Материалы по тегу: дезагрегация
|
27.05.2024 [22:20], Алексей Степин
Тридцать на одного: Liqid UltraStack 30 позволяет подключить десятки GPU к одному серверуКомпания Liqid сотрудничает с Dell довольно давно — ещё в прошлом году она смогла добиться размещения 16 ускорителей в своей платформе UltraStack L40S. Но на этом компания не остановилась и представила новую композитную платформу UltraStack 30, в которой смогла довести число одновременно доступных хост-системе ускорителей до 30. Для подключения, конфигурации и управления ресурсами ускорителей Liqid использует комбинацию фирменного программного обеспечения Matrix CDI и интерконнекта Liqid Fabric. В основе последнего лежит PCI Express. Это позволяет динамически конфигурировать аппаратную инфраструктуру с учётом конкретных задач с её возвратом в общий пул ресурсов по завершению работы. Сами «капсулы» с ресурсами подключены к единственному хост-серверу, что упрощает задачу масштабирования, минимизирует потери производительности, повышает энергоэффективность и позволяет добиться наиболее плотной упаковки вычислительных ресурсов, нежели это возможно в классическом варианте с раздельными серверами. А благодаря гибкости конфигурирования буквально «на лету» исключается простой весьма дорогостоящих аппаратных ресурсов. 
Источник здесь и далее: Liqid В случае UltraStack 30 основой по умолчанию является сервер серии Dell PowerEdge R760 с двумя Xeon Gold 6430 и 1 Тбайт оперативной памяти, однако доступен также вариант на базе Dell R7625, оснащённый процессорами AMD EPYC 9354. Опционально можно укомплектовать систему NVMe-хранилищем объёмом 30 Тбайт, в качестве сетевых опций доступны либо пара адаптеров NVIDIA ConnectX-7, либо один DPU NVIDIA Bluefield-3.  За общение с ускорительными модулями отвечает 48-портовой коммутатор PCI Express 4.0 вкупе с фирменными хост-адаптерами Liqid. Технология ioDirect позволяет ускорителям общаться друг с другом и хранилищем данных напрямую, без посредничества CPU. В трёх модулях расширения установлено по 10 ускорителей NVIDIA L40S, каждый несет на борту 48 Гбайт памяти GDDR6. Такая конфигурация теоретически способна развить 7,3 Пфлопс на вычислениях FP16, вдвое больше на FP8, и почти 1,1 Пфлопс на тензорных ядрах в формате TF32. 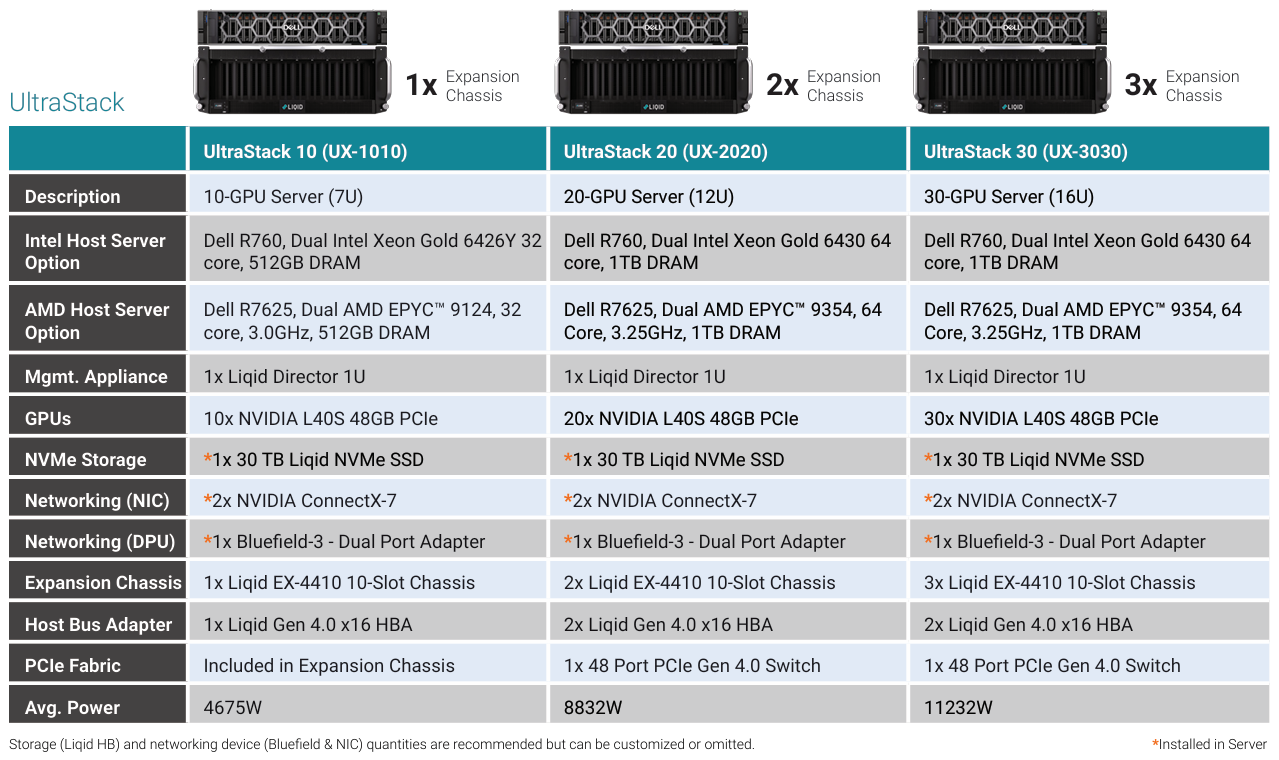 Платформа UltraStack 30 предназначена в первую очередь для быстрого развёртывания достаточно мощной ИИ-инфраструктуры там, где требуется тонкая подстройка и дообучение уже «натасканных» больших моделей. При этом стоит учитывать довольно солидное энергопотребление, составляющее более 11 кВт. Также в арсенале компании есть решения SmartStack на базе модульных систем Dell PowerEdge C-Series, позволяющие подключать к каждому из лезвийных модулей MX760c, MX750с и MX740c до 20 ускорителей. Модульные решения Liqid поддерживают также ускорители других производителей, включая достаточно экзотические, такие как Groq.
10.05.2024 [11:32], Сергей Карасёв
Суперкомпьютер в стойке GigaIO SuperNODE обзавёлся поддержкой AMD Instinct MI300XКомпания GigaIO анонсировала новую модификацию системы SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Суперкомпьютер в стойке теперь может комплектоваться ускорителями AMD Instinct MI300X, благодаря чему значительно повышается производительность при работе с большими языковыми моделями (LLM). Решение SuperNODE, напомним, использует фирменную архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE даёт возможность более эффективно использовать ресурсы. Изначально для SuperNODE предлагались конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100. Новая версия допускает использование 32 изделий Instinct MI300X. Утверждается, что архитектура FabreX в сочетании с технологией интерконнекта AMD Infinity Fabric наделяет систему SuperNODE «лучшими в отрасли» возможностями в плане задержек при передаче данных, пропускной способности и управления перегрузками. Это позволяет эффективно справляться с обучением LLM с большим количеством параметров. 
Источник изображения: GigaIO Отмечается, что SuperNODE значительно упрощает процесс развёртывания и управления инфраструктурой ИИ. Традиционные конфигурации обычно включают в себя сложную сеть и необходимость синхронизации нескольких серверов, что создаёт определённые технических сложности и приводит к дополнительным временным затратам. Конструкция SuperNODE с 32 мощными ускорителями в рамках одной системы позволяет решить указанные проблемы.
11.11.2023 [23:59], Алексей Степин
СуперДупер: GigaIO SuperDuperNODE позволяет объединить посредством PCIe сразу 64 ускорителяКомпания GigaIO, чьей главной разработкой является система распределённого интерконнекта на базе PCI Express под названием FabreX, поставила новый рекорд — в новой платформе разработчикам удалось удвоить количество одновременно подключаемых PCIe-устройств, увеличив его с 32 до 64. О разработках GigaIO мы рассказывали читателям неоднократно. Во многом они действительно уникальны, поскольку созданная компанией композитная инфраструктура позволяет подключать к одному или нескольким серверам существенно больше различных ускорителей, нежели это возможно в классическом варианте, но при этом сохраняет высокий уровень утилизации этих ускорителей. 
GigaIO SuperNODE. Источник изображений здесь и далее: GigaIO В начале года компания уже демонстрировала систему с 16 ускорителями NVIDIA A100, а летом GigaIO представила мини-кластер SuperNODE. В различных конфигурациях система могла содержать 32 ускорителя AMD Instinct MI210 или 24 ускорителя NVIDIA A100, дополненных СХД ёмкостью 1 Пбайт. При этом система в силу особенностей FabreX не требовала какой-либо специфической настройки перед работой. 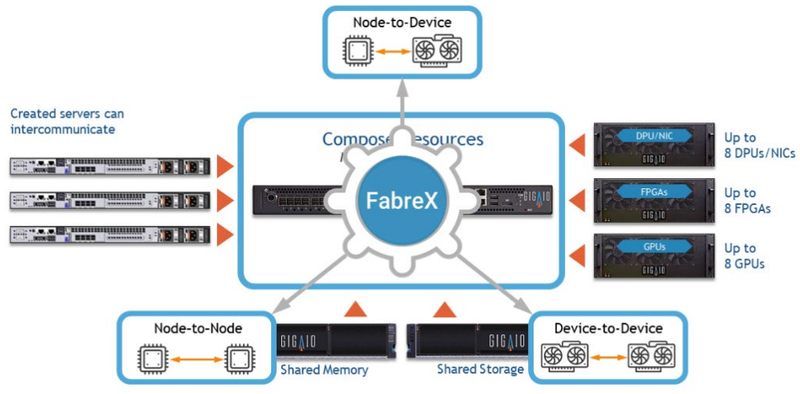
FabreX позволяет физически объединить все типы ресурсов на базе существующего стека технологий PCI Express На этой неделе GigaIO анонсировала новый вариант своей HPC-системы, получившей незамысловатое название SuperDuperNODE. В ней она смогла удвоить количество ускорителей с 32 до 64. Как и прежде, система предназначена, в первую очередь, для использования в сценариях генеративного ИИ, но также интересна она и с точки зрения ряда HPC-задач, в частности, вычислительной гидродинамики (CFD). Система SuperNODE смогла завершить самую сложную в мире CFD-симуляцию всего за 33 часа. В ней имитировался полёт 62-метрового авиалайнера Конкорд. Хотя протяжённость модели составляет всего 1 сек, она очень сложна, поскольку требуется обсчёт поведения 40 млрд ячеек объёмом 12,4 мм3 на протяжении 67268 временных отрезков. 29 часов у системы ушло на обсчёт полёта, и ещё 4 часа было затрачено на рендеринг 3000 4К-изображений. С учётом отличной масштабируемости при использовании SuperDuperNODE время расчёта удалось сократить практически вдвое. Как уже упоминалось, FabreX позволяет малой кровью наращивать число ускорителей и иных мощных PCIe-устройств на процессорный узел при практически идеальном масштабировании. Обновлённая платформа не подвела и в этот раз: в тесте HPL-MxP пиковый показатель утилизации составил 99,7 % от теоретического максимума, а в тестах HPL и HPCG — 95,2 % и 88 % соответственно. Компания-разработчик сообщает о том, что программное обеспечение FabreX обрело завершённый вид и без каких-либо проблем обеспечивает переключение режимов SuperNODE между Beast (система видна как один большой узел), Swarm (множество узлов для множества нагрузок) и Freestyle Mode (каждой нагрузке выделен свой узел с заданным количеством ускорителей). Начало поставок SuperDuperNODE запланировано на конец года. Партнёрами, как и в случае с SuperNODE, выступят Dell и Supermicro.
18.07.2023 [22:45], Сергей Карасёв
Суперкомпьютер в стойке: GigaIO SuperNODE позволяет объединить 32 ускорителя AMD Instinct MI210Компания GigaIO анонсировала HPC-систему SuperNODE, предназначенную для решения ресурсоёмких задач в области генеративного ИИ. SuperNODE позволяет связать воедино до 32 ускорителей посредством компонуемой платформы GigaIO FabreX. Архитектура FabreX на базе PCI Express, по словам создателей, намного лучше InfiniBand и NVIDIA NVLink по уровню задержки и позволяет объединять различные компоненты — GPU, FPGA, пулы памяти и пр. SuperNODE даёт возможность более эффективно использовать ресурсы, нежели в случае традиционного подхода с ускорителями в составе нескольких серверов. В частности для SuperNODE доступны конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100 с хранилищем ёмкостью до 1 Пбайт. При этом платформа компактна, энергоэффективна (до 7 кВт) и не требует дополнительной настройки перед работой. 
Источник изображений: GigaIO Поскольку приложения с большими языковыми моделями требуют огромных вычислительных мощностей, технологии, которые сокращают количество необходимых обменов данными между узлом и ускорителем, имеют решающее значение для обеспечения необходимой скорости выполнения операций при снижении общих затрат на формирование инфраструктуры. Что немаловажно, платформ, по словам разработчиков, демонстрирует хорошую масштабируемость производительности при увеличении числа ускорителей. 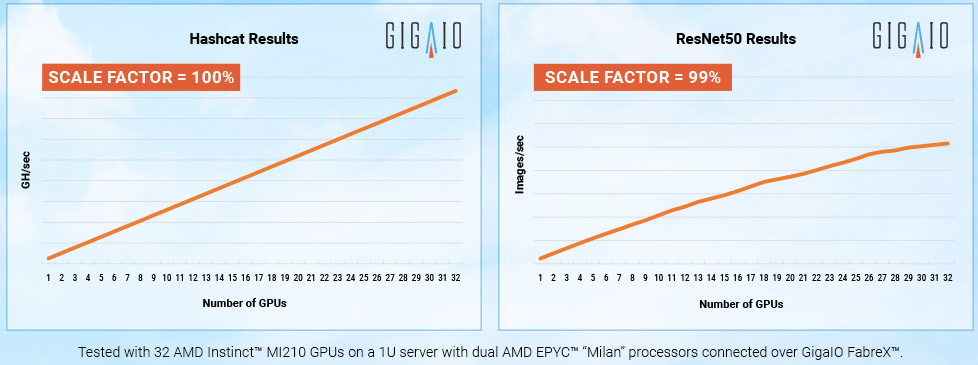 «Система SuperNODE, созданная GigaIO и работающая на ускорителях AMD Instinct, обеспечивает привлекательную совокупную стоимость владения как для традиционных рабочих нагрузок HPC, так и для задач генеративного ИИ», — сказал Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер по дата-центрам AMD. Стоит отметить, что у AMD нет прямого аналога NVIDIA NVLink, так что для объединение ускорителей в большие пулы с высокой скоростью подключения возможно как раз с использованием SuperNODE.
02.08.2022 [16:00], Алексей Степин
Опубликованы спецификации Compute Express Link 3.0Мало-помалу стандарт Compute Express Link пробивает себе путь на рынок: хотя процессоров с поддержкой ещё нет, многие из элементов инфраструктуры для нового интерконнекта и базирующихся на нём концепций уже готово — в частности, регулярно демонстрируются новые контроллеры и модули памяти. Но развивается и сам стандарт. В версии 1.1, спецификации на которую были опубликованы ещё в 2019 году, были только заложены основы. Но уже в версии 2.0 CXL получил массу нововведений, позволяющих говорить не просто о новой шине, но о целой концепции и смене подхода к архитектуре серверов. А сейчас консорциум, ответственный за разработку стандарта, опубликовал свежие спецификации версии 3.0, ещё более расширяющие возможности CXL. 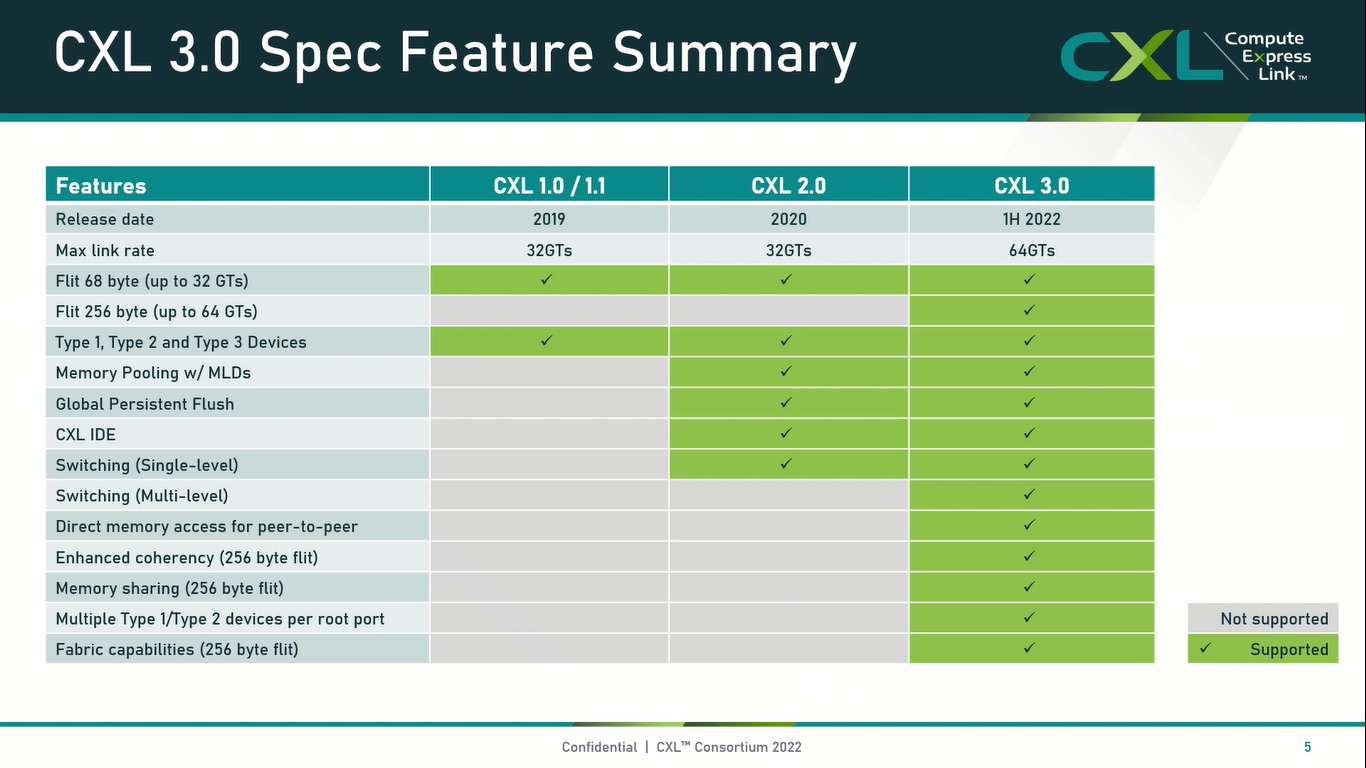
Источник: CXL Consortium И не только расширяющие: в версии 3.0 новый стандарт получил поддержку скорости 64 ГТ/с, при этом без повышения задержки. Что неудивительно, поскольку в основе лежит стандарт PCIe 6.0. Но основные усилия разработчиков были сконцентрированы на дальнейшем развитии идей дезагрегации ресурсов и создания компонуемой инфраструктуры. 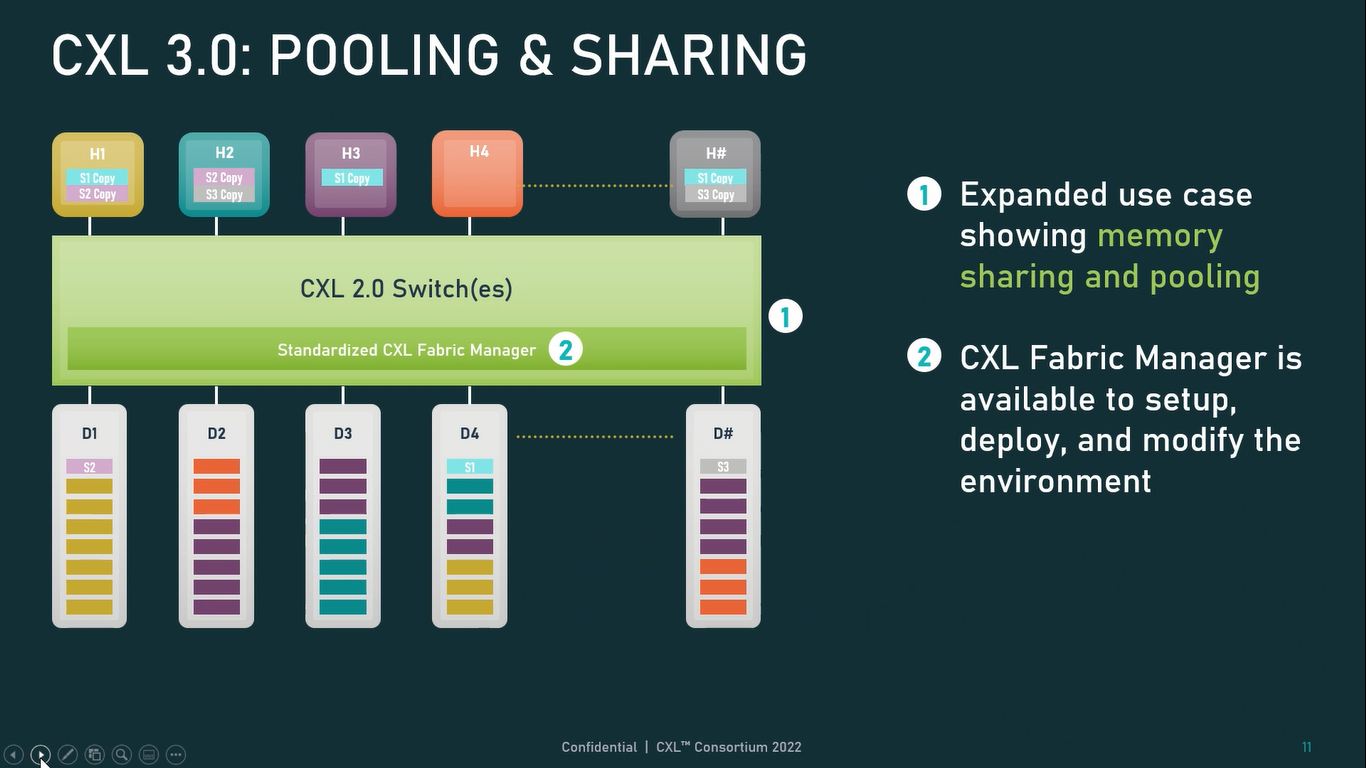 Сама фабрика CXL 3.0 теперь допускает создание и подключение «многоголовых» (multi-headed) устройств, расширены возможности по управлению фабрикой, улучшена поддержка пулов памяти, введены продвинутые режимы когерентности, а также появилась поддержка многоуровневой коммутации. При этом CXL 3.0 сохранил обратную совместимость со всеми предыдущими версиями — 2.0, 1.1 и даже 1.0. В этом случае часть имеющихся функций попросту не будет активирована. 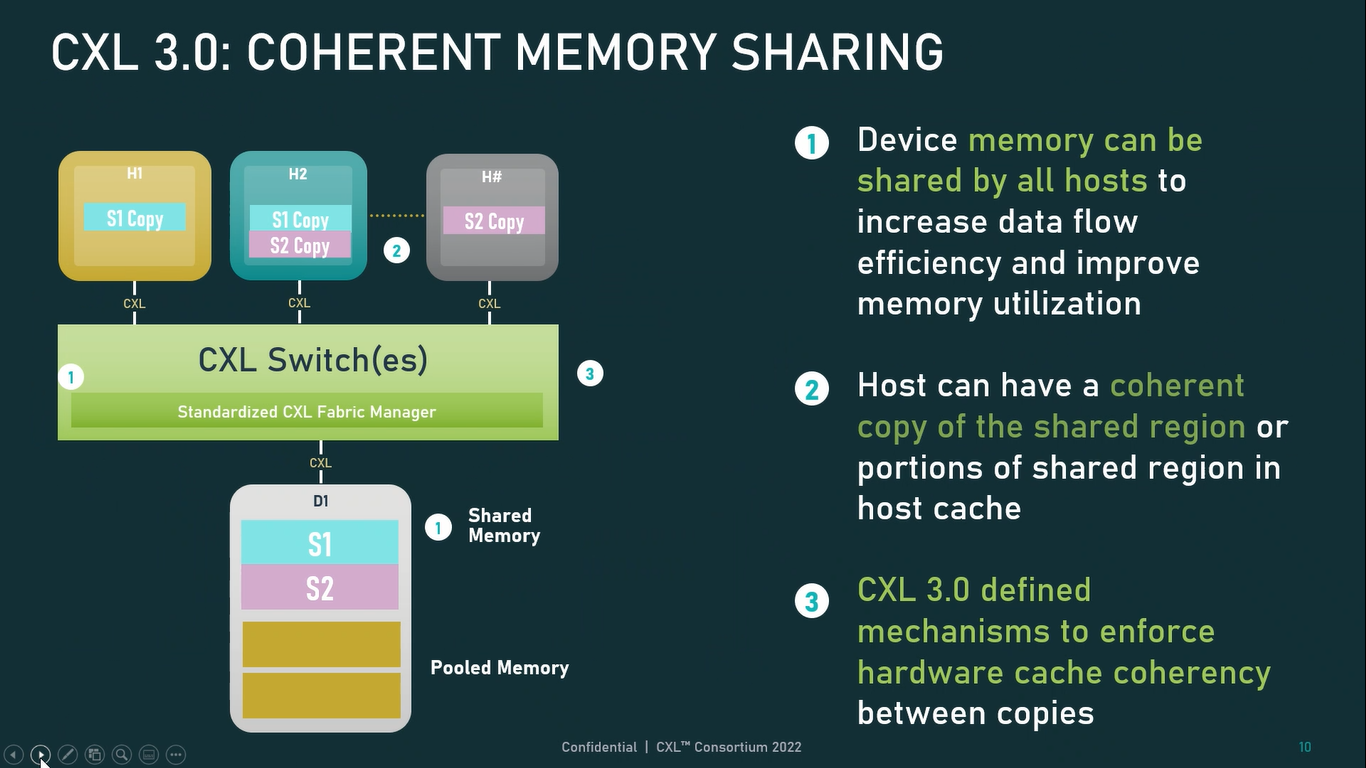 Одно из ключевых новшеств — многоуровневая коммутация. Теперь топология фабрики CXL 3.0 может быть практически любой, от линейной до каскадной с группами коммутаторов, подключенных к коммутаторам более высокого уровня. При этом каждый корневой порт процессора поддерживает одновременное подключение через коммутатор устройств различных типов в любой комбинации.  Ещё одним интересным нововведением стала поддержка прямого доступа к памяти типа peer-to-peer (P2P). Проще говоря, несколько ускорителей, расположенных, к примеру, в соседних стойках, смогут напрямую общаться друг с другом, не затрагивая хост-процессоры. Во всех случаях обеспечивается защита доступа и безопасность коммуникаций. Кроме того, есть возможность разделить память каждого устройства на 16 независимых сегментов.  При этом поддерживается иерархическая организация групп, внутри которых обеспечивается когерентность содержимого памяти и кешей (предусмотрена инвалидация). Теперь помимо эксклюзивного доступа к памяти из пула доступен и общий доступ сразу нескольких хостов к одному блоку памяти, причём с аппаратной поддержкой когерентности. Организация пулов теперь не отдаётся на откуп стороннему ПО, а осуществляется посредством стандартизированного менеджера фабрики.  Сочетание новых возможностей выводит идею разделения памяти и вычислительных ресурсов на новый уровень: теперь возможно построение систем, где единый пул подключенной к фабрике CXL 3.0 памяти (Global Fabric Attached Memory, GFAM) действительно существует отдельно от вычислительных модулей. При этом возможность адресовать до 4096 точек подключения скорее упрётся в физические лимиты фабрики. 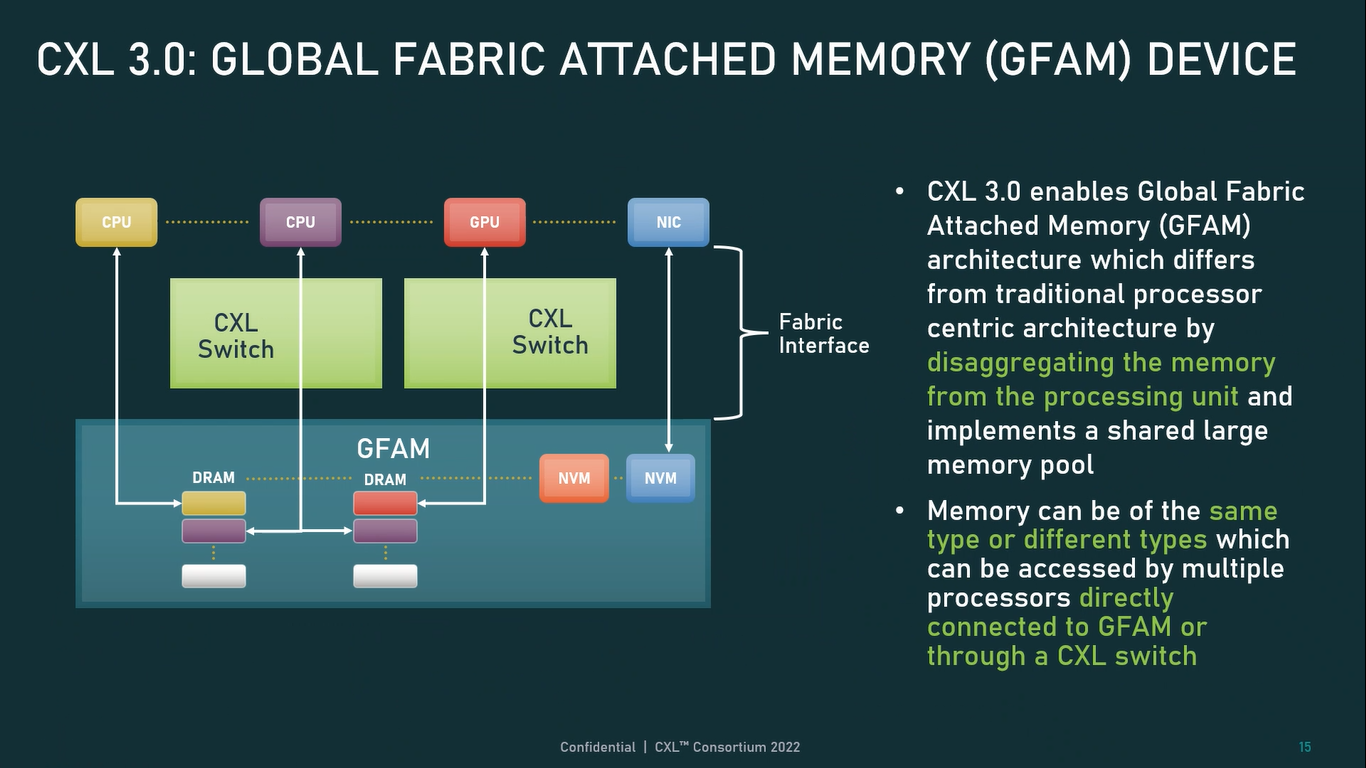 Пул может содержать разные типы памяти — DRAM, NAND, SCM — и подключаться к вычислительным мощностями как напрямую, так и через коммутаторы CXL. Предусмотрен механизм сообщения самими устройствами об их типе, возможностях и прочих характеристиках. Подобная архитектура обещает стать востребованной в мире машинного обучения, в котором наборы данных для нейросетей нового поколения достигают уже поистине гигантских размеров. 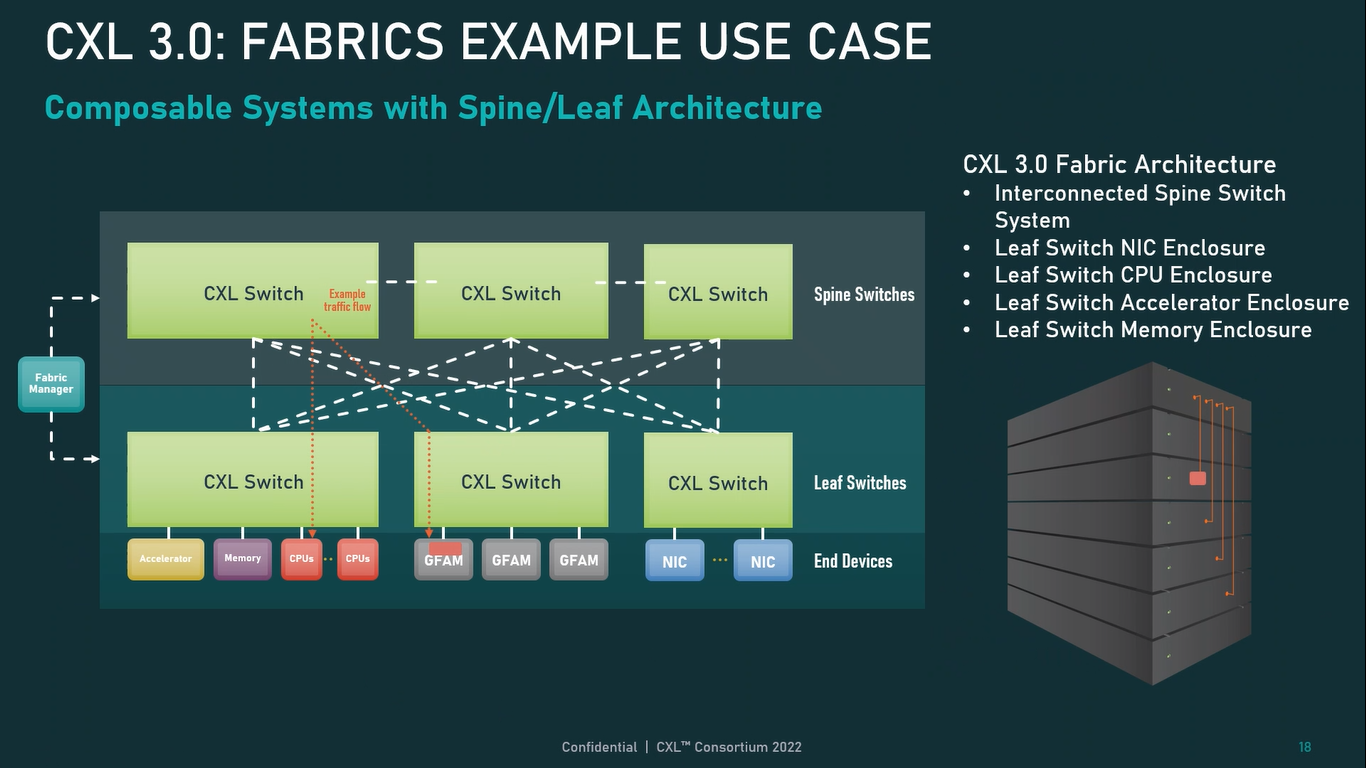 В настоящее время группа CXL уже включает 206 участников, в число которых входят компании Intel, Arm, AMD, IBM, NVIDIA, Huawei, крупные облачные провайдеры, включая Microsoft, Alibaba Group, Google и Meta✴, а также ряд крупных производителей серверного оборудования, в том числе, HPE и Dell EMC. |
|

