Материалы по тегу: huawei
|
05.06.2020 [23:23], Алексей Степин
Предложение Huawei отказаться от TCP/IP восторгов не вызвалоСтеку TCP/IP, благодаря которому существует всемирная сеть, уже не один десяток лет. DARPA начало исследования по этой теме ещё в конце 60-х, и не все согласны с тем, что данная технология продолжает отвечать требованиям времени: Huawei предложила Международному союзу электросвязи (ITU) план по отказу от TCP/IP и переходу на более современное и безопасное, по её мнению, решение New IP. Определённый резон в этом есть: современные сети чрезвычайно сложны, они базируются на весьма разнообразном оборудовании, и что такое «кибервойна» сегодня, пожалуй, знают все, кто хоть сколько-то интересуется тематикой информационных технологий. Достаточно хотя бы сделать на нашем сайте поиск по слову «уязвимость» — и становится понятным, что понятия «интернет» и «безопасность» сегодня сочетаются не очень хорошо. 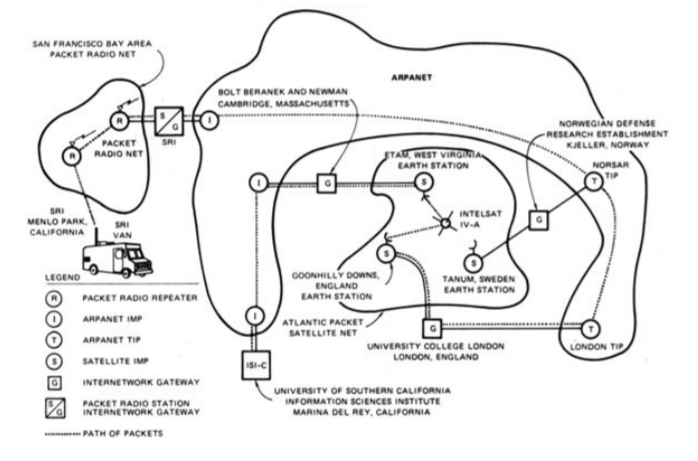
Демонстрация TCP/IP, объединяющая сети ARPANET, PRNET и SATNET. 1977 год Корпорация Huawei выступила в ITU с предложением отказаться от стека TCP/IP и перейти на использование более гибких и безопасных технологий. Понять позицию китайской компании можно: она находится в состоянии «войны» с США и желание продвинуть собственные технологии для нее совершенно естественно. Позиции, предлагаемые Huawei, выглядят довольно привлекательно:
Технических деталей, к сожалению, в публичном доступе пока нет. Реакция на предложение Huawei оказалась достаточно негативной: оно было охарактеризовано, как попытка внедрения централизации и «тоталитарных» методов. В частности, предложенный механизм отсечения частей сети можно использовать не только для защиты от DDoS-атак. Сама Huawei обвинения в «тоталитаризме» отвергла, заявив, что не связывает технологию с политикой. Еврокомиссия опубликовала свой ответ: в нём говорится, что за время своего существования модель TCP/IP доказала свою жизнеспособность, продемонстрировав нужную степень отказоустойчивости и масштабируемости. Аналогичной точки зрения придерживается Cisco, считая TCP/IP достаточно гибкой технологией, чтобы отвечать вызовам времени. 
О дивный, новый Интернет! Нужда в усовершенствовании сетевых технологий существует, но это следует делать в рамках существующих стандартов. Евросоюз планирует защищать «видение единого, открытого, нейтрального, свободного и нефрагментированного интернета». («the vision of a single, open, neutral, free and unfragmented internet»). Тем не менее, война технологий, скорее всего, в ближайшее время продолжится. Предсказать исход пока не представляется возможным, но Huawei явно не собирается сдаваться просто так и будет продвигать инициативу New IP далее.
27.08.2019 [11:00], Геннадий Детинич
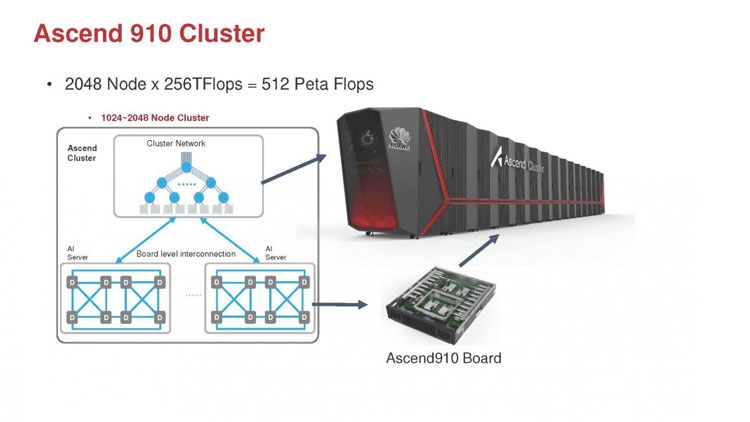
Huawei Ascend 910: китайская альтернатива ИИ-платформам NVIDIAГлубокое машинное обучение ― это сравнительно новая область приложения для вычислительных архитектур. Как всё новое, ML заставляет искать альтернативные пути решения задач. В этом поиске китайские разработчики оказались на равных и даже в привилегированных условиях, что привело к появлению в Китае мощнейших ИИ-платформ. Как всем уже известно, на конференции Hot Chips 31 компания Huawei представила самый мощный в мире ИИ-процессор Ascend 910. Процессоры для ИИ каждый разрабатывает во что горазд, но все разработчики сравнивают свои творения с ИИ-процессорами компании NVIDIA (а NVIDIA с процессорами Intel Xeon). Такова участь пионера. NVIDIA одной из первых широко начала продвигать свои модифицированные графические архитектуры в качестве ускорителей для решения задач с машинным обучением.  Гибкость GPU звездой взошла над косностью x86-совместимой архитектуры, но во время появления новых подходов и методов тренировки машинного обучения, где пока много открытых дорожек, она рискует стать одной из немногих. Компания Huawei со своими платформами вполне способна стать лучшей альтернативой решениям NVIDIA. Как минимум, это произойдёт в Китае, где Huawei готовится выпускать и надеется найти сбыт для миллионов процессоров для машинного обучения. 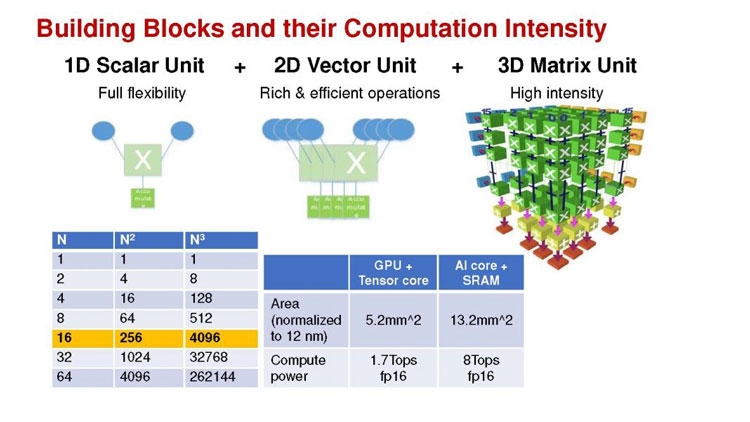 Мы уже публиковали анонс наиболее мощного ускорителя для ML чипа Huawei Ascend 910. Сейчас посмотрим на это решение чуть пристальнее. Итак, Ascend 910 выпускается компанией TSMC с использованием второго поколения 7-нм техпроцесса (7+ EUV). Это техпроцесс характеризуется использованием сканеров EUV для изготовления нескольких слоёв чипа. На конференции Huawei сравнивала Ascend 910 с ИИ-решением NVIDIA на архитектуре Volta, выпущенном TSMC с использованием 12-нм FinFET техпроцесса. Выше на картинке приводятся данные для Ascend 910 и Volta, с нормализацией к 12-нм техпроцессу. Площадь решения Huawei на кристалле в 2,5 раза больше, чем у NVIDIA, но при этом производительность Ascend 910 оказывается в 4,7 раза выше, чем у архитектуры Volta. 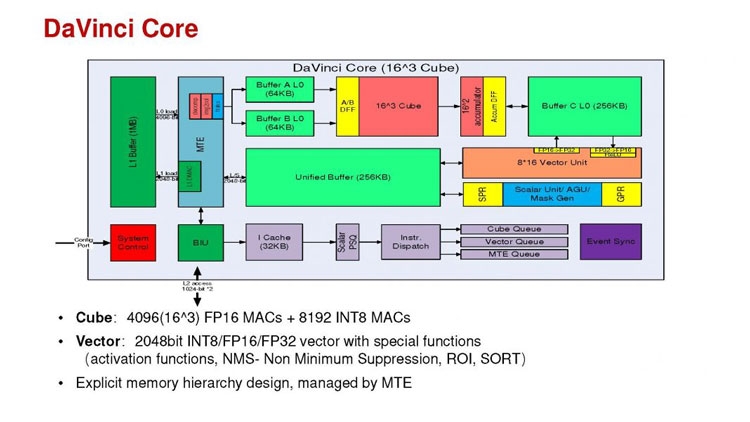 Также на схеме видно, что Huawei заявляет о крайне высокой масштабируемости архитектуры. Ядра DaVinci, лежащие в основе Ascend 910, могут выпускаться в конфигурации для оперирования скалярными величинами (16), векторными (16 × 16) и матричными (16 × 16 × 16). Это означает, что архитектура и ядра DaVinci появятся во всём спектре устройств от IoT и носимой электроники до суперкомпьютеров (от платформ с принятием решений до машинного обучения). Чип Ascend 910 несёт матричные ядра, как предназначенный для наиболее интенсивной работы. 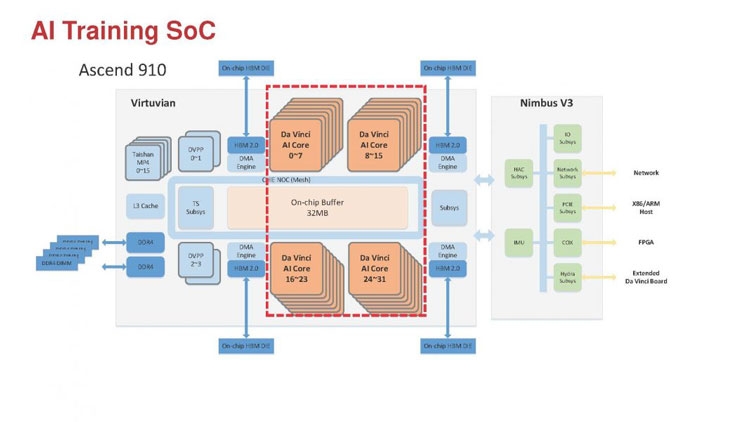 Ядро DaVinci в максимальной конфигурации (для Ascend 910) содержит 4096 блоков Cube для вычислений с половинной точностью (FP16). Также в ядро входят специализированные блоки для обработки скалярных (INT8) и векторных величин. Пиковая производительность Ascend с 32 ядрами DaVinci достигает 256 терафлопс для FP16 и 512 терафлопс для целочисленных значений. Всё это при потреблении до 350 Вт. Альтернатива от NVIDIA на тензорных ядрах способна максимум на 125 терафлопс для FP16. Для решения задач ML чип Huawei оказывается в два раза производительнее. 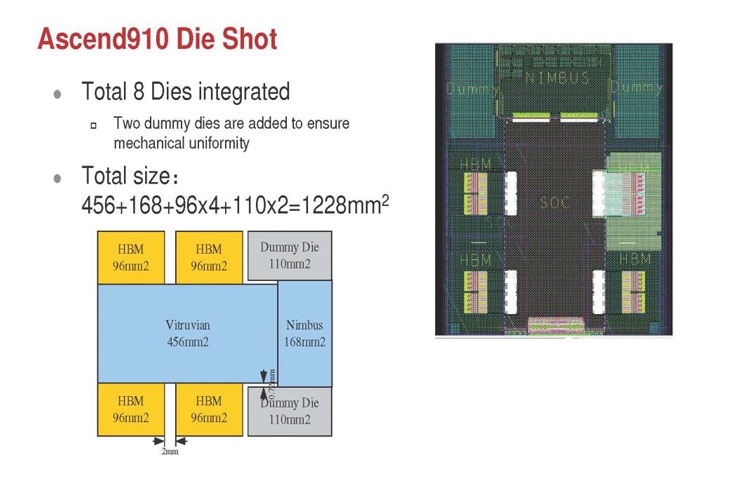 Помимо ядер DaVinci на кристалле Ascend 910 находятся несколько других блоков, включая контроллер памяти HBM2, 128-канальный движок для декодирования видеопотоков. Мощный чип для операций ввода/вывода Nimbus V3 выполнен на отдельном кристалле на той же подложке. Рядом с ним для механической прочности всей конструкции пришлось расположить два кристалла-заглушки, каждый из которых имеет площадь 110 мм2. С учётом болванок и четырёх чипов HBM2 площадь всех кристаллов достигает 1228 мм2. 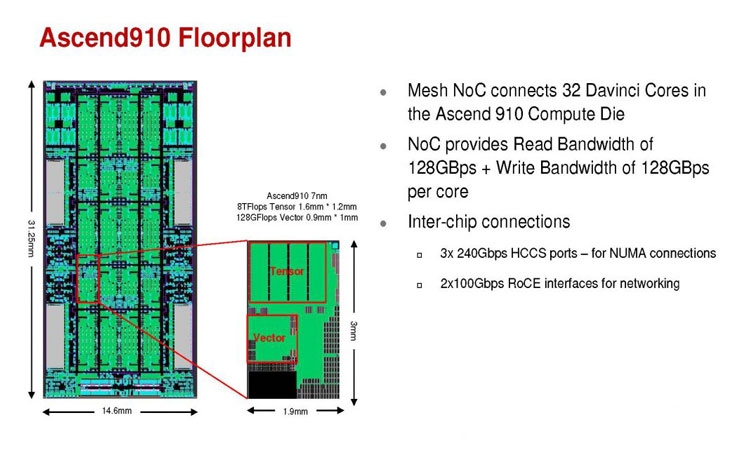 Для связи ядер и памяти на кристалле создана ячеистая сеть в конфигурации 6 строк на 4 колонки со скоростью доступа 128 Гбайт/с на каждое ядро для одновременных операций записи и чтения. Для соединения с соседними чипами предусмотрена шина со скоростью 720 Гбит/с и два линка RoCE со скоростью 100 Гбит/с. К кеш-памяти L2 ядра могут обращаться с производительностью до 4 Тбайт/с. Скорость доступа к памяти HBM2 достигает 1,2 Тбайт/с.  В каждый полочный корпус входят по 8 процессоров Ascend 910 и блок с двумя процессорами Intel Xeon Scalable. Спецификации полки ниже на картинке. Решения собираются в кластер из 2048 узлов суммарной производительностью 512 петафлопс для операций FP16. Кластеры NVIDIA DGX Superpod обещают производительность до 9,4 петафлопс для сборки из 96 узлов. В сравнении с предложением Huawei это выглядит бледно, но создаёт стимул рваться вперёд. 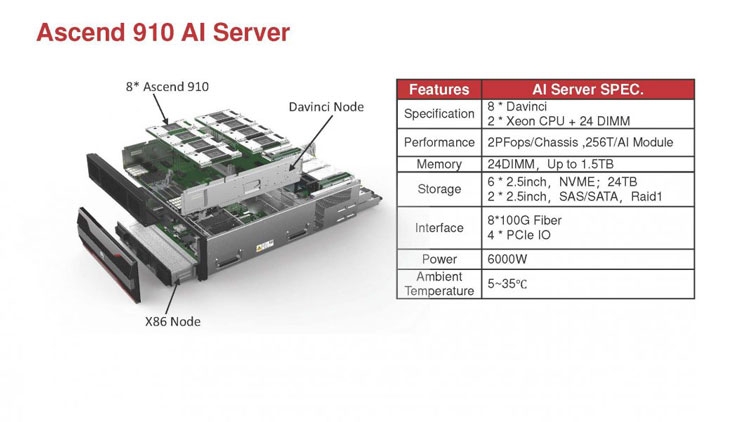
 |
|

