Компания NVIDIA опубликовала новые, ещё более впечатляющие результаты в области работы с большими языковыми моделями (LLM) в бенчмарке MLPerf Inference 4.0. За прошедшие полгода и без того высокие результаты, демонстрируемые архитектурой Hopper в инференс-сценариях, удалось улучшить практически втрое. Столь внушительный результат достигнут благодаря как аппаратным улучшениям в ускорителях H200, так и программным оптимизациям.
Генеративный ИИ буквально взорвал индустрию: за последние десять лет вычислительная мощность, затрачиваемая на обучение нейросетей, выросла на шесть порядков, а LLM с триллионом параметров уже не являются чем-то необычным. Однако и инференс подобных моделей тоже является непростой задачей, к которой NVIDIA подходит комплексно, используя, по её же собственным словам, «многомерную оптимизацию».

Источник изображений: NVIDIA
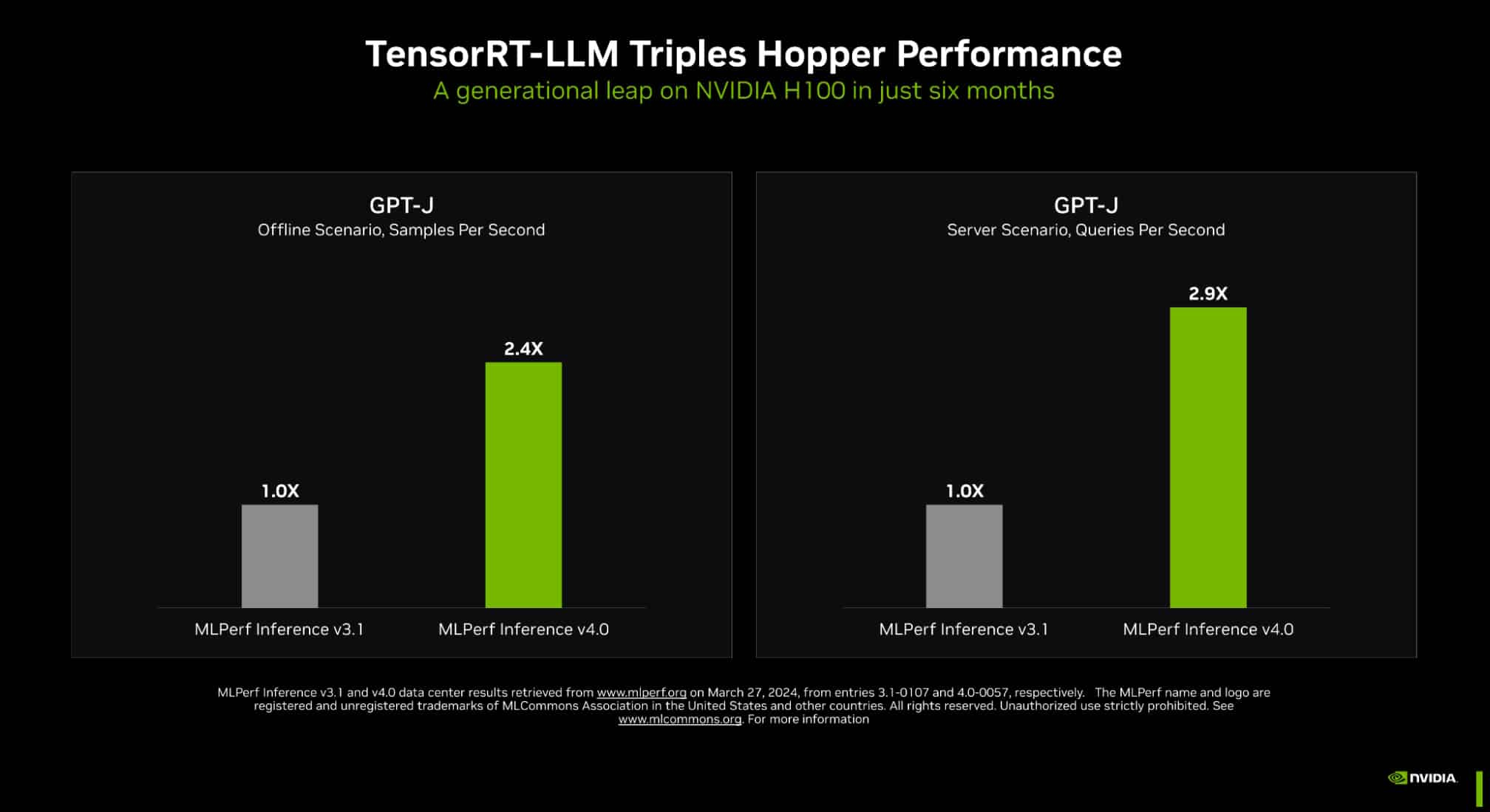
Одним из ключевых инструментов является TensorRT-LLM, включающий в себя компилятор и прочие средства разработки, учитывающие архитектуру ускорителей компании. Благодаря ему удалось почти втрое повысить производительность инференса GPT-J на ускорителях H100 всего за полгода. Такой прирост достигнут благодаря оптимизации очередей на лету (inflight sequence batching), применению страничного KV-кеша (paged KV cache), тензорному параллелизма (распределение весов по ускорителям), FP8-квантизации и использованию нового ядра XQA (XQA kernel).
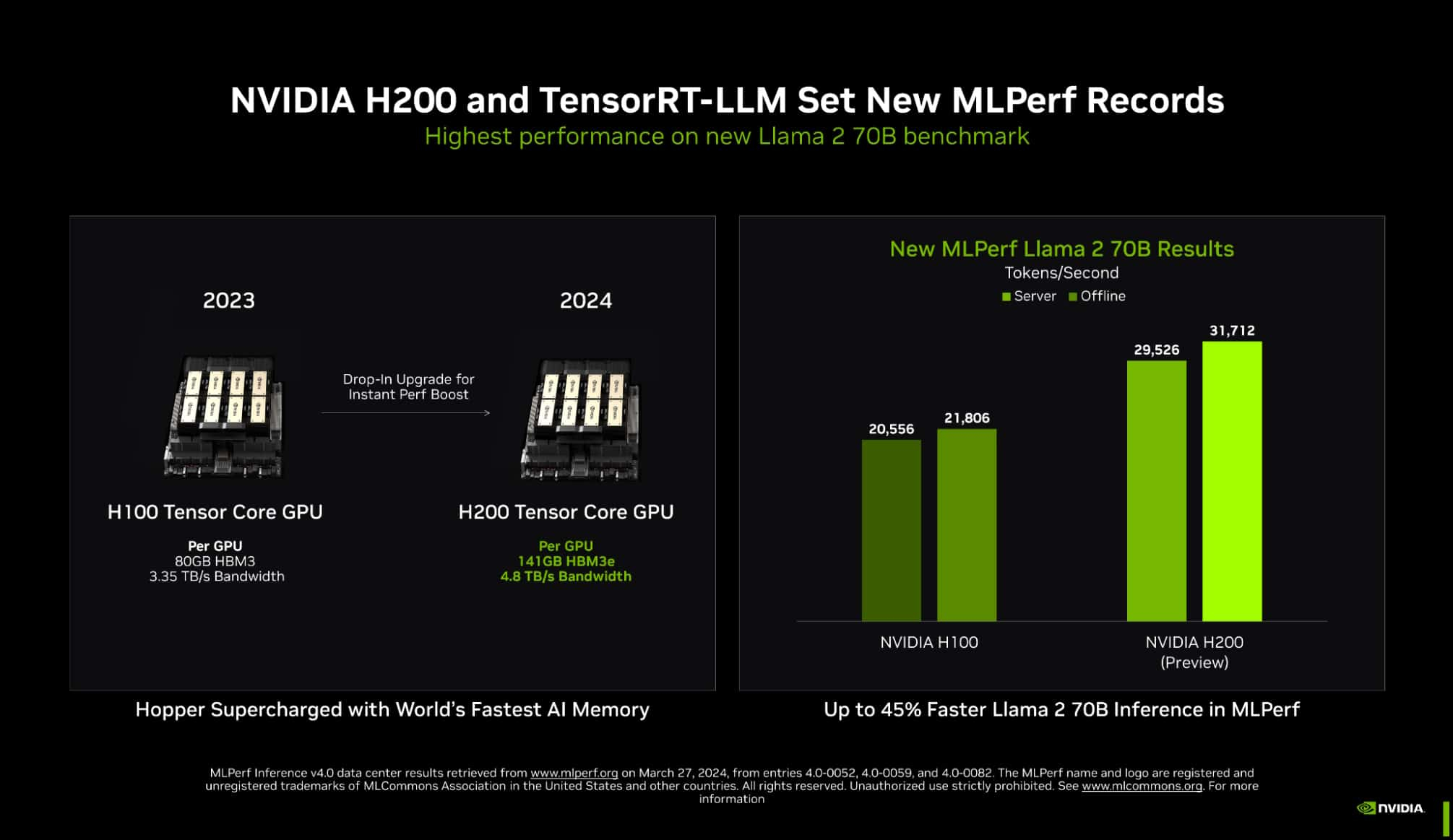
В случае ускорителей H200, использующих ту же архитектуру Hopper, что и H100, важную роль играет память: 141 Гбайт HBM3e (4,8 Тбайт/с) против 80 Гбайт HBM3 (3,35 Тбайт/с). Такой объём позволяет разместить модель уровня Llama 2 70B целиком в локальной памяти. В тесте MLPerf Llama 2 70B ускорители H200 на 28 % производительнее H100 при том же теплопакете 700 Вт, а увеличение теплопакета до 1000 Вт (так делают некоторые вендоры в своих MGX-платформах) даёт ещё 11–14 % прироста, а итоговая разница с H100 в этом тесте может доходить до 45 %.
В специальном разделе новой версии MLPerf NVIDIA продемонстрировала несколько любопытных техник дальнейшей оптимизации: «структурированную разреженность» (structured sparsity), позволяющую поднять производительность в тесте Llama 2 на 33 %, «обрезку» (pruning), упрощающую ИИ-модель и позволяющую повысить скорость инференса ещё на 40 %, а также DeepCache, упрощающую вычисления для Stable Diffusion XL и дающую до 74 % прироста производительности.
На сегодня платформа на базе модулей H200, по словам NVIDIA, является самой быстрой инференс-платформой среди доступных. Результатами GH200 компания похвасталась ещё в прошлом раунде, а вот показатели ускорителей Blackwell она не предоставила. Впрочем, не все считают результаты MLPerf показательными. Например, Groq принципиально не участвует в этом бенчмарке.
Источник:

