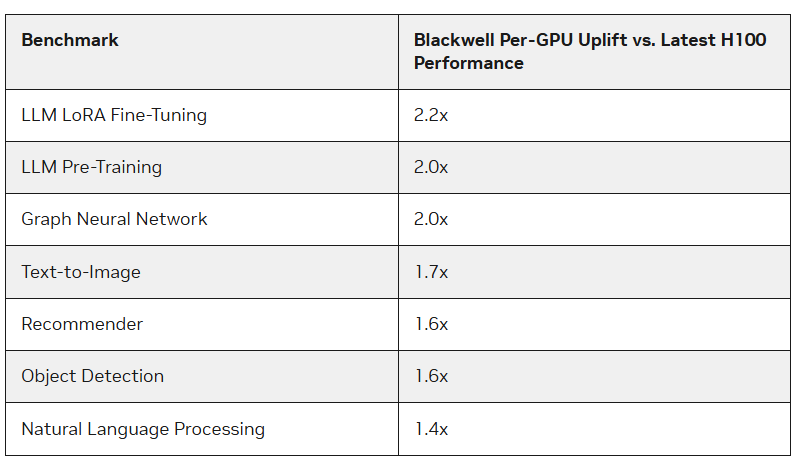
Ускорители Blackwell компании NVIDIA опередили в бенчмарках MLPerf Training 4.1 чипы H100 более чем в 2,2 раза, сообщил The Register. По словам NVIDIA, более высокая пропускная способность памяти в Blackwell также сыграла свою роль. Тесты были проведены с использование собственного суперкомпьютера NVIDIA Nyx на базе DGX B200.
Новые ускорители имеют примерно в 2,27 раза более высокую пиковую производительность в вычисления FP8, FP16, BF16 и TF32, чем системы H100 последнего поколения. B200 показал в 2,2 раза более высокую производительность при тюнинге модели Llama 2 70B и в два раза большую производительность при предварительном обучении (Pre-training) модели GPT-3 175B. Для рекомендательных систем и генерации изображений прирост составил 64 % и 62 % соответственно.
Компания также отметила преимущества используемой в B200 памяти HBM3e, благодаря которой бенчмарк GPT-3 успешно отработал всего на 64 ускорителях Blackwell без ущерба для производительности каждого GPU, тогда как для достижения такого же результата понадобилось бы 256 ускорителей H100. Впрочем, про Hopper компания тоже не забывает — в новом раунде компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100.

Источник изображений: NVIDIA
Компания отметила, что платформа NVIDIA Blackwell обеспечивает значительный скачок производительности по сравнению с платформой Hopper, особенно при работе с LLM. В то же время чипы поколения Hopper по-прежнему остаются актуальными благодаря непрерывным оптимизациям ПО, порой кратно повышающим производительность в некоторых задач. Интрига в том, что в этот раз NVIDIA решила не показывать результаты GB200, хотя такие системы есть и у неё, и у партнёров.
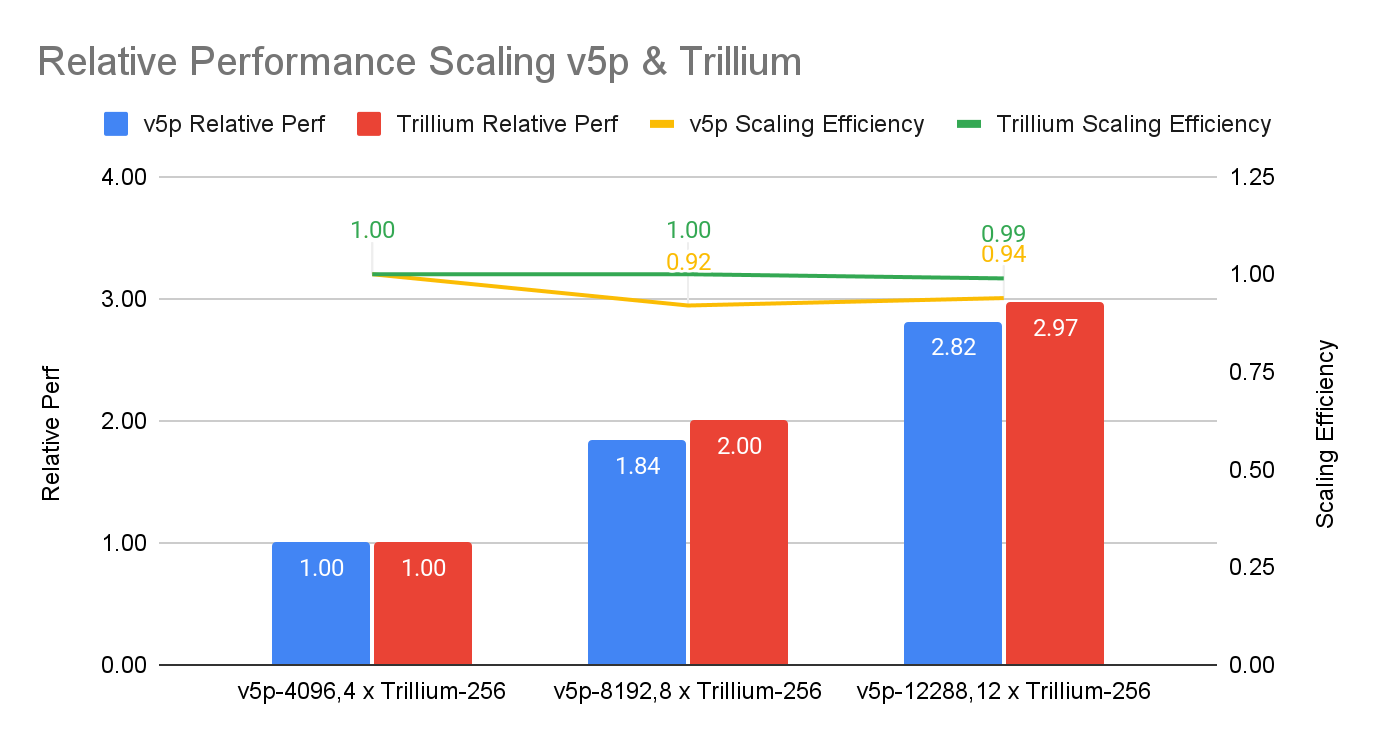
В свою очередь, Google представила первые результаты тестирования 6-го поколения TPU под названием Trillium, о доступности которого было объявлено в прошлом месяце, и второй раунд результатов ускорителей 5-го поколения TPU v5p. Ранее Google тестировала только TPU v5e. По сравнению с последним вариантом, Trillium обеспечивает прирост производительности в 3,8 раза в задаче обучения GPT-3, отмечает IEEE Spectrum.

Если же сравнивать результаты с показателями NVIDIA, то всё выглядит не так оптимистично. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 мин, отстав от системы с 11 616 H100, которая выполнила задачу примерно за 3,44 мин. При одинаковом же количестве ускорителей решения Google почти вдвое отстают от решений NVIDIA, а разница между v5p и v6e составляет менее 10 %.
Источник изображения: Google
В тесте Stable Diffusion система из 1024 TPU v5p заняла второе место, завершив работу за 2,44 мин, тогда как система того же размера на основе NVIDIA H100 справилась с задачей за 1,37 мин. В остальных тестах на кластерах меньшего масштаба разрыв остаётся примерно полуторакратным. Впрочем, Google упирает на масштабируемость и лучшее соотношение цены и производительности в сравнении как с решениями конкурентов, так и с собственными ускорителями прошлых поколений.
Также в новом раунде MLPerf появился единственный результат измерения энергопотребления во время проведения бенчмарка. Система из восьми серверов Dell XE9680, каждый из которых включал восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), в задаче тюнинга Llama2 70B потребила 16,38 мДж энергии, потратив на работу 5,05 мин. — средняя мощность составила 54,07 кВт.
Источники:

