Корпорация Intel обнародовала результаты тестирования ускорителя Habana Gaudi2 в бенчмарке GPT-J (входит в MLPerf Inference v3.1), основанном на большой языковой модели (LLM) с 6 млрд параметров. Полученные данные говорят о том, что это изделие может стать альтернативой решению NVIDIA H100 на ИИ-рынке.
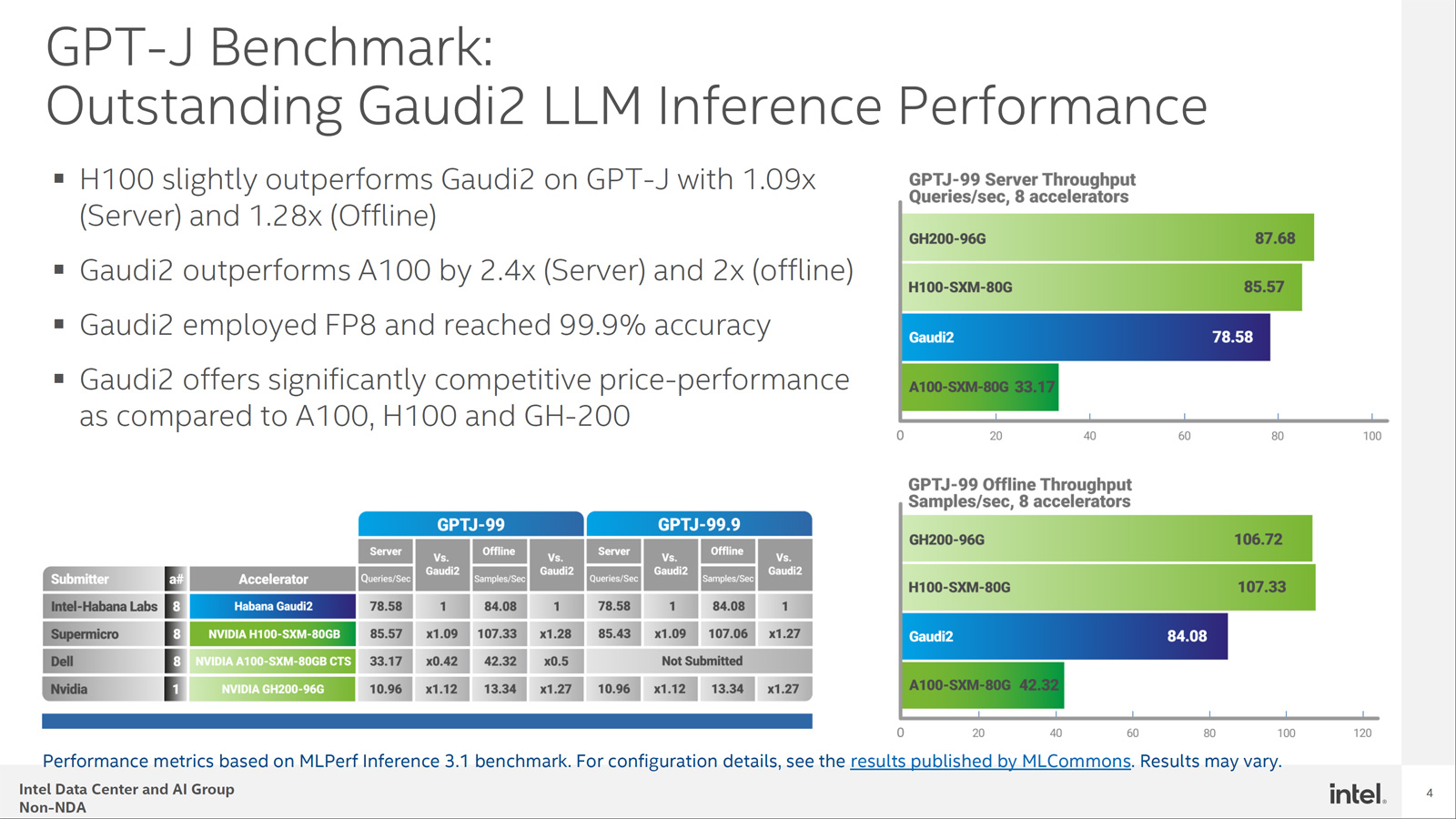
В частности, в тесте GPT-J ускоритель H100 демонстрирует сравнительно небольшое преимущество в плане производительности по сравнению с Gaudi2 — ×1,09 в серверном режиме и ×1,28 в оффлайн-режиме. При этом Gaudi2 превосходит ускоритель NVIDIA A100 в 2,4 раза в режиме server и в 2 раза в оффлайн-режиме.
Кроме того, решение Intel опережает H100 на моделях BridgeTower. Этот тест обучен на 4 млн изображений. Говорится, что точность Visual Question Answering (VQAv2) достигает 78,73 %. При масштабировании модель имеет ещё более высокую точность — 81,15 %, превосходя модели, обученные на гораздо более крупных наборах данных.
Источник изображений: Intel
Тест GPT-J говорит о конкурентоспособности Habana Gaudi2. При онлайн-обработке запросов этот ускоритель достигает производительности 78,58 выборки в секунду, а в автономном режиме — 84,08 выборки в секунду. Для сравнения: у NVIDIA H100 эти показатели равны соответственно 85,57 и 107,33 выборки в секунду.

В дальнейшем Intel планирует повышать производительность и расширять охват моделей в тестах MLPerf посредством регулярных обновлений программного обеспечения. Но Intel всё равно остаётся в догоняющих — NVIDIA подготовила открытый и бесплатный инструмент TensorRT-LLM, который не только вдвое ускоряет исполнение LLM на H100, но и даёт некоторый прирост производительности и на старых ускорителях.
Источник:

