Вычислительные платформы NVIDIA снова продемонстрировали высокую производительность, на этот раз в свежих тестах MLPerf Training v4.0. Так, суперкомпьютер NVIDIA EOS-DFW более чем утроил свою производительность в LLM-тесте на базе GPT-3 175B по сравнению с прошлогодним результатом.
Как сообщается, 11 616 ускорителей NVIDIA H100, объединённых 400G-интерконнектом NVIDIA Quantum-2 InfiniBand, позволили суперкомпьютеру EOS достичь столь значительного результата благодаря более масштабному и комплексному подходу к проектированию системы. А это позволяет более эффективно обучать и запускать крупные модели, экономя время и ресурсы, говорит компания. А более современный ускоритель H200 с улучшенной подсистемой памяти в MLPerf Training быстрее H100 на 14 %, а в GNN-тестах (RGAT) узлы с H200 оказались быстрее узлов с H100 сразу на 47 %.

Источник изображений: NVIDIA
По словам компании, поставщики услуг LLM могут всего за четыре года, инвестировав $1, получить $7, используя модель Llama 3 70B на серверах на базе NVIDIA HGX H200, если исходить из того, что обслуживание обходится в $0,60 за миллион токенов, а пропускная способность HGX H200 составляет 24 тыс. токенов в секунду.
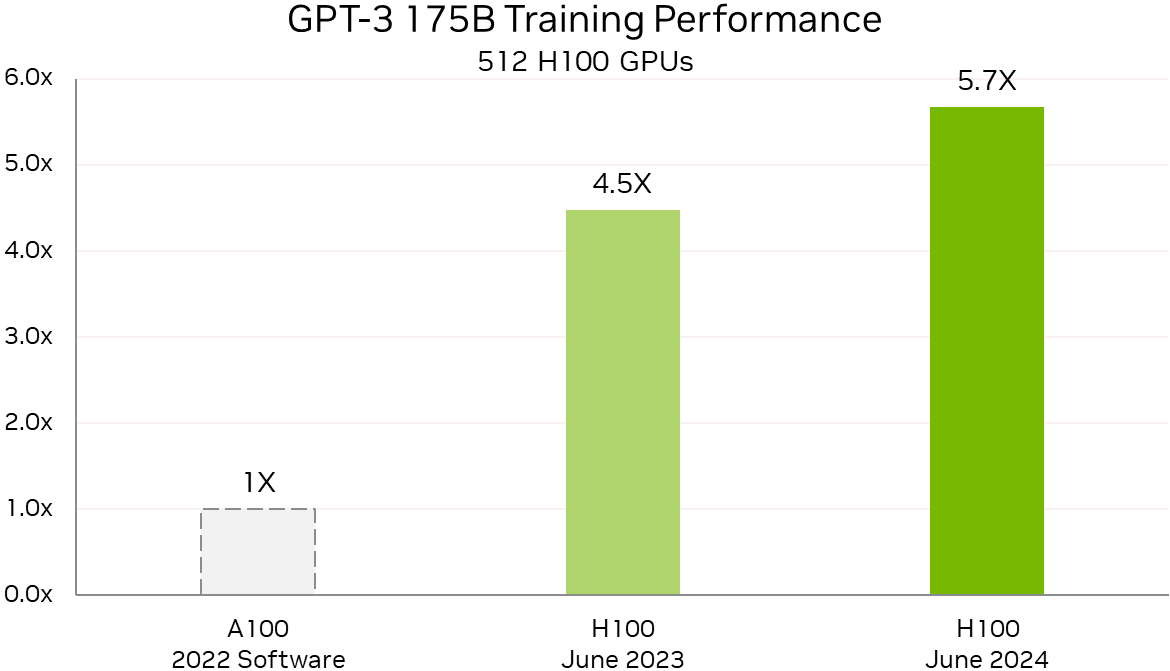
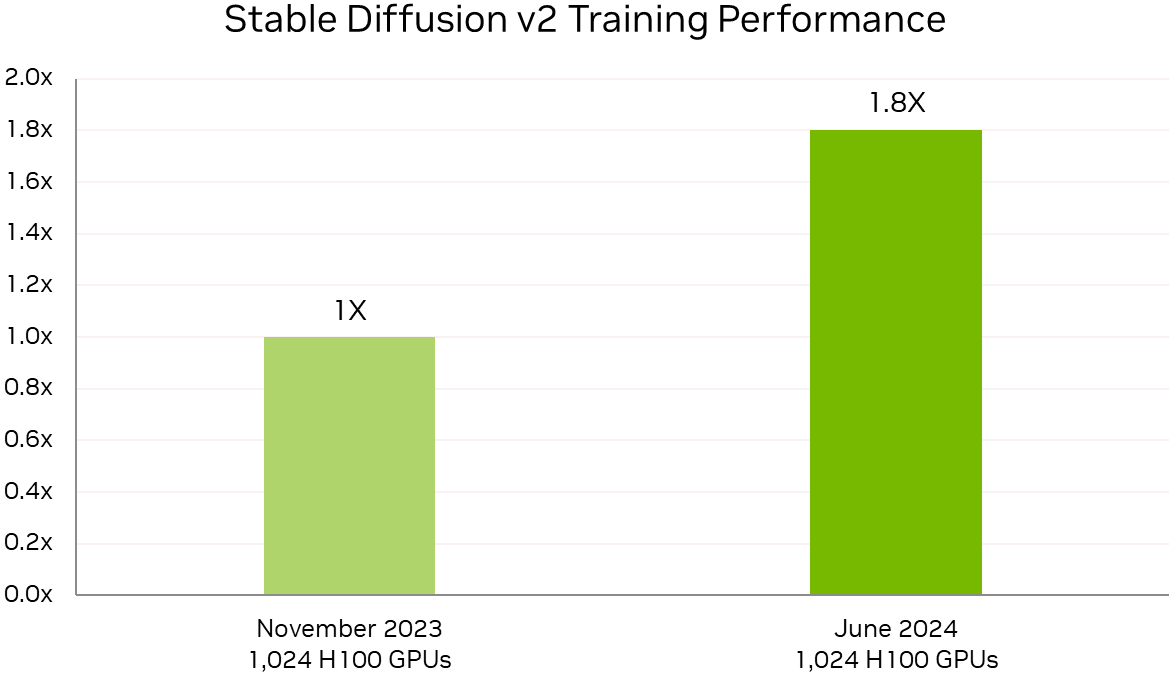
Росту производительности также способствовало совершенствование и оптимизация ПО. Так, кластер из 512 чипов H100 за год стал на 27 % быстрее, а рост производительности с увеличением количества ускорителей теперь более линеен. В новом тесте MLPerf Training по тюнингу LLM (LoRA применительно к Meta✴ Llama 2 70B) системы NVIDIA показали эффективное масштабирование при количестве ускорителей от 8 до 1024. NVIDIA также увеличила производительность обучения Stable Diffusion v2 почти на 80 % при тех же масштабах систем, что были представлены в прошлом тестировании.
NVIDIA отметила, что для компаний, запускающих приложения на базе LLM, высокая производительность имеет большое значение. Возможность обучать и настраивать более мощные модели — и быстрее их развёртывать и запускать — позволит получить лучшие результаты и более высокий доход. А с выходом платформы NVIDIA Blackwell скоро появится возможность как обучения, так и инференса моделей генеративного ИИ с триллионом параметров.
Источник:

