Материалы по тегу: 400gbe
|
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 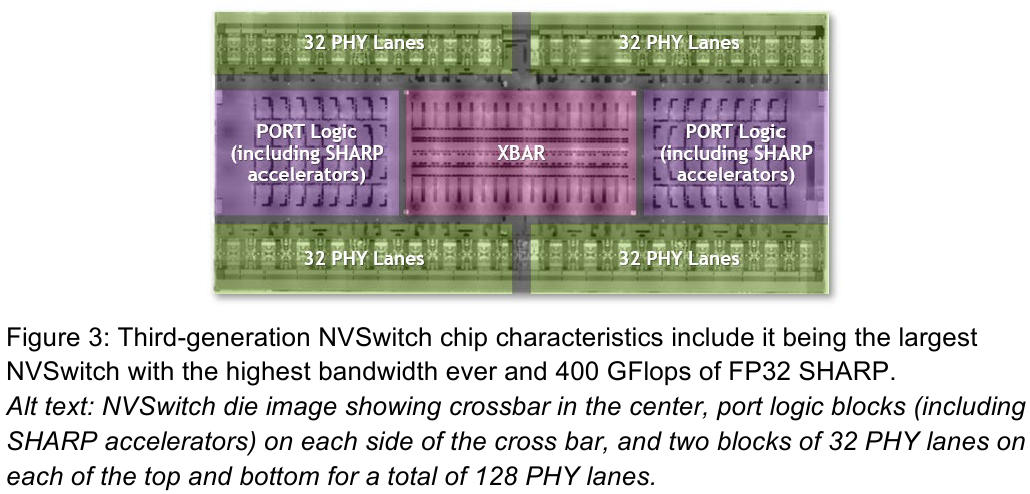 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 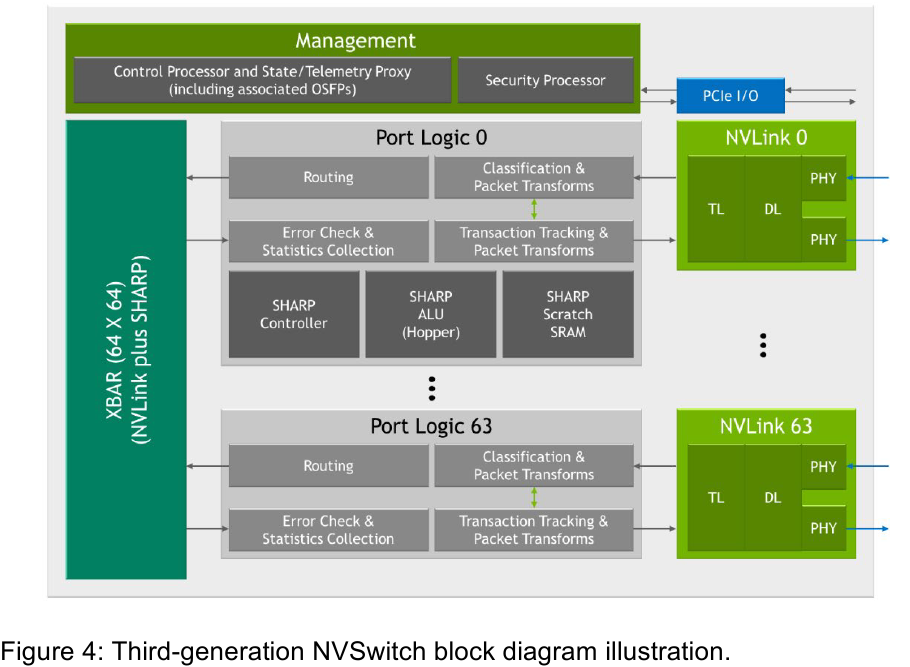 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 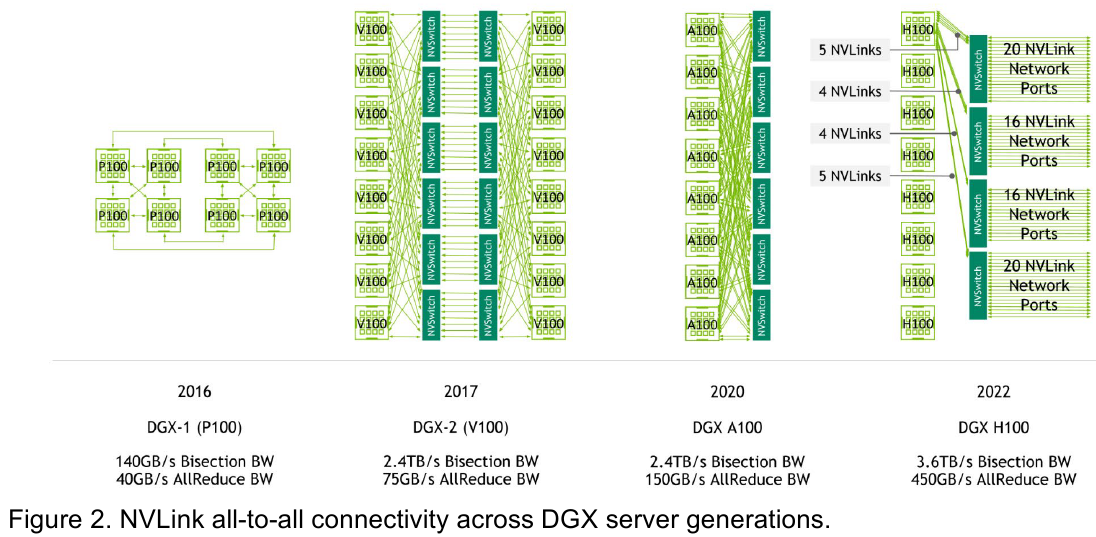 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 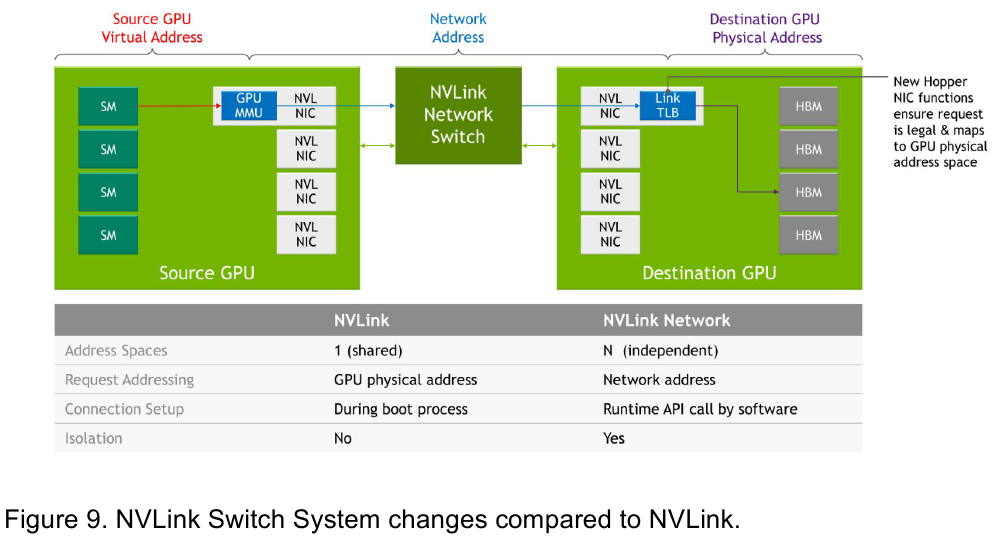 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
28.04.2022 [22:54], Алексей Степин
Chelsio представила седьмое поколение сетевых чипов Terminator: 400GbE и PCIe 5.0 x16Компания Chelsio Communications анонсировала седьмое поколение своих сетевых процессоров Terminator с поддержкой 400GbE. От предшественников T7 отличает более развитая вычислительная часть общего назначения, включающая в себя до 8 ядер Arm Cortex-A72, так что их уже можно назвать DPU. Всего представлено пять вариантов 5 чипов (T7, N7, D7, S74 и S72), которые различаются между собой набором движков и ускорителей. Референсная платформа T7 будет доступна в мае, первых же адаптеров на базе новых DPU следует ожидать в III квартале 2022 года. Для задач сжатия, дедупликации или криптографии есть отдельные сопроцессоры. Никуда не делся и привычный для серии Unified Wire встроенный L2-коммутатор. Для подключения к хосту T7 теперь использует шину PCIe 5.0 x16, причём он же содержит и root-комплекс. Более того, имеется и набортный коммутатор+мост PCIe 4.0, и NVMe-интерфейс, и даже поддержка эмуляции NVMe. Всё это, к примеру, позволяет легко и быстро создать NVMe-oF хранилище или мост NVMe-NVMe для компрессии и шифрования данных на лету. Новинка предлагает ускорение работы RoCEv2 и iWARP, FCoE и NVMe/TCP, iSCSI и iSER, а также RAID5/6. Сетевая часть поддерживает разгрузку Open vSwitch и Virt-IO. 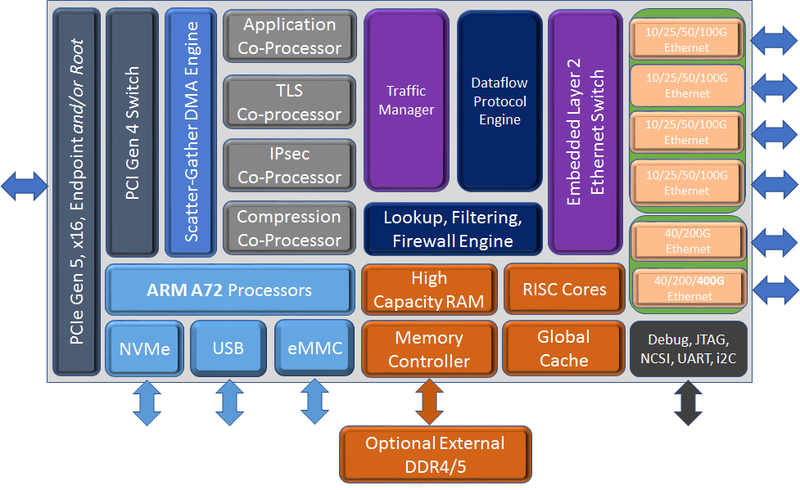
Блок-схема старшего варианта T7 (Изображения: Chelsio Communcations) Впрочем, поддержки P4 тут нет — Chelsio продолжает использовать собственные движки для обработки трафика. Но наработки, сделанные для серий T5 и T6, будет проще перенести на новое поколение чипов. Кроме того, появилась и практически обязательная нынче «глубокая» телеметрия всего проходящего через DPU трафика для повышения управляемости и его защиты. Если и этого окажется мало, то к T7 (и D7) можно напрямую подключить FPGA, а набортную память расширить банками DDR4/5. В пресс-релизе также отмечается, что T7 сможет стать достойной заменой InfiniBand в HРC-системах. 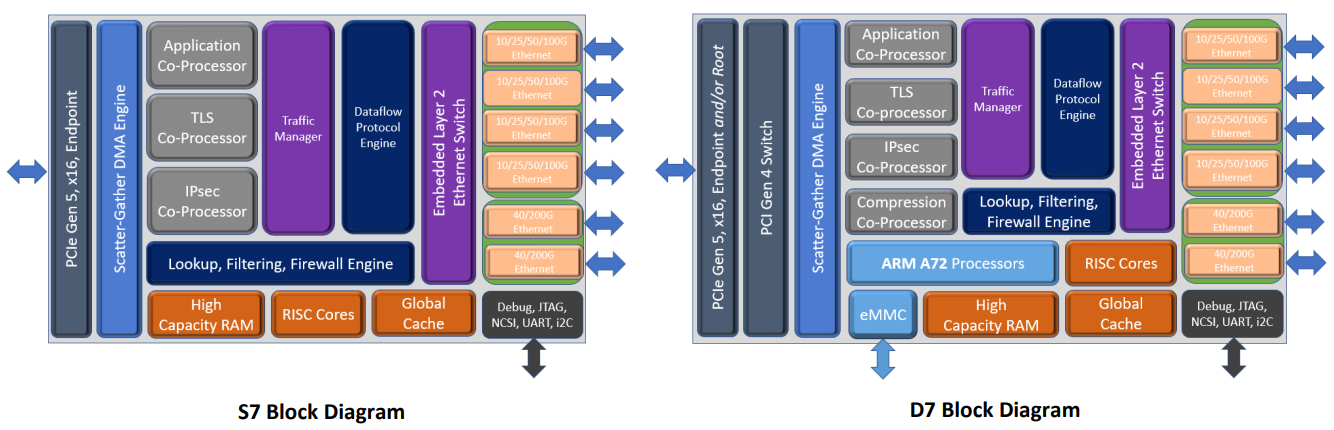 Вариант D7 наиболее близок к T7, но предлагает только 200GbE-подключение, лишён некоторых функций и второстепенных интерфейсов, да и в целом рассчитан на создание СХД. N7, напротив, лишён Arm-ядер и всех функций для работы с хранилищами, нет у него и PCIe-коммутатора и моста. Предлагает он только 200GbE-интерфейсы. Наконец, чипы серии S7 лишены целого ряда второстепенных функций и предоставляют только 100/200GbE-подключение. Они относятся скорее к SmartNIC, поскольку начисто лишены Arm-ядер и некоторых функций. Но зато они и недороги. Кроме того, в седьмом поколении Termintator появилась возможность обойтись без набортной DRAM с сохранением всей функциональности. Так что использование памяти хоста позволит дополнительно снизить стоимость конечных решений, которые будут создавать OEM-производители. Сами чипы производятся с использованием техпроцесса TSMC 12-нм FFC, так что даже у старшей версии чипов типовое энергопотребление не превышает 22 Вт.
30.06.2021 [22:44], Алексей Степин
Marvell анонсировала 5-нм DPU Octeon 10: 36 ядер ARM Neoverse N2, 400GbE, PCIe 5.0 и DDR5Концепция ускорителя для работы с данными, выделенного DPU, продолжает набирать популярность. В последнее время целый ряд компаний представил свои решения. А на днях очередь дошла до крупного разработчика микроэлектроники, компании Marvell, которая анонсировала DPU серии Octeon 10. Новые сопроцессоры построены на основе наиболее совершенного 5-нм техпроцесса TSMC и должны на равных сражаться с такими соперниками, как ускорители NVIDIA BlueField. Сама Marvell известна разработкой собственных вычислительных ядер, однако в Octeon 10 от этого подхода компания отошла, вернувшись к лицензированию ядер ARM — в основу новой серии чипов легли ядра Neoverse N2. 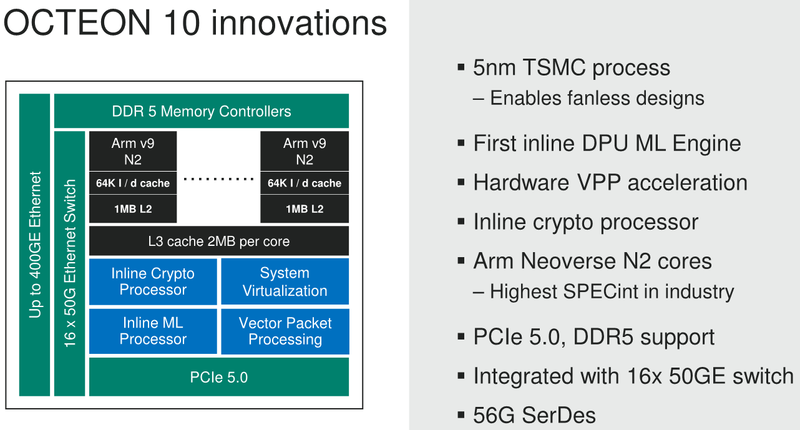 В основе данной архитектуры лежит набор команд ARM v9, появившийся не так уж давно. В сравнении с решениями на базе ARM v8.x эта архитектура может обеспечивать до 40% прироста в производительности, в том числе, за счёт поддержки 128-битных векторных расширений SVE2 и развитой подсистемы кешей. Процессорные ядра в Octeon 10 располагают по 1 и 2 Мбайт кешей второго и третьего уровня на каждое ядро. 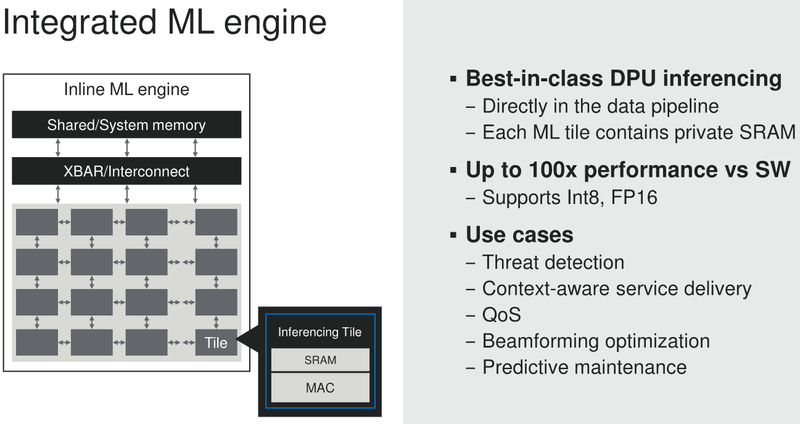 В составе новой SoC также присутствуют блоки ускорения сетевых задач и криптографические акселераторы. Кроме этого, кремний Octeon 10 получил и сетевой коммутатор, обеспечивающий работу 16 портов Ethernet со скоростью 50 Гбит/с. «Прокормить» столь требовательную «семью» непросто, но в плане подсистем ввода-вывода новые DPU также отвечают современным реалиям: они рассчитаны на работу с памятью DDR5-5200 и поддерживают интерфейс PCI Express 5.0, блоки SerDes относятся к поколению 56G. 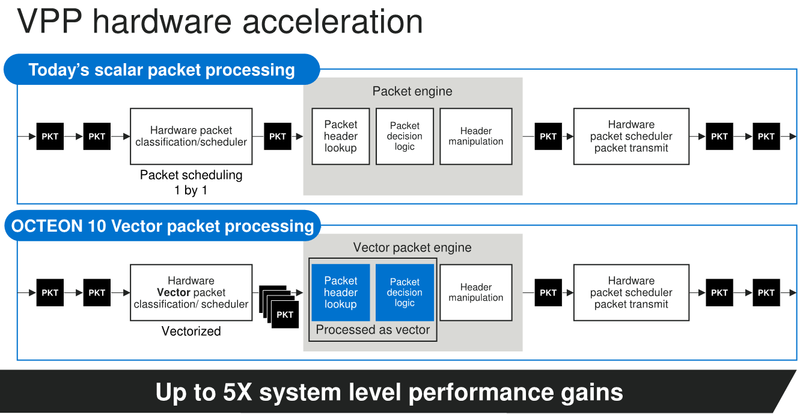 Отдельного упоминания заслуживает движок векторной обработки пакетов (Vector Packet Processing Engine), способный объединять в единую серию сетевые пакеты и «переваривать» их одновременно, как векторные данные. Такой подход позволяет серьёзно снизить латентность, что для DPU очень важно. Имеются в составе Octeon 10 и средства для работы с алгоритмами машинного обучения, причём каждый «тайл», поддерживающий INT8 и FP16, имеет свой объём SRAM. 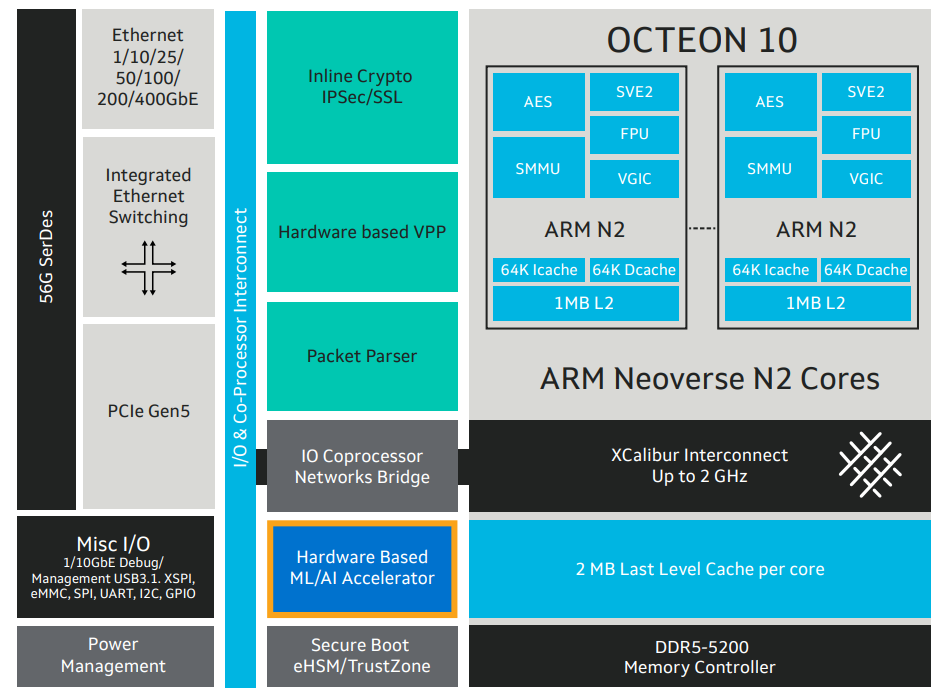 Пока семейство Octeon 10 представлено четырьмя моделями, младшая из которых может содержать до 8 ядер Neoverse N2, а старшая — до 36 таких ядер, причём о масштабировании подсистемы памяти разработчики также подумали и число контроллеров DDR5 в новых чипах варьируется от 2 до 12. Несмотря на столь солидные характеристики, теплопакеты удалось удержать в разумных рамках, и даже у наиболее мощной версии DPU400 TDP составляет всего 60 Ватт. 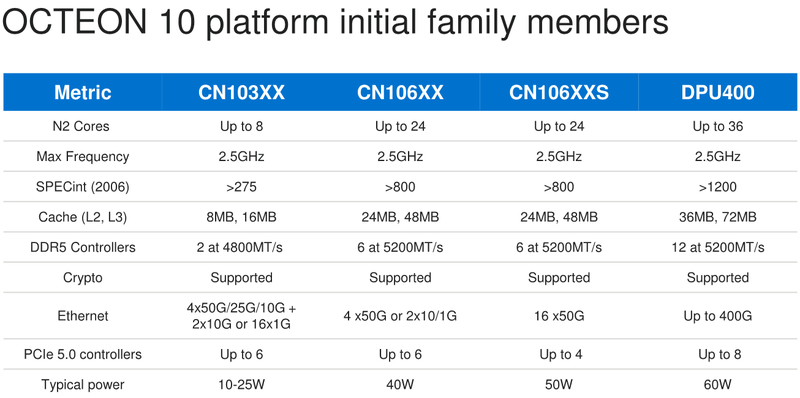 В настоящее время Marvell Octeon 10 уже находится в производстве, первые же партии новых чипов должны поступить к заказчикам во второй половине этого года. Столь многогранные DPU должны найти применение в самых разных сценариях, от поддержания инфраструктуры 5G RAN до работы в составе облачных систем, а также в высокопроизводительных маршрутизаторах.
12.04.2021 [19:21], Алексей Степин
NVIDIA анонсировала DPU BlueField-3: 400 Гбит/с, 16 ядер Cortex-A78 и PCIe 5.0Идея «сопроцессора данных», озвученная всерьёз в 2020 году компанией Fungible, продолжает активно развиваться и прокладывать себе дорогу в жизнь. На конференции GTC 2021 корпорация NVIDIA анонсировала новое поколение «умных» сетевых карт BlueField-3, способное работать на скорости 400 Гбит/с. Изначально серия ускорителей BlueField разрабатывалась компанией Mellanox, и одной из целей создания столь продвинутых сетевых адаптеров стала реализация концепции «нулевого доверия» (zero trust) для сетевой инфраструктуры ЦОД нового поколения. Адаптеры BlueField-2 были анонсированы в начале прошлого года. Они поддерживали два 100GbE-порта, микросегментацию, и могли осуществлять глубокую инспекцию пакетов полностью автономно, без нагрузки на серверные ЦП. Шифрование TLS/IPSEC такие карты могли выполнять на полной скорости, не создавая узких мест в сети. 
Кристалл BlueField-3 не уступает в сложности современным многоядерным ЦП — 22 млрд транзисторов Но на сегодня 100 и даже 200 Гбит/с уже не является пределом мечтаний — провайдеры и разработчики ЦОД активно осваивают скорости 400 и 800 Гбит/с. Столь скоростные сети требуют нового уровня производительности от DPU, и NVIDIA вскоре сможет предложить такой уровень: на конференции GTC 2021 анонсировано новое, третье поколение карт BlueField. 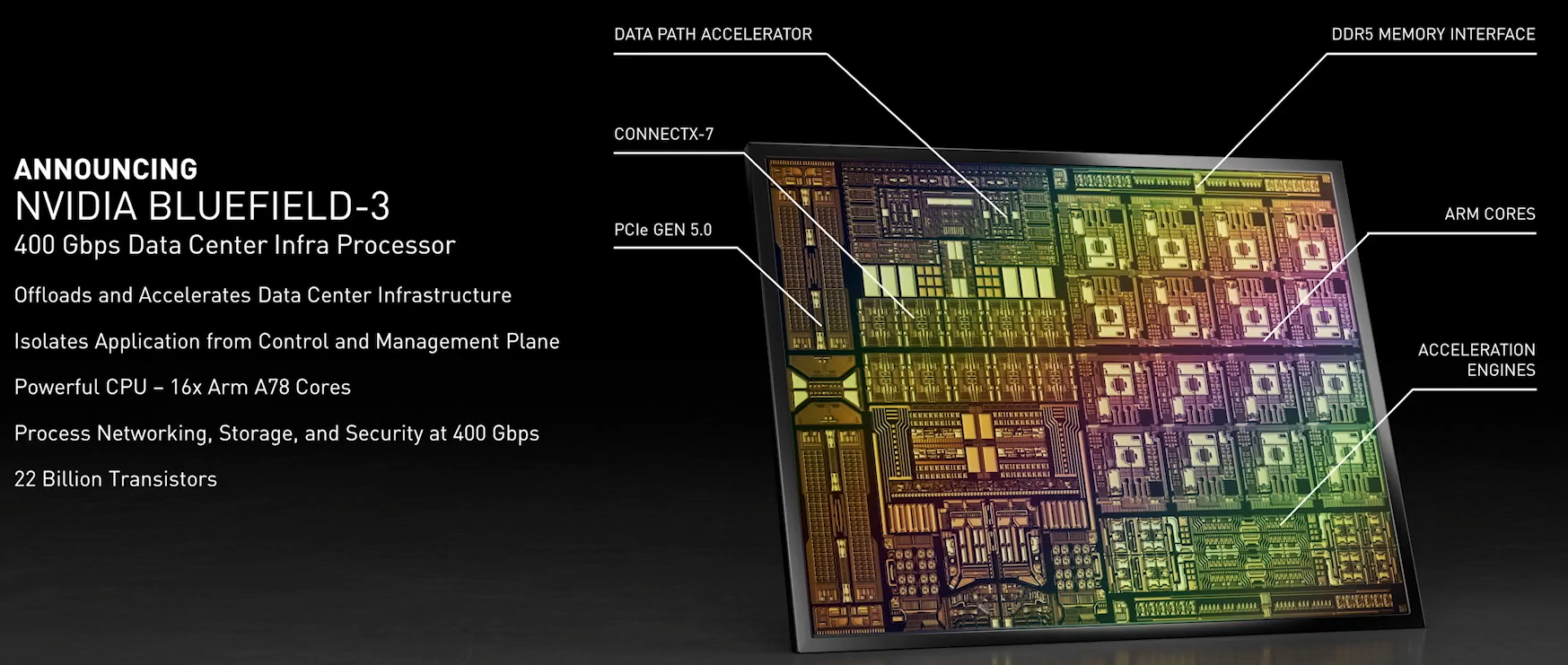 Если BlueField-2 могла похвастаться массивом из восьми ядер ARM Cortex-A72, объединённых когерентной сетью, то BlueField-3 располагает уже шестнадцатью ядрами Cortex-A78 и в четыре раза более мощными блоками криптографии и DPI. Совокупно речь идёт о росте производительности на порядок, что позволяет новинке работать без задержек на скорости 400 Гбит/с — и это первый в индустрии адаптер класса 400GbE со столь продвинутыми возможностями, поддерживающий, к тому же, стандарт PCI Express 5.0. Известно, что столь быстрым сетевым решениям PCIe 5.0 действительно необходим.  С точки зрения поддерживаемых возможностей BlueField-3 обратно совместим с BlueField-2, что позволит использовать уже имеющиеся наработки в области программного обеспечения для DPU. Одновременно с анонсом нового DPU компания представила и открытую программную платформу DOCA, упрощающую разработку ПО для таких сопроцессоров, поскольку они теперь занимаются не просто обработкой сетевого трафика, а оркестрацией работы серверов, приложений и микросервисов в рамках всего дата-центра. 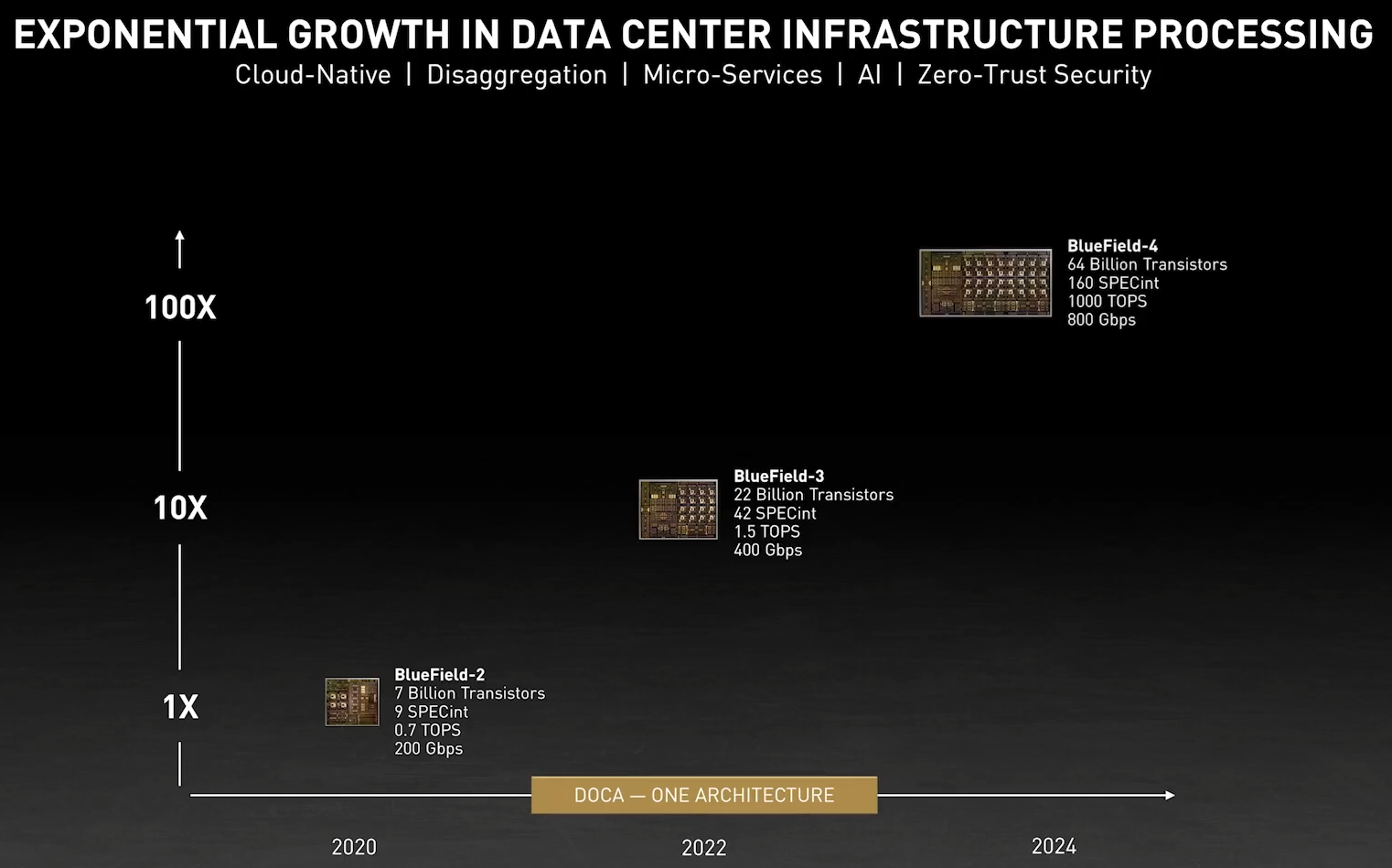 В настоящее время NVIDIA сотрудничает с такими крупными поставщиками серверных решений, как Dell EMC, Inspur, Lenovo и Supermicro, со стороны разработчиков ПО интерес к BlueField проявляют Canonical, VMWare, Red Hat, Fortinet, NetApp и ряд других компаний. О массовом производстве BlueField-3 речи пока не идёт, поставка малыми партиями ожидается в первом квартале 2022 года, но карты BlueField-2 доступны уже сейчас. А в 2024 году появятся BlueField-4 с портами 800 Гбит/с. |
|

