Компания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.

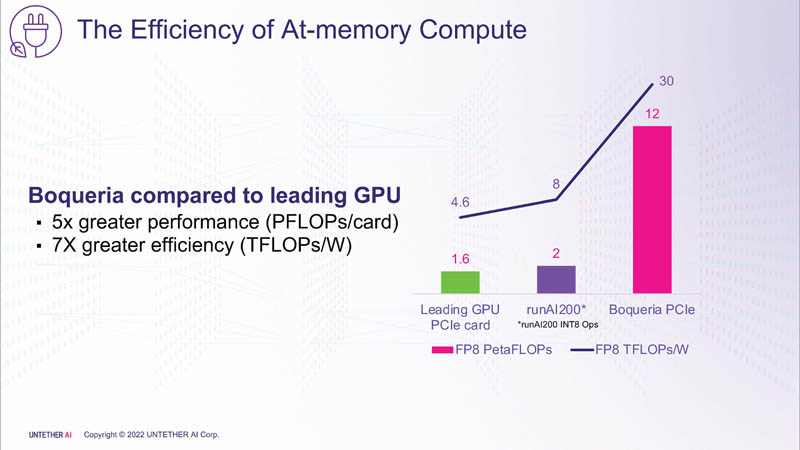
Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт.
.jpg)
Изображения: Untether AI (via ServeTheHome)
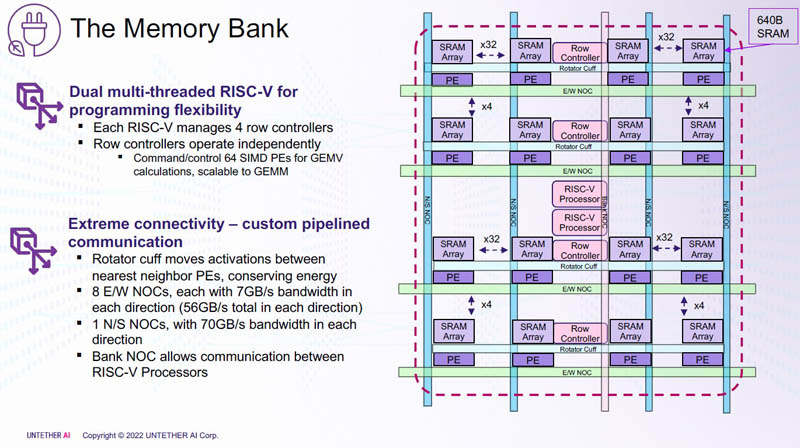
Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1.
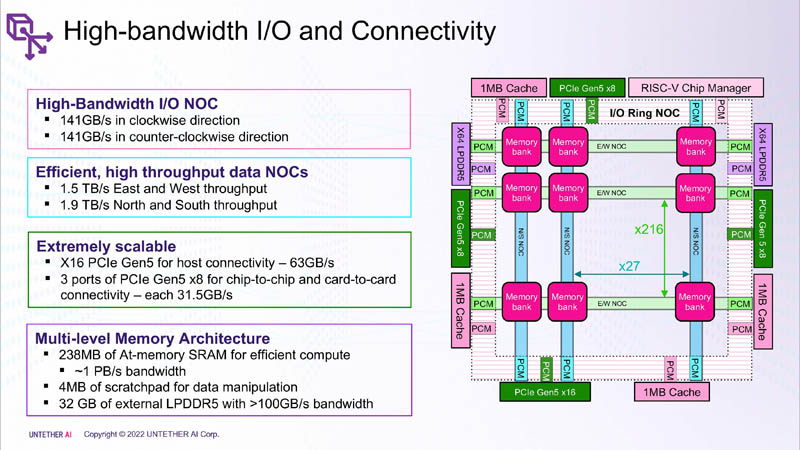
Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.

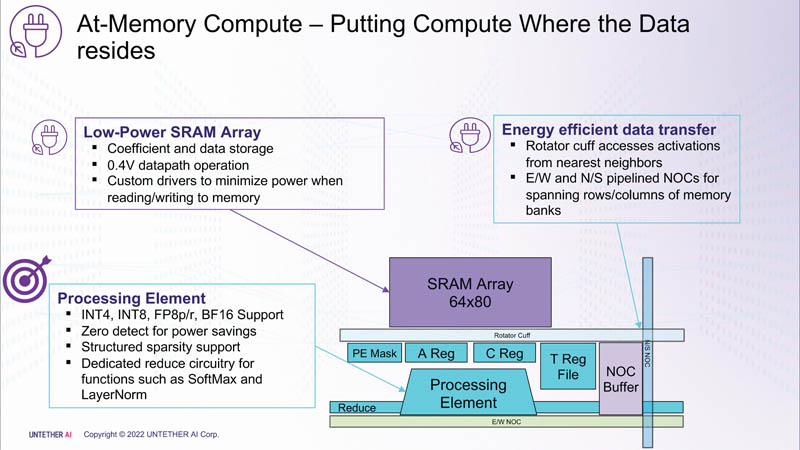
На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов.
Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года.
Источники:

