Материалы по тегу: ии
|
20.11.2024 [10:59], Сергей Карасёв
Nebius, бывшая Yandex, развернёт в США своей первый ИИ-кластер на базе NVIDIA H200Nebius, бывшая материнская компания «Яндекса», объявила о создании своего первого вычислительного ИИ-кластера на территории США. Система будет развёрнута на базе дата-центра Patmos в Канзас-Сити (штат Миссури), а её ввод в эксплуатацию запланирован на I квартал 2025 года. На начальном этапе в составе кластера Nebius будут использоваться ИИ-ускорители NVIDIA H200. В следующем году планируется добавить решения поколения NVIDIA Blackwell. Мощность площадки может быть увеличена с первоначальных 5 МВт до 40 МВт: это позволит задействовать до 35 тыс. GPU. По заявлениям Nebius, фирма Patmos была выбрана в качестве партнёра в связи с гибкостью и опытом в поэтапном строительстве ЦОД. Первая фаза проекта включает развёртывание необходимой инфраструктуры, в том числе установку резервных узлов, таких как генераторы. Новая зона доступности, как ожидается, позволит Nebius более полно удовлетворять потребности американских клиентов, занимающихся разработками и исследованиями в области ИИ. 
Источник изображения: Nebius Говорится, что Nebius активно наращивает присутствие в США в рамках стратегии по формированию ведущего поставщика инфраструктуры для ИИ-задач. На 2025 год намечено создание второго — более масштабного — кластера GPU в США. Кроме того, компания открыла два центра по работе с клиентами — в Сан-Франциско и Далласе, а третий офис до конца текущего года заработает в Нью-Йорке. Напомним, что ранее Nebius запустила первый ИИ-кластер во Франции на базе NVIDIA H200. У компании также есть площадка в Финляндии. К середине 2025 года Nebius намерена инвестировать более $1 млрд в инфраструктуру ИИ в Европе. А около месяца назад компания представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200.
20.11.2024 [01:40], Владимир Мироненко
Microsoft представила кастомные чипы Azure Boost DPU и Integrated HSM, уникальный AMD EPYC 9V64H с HBM и собственный вариант NVIDIA GB200 NVL72
amd
azure arc
azure stack
dpu
epyc
gb200
hardware
hbm
hpc
microsoft
microsoft azure
nvidia
гибридное облако
ии
информационная безопасность
облако
ускоритель
Microsoft представила на конференции Microsoft Ignite новые специализированные чипы Azure Boost DPU и Azure integrated Hardware Security Module (HSM), предназначенные для использования в ЦОД с целью поддержки рабочих нагрузок в облаке Azure и повышения безопасности. 
Источник изображений: Microsoft Чтобы снизить зависимость от поставок чипов сторонних компаний, Microsoft занимается разработкой собственных решений для ЦОД. Например, на прошлогодней конференции Microsoft Ignite компания представила Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100 собственной разработки. Azure Boost DPU включает специализированные ускорители для работы с сетью и хранилищем, а также предлагает функции безопасности. Так, скорость работы с хранилищем у будущих инстансов Azure будет вчетверо выше, чем у нынешних, а энергоэффективность при этом вырастет втрое.  Не вызывает сомнений, что в разработке Azure Boost DPU участвовали инженеры Fungible, производителя DPU, который Microsoft приобрела в декабре прошлого года. Как отмечает TechCrunch, в последние годы популярность DPU резко увеличилась. AWS разработала уже несколько поколений Nitro, Google совместно с Intel создала IPU, AMD предлагает DPU Pensando, а NVIDIA — BlueField. Есть и другие нишевые игроки. Согласно оценкам Allied Analytics, рынок чипов DPU может составить к 2031 году $5,5 млрд.  Ещё один кастомный чип — Azure integrated Hardware Security Module (HSM) — отвечает за хранение цифровых криптографических подписей и ключей шифрования в защищённом модуле «без ущерба для производительности или увеличения задержки». «Azure Integrated HSM будет устанавливаться на каждом новом сервере в ЦОД Microsoft, начиная со следующего года, чтобы повысить защиту всего парка оборудования Azure как для конфиденциальных, так и для общих рабочих нагрузок», — заявила Microsoft. Azure Integrated HSM работает со всем стеком Azure, обеспечивая сквозную безопасность и защиту.  Microsoft также объявила, что задействует ускорители NVIDIA Blackwell и кастомные серверные процессоры AMD EPYC. Так, инстансы Azure ND GB200 v6 будут использовать суперускорители NVIDIA GB200 NVL 72 в собственном исполнении Microsoft, а интерконнект Quantum InfiniBand позволит объединить десятки тысяч ускорителей Blackwell. Компания стремительно наращивает закупки этих систем. А инстансы Azure HBv5 получат уникальные 88-ядерные AMD EPYC 9V64H с памятью HBM, которые будут доступны только в облаке Azure. Каждый инстанс включает четыре таких CPU и до 450 Гбайт памяти с агрегированной пропускной способностью 6,9 Тбайт/с.  Кроме того, Microsoft анонсировала новое решение Azure Local, которое заменит семейство Azure Stack. Azure Local — это облачная гибридная инфраструктурная платформа, поддерживаемая Azure Arc, которая объединяет локальные среды с «большим» облаком Azure. По словам компании, клиенты получат обновление до Azure Local в автоматическом режиме. Наконец, Microsoft анонсировала новые возможности в Azure AI Foundry, новой «унифицированной» платформе приложений ИИ, где организации смогут проектировать, настраивать и управлять своими приложениями и агентами ИИ. В числе новых опций — Azure AI Foundry SDK (пока в виде превью).
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 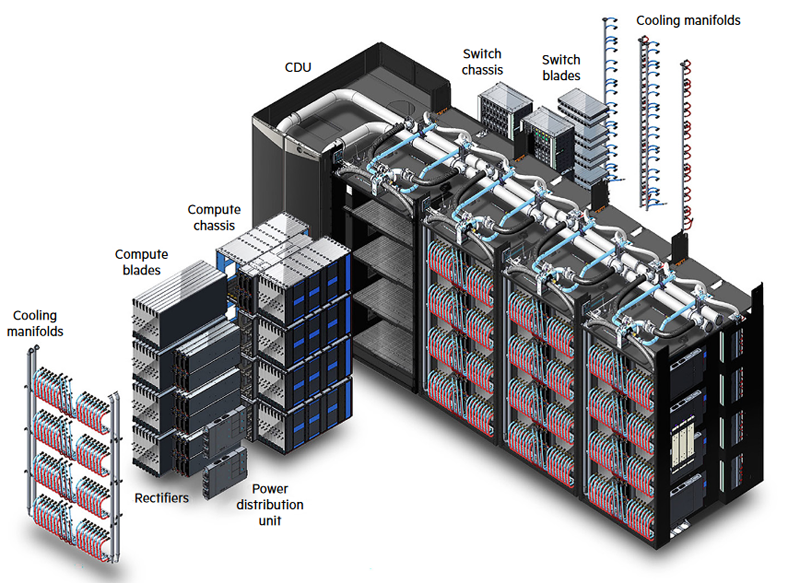 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
19.11.2024 [14:53], Владимир Мироненко
UserGate представила новую серию межсетевых экранов DCFW и первый российский NGFW с FPGA-ускорителемКомпания UserGate представила новую серию межсетевых экранов DCFW (Data Center Firewall) — высокопроизводительных программно-аппаратных комплексов, разработанных для обеспечения надёжной защиты масштабной инфраструктуры уровня ЦОД. Новая серия включает модель UserGate FG с FPGA-модулем, а также модели E1010, E3010, F8010 и G9300. Новинки по соотношению Мбит/с на рубль почти вдвое опережают решения конкурентов. Межсетевой экран E1010 приходит на смену модели E1000. По оценкам компании, E1010 превосходит предшественника по скорости примерно на 40 %. В свою очередь, E3010 заменит модель E3000, превосходя её по скорости примерно в два раза. Отличительной чертой обеих моделей является наличие четырёх модулей расширения, которые позволяет гибко сконфигурировать интерфейсы: RJ45, SFP, SFP+, QSFP. Производительность E1010 в режиме FW L3/L4 — 38 Гбит/с, у E3010 — 70 Гбит/с; с функцией L7-фильтрации (трафик EMIX) производительность составляет 16 Гбит/с, у E3010 — 40 Гбит/с. С функцией L7-фильтрации и системой предотвращения вторжений (IPS) у E1010 производительность равна 5 Гбит/с, у E3010 — 18 Гбит/с. 
Источник изображений: UserGate С набором опций NGFW (FW+DPI+IPS+CF) у E1010 производительность составляет 1 Гбит/с, у E3010 — 2,5 Гбит/с. У E1010 максимальное число одновременных сессий в секунду (CPS) — 100 тыс.; 180 тыс. — у E3010. Максимальное количество одновременных TCP-сессий — 4 млн у E1010 и 12 млн у E3010.   Производительность модели F8010 составляет: в режиме FW L3/L4 — 80 Гбит/с, с функцией L7-фильтрации (трафик EMIX) — 47 Гбит/с, с функцией L7-фильтрации и системой предотвращения вторжений (IPS) равна 30 Гбит/с, с набором опций NGFW (FW+DPI+IPS+CF) — 3,5 Гбит/с. Максимальное число сессий в секунду (CPS) составляет 320 тыс., максимальное количество одновременных TCP сессий — 24 млн. Модель F8010 вышла на замену F8000.  F8010 имеет высоту 2U и предлагает сразу восемь посадочных мест для модулей сетевых портов (RJ45, SFP, SFP+, QSFP). Межсетевой экран F8010 уже внесён в реестр российской промышленной продукции Минпромторга России, а E1010 и E3010 будут внесены в этом месяце. В реестр попал и ещё один, уникальный для российского рынка продукт — UserGate FG, высокопроизводительный программно-аппаратный комплекс, разработанный для обеспечения безопасности высоконагруженных систем и объектов КИИ как коммерческих, так и государственных предприятий.  UserGate FG подходит для защиты ядра сети, объединения всех зон безопасности и обеспечения безопасного прохождения трафика между сегментами. Благодаря способности обрабатывать огромное количество трафика UserGate FG, в том числе т.н. потоков Elephant Flow, например, с IP-камер, он подойдёт для защиты высоконагруженных систем, таких как целый ЦОД, инфраструктура телеком-операторов и т.д. 1U-шасси UserGate FG предлагает 16 10GbE-портов SFP+ и пару 100GbE-портов QSFP28.  Пропускная способность модуля FW (L3/L4) у UserGate FG достигает рекордного значения в 150 Гбит/с на трафике UDP с пакетами 1518 байт и 90 Гбит/с на трафике EMIX. С функцией L7-фильтрации (трафик EMIX) производительность составляет 45 Гбит/с (со II квартала 2025 года), с функцией L7-фильтрации и системой предотвращения вторжений (IPS) она равна 25 Гбит/с (со II квартала 2025 года). Максимальное число сессий в секунду (CPS) составляет 84 тыс., максимальное количество одновременных TCP сессий — 22 млн.
Секрет высокой производительности UserGate FG кроется в использовании FPGA. При поступлении сетевого потока на CPU лишь формируется правило для обработки трафика, после чего поток направляется на FPGA и в дальнейшем минует CPU. Впрочем, пока есть некоторые ограничения. На сегодня доступна работа с 10 тыс. правил межсетевого экрана. Ко II кварталу 2025 года на FPGA будут переведены функции FW L7 и IPS, а количество правил доведено до 131 тыс., т.е. как у всех остальных новинок серии DCFW. Свежие прошивки для FPGA будут поставляться вместе с обновлениями программной платформы.  UserGate FG можно использовать как отдельно, так и с другими новыми платформами компании. Это позволяет отделить control plane от data plane и легко масштабировать производительность. Одна из новинок серии DCFW, модель G9300, как раз и представляет собой комбинацию моделей E3010 и FG, которая управляется как единое целое. Её производительность достигает 200 Гбит/с для FW L3/L4 на трафике TCP/UDP с пакетами 1518 байт и 30 Гбит/с — для функций FW L7 + IPS на трафике EMIX. Результаты получены при применении 10 тыс. правил файрвола и 8 000 сигнатур и приложений IPS. Максимальное количество одновременных TCP-сессий – 24 млн, новых сессий (CPS) — 400 тыс. в секунду.  Во II квартале 2025 года появятся модели G9100 (E1010+FG) и G9800 (F8010+FG). Но в целом будет доступна возможность докупить и объединить E1010/3010, F8010 или FG для формирования G9100/9300/9800, а также объединение нескольких устройств серии G в отказоустойчивый кластер. Серия DCFW изначально поддерживает формирование кластеров Active–Passive на два узла или Active–Active на два, три или четыре узла. Есть поддержка OSPF/BGP/RIP/PIM, а также PBR/VRF/ECMP/BFD. Доступны VLAN, WCCP, DHCP. 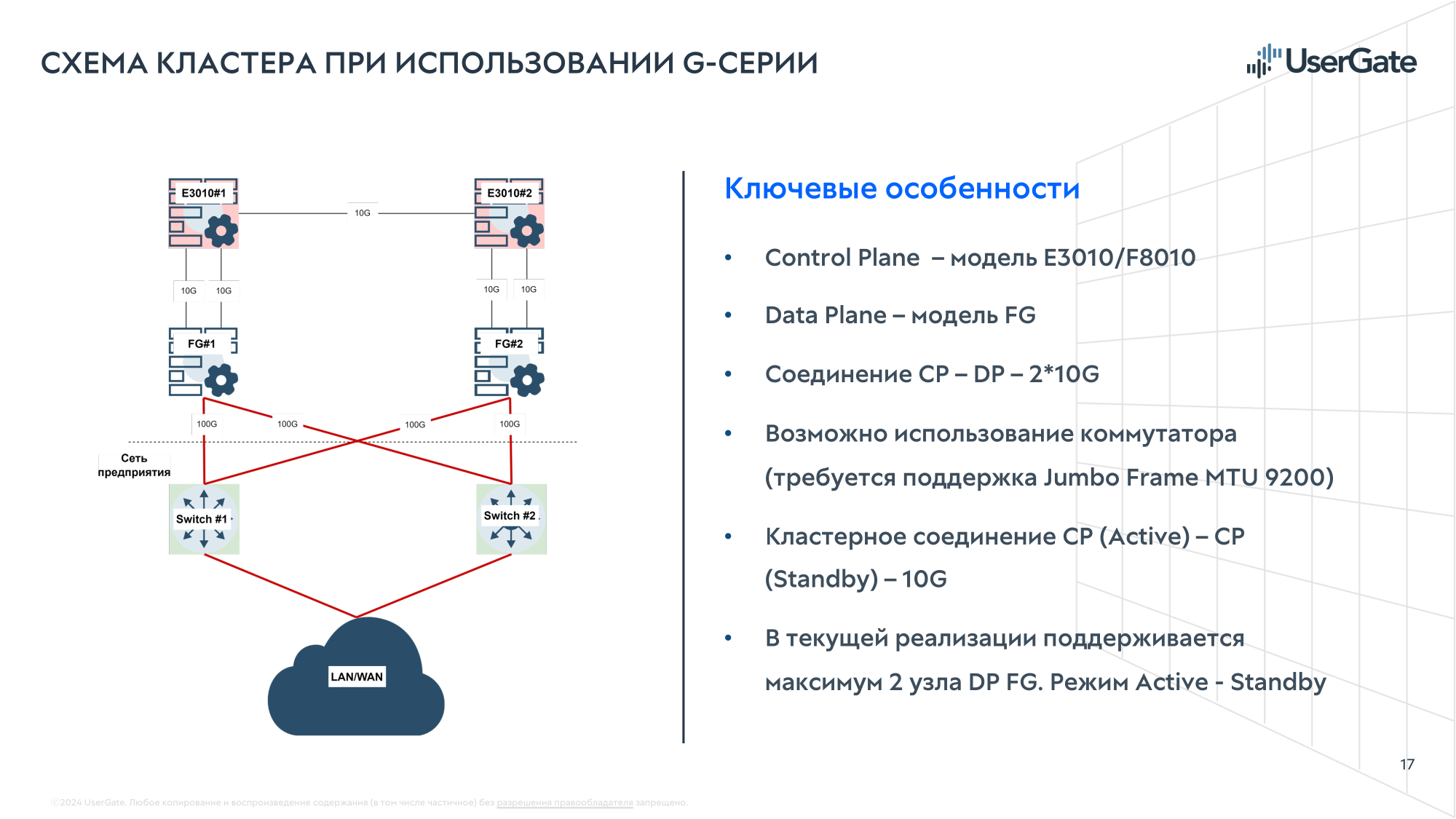 Отличительной чертой DCFW является функция Identity Firewall, т.е. возможность идентифицировать пользователя и генерируемый им трафик. По словам компании, ни один другой отечественный NGFW такую функцию предложить не может. Кроме того, в DCFW реализована функция виртуальных систем, позволяющая разделить ПАК на отдельные, независимо управляемые сегменты. Правда, для модели FG поддержка этой функции появится в I квартале 2025 года, а возможность разгрузки трафика таких виртуальных систем на FPGA появится ближе к середине года. 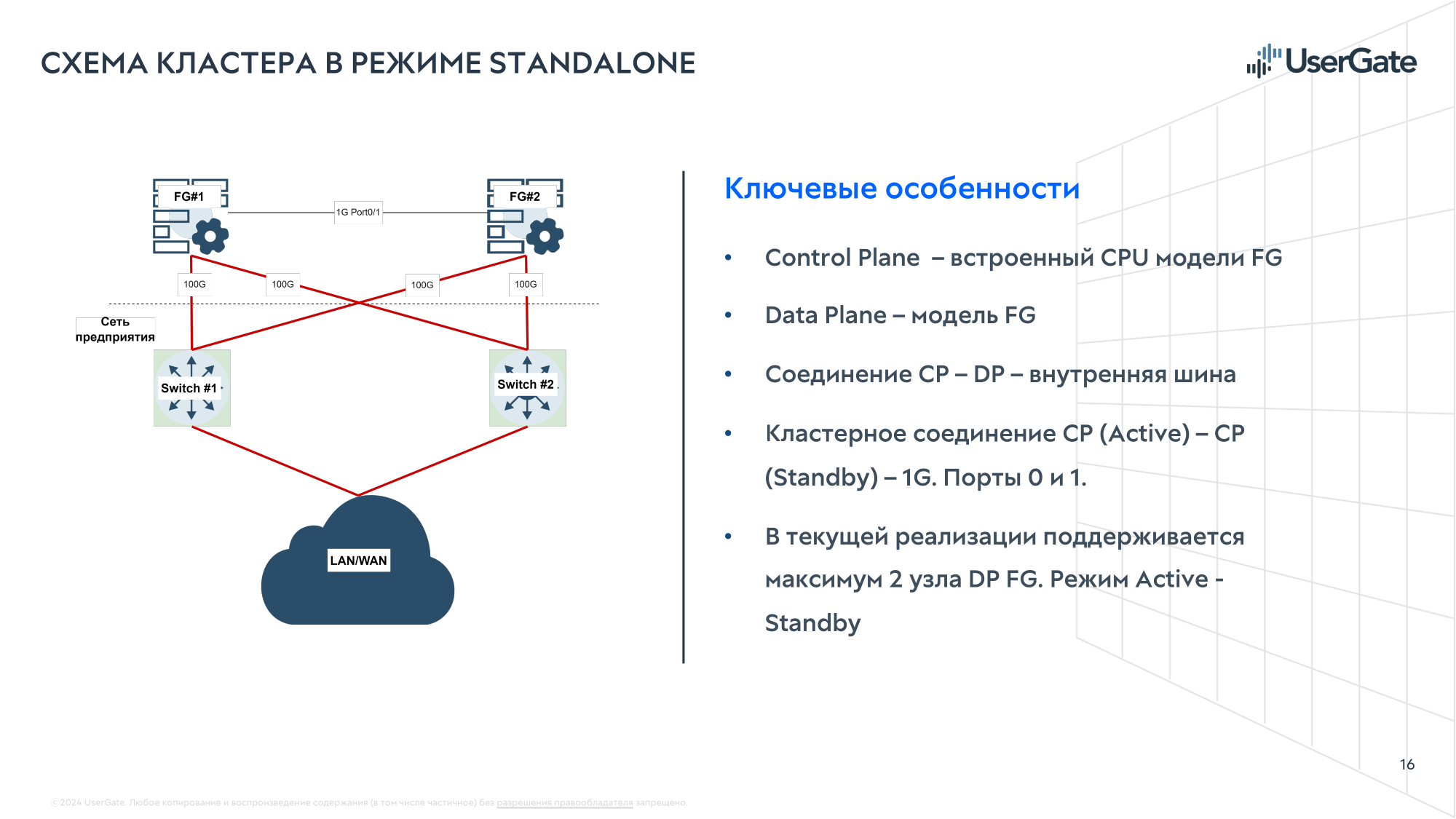 Централизованное управление всеми устройствами UserGate осуществляется с помощью отдельного решения UserGate Management Center, поддерживающее управление всей экосистемой продуктов UserGate SUMMA (NGFW, DCFW, SIEM, Log Analyzer, Client). Реализованы мультитенантность, гибкая ролевая модель и возможность создания отказоустойчивого кластера. Доступно управление более 10 тыс. устройств. В целом, экосистема компании готова к интеграции практически в любую инфраструктуру.  Компания гордится тем, что разрабатывает и производит свои решения на территории России, в Новосибирске. Это обеспечивает полный контроль над аппаратными платформами, снижает санкционные риски и позволяет в более полной мере удовлетворить все требования в области импортозамещения. Кроме того, это даёт большую свободу при разработке и возможность учесть реальные требования заказчиков. В частности, в серии DCFW есть BMC для управления платформой и используются блоки питания и вентиляторы с поддержкой «горячей» замены. Вентиляторы могут работать и на вдув, и на выдув — их UserGate разработала сама. С 25 ноября 2024 года по предзаказу будет доступна модель UserGate FG, а остальные новинки с функциональностью в полном объёме будут доступны со II квартала 2025 года.
19.11.2024 [12:57], Руслан Авдеев
Dell отобрала у Supermicro крупный заказ на ИИ-серверы для xAI Илона МаскаОснованный Илоном Маском (Elon Musk) стартап xAI, похоже, отнял все прежние заказы на ИИ-серверы у испытывающей не лучшие времена Supermicro, чтобы передать их её конкурентам. Как сообщает UDN, выгодоприобретателями станет Dell, а также её партнёры Inventec и Wistron. Для Supermicro, которой и без того грозит делистинг с Nasdaq, это станет очередным ударом. Ранее Dell и Supermicro поставляли оборудования компаниям Илона Маска, в т.ч. xAI и Tesla. Официально сообщалось, что xAI закупила ИИ-серверы с жидкостным охлаждением у Supermicro. Но после того, как Министерство юстиции США начало расследование деятельности поставщика в связи с вероятными махинациями с бухгалтерской отчётностью и нарушением санкционного режима, акции компании обрушились. После этого, по данным UDN, компании Маска и приняли решения передать заказы другим исполнителям. Среди поставщиков ИИ-серверов у Dell хорошие возможности получения заказов. Например, Wistron выпускает материнские платы для ИИ-серверов компании и выполняет некоторые задачи по сборке — партнёры станут одними из основных бенефициаров краха Supermicro. Фактически Wistron уже расширяет производственные мощности для удовлетворения спроса, в частности на трёх заводах на Тайване, а также в Мексике. В Wistron смотрят в будущее с большим оптимизмом и ожидают, что спрос на ИИ-серверы будет расти «трёхзначными» значениями в процентном отношении. 
Источник изображения: Bermix Studio/unsplash.com Inventec также является крупным поставщиком Dell и тоже получит свою долю «пирога» от заказа Supermicro. Компания давно участвует в производстве ИИ-систем и входит в тройку ведущих партнёров Dell, участвующих в сборке серверов. В 2024 году компания поставляла машины на чипах семейства NVIDIA Hopper, но в I квартале 2025 года она сможет поставлять уже варианты на платформе NVIDIA Blackwell — с ускорителями B200 и B200A. Считается, что у компании есть свободные производственные мощности в Мексике, поэтому она сможет нарастить выпуск ИИ-серверов для компаний, ранее работавших с Supermicro. 
Фото: Michael Dell Одной из ключевых причин проблем Supermicro считается задержка с подачей финансовых документов, из-за чего компания рискует покинуть биржу Nasdaq. Чтобы избежать делистинга, Supermicro должна была объяснить задержки с подачей материалов и подать доклад по форме K-10 к 16 ноября, но сделать этого не успела. Впрочем, первые неприятности у Supermicro начались значительно раньше, когда Hindenburg Research опубликовала разгромный доклад о финансовой отчётности компании. Если Supermicro дождётся делистинга на бирже, это приведёт к серьёзными финансовыми последствиями, включая стремительное падение акций и необходимость немедленного погашения долга $1,725 млрд по конвертируемым облигациям — обычно такие «триггеры» учитываются в соглашениях и активируются при делистинге. Буквально на днях сообщалось, что Supermicro лишилась заказа от индонезийской YTL Group (YTLP) на поставку суперускорителей NVIDIA GB200 NVL72 для одного из крупнейших в Юго-Восточной Азии ИИ-суперкомпьютеров. Теперь поставками будет заниматься только Wiwynn, которая принадлежит всё той же Wistron. При этом сама Wiwynn сейчас судится с X (Twitter), которой владеет Илон Маск.
19.11.2024 [11:47], Сергей Карасёв
Esperanto и NEC займутся созданием HPC-решений на базе RISC-VСтартап Esperanto Technologies и корпорация NEC объявили о заключении соглашения о сотрудничестве в области НРС. Речь идёт о создании программных и аппаратных решений следующего поколения, использующих открытую архитектуру RISC-V. Напомним, Esperanto разрабатывает высокопроизводительные RISC-V-чипы для задач НРС и ИИ. Первым продуктом компании стало изделие ET-SoC-1, которое объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. В августе 2023 года стало известно о подготовке чипа ET-SoC-2 с высокопроизводительными ядрами RISC-V с векторными расширениями. В рамках соглашения о сотрудничестве, как отмечается, будут объединены опыт и экспертизы NEC в области проектирования суперкомпьютеров и создания специализированного софта для HPC-задач с технологиями Esperanto в сфере высокопроизводительных энергоэффективных чипов на основе набора инструкций RISC-V. При этом упоминаются достижения NEC по направлению векторных процессоров: японская компания проектировала уникальные изделия SX-Aurora, но их разработка была остановлена в 2023 году. 
Источник изображения: Esperanto «Используя глубокий опыт и экспертные знания NEC в области HPC, а также открытый набор инструкций RISC-V в сочетании с вычислительной технологией Esperanto, мы сможем разрабатывать масштабируемые и эффективные решения для ИИ и высокопроизводительных вычислений», — отметил Арт Свифт (Art Swift), президент и генеральный директор Esperanto.
19.11.2024 [09:03], Андрей Крупин
Российский no-code-конструктор аналитических систем «Триафлай 5» получил множество доработокКомпания «Доверенная среда» (входит в IT-холдинг «Национальная компьютерная корпорация») выпустила усовершенствованную версию модульного no-code-конструктора аналитических систем «Триафлай» 5-го поколения. «Триафлай 5» представляет собой унифицированную среду для создания комплекса прикладных решений управления бизнес-показателями предприятий, корпораций, холдингов. Продукт позволяет систематизировать сбор, обработку, анализ, хранение и визуализацию больших объёмов данных, построение отчётности и поддержку принятия решений на основе моделирования и прогнозирования. Платформа зарегистрирована в реестре российского ПО и по функциональным возможностям способна составить альтернативу зарубежным системам IBM Cognos Analytics и SAP Business Intelligence. 
Источник изображения: triafly.ru В рамках развития возможностей «Триафлай 5» в платформу были встроены модули «Аналитика», «Управление данными», «Разработка», Process Mining и IoТ. Значительным доработка подверглись инструменты загрузки данных, отчётности, администрирования и визуализации. Были добавлены виртуальные коннекторы, конструктор аналитических корпоративных хранилищ данных. Конструктор OLAP-отчётов и дашбордов получил полностью обновлённый интерфейс. Не менее важным изменением «Триафлай 5» стала встроенная библиотека готовых решений, в настоящий момент включающая четыре программных продукта, предназначенных для подготовки управленческой отчётности, финансового планирования, управления рисками и внутреннего контроля бизнес-процессов. Отмечается, что с платформой уже работают такие известные интеграторы, как Glowbyte, Ramax International, Softline и другие.
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
18.11.2024 [20:15], Руслан Авдеев
Ключевыми клиентами ИИ-сервиса Microsoft Azure OpenAI стали Adobe и Meta✴, но крупнейшим заказчиком всё ещё остаётся TikTokХотя крупнейшим облачным клиентом сервисов Azure OpenAI компании Microsoft по-прежнему остаётся социальная сеть TikTok, облачный ИИ-провайдер активно диверсифицирует свой бизнес. В распоряжение The Verge попал список крупнейших клиентов Microsoft, получающих облачный доступ к большим языковым моделям (LLM) — как оказалось, более $1 млн/мес. на сервисы Azure OpenAI тратит не только TikTok. В десятку ключевых пользователей Azure OpenAI вошли Adobe и Meta✴, каждая из которых потратила более $1 млн только в сентябре 2024 года. Впрочем, компании по-прежнему отстают от TikTok, принадлежащей ByteDance. Ранее сообщалось, что TikTok платила Microsoft почти $20 млн/мес. за доступ к моделям OpenAI. По итогам IV квартале 2024 финансового года, завершившемся 30 июня, на TikTok пришлось почти четверть выручки Azure OpenAI. Теперь траты ByteDance на Azure OpenAI составляют менее 15 % всей выручки Microsoft в этом сегменте — расходы ByteDance падают, а других клиентов растут. Например, G42 из ОАЭ тратит на сервисы Azure OpenAI миллионы долларов ежемесячно, являясь вторым по величине пользователем соответствующего сервиса после ByteDance. Ранее в этом году Microsoft инвестировала $1,5 млрд в G42, поэтому, вероятно, последняя сохранит статус одного из ключевых пользователей Azure OpenAI. Ранее в этом году главным потребителем ИИ-сервисов Microsoft считалась американская торговая сеть Walmart, но теперь её нет даже в десятке. Список серьёзно меняется от месяца к месяцу, во многом потому, что клиенты Microsoft время от времени запускают или тестируют новые ИИ-проекты. Так, постоянным клиентом остаётся Intuit, хотя её расходы несопоставимы с затратами G42 или ByteDance. Компания занимается разработкой инструментов для финансового управления и обучает собственные ИИ-модели на клиентских данных. 
Источник изображения: Donald Giannatti/unsplash.com Также Microsoft удалось привлечь к сотрудничеству тесно связанную с Alibaba компанию Ant Group, которая потратила на Azure OpenAI как минимум $1 млн. Среди ключевых клиентов есть и пекинская Sankuai Technology, а всего в десятку самых «дорогих» клиентов в сентябре вошли сразу три китайские компании. В Microsoft информацию не комментируют. В компании лишь отметили, что Azure OpenAI — один из самых быстрорастущих сервисов Azure за всю историю, которым уже пользуются 60 тыс. организаций по всему миру. За последние месяцы рост сервиса удвоился. Microsoft также продаёт лицензии Copilot для бизнеса, обеспечивающие ИИ-сервисы, например, в офисных приложениях. По данным самой компании, 70 % компаний из рейтинга Fortune 500 так или иначе пользуются Microsoft 365 Copilot. Скоро выручка ИИ-бизнеса Microsoft превысит $10 млрд в год. В Microsoft утверждают, что это будет самый быстрый в истории бизнес, достигший подобного показателя. Но пока затраты довольно велики, так что инвесторы внимательно наблюдают за показателями Azure OpenAI и Microsoft 365 Copilot. Microsoft уже не хватает ресурсов для обработки ИИ, но компания готова вкладывать деньги в новые ЦОД.
18.11.2024 [18:42], Руслан Авдеев
CoreWeave добилась оценки в $23 млрд после вторичной продажи акций, среди инвесторов — Pure StorageОператор ИИ-облака CoreWeave завершил вторичную продажу акций на $650 млн. По данным инсайдеров, теперь компания оценивается в $23 млрд, сообщает Blocks & Files. Ведущими инвесторами стали Jane Street, Magnetar, Fidelity Management и Macquarie Capital, Cisco и, наконец, Pure Storage, на сотрудничество с которой у CoreWeave большие планы. В ходе вторичной продажи акций существующие инвесторы продали свои акции новым. По данным источников, близких к информации о сделке, капитализация CoreWeave за год выросла с $7 млрд до $23 млрд. В мае 2024 года компания оценивалась в $19 млрд после раунда финансирования серии C, лидером которого стала частная инвестиционная компания Coatue. Ожидается, что CoreWeave выйдет на IPO в следующем году. Что касается участия поставщика All-Flash СХД Pure Storage, то компания помимо собственно инвестиций предложит клиентам CoreWeave свои хранилища в рамках стратегического альянса с оператором. Инвестиционный банк William Blair оценивает сделку между Pure Storage и CoreWeave в десятки миллионов долларов. Речь идёт о подписке Evergreen//One, что делает CoreWeave одним из ключевых клиентов Pure Storage. 
Источник изображения: Sebastian Herrmann/unsplash.com Впрочем, в банке считают, что сделка не является неким крупным соглашением с гиперскейлером, о котором Pure Storage неоднократно сообщала, избегая деталей — CoreWeave пока не входит в десятку крупнейших гиперскейлеров. Как минимум с прошлого года CoreWeave также пользуется хранилищами ещё одного молодого поставщика All-Flash СХД — VAST Data. |
|


