитанием.
01.06.2022 [01:18], Владимир Мироненко
Ведущий специалист NERSC перешёл в Microsoft, заявив, что строящиеся экзафлопсные суперкомпьютеры будут последними в своём родеГленн Локвуд (Glenn K. Lockwood), ведущий специалист Национального научного вычислительного центра энергетических исследований (NERSC) при Министерстве энергетики США перешёл на работу в Microsoft. Он является архитектором высокопроизводительных масштабируемых систем хранения данных для суперкомпьютеров. Локвуд, в частности, руководил развёртыванием первого в мире 35-Пбайт All-Flash хранилища с ФС Lustre для суперкомпьютера Perlmutter. В своём блоге Локвуд объяснил, почему он ушёл из NERSC в Microsoft. По его словам, лидирующие HPC-системы балансируют на грани выживания, в то время как HPC-системы среднего клсса практически полностью обесцениваются поставщиками облачных услуг. При текущих тенденциях стоимость строительства нового дата-центра и обширной инфраструктуры питания и охлаждения для каждого нового мощного суперкомпьютера очень скоро станет непомерно высокой, говорит Локвуд. Он высказал мнение, что ЦОД мощностью 50–60 МВт, строящиеся сейчас для экзафлопсных суперкомпьютеров, будут последними в своём роде. 
Источник изображения: AMD Что касается менее мощных систем, таких как Perlmutter, то необходимость в них постепенно сокращается по мере того, как облако набирает обороты. «Вы можете установить полную систему [HPE] Cray EX, идентичную той, что вы можете найти в NERSC или OLCF, в Azure <…> и интегрировать её с богатыми инфраструктурными возможностями облака», — говорит Локвуд. Кроме того, облака действительно гораздо быстрее внедряют новинки. Так, процессоры AMD EPYC MilanX и ускорители Instinct MI200 появились в инфраструктуре Microsoft Azure намного раньше, чем в HPC-центрах. «Я не утверждаю, что знаю будущее, и многое из того, что я изложил, является в лучшем случае гипотетическим», — заявил Гленн Локвуд, отметив, что приверженность Министерства энергетики США к независимым HPC-системам сохранится по меньшей мере ещё десятилетие. Локвуд стал очередным специалистом, покинувшем традиционный HPC-сектор и ушедшим в Microsoft. В 2020 году в Microsoft перешёл технический директор Cray Стив Скотт (Steve Scott). Год спустя к Microsoft присоединился соруководитель программы Cray PathForward доктор Дэн Эрнст (Dan Ernst).
30.05.2022 [10:00], Игорь Осколков
Июньский TOP500: есть экзафлопс!59-я редакция TOP500, публичного рейтинга самых производительных суперкомпьютеров мира, стала наиболее знаменательной за последние 14 лет, поскольку официально был преодолён экзафлопсный барьер. Путь от петафлопса оказался долгим — первой петафлопсной системой стал суперкомпьютер IBM Roadrunner, и произошло это аж в 2008 году. Но минимальным порогом для попадания в TOP500 эта отметка стала только в 2019 году. Как и было обещано, официально и публично отметку в 1 Эфлопс в бенчмарке HPL на FP64-вычислениях первым преодолел суперкомпьютер Frontier — его устоявшаяся производительность составила 1,102 Эфлопс при теоретическом пике в 1,686 Эфлопс. Система на платформе HPE Cray EX235a использует оптимизированные 64-ядерные процессоры AMD EPYC Milan (2 ГГц), ускорители AMD Instinct MI250X и фирменный интерконнект Slingshot 11-го поколения. Система имеет суммарно 8 730 112 ядер, потребляет 21,1 МВт и выдаёт 52,23 Гфлопс/Вт, что делает её второй по энергоэффективности в мире. 
Суперкомпьютер Frontier (Фото: AMD) Впрочем, первое место в Green500 по данному показателю всё равно занимает тестовый кластер в составе всё того же Frontier: 120 832 ядра, 19,2 Пфлопс, 309 кВт, 62,68 Гфлопс/Вт. Третье и четвёртое места достались европейским машинам LUMI и Adastra, новичкам TOP500, которые по «железу» идентичны Frontier, но значительно меньше. Да и разница в Гфлопс/Вт между ними минимальна. Скопом они сместили предыдущего лидера — экзотичную японскую систему MN-3 от Preferred Networks. Японская система Fugaku, лидер по производительности в течение двух последних лет, сместилась на второе место TOP500. Третье место у финской системы LUMI с показателем производительности 151,9 Пфлопс — обратите внимание, насколько велик разрыв в первой тройке машин. Наконец, в Топ-10 последнее место занял новичок Adastra (46,1 Пфлопс), который расположен во Франции. 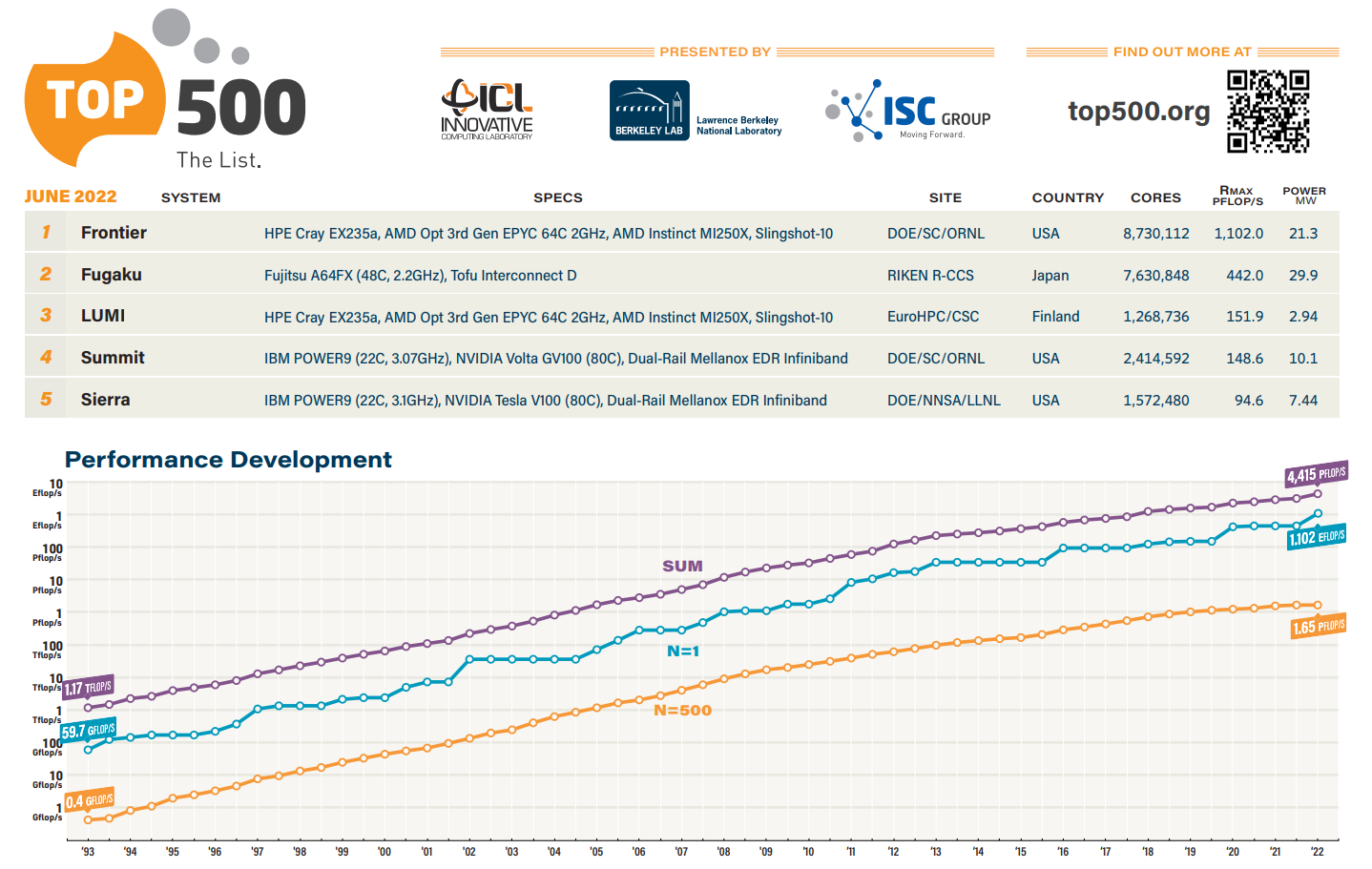
Источник: TOP500 В бенчмарке HPCG всё ещё лидирует Fugaku (16 Пфлопс), но, судя по всему, только потому, что для Frontier данных пока нет. Ну и потому, что результат суперкомпьютера LUMI, который почти на порядок медленнее Frontier, в HPCG составляет 1,94 Пфлопс. Наконец, в HPL-AI Frontier также отобрал первенство у Fugaku — 6,86 Эфлопс в вычислениях смешанной точности против 2 Эфлопс. В общем, у Frontier полная победа по всем фронтам, и эту машину можно назвать не только самой быстрой в мире, но первой по-настоящему экзафлопсной системой. Если, конечно, не учитывать неофициальные результаты OceanLight и Tianhe-3 из Поднебесной, которые в TOP500 никто не заявил. Число китайских систем в нынешнем рейтинге осталось прежним (173 шт.), тогда как США «ужались» со 150 до 127 шт. Российских систем в списке всё так же семь. Лидерами по числу поставленных систем остаются Lenovo, HPE и Inspur, а по их суммарной производительности — HPE, Fujitsu и Lenovo. С другой стороны, массовых изменений и не было — в нынешнем списке всего около сорока новых систем. 
Источник: TOP500 Однако нельзя не отметить явный прогресс AMD — да, чуть больше трёх четвертей машин из списка используют процессоры Intel, но AMD удалось за полгода отъесть около 4 %. При этом AMD EPYC Milan присутствует в более чем трёх десятках систем, а доля Intel Xeon Ice Lake-SP вдвое меньше, хотя эти процессоры появились практически одновременно. Ускорители ожидаемо стали использовать больше — они применяются в 170 системах (было 150). Подавляющее большинство приходится на решения NVIDIA разных поколений, но и для новых Instinct MI250X нашлось место в восьми машинах. Ну а в области интерконнекта Infiniband потихоньку догоняет Ethernet: 226 машин против 196 + ещё 40 с Omni-Path + редкие проприетарные решения.
16.04.2022 [23:54], Алексей Степин
Космический суперкомпьютер HPE Spaceborne-2 успешно завершил 24 эксперимента на МКСПериферийные вычисления подразумевают работу достаточно мощных серверов в нестандартных условиях. Казалось бы, 400 километров — не такое уж большое расстояние. Но если это высота орбиты космической станции, то более «периферийное» место найти будет сложно. А ведь если человечество планирует и далее осваивать космос, оно неизбежно столкнётся и с проблемами, свойственными космическим ЦОД. Первый космический суперкомпьютер, как его окрестили создатели из HPE, появился в 2017 году и успешно проработал на орбите 615 дней. Инженеры учли выявленные особенности работы такой системы на орбите и в прошлом году отправили на МКС Spaceborne-2 (SBC-2), который стал вдвое производительнее предшественника. 
HPE Spaceborne-1 Хотя SBC-2 по земным меркам и невелик и состоит всего из двух вычислительных узлов (HPE Edgeline EL4000 и HPE ProLiant DL360 Gen10, совокупно чуть более 2 Тфлопс), это самая мощная компьютерная система, когда-либо работавшая в космосе. К тому же, это единственная космическая вычислительная система, оснащённая ИИ-ускорителем NVIDIA T4. 
HPE Spaceborne-2 (Изображения: HPE) Теперь же HPE сообщает, что эта машина меньше чем за год помогла в проведении 24 важных научных экспериментов. Всё благодаря достаточно высокой производительности. Одним из первых стал стал анализ генов — обработка данных непосредственно на орбите позволила снизить объём передаваемой информации с 1,8 Гбайт до 92 Кбайт. Но это далеко не единственный результат.  Так, ИИ-ускорители были задействованы для визуального анализа микроскопических повреждений скафандров, используемых для выхода в открытый космос. Они же помогли в обработке данных наблюдения за крупными погодными изменениями и природными катаклизмами. Также был проведён анализ поведения металлических частиц при 3D-печати в невесомости, проверена возможность работы 5G-сетей космических условиях, ускорены расчёты требуемых объёмов топлива для кораблей и т.д.  Ряд проблем ещё предстоит решить: в частности, в условиях повышенной космической радиации существенно быстрее выходят из строя SSD, что естественно для технологии, основанной на «ловушках заряда». По всей видимости, для дальнего космоса целесообразнее будет использовать накопители на базе иной энергонезависимой памяти. Впрочем, при освоении Луны или Марса полагаться на земные ЦОД тоже будет трудно, а значит, достаточно мощные вычислительные ресурсы придётся везти с собой.
30.03.2022 [22:01], Владимир Мироненко
Российская суперкомпьютерная платформа «РСК Торнадо» объединила отечественные «Эльбрусы» и зарубежные x86-процессорыГруппа компаний РСК на конференции «Параллельные вычислительные технологии (ПаВТ) 2022» сообщила о создании суперкомпьютерной платформы «РСК Торнадо», которая позволяет одновременно использовать в одной системе вычислительные узлы на базе зарубежных x86-процессоров и отечественных чипов «Эльбрус». Возможность использования различных типов микропроцессорных архитектур в одном монтажном шкафу (до 104 серверов в стойке), позволит ускорить темпы импортозамещения в области высокопроизводительных вычислительных систем (HPC), решений для центров обработки данных (ЦОД) и систем хранения данных (СХД). Унифицированная интероперабельная (т.е. обеспечивающая функциональную совместимость разных решений) платформа «РСК Торнадо» предназначена для решения широкого круга задач, в том числе для работы с нагрузками Big Data, HPC и ИИ. 
Суперкомпьютер «Говорун» в ОИЯИ (Фото: Группа компаний РСК) Разработка и создание вычислительных систем на основе «РСК Торнадо» осуществляется на территории России в рамках соглашения с Министерством промышленности и торговли Российской Федерации с целью реализации подпрограммы «Развитие производства вычислительной техники» в составе государственной программы «Развитие электронной и радиоэлектронной промышленности». Программный стек «РСК БазИС» для вышеупомянутой платформы тоже разработан в России. В настоящее время система «РСК БазИС» используется для оркестрации вычислительных мощностей Межведомственного суперкомпьютерного центра (МСЦ) РАН, Санкт-Петербургского политехнического университета (СПбПУ) и Объединенного института ядерных исследований (ОИЯИ), сведённых в единую инфраструктуру для оптимизации вычислительных ресурсов.
16.02.2022 [21:17], Алексей Степин
Atos анонсировала экзафлопсные суперкомпьютеры BullSequana XH3000 — гибридные и «зелёные»Atos представила суперкомпьютерную платформу BullSequana XH3000, которая придёт на смену XH2000 и станет основой для машин экзафлопсного класса, ориентированных на такие требовательные к вычислениям области науки как климатология, фармакология и генетика. Суперкомпьютер имеет гибридную архитектуру и на данный момент является самым мощным и энергоэффективным решением в арсенале Atos. Что немаловажно, новая система разработана в Европе и будет производиться на заводе Atos в городе Анже ( Франция). Начало коммерческих поставок запланировано на IV квартал 2022 года.  Наиболее интересной особенностью BullSequana XH3000, пожалуй, можно назвать действительно беспрецедентный уровень гибридизации архитектур «под одной крышей». В рамках одного кластера могут быть задействованы вычислительные архитектуры AMD, Intel, NVIDIA и даже чипы, разрабатываемые консорциумом EPI, в том числе SiPearl. А в будущем возможна интеграция квантовых систем. Такая гибкость позволяет компании-разработчику говорить о шестикратном превосходстве новинки над решениями предыдущего поколения.  Кроме того, Atos весьма серьёзное внимание уделяет проблеме энергоэффективности и экологичности. В BullSequana XH3000 используется последнее, четвёртое поколение систем жидкостного охлаждения с «прямым контактом», которое минимум на 50% эффективнее предыдущего поколения. К тому же, вся платформа спроектирована таким образом, чтобы весь её жизненный цикл, от добычи материалов и производства до демонтажа и утилизации, был как можно более «зелёным». Новый суперкомпьютер изначально спроектирован как масштабируемое решение — будут доступны конфигурации производительностью от 1 Пфлопс до 1 Эфлопс, а к моменту появления ускорителей следующего поколения появятся и варианты с производительностью 10 Экзафлопс. Также разработчики обращают внимание на крайнюю гибкость BullSequana XH3000 по части интерконнекта — она будет совместима с фирменной фабрикой BXI, Ethernet, а также InfiniBand HDR/NDR.
25.01.2022 [03:33], Владимир Мироненко
Meta✴ и NVIDIA построят самый мощный в мире ИИ-суперкомпьютер RSC: 16 тыс. ускорителей A100 и хранилище на 1 ЭбайтMeta✴ (ранее Facebook✴) анонсировала новый крупномасштабный исследовательский кластер — ИИ-суперкомпьютер Meta✴ AI Research SuperCluster (RSC), предназначенный для ускорения решения задач в таких областях, как обработка естественного языка (NLP) с обучением всё более крупных моделей и разработка систем компьютерного зрения. На текущий момент Meta✴ RSC состоит из 760 систем NVIDIA DGX A100 — всего 6080 ускорителей. К июлю этого года, как ожидается, система будет включать уже 16 тыс. ускорителей. Meta✴ ожидает, что RSC станет самым мощным ИИ-суперкомпьютером в мире с производительностью порядка 5 Эфлопс в вычислениях смешанной точности. Близкой по производительность системой станет суперкомпьютер Leonardo, который получит 14 тыс. NVIDIA A100. 
Изображения: Meta✴ Meta✴ RSC будет в 20 раз быстрее в задачах компьютерного зрения и в 3 раза быстрее в обучении больших NLP-моделей (счёт идёт уже на десятки миллиардов параметров), чем кластер Meta✴ предыдущего поколения, который включает 22 тыс. NVIDIA V100. Любопытно, что даже при грубой оценке производительности этого кластера он наверняка бы попал в тройку самых быстрых машин нынешнего списка TOP500.  Новый же кластер создаётся с прицелом на возможность обучения моделей с триллионом параметров на наборах данных объёмом порядка 1 Эбайт. Именно такого объёма хранилище планируется создать для Meta✴ RSC. Сейчас же система включает массив Pure Storage FlashArray объемом 175 Пбайт, 46 Пбайт кеш-памяти на базе систем Penguin Computing Altus и массив Pure Storage FlashBlade ёмкостью 10 Пбайт. Вероятно, именно этой СХД и хвасталась Pure Storage несколько месяцев назад, не уточнив, правда, что речь шла об HPC-сегменте.  Итоговая пропускная способность хранилища должна составить 16 Тбайт/с. Meta✴ RSC сможет обучать модели машинного обучения на реальных данных, полученных из социальных сетей компании. В качестве основного интерконнекта используются коммутаторы NVIDIA Quantum и адаптеры HDR InfiniBand (200 Гбит/с), причём, судя по видео, с жидкостным охлаждением. Каждому ускорителю полагается выделенное подключение. Фабрика представлена двухуровневой сетью Клоза.  Meta✴ также разработала службу хранения AI Research Store (AIRStore) для удовлетворения растущих требований RSC к пропускной способности и ёмкости. AIRStore выполняет предварительную обработку данных для обучения ИИ-моделей и предназначена для оптимизации скорости передачи. Компания отдельно подчёркивает, что все данные проходят проверку на корректность анонимизации. Более того, имеется сквозное шифрование — данные расшифровываются только в памяти узлов, а ключи регулярно меняются. 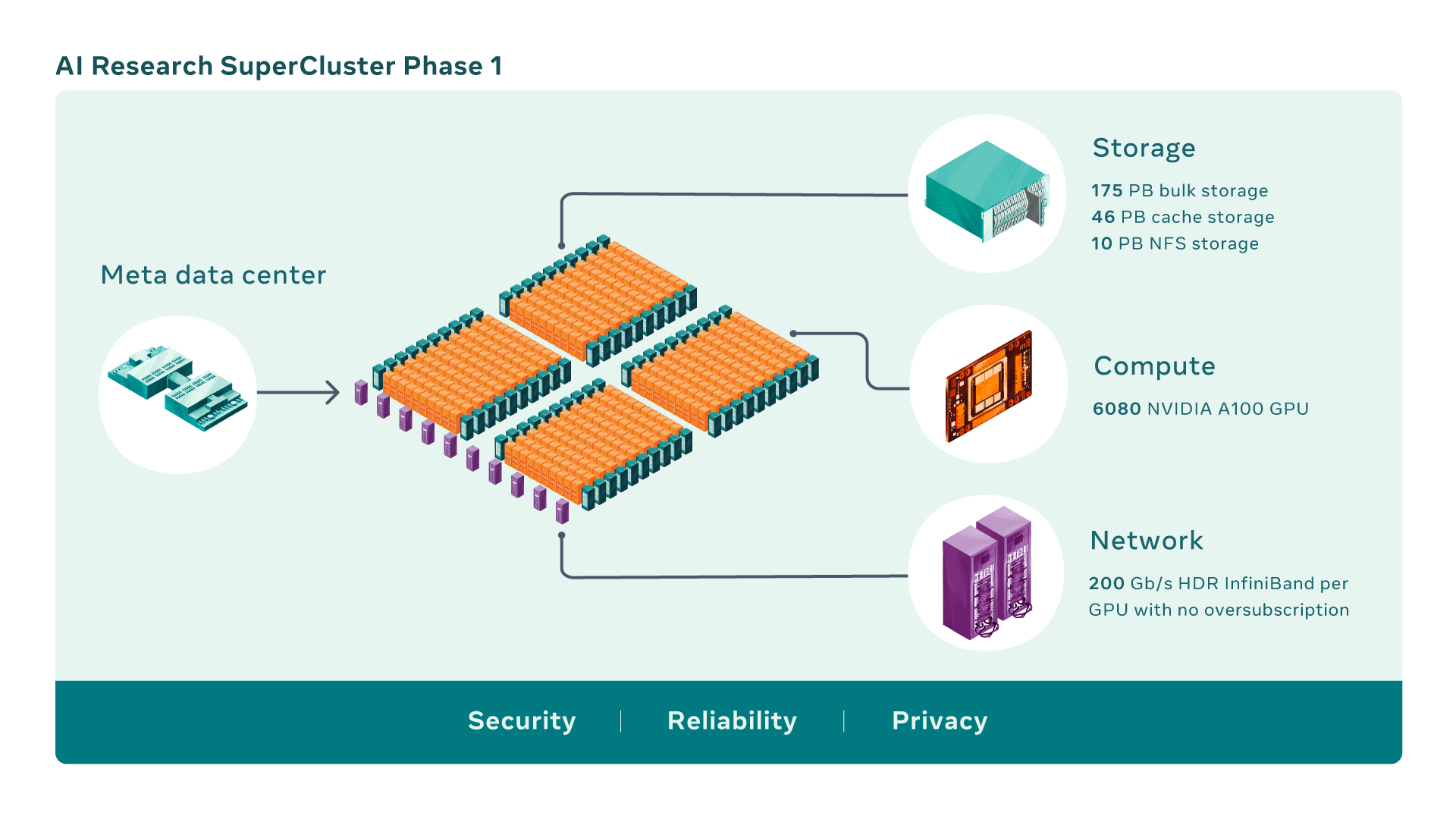 Однако ни о стоимости проекта, ни о потребляемой мощности, ни о физическом местоположении Meta✴ RSC, ни даже о том, почему были выбраны узлы DGX, а не HGX (или вообще другие ускорители), Meta✴ не рассказала. Для NVIDIA же эта машина определённо стала очень крупным и важным заказом.
16.11.2021 [03:33], Игорь Осколков
TOP500: уж ноябрь на дворе, а экзафлопса не видатьПоследняя версия публичного рейтинга самых производительных в мире суперкомпьютеров TOP500 так и осталась без экзафлопсных машин. Китай не захотел включать в него две системы такого класса и пошёл обходным путём, номинировав работы своих учёных на премию Гордона Белла — в соответствующих научных работах даны неполные характеристики машин и показатели их производительности. Поэтому лидером списка остаётся обновлённая японская система Fugaku, 7,6 млн ядер которой выдают 442 Пфлопс. И она всё ещё втрое быстрее своего ближайшего конкурента Summit. Первые результаты сборки Frontier в список попасть не успели. Всего в ноябрьском рейтинге есть порядка 70 новых систем, но, как и прежде, больше половины из них — однотипные системы Lenovo, массово устанавливаемые в Китае. На Китай вообще приходится более трети (34,6%) систем в списке. На втором месте находятся США (29,8%), а на третьем — Япония (6,4%). По суммарной производительности Топ-3 тот же, но порядок иной: США (32,5%), Япония (20,7%), Китай (17,5%). В число лидеров также входят Германия, Франция, Нидерланды, Канада, Великобритания, Южная Корея и Россия. У РФ теперь есть сразу семь машин в списке с суммарной производительностью 73,715 Пфлопс. Для сравнения — Perlmutter (5 место) после апгрейда выдаёт 70,87 Пфлопс, а у Южной Кореи тоже есть семь машин, но с чуть более высокой суммарной производительностью в 82,177 Пфлопс. 
Суперкомпьютер Chervonenkis (Фото: Яндекс) К уже имевшимся в TOP500 российским системам MTS GROM (294 место), Lomonosov-2 (Ломоносов-2, 241 место) и Christofari (Кристофари, 72 место) добавились Christofari Neo (Кристофари Нео, 43 место), а также сразу три системы Яндекса: Ляпунов (Lyapunov, 40 место), Галушкин (Galushkin, 36 место) и Червоненкис (Chervonenkis, 19 место). Примечательно, что все российские системы этого года используют AMD EPYC Rome и NVIDIA A100, а также интерконнект Infininiband. Машины для МТС и Сбера сделала сама NVIDIA (это всё DGX), а вот у Яндекса путь особый. Ляпунов (12,81 Пфлопс) создан китайским Национальным университетом оборонных технологий (National University of Defense Technology, NUDT) и Inspur на базе серверов NF5488A5 (AMD EPYC 7662@2 ГГц + A100 40 Гбайт). Червоненкис (21,53 Пфлопс) и Галушкин (16,02 Пфлопс) разработаны IPE, NVIDIA и Tyan. В этих системах используются EPYC 7702 (тоже 64-ядерные с базовой частотой 2 ГГц) и более новые A100 (80 Гбайт). Среди прочих новых систем TOP500 особо выделяется Voyager-EUS2, которая замыкает Топ-10. Это ещё система на базе обновлённых инстансов Microsoft Azure ND A100 v4 с 80-Гбайт версией A100. Однако ещё одной облачной машиной уже никого не удивить, в отличие от совершенно неожиданного возврата японской PEZY, пропавшей с радаров после скандала 2017 года. Новая ZettaScaler3.0 занимает 453 место и базируется на AMD EPYC 7702P и фирменных ускорителях PEZY-SC3. 
Изображение: OGAWA, Tadashi (twitter.com/ogawa_tter) В целом, последний год был удачным и для AMD, и для NVIDIA. Первая почти втрое нарастила число систем на базе EPYC — их теперь в списке 74 (или почти треть новых участников списка), если учитывать Naples/Hygon (таких систем 3). Если же смотреть более детально именно на CPU, то тут лидером всё равно остаётся Intel, хотя она и потеряла несколько процентных пунктов за последние полгода — всего 408 машин используют её процессоры. Правда, новейших Ice Lake-SP среди них всего 10, тогда как у EPYC Milan уже 17. Без акселераторов обходятся 350 суперкомпьютеров списка, зато из 150 оставшихся 143 используют различные поколения ускорителей NVIDIA. Удивительно, но ни одной системы с ускорителями AMD Instinct в ноябрьском рейтинге нет. Остальные акселераторы представлены в единичном экземпляре. И это либо устаревшие системы, либо экзотика из Китая и Японии. Последняя в лице MN-3 всё ещё лидирует по энергоэффективности в Green500. Систем с Infiniband в списке 178, с Ethernet — 242. Как обычно, по производительности систем лидирует именно IB — 44,5% против 22,4% у Ethernet. Это, к слову, несколько отличается от показателей HPC-индустрии в целом, где в количественном выражении у них практически равные доли. На Omni-Path пришлось 40 систем в TOP500, и столько же на проприетарные интерконнекты. Тут интересно разве что появление второй машины с Atos BXI V2. 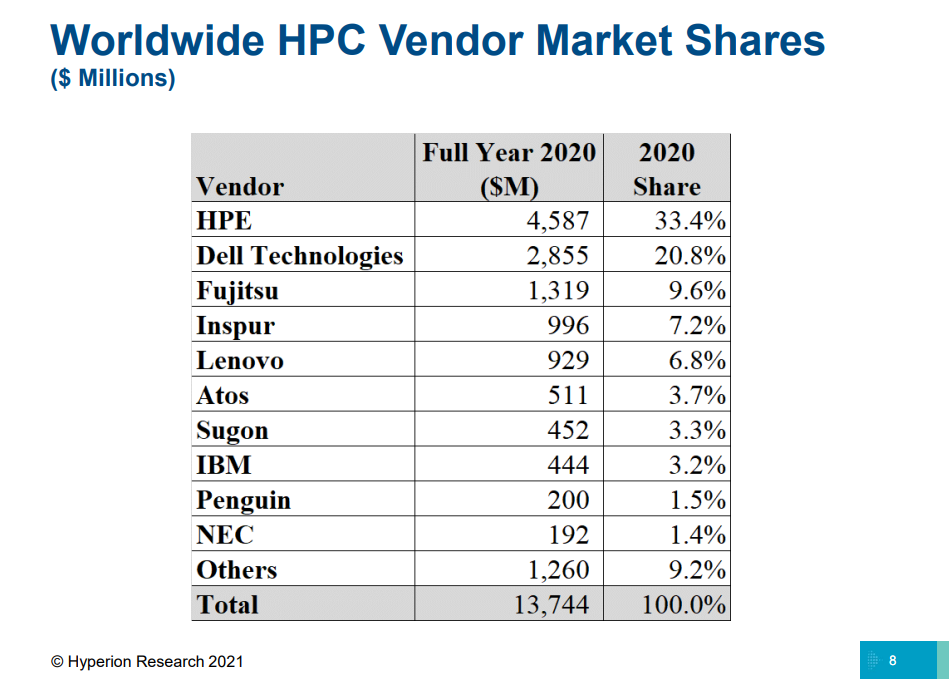 Среди производителей по количеству машин лидируют Lenovo (180 шт., это в основном уже упомянутые типовые развёртывания в Китае), HPE (84 шт., сюда же входит наследие Cray и SGI) и Inspur (50 шт.). По производительности картина иная, в Топ-3 входят HPE, Fujitsu (во многом благодаря Fugaku) и Lenovo. По HPC-рынку в целом, согласно данным Hyperion Research, в денежном выражении тройка лидеров включает HPE, Dell и Fujitsu (да, опять «виноват» Fugaku).
22.10.2021 [20:03], Руслан Авдеев
Для обеспечения работы суперкомпьютера El Capitan потребуется 28 тыс. тонн воды и 35 МВт энергииК моменту ввода в эксплуатацию в 2023 году суперкомпьютер El Capitan на базе AMD EPYC Zen4 и Radeon Instinct, как ожидается, будет иметь самую высокую в мире производительность — более 2 Эфлопс. А это означает, что ему потребуются гигантские мощности для питания и охлаждения. Ливерморская национальная лаборатория (LLNL), в которой и будет работать El Capitan, поделилась подробностями о масштабном проекте, призванном обеспечить HPC-центр необходимой инфраструктурой. В основе плана модернизации лежит проект Exascale Computing Facility Modernization (ECFM) стоимостью около $100 млн. В его рамках будет обновлена уже существующая в LLNL инфраструктура. Для реализации проекта необходимо получить очень много разрешений от местных регуляторов и очень тесно взаимодействовать с местными поставщиками электроэнергии. Тем не менее, LLNL заявляет, что проект «почти готов», по некоторым оценкам — на 93%. Функционировать новая инфраструктура должна с мая 2022 года (с опережением графика).  Сам проект стартовал ещё в 2019 году и, согласно планам, должен быть полностью завершён в июле 2022 года. В его рамках модернизируют территорию центра, введённого в эксплуатацию в 2004 году, общей площадью около 1,4 га. Если раньше центр, в котором работали системы вроде лучшего для 2012 года суперкомпьютера Sequoia (ныне выведенного из эксплуатации), обеспечивал подачу до 45 МВт, то теперь инфраструктура рассчитана уже на 85 МВт. Конечно, даже для El Capitan такие мощности будут избыточны — ожидается, что суперкомпьютер будет потреблять порядка 30-35 МВт. Однако LLNL заранее думает о «жизнеобеспечении» преемника El Capitan. Следующий суперкомпьютер планируется ввести в эксплуатацию до того, как его предшественник будет отключён в 2029 году. Кроме того, для новой системы потребуется установка нескольких 3000-тонных охладителей. Если раньше общая ёмкость системы охлаждения составляла 10 000 т воды, то теперь она вырастет до 28 000 т. |
|

