Про ускорители Gaudi3 компания Intel достаточно подробно рассказала ещё весной этого года — 5-нм новинка стала дальнейшим развитием идей, заложенных в предыдущих поколениях Gaudi. Объявить о доступности новых ИИ-ускорителей Intel решила одновременно с анонсом новых серверных процессоров Xeon 6900P (Granite Rapids), которые в видении компании являют собой «идеальную пару». Впрочем, в компании признают лидерство NVIDIA, так что обещают оптимизировать процессоры для работы с ускорителями последней. А вот ускорителей Falcon Shores, вполне вероятно, с новой политикой Intel потенциальные заказчики не дождутся.

Источник изображений здесь и далее: Intel
На данный момент главной новостью является то, что в распоряжении Intel не просто есть некий ИИ-ускоритель с более или менее конкурентоспособной архитектурой и производительностью, а законченное и доступное заказчикам решение, уже успевшее привлечь внимание крупных производителей и поставщиков серверного оборудования.
Впрочем, на презентации были продемонстрированы любопытные слайды, в частности, касающиеся архитектуры и принципов работы блоков матричной математики (MME), тензорных ядер (TPC), а также устройство подсистемы памяти.
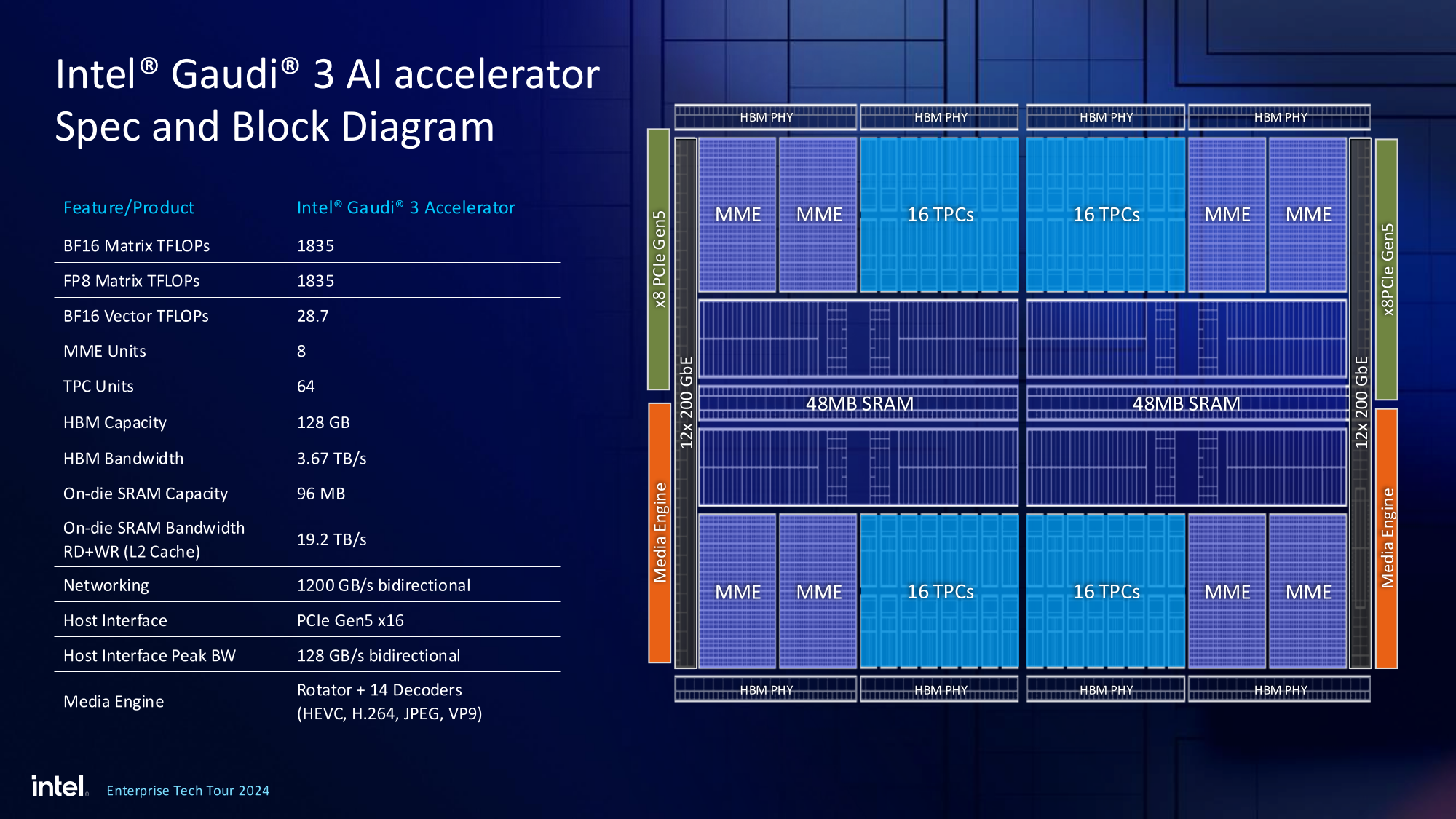
В последнем случае любопытен максимальный отход от иерархических принципов построения в пользу единого унифицированного пространства памяти, включающего в себя кеши L2 и L3, а также набортные HBM2e-стеки ускорителя. Общение с сетевым интерконнектом при этом организовано из пространства L3, что должно минимизировать задержки.

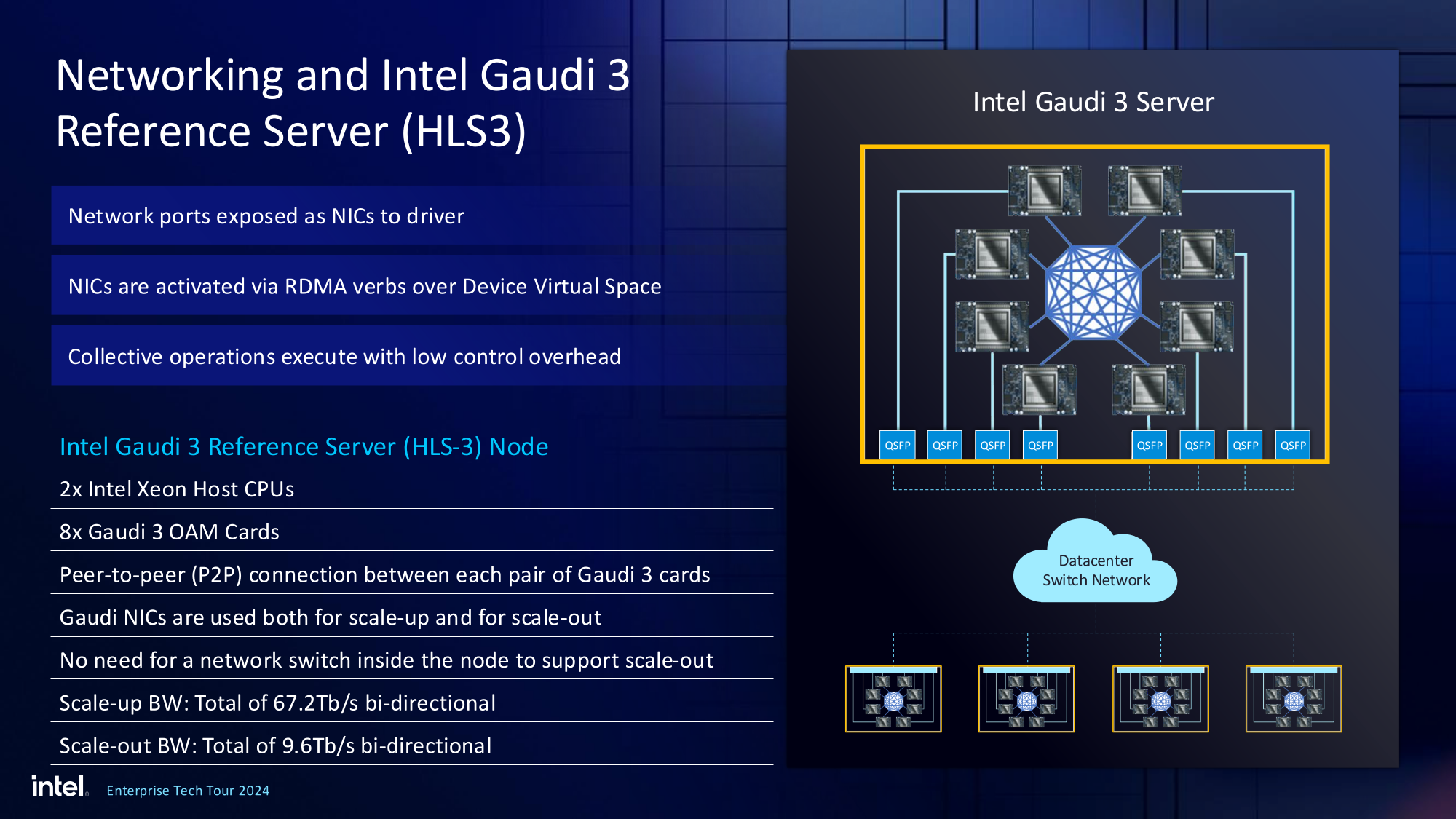
При этом сетевые порты доступны операционной системе как NIC через драйвер Gaudi3, с управлением посредством RDMA verbs. Благодаря большому количеству таких виртуальных NIC, организация интерконнекта внутри сервера-узла не требует никаких коммутаторов, а совокупная внутренняя производительность при этом достигает 67,2 Тбит/с.

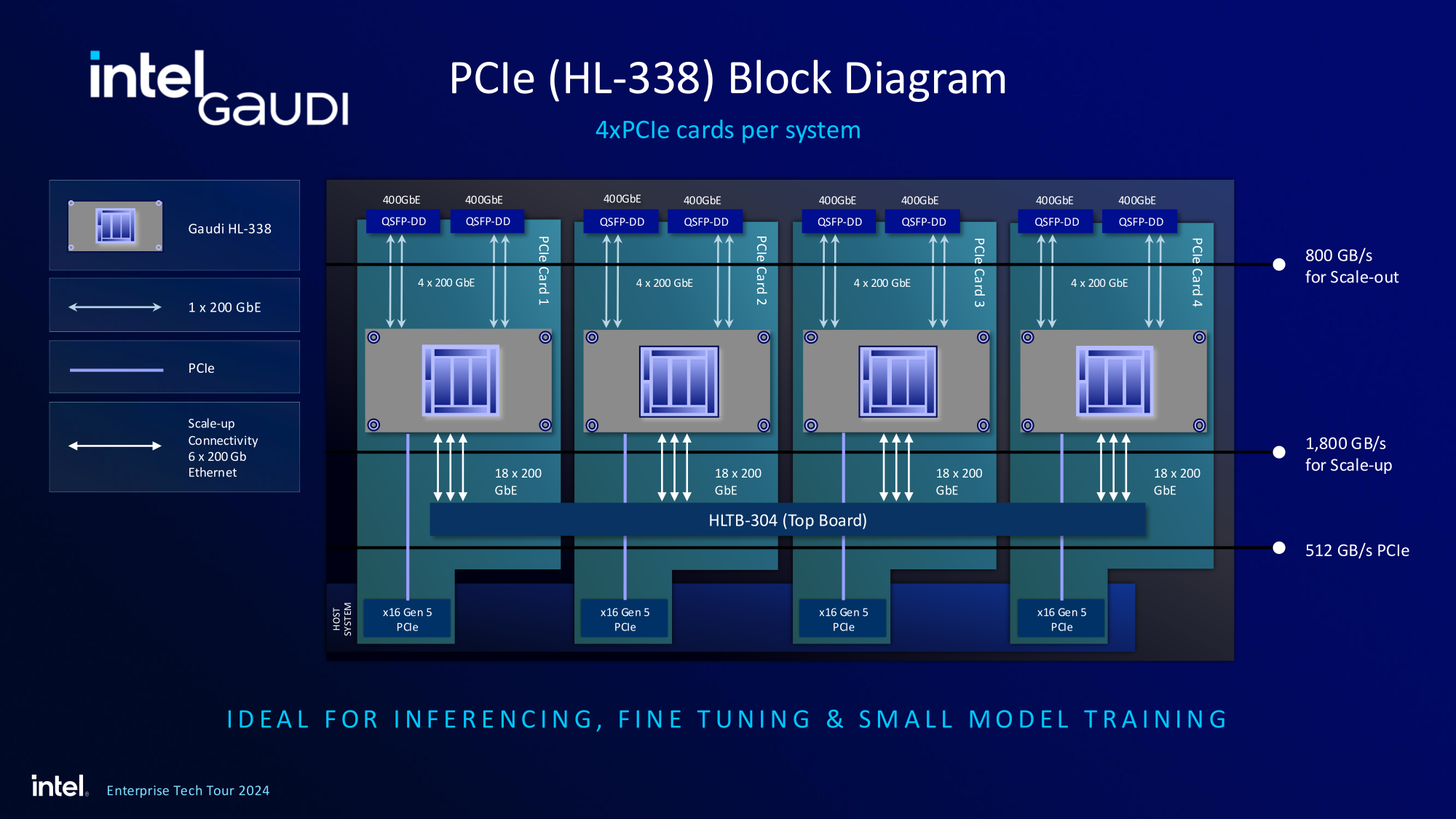
Хотя основой экосистемы Gaudi3 станут в первую очередь ускорители HL-325L и UBB-платы HLB-325, есть у Intel и PCIe-вариант в виде FHFL-платы HL-338: 1,835 Пфлопс в режиме FP8 при теплопакете 600 Вт. Оно имеет только 22 200GbE-контроллера, а в остальном повторяет конфигурацию HL-325L с восемью блоками матричной математики (MME).

Эти ускорители получат пару портов QSFP-DD, каждый из которых будет поддерживать скорость 400 Гбит/с, а между собой платы в пределах одного сервера смогут общаться при помощи специального бэкплейна.
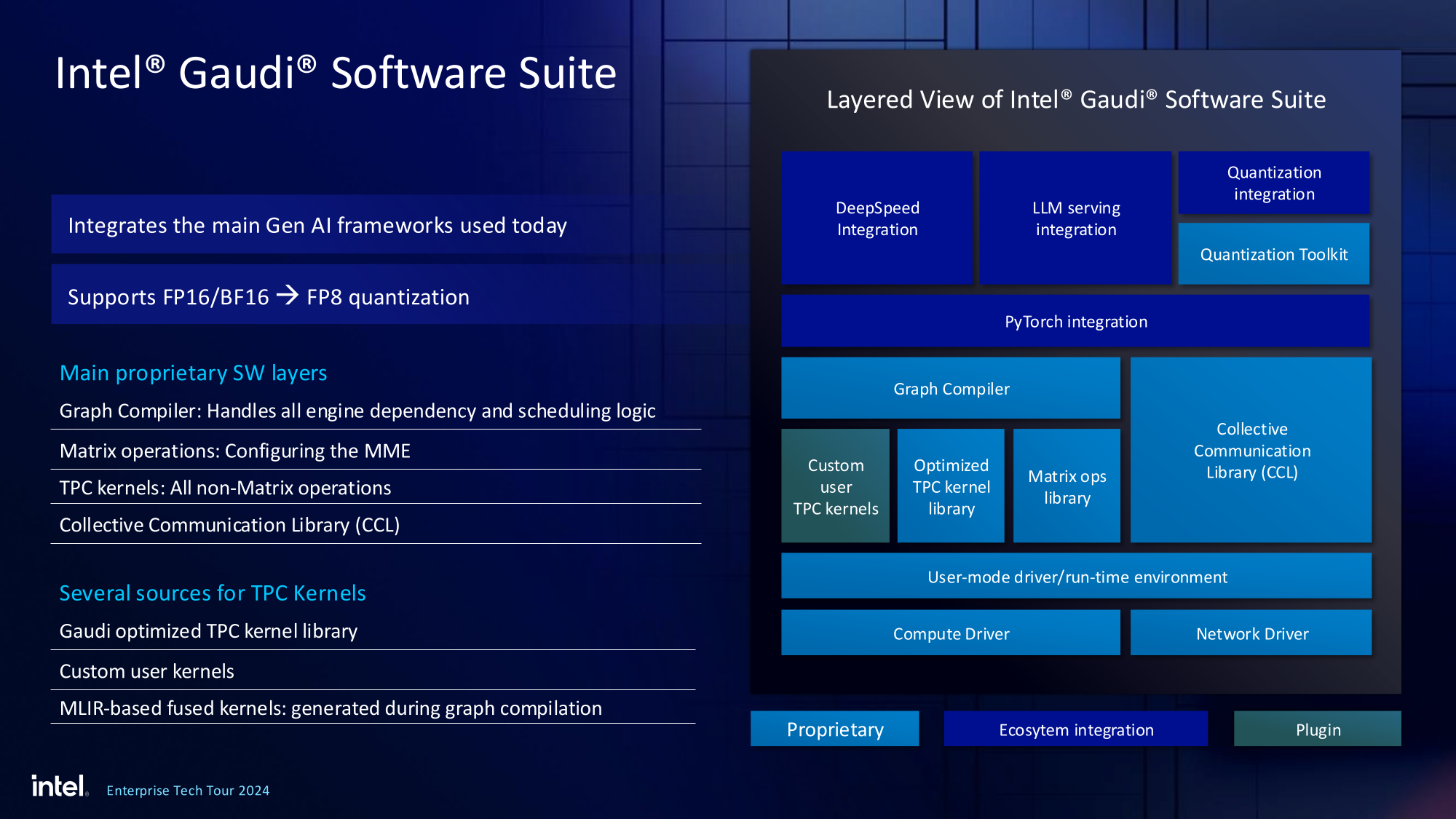
Важно то, что Gaudi3 успешно прошёл путь от анонса до становления сердцем полноценной аппаратно-программной экосистемы, в том числе благодаря ставке на программное обеспечение с открытым кодом. В настоящее время Intel в содействии с партнёрами могут предложить широчайший по масштабу спектр решений на базе Gaudi3 — от рабочих станций и периферийных серверов до вычислительных узлов, собирающихся в стойки, кластеры и даже суперкластеры.
В числе крупнейших партнёров Intel по новой экосистеме есть Dell и Supermicro, представившие серверные системы c Gaudi3. Начало массовых поставок этих систем запланировано на октябрь 2024 года. Вряд ли такие серверы будут развёртываться по одному, поэтому Intel рассказала о возможностях масштабирования Gaudi3-платформ.

Один узел с восемью OAM-модулями HL-325L, развивающий 14,7 Пфлопс в режиме FP8 и располагающий 1 Тбайт HBM станет основой для 32- и 64-узловых кластеров с 256 и 512 Gaudi3 на борту, благо нехватка пропускной способности сетевой части Gaudi3 не грозит — она составляет 9,6 Тбайт/с для одного узла. Из таких кластеров может быть составлен суперкластер с 4096 ускорителями или даже мегакластер, где их число достигнет 8192. Производительность в этом случае составит 15 Эфлопс при объёме памяти 1 Пбайт и совокупной производительности сети 9,8 Пбайт/с.
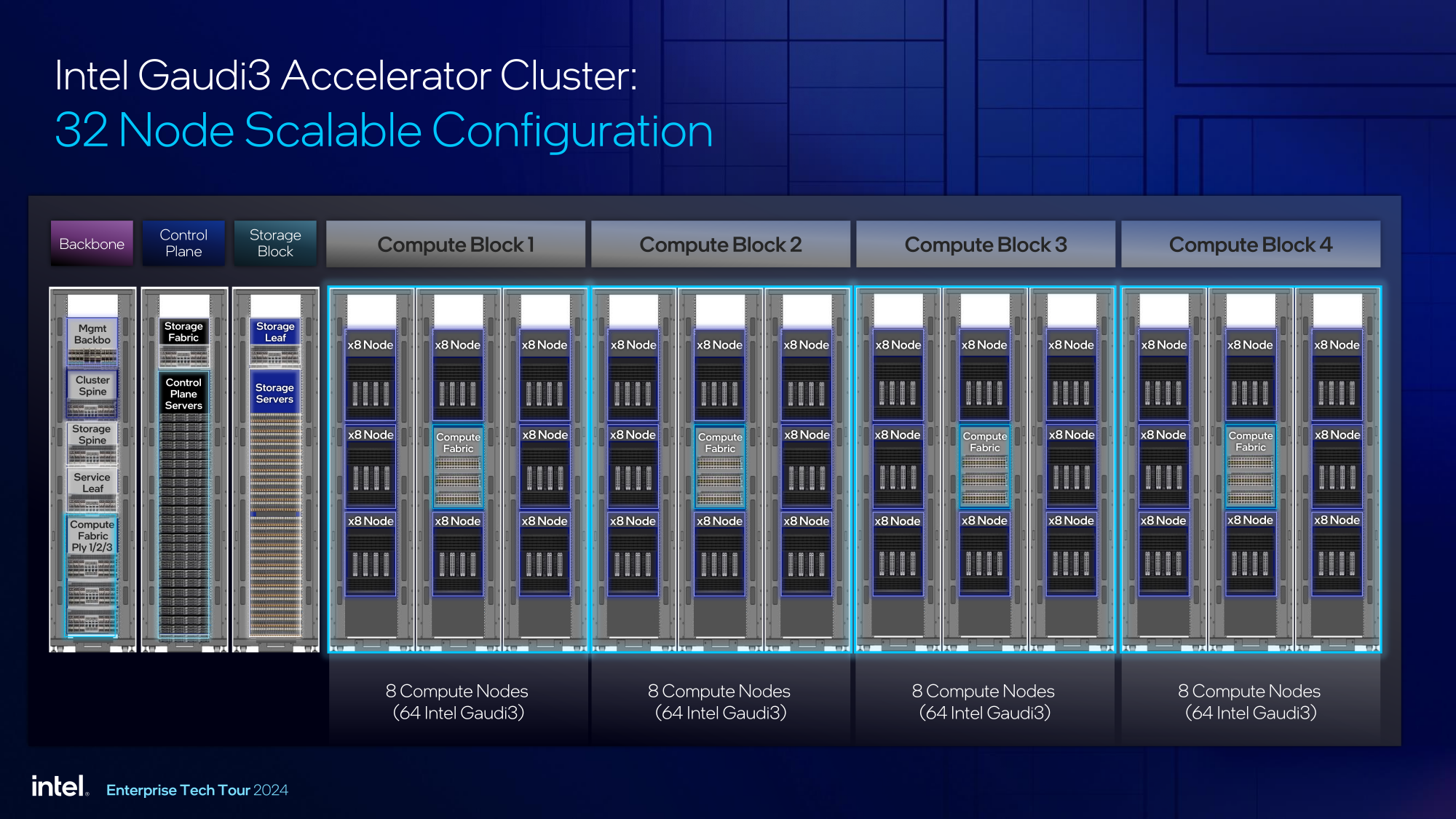
Типовой 32-узловой кластер на базе Gaudi3 Intel — это решение средней плотности с 15 стойками, содержащими не только вычислительные узлы, но и управляющие серверы, сетевые коммутаторы и подсистему хранения данных. Благодаря тому, что Intel в качестве интерконнекта для Gaudi3 избрала открытый и широко распространённый стандарт Ethernet (200GbE RoCE, 24 контроллера на ускоритель), не должно возникнуть проблем с совместимостью и привязкой к аппаратному обеспечению единственного вендора, как это имеет место быть c NVIDIA InfiniBand и NVLink.

Вкупе с программным обеспечением, основой которого является открытый OneAPI, и развитой системой техподдержки, системы на базе Gaudi3 станут надёжной основой для развёртывания ИИ-систем класса RAG, позволяющих заказчику в кратчайшие сроки запускать сети LLM с собственными датасетами без переобучения модели с нуля, говорит компания.

Именно в сферах, так или иначе связанных с большими языковыми моделями, Gaudi3 и системы на его основе должны помочь Intel укрепить свои позиции. Компания приводит данные, что Gaudi3 производительнее H100 примерно в 1,19 раза без учёта энергоэффективности, но в пересчёте «ватт на доллар» эти ускорители превосходят NVIDIA H100 уже в два раза.

Правда, H100 арсенал NVIDIA уже не ограничивается, но с массовой доступности новых решений Intel они могут оказаться привлекательнее. К тому же платформа совместима со всеми основными фреймворками, библиотеками и средствами управления. Впрочем, на примере AMD прекрасно видно, насколько индустрия привязана к решениям NVIDIA, причём в первую очередь программным.
Источник:

