Материалы по тегу: ibm
|
08.09.2021 [17:40], Владимир Мироненко
IBM представила серверы E1080: 16 CPU POWER10, 240 ядер, 1920 потоков, 64 Тбайт RAM и 224 PCIe-слота в одной системеIBM объявила о выходе нового поколения серверов IBM POWER E1080 на базе 7-нм чипа POWER10. Это первая коммерческая система на новых процессорах IBM, представленных на прошлогодней конференции Hot Chips и использующих архитектуру POWER v3.1. IBM POWER E1080 предназначен для удовлетворения спроса на надёжные гибридные облачные среды. E1080 представляет собой четырёхсокетный сервер с процессорами POWER10. На текущий момент компания предлагает CPU c 10, 12 или 15 ядрами (ещё одно «запасное» ядро отключено), тогда как у POWER9 число ядер не превышало 12. На каждое ядро приходится 2 Мбайт L2-кеша и 8 Мбайт — L3 (до 120 Мбайт общего кеша на CPU). Для систем на базе E1080 поддерживается масштабирование до четырёх узлов, то есть можно получить 16 процессоров, 240 ядер, 1920 потоков, 64 Тбайт RAM и 224 PCIe-слота. 
IBM POWER E1080 Отличительной чертой новинок является поддержка SMT8, то есть обработка до 120 потоков на процессор. По сравнению с POWER9 производительность новых CPU выросла на 20% на поток и на 30% на ядро, а в пересчёте на Вт она выросла трёхкратно. А четыре 512-бит матричных движка и восемь 128-бит SIMD-блоков повысили скорость INT8-операций в 20 и более раз. 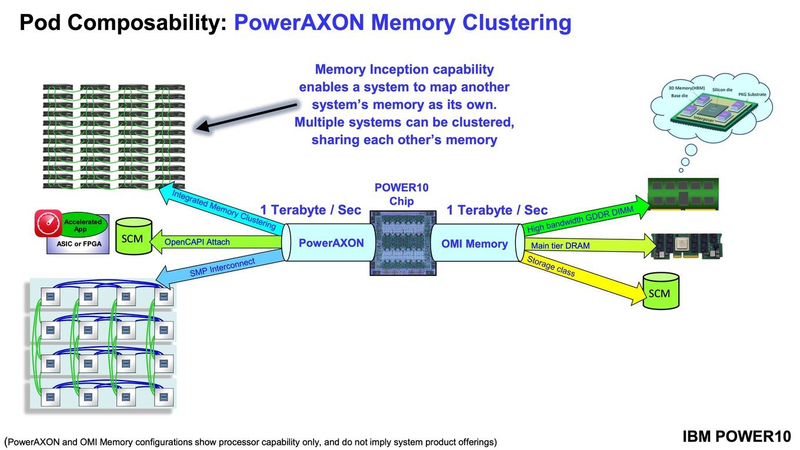 Память тоже новая — буферизированная OMI DDR4 DDIMM, которая, по словам компании, отличается повышенной надёжностью и отказоустойчивостью в сравнении с традиционными DDIMM. На один сервер приходится 64 слота с поддержкой до 16 Тбайт RAM с поддержкой технологии прозрачного шифрования памяти (Transparent Secure Memory Encryption, TSME), которая в 2,5 раза быстрее по сравнению с IBM POWER9. Заявленная пропускная способность составляет 409 Гбайт/с на ядро. 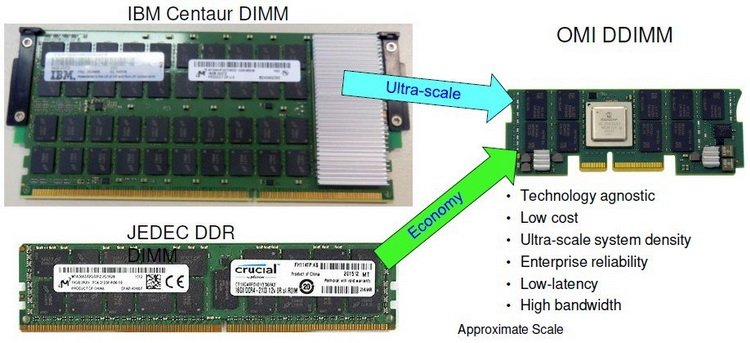 И для OMI, и для OpenCAPI используется шина PowerAXON (1 Тбайт/с), которая позволяет подключать к системе различные типы памяти (можно адресовать до 2048 Тбайт в рамках одного кластера), накопители, ускорители и т.д. Также в самой системе доступно четыре слота для NVMe SSD и 8 слотов PCIe 5.0. К E1080 можно подключить до четырёх полок расширения с 12 слотами PCIe 5.0 в каждой.  По данным IBM, благодаря E1080 установлен «мировой рекорд производительности: это первая система, достигшая 955 000 SAPS (SAP Application Performance Standard, в стандартном тесте приложений SAP SD в восьмипроцессорной системе — значительно больше, чем у альтернативной архитектуры x86, 2x на сокет (и) до 4 раз больше возможностей на ядро с E1080 (по сравнению с Intel)».  IBM заявила, что повышение производительности на ядро и увеличение количества ядер в системе означает значительное сокращение занимаемой серверами площади и энергопотребления. В тематическом исследовании неназванного клиента компания сообщила, что 126 серверов на чипах Intel, обслуживающих СУБД Oracle, были заменены тремя E980 на базе POWER9 и, по прогнозам, их можно будет заменить на два E1080. В результате потребляемая мощность упадёт со 102 до 20 кВт, а количество требуемых лицензий сократится с 891 (для системы Intel) до 263 (для E1080).  Новинка имеет в 4,1 раза более высокую по сравнению с x86-серверами пропускную способность контейнеризированных приложений OpenShift, а также целостность архитектуры и гибкость в гибридной облачной среде для повышения универсальности и снижения расходов без рефакторинга приложений. А по сравнению с IBM POWER E980v рост производительности и масштабируемости составил до 50% с одновременным снижением энергопотребления.  Кроме того, E1080 предлагает новые функции RAS для расширенного восстановления, самовосстановления и диагностики, а также усовершенствования для гибридного облака, включая первый в индустрии поминутный контроль использования ПО Red Hat, в том числе OpenShift и Red Hat Enterprise Linux. У IBM POWER E1080 также имеется возможность мгновенного масштабирования с помощью POWER Private Cloud with Dynamic Capacity, что позволит платить только за использованные ресурсы. Среди прочих преимуществ своего решения IBM отмечает наличие надёжной экосистемы независимых поставщиков ПО, бизнес-партнёров и поддержки для E1080. Кроме того, IBM анонсировала многоуровневый сервис POWER Expert Care, призванный обеспечить защиту от продвинутых киберугроз, а также согласованное функционирование аппаратного и программного обеспечения и более высокую эксплуатационную готовность систем.
24.08.2021 [04:11], Алексей Степин
IBM представила процессоры Telum: 8 ядер, 5+ ГГц, L2-кеш 256 Мбайт и ИИ-ускорительФинансовые организации, системы бронирования и прочие операторы бизнес-критичных задач любят «большие машины» IBM за надёжность. Недаром литера z в названии систем означает Zero Downtime — нулевое время простоя. На конференции Hot Chips 33 компания представила новое поколение z-процессоров, впервые в истории получившее собственное имя Telum (дротик в переводе с латыни). «Оружейное» название выбрано неспроста: в новой архитектуре IBM внедрила и новые, ранее не использовавшиеся в System z решения, предназначенные, в частности, для борьбы с фродом. 
Пластина с кристаллами IBM Telum Одни из ключевых заказчиков IBM — крупные финансовые корпорации и банки — давно ждали встроенных ИИ-средств, поскольку их системы должны обрабатывать тысячи и тысячи транзакций в секунду, и делать это максимально надёжно. Одной из целей при разработке Telum было внедрение инференс-вычислений, происходящих в реальном времени прямо в процессе обработки транзакции и без отсылки каких-либо данных за пределы системы.  Поэтому инференс-ускоритель в Telum соединён напрямую с подсистемой кешей и использует все механизмы защиты процессора и памяти z/Architecture. И сам он тоже несёт ряд характерных для z подходов. Так, управляет работой акселератора отдельная «прошивка» (firmware), которую можно менять для оптимизации задач конкретного клиента. Она выполняется на одном из ядер и собственно ускорителе, который общается с данным ядром, и отвечает за обращения к памяти и кешу, безопасность и целостность данных и управление собственно вычислениями. 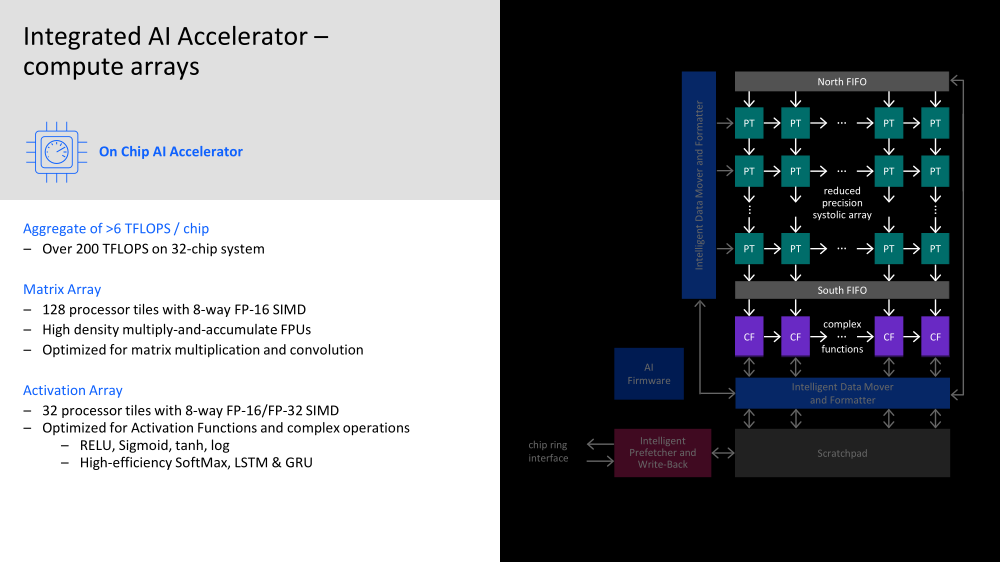 Акселератор включает два вида движков. Первый имеет 128 SIMD-блоков для MAC-операций с FP16-данными и нужен для перемножения и свёртки матриц. У второго всего 32 SIMD-блока, но он может работать с FP16/FP32-данными и оптимизирован для функций активации сети и других, более комплексных задач. Дополняет их блок сверхбыстрой памяти (scratchpad) и «умный» IO-движок, ответственный за перемещение и подготовку данных, который умеет переформатировать их на лету. 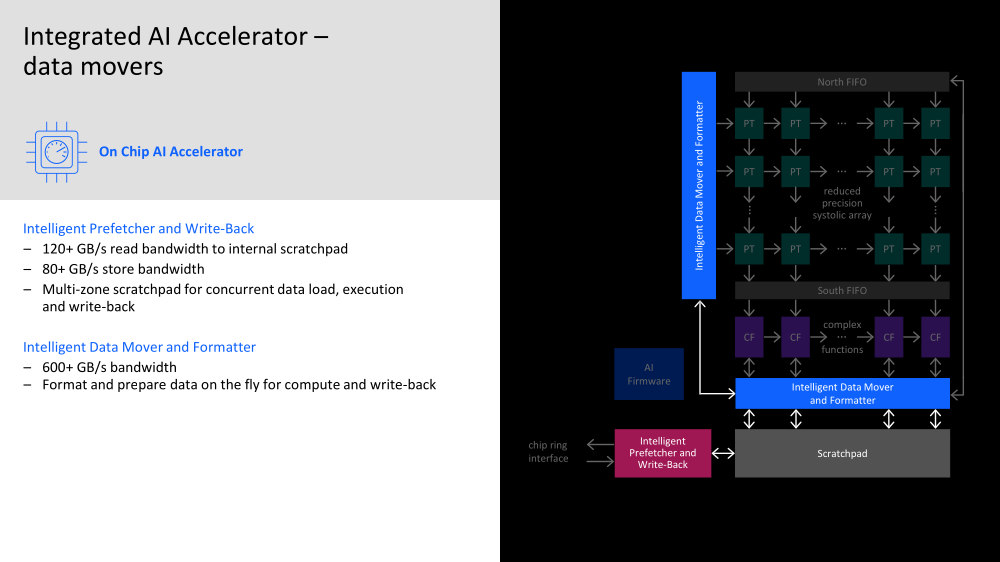 Scratchpad подключён к блоку, который подкачивает данные из L2-кеша и отправляет обратно результаты вычислений. IBM отдельно подчёркивает, что наличие выделенного ИИ-ускорителя позволяет параллельно использовать и обычные SIMD-блоки в ядрах, явно намекая на AVX-512 VNNI. Впрочем, в Sapphire Rapids теперь тоже есть отдельный AMX-блок в ядре, который однако скромнее по функциональности. 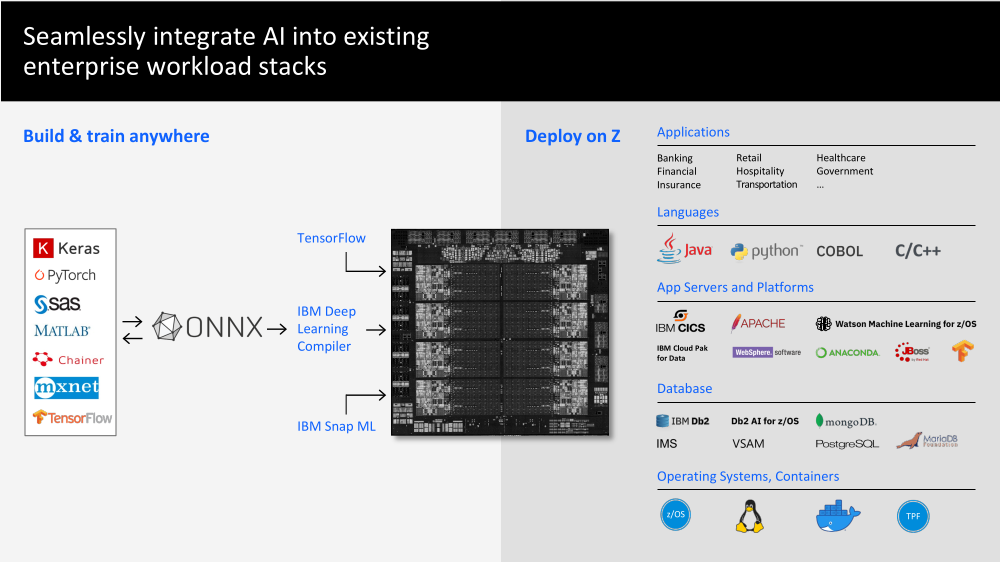 Доступ к ускорителю возможен из пространства пользователя, в том числе в виртуализированном окружении. Для работы с новым ускорителем компания предлагает IBM Deep Learning Compiler, который поможет оптимизировать импортируемые ONNX-модели. Также есть готовая поддержка TensorFlow, IBM Snap ML и целого ряда популярных средств разработки. На процессор приходится один ИИ-ускоритель производительностью более 6 Тфлопс FP16. 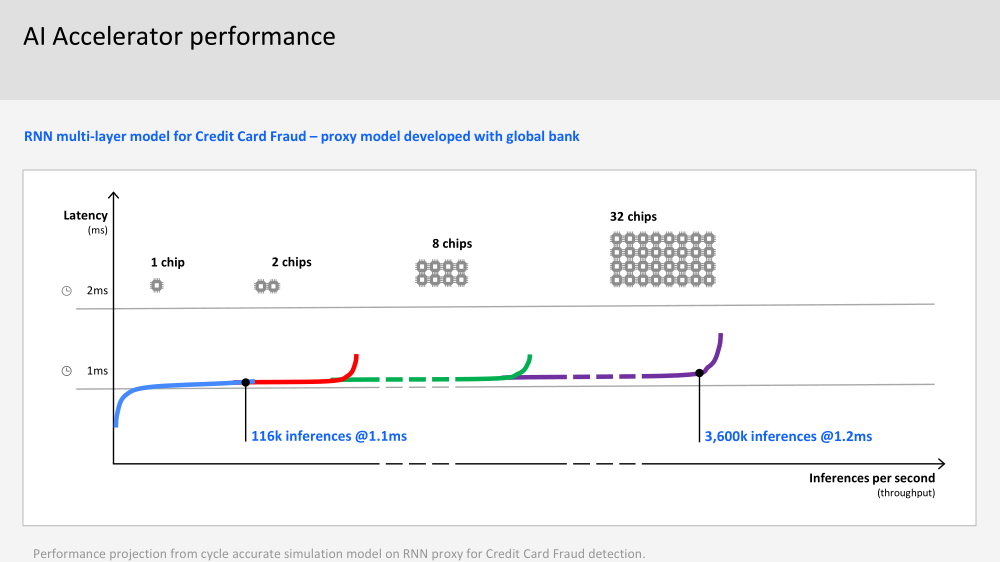 На тестовой RNN-модели для защиты от фрода чип может выполнять 116 тыс. инференс-операций с задержкой в пределах 1,1 мс, а для системы из 32 процессоров этот показатель составляет уже 3,6 млн инференс-операций, а латентность при этом возрастает всего лишь до 1,2 мс. Помимо ИИ-акселератора также имеется общий для всех ядер ускоритель (де-)компрессии (gzip) + у каждого ядра есть ещё и движок для CSMP. Ну и ускорители для сортировки и шифрования тоже никуда не делись.  За надёжность отвечают сотни различных механизмов проверки и перепроверки работоспособности. Так, например, регистры и кеш дублируются, позволяя в случае сбоя ядра сделать его полную перезагрузку и продолжить выполнение задач ровно с того места, где оно прервалось. А для оперативной памяти, которая в обязательном порядке шифруется, используется режим Redundant Array of Memory (RAIM), своего рода RAID-массив, где одна кеш-линия «размазывается» сразу между восемью модулями.  Telum, унаследовав многое от своего предшественника z15, всё же кардинально отличается от него. Процессор содержит восемь ядер с поддержкой «умного» глубокого внеочередного исполнения и SMT2, работающих на частоте более 5 ГГц. Каждому ядру полагается 32 Мбайт L2-кеша, так что на его фоне другие современные CPU выглядят блекло. Но не всё так просто. 
IBM Telum Между собой кеши общаются посредством двунаправленной кольцевой шины с пропускной способностью более 320 Гбайт/с, формируя таким образом виртуальный L3-кеш объёмом 256 Мбайт и со средней задержкой в 12 нс. Каждый чип Telum может содержать один (SCM) или два (DCM) процессора. А в одном узле может быть до четырёх чипов, то есть до восьми CPU, объединённых по схеме каждый-с-каждым с той же скоростью 320 Гбайт/с.  Таким образом, в рамках узла формируется виртуальный L4-кеш объёмом уже 2 Гбайт. Плоская топология кешей, по данным IBM, обеспечивает новым процессорам меньшую латентность в сравнении с z15. Масштабирование возможно до 32 процессоров, но отдельные узлы связаны несколькими подключениями со скоростью «всего» 45 Гбайт/с в каждую сторону.  В целом, IBM говорит о 40% прироста производительности в сравнении с z15 в пересчёте на сокет. Telum содержит 22 млрд транзисторов и имеет TDP на уровне 400 Вт в нормальном режиме работы. Процессор будет производиться на мощностях Samsung с использованием 7-нм техпроцесса EUV. Он станет основной для мейнфреймов IBM z16 и LinuxNOW. Программной платформой всё так же будут как традиционная z/OS, так и Linux.
08.10.2020 [21:26], Владимир Мироненко
IBM разделится на две компании и сосредоточится на создании гибридного облака стоимостью $1 трлнКомпания IBM, изначально сделавшая себе имя благодаря выпуску корпоративного оборудования, делает ещё один шаг в сторону от этого наследия, углубляясь в мир облачных сервисов. Сегодня компания объявила о решении выделить подразделение управляемых инфраструктурных услуг в отдельную публичную компанию с годовой выручкой в $19 млрд, чтобы сосредоточиться на новых возможностях гибридных облачных приложений и искусственного интеллекта. Как сообщил генеральный директор IBM Арвинд Кришна (Arvind Krishna), процесс создания новой компании с условным названием NewCo (новая компания) будет завершён к концу 2021 года. У неё будет 90 тыс. сотрудников, 4600 крупных корпоративных клиентов в 115 странах, портфель заказов в размере $60 млрд, «и более чем в два раза больше, чем у ближайшего конкурента» присутствие в области инфраструктурных услуг. 
Gleb Garanich/Reuters В число конкурентов новой компании входят BMC и Microsoft. Остающийся у IBM после выделения новой компании бизнес в настоящее время приносит её около $59 млрд годового дохода. Услуги инфраструктуры включают в себя ряд управляемых сервисов, основанных на устоявшейся инфраструктуре и связанной с ней цифровой трансформации. Они включают в себя, в том числе тестирование и сборку, а также разработку продуктов и лабораторные сервисы. Этот шаг является значительным сдвигом для компании и подчеркивает большие изменения в том, как ИТ-инфраструктура предприятия развивалась и, похоже, продолжит меняться в будущем. IBM делает ставку на то, что устаревшая инфраструктура и ее обслуживание, продолжая приносить чистую прибыль, не будут расти, как это было в прошлом, и по мере того, как компания продолжит модернизацию или «цифровую трансформацию», она будет всё больше обращаться к внешней инфраструктуре и использованию облачных сервисов как для ведения своего бизнеса, так и для создания сервисов, взаимодействующих с потребителями. Объявление было сделано через год после того, как IBM приобрела компанию Red Hat, предлагающую ПО с открытым исходным кодом, за $34 млрд, рассчитывая перевести большую часть своего бизнеса в облачные сервисы. «Я очень рад предстоящему пути и огромной ценности, которую мы создадим, если две компании будут сосредоточены на том, что у них получается лучше всего, — отметил в своем заявлении Арвинд Кришна. — Это принесёт пользу нашим клиентам, сотрудникам и акционерам и выведет IBM и NewCo на траекторию улучшенного роста». «IBM сосредоточена на возможности создания гибридного облака стоимостью $1 трлн, — сказал Кришна. — Потребности клиентов в покупке приложений и инфраструктурных услуг разнятся, в то время как внедрение нашей гибридной облачной платформы ускоряется. Сейчас подходящее время для создания двух лидирующих на рынке компаний, сосредоточенных на том, что у них получается лучше всего. IBM сосредоточится на своей открытой гибридной облачной платформе и возможностях ИИ. NewCo будет более гибко проектировать, управлять и модернизировать инфраструктуру самых важных организаций мира. Обе компании будут двигаться по траектории улучшенного роста с большей способностью сотрудничать и использовать новые возможности, создавая ценность для клиентов и акционеров».
17.08.2020 [15:32], Алексей Степин
Подробности о процессорах IBM POWER10: SMT8, OMI DDR5, PCIe 5.0 и PowerAXON 2.0Мы внимательно следим за судьбой и развитием архитектуры POWER, которая наряду с ARM представляет определённую угрозу для x86 в сфере серверов и суперкомпьютеров — недаром одна из самых мощных в мире HPC систем, суперкомпьютер Ок-Риджской национальной лаборатории Summit, использует процессоры POWER9. Ранее ожидалось что по ряду причин выход следующей в семействе архитектуры, POWER10, откладывается до 2021 года, хотя IBM и продвигала активно новые решения вроде универсального стандарта оперативной памяти OMI. Однако официальный анонс IBM POWER10 состоялся сегодня, а немецкий портал Hardwareluxx выложил слайды презентации компании.  Как компания уже отмечала ранее, она делает упор на большие системы и гибридные облака. С учётом этих тенденций и были разработаны новые процессоры. Поскольку в крупных облачных ЦОД упаковка вычислительных плотностей достигает уже невиданного ранее уровня, всё острее встаёт вопрос с энергоэффективностью и отводом тепла. Но именно здесь, как считает IBM, POWER10 и должен показать себя с наилучшей стороны — новые процессоры производятся с использованием 7-нм техпроцесса и могут демонстрировать трёхкратное преимущество в энергоэффективности в сравнении с POWER9. 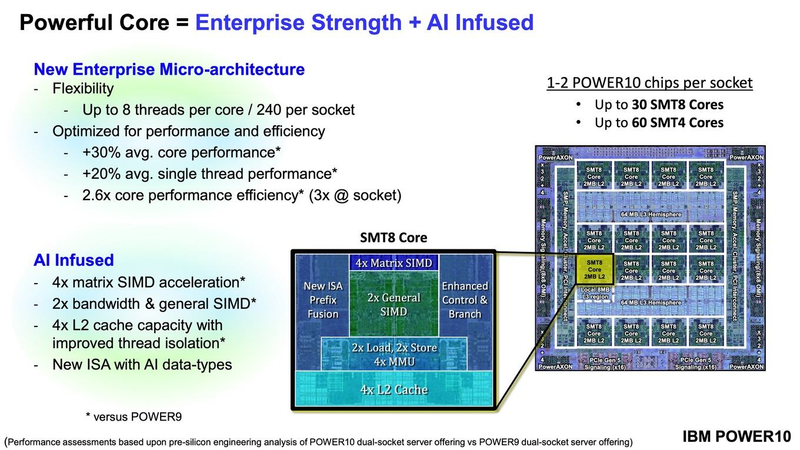 POWER10 — первый коммерческий процессор IBM, использующий нормы производства 7 нм; любопытно, что теперь Intel отстаёт не только от AMD, которая стала пионером в использовании столь тонкого техпроцесса в «крупных» серверных процессорах, но и от IBM. В отличие от AMD EPYC, производимых на мощностях TSMC, новинки IBM «куются» в полупроводниковых кузнях Samsung. Площадь кристалла, состоящего из 18 миллиардов транзисторов, у новых процессоров достигает 602 мм2, что меньше, чем у новейших графических ядер, но всё равно цифра довольно солидная. 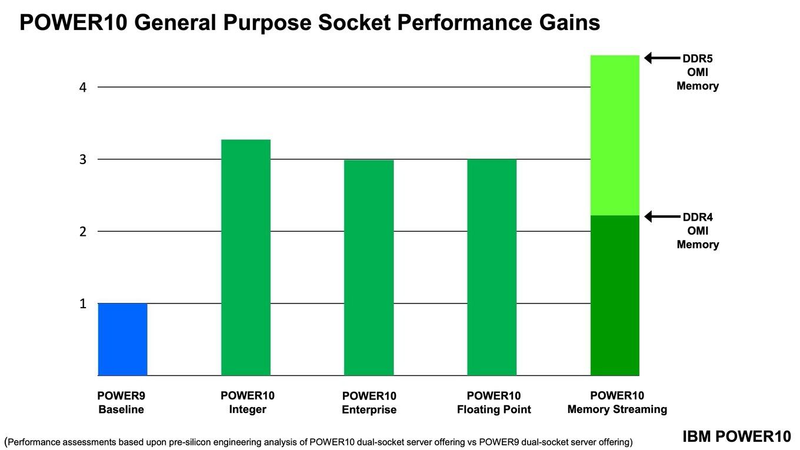 Техпроцесс POWER10 является совместной разработкой Samsung и IBM. В нём реализованы некие особенности, которые, предположительно, должны позитивно сказаться на характеристиках отдельных транзисторов. Не забыта и мода на установку нескольких кристаллов в один корпус: POWER10 доступны как в классическом варианте (SCM), так и в виде сборки из двух кристаллов (DCM), так что для каждого сценария использования можно выбрать подходящий вариант. В варианте SCM тактовая частота ядер составляет 4 ГГц, количество процессорных разъёмов в системе может достигать 16. В версии DCM частота снижена до 3,5 ГГц. 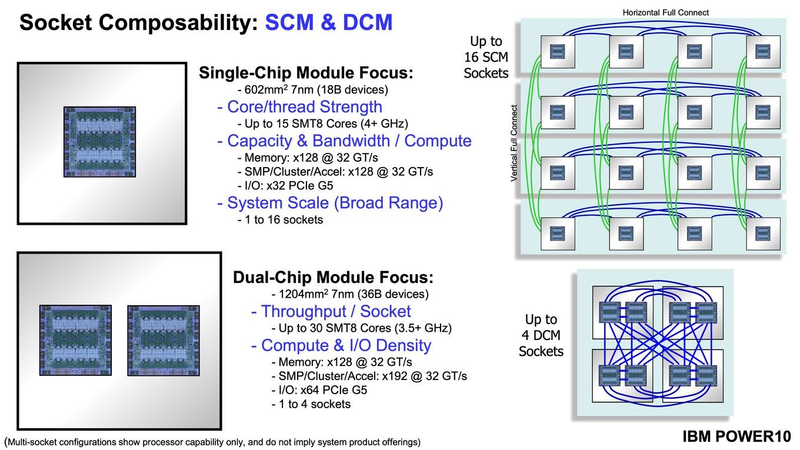 Базовый кристалл POWER10 имеет 16 вычислительных ядер, хотя используется из них только 15, каждое ядро дополнено 2 Мбайт кеша L2, а общий объём кеша L3 может достигать внушительных 120 Мбайт. Степень параллелизма была увеличена с SMT4 до SMT8, так что процессор может исполнять одновременно до 120 потоков, хотя, естественно, не в любой задаче такое распараллеливание ресурсов ядер будет эффективным. Производительность блоков SIMD была существенно увеличена, они вдвое быстрее аналогичных блоков POWER9, а на матричных операциях — быстрее в четыре раза. 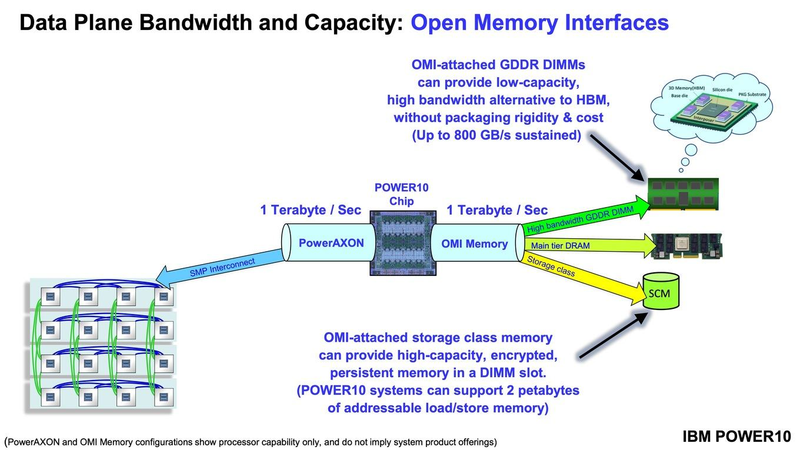 За общение процессора с «внешним миром» отвечают интерфейсы PowerAXON 2.0 и PCI Express 5.0, в первом случае поддерживается открытый стандарт OpenCAPI, во втором реализовано 64 линии со скоростью 32 ГТ/с на линию, как и предписано стандартом. Компоновка связей у DCM и SCM разная. В первом случае сокетов может быть только 4, зато используется топология «каждый с каждым», а вот в 16-сокетном варианте SCM «по диагонали» между собой процессоры напрямую не общаются. 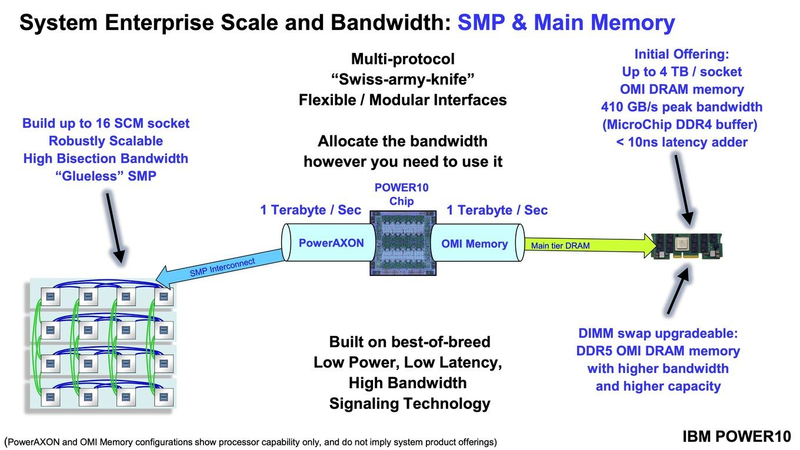 Интерфейс PowerAXON универсален, он использовался, в числе прочего, для реализации протокола NVLink для подключения ускорителей на базе графических процессоров NVIDIA. Проблем с пропускной способностью быть не должно, у каждого процессора в системе PowerAXON обеспечивает до 1 Тбайт/с. Кроме подключения ускорителей и общения процессоров между собой, у PowerAXON есть и ещё одно интересное и важное применение, о котором ниже. 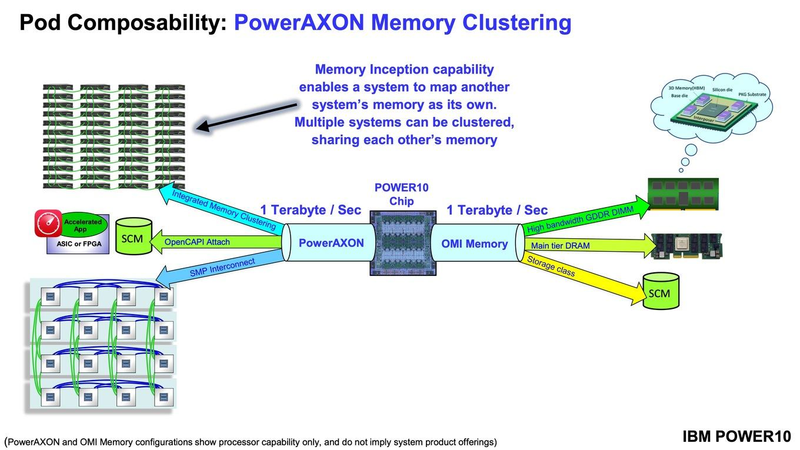 О преимуществах унифицированного интерфейса OMI, позволяющего «малой кровью» модернизировать подсистему памяти, мы уже рассказывали читателям ранее. В новом процессоре эти возможности задействованы полностью. Каждый базовый кристалл POWER10 имеет 16 линков OMI x8, общая пропускная способность достигает 1 Тбайт/с. Латентность, разумеется, возросла, поскольку контроллер DDR у OMI, по сути, внешний, но прирост небольшой и составляет менее 10 наносекунд. Универсальность и возможность модернизации этот недостаток искупают с лихвой. В текущем варианте пиковая пропускная способность достигает 410 Гбайт/с на разъём, объём — 4 Тбайт на разъём, однако с внедрением более быстрых типов памяти (DDR5, GDDR или даже HBM) может быть достигнута цифра 800 Гбайт/с на разъём. Отдельно упоминается возможность работы с SCM, но без конкретики. На данный момент такая память массово представлена только 3D XPoint в виде Intel Optane DCPMM. 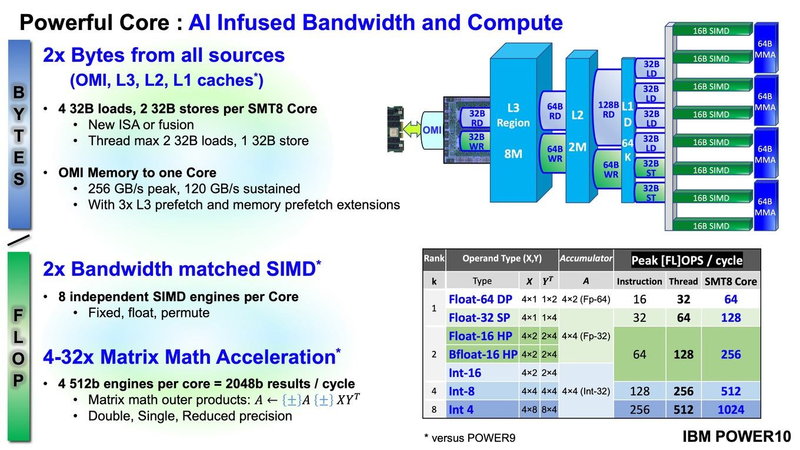 Любопытна технология Memory Clustering. С помощью PowerAXON система может обращаться к оперативной памяти в другой системе, как к собственной. Латентность при этом составляет 50 ‒ 100 нс, для систем типа NUMA совсем немного. Общий объем на одну систему POWER10 может достигать 2 Пбайт; с учётом применения систем IBM для запуска таких «пожирателей памяти», как SAP HANA такие объемы очень к месту. 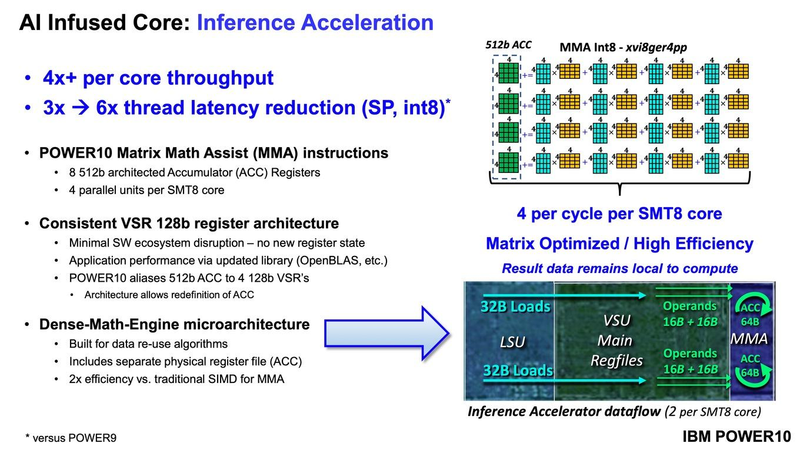 Следуя текущей моде на машинное обучение, разработчики реализовали в POWER10 развитую поддержку форматов вычислений, отличных от традиционных FP32/64. Блок плавающих вычислений в новом процессоре носит название Matrix Math Accelerator. В сравнении с POWER9 он быстрее в 10, 15 и 20 раз в режимах FP32, BFloat16 и INT8 соответственно. Иными словами, именно для инференс-систем POWER10 станет хорошим выбором. 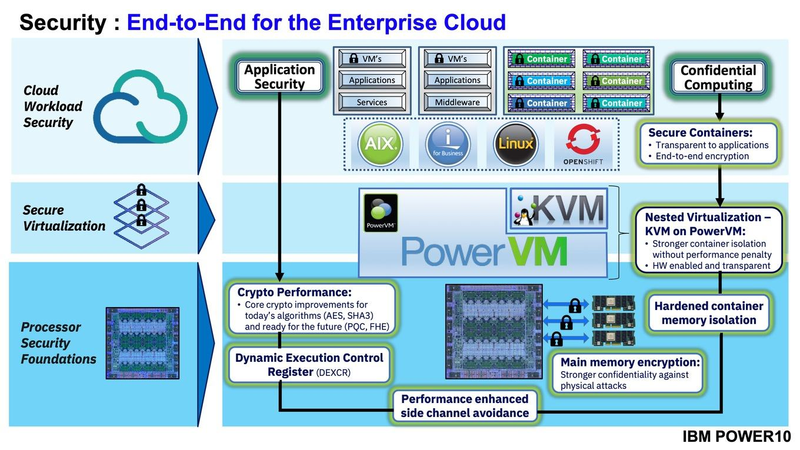 Поскольку одним из применений POWER10 компания видит облачные комплексы, серьёзное внимание уделено обеспечению безопасности. Новые процессоры поддерживают полное шифрование содержимого оперативной памяти, а для ускорения криптографических процедур в их составе есть соответствующие аппаратные блоки, причём не только для широко распространённого стандарта AES. Они достаточно гибки, чтобы поддерживать и шифрование будущего класса quantum safe. Также поддерживается защита и изоляция контейнеров на аппаратном уровне. Успешная атака на один контейнер в пределах машины не означает и успеха с другими контейнерами.  В качестве программной основы IBM предлагает Red Hat OpenShift, и архитектура POWER10 была соответствующим образом оптимизирована, чтобы показывать наилучшие результаты именно с этой средой. В целом, можно уверенно сказать: новые процессоры Голубого Гиганта получились интересными и весьма достойно выглядящими решениями даже на фоне успеха AMD EPYC.  Официальный анонс состоялся сегодня, но развёртывание массового производства должно занять определённое время, так что появления первых серверов на базе IBM POWER10 стоит ожидать не ранее начала следующего, 2021 года. А планы компании говорят о том, что POWER11 уже находится в разработке.
04.11.2019 [21:00], Алексей Степин
IBM продвигает открытый стандарт оперативной DDIMM-памяти OMI для серверовПрактически у всех современных процессоров контроллер памяти давно и прочно является частью самого ЦП, будь то монолитный кристалл или чиплетная сборка. Но не всегда подобная монолитность является плюсом — к примеру, она усложняет задачу увеличения количества каналов доступа к памяти. Таких каналов уже 8 и существуют проекты процессоров с 10 каналами памяти. Но это усложняет как сами ЦП, так и системные платы, ведь только на подсистему памяти, без учёта интерфейса PCI Express, может уйти 300 и более контактов, которые ещё требуется корректно развести и подключить. 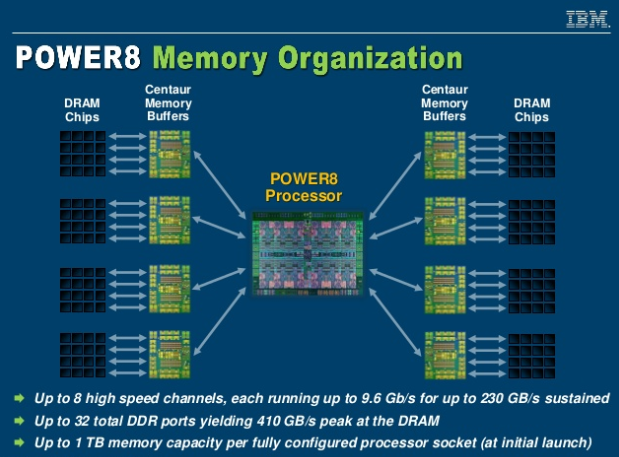
Организация подсистемы памяти у POWER8 У IBM есть ответ, и заключается он в переносе части функций контроллера памяти на сторону модулей DIMM. Сам интерфейс между ЦП и модулями памяти становится последовательным и предельно унифицированным. Похожая схема использовалась в стандарте FB-DIMM, аналогичную компоновку применила и сама IBM в процессорах POWER8 и POWER9 в варианте Scale-Up. 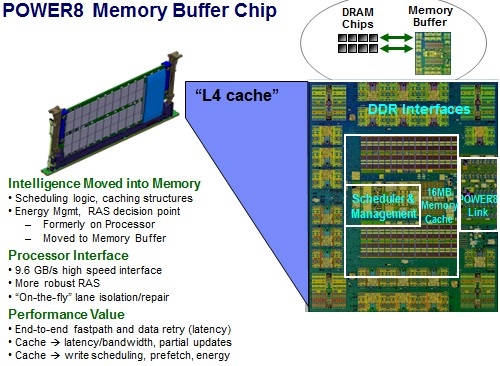
Роль и возможности буфера Centaur у POWER8 Контроллер памяти у этих процессоров упрощён, в нём отсутствует контроллер физического уровня (PHY). Его задачи возложены на чип-буфер Centaur, который посредством одноимённого последовательного интерфейса и связывается с процессором на скорости 28,8 Гбайт/с. Контроллеров интерфейса Centaur в процессорах IBM целых восемь, что дает ПСП в районе 230 Гбайт/с. За счёт выноса ряда функций в чипы-буфера удалось сократить площадь кристалла, и без того немалую (свыше 700 мм2), но за это пришлось заплатить увеличением задержек в среднем на 10 нс. Частично это сглажено за счёт наличия в составе Centaur кеша L4. 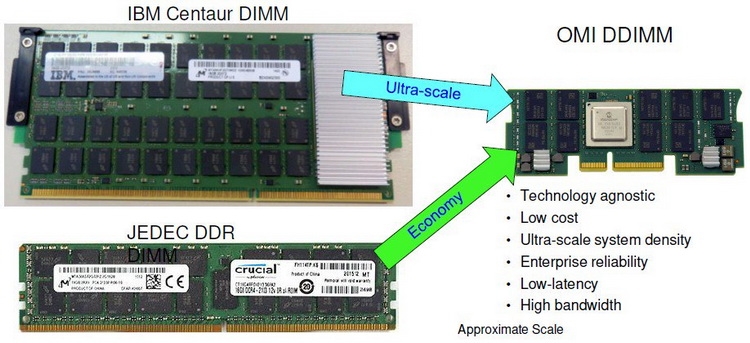
Сравнительные размеры модулей Centaur, RDIMM и OMI DDIMM Стандарт не является открытым, но IBM предлагает ему на смену полностью открытый вариант под названием Open Memory Interface (OMI). В его основу положена семантика и протоколы, описанные в стандарте OpenCAPI 3.1, а физический уровень представлен шиной BlueLink (25 Гбит/с на линию), которая уже используется для реализации NVLink и OpenCAPI. Реализация OMI проще Centaur, что позволяет сделать чип-буфер более компактным и выделяющим меньше тепла. Но все преимущества сохраняются: так, число контактов процессора, отвечающих за интерфейс памяти, можно снизить с примерно 300 до 75, поскольку посылаются только простые команды загрузки и сохранения данных. Вся реализация физического интерфейса осуществляется силами чипа-компаньона OMI, и в нём же может находиться дополнительный кеш. 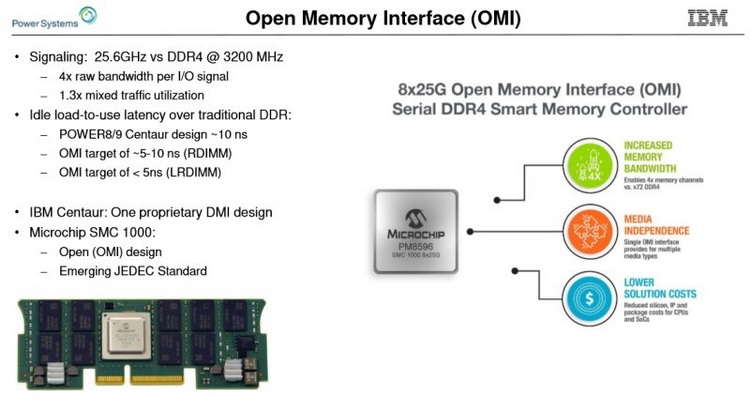
Модули OMI DDIMM станут стандартом JEDEC Помимо экономии контактов есть и ещё одна выгода: можно реализовать любой тип памяти, будь то DDR, GDDR и даже NVDIMM — вся PHY-часть придётся на различные варианты чипов OMI, но со стороны стандартного разъёма любой модуль OMI будет выглядеть одинаково. Сейчас взят прицел на реализацию модулей с памятью DDR5. При использовании существующих чипов DDR4 система с интерфейсом OMI может достичь совокупной ПСП порядка 650 Гбайт/с. Дополнительные задержки составят 5 ‒ 10 нс для RDIMM и лишь 4 нс для LRDIMM. Из всех соперников технологии на такое способны только сборки HBM, которые в силу своей природы имеют ограниченную ёмкость, дороги в реализации и не могут быть вынесены с общей с ЦП подложки. 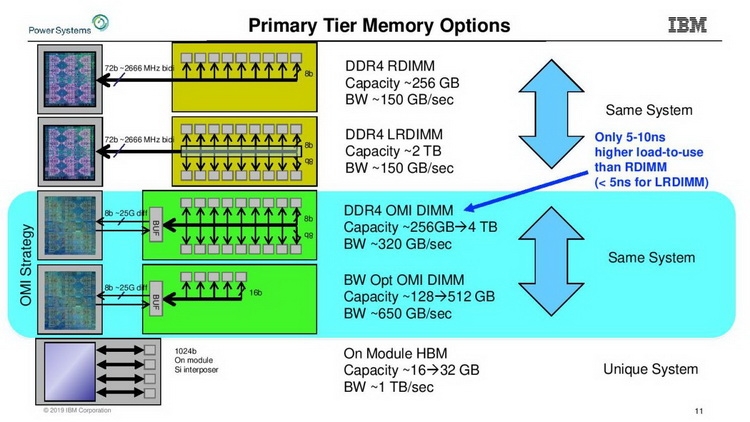
Новый стандарт упростит процессоры и позволит увеличить ёмкость подсистемы памяти Чипы-буферы OMI можно разместить как на модуле памяти, так и на системной плате. Разумеется, для стандартизации выбран первый вариант. В нём предусмотрено 84 контакта на модуль, сами же модули получили название Dual-Inline Memory Module (DDIMM). DDIMM вышли существенно компактнее своих традиционных собратьев: ширина модуля сократилась со 133 до 85 мм. Реализация буфера OMI ↔ DDR4 уже существует в кремнии: компания Microsemi продемонстрировала чип SMC 1000 (PM8596), поддерживающего 8 линий OMI со скоростью 25 Гбит/с каждая. Допустима также работа в режиме 4 × 1 с вдвое меньшей общей пропускной способностью. 
DDIMM: меньше ширина, проще разъём Со стороны чипов памяти SMC 1000 имеет стандартный 72-битный интерфейс с ECC и поддержкой различных комбинаций DRAM и NAND-устройств. Тактовая частота DRAM — до 3,2 ГГц, высота модуля зависит от количества и типов устанавливаемых чипов. В случае одиночной высоты модули могут иметь ёмкость до 128 Гбайт, двойная высота позволит создать DDIMM объёмом свыше 256 Гбайт. Сам чип SMC 1000 невелик, всего 17 × 17 мм, а невысокое тепловыделение гарантирует отсутствие проблем с перегревом, свойственных FB-DIMM. 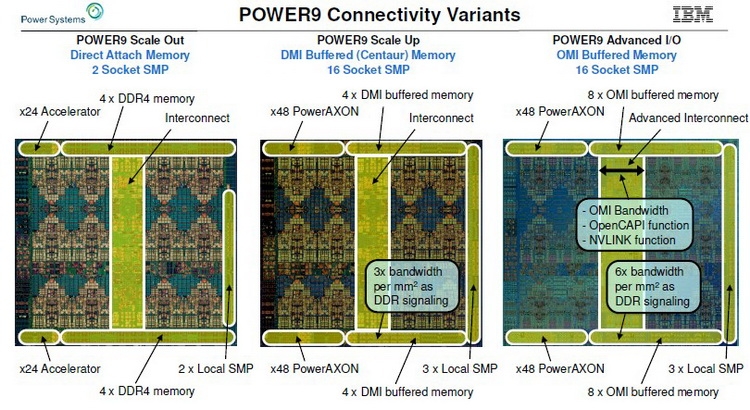
Процессоры IBM POWER9 AIO дополнили существующую серию Первыми процессорами с поддержкой OMI стали новые POWER9 версии Advanced I/O (AIO), дополнившие семейства Scale Up (SC) и Scale Out (SO). В них реализовано 16 каналов OMI по 8 линий каждый (до 650 Гбайт/с суммарно), а также новые версии интерфейсов NVLink (возможно, 3.0) и OpenCAPI 4.0. Количество линий PCI Express 4.0 по-прежнему составляет 48. Шина IBM BlueLink была переименована в PowerAXON. За счёт её использования в системах на базе процессоров POWER возможна реализация 16-сокетных систем без применения дополнительной логики. Максимальное количество ядер у POWER9 AIO равно 24, с учётом SMT4 это даёт 96 исполняемых потоков. Имеется также кеш L3 типа eDRAM объёмом 120 Мбайт. Техпроцесс остался прежним, это 14-нм FinFET. 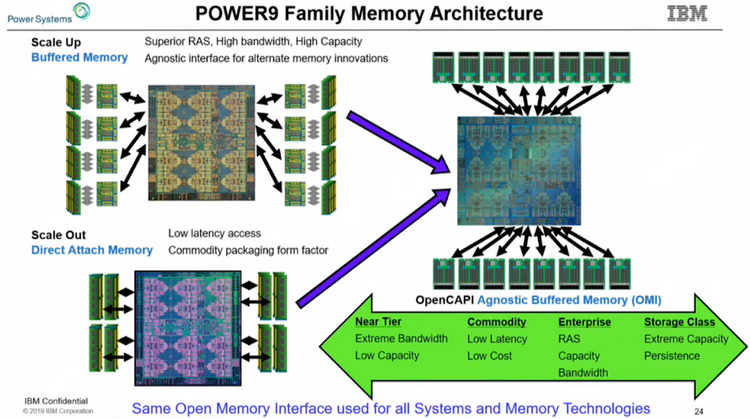
Архитектура подсистем памяти у семейства IBM POWER9 Поставки POWER9 AIO начнутся в этом году, цены неизвестны, но с учётом 8 миллиардов транзисторов и кристалла площадью 728 мм2 они не могут быть низкими. Однако без OMI эти процессоры были бы ещё более дорогими. В комплект поставки входит и чип-буфер OMI, правда, не самая быстрая версия с пропускной способностью на уровне 410 Гбайт/с. Задел для модернизации есть, и для расширения ПСП достаточно будет заменить модули DDIMM на более быстрые варианты. 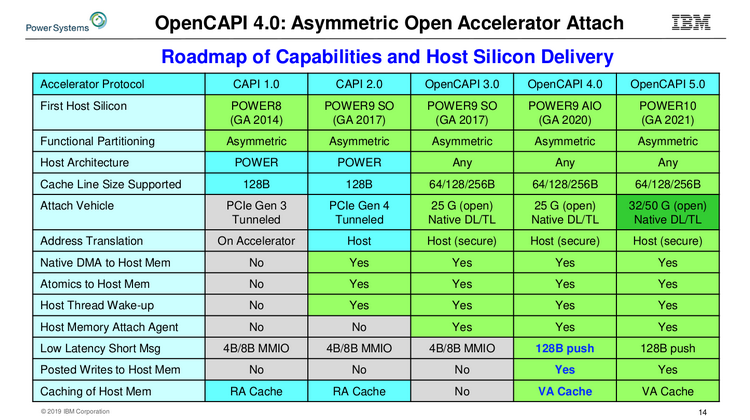
Сравнительная таблица существующих и будущих версий OpenCAPI Следующее поколение процессоров IBM, POWER10, появится только в 2021 году. К этому времени ожидается принятие стандарта OMI на рынке высокопроизводительных многопроцессорных систем. Попутно IBM готовит новые версии OpenCAPI, не привязанные к архитектуре POWER, а значит, путь к OMI будет открыт и другим вендорам.
24.08.2019 [06:14], Андрей Галадей
IBM передала наработки по архитектуре Power сообществуКорпорация IBM сообщила, что переводит архитектуру набора команд (ISA) Power в разряд открытых решений. То есть, за неё не нужно будет платить, как это было в последние 6 лет. Отмечается, что с 2013 года действовал консорциум OpenPOWER, который лицензировал связанную с Power интеллектуальную собственность. Но теперь все наработки и патенты будут переданы сообществу безвозмездно. Сама же организация OpenPOWER Foundation будет переподчинена Linux Foundation, что позволит создать площадку для развития архитектуры без привязки к чипмейкеру или иной компании. Как отмечается, OpenPOWER Foundation включает в себя более 350 компаний, а сообществу передали свыше 3 млн строк кода системных прошивок, спецификаций и схем. Всё это позволит создавать Power-совместимые чипы всем желающим. 
pixabay.com Помимо собственно процессоров, компания передала сообществу и смежные технологии для разработки расширений на основе интерфейсов OpenCAPI (Open Coherent Accelerator Processor Interface) и OMI (Open Memory Interface). Первая технология должна устранить «узкие места» во взаимодействии CPU, GPU, ASIC, а также других чипов и контроллеров. Вторая же должна ускорить оперативную память. Это позволит создавать на базе архитектуры Power специализированные чипы для искусственного интеллекта. Важно отметить, что процессоры Power позволяют создавать современные серверы и суперкомпьютеры. К примеру, суперкомпьютеры Summit и Sierra работают как раз на таких чипах. А это, на минуточку, первый и второй номера в мировом рейтинге таких систем. Напомним, на процессорах с архитектурой Power (хотя и специализированных) работали в том числе и консоли Sony PlayStation 3, Xbox 360, а также старые ПК и ноутбуки Apple.
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 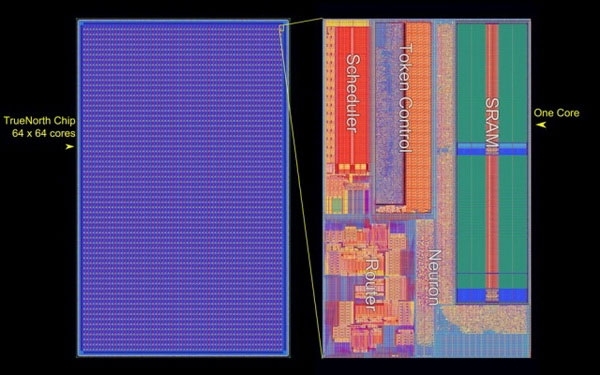
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране. |
|

